中文命名实体识别
代码地址:NER_in_Chinese/命名实体识别_中文.ipynb at main · lansinuote/NER_in_Chinese (github.com)
中文命名实体识别
加载分词器
from transformers import AutoTokenizer
#加载分词器
tokenizer = AutoTokenizer.from_pretrained('hfl/rbt6')
print(tokenizer)
#分词测试
tokenizer.batch_encode_plus(
[[
'海', '钓', '比', '赛', '地', '点', '在', '厦', '门', '与', '金', '门', '之', '间',
'的', '海', '域', '。'
],
[
'这', '座', '依', '山', '傍', '水', '的', '博', '物', '馆', '由', '国', '内', '一',
'流', '的', '设', '计', '师', '主', '持', '设', '计', ',', '整', '个', '建', '筑',
'群', '精', '美', '而', '恢', '宏', '。'
]],
truncation=True,
padding=True,
return_tensors='pt',
is_split_into_words=True)
加载数据集
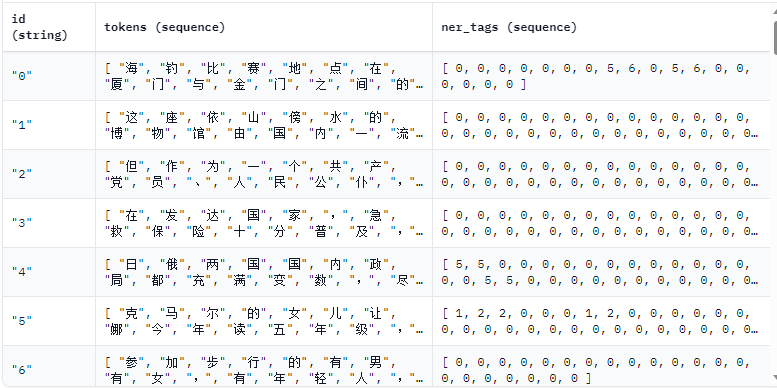
数据集样例
import torch,gc
from datasets import load_dataset, load_from_disk
# 清楚无用pytorch缓存
gc.collect()
torch.cuda.empty_cache()
class Dataset(torch.utils.data.Dataset):
def __init__(self, split):
#names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC']
# 0:代表这是一个单词
# 1:B-PER,代表person name的开始
# 2:I-PER,person name的中间,如果有个三字人名的话,数字表示就是122
# 3:B-ORG:代表organizaiton的开始
# 4:I-ORG:代表organizaiton的中间
# 5:B-LOC :代表location的开始
# 6:I-LOC :代表location的中间
#在线加载数据集
#dataset = load_dataset(path='peoples_daily_ner', split=split)
#离线加载数据集
# 先用py文件,报错后,用下面的代码
#dataset = load_dataset('./data/clone/peoples_daily_ner/peoples_daily_ner.py')
#
dataset = load_dataset('./data/clone/peoples_daily_ner')
dataset.save_to_disk(dataset_dict_path='./data/people_daily_ner')
dataset = dataset[split]
#过滤掉太长的句子
def f(data):
return len(data['tokens']) <= 512 - 2
dataset = dataset.filter(f)
self.dataset = dataset
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
tokens = self.dataset[i]['tokens']
labels = self.dataset[i]['ner_tags']
return tokens, labels
dataset = Dataset('train')
tokens, labels = dataset[0]
len(dataset), tokens, labels
数据整理函数
#数据整理函数
def collate_fn(data):
tokens = [i[0] for i in data]
labels = [i[1] for i in data]
# 中文编码为数字
inputs = tokenizer.batch_encode_plus(tokens,
truncation=True,
padding=True,
return_tensors='pt',
is_split_into_words=True)
lens = inputs['input_ids'].shape[1]
for i in range(len(labels)):
labels[i] = [7] + labels[i]
labels[i] += [7] * lens
labels[i] = labels[i][:lens]
return inputs, torch.LongTensor(labels)
#数据加载器
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=16,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
#查看数据样例
for i, (inputs, labels) in enumerate(loader):
break
print(len(loader))
print(tokenizer.decode(inputs['input_ids'][0]))
print(labels[0])
for k, v in inputs.items():
print(k, v.shape)
输出结果

