寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 任务一:阅读《构建之法》并提问、任务二:完成词频统计个人作业、任务三:撰写博客 |
| 其他参考文献 | CSDN、博客园、简书等 |
part1:阅读《构建之法》并提问
1.1 问题一
在书中2.3个人开发流程中,书里写到“PSP依赖于数据。如果数据不准确或有遗失,怎么办?让工程师编造些?”,
- 我有了这个问题:如何保证数据准确呢。我在这次作业编写程序过程中明显感受到计划赶不上变化,并不能很好的预估时间。而我上网查了资料,感觉这方面的内容也比较少,看的也不是很明白,就感觉时间不知道怎么预估,有些模块在做的时候甚至不知道自己做了,导致感觉自己统计的时间也不是很准确,总结之后我的理解是:感觉现在这份表格,感觉有的不适合现在的我们的普通作业,比如生成设计文档等,可能在脑子里想想就过去了,有些部分在这次作业中不会出现,这就导致这部分的内容很难预估时间,我的困惑是如何能在各种项目中都写好PSP。
1.2 问题二
在书中3.2软件工程师的思维误区中,书里写到“一个工程师在写程序时,经常容易在某个问题上陷进去,花大量时间对其进行优化,无视这个模块对全局的重要性,甚至还不知道这个“全局”是怎么样的。这个毛病早就被归纳为“过早的优化是一切罪恶的根源"
- 我有了这个问题:难道在各种项目中过早优化都是不好的吗,上网查阅资料后看到了一些观点:1、过早优化出现在一些相对容易解决的问题。2、过早优化是一种“美好的愿景”。3、过早优化是由于未能正确对任务进行优先级排序。目前根据我自己的一些经验,似乎过早优化并没有坏处,反而感觉如果有的项目,作业之类,开头没有优化,会导致后期要优化时要改大量的代码。所以我目前的观点是一些小项目前期优化时可以的。也不知道自己的观点对不对。
1.3 问题三
在书中第5章第7章都讲了团队合作,书里写到“各司其职,对项目共同负责;团队的各个角色合起来,对整个项目最终的成功负责,为什么?因为每个角色在其职责范围内的失败都会导致整个项目的失败。”
- 平时,在进行团队合作时或多或少会出现团队各个组员实力不均,分配完任务,可能会因为某些问题有的组员抱着混一混的心思,并不能完成自己的任务。那这时候为了顺利完成任务,其他人就不仅要完成自己份内的任务还要兼顾别人任务,这就可能导致组员心态的失衡,网上很多办法都是换组员什么的,但我想知道有什么更好的办法可以避免这种现象呢,或者说如何调动组员的积极性呢?
1.4 问题四
在书中8.3.2提到了深度面谈来获取用户需求,“通过详细的面谈,广泛而深入地了解用户的背景、心理、需求等。这通常是一对一的采访。这种方法费时费力,效果往往取决于主持面谈的团队成员的能力。深入面谈这一方法也可以用在某一特定领域,例如软件的用户可用性和用户界面,这也可以称为软件可用性研究(Usability)”
- 文章提到深度面谈来获取用户需求,比如说进行用户界面的修改,但我的观点是:一千个观众眼中有一千个哈姆雷特,每个人的审美也是不同的,可能有的人认为这个界面好看,有的人认为那个界面好看,但深度面谈这种方法费时费力显然不可能大规模开展,取到的样本数也应该不会太多,那怎么能判断出深度面谈所获得的需求一定会适用于大多数人呢?
、
1.5 问题五
在书中12.1.6用户体验和质量中,书里写到“好的用户体验当然是所有人都想要的,如果它和产品的质量有冲突,怎么办?牺牲质量去追求用户体验么,用户能接受么?”
- 看了后面杰克·韦尔奇的故事,我有了这样问题到底是体验>质量,还是质量>体验呢,如何能找到他们之前的平衡点呢?网上有些的说法是这样的:“用户需求是根本,在用户体验这个问题上,还要特别考虑到短期刺激和长期影响,在必要的时候我觉得可以牺牲软件质量去追求用户体验。”因为项目做得不多在这方面也没有什么直观的感受,看完了网上的回答的困惑是如何能更好平衡产品质量和用户体验呢?
