实用机器学习
1.1 课程介绍
机器学习的流程
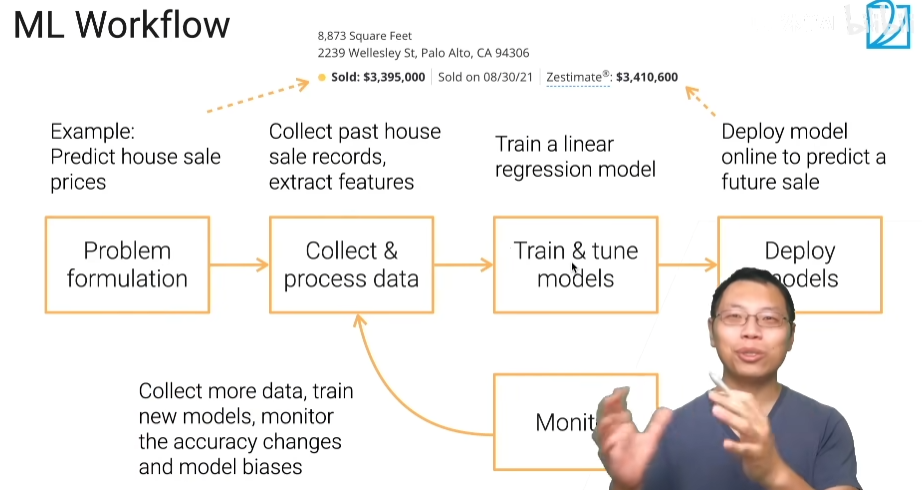
1)将问题变为机器学习的问题
2)收集数据
3)训练模型,调参
4)部署上线,预测一些未来的事情
5)部署后,你会得到新的数据,把新的数据收集过来,重新处理好
所面临的问题

- 有些问题很难转换为机器学习的问题
- 获得好质量的数据是很难的
- 模型不好训练
- 部署的话,花销比较大
- 需要长期监控你的模型
1.2 数据获取
常见的数据集

找数据集的地方

- Paperswithcodes Datasets Machine Learning Datasets | Papers With Code
- Kaggle Datasets Find Open Datasets and Machine Learning Projects | Kaggle
- Google Dataset search Dataset Search (google.com)
- Open Data on AWS AWS Marketplace: Search Results (amazon.com)
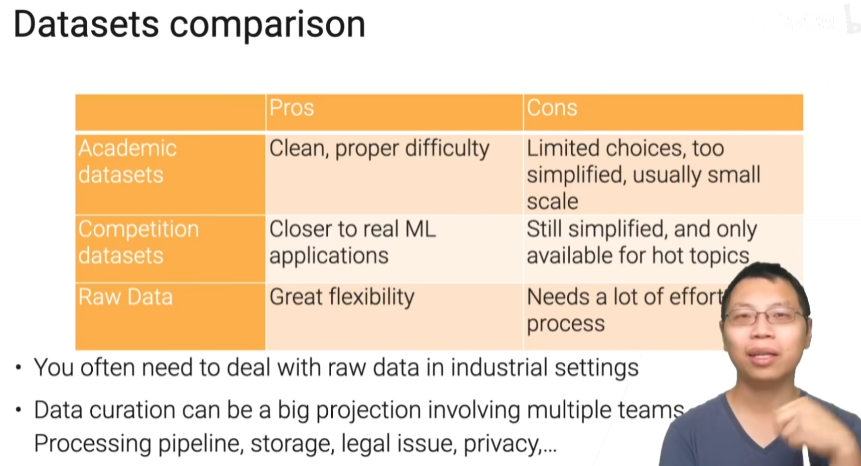
不用数据集的对比
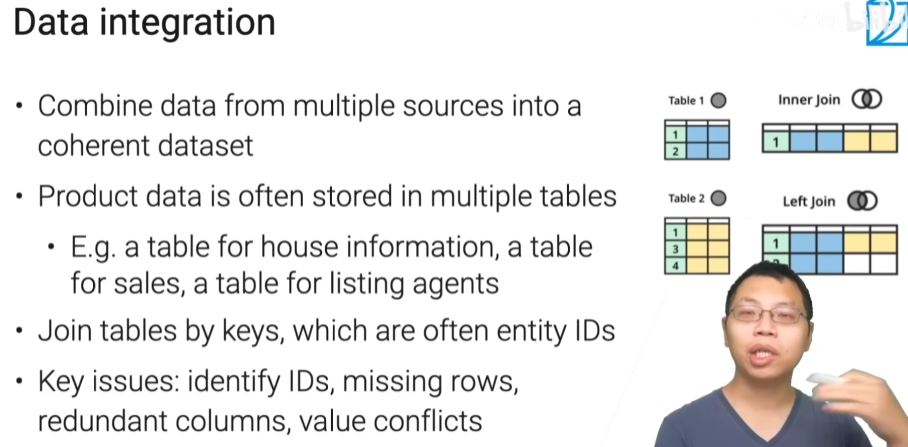
数据融合
生成合成数据

- 使用GAN
- 数据增强
1.3 网页数据抓取
抓取网页
from selenium import webdriver # webdriver是Chrome的后台
chrome_options = webdriver.ChromeOptions # 获取chrome的一个属性
chrome_options.headless = True # true代表不需要图形化界面
chrome = webdriver.Chrome( # 在python里面创建一个这样的实例
chrome_options = chrome_options
executable_path= r'E:\chromedriver.exe' # 还需要指定浏览器位置
)
page = chrome.get(url) # 通过get方法,把url放进去,那么它会返回你的html配置
获取房子的ID
page = BeautifulSoup(open(html_path,'r')) # 打开已经爬好的网页
links = [a['href'] for a in page.find_all('a','list-card-link')] # 把所有的link元素找出来
ids = [l.split('/')[-2].split('_')[0] for l in links] # 把id存下来
抽取数据
sold_items = [a.text for a in page.find('div','ds-home-details-chip').find('p').find_all('span')]
for item in sold_items:
if 'Sold:' in item:
result['Sold Price'] = item.split(' ')[1]
if 'Sold on' in item:
result['Sold On'] = item.split(' ')[-1]
获取图片的url
p = r'https:\\/\\/phots.zillowstatic.com\\/fp\\/([\d\w\-\-]+).jpg'
ids = [a.split('-')[0] for a in re.findall(p,html)]
urls = [f'https://photos.zillowstatic.com/fp/{id}-uncropped_scaled_within_1536_1152.jpg' for id in ids]
1.4 数据标注
数据标注流程
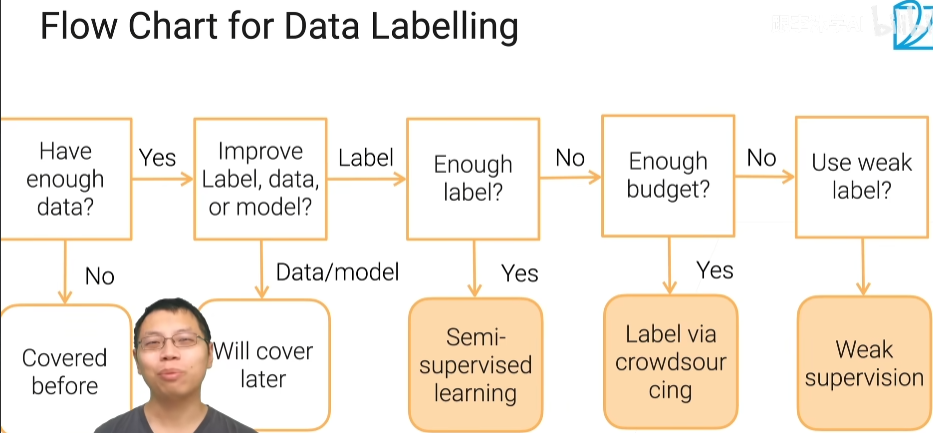
半监督学习

自训练
先对已经标好的数据进行学习,然后对没有标好的数据进行预测,对没有标注的数据拿到一些伪标号,再和已经标好的数据合并起来,再训练新的模型,不断迭代,不断训练
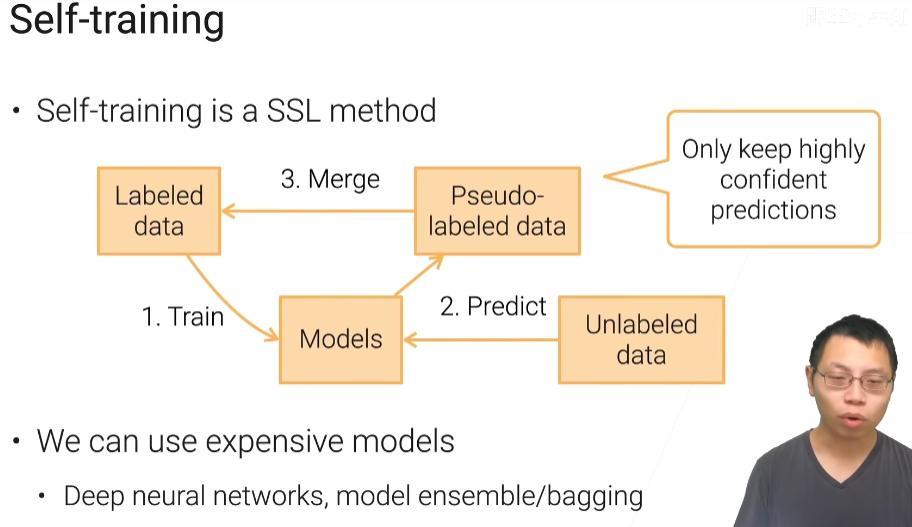
主动学习

和半监督学习类似,但是会有人的干预,最不确信的样本让人来确信
主动学习和自训练
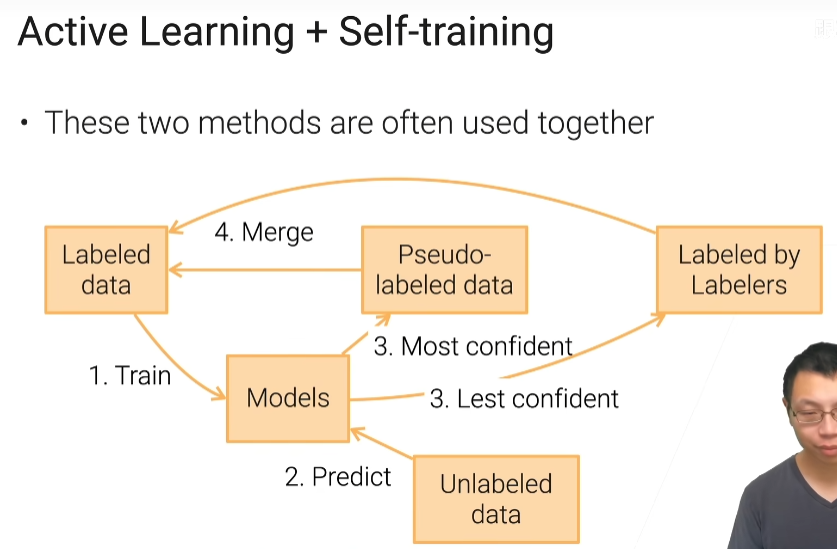
对于所有的剩下的没有标注的数据进行预测,预测里面最置信的模型放在伪标号数据中,然后和已经标好的数据合并,最不确信的数据在让标注工进行标注,标注好了再合并
弱监督学习
他就是半自动的生成标号,但是通常呢有时他比人标的要差一些,但是好到可以训练个也还不错的模型
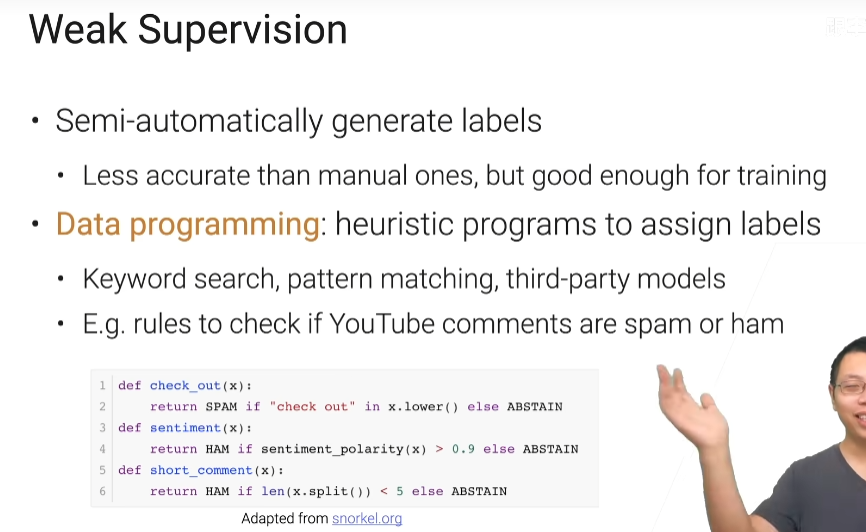
总结

-
标注的方法
- 自训练:你有已经有一些样本的标号了,然后我们不断的去训练模型,把这些模型在没有标的数据上预测比较准的那些东西,放进我的标注集里面,不断训练,直到说我们标注了足够多的数据
- 众包:机器不容易标注的让人来标注
-
没有标号,可以选择无监督的算法
2.1 探索性数据分析
步骤
第一步导包和读文件
import numpy as np
import pandas as pd
import seaborn as sns
from IPython import display
import matplotlib.pyplot as plt
import pyarrow # 不导入这个,等下data那里会报错
display.set_matplotlib_formats('svg')
data = pd.read_feather('house_sales.ftr')
第二步查看数据的大小
data.shape
data.head() # jyputer里面有用
第三步,如果数据某一列的缺失30%以上的值,我们就把它丢失掉
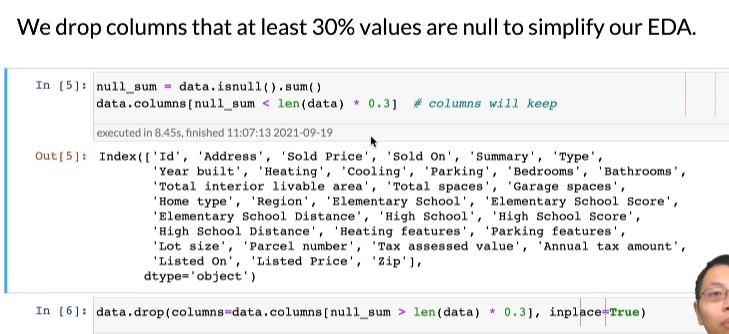
null_sum = data.isnull().sum() # 统计这一列中空值的个数
print(type(null_sum)) # <class 'pandas.core.series.Series'>
print(null_sum < len(data)*0.3)
data.columns[null_sum < len(data)*0.3] # 查看缺失率低于30%的列
data.drop(columns=data.columns[null_sum > len(data) * 0.3],inplace=True) # 删除缺失率大于30%的列,inplace表示把这个输入的data里面的列去掉
下图是上面第4行代码运行的结果,展示趋势率低于30%的列

