双向注意力流模型
Bidirectional Attention Flow for Machine Comprehension | Papers With Code
双向注意力模型
开山之作,奠定了机器阅读理解的编码层-交互层-输出层的结构
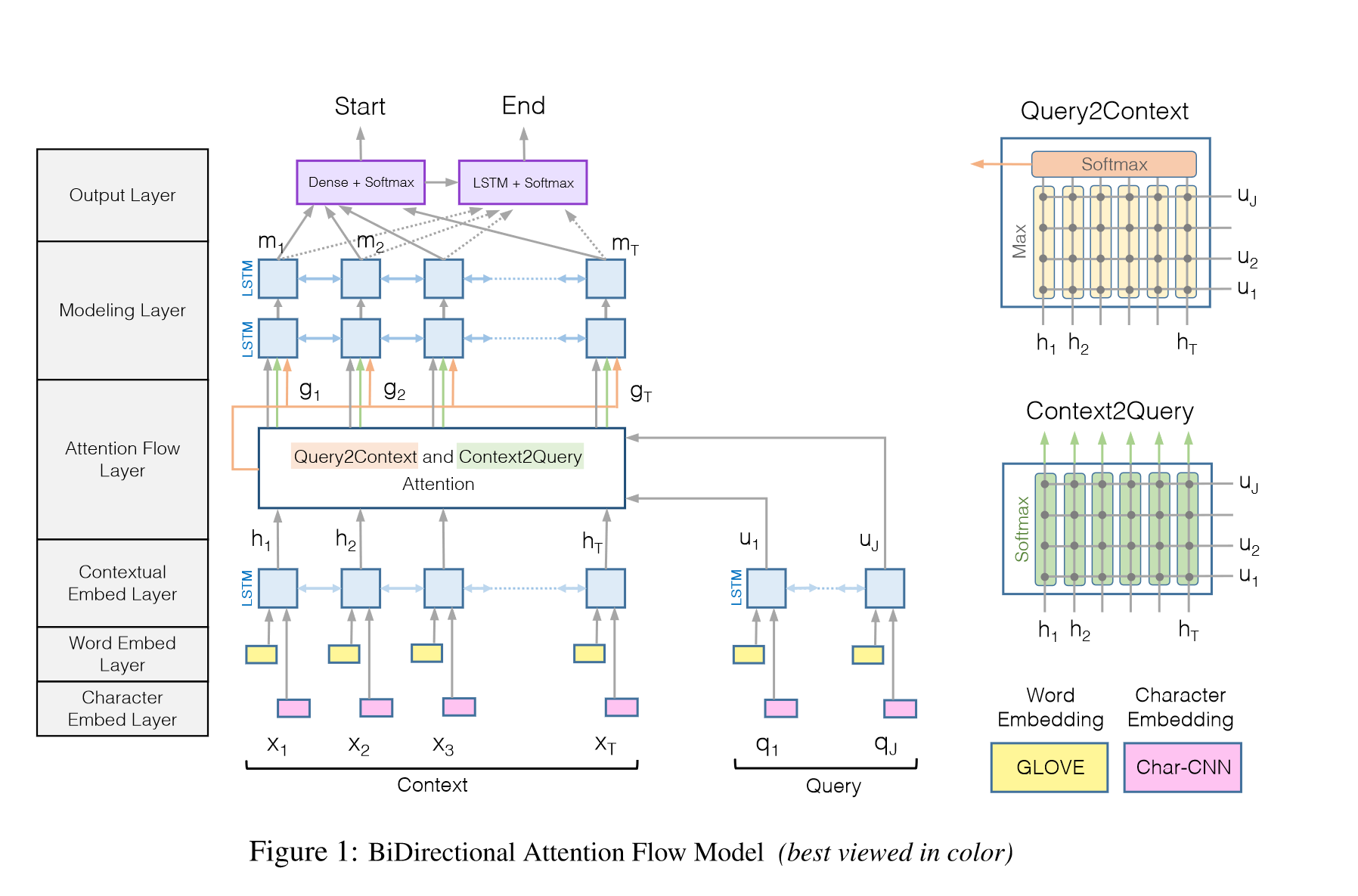
编码层
Character Embed Layer

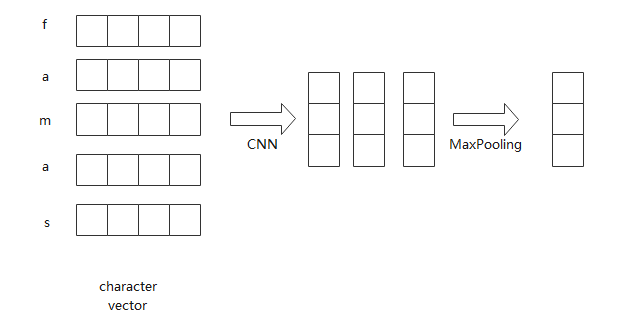
因为每个单词的长度不一样,每个单词可能有不同个数的字符向量,我们需要产生固定长度的字符信息向量

将单词转换为词向量后,通过CNN,然后通过最大池化层,如下图
代码
class Char_CNN_Maxpool(nn.Module):
def __init__(self,char_num,char_dim,window_size,out_channels):
super(Char_CNN_Maxpool,self).__init__()
self.char_embed = nn.Embedding(char_num,char_dim)
self.cnn = nn.Conv2d(1,out_channels,(window_size,char_dim))
def forward(self,char_ids):
x = self.char_embed(char_ids)
x_unsqueeze = x.view(-1,x.shape[2],x.shape[3]).unsqueeze(1) # batch*seq_len,1,word_len,char_dim
x_cnn = self.cnn(x_unsqueeze)
x_cnn_result = x_cnn.squeeze(3) # batch*seq_len,out_channels,new_seq_len
res,_ = x_cnn_result.max(2) #
return res.view(x.shape[0],x.shape[1],-1)
Word Embed Layer

BiDAF将每个单词的字符编码和词表编码拼接成d维向量,通过一个高速公路网络传给双向LSTM(Contextual Embed Layer),高速路公式如下
⊙是elementwise multiplication :对应位置的元素相乘,如下图
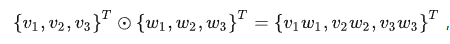
element-wise product = element-wise multiplication = Hadamard product
第一步部分是输入x经过一个网络H得到的结果,第二部分是输入x本身,\(H(x)=tanh(W_{h}x+b_{h})\),\(T(x)=σ(W_{t}x+b_{r})\),高速路的作用缓解了梯度爆炸和梯度消失。经过双向LSTM得到文章和问题中的每个单词的上下文编码,文章和问题的每个单词均由一个2d向量表示。
Contextual Embed Layer

交互层
Attention Flow Layer
注意力流层负责链接和融合来自上下文和查询词的信息。让每个时间步上的注意力向量,以及来自前几层的嵌入,可以流经到后续的建模层。这样减少了早期摘要带来的信息损失。该层的输入是上下文H和查询U的上下文向量表示。该层的输出是上下文单词G的查询感知向量表示以及来自上一层的上下文嵌入。然后这里计算双向注意力(BiDAF的创新点),从上下文到问题和从问题到上下文的注意力。它们都来自于上下文( H )和查询( U )的上下文嵌入之间的共享相似度矩阵\(S∈R^{I× J}\),其中\(S_{ij}\)表示第i个上下文词和第j个查询词之间的相似度。
Context-to-query
BiDAF的编码层得到文章的m个2d维单词向量\(H=(h_{1},h_{2},....,h_{m})\)和问题的n个2d维\(U=(u_{1},u_{2},....,u_{n})\)向量,文章中第i个单词和问题中第j个单词的注意力分数是