附加题
故事:玛丽·肯尼思·凯勒(Mary Kenneth Keller)在计算机科学历史上绝对占有一席之地:她还是研究生时,帮助开发了BASIC语言;1965年从威斯康星大学计算机学系拿到了博士学位,这让她成为第一批计算机学博士。同一个月,欧文·C·唐(Irving C. Tang)拿到了他在华盛顿大学圣路易斯分校的理学博士;这意味着,拥有计算机学博士学位的所有人当中有一半一度是女性。让这个故事更具戏剧性的是,凯勒还是个修女,来自圣母玛利亚修女会,受命致力于教育事业。后来,凯勒在克拉克学院担任了20年的计算机学系系主任。
见解:并不能说做程序员男生一定比女生有优势,从事任何一份职业,努力必然会有结果,所以无论是男性还是女性,用能力和代码来说话,每一个热爱编程、肯于努力的人都会有回报。
part2:WordCount编程
2.1 Github项目地址
2.2 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 415 | 740 |
| • Analysis | • 需求分析 (包括学习新技术) | 70 | 40 |
| • Design Spec | • 生成设计文档 | 20 | 20 |
| • Design Review | • 设计复审 | 20 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 5 | 30 |
| • Design | • 具体设计 | 20 | 40 |
| • Coding | • 具体编码 | 120 | 200 |
| • Code Review | • 代码复审 | 40 | 80 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 300 |
| Reporting | 报告 | 55 | 65 |
| • Test Repor | • 测试报告 | 20 | 20 |
| • Size Measurement | • 计算工作量 | 15 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 490 | 835 |
2.3 解题思路描述
- 看到输入文件和输出文件以命令行参数传入,想到涉及文件读写就想着有没有高效的文件读写方式
- 统计文件的字符,因为只需要统计Ascii码,汉字不需考虑,感觉一个个字符读出来取长度就行了
- 统计单词当时一开始想的是循环暴力判断,后面做的时候发现好像可以通过正则表达式取出单词,就直接去其他博文上查找正则的知识
- 统计有效空行,想的是取出行后trim完和空字符串对比即可判断
- 统计单词Top10看到要用键值储存就想到hashmap,要排序什么的感觉hashmap应该也有方法,就要用hashmap存放单词
- 查询资料主要是CSDN、简书、博客园等
2.4 代码规范制定链接
2.5 设计与实现过程
代码分为Lib类(7个函数)和WordCount类(2个函数),WordCount类通过调用Lib类中的方法来完成要求:
Lib类
public class Lib {
//统计字符数
public static int countCharacters(String str)
//统计有效行数
public static int countLines(String str)
//统计单词数
public static int countWords(String str, HashMap<String, Integer> wordMap)
//按照单词出现个数排序
public static List<HashMap.Entry<String, Integer>> getSortedList(HashMap<String, Integer> wordMap)
//读取输入文件
public static String readFile(String filePath) throws IOException
//将结果拼接成字符串
public static String getResStr(int charsNum, int wordsNum, int linesNum
, HashMap<String, Integer> wordMap)
//将拼接的字符串写入文件
public static void writeFile(String filePath, int charsNum, int wordsNum, int linesNum
, HashMap<String, Integer> wordMap) throws IOException
}
WordCount类
public class WordCount {
//构造函数
public WordCount(String filePath) throws IOException