第四步,查看数据的类型
data.dtype
第五步,将货币从字符类型转换为数值类型

currency = ['Sold Price','Listed Price','Tax assessed value','Annual tax amount']
for c in currency:
data[c] = data[c].replace(
r'[$,-]','',regex=True).replace( # 将'$', ',' , '-' 替换为空
r'^\s*$',np.nan,regex=True).astype(float) # 将 空字符串 ,转换为not a number
第六步,将面积从字符类型转换数值类型
面积实例
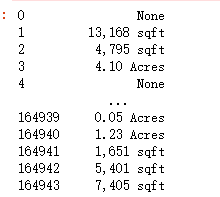
areas = ['Total interior livable area','Lot size']
for c in areas:
acres = data[c].str.contains('Acres') == True
print(acres) # True or False
col = data[c].replace(r'\b sqft\b|\b Acres\b|\b,\b','',regex=True).astype(float) #将sqft,acres替换为空
col[acres] *= 43560 # 1 acres = 43560 square feet
data[c] = col
acres和col[acres]结果,col[acres]会对acres里面为true的值进行更改
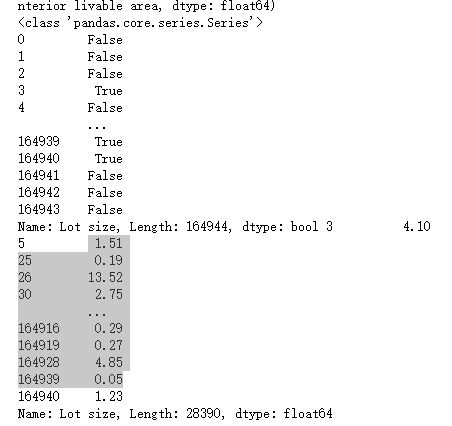
思路:获取到目标列后,会逐行遍历列里面的内容,将列里面的sqft和Acres替换为空,对含有acres的会乘上43560进行转换
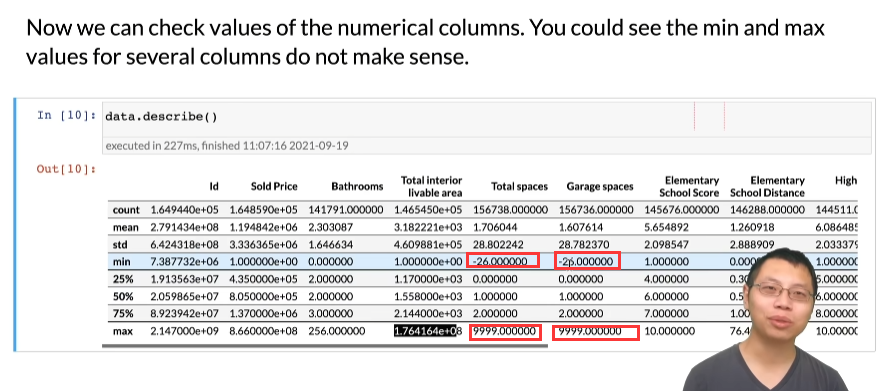
第七步,查看处理后的结果,可以根据最大值和最小值找出异常数值
第八步,对异常值进行处理,为后面画图做好准备,这里拿房子的可居住面积处理,例如说住居面积不到1平米,或者大于1万平米,
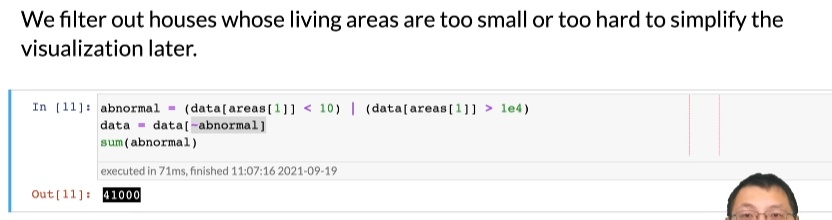
abnormal = (data[areas[1]] < 10) | (data[areas[1]] > 1e4)
data = data[~abnormal]
sum(abnormal)
发现不正常的点大约有4万个
第九步,查看卖的价格的分布图
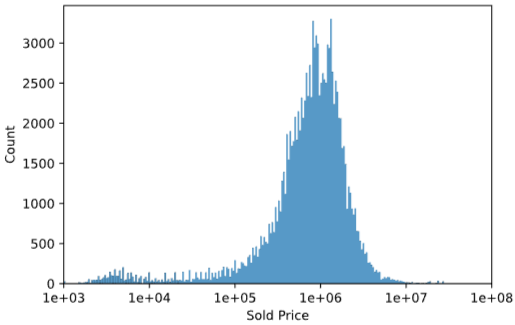
ax = sns.histplot(np.log10(data['Sold Price'])) # 对价格做log10以后,会显得分布的均匀一点,否则预测容易出现负值
ax.set_xlim([3, 8])
ax.set_xticks(range(3, 9))
ax.set_xticklabels(['%.0e'%a for a in 10**ax.get_xticks()]);
histplot:直方图
xlim:设置x轴的最大最小值
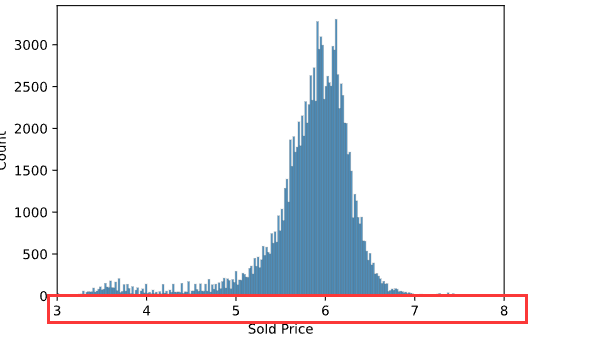
xticks:设置刻度值
xtickslabels:为每个刻度值指定一个标签
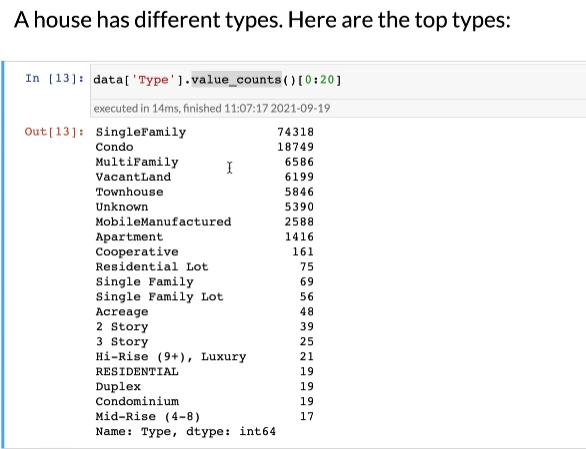
第十步,查看房子的种类,有些房子的种类是属于噪音,等下在清理,最重要的就是前面的几个类别
value_counts:返回每个项的计数
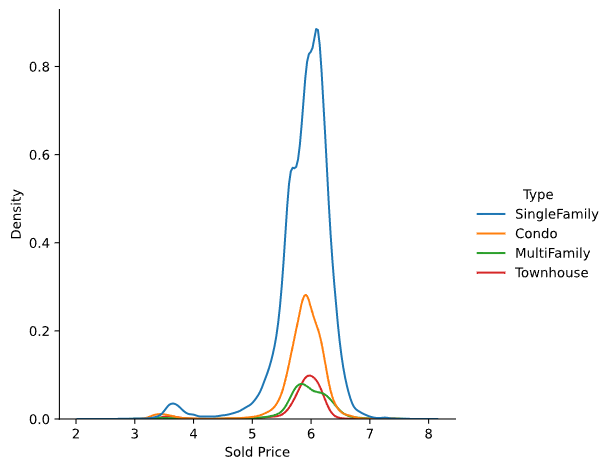
第十一步,查看不同类别房子的价格
types = data['Type'].isin(['SingleFamily','Condo','MultiFamily','Townhouse'])
sns.displot(pd.DataFrame(
{
'Sold Price':np.log10(data[types]['Sold Price']),
'Type':data[types] ['Type']
}
),x='Sold Price',hue='Type',kind='kde')
types的结果

接下来会将值为true的结果的sold price和type在图上显示出现
displot:密度图
第十二步,查看一平米卖多少钱
data['Price per living sqft'] = data['Sold Price'] / data['Total interior livable area']
ax = sns.boxplot(x='Type', y='Price per living sqft', data=data[types], fliersize=0)
ax.set_ylim([0,2000])
boxplot:箱型图
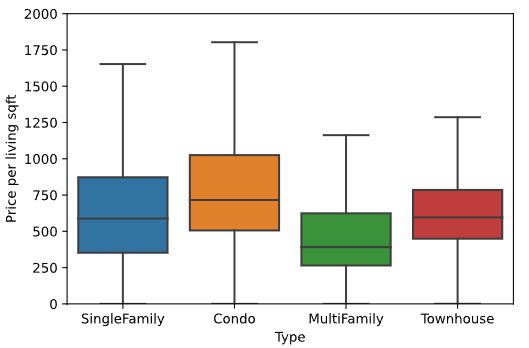
第十三步,查看前20的邮政编码每平米卖多少钱
首先查看前20的邮政编码有那些
data['Zip'].value_counts()

接下来取属于前20的邮政编码的数据的keys值(可以理解为索引)
data['Zip'].value_counts()[:20].keys()

判断结果
data['Zip'].isin(data['Zip'].value_counts()[:20].keys())

取出在前20邮政编码的数据
d = data[data['Zip'].isin(data['Zip'].value_counts()[:20].keys())]
完整代码
d = data[data['Zip'].isin(data['Zip'].value_counts()[:20].keys())]
ax = sns.boxplot(x='Zip',y='Price per living sqft',data=d,fliersize=0)
ax.set_ylim([0,2000])
ax.set_xticklabels(ax.get_xticklabels(),rotation=90)
运行结果
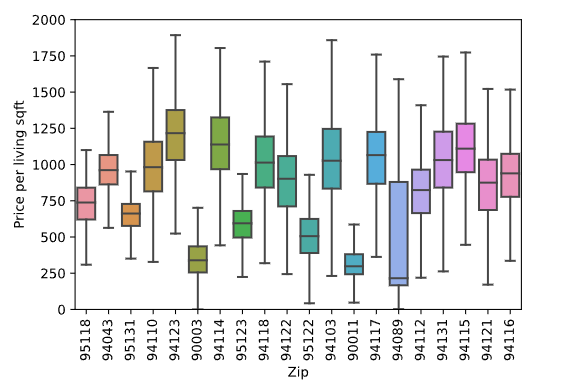
第十四步,我们查看每个特征之间的一些关系,查看协方差矩阵
_,ax = plt.subplots(figsize=(6,6))
columns = ['Sold Price','Listed Price','Annual tax amount','Price per living sqft','Elementary School Score','High School Score']
sns.heatmap(data[columns].corr(),annot=True,cmap='RdYlGn',ax=ax)
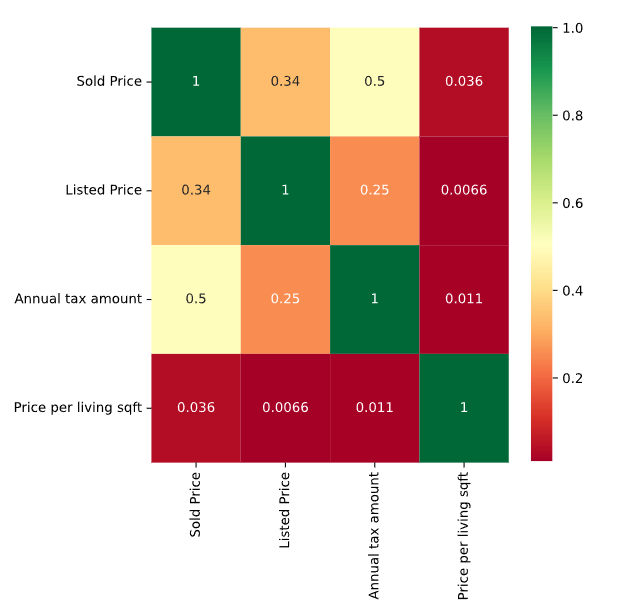
总结
- 演示了一些做探索性数据分析的一些最基本的技能,比如查看每列的类型,是否需要进行转换,值对不对
- 看下不同列之间的关系
- 看了一下比较简单的分析,比如房价和小学,中学,每年纳的税的关联程度
2.2 数据清理
数据处理流程
数据错误类型

通常分为三类
- 数据的值不在正常分布的区间内
- 规则冲突
- 违反了自定义限制
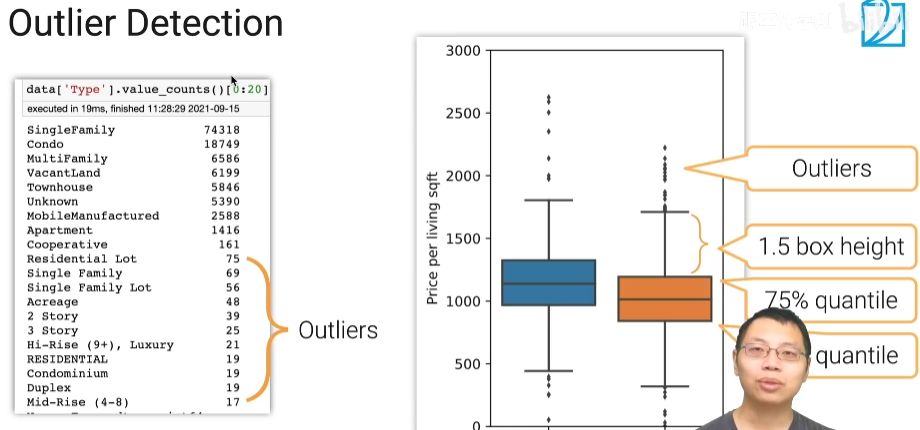
outlier类型错误
左边的图片中,有的名称不符合要求,需要进行修改,比如single family之间不要加空格,去掉空格以后,就可以和第一个SingleFamily合并
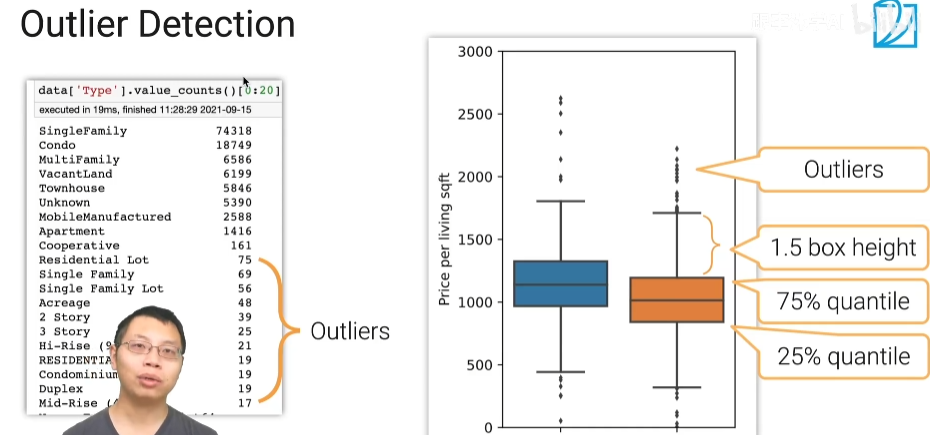
右边的图片中,那些点不在数值的范围
rule-based detection

Pattern-based detection
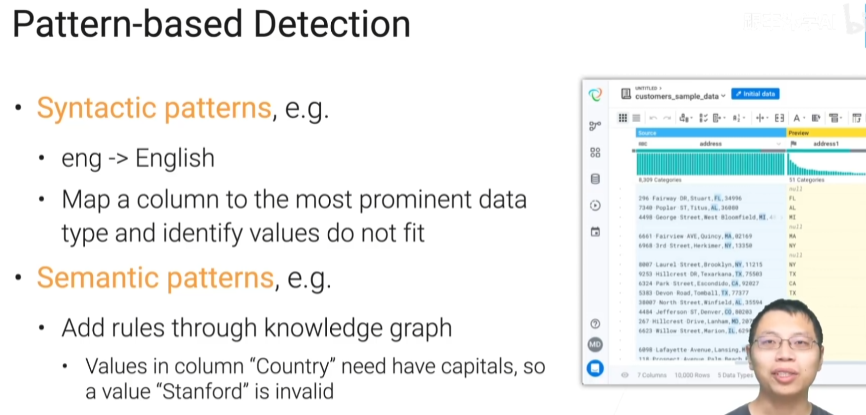
总结

数据里面总是有错误,错误特别多的时候,我们需要进行数据清理,通常的错误,你会发现是说有一些Outlier,Outlier就是一些比较外的点。包括了如果你是数值的话,那你就是在分布之外的。
另外是你和我定义的规则或者模式是有冲突的。
在数据清理这里,有大量的工具可以使用,它们提供一些图形界面,可以做交互式的数据清理
2.3 数据变换
常见的数据变换
实数的标准化
- 第一种(min-max normalization),把它的最小值和最大值都限定在个固定的区间里面,机器学习它对数值是比较敏感的,假设你的原始的那些特征啊最小值是啊1万最大值是100万的话,那么这个是只对于机器学习来讲是比较难的,因为你在算之后算梯度啊在更新的时候,很容易会产生数值不稳定性。然后而且你这个特征你那么大另外一个特征如果是在0和1之间的话,机器学习算法会觉得你这个特征(特别大)特别重要,因为你的数值那么大。
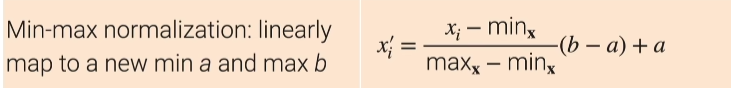
- 第二种(z-score),Z-score这个也是我们其实用的更常见的方法,因为你都不需要太指定说我们之前a和b是什么样子了,具体来说他是说我把那个一列的特征啊,他们所有的元素它的均值变成0方差变成1,就是说我对每一个元素它减去这一列里面所有的均值再除以你这一列里面的所有的方的方差那么得到xi‘,那么xi''呢就认为是啊你再去算这一列的值的话,那么均值是0它的方差等于1了,几乎是用的最常见的一种啊

- 第三种(decimal scaling),我把你整个xi换成是一 个零点几,或者是+1到-1之间的数字,可具体来说是我xi会除以十的一个j次方,这个j是最小的j使得使得你所有新的那一列里面他的绝对值小于1,就是说你的最大值和最小值都是在在+ 1和-1之间,而且你是在一个零点几的范畴
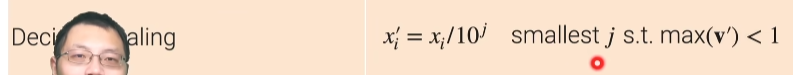
- 第四种,如果你的xi值是总是大于零的,它的数值相对来说它会变化比较大的话你可以通过一个log然后把它的东西拉成一个log的空间,对于比较大的正数我们经常用的一个变化
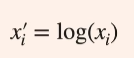
图片的变换

机器对分辨率低的图片识别率比较高,而且分辨率低意味着存储和读取就比较快,对中等图片进行压缩时,可能会下降1%的精度
视频的变换

你需要去平衡你的存储的大小,你数据的质量以及说你读取的速度,在机器学习里面我们通常会用很短的那些一段一段的小视频,通常来说比抖音可能还会短一点比短视频还要短一点就基本上在10秒以内啊
文本的变换

