关键词检索与阅读模型
https://aclanthology.org/N19-1030/
摘要
这里介绍了一个检索器-阅读器的模型,它是专门建立在大规模文本库上的多项选择器阅读理解任务,检索器利用关键字抽取技术提高了检索结果与问题的相关性,阅读器根据检索结果,问题和选项建立了网络模型。
主要有两部分
- 检索器
找出问题中最重要的单词,和选项一起生成query,去长文本中查询相应的片段
- 阅读器
区分关键字和干扰字去预测答案
引言
QA面临的问题
- 有些问题,很难在文中找相应的依据
- 回答问题的形式是多样化的
- 机器需要去理解很长且复杂的文本,而不是简单的匹配
解决方法
要么用整合常识,要么提高检索能力,以便更好地找到答案
方法
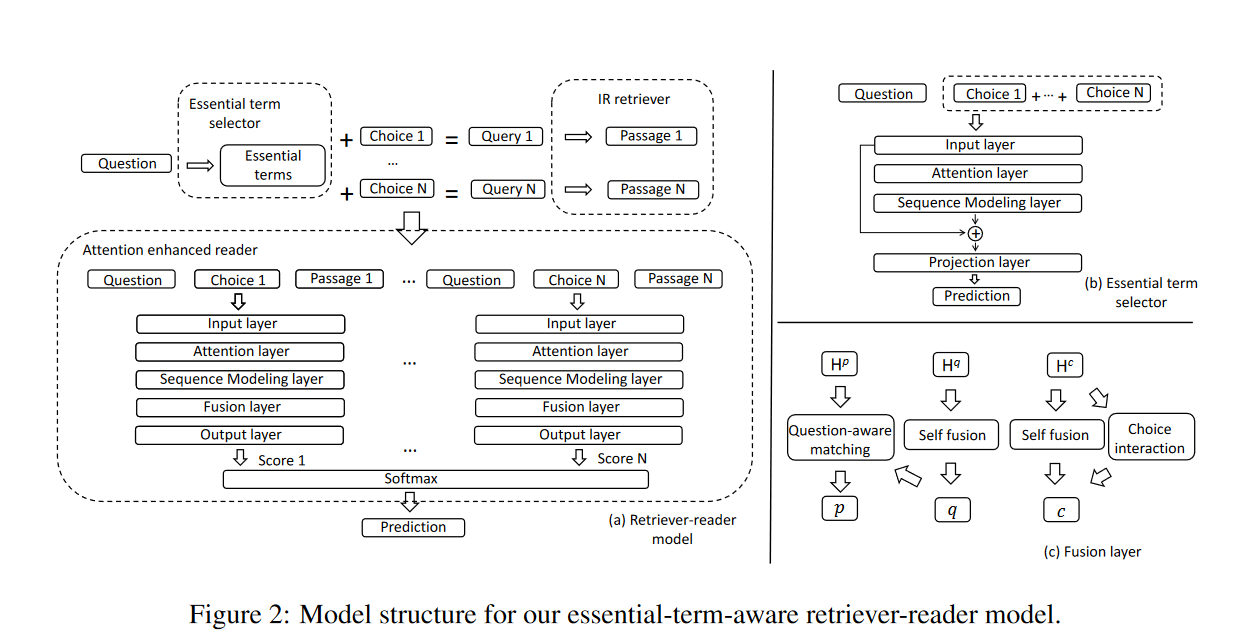
阅读器
阅读器的输入是问题Q,选项\(C_{i}\)和\(P_{i}\)。
Input Layer
每个单词需要经历以下Embedding
Word Embedding
预训练的GloVe词嵌入,维度是300
Part-of-Speech Embedding and Named-Entity Embedding
对单词的词性和命名实体进行编码,16维的
Relation Embedding
利用大规模单词关系图ConceptNet获得文章中的每个单词与问题及选项中每个单词的关系。例如“汽车”和“行驶”之间的关系就可以为“可以”,"卡车" 和“汽车"之间的关系可以为”是一种“。然后,ET-RR建立编码字典,每种关系都有一个10维的编码,将单词w找到的关系r所对应的编码拼接在w的单词编码后,如果单词w和问题及选项中有多种的话,随机选一种
Feature Embedding
根据文章P中的单词w是否在问题和选项中出现,ET-RR给w加入了一个1维的0/1精确匹配编码,还加入了一个w出现频率的对数也作为一维编码
Attention Layer
经过上面的四个编码后,问题中所有单词的词向量矩阵\(W_{Q}\)和所有选项拼接而成的文本的向量组成的词向量矩阵\(W_{C}\),和所有文章单词的词向量矩阵\(W_{P}\)
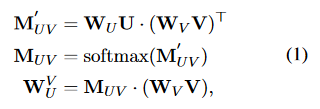
通过上面公式分别计算
1.文章到问题的注意力向量\(W^{Q}_{P}\)