//主函数
public static void main(String[] args) throws IOException
}
流程图
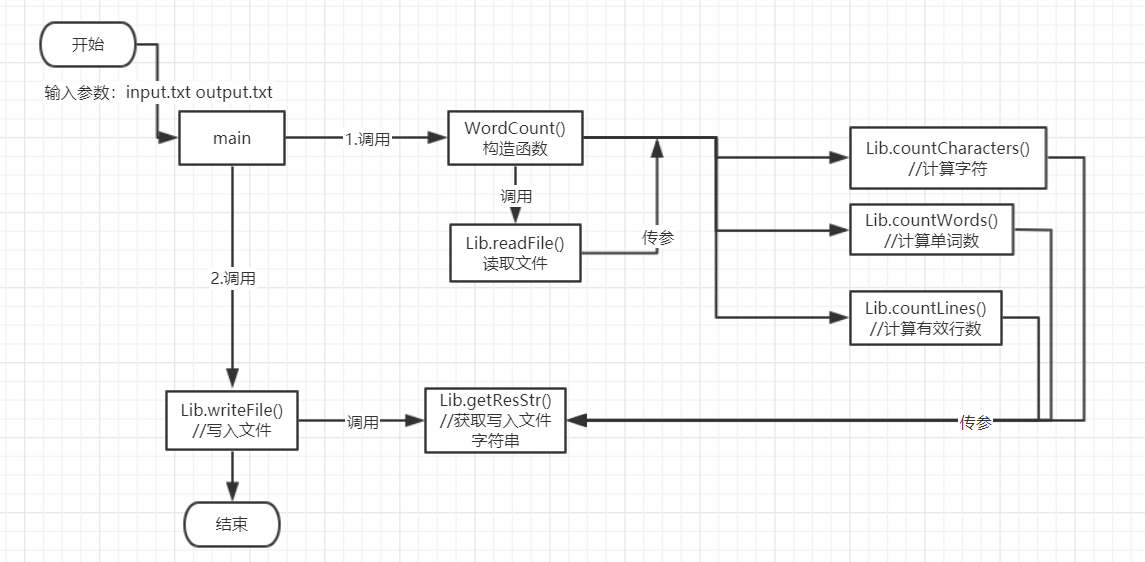
函数关系
WordCount()构造函数,调用readFile()函数将文件读入为字符串,并将得到的字符串作为参数传递给countCharacters,countLines,countWords三个函数获取字符数、有效行数、单词数。getResStr()获取结果字符串函数,调用getSortedList()函数,对单词按出现次数进行排序。writeFile()写入文件函数,调用getResStr()函数获取最终结果字符串,并将字符串写入文件。
主要函数介绍
- 读取文件:通过
BufferWriter,将文件的每个字符读出,并通过StringBuilder拼接成字符串返回。这样,所返回的字符串可以用于多个方法,而不用多次读入文件。
public static String readFile(String filePath) throws IOException {
...
while ((ch = reader.read()) != -1) {
str.append((char)ch);
}
...
}
- 统计文件字符数:因为只需要统计Ascii码,汉字不需考虑,直接获取
length()即可
public static int countCharacters(String str) {
return str.length();
}
- 统计文件有效行数:先通过
str.split("\r\n|\n")将文件字符串按行分割,然后再将分割出来的每行去掉空白符与空字符串对比,如果不是空字符串则有效行数+1
public static int countLines(String str) {
...
String[] strLine = str.split("\r\n|\n");
for (String validLine : strLine) {
if (!validLine.replaceAll("\r|\n", "").trim().equals("")) {
cnt++;
}
}
...
}
- 统计文件单词数:因为单词是以分隔符分割,用正则表达式
[^a-zA-Z0-9]对文件字符串分割,分割出的字符串即可能会成为单词,然后再用正则表达式^[a-z]{4}[a-z0-9]*判断分割出的字符串是否为单词(因为word = word.toLowerCase(),所以不用正则表达式中不需要A-Z),若是单词则存入wordMap中.
public static int countWords(String str, HashMap<String, Integer> wordMap) {
...
Pattern pattern = Pattern.compile("^[a-z]{4}[a-z0-9]*");
Matcher matcher = null;
String[] wordStrTmp = str.split("[^a-zA-Z0-9]");
for (String word : wordStrTmp) {
word = word.toLowerCase();
matcher = pattern.matcher(word);
if (!word.equals("") && matcher.find()) {
cnt++;
if(wordMap.containsKey(word)) {
wordMap.put(word, wordMap.get(word) + 1);
}
else {
wordMap.put(word, 1);
}
}
}
...
}
- 单词出现次数排序:
HashMap改为List存储,再用Collections.sort进行排序
public static List<HashMap.Entry<String, Integer>> getSortedList(HashMap<String, Integer> wordMap) {
...
Collections.sort(list, new Comparator<Map.Entry<String,Integer>>() {
public int compare(Map.Entry<String,Integer> o1, Map.Entry<String,Integer> o2){
if(o1.getValue().equals(o2.getValue())) {
return o1.getKey().compareTo(o2.getKey());
}
return o2.getValue().compareTo(o1.getValue());
}
});
...