总结

我们需要将数据转换为机器学习所需要的,要平衡数据的大小,数据太大了就存储比较难而且读取的时候相对是比较慢,数据的质量就是说我要为了把数据的大小变小通常会通过大量的压缩的,需要保证质量,不能为了把它弄特别特别小就把质量给你丢掉了,因为数据弄得特别小你可以通过加机器来解决,掏钱来解决但你一旦数据质量你发生了不可逆的变化的话,就不行。一定的损害是没关系的一定压缩是可以的,但是你如果压缩太狠你机器学习的算法会有一定的精度的损失所以你这时会得不偿失。第三个当然是说你具体用什么格式来存呢,如果图片是一个一个放在文件系统里面的话,相对来说读起来比较慢,但你把图片放在一个一个文件里面,然后里面有个特定格式的话。那么相对是他读的却会比较快一点
如果是Tabular的话就是一个表的话那么你对实数是一些数值啊,你可以通过Normalization就把它的数值变成一个比较合理的区间
图片的话啊你可以通过剪裁下采样或者whitening把图片把它的大小变得小一点
video的话你会切成一段一段的一些片段使得你的通常机器学习是十秒以内啊,而且你可以采样出一些帧出来
文本的话我们会把文本呢通过一些词根化呀语法化呀得到一个相对来说比较常见的一些些形状,然后通过词原话得到你记忆学习要的那些小的单元
2.4 特征工程
为什么要有特征工程呢?
答:因为机器学习的算法他比较喜欢定义的比较好的,他能够比较好的去处理的,而且是固定长度的输入和输出
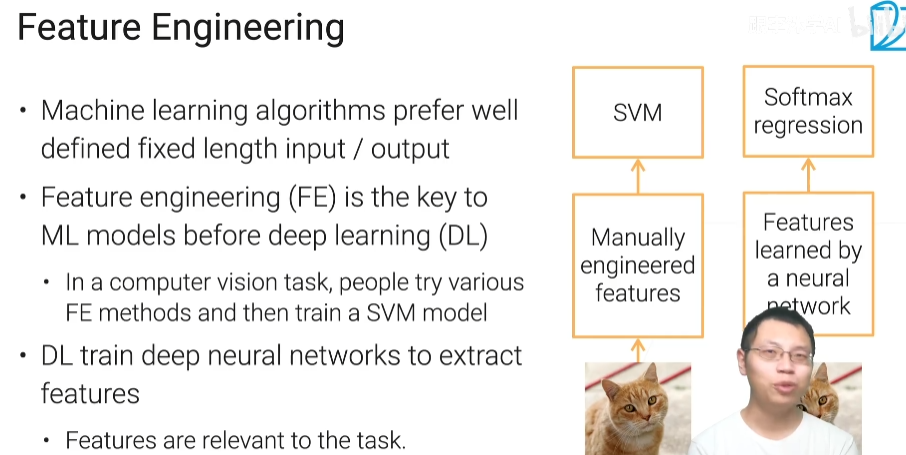
常见的数据进行特征工程
tabluar data feature(表数据特征)

- 表的数据呢如果你是一列啊,是一个整数型或者是浮点型的话呢,就是说直接放到一个机器学习模型里面可以直接用,不然的话你还有个做法是说你可以把它变成整个实数,把这个数值最大值和最小值拿出来把它切成n个bin(分桶),n个子区间。如果这个值在这个区间里话那就会把它给他一个这个区间的那个位置,就是第i个区间就是给他一个i。这样子的话一个实数值啊我就可以展开成一个长为n的一 个向量,其中第i个元素为1的话,就表示你这个实数值落在我的第i个那个区间里面,这样子好处是说你让机器学习算法不再去纠结于有一些数字你可能是比如说你的房价100万他101万,其实你在你看来其实没什么还有区别,但是机器学习对他来讲他就是一个数值也不一 样,所以他还可能去去仔细看这个东西,你可以现在告诉他说其实没关系,我就不需要那么细粒度的值,我给你一个比较粗粒度就行了
- 对于类别的数据,可以采用one-hot encoding独热编码
- 特征组合
text features(文本特征)
文本变化的时候可以把文本已经换成的一些token的一些词元,一个文本里面有很多个词元

- bag of words(BoW)model:把每一个词元,用one-hot表示,然后把所有这个句子里面词元给你加起来,具体来说你看到什么狗和猫和dinosaur,假设我这句话我要对他做表示的话,出现一次就加一次
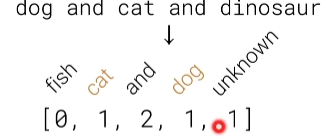
- word embedding(词嵌入):你先训练一 个词嵌入的模型,这个模型就他把一个词表示成一个向量,而且这个向量呢是之间是有一定的语义信息的,就是说他两个词他的对应的向量,如果他的距离比较近(算那个向量的内积啊)比较近的话,就是那个向量的那个角度比较近的话,那表示这个词在语义上来说是比较相近的。因为他在训练的时候呢去通过去在一个词通过预测他的那个上下文词来进行训练使得他训练出来的向量是有这样子的信息的,你如果把一段话的向量加起来或者做均值,通过word2vec就可以得到这句话的字嵌入的表示
现在用的最多的是预训练好的比较大的语言模型啊,比如说你大概可能听说过BERT呀GPT-3

Image/Video Features(图片/视频特征)

以前是手动提取(sift),现在是神经网络提取
总结

特征是非常重要的,在机器学习里面模型是一块,但是原始的数据到真正的模型中间有一个巨大的鸿沟啊,目前来看呢在一些应用上在图片上视频上文本上,现在用深度学习来抽取特征已经是一个主流了啊,但是在Tabular Data上呢现在还是有一点点困难,因为Tabular Data的话没有那么大的比较公用的一些数据集使能训练出一个巨大的一个神经网络
2.5 数据科学家的日常
所面临的挑战

3.1 机器学习介绍
机器学习算法分类

自监督学习,标号是数据产生的
强化学习,是模型跟环境进行交互,从环境中获取一些观察点,然后再进行学习
监督学习
训练中最重要的四个事情

model,loss,objective,optimization
监督模型的分类
决策树,线性方法,核机器,神经网络
总结
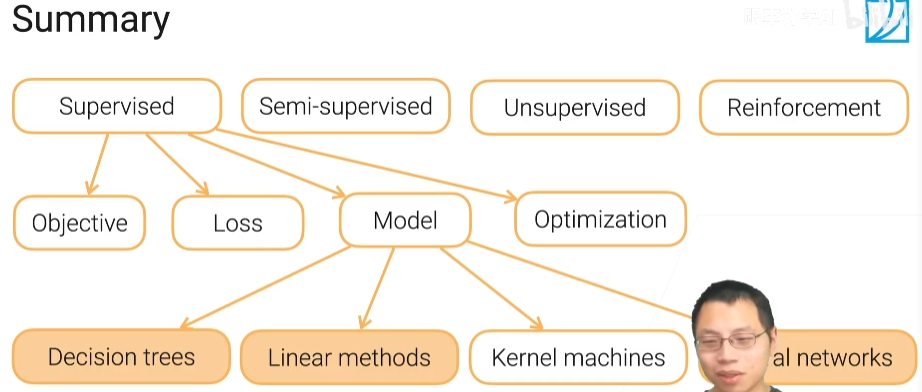
机器学习有那么四大任务就是监督学习半监督学习无监督学习以及强化学习
训练一个监督学习的任务呢有那么四个重要的部分啊目标函数损失模型和优化
模型可以分为决策树啊线性模型啊核方法呀以及神经网络
3.2 最简单也最常用的决策树

好处:
- 良好的解释性
- 它能够处理啊数值类的和类别类的特征,如果你是数值类的话当然是说你这个结点里面,这个数值是大于哪一个还是小于哪一个。如果是类别特征的话那你这个决策,结点的时候就看你这个结点是不是等于你是哪个值还是不是哪个值
坏处:
- 它是对整个数据进行不断的,每个特征不断的分裂分裂出来,它非常的不稳定,就是说你数据里面产生了一定的噪音之后啊,它可能整棵树构建出来的样子就不一样了
- 如果你的数据特别复杂的话,我可以生成一个特别复杂的数,容易过拟合
- 不容易并行计算
随机森林

我们之前有讲过是说一棵树不稳定,常见的方法是随机森林可以让它稳定下来,就是说我训练多个决策树来提升我的稳定性,分类用投票,回归用平均。缺点是他代价就是说假设你有十棵树的话,那么你训练的成本是十倍。
如果你不是随机的话那你那你对稳定性的提升可能是有限的,第一个是我训练一棵树的时候用了一个训练集,bagging就是我在这个训练集里面随机采样一些样本出来,而且是替换的采样,假设你的样本本来是12345,做bagging的时候,我一样的在里面随机采样五个出来,但是这面采样可能是有重复的比如我拿的是12234,2重复了两次,拿到这一个baging出来的数据集之后,我们就在上面训练一棵树,然后一直重复训练n棵树为止。第二个随机性是我把Bagging出的数据拿出来之后呢,再随机采样一些特征列出来不要用整个特征
梯度增强决策树

我也是要训练多棵树,但是呢这棵树不再是独立的完成而是顺序的完成,这些树一起能合成一个比较 大的一个模型出来。假如说我要训练啊n棵树的话,Ft(x)是过去所有训练数的求和,接下来在新的时间,训练一棵树ft,但是呢它不在原始的数据上而是在一个残差数据上,所的残差数据是说x就是你的特征还是不变,但是你的标号(label)是要变了
总结

树模型就是机器学习里面为数不多的,一个可解释的模型,也可以做分类也可以做回归,然后在树模型的一大问题说它不是那么的稳定它对数据的噪音非常敏感,所以我们可以通过用很多树放在一起来降低我的偏移和方差。
随机森林就是我们在随机的并行的训练多棵树,然后这些树合并起来做投票或者做平均来预测。
Gradient Boosting就是我们顺序的训练出一些树,每一棵新的树啊是之前那些树预测的不准的那一块部分去继续去拟和它。
不用经常调参,也就是不容易出错
3.3 最简单也同样最常用的线性模型
回归与分类的区别:浅谈机器学习-回归与分类的区别 - 腾讯云开发者社区-腾讯云 (tencent.com)
线性模型作回归
线性回归是变量之间符合线性关系,建立线性模型,预测结果

计算向量内积和偏移量
import numpy as np
weight = [1,2,3,4]
x = [4,3,2,1]
b = 10
result = np.dot(weight,x)
print(result+b) # 30
目标函数(把最大化或者最小化的函数称为目标函数,把需要最小化的函数称为代价函数或者损失函数)

MSE实现
from sklearn.metrics import mean_squared_error
y = ([1,2])
y_hat = ([1,3])
print("均方误差",mean_squared_error(y,y_hat))
# 均方误差 0.5
线性模型作分类

假设我要做多类物体的话,我可以做一个向量的数据,就我不是在输出一个元素,而是在输出啊m个元素,这m是你的类别的个数,我的输出是一个长为m的一条向量,向量里面第i个元素反应的是说,我这个模型觉得你这个样本是属于第i类的,这一个概率或者是它的置信度是多少,值越高就表示我越觉得你的样本是属于这一类,如果越低的话当然就表示越差。
Oi是每个类的置信度,label y是one-hot encoding
线性回归做分类的问题:因为我要使得我所有的o和我的y是一样的,但是我们其实不那么关心你这个不是属于这类的时候我的o是输出,我关心的是我的真实类别的,它的置信度要大,但是在我们之前的MSE那个误差里面呢,就保证说我就算这个类别不是属于I我也要使了我的置信度要是等于零的。这个东西会带来的问题是我的学习的东西太多了,我关注了啊很多其实你不那么关心的事情,假设你的类别说1000或者1万的话啊,每一个样本我要去拟合一个长为1千1万的一个输出,导致我的很多精力啊这个模型去关注了一些啊不正确的类上面,所以有一个办法是我们可以让我们的模型更加专注到把正确类的那个执行都弄对别的我们就不能关心
softmax regression
主要用来解决m类分类问题

首先啊我们把我们的预测的分数啊换成个概率,线性回归的Oi输出范围随意,它在+∞到]-∞之间都可以发生,我们如果想把它变成一个概率,所谓的概率就是每一个元素它应该是大于等于零的而且对每一类它的那个值啊加起来要等于1,O是一个m长的元素表示类i的这个置信度,对每个Oi经过下面的操作后
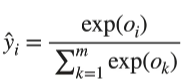
得到\({\hat y_{i}}\),所有的\({\hat y_{i}}\)加起来就是1,这时候模型的概率就是\({\hat y_{i}}\)
softmax代码实现
import numpy as np
def softmax(a):
c = np.max(a) # 溢出策略
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
return exp_a / sum_exp_a
a = np.array([0.3,2.9,4.0])
print(softmax(a)) # [0.01821127 0.24519181 0.73659691]
print(softmax(a).sum()) # 1.0
然后yi因为是one-hot encoding,只有一个,其它基本为0,这样可以只用算这个类,其它类我不关心
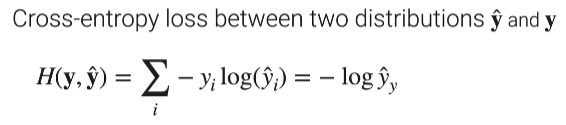
交叉熵代码实现
def cross_entroy_error(y,y_hat):
return -np.sum(y*np.log(y_hat))
a = np.array([0.3,2.9,4.0])
y = [0,0,1]
cross_entroy_error(y,softmax(a)) # 0.305714464812452
3.4 随机梯度下降(SGD)

小批量随机梯度下降这个是,整个深度学习里面,目前来说几乎是唯一的求解方法
It就是采样n个样本,It的大小是等于b的,b是批量的大小,然后去算目标函数(可以理解为李宏毅里面1机器学习的第一步:定义一个带未知参数的函数)对w的导数
好处:基本解决除了决策树之外的问题
坏处:对超参b和ηt比较敏感
SGD代码
def data_iter(batch_size,feature,labels):
num_examples = len(features) # 特征的长度
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0,num_examples,batch_size):
batch_indices = torch.tensor(
indices[i:min(i+batch_size,num_example)] # 防止batch_size比num_example大
)
yield features[batch_indices],labels[batch_indices] # 创建一个生成器
# 因为要对w和b进行求导,所以这里的requires_grad为true
w = torch.normal(0,0.01,size=(p,1),requires_grad=True)
b = torch.zeros(1,requires_grad=True)
for epoch in range(num_epochs):
for X,y in data_iter(batch_size,features,labels):
y_hat = X @ w + b # @是作矩阵的乘法
loss = ((y_hat - y)**2 /2).mean() # 均方误差
loss.backward() #求导
for paramin in [w,b]:
param -=learning_rate * param.grad
param.grad.zero_() # 把导数清零,使得下一次迭代还能够继续算导数
yield教程:你在 Python 中常看到的 yield 到底是什么鬼?_哔哩哔哩_bilibili
总结

3.5 多层感知机(mlp)
线性通常要对我们的原始数据做一些特征工程,把原始数据表示成我们的线性模型喜欢的那些特征之后这每一个向量必须是一个数,而且它们之间语义信息是比较清楚的,我们的线性模型给它做一个线性的分割面,现在的深度学习可认为它就是把我们的手工特征提取的部分换成了一个神经网络,之前是用人的知识对原始数据进行特征提取,现在是说我用神经网络来对原始数据进行提取,可能会更好一些
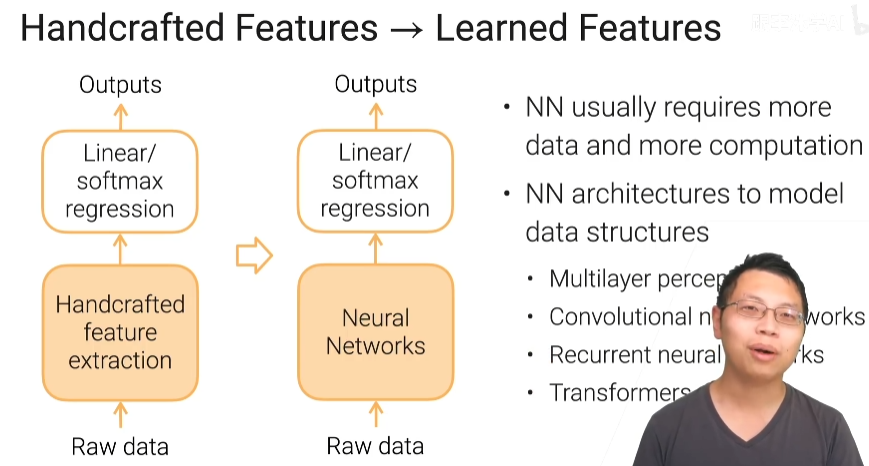
如何从线性方法到我们的多层感知机

w是一个m×n维的矩阵,b是m维的向量,这时我的线性回归你可以认为它就是一个全连接层但是你只有一个输出就是m等于1。
如果是softmax回归,它其实就是一个dense layer但是有m个输出m是你的类别的个数再加上一个叫做softmax的操作子得到我们的一个概率的输出
所以线性模型你都可以统一表示成输入到一个dense层然后直接变成了输出,这是一个简单的单层感知机
多层感知机的输入是二维的(因为w是m×n),而卷积层是四维的输入(n×c×w×h)

上面是单层感知机的例子,要变成多层感知机,我们想得到一个非线性的模型因为线性模型毕竟是能力有限啊,想要做到非线性的话我们使用多个这样子的全连接层,但是简简单单的拿到多个全连接层是没有用的,因为简单放在一起你n个线性操作的叠加还是一个线性操作,所以你需要加入非线性在里面。非线性就是叫做激活函数,激活函数是一个按元素的一个非线性的函数
多层感知机的超参
- 隐藏层的个数(李宏毅中的一排是一个hidden layer)
- 每个隐藏层的输出的大小
实现1层隐藏层的MLP代码
import torch
from torch import nn
def relu(X):
return torch.max(X,0)
num_inputs = 2
num_hiddens = 1
num_outputs = 3
W1 = nn.Parameter(torch.randn(num_inputs,num_hiddens) * 0.01)
print(type(W1))
b1 = nn.Parameter(torch.zeros(num_hiddens))
print(type(b1))
W2 = nn.Parameter(torch.randn(num_hiddens,num_outputs) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs))
H = relu(X @ W1+b1)
Y = H @ W2+b2
torch.randn:返回一个标准正太分布,(20条消息) torch.randn用法_江南汪的博客-CSDN博客_torch.randn()
torch.nn.Parameter:PyTorch37.torch.nn.Parameter() - 知乎 (zhihu.com)
3.6 卷积神经网络
如何从全连接层过渡到卷积层