这里的o是elementwise multiplication :对应位置的元素相乘,和上面的⊙一样,\(w_{s}\)是一个可训练的权重向量。如果\(w_{s}\)=[0...0;0...0;1...1]那么\(s_{i,j}\)就是\(h_{i}\)和\(u_{j}\)的内积。
[;]是跨行的向量连接
得到\(s_{i,j}\)后,模型计算softmax的值\(β_{i,j}\),并根据\(β_{i,j}\)计算问题单词向量的加权和,得到注意力向量\(\tilde{u_{i}}\)
Quey-to-context
BiDAF在计算Quey-to-context时,不是将文章到问题的参数对调,而是使用C2Q中的注意力函数结果\(s_{i,j}\)。然后对,对于文章中每个单词\(w_{i}\),计算和它最接近的问题单词的相似度\(t_{i}= \max_{1≤j≤n}s_{i,j}\),然后,执行softmax操作,计算文章单词向量的加权和\(\tilde{h}\):
将\(\tilde{h}\)重复m次得到矩阵\(\tilde{H}=[\tilde{h};\tilde{h};...\tilde{h};]\)
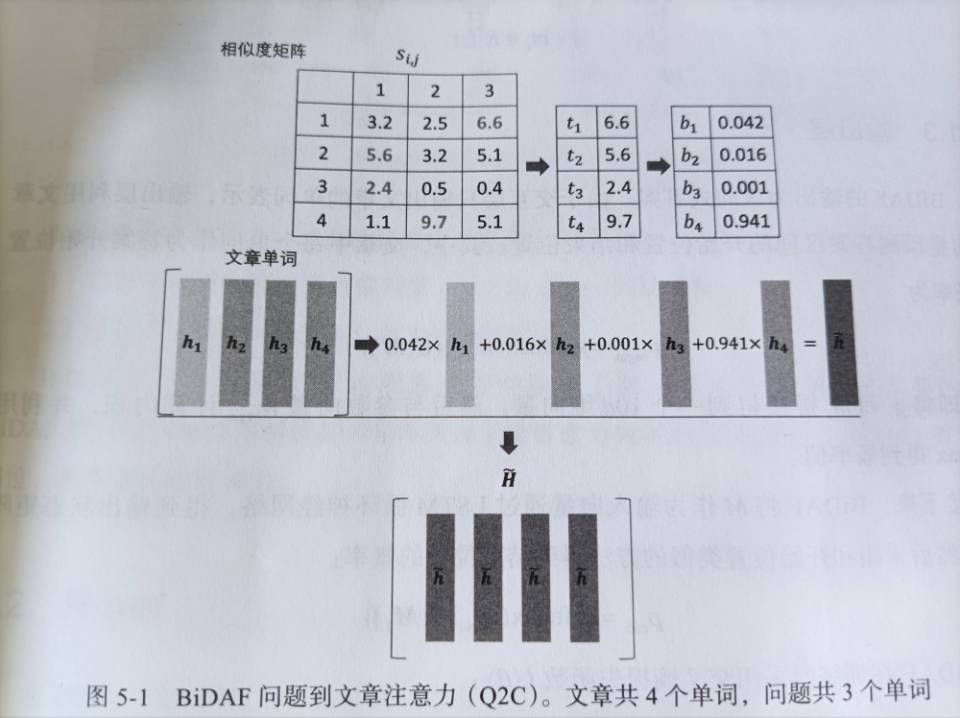
C2Q和Q2C的注意力结果\(\tilde{U}\)和\(\tilde{H}\)矩阵的维度均为2d×m,将这个3个矩阵拼接起来
每个文章的单词被一个2d+2d+2d+2d=8d维向量\(g_{i}\)表示,其中包含了单词本身、文章上下文以及问题的含义。
Modeling Layer
在这一层,文章的词向量再次经过双向RNN,输出每个文章单词的最终向量表示:2d维向量\(m_{i}\),与前面的LSTM不同,这里输入向量同时包括文章和问题,模型层对所有信息进行了更深层次的融合
输出层
BiDAF的输出为区间式答案。答案的开始位置的概率为
将\(g_{i}\)和\(m_{i}\)拼接得一个10d维向量,然后和参数向量\(w_{begin}\)计算内积,然后用softmax得到概率。
然后将M输入到LSTM中,得到\(M_{2}\),然后用同样的公式计算结束位置的概率
训练时,采用交叉熵损失函数为
\(y^{i}_{begin}\)和\(y_{i}^{end}\)分别表示第i个问题的标准答案在文章中的开始位置和结束位置
代码
class BiDAF(nn.Module):
def __init__(self, args, pretrained):
super(BiDAF, self).__init__()
self.args = args
# 1. Character Embedding Layer
self.char_emb = nn.Embedding(args.char_vocab_size, args.char_dim, padding_idx=1)
nn.init.uniform_(self.char_emb.weight, -0.001, 0.001)
self.char_conv = nn.Sequential(
nn.Conv2d(1, args.char_channel_size, (args.char_dim, args.char_channel_width)),
nn.ReLU()
)
# 2. Word Embedding Layer
# initialize word embedding with GloVe
self.word_emb = nn.Embedding.from_pretrained(pretrained, freeze=True)
# highway network
assert self.args.hidden_size * 2 == (self.args.char_channel_size + self.args.word_dim)
for i in range(2):
setattr(self, 'highway_linear{}'.format(i),