}
2.6 性能改进
- 减少IO次数,一开始在统计字符、统计空行等函数里都要进行读入文件操作,后来把读取文件单独独立为一个函数,统计字符函数只需要接收字符串即可,减少了读取文件次数。
- 用
BufferWriter替代FileWriter,前者有效的使用了缓存器将缓存写满以后(或者close以后)才输出到文件中,然而后者每写一次数据,磁盘就会进行一次写操作。 - 一开始是使用
String不停拼接字符来存取文件中的数据
String str = "";
while ((ch = reader.read()) != -1) {
str += (char)ch;
}
- 但
String每一次内容发生改变,都会生成一个新的对象,小文件在读取时影响不大,但在稍大文件效率就很低 - 于是改用
StringBulider来存放数据
StringBuilder str = new StringBuilder();
while ((ch = reader.read()) != -1) {
str.append((char)ch);
}
- 下面是读取50w字符文件用
String进行拼接所需耗时

- 下面是读取50w字符文件用
StringBuilder进行拼接所需耗时

2.7 单元测试
测试函数说明
- 单个函数测试,均是通过
BufferedWriter将数据写入文件,并在单元测试函数汇总调用Lib类中对应方法进行测试,并通过Assert.assertEquals()将测试函数的结果与预期结果进行比较。
下为部分单元测试函数(部分测试样例):
- 字符统计
@org.junit.jupiter.api.Test
void testCountCharacters() throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("test1.txt"));
String str = "aaa[ \t$bbbbb\nsdsd\r\n1";
for (int i = 0; i < 10000; i++) {
bw.write(str);
}
bw.close();
String test = testReadFile("test1.txt");
int cnt = Lib.countCharacters(test);
Assert.assertEquals(cnt, 20 * 10000);
}
- 单词统计
@org.junit.jupiter.api.Test
void testCountWords() throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("test3.txt"));
String str = "tes@word\naaaa\tqifei123|]haoye(123test)123test123\t\r\nwuhu\n";
HashMap<String, Integer> wordMap = new HashMap<>();
for (int i = 0; i < 10000; i++) {
bw.write(str);
}
bw.close();
String test = testReadFile("test3.txt");
int cnt = Lib.countWords(test, wordMap);
Assert.assertEquals(cnt, 5 * 10000);
}
- 整体运行测试
@org.junit.jupiter.api.Test
void testMain() throws IOException {
String str = Lib.readFile("input5.txt");
HashMap<String, Integer> wordMap = new HashMap<>();
int charNum = Lib.countCharacters(str);
int lineNum = Lib.countLines(str);
int wordNum = Lib.countWords(str, wordMap);
Lib.writeFile("output.txt", charNum, wordNum, lineNum, wordMap);
}
构造测试数据的思路
- 1、尽量覆盖多的测试范围
- 2、测试数据量大
- 3、包含大量空白字符,大量换行,开头结尾换行
- 4、包含大量非法单词(如:98qwer123456)
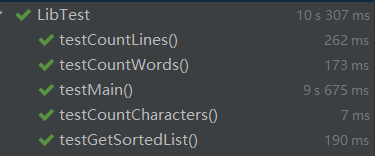
测试覆盖率截图

如何优化覆盖率
- 1、代码尽量简洁,删除重复的代码
- 2、
try/catch中有的异常可能会没有覆盖到,可以选择编写一个异常类 - 3、简化逻辑,不要一直增加if
2.8 异常处理说明
- 本次作业异常较少,主要是文件异常(
IOException和FileNotFoundException)和用户输入异常 - 用户输入命令行参数不对时:

- 用户输入的文件不存在:

- 用户输出文件不存在则会自动创建文件
2.9 心路历程与收获
- 在这次作业中感觉收获了很多,之前虽然用过git,github但也已经好久没用了,这次作业终于捡起来了,更加深入了解了版本控制,也体会到了代码应该一实现一个小模块就该签入,而不是等到写了很多再进行签入。
- 通过这次作业也学习了单元测试,之前并没有体会到它的优点,进行单元测试感觉能让自己的代码更为可靠,也能更好的减少bug吧,也感觉通过观察覆盖率去让自己的方法更为简洁有效。
- 通过编写PSP表格,深深体会到把握开发流程的重要性,强迫自己去做好规划,而不是直接上手去写代码,这样编出来的程序也更有条理,但第一次写感觉预估时间不是很准确,感觉还是要多写多估。
- 也好好巩固了Java知识吧,毕竟好久没用都有点忘了,之前只记得有hashmap,api啥的都忘记了,感觉代码其实还是要多打,打多了就记得牢了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号