卷积层

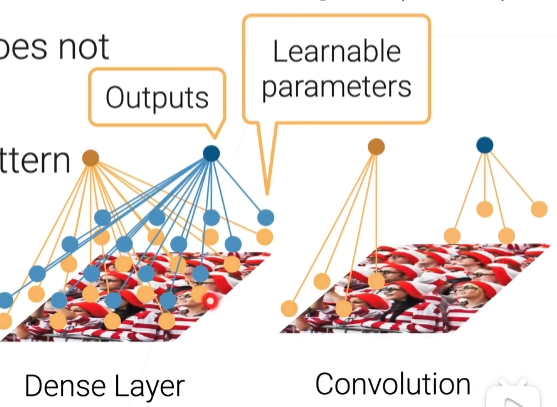
第一个是一个全连接层,假设我们要算两个输出,但是每一个输出对每一个输入,在全连接里面都要有个权重,全连接的每个输出是要跟每一个像素跟它的权重做乘法然后加起来得到输出
然后在卷积里面呢,就是说假设我说这个输出它对应是图片的左下角的东西的话,而且我选择一个k等于2(2×2的窗口),那么算它的时候啊,我只看左下角这个2*2的像素块里面它的输入跟我的权重做加权和得到我的输出,意思是说我其它就不看了,这样的话对这个输出它的参数已经从一个n×n变成2×2的东西,这时就小很多,那我不管你的图片有多大,我只要定好我的2乘2的话,那我的权重就是2*2了。
平移不变性或者变换不变性的意思是如果我有一个权重,能够在这边识别一个东西,我把这个东西移动到别的地方一样的能识别,那么就是说我在算它(右上角)的输出的时候,我不需要给它重新学习一套新的权重,我就跟它用样的权重就行了,这样的话就是权重之间是可以共享的(和李宏毅的共享参数差不多),有了这个思路以后,我们卷积层的可学习参数的个数啊不再跟你输入的大小和输出的大小相关,它只跟你的k,就是你那个窗相关了
单通道的卷积代码
h,w = K.shape # kernel
Y = torch.zeros((X.shape[0] - h + 1,X.shape[1] - w + 1)) # X input
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i,j] = (X[i:i+h,j:j+w] * K).sum()
print(k.shape[0]) # 为矩阵的行数
print(k.shape[1]) # 同理shape[1]输出列数
池化层

池化层实现代码
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i,j] = X[i:i+h,j:j+w].max()
elif mode == 'avg':
Y[i,j] = X[i:i+h,j:j+w].mean()
CNN

因为卷积层你可以为它是一个特别的一个全连接层,如果你不加激活函数的话,它还是一个线性模型,不管你堆多少层,另外一个是说卷积层对位置很敏感,我们用一个池化层来得到些对位置没那么敏感的输出,所以通常池化层放在卷积层后面

3.7 循环神经网络
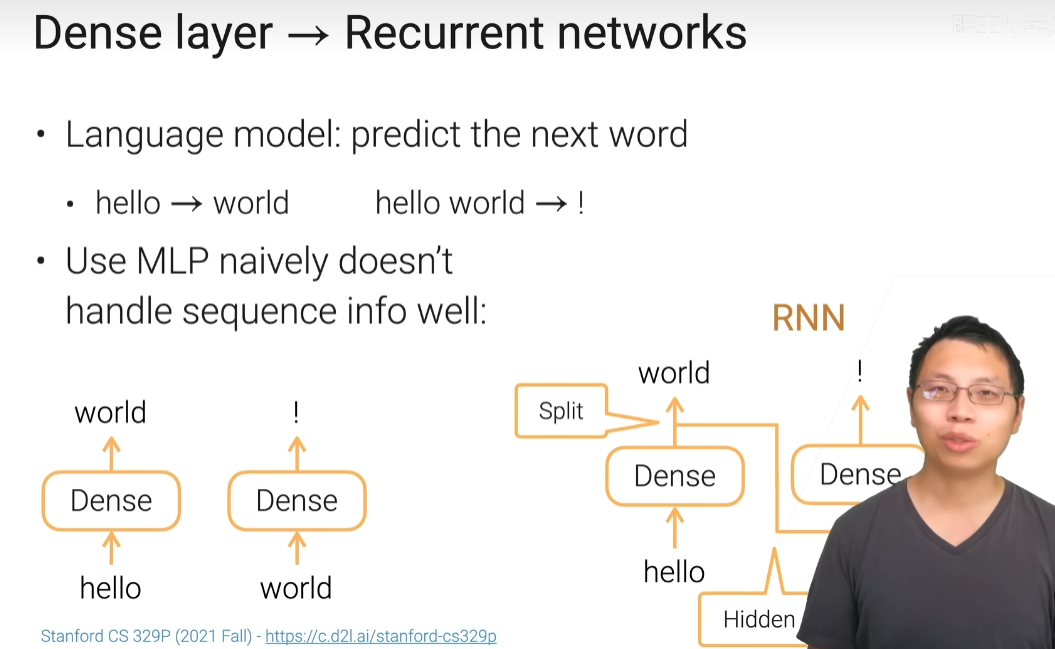
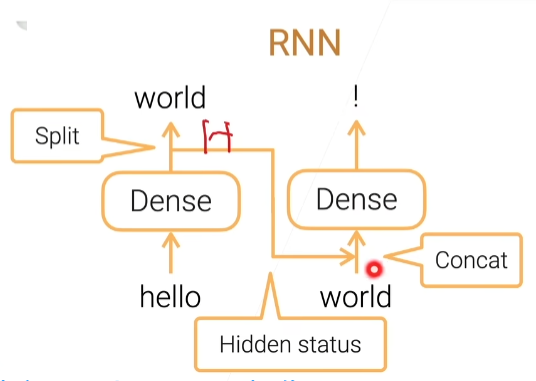
隐藏状态,包括了过去时间所有的信息,再和当前信息合并,就可以看到一个信息的输出
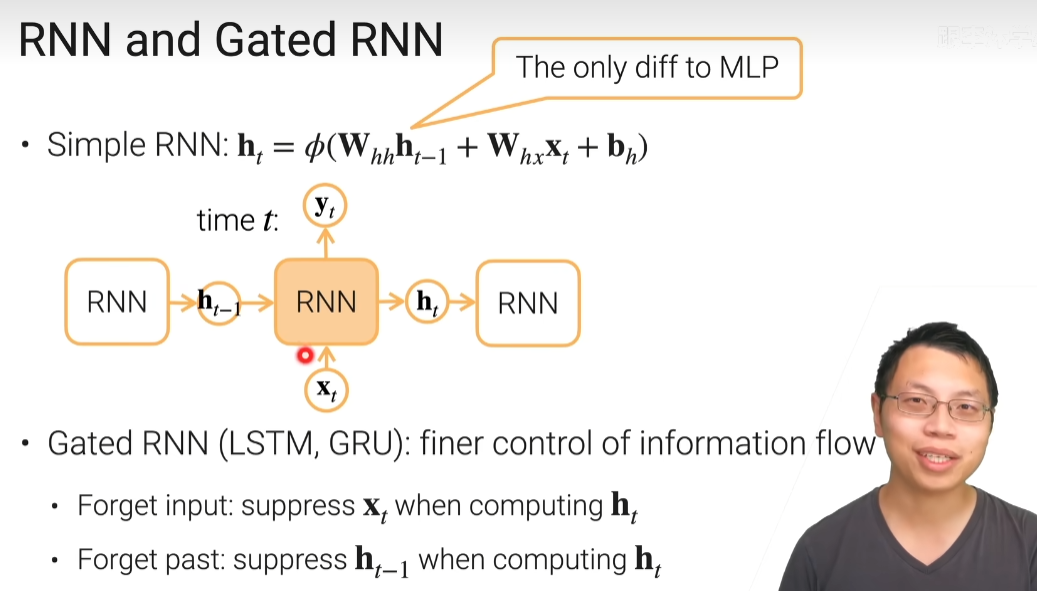
简单RNN中的Φ()是个激活函数
W_xh = nn.Parameter(torch.randn(num_inputs,num_hiddens) * 0.01) # num_inputs是输出向量的维度,
W_hh = nn.Parameter(torch.randn(num_hiddens,num_hiddens) * 0.01) # num_hiddens是隐藏层的个数
b_h = nn.Parameter(torch.zeros(num_hiddens))
H = torch.zeros(num_hiddens) # 0时刻的时候,我认为是没有信息的,所以全部为0
outputs = []
for X in inputs: # X 是对每个时刻进行迭代,H是上一个时刻
H = torch.tanh(H @ W_hh + X @ W_xh + b_h)
outputs.append(H)
双向RNN
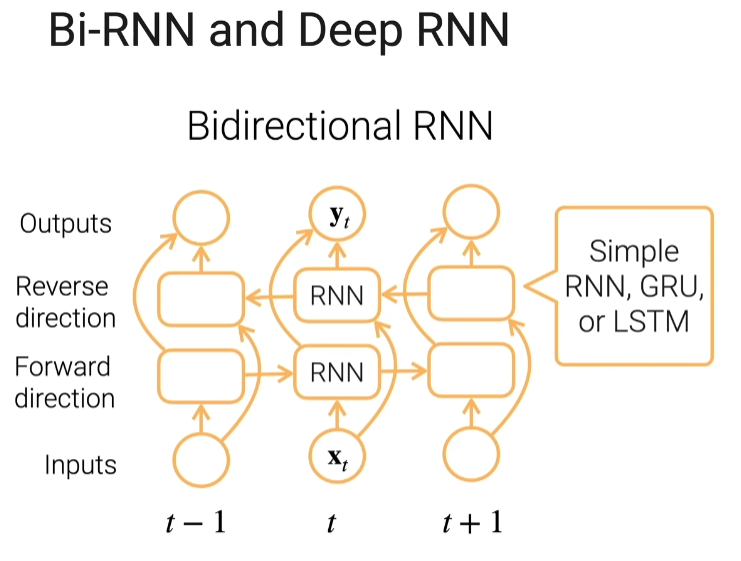
机器可以从左往右看句子,也可以从右往左看句子,双向就是其实它有两层,一层是往这个方向走,一层是往反方向走,正向层和反向层在当前时刻的输出合并起来做成我的yt,yt看过两个方向的信息
DeepRNN
把RNN累加起来
总结
模型的选择
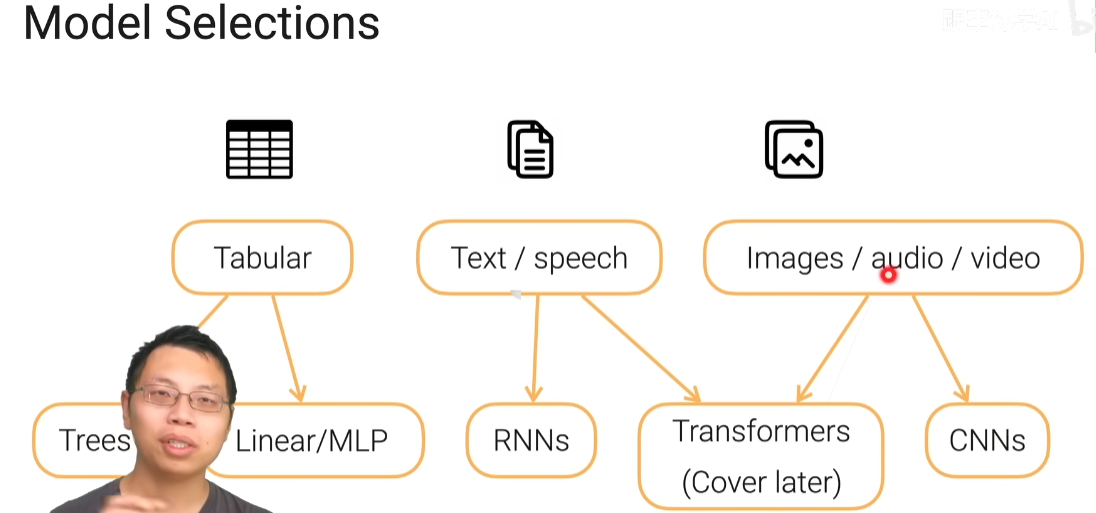

MLP:多个全连接层给你堆起来,然后中间通过激活层得到一些非线性
CNN:比较特殊的全连接层,它里面的卷积层呢是使用的一些空间上的本地性和平易不变性的特性做了一个简化版的全连接层然后它参数更好更少,然后更适合处理这个空间信息
RNN:他就是把全连接层在时序上把过去的信息放到现在加进来一个全连接层,加了一条额外的边,所以得到一个循环神经网络,它是非常适合做有持续信息的数据,通过隐藏状态处理这些持续信息
全连接层
可以累加weight和x然后再加上b

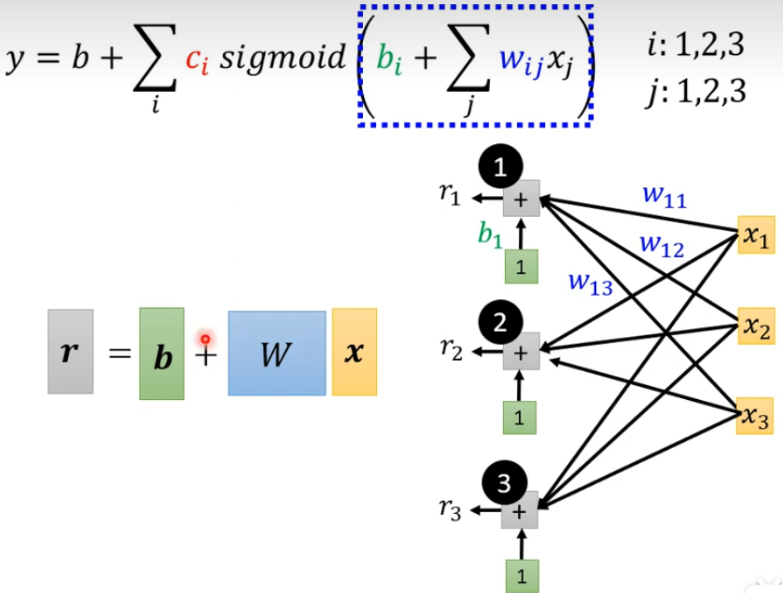
4.1 模型评估

模型评估的指标不仅仅只是一个简单的loss来衡量,一个模型的质量啊通常是会被有多个指标来衡量,比如说你做分类的时候,我们可以会去评估你这个模型的精度,如果你做目标检测的时候呢会去评估你的mAP,还有比如通用的AUC、ROC、召回率、精确率等
实例:展现广告
当你搜鲜花的时候,我会给你推送一些鲜花的广告,搜游戏,推送游戏广告,然后去预测用户去点击这个广告的概率
AUC ROC
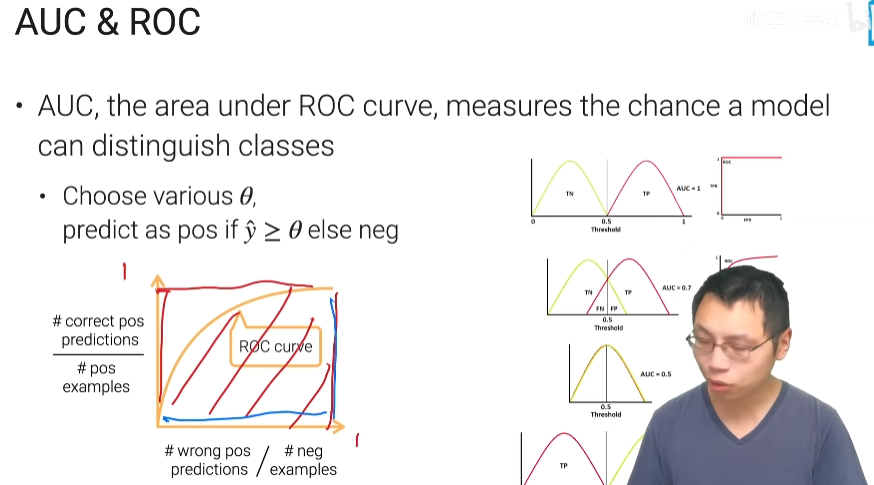
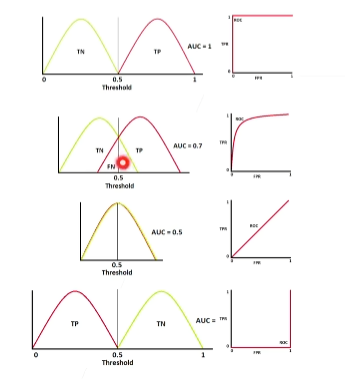
第一个是完美的预测工程
第二个是有错误的预测
第三个是无法区分正类和父类
第四个是把正负类弄反了
1的AUC表示特别好,0.5的AUC特别差,广告是个二分类问题
模型最关心的是AUC
总结

