动手学深度学习
2.预备知识
2.2. 数据预处理¶
2.2.1. 读取数据集¶
首先创建一个目录,然后在这个目录下创建一个house_tiny.csv文件,然后手动将数据集写到文件中
import os
os.makedirs(os.path.join('.','data'),exist_ok=True)
data_file = os.path.join('.','data','house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
要从创建的CSV文件中加载原始数据集,我们导入pandas包并调用read_csv函数。该数据集有四行三列。其中每行描述了房间数量(“NumRooms”)、巷子类型(“Alley”)和房屋价格(“Price”)
import pandas as pd
data = pd.read_csv(data_file)
print(data)
NumRooms Alley Price 0 NaN Pave 127500 1 2.0 NaN 106000 2 4.0 NaN 178100 3 NaN NaN 140000
2.2.2. 处理缺失值¶
通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
inputs,outputs = data.iloc[:,0:2],data.iloc[:2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
NumRooms Alley 0 3.0 Pave 1 2.0 NaN 2 4.0 NaN 3 3.0 NaN
对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
(20条消息) pandas.get_dummies 的用法_魔术师_的博客-CSDN博客_pandas.get_dummies
inputs = pd.get_dummies(inputs,dummy_na=True)
print(inputs)
NumRooms Alley_Pave Alley_nan 0 3.0 1 0 1 2.0 0 1 2 4.0 0 1 3 3.0 0 1
2.2.3. 转换为张量格式¶
n维数组,也称为张量(tensor)
import torch
X,y = torch.tensor(inputs.values),torch.tensor(outputs.values)
X,y
(tensor([[3., 1., 0.],
[2., 0., 1.],
[4., 0., 1.],
[3., 0., 1.]], dtype=torch.float64),
tensor([127500, 106000, 178100, 140000]))
先将list转换为numpy再转化为tensor,速度最快
list转Tensor不同方式的速度对比_喝粥也会胖的唐僧的博客-CSDN博客_list转tensor
2.2.5. 练习¶
1.删除缺失值最多的列。
# 第一个版本使用max
def dropMaxNullCol(data):
s = dict(data.isnull().sum())
values = s.values()
max_col = max(values)
for item in s:
if s[item] == max_col:
data= data.drop(item,axis=1)
return data
# 第二个版本使用idxmax
def dropMaxNullCol(data):
s = data.isnull().sum()
max_col = s.idxmax() # argmax()
data = data.drop(max_col,axis=1)
return data