nn.Sequential(Linear(args.hidden_size * 2, args.hidden_size * 2),
nn.ReLU()))
setattr(self, 'highway_gate{}'.format(i),
nn.Sequential(Linear(args.hidden_size * 2, args.hidden_size * 2),
nn.Sigmoid()))
# 3. Contextual Embedding Layer
self.context_LSTM = LSTM(input_size=args.hidden_size * 2,
hidden_size=args.hidden_size,
bidirectional=True,
batch_first=True,
dropout=args.dropout)
# 4. Attention Flow Layer
self.att_weight_c = Linear(args.hidden_size * 2, 1)
self.att_weight_q = Linear(args.hidden_size * 2, 1)
self.att_weight_cq = Linear(args.hidden_size * 2, 1)
# 5. Modeling Layer
self.modeling_LSTM1 = LSTM(input_size=args.hidden_size * 8,
hidden_size=args.hidden_size,
bidirectional=True,
batch_first=True,
dropout=args.dropout)
self.modeling_LSTM2 = LSTM(input_size=args.hidden_size * 2,
hidden_size=args.hidden_size,
bidirectional=True,
batch_first=True,
dropout=args.dropout)
# 6. Output Layer
self.p1_weight_g = Linear(args.hidden_size * 8, 1, dropout=args.dropout)
self.p1_weight_m = Linear(args.hidden_size * 2, 1, dropout=args.dropout)
self.p2_weight_g = Linear(args.hidden_size * 8, 1, dropout=args.dropout)
self.p2_weight_m = Linear(args.hidden_size * 2, 1, dropout=args.dropout)
self.output_LSTM = LSTM(input_size=args.hidden_size * 2,
hidden_size=args.hidden_size,
bidirectional=True,
batch_first=True,
dropout=args.dropout)
self.dropout = nn.Dropout(p=args.dropout)
def forward(self, batch):
# TODO: More memory-efficient architecture
def char_emb_layer(x):
"""
:param x: (batch, seq_len, word_len)
:return: (batch, seq_len, char_channel_size)
"""
batch_size = x.size(0)
# (batch, seq_len, word_len, char_dim)
x = self.dropout(self.char_emb(x))
# (batch, seq_len, char_dim, word_len)
x = x.transpose(2, 3)
# (batch * seq_len, 1, char_dim, word_len)
x = x.view(-1, self.args.char_dim, x.size(3)).unsqueeze(1)