对一个模型来说我们通常会去考虑多个指标,比如损失和精度
4.2 过拟合和欠拟合
训练和泛化误差

泛化误差指的是对新的数据的误差

训练误差低,泛化误差高是过拟合
训练误差高,泛化误差低是欠拟合
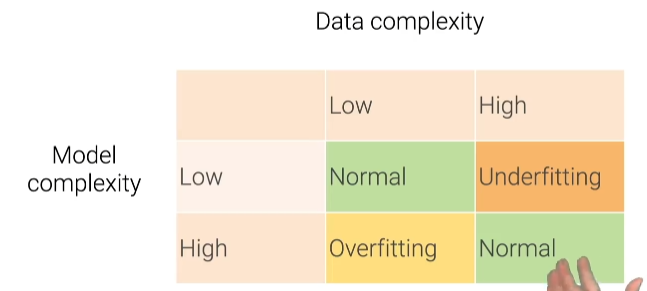
数据与模型复杂度
数据和模型的复杂度要对等,如果数据比较复杂,模型不复杂,模型就无法去拟合这些数据容易欠拟合,如果数据不复杂,模型复杂,容易过拟合
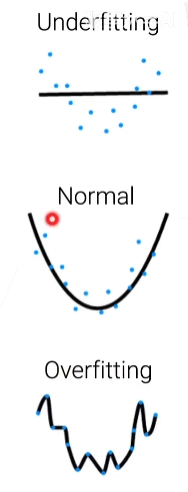
模型的复杂度

有值限制的模型会比较简单些
模型复杂度的影响
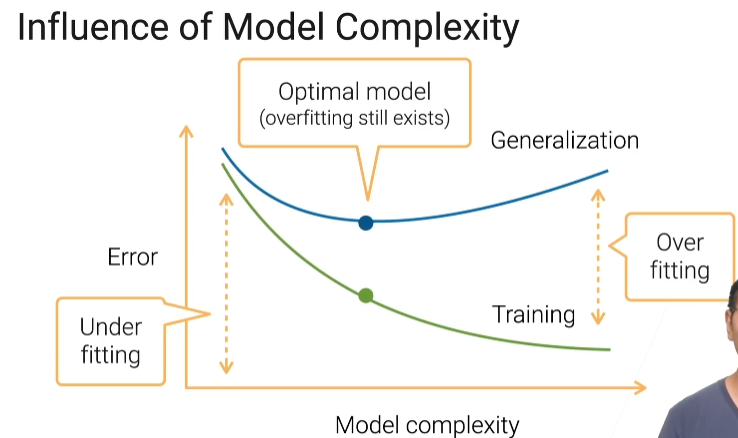
最好的情况是你泛化误差比较低的时候
数据复杂度

数据的复杂度包括
- 样本数越多你相对来说你数据就越复杂点
- 你每个样本里面啊有多少个元素就说你的维度多高,一张1000x1000的图片就比一 张20x20的图片复杂
- 你在数据里面有没有一些特殊的一些时间啊空间的一些结构,例如股票数据是有时序的结构的,图片数据是有空间结构的,有特殊结构的数据很有可能你的数据复杂度会高那么一些
- 多样性,比如要做图片分类的话,你那里面到底是有10种动物还是有100种动物1000种动物
数据的复杂度和模型的复杂度是一个要相互匹配的过程
模型的选择

总结

我们关心的是泛化误差而不是训练误差
4.3 模型验证

通常我们会用测试误差来近似泛化误差,在这个地方测试数据集只能用一次,使用一次你就可以看到的你的模型表现是什么样子的,因为只能使用一次比较费数据,实际应用中,我们会用一个验证数据集(Validation Datasets)的东西,可以被使用多次,多次评估我的误差,通常来说它是训练数据集中的一块,我们把训练数据集中拿出一块作为验证数据集来做模型的选择。
经常我们说我们是用测试数据集叫test data,或者叫做test accuracy,这个测试数据集在大部分情况下我们其实指的是验证,因为我们可能这个测试数据会用多次,所以在现实生活中,不管是你在论文中,我们用到的test data或者test accuray其实很多时候它就是一个验证数据集,它不是真正意义上严格意义上的测试数据集,但是大家一直都是这么用的,这个东西他不是真正的测试的精度而是你的验证的精度。
常见的生成验证数据集的方法
hold out validation

- 假设我有8个样本,我把它随机分为两个集合,一个叫做训练集一个叫做验证集,然后在训练集这个数据上训练一个模型,然后在验证集上去算一下我们的误差,或者是任何我们的指标都行。然后用验证的误差或者验证上的指标来近似我们的泛化误差
非独立同分布的数据分割

-
把数据随机分开,但是很多时候随机分开不一定是行的,如果数据是符合独立同分布的时候可以随机划分。但是很多数据他不是一个随机的,不符合这个I. I.D(独立同分布)的这个假设,比如说我的数据里面可能有些时序的信息,例如卖房我是每一天卖一些房,就是房子之间是有个时序的信息,股票也是类似。如果你在选取你的验证数据集的时候是随机的话,我们可能每一天都会随机(选) 一些房子出来做我的验证集,每一天就随机一些房子作为我的训练集,它的问题在于你真正的部署的时候,假设现在有一个模型去预测明天的房价,但是你在训练的和验证的时候,其实模型已经看过同一天的房价了,这个时候你可能会有一定的误差。
-
还有是假设一个人有多张图片,随机分成训练集和验证集,这时候如果训练集和验证集有同一张人的图片,会导致模型去看别的人的图片时候,会有误差
-
数据不是平衡的,就有些类特别多有些类特别少,如果随机采样的话,你的类多的那些样本采样的比较多,类小的比较少,然后导致说你的精度可能会偏高
上述这些情况不能采取随机分割,第一种情况要保证你的验证集的样本,一定是在训练集样本之后的。然后是说你有group信息的话,可以在随意的组之间进行分割,就随机先把人分开,就是说一共有100个人的照片的话,我把随机挑70个人作为训练,随机挑30个人做验证。如果你是不平衡数据的话呢,你可以说我应该对于小的类就是说挑(训) 验证集的时候对它的采样的概率要高那么一些
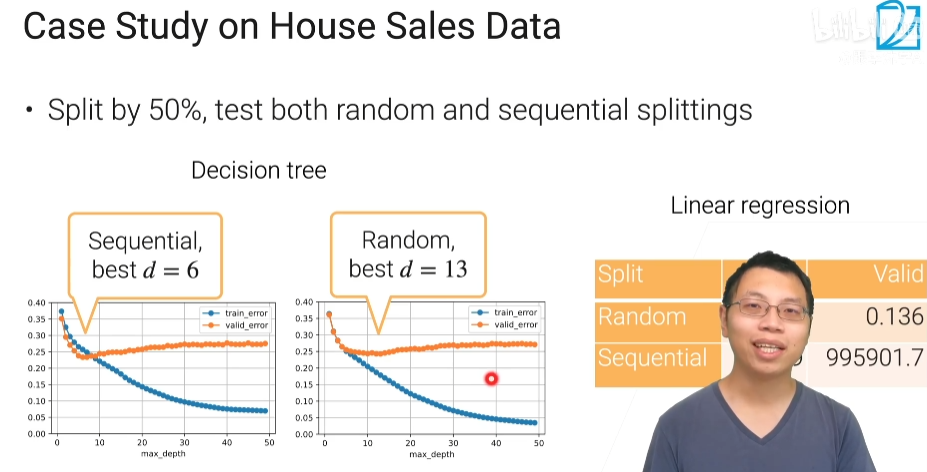
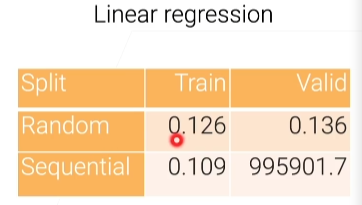
按顺序划分的决策树最优是6层,而随机分的话,最优是13层,也就是晚一点过拟合
顺序划分:就是前面一半时间作为训练,后一半做验证集,如果取得比较复杂的树,过拟合会出现的早一点,比如过去三个月的数据预测未来三个月的时候,你不能把过去三个月的数据拟合的太好,用过度复杂的模型拟合太好,是因为未来三个月可能会发生比较大的一些变化,过于拟合当前数据的模型,可能在未来表现比较差点,线性回归:在训练时很好,但在验证时就不太行了;
随机划分:训练误差还是往下降,但是验证误差,它可以允许我最好的取到了13层的树,也就是在随机取的时候过拟合发生的晚一些,最好的时候,我可以选择一个比较大的一颗树深度为 13 的时候测试误差往上走了(相当于我可以看清楚全局发生的事情,并进行预测,不会过拟合于一些局部的信息),线性回归:训练和验证误差都很正常;
k-折交叉验证
适用数据不多

划分为k个部分,每个部分取一块做验证集,最后把平均的k个验证误差,当做模型的验证误差,代价是你得重复更多的次数,如果数据量不大而且模型训练不那么贵的时候,我们用交叉验证也是最常用的一个方法
常见错误

机器学习训练特别好,90%是bug,在这个bug里面最大的一个原因是说你的验证集被污染了,可能跟你的训练集是有一定的重叠。
总结

5.1 方差和偏差
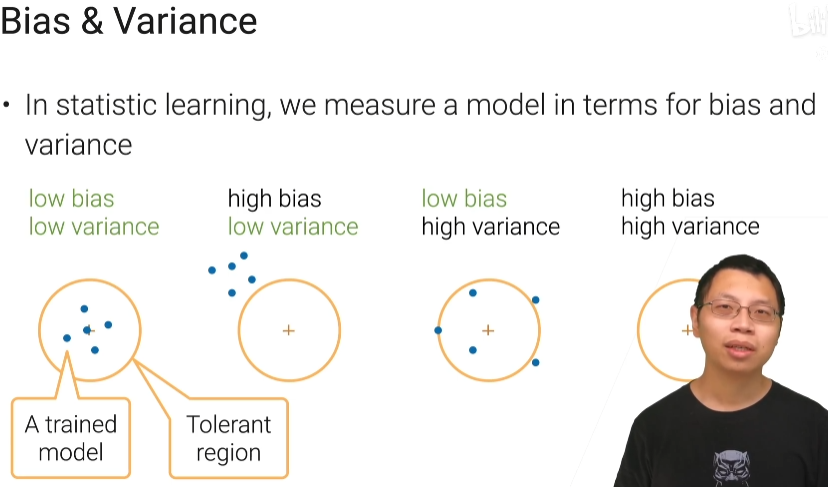
偏差:所谓的偏差说你学习到的模型跟你真实的点之间跟你真实模型之间区别位移(和容忍区域中间点的距离)
方差:方差说每次学习的东西它的差别多大(蓝点之间的距离)

y=f(x)+ε,这种ε是个噪音,E表示求期望

正太分布,均值为0,方差为1,标准差是方差的平方根,Var(x)代表方差,E(x)代表期望,大数定律规定,随着重复次数接近无穷大,数值的算术平均值几乎肯定地收敛于期望值。
公式详细解释见:深入了解均方误差 — 贝叶西伯爵 (countbayesie.com)

图片中的公式链接:(20条消息) 数学期望 Expectation_爱学习的段哥哥的博客-CSDN博客_期望的数学符号
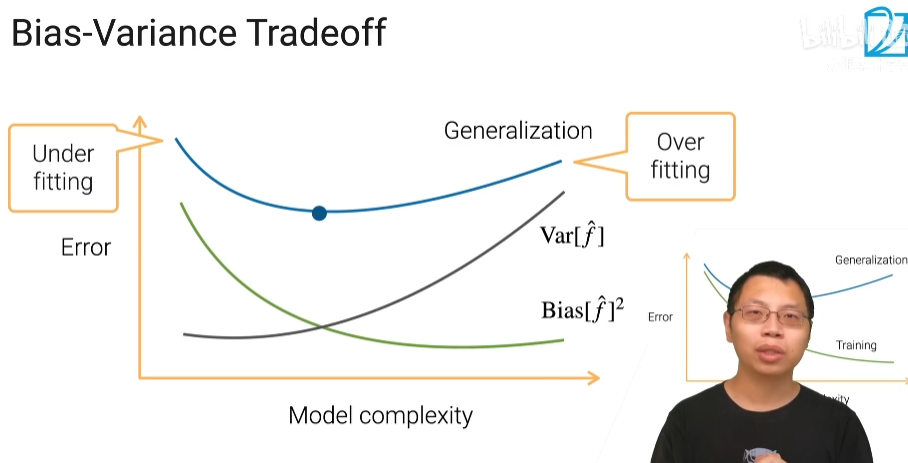
过拟合就是模型在训练数据上的损失不断减小,在测试数据上的损失先减小再增大,这才是过拟合现象
减少偏差和方差
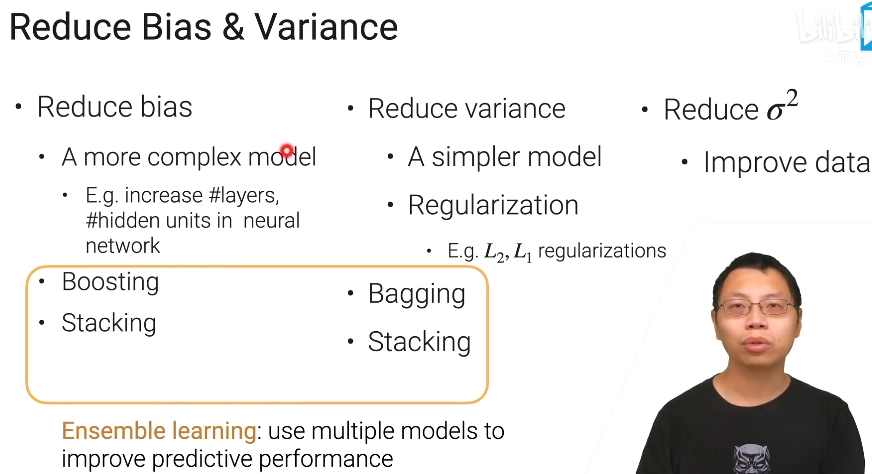
总结

就我们在统计学习里面可以把模型的泛化误差分解成你方差的偏差的平方,再加上方差再加上你数据来自数据和采集模型的误差
集成学习呢它能够将多个模型把它组合起来来降低我的方差偏差
5.2 Bagging

with replacement的意思,就是我拿了m个样本,每次拿一个记下来,然后放回去,虽然我拿了m个样本,但是里面有些样本是重复的
实现代码
import numpy as np
from sklearn import clone
class Bagging:
# base_learner 指定base learner是谁
# n_learners learner的个数
def __init__(self,base_learner,n_learners):
self.learners = [clone(base_learner) for _ in range(n_learners)] # 模型复制n次,模型之间参数是不共享的,模型之间是独立的
# 定义一个训练函数
def fit(self,X,y):
for learner in self.learners:
examples = np.random.choice(
np.range(len(X)),int(len(X)),replace=True # replace 随机采样
)
learner.fit(X.iloc[examples,:],y.iloc[examples]) # learner.fit来自机器学习的函数
def predict(self,X):
# 每一个base_learner学到的都存在这里
preds = [learner.predict(X) for learner in self.learners] # 对每一个学到的learner,拿出来对X做预测, learner.predict来自机器学习
return np.array(preds).mean(axios=0) # axios=0 表示在第一个维度做均值
-
[1 for _ in range(10)]:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],range多少,前面执行多少次
-
np.arange(len(X)):返回一个X的长度的数组,如果X的长度为5,返回值是[0 1 2 3 4]
-
int(len(X)):返回数组的长度,对上一步的np.arange(len(X))所执行的操作
-
replace:样本拿出来后又放回去,意思是数组里面的值可以重复
-
iloc:通过行(列)号来取数据pandas中的iloc、loc、ix有什么区别? - 知乎 (zhihu.com)
-
learner.fit()
随机森林
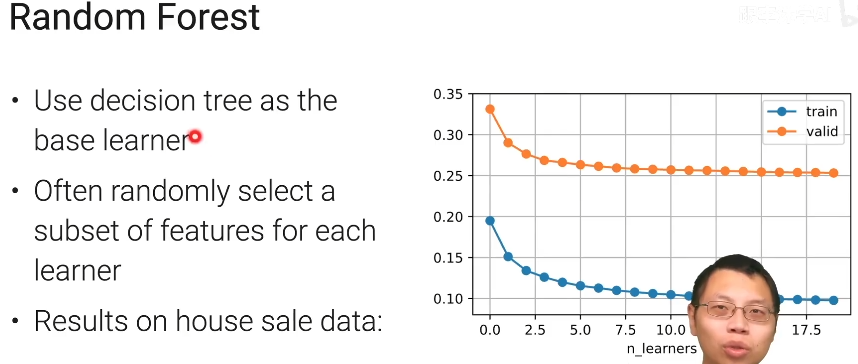
这里没有过拟合,因为验证误差没有上升。这里只是bias比较大而已
随机森林使用决策树来做base learner;
使用随机森林时的常用技术,在bootstrap样本时还会每次随机采样一些特征出来,但在这个地方就不会去采样重复的类出来,因为重复的类没有太大的意义;这样做主要的好处是随机采样之后可以避免一定的过拟合,而且能够增加每一棵决策树之间的差异性;
在右边的曲线图中,我们可以知道,随着learner的数量增加,模型的误差是逐渐减小的。但是泛化误差的曲线不会往上升,这是因为我们降低了方差但没使得偏差更大,这也就改善了泛化误差中三项其中的一项,但没增加另外两项
Unstable Learners
方差比较大的模型叫unstable 模型