- inputs

定义训练设备
def try_gpu(i=0):
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
device = try_gpu()
加载预训练模型
from transformers import AutoModel
#加载预训练模型
pretrained = AutoModel.from_pretrained('hfl/rbt6')
pretrained = pretrained.to(device)
#统计参数量
#print(sum(i.numel() for i in pretrained.parameters()) / 10000)
#模型试算
#[b, lens] -> [b, lens, 768]
#pretrained(**inputs).last_hidden_state.shape
定义下游模型
#定义下游模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.tuneing = False
self.pretrained = None
self.rnn = torch.nn.GRU(768, 768,batch_first=True)
self.fc = torch.nn.Linear(768, 8)
def forward(self, inputs):
if torch.cuda.is_available():
inputs = inputs.to(device)
if self.tuneing:
out = self.pretrained(**inputs).last_hidden_state
else:
with torch.no_grad():
out = pretrained(**inputs).last_hidden_state
out, _ = self.rnn(out)
out = self.fc(out).softmax(dim=2)
return out
def fine_tuneing(self, tuneing):
self.tuneing = tuneing
# 微调的话,需要计算预训练模型的参数
if tuneing:
for i in pretrained.parameters():
i.requires_grad = True
pretrained.train()
self.pretrained = pretrained
else:
for i in pretrained.parameters():
i.requires_grad_(False)
pretrained.eval()
self.pretrained = None
model = Model()
model = model.to(device)
model(inputs).shape
# torch.Size([16, 81, 8])
- torch.no_grad()
1、可以减少内存使用
2、训练集训练好模型后,在验证集这里使用with torch.no_grad(),训练集则不会计算梯度值,然后并不会改变模型的参数,只是看了训练的效果。
with torch.no_grad()用处 - 平凡之上 - 博客园 (cnblogs.com)
对计算结果和label变形,移除pad
#对计算结果和label变形,并且移除pad
def reshape_and_remove_pad(outs, labels, attention_mask):
#变形,便于计算loss
#[b, lens, 8] -> [b*lens, 8]
print('----out----之前')
print(outs)
print('----out----之后')
outs = outs.reshape(-1, 8)
print(outs)
#[b, lens] -> [b*lens]
print('----label----之前')
print(labels)
labels = labels.reshape(-1)
print('----label----之后')
print(labels)
#忽略对pad的计算结果
#[b, lens] -> [b*lens - pad]
print('--------attention_mask---之前')
print(attention_mask)
select = attention_mask.reshape(-1) == 1
print('----------select------')
print(select)
outs = outs[select]
labels = labels[select]
return outs, labels
reshape_and_remove_pad(torch.randn(2, 3, 8), torch.ones(2, 3),
torch.ones(2, 3))

获取正确数量和总数
#获取正确数量和总数
def get_correct_and_total_count(labels, outs):
#[b*lens, 8] -> [b*lens]
outs = outs.argmax(dim=1)
correct = (outs == labels).sum().item()
total = len(labels)
#计算除了0以外元素的正确率,因为0太多了,包括的话,正确率很容易虚高
select = labels != 0
outs = outs[select]
labels = labels[select]
correct_content = (outs == labels).sum().item()
total_content = len(labels)
return correct, total, correct_content, total_content
get_correct_and_total_count(torch.ones(16), torch.randn(16, 8))
# (5, 16, 5, 16)
训练
from transformers import AdamW
#训练
def train(epochs):
lr = 2e-5 if model.tuneing else 5e-4
#训练
optimizer = AdamW(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(epochs):
for step, (inputs, labels) in enumerate(loader):
if torch.cuda.is_available():
inputs = inputs.to(device)
labels = labels.to(device)
#模型计算
#[b, lens] -> [b, lens, 8]
outs = model(inputs)
#对outs和label变形,并且移除pad
#outs -> [b, lens, 8] -> [c, 8]
#labels -> [b, lens] -> [c]
outs, labels = reshape_and_remove_pad(outs, labels,
inputs['attention_mask'])
#梯度下降
loss = criterion(outs, labels)
loss = loss.to(device)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if step % 50 == 0:
counts = get_correct_and_total_count(labels, outs)
accuracy = counts[0] / counts[1]
accuracy_content = counts[2] / counts[3]
print(epoch, step, loss.item(), accuracy, accuracy_content)
torch.save(model, './model/命名实体识别_中文.model')
model.fine_tuneing(False)
print(sum(p.numel() for p in model.parameters()) / 10000)
train(1)
如果遇到这样的报错,不需要重新再跑一边,model已经创建好了,只需要新建一个单元格
再保存以下就可以了,像下图这样

测试
#测试
def test():
model_load = torch.load('./models/命名实体识别_中文.model')
model_load.eval()
loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'),
batch_size=4,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
correct = 0
total = 0
correct_content = 0
total_content = 0
for step, (inputs, labels) in enumerate(loader_test):
if torch.cuda.is_available():
inputs = inputs.to(device)
labels = labels.to(device)
if step == 5:
break
print(step)
with torch.no_grad():
#[b, lens] -> [b, lens, 8] -> [b, lens]
outs = model_load(inputs)
#对outs和label变形,并且移除pad
#outs -> [b, lens, 8] -> [c, 8]
#labels -> [b, lens] -> [c]
outs, labels = reshape_and_remove_pad(outs, labels,
inputs['attention_mask'])
counts = get_correct_and_total_count(labels, outs)
correct += counts[0]
total += counts[1]
correct_content += counts[2]
total_content += counts[3]
print(correct / total, correct_content / total_content)
test()
预测
def predict():
model_load = torch.load('./models/命名实体识别_中文.model')
model_load.eval()
loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'),
batch_size=32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i, (inputs, labels) in enumerate(loader_test):
break
# 测试和预测的时候不需要更新梯度,with torch.no_grad就是说不用算梯度
with torch.no_grad():
#[b, lens] -> [b, lens, 8] -> [b, lens]
outs = model_load(inputs).argmax(dim=2)
for i in range(32):
#移除pad
select = inputs['attention_mask'][i] == 1
input_id = inputs['input_ids'][i, select]
out = outs[i, select]
label = labels[i, select]
#输出原句子
print(tokenizer.decode(input_id).replace(' ', ''))
#输出tag
for tag in [label, out]:
s = ''
for j in range(len(tag)):
if tag[j] == 0:
s += '·'
continue
s += tokenizer.decode(input_id[j])
s += str(tag[j].item())
print(s)
print('==========================')
predict()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号