# (batch * seq_len, char_channel_size, 1, conv_len) -> (batch * seq_len, char_channel_size, conv_len)
x = self.char_conv(x).squeeze()
# (batch * seq_len, char_channel_size, 1) -> (batch * seq_len, char_channel_size)
x = F.max_pool1d(x, x.size(2)).squeeze()
# (batch, seq_len, char_channel_size)
x = x.view(batch_size, -1, self.args.char_channel_size)
return x
def highway_network(x1, x2):
"""
:param x1: (batch, seq_len, char_channel_size)
:param x2: (batch, seq_len, word_dim)
:return: (batch, seq_len, hidden_size * 2)
"""
# (batch, seq_len, char_channel_size + word_dim)
x = torch.cat([x1, x2], dim=-1)
for i in range(2):
h = getattr(self, 'highway_linear{}'.format(i))(x)
g = getattr(self, 'highway_gate{}'.format(i))(x)
x = g * h + (1 - g) * x
# (batch, seq_len, hidden_size * 2)
return x
def att_flow_layer(c, q):
"""
:param c: (batch, c_len, hidden_size * 2)
:param q: (batch, q_len, hidden_size * 2)
:return: (batch, c_len, q_len)
"""
c_len = c.size(1)
q_len = q.size(1)
# (batch, c_len, q_len, hidden_size * 2)
#c_tiled = c.unsqueeze(2).expand(-1, -1, q_len, -1)
# (batch, c_len, q_len, hidden_size * 2)
#q_tiled = q.unsqueeze(1).expand(-1, c_len, -1, -1)
# (batch, c_len, q_len, hidden_size * 2)
#cq_tiled = c_tiled * q_tiled
#cq_tiled = c.unsqueeze(2).expand(-1, -1, q_len, -1) * q.unsqueeze(1).expand(-1, c_len, -1, -1)
cq = []
for i in range(q_len):
#(batch, 1, hidden_size * 2)
qi = q.select(1, i).unsqueeze(1)
#(batch, c_len, 1)
ci = self.att_weight_cq(c * qi).squeeze()
cq.append(ci)
# (batch, c_len, q_len)
cq = torch.stack(cq, dim=-1)
# (batch, c_len, q_len)
s = self.att_weight_c(c).expand(-1, -1, q_len) + \
self.att_weight_q(q).permute(0, 2, 1).expand(-1, c_len, -1) + \
cq