base_learner在取一个均值后得到f hat预测值
bagging主要下降的是方差,在统计上采样1次和采样n次取平均,它的均值是不会发生变化的就bias是不会发生变化的,唯一下降的是方差,采样的越多,方差相对来说变得越小。
方差什么时候下降的比较快,方差比较大的时候下降的相关比较好。
那什么时候方差大呢,方差比较大的模型我们叫做unstable的模型;以回归来举例子,真实的是f ,base learner是h,bagging之后 对每个学到的base learner的预测值取个均值 就会得到预测值f_hat;因为期望的平方会小于方差,所以h(x)与f(x)差别很大的时候,bagging的效果比较好
也就是说,在base learner没那么稳定的时候,它对于下降方差的效果会好
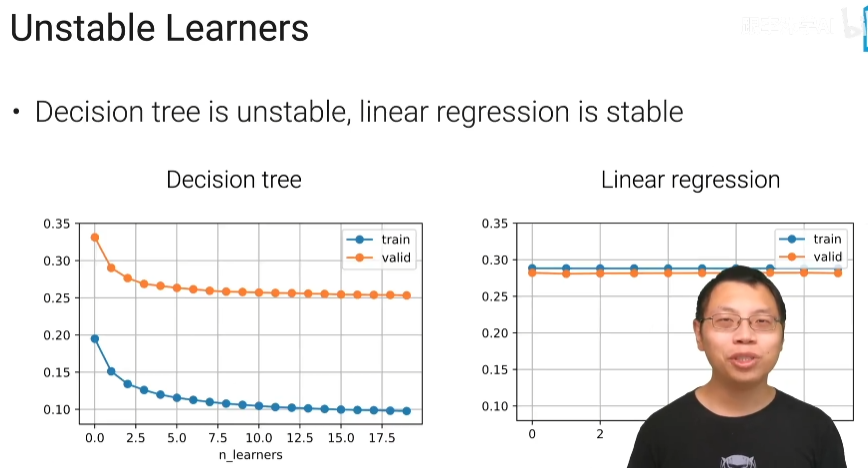
决策树它不是一个很稳定的一个模型,是因为你数据一旦发生变化,那么我每一次选取哪个特征,然后选取特征里面那个值啊做切开的分支它就会显得不一样,因为决策树不稳定时候做bagging,
为什么决策数适合做bagging参考链接:为什么使用决策树作为基学习器?-云社区-华为云 (huaweicloud.com)
线性回归比较稳定,一个线性回归和10个线性回归做bagging没太多变化
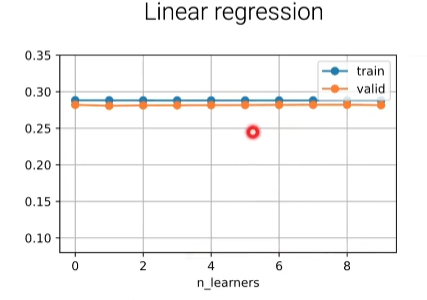
总结

bagging就是训练多个模型,每一个模型就是通过在我的训练数据上,通过bootstrap采样训练而来,所谓bootstrap就是每一次用m个样本的话,每采样一个的时候把一个放回去,主要的效果是能够降低我的方差
决策树因为不稳定,所以用来做bagging效果最佳
5.3 Boosting

他的想法是说我们将多个弱一点的模型把它组合在一起变成一个比较强的模型,他的主要的目的是去降低你的偏差,而不是我们之前Bagging的那个方差。方差就是说我有n个不那么稳定的模型我把它放在一起,这样子呢使得我得到一个相对来说稳定的模型这样子我的方差比较低。但是呢Boosting是说我把我n个比较弱的模型,就是偏差比较大的模型把它组合成个比较强的模型,这样子呢得到一个偏差比较小的模型。boosting和bagging有点不一样,在学习上来说啊Boosting也会有不一样,Boosting是说我要按顺序的学习n个模型,之前Bagging是说每个模型之间是独立的。
我在第时间i步的时候我会训练我一个弱模型hi,然后我们会去根据你hi的一个误差去评估一下,然后呢会根据我们当前的误差我们再把数据重新变换一下就可能是重新采样下,使得我们接下来的下一个模型hi+1会去关注我们预测不正确的那些样本。等于是说我们先训练一个简单模型看一下效果,把那些训练样本啊做的不好的那些祥本重新拿出来,那些训练好的样本我们就不那么看了,接下来再训练一个模型再把它做好一点,然后一直迭代下去。
gradient Boosting

假设我在时间t的时候呢我当前训练好的模型是Ht(x),当然我一开始就可以为是0,预则就是0,时间t处,我们训练一个模型,跟之前不一样的是说我们是在残差上训练的,残差是说假设我还需要m个样本,我的样本本身不发生变化我的特征不变化但是我标号(label)变了,我标号是等于是yi减去我当前Boosting出来的模型它的预测值,但一开始t等于1的时候他还等于0,所以在时间1的时候我是在原始的样本上进行训练,但是在之后的时间里面我都是说把我当前时刻Boosting出来的模型拟合不够的那个差值(假设这里做回归,就是真实的yi减去我的预测的时间,yi-Ht(xi)),就是说我去做一个回归拟合一个数值,当前t的时候我是去训练一个小模型拟合我没有拟合的那一部分,如果已经拟合好了这个东西(yi-Ht(xi))已经变成零那我就无所谓了就不用再训练了,所以就是说每一个ht去把之前没有拟合好的残差重新去拟合一下。
然后我们把小ft乘上一个学习率η加进当前整个boosting出来的模型,做成下一个时候的Boosting模型。学习率就是它会做为一个正则项,这个东西在Boosting里面叫shrinkage就是收缩,如果η为1,容易造成过拟合,就说把η搞成一个0.1或者零点几的样子使得呢就不要去真的把这个东西全部给一次性的拟合掉了。
看上去很像我们的梯度下降对吧,学习率都有了。假设用一个MSE作为我的损失函数或者目标函数的话,对我的函数做梯度的话,那么他的残差就等价于是他的做完梯度他的负方向,也就是
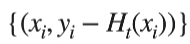
和
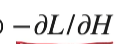
是相等的
我们之前在梯度下降的时候每一次是用负的导数梯度乘以学习率加到我的权重里面,在这个地方我们不是这样的权重因为我们学习的是个函数的东西,我是学习一系列函数出来我们不是学习个模型的权重,所以呢每次我训练个ht去拟合我的负梯度 然后再乘上个学习率,所以叫gradient boosting。
别的一些boosting函数很多时候都可以换到这个Gradient Boosting的框架里面,就是你怎么选这个L,不同的L的选择导致你可采取不一样的Boosting的算法,这个地方我们用的是最简单的做回归的时候的MSE的loss,做分类或别的Boosting他的损失函数不一样。
基本思想

gradient boosting实现代码
李沐版
import numpy as np
from sklearn import clone
class GradientBoosting:
def __init__(self,base_learner,n_learners,learning_rate):
self.learners = [clone(base_learner) for _ in range(n_learners)]
self.lr = learning_rate
def fit(self,X,y):
residual = y.copy()
for learner in self.learners:
learner.fit(X,residual) # residual最开始是label值,后来就是残差
residual -= self.lr * learner.predict(X) # 一个模型训练好后,用当前label和预测的值计算残差,根据这个残差,进行下一次迭代,这里learner.predict(X)是h_t(x)
def predict(self,X):
preds = [learner.predict(X) for learner in self.learners] # 对每一个学到的learner,拿出来对X做预测
return np.array(preds).sum(axios = 0) * self.lr
predict和fit函数:(20条消息) python中predict函数_sklearn中predict()与predict_proba()用法区别_weixin_39982568的博客-CSDN博客,(20条消息) 机器学习笔记二:(fit()函数的参数记录)_夏天的风€&_的博客-CSDN博客_fit函数的参数
learner.fit(X,residual) :这里对应的是{(xi,yi-Ht(xi))},residual对应的是yi-Ht(xi),最开始residual是y,因为t=1时,H1(x)=0,第一个模型训练后,第二个模型就要根据第一个模型的残差进行优化
residual -= self.lr * learner.predict(X) :learner.predict(X)是ht(x)
return np.array(preds).sum(axios = 0) * self.lr:乘学习率是为了加权每个弱学习器的结果
知乎版链接:Gradient Boosting 原理、推导及代码实现 - 知乎 (zhihu.com)
def fit(self, train_X, train_y):
self.estimator_list = list()
self.F = np.zeros_like(train_y, dtype=float)
for i in range(1, self.n_estimators + 1):
# get negative gradients
neg_grads = train_y - self.F
base = DecisionTreeRegressor(max_depth=self.max_depth)
base.fit(train_X, neg_grads)
train_preds = base.predict(train_X)
self.estimator_list.append(base)
if self.is_first:
self.F = train_preds
self.is_first = False
else:
self.F += self.lr * train_preds
Gradient Boosting Decision Trees (GBDT)
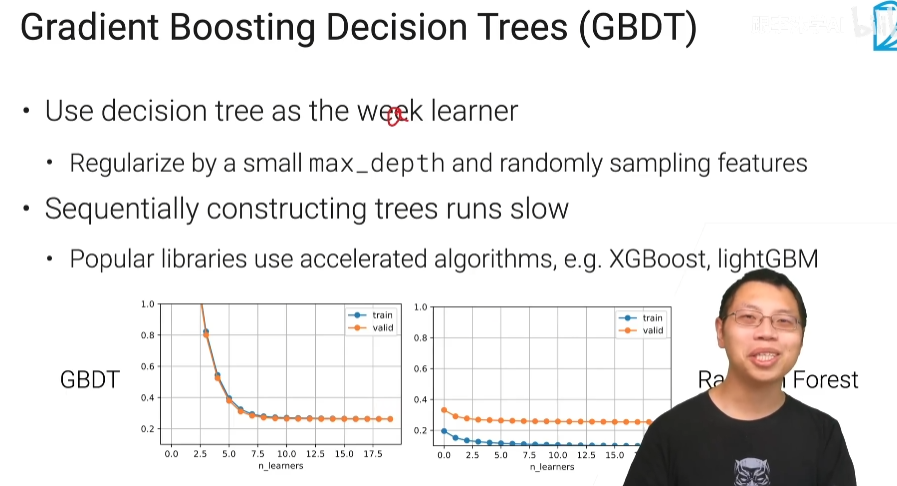
用决策树作为我的weak learner,Gradient Boosing它非常容易过拟合,所以我们需要对它做一些正则化,我们真的需要用一个弱的一个模型不能用一个很强的模型。决策树不能说是个弱模型啊 决策树可以把整个数据给拟合住所以它是一个很强的模型。
如何得到弱模型?
答:当决策树的层数比较低的时候,你模型相对于比较简单,或者像bagging一样随机的采取一些列回来,这样子你只在一些子特征上训练你的模型而不是在整个特征上训练,可以让你的整个模型变得更弱一点,而弱是因为这样子能够上你的过拟合不那么严重
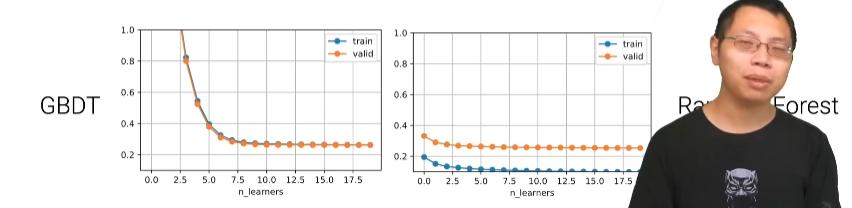
GBDT的图像随着我的learner数往上增加它也没有看到过拟合,就是当你就weak learner的控制比较好的时候和学习率控制比较好的时候他的过拟合(训练误差小于验证误差,而且 train error 很低然后 valid error 往上翘)现象不那么严重。另外一个是说Boosting跟random forest的不一样是说random forest的里面可以啊每个树都可以并行训练,但是在这个地方(GBDT)我一棵棵树得顺序的训练所以导致说在比较大的数据集上比较吃亏啊
XGBoost,lightGBM他们两个都使用了一些加速的算法使得在构建树的时候相对是比较快一点
总结

Boosting是说我把n个比较弱的一个模型组合在一起变成个强的模型用来降低我的偏差。
gradient boosting是每一次的时候我的弱的那个模型是去拟合我们在标号上的残差,每次拟合的是一 个给定损失函数他的负梯度的方向所以他叫gradient。
AdaBoost你可以认为是在取一个不同的损失函数的时候他的一种gradient boosting的变种。
虽然GBDT同样由许多决策树组成,但它与随机森林有许多不同,其中之一是GBDT中的树都是回归树,树有分类有回归,分类是结果是好还是坏,回归是给一个数值。GBDT的每一个树都是建立在前一颗树的基础上。以给苹果打分为例,我会先训练一棵树,给苹果打分,再去训练一棵树去预测它们与真实分数间的差距,如果两者相加仍与真实分数存在差距,我们再训练第三棵树预测这部分差距,重复这个过程不断减少误差,将这些树的预测值加起来就是苹果的分数,GBDT属于集成学习。
像这类一个模型依赖于上一个模型,共同逼近正确答案的方法被称为Boosting提升
模型间相互独立共同投票出结果的方法则被称为Bagiging装袋
在多个模型的基础上放置一个更高层的模型,将底层模型的输出作为它的输入,由更高层给出最终的预测结果称为stacking
5.4 Stacking
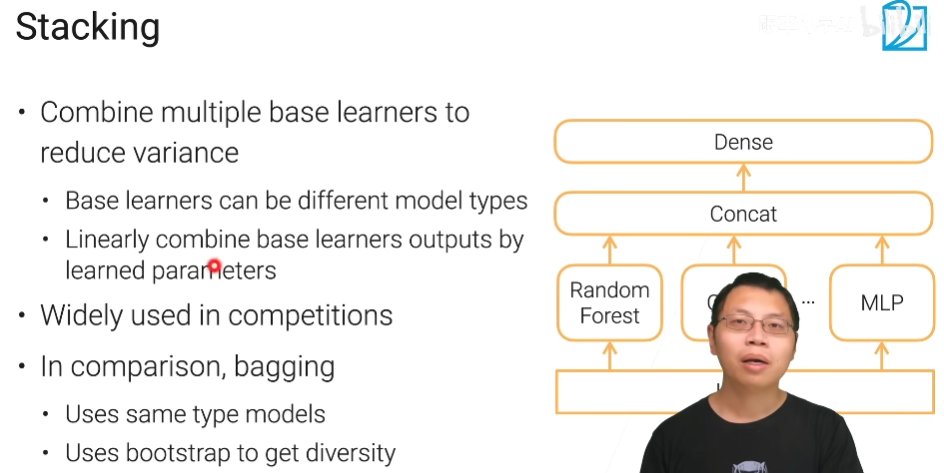
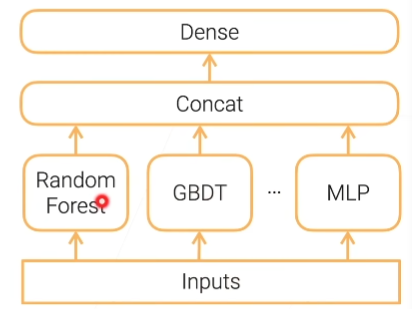
多层stacking

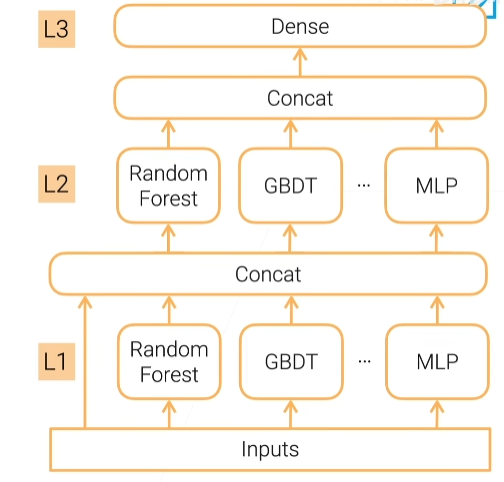
为了简单起见,我们会让每一层模型的组合一样,方便调参,多层stacking特别容易过拟合
避免过拟合

-
最简单是说训练第一层和第二层的数据就不应该是同一个数据,我把我们的训练集分成a b两块,第一层的那些模型呢先在a上面训练好,然后用第一层的模型啊对b做预测,把他的预测的结果再加上b的本身用来做第二层模型的训练,那么第二层模型的训练集跟第一层的训练集它是不是耦合在一起的。缺点就是每一层只用了一半的数据,比较吃亏
-
k-折 bagging,我们跟k折交叉验证一样的,把它分开就是一个数据集分成k份,每次我们在一个k-1份上训练,然后在k上面做验证我们这样子可以训练k个模型,假设我的第i个模型啊,是在第i个块上面做了验证,在剩下的上面做训练的话,那么我们把第i个模型在第i份数据的输出,也就是说他在验证时的输出留下来,这样的话我们有k个模型这样子,每一个模型能对一块数据没有参加训练那块数据它做预测,最后把这些预测并起来,变成全样本的新增变量,加上原来的再训练。
-
更昂贵的是对每一层的每一个模型,重复第一步和第二步(repeated k-fold bagging下面的第一步和第二步)n次,将n次后预测的平均作为下次的输入,相当于训练了k*n次
总结