2.选项到问题的注意力向量\(W^{Q}_{C}\)
3.选项到文章的注意力向量\(W^{P}_{C}\)
Sequence Modeling Layer
这里使用双向LSTM处理输入层和注意力层的单词表示
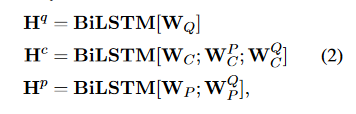
Fusion Layer
问题和选项经过单词向量加权和,各自用一个向量q和c来表示
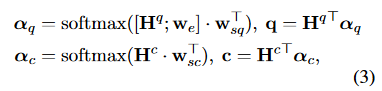
\(w_{sq}\)和\(w_{sc}\)为参数向量,\(w_{e}\)向量是关键字选择器的输出,格式为
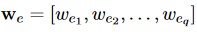
其中\(w_{ei}\)的值的Q中第i个字是否为关键字,1为是,0为不是
Choice Interaction
将\(H^{C_n}\)(\(H^{C}\)中最后一个隐藏状态)和每一个隐藏状态\(H^{C_i}\),通过下面公式
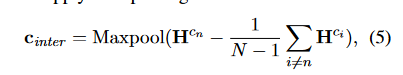
然后拼接
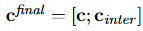
Output Layer
输入为
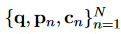
输出为
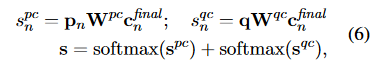
检索器
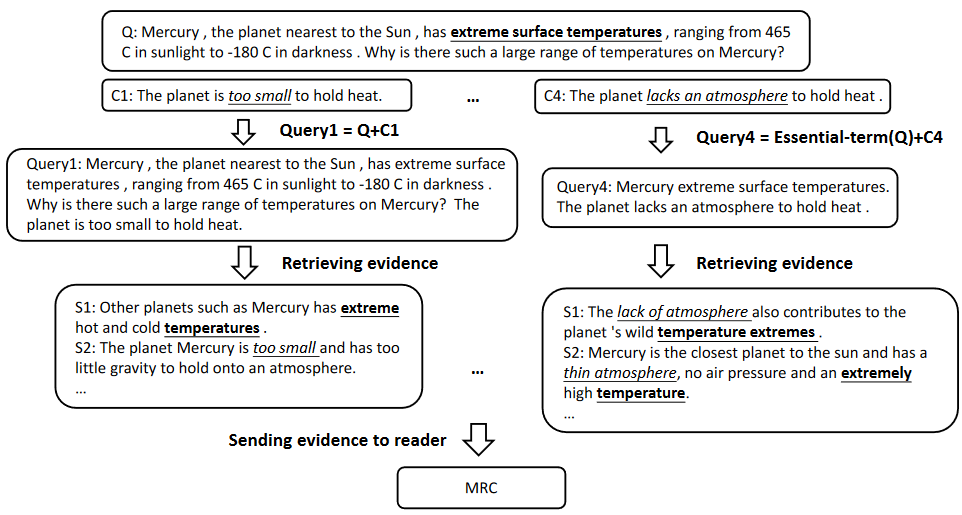
通过上图可以看出有检索器的话,查找依据就准确很多
给定问题Q和N个选项\(C_{i},..,C_{N}\),就是想预测\(Q_{i}\)是否为关键字,1代表是,0代表不是。
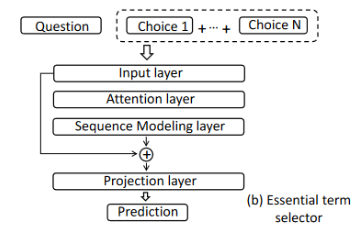
检索器的结构和阅读器的结构差不多,Q和C经过输入层获得了嵌入矩阵表示后,然后经过注意力层计算带有选项感知的问题表示\(W^{C}_{Q}\),
然后送入到序列模型层得到
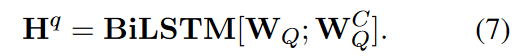
然后就计算y
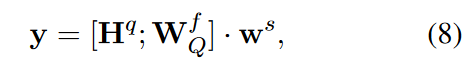


 浙公网安备 33010602011771号
浙公网安备 33010602011771号