# (batch, c_len, q_len)
a = F.softmax(s, dim=2)
# (batch, c_len, q_len) * (batch, q_len, hidden_size * 2) -> (batch, c_len, hidden_size * 2)
c2q_att = torch.bmm(a, q)
# (batch, 1, c_len)
b = F.softmax(torch.max(s, dim=2)[0], dim=1).unsqueeze(1)
# (batch, 1, c_len) * (batch, c_len, hidden_size * 2) -> (batch, hidden_size * 2)
q2c_att = torch.bmm(b, c).squeeze()
# (batch, c_len, hidden_size * 2) (tiled)
q2c_att = q2c_att.unsqueeze(1).expand(-1, c_len, -1)
# q2c_att = torch.stack([q2c_att] * c_len, dim=1)
# (batch, c_len, hidden_size * 8)
x = torch.cat([c, c2q_att, c * c2q_att, c * q2c_att], dim=-1)
return x
def output_layer(g, m, l):
"""
:param g: (batch, c_len, hidden_size * 8)
:param m: (batch, c_len ,hidden_size * 2)
:return: p1: (batch, c_len), p2: (batch, c_len)
"""
# (batch, c_len)
p1 = (self.p1_weight_g(g) + self.p1_weight_m(m)).squeeze()
# (batch, c_len, hidden_size * 2)
m2 = self.output_LSTM((m, l))[0]
# (batch, c_len)
p2 = (self.p2_weight_g(g) + self.p2_weight_m(m2)).squeeze()
return p1, p2
# 1. Character Embedding Layer
c_char = char_emb_layer(batch.c_char)
q_char = char_emb_layer(batch.q_char)
# 2. Word Embedding Layer
c_word = self.word_emb(batch.c_word[0])
q_word = self.word_emb(batch.q_word[0])
c_lens = batch.c_word[1]
q_lens = batch.q_word[1]
# Highway network
c = highway_network(c_char, c_word)
q = highway_network(q_char, q_word)
# 3. Contextual Embedding Layer
c = self.context_LSTM((c, c_lens))[0]
q = self.context_LSTM((q, q_lens))[0]
# 4. Attention Flow Layer
g = att_flow_layer(c, q)
# 5. Modeling Layer
m = self.modeling_LSTM2((self.modeling_LSTM1((g, c_lens))[0], c_lens))[0]
# 6. Output Layer
p1, p2 = output_layer(g, m, c_lens)
# (batch, c_len), (batch, c_len)
return p1, p2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号