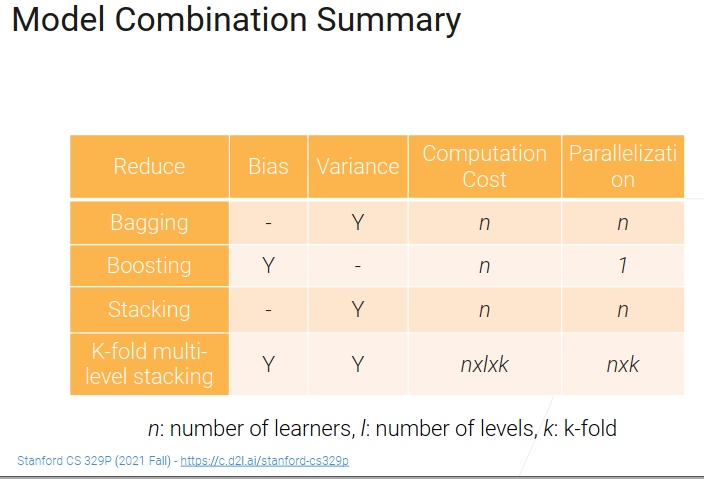
bagging降方差,可以并行,模型之间是相互独立的
boosting降偏差,串行
stacking降方差,每个模型基本可以参加独立的训练
9.1 模型调参
手动调参


最好把实验日志和超参数记录下来,这样调新的参数的时候,可以之前的作比较
自动调参

9.2 超参数优化
通过算法来选择超参数
搜索空间

categorical:在一些东西里面,随便选一个出来
log-uniform:我把这个值先做下log,然后他这个东西就变成1e-6和1e-1,然后在区间-6和-1之间均匀的随机取,然后做指数
weight_decay:也是随机梯度下降里面的一个值
搜索空间不能太大,太大了贵,也不能太小
HPO
超参优化技术(Hyper parameter Optimization, HPO)

hpo算法
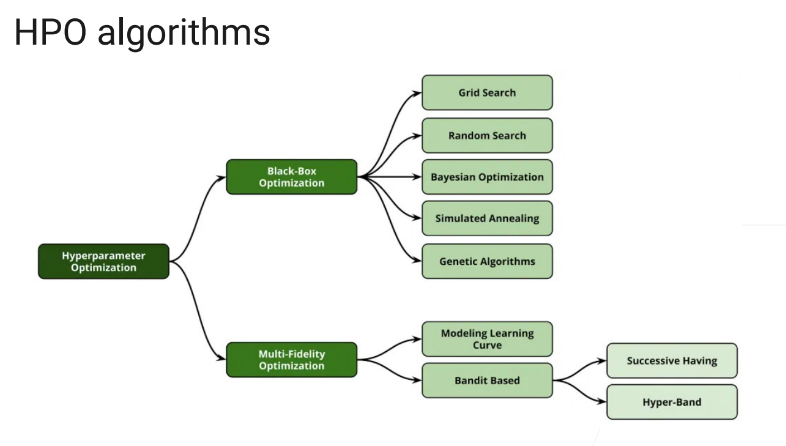
常见HPO策略

grid search:暴力穷举,把每一个config训练一遍,然后评价一次,把最好的结果返回给你,缺点是如果搜索空间特别大的话,几乎不可能
random search:最多n次,每次在search_space里面随机选出一个config
BO
用得不多

Successive Halving
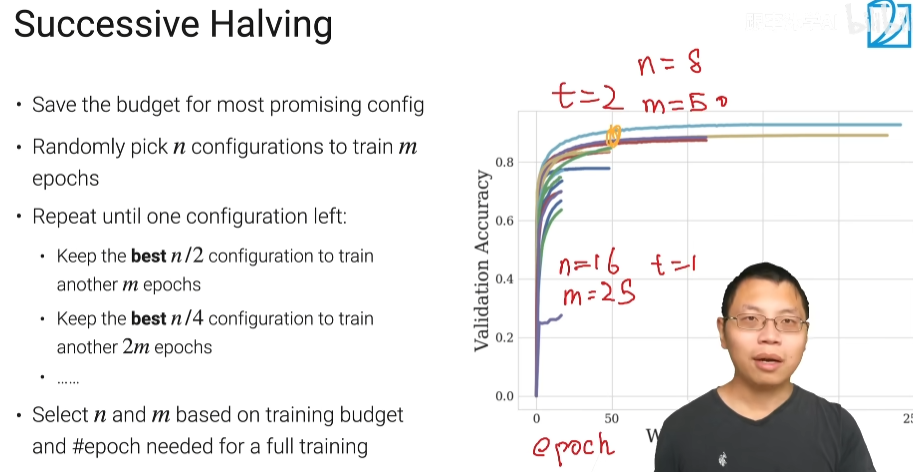
第一次用n个数据扫描m遍epochs,第二次用n/2个数据(去掉差的,保留好的)扫描2m遍epochs,第三次用n/4个数据扫描4m遍epochs....,每次把最好的数据留下来,进行下一次训练
hyperband
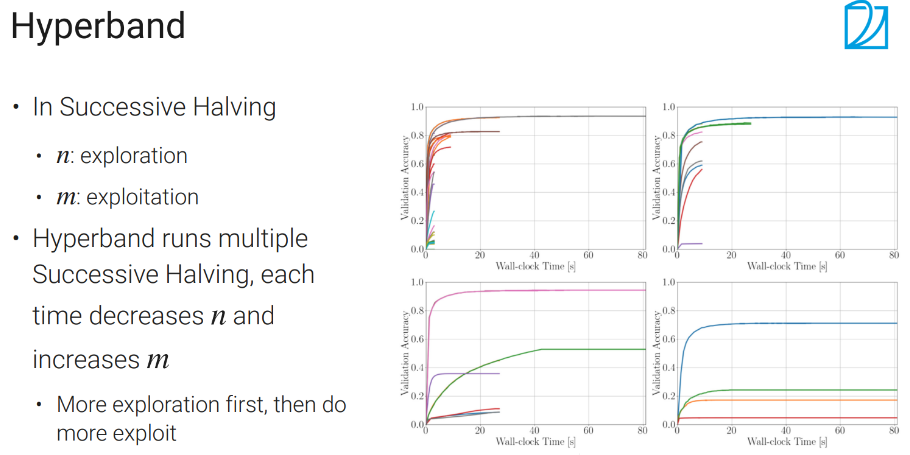
n越大,每次试的东西会越多
m取决于每一个参数,你去跑多长时间,时间越长,你看的越准
总结

HPO里面有两种主流算法,一个是黑盒的黑盒就是说我整个任务的训练就是做一个黑盒一个超参数进去个模型出来然后知道模型的好坏啊这里面有暴力搜索,随机搜索(用的最多),还有一个贝叶斯优化。
还有就是有些模型表现的好,接下来可以直接用这几个好的进行训练
9.3 网络架构搜索
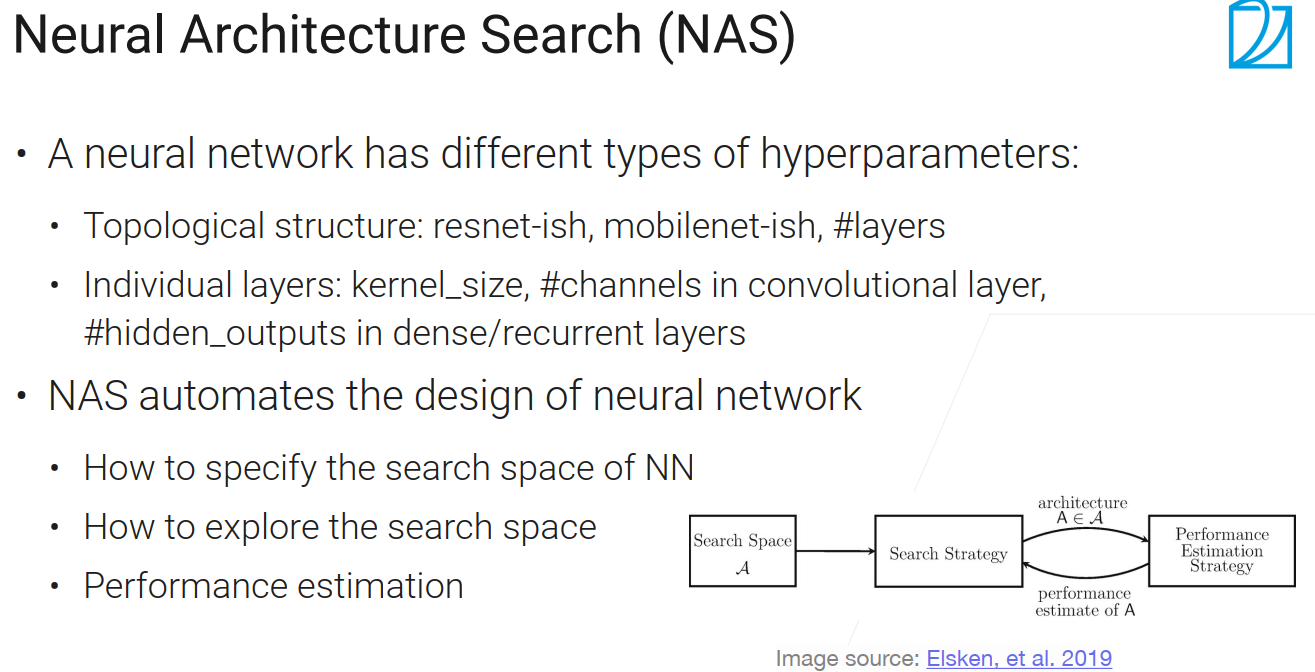
神经网络有不同类型的超参数:如
网络的拓扑结构(ResNet、MobileNet(通过特殊的卷积层,把整个计算复杂度降低,使得在手机或其他低功耗设备上算的比较快)、架构的层数等);
具体层的参数(卷积层中核窗口的大小、输出的通道数是多少、全连接层或RNN中输出的隐藏单元的个数)。
NAS的作用:尽量的使得整个网络的设计能够自动化
甚至可以从零开始设计一个神经网络;
给出一些网络的选择,选取最优的出来(有点像HPO);
NAS需要关心的东西:
整个搜索的空间是什么样子的(整个神经网络的超参数【SGD的或是其他的超参数不关心】);
怎么样在搜索空间中搜索;
怎么判断网络的好坏。
基本流程:设计一个搜索空间 -> 设计搜索策略 -> 每次采样一个架构出来,查看其性能 -> 反馈回搜索策略让策略更新;
NAS with Reinforcement Learning
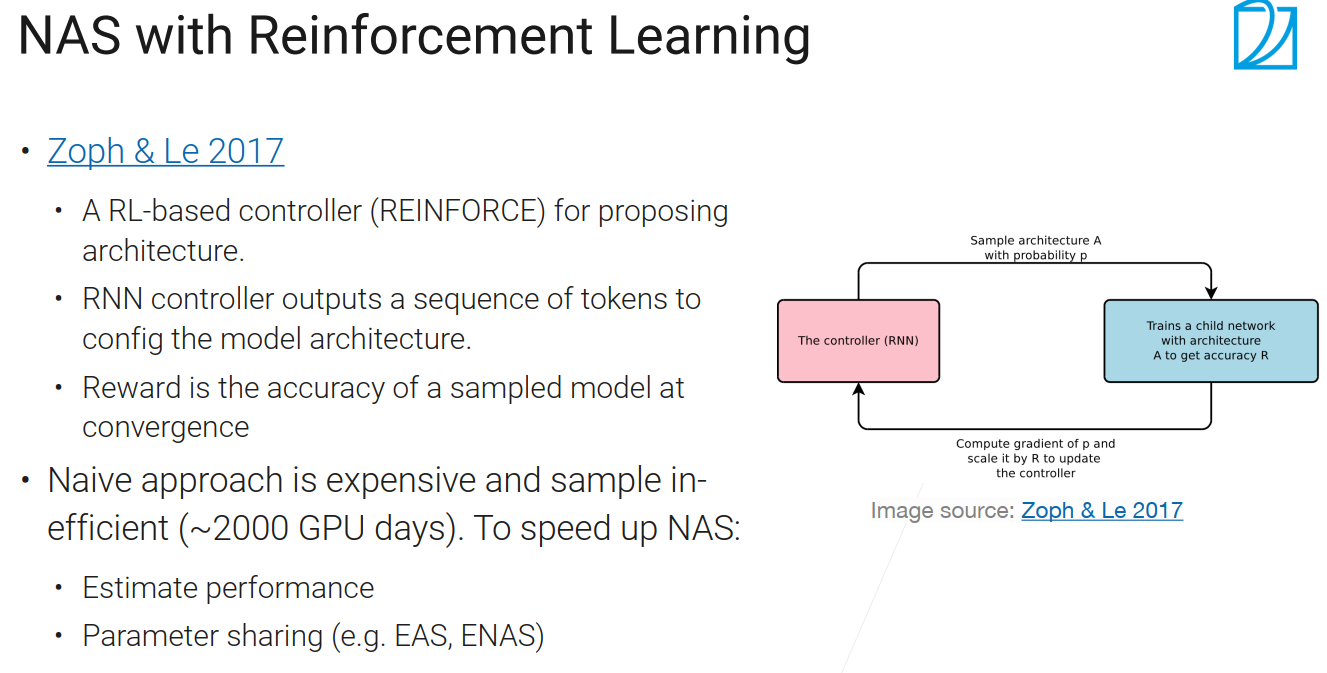
The One-shot Approach

-
即学超参数也学架构
-
训练特大的模型,这个模型的子模型是每种架构,训练一遍后既得到了他的性能,又得到了他的参数,当然了这个模型是非常巨大的,不可能全部放进gpu
-
只关心候选架构的排名关系,用一个近似指标看这些架构它们之间的精度,选出好的
-
在最好的架构上,重新做训练
可微架构搜索(Differentiable Architecture Search)
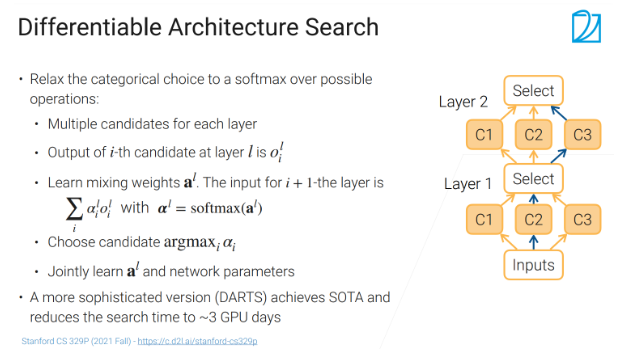
右图中有两层,每一层里面会有多个候选层,候选就是可以选择kernel的大小,通道数,选出靠谱的就行了,比如第一层选c1,第二层选c3。
第L层的第i个候选者的输出是\({o_{i}^{l} }\),比如C2输出\({o_{2}^{l} }\),这些输出会进入select操作,select里面有三个可以学的参数(继承的al),对这些参数(al)做softmax之后就变成非0的,在0到1之间然后加起来等于1,然后做成一个αl,然后select的输出就是等价于\({\sum_{i}^{} a_{i}^{l} o_{i}^{l} }\),等价于是说,这三个candidate,三个候选的每一个的输出,然后我们把它加权求和放进去
如何做最优解:假设C2是最优解,我最要C2对应的权重\({a_{2}^{l} }\),想办法通过学习把这个权重变的比较大,那么进入softmax的时候,这一个权重是趋近于1的,剩下的变为0,这样的输出的时候,基本上是看C2的输出,而不是看C1和C3的输出,这样就完成了一次选择的操作,训练完之后,我们在做选择的时候就是每次把每一个层里面最大的那个最大参数的候选拿出来,剩下的我就去掉了。
通过学习来选择我到底是哪条路比较好,这样子我避免了很多麻烦,这个softmax我可以加个温度,来使得他更加趋向于一个0和1
Scaling CNNs

flops:每秒浮点计算
CNN的变换的3种方式
- 深度:更深
- 宽度:更多输出通道
- 大的输入:把输入的图片变大一点
EfficientNet是这3种变换方式一起弄,α,β,γ,一般是会手动调好的,只需要调Φ值,反映你模型计算的复杂度
总结

NAS常用语把图片深度,宽度,分辨率合起来一起调
10.1 深度神经网络架构

Batch Normalization

标准化数据(使得数据的每一个特征均值为0,方差为1)使得损失函数更加平滑,特别是对线性模型来说。
平滑就是你给我一个输入x和输入一个 y,f是整个损失函数的话,f关于x的导数和f关于y的导数,它们之间的差的平方和会小于某个常数β乘以x和y之间的差的平方和。
假设我在做优化的时候,当前点是在f(x),我要在这个地方求梯度,然后沿着梯度往前走,但是走的时候有个问题。如果你走的比较远,比如走到y的时候,我沿着的方向还是x点求的导数,如果y的导数已经不一样了,方向发生了变化的话,我再往前走很有可能会走歪,如果y的梯度没有发生太大的变化的话,那我还可以继续往前走。也就是每次更新的时候,我可以沿着方向走的更远,学习可以更大假设你的x和y之间隔得不远的话,那么它的梯度的可以被上限约束住。
但是他不会帮助你的深度神经网络,这是因为如果你对x进行标准化的话,他只会帮助直接线性作用于x上的这个函数,也就是如果是线性模型是可以的,如果你有多层的话,可以帮助最下层线性层其他的帮不了。
批量归一化就是说我把中间的一些层啊,就Internal Layer的那些输入也对你做了标准化,那么他可以帮助你整个函数更加平滑,在训练深度神经网络的时候更加容易(观点还有争议)
通常来说你用了批量归一化之后,你的整个神经网络在收敛上更加容易就是说你可以选用更大的一些学习率,但是一般来说他不会改变你最后的结果,也就是用没用批量归一化最后的精度差不多
批量归一化的步骤

批量归一化可以拆解成4个步骤,之所以这么拆解是为了之后我们在讲别的归一化的时候,多多少少都能够放到这个框架里面来
-
第一步:变形,是2D不用变,不是2D要变为2D矩阵。假设你的x是你的卷积的输入的话,卷积一般呢就是一个4D的一个东西,你的第一个纬度是n(批量大小),第二个是通道,或者卷积的输出通道,第三个是宽,第四个是高。然后我们会变为一个2纬的矩阵,就是变成一个nwh×c,就是把第二个纬度(通道)拉到最后,把后面两个纬度(w,h)拉到前面
-
第二步:标准化,对每一列进行标准化(每一行是样本,每一列是特征,和李宏毅老师一样的)减去这一列的均值,再除以这一列的标准方差
-
第三步:还原,对刚才标准化的x的第j列,再乘以γj,再加上βj,这样允许你还原回去,如果你把βj换成均值的话,那么就可以还原出\({x_{j}^{'}}\),γj和βj是一个可以学习的参数,也就是神经网络会根据你的需求去找出来
-
第四步:得到最终输出Y,把Y‘换成以前的东西,如果是2为矩阵不需要变什么东西,如果你是一个卷积的话将从nwh×c还原成n×c×w×h
批量归一化代码实现
import torch
# X 输入的那个样本
# gamma和beta是可以学习到的,在recover里面的
# γ是一个响亮,向量长度等于你的数据里面它的特征纬度的个数
# moving_mean,moving_var 是均值和方差用来存放做预测用的
# eps 避免除0的东西
# momentum,冲量
def batch_norm(X,gamma,beta,moving_mean,moving_var,eps,momentum):
# 如果你的批量大小为1,你去算他的均值和方差就不那么准了,这个是用的是在训练的时候
if not torch.is_grad_enabled(): # 如果没有梯度就是在预测模式,否则就是做训练
# 在做预测的时候,我的均值和方差是来自于前面在训练的时候存下来的值,一个全局的值
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps) # 标准差是方差的平方根,所以这里要开根号,这个eps很小,主要是避免除0
else:
# 但是在做预测时候,我的这个均值和方差,都是在当前x里面求出来的,对当前这个批量求出来的均值和方差
assert len(X.shape) in (2,4) # 处理二维或者四维的情况
if len(X.shape) == 2: # 2维是mlp的输入
# mean的长度就是等于你x第0维,就是你的样本的个数,他就是一条向量,他表示的是每个样本它的特征的那个均值
mean = X.mean(dim=0) # dim=0,除了第0维之外别的维度啊,就是把它全部压成一个值,压成它的均值
var = ((X - mean)**2).mean(dim=0)
else: # 4维是卷积层的输入
mean = X.mean(dim=(0,2,3),keepdim=True) # 除了0,2,3这些维度(batch,width,height),把1维度(channel)全部拉成一个均值
var = ((X - mean)**2).mean(dim=(0,2,3),keepdim=True) # 这里的var是方差
X_hat = (X - mean) / torch.sqrt(var + eps) # 标准差是方差的平方根,所以这里要开根号,对应的是第二步normalize
# 我会把它的均值乘以一个momentum,移动平滑,
moving_mean = momentum * moving_mean + (1.0 - momentum)
# 对这个var也使用了这个移动平滑
moving_var = momentum * moving_var + (1.0 - momentum)
# 第三步,recovery
Y = gamma * X_hat + beta
return Y,moving_mean,moving_var # 预测的时候不会更新,但是在训练的时候会不断的更新
mlp的输入是2维的
卷积层的输入是4维的
keepdim=True:返回的还是原来的维度
assert:assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常
层归一化(Layer Normalization)
层归一化主要用在循环神经网络里面。
批量归一化的问题:假设在RNN里面你的句子长度是等于一个P,你需要做P次mlp,如果你用BN在这个地方,每个时间步骤你要用自己的均值,方差,甚至是γ和β。就是你在不同的时间步之间,不要去共享均值和方差,因为对不同的时间步,这些东西变化比较大。BN最好还是能够对当前的数据做一个比较稳定的,准确一点的均值方差的估计,如果你这个均值方差抖动比较大,就失去了标准化的意义。假设你的输入长度为10,我就维护10个在不同的时间步的均值方差,均值方差是做inference(推理)用的,γ和β也得维护好。

层归一化和batch normalization非常像,它在做reshape的时候,如果是2维的,LN做了个转置,但是BN就不管了。如果是4维的,就把n拉到最后,c,w,h提前。除此外,LN和BN两个唯一的区别是按那个维度去计算均值和方差,BN是每一个列算他的均值和方差,使得这一列均值为0,方差为1。现在对每个样本按行来算均值和方差。
总结

normalization就是我们把一些中间的层,让你数值变的稳定一点,让你的整个损失函数更加平滑一点,使得整个神经网络训练的更加容易,一般来说,他不会改变你最后的那一个精度,但是他主要是让你的训练更加容易,优化的曲线更动平滑一点,BN用在CNN多点,LN用在transformer里面多点
11.1 迁移学习

CV中的微调(fine-tuning)

预训练好的模型

神经网络可以分为两块
- encoder (编码器):特征提取器,把原始的像素,转换成一个语义空间里面可以线性可分的一些特征
- decoder(解码器):简单的线性分类器
比如你把一张猫的图片输入,前面所有的层可以当做特征提取器,最后一层是线性分类器
预训练模型,因为是在大量的数据集上训练而成,所以应该有一定的泛化能力,对于未知的图片或者其他任务能够起一些作用
Fine-Tuning techniques(微调技术)
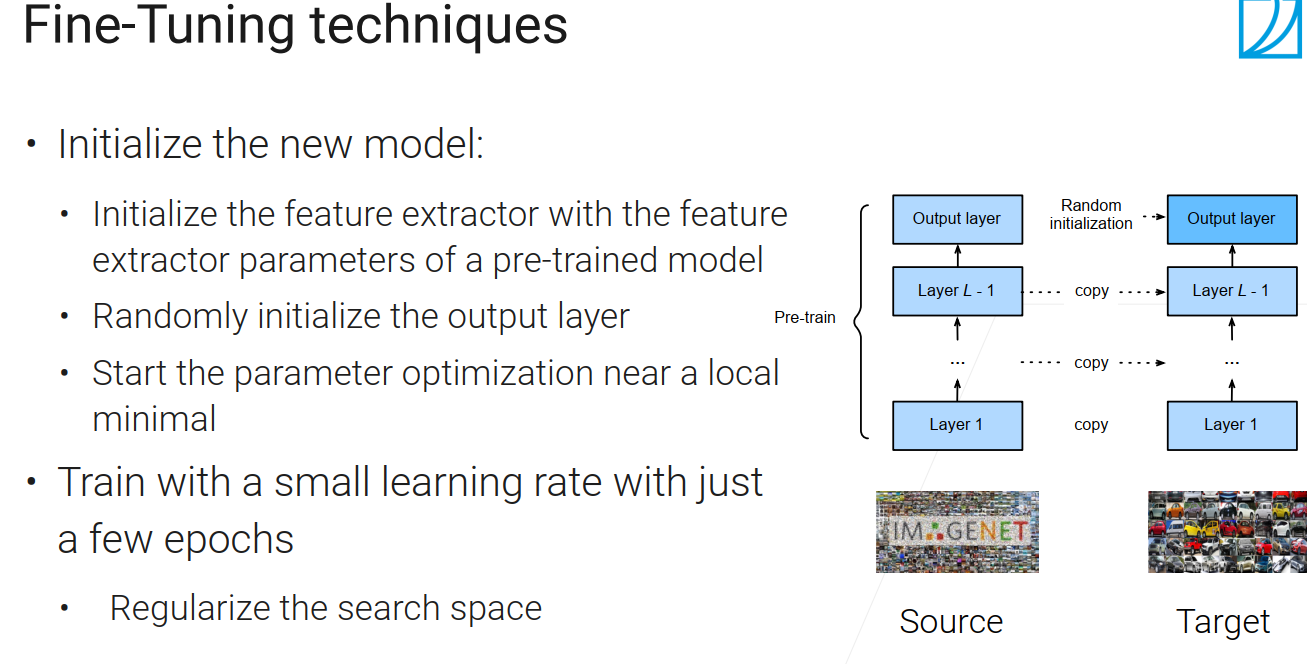
在新的任务上构建一个新的模型,这个新模型的架构要和预训练模型的架构一样。我的新模型的特征提取器(除了最后一层外的,卷积层,全连接层)它的权重初始的时候,参数不是随机的,而是把预训练好的模型的权重直接复制过来,最后一层(解码器),我用的还是随机的。也就是前面的都一样,最后一层我要随机初始化,并学会如何去做决策。
因为你初始的结果已经是比较好的了,离你最优解比较接近,这时候你就不要让模型走太远,要限制住它,让学习率小点比如0.1,还有不要训练太长时间,这两个东西让整个搜索空间变的小一点,不要太大了
freeze bottom layer(固定最底层)
限制搜索空间的方法之一

神经网络通常有一个层次化的,最底层一般是学习了底层的特征,上层的更与语义相关,所以一般来说底层与上面层没有太多的关系,在换了数据集之后泛化性都很好;
最后一层还是随机初始化学习,然后只对某一些层进行改动,最下面那些层在微调时就不去动了(可以说是学习率为0);
固定住多少层是要根据应用来看的,假设应用与预训练模型差别比较大的话,可以多训练一些层
怎样找到预训练模型
Tensorflow Hub链接:https://tfhub.dev/
TIMM链接:https://github.com/rwightman/pytorch-image-models
微调的应用

- 微调能加速收敛,比如你之前需要扫100轮,才能得到一个比较好的精度,现在可能几轮就行了
- 不一定会提升你的精度,最坏情况下精度不变
总结

-
通常会在大的数据集上预训练模型,常在CV领域
-
新的任务上,把预训练好的模型的权重,复制你的模型上,但是最后一层是随机初始
-
用小的学习率,通常会加速你的收敛有时会提升精度
NLP中的微调

在NLP里面,我们一般会去做自监督的一个预训练,自监督就是自己产生的所谓的一些伪标号,然后再用监督学习的任务来完成我们的预训练。
在NLP中有两个常见的应用可以生成这样子的伪标号
-
语言模型:预测下一个单词
-
带掩码的语言模型:随机将句子中某些单词抹掉,让机器预测,也就是所谓的完形填空
常见的预训练模型

-
词嵌入
模型会学习两个向量u_w和v_w,然后对给定掩码的词Y,用其x1……xn去预测Y
具体来说,要预测的值用u来表示,上下文的词用v来表示,然后把v给加起来再与u做内积,这样就可以的到u与v之间的关系,这个算法叫CBOW;然后做预测时就从字典中选取一个y使得CBOW的值最大;
当然,也可以用中心词去预测周围的词。具体是说,对所有的词学到了两个向量,这两个词具有一定的语义关系(两个词如果差不多同时出现的话,那么存在相似度),如果说y与xi出现在一起的话,内积比较大的话,意味着说有相似性; -
基于transformer的预训练模型
BERT
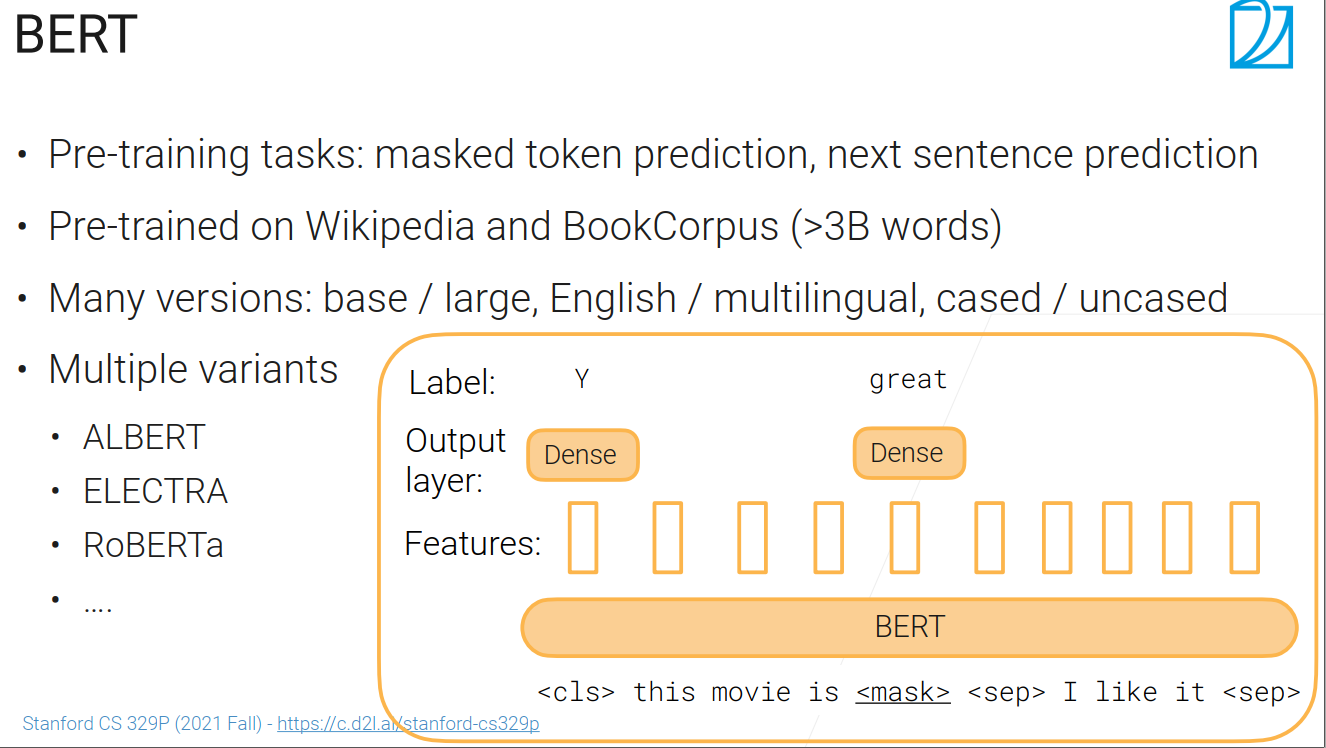
BERT微调
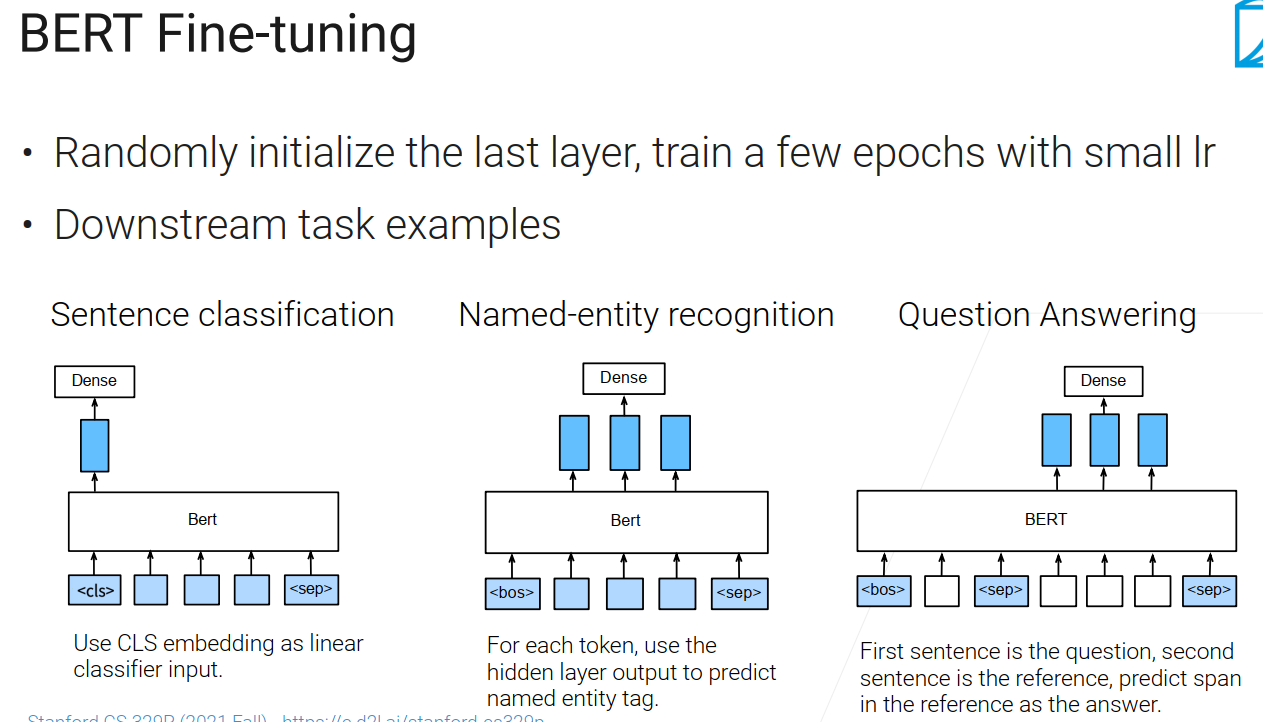
训练好预训练模型后,可以用bert做微调,拿到一个bert以后,把最后一层改成你的任务要求,输出你要求输出的东西,所以我只需要改最后一层
一些问题

-
微调的时候,最好使用完整版的adam
-
训练时候,最好多训练几个epoch
如何找到预训练模型

应用

总结

在nlp里面,我们的预训练模型通常是通过自监督来完成的,因为自然语言里面的数据集相对没有特别大的有标好的数据集,常见的应用是做语言模型或者是带掩码的语言模型,bert是一个特别大的transformer的编码器,gpt是一个特别大的解码器,T5是一个特别大的transformer编码器加解码器,用bert做下游任务微调的时候,只要改最后一层

 浙公网安备 33010602011771号
浙公网安备 33010602011771号