# 第三个版本使用argmax
def dropMaxNullCol(data):
s = data.isnull().sum()
max_col_index = s.argmax()
tmp_data = data.iloc[:,max_col_index:max_col_index+1]
data = data.drop(tmp_data.columns[0],axis=1)
return data
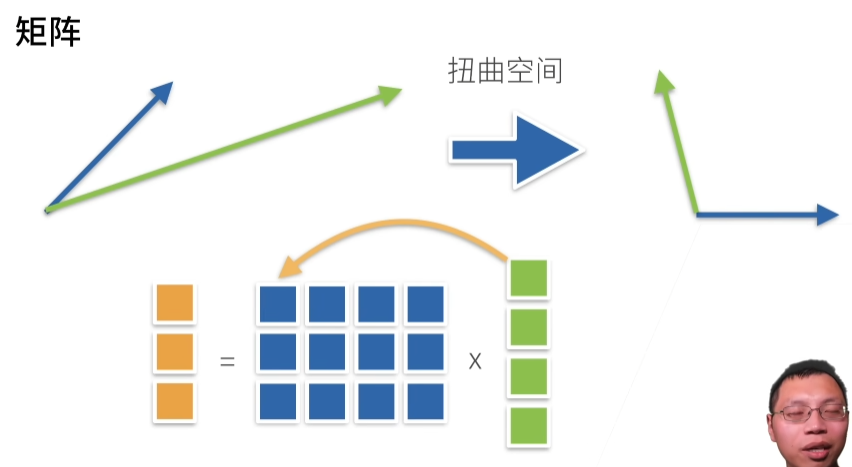
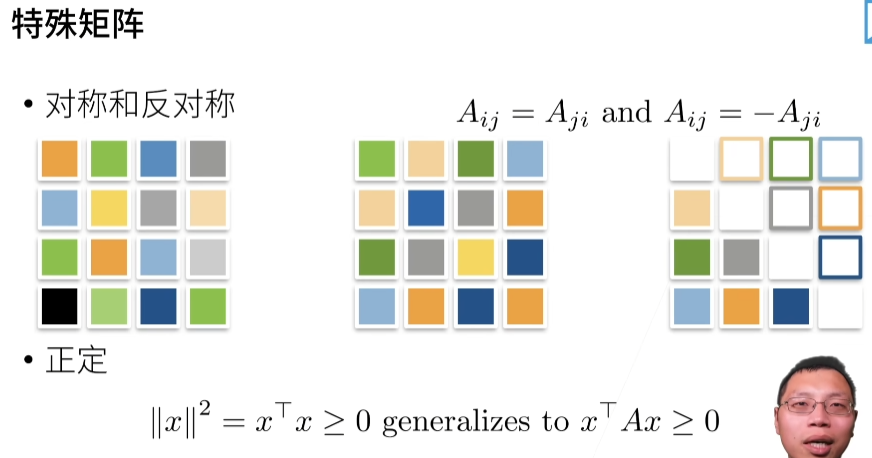
2.3. 线性代数¶
2.3.1. 标量¶
标量由只有一个元素的张量表示。 在下面的代码中,我们实例化两个标量,并执行一些熟悉的算术运算,即加法、乘法、除法和指数。
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
print(x+y,x*y,x/y,x**y)
tensor(5.) tensor(6.) tensor(1.5000) tensor(9.)

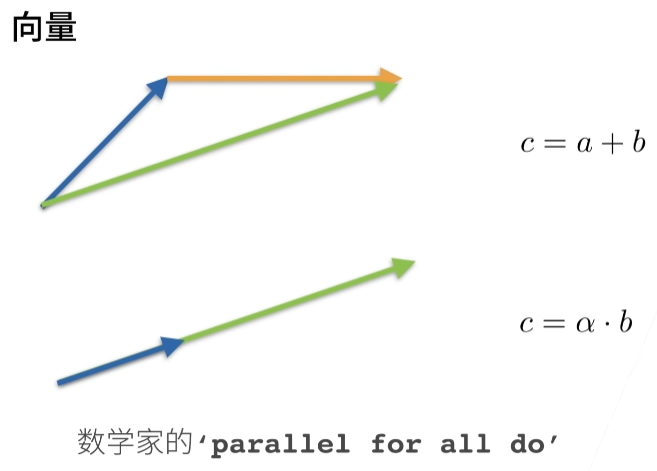
2.3.2. 向量¶
可以将向量视为标量值组成的列表。
我们通过一维张量处理向量。一般来说,张量可以具有任意长度。
x = torch.arange(4)
x
tensor([0, 1, 2, 3])

2.3.6. 降维¶
求和
A = np.arange(6).reshape(2,3)
print(A)
#[[0 1 2]
# [3 4 5]]
print(A.shape) # (2, 3)
print(A.sum()) # 15
print(A.sum(axis=0)) # [3 5 7]
print(A.sum(axis=1)) # [ 3 12]
sum(aixs=0)可以理解把轴为0的相加,何为轴为0,可以理解为
这里b = np.arange(20).reshape(1,4,5),b是一个1×4×5的数组,如下所示
[
[
[ 0 1 2 3 4]
[5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
]
]
sum(aixs=0)就是求和最外面那一层所含的数组的值,最外面只包含一个二维数组
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
所以结果就是
[
[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
]
sum(aixs=1)就是求第二层括号里面所含的数组的值,这里包括了4个1维数组
[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
所以结果是
[[30 34 38 42 46]]
sum(aixs=1)就是求地面的括号里面所含的数值
0 +1+2+3 +4 = 10
5 +6+7+8+9 = 35
......
所以结果
[[10 35 60 85]]
综上计算发现,按照axis计算就降维,原来是有3对括号,计算后只有2对
均值
# 第一种
print(A.mean())
# 第二种
A = torch.Tensor(A)
print(A.numel()) # 使用numel()需要将A转换为tensor
print(A.sum() / A.numel())
2.3.6.1. 非降维求和¶
但是,有时在调用函数来计算总和或均值时保持轴数不变会很有用。
c = np.arange(20).reshape(4,5)
print(c.sum(axis=0)) # [30 34 38 42 46]
print(c.sum(axis=0,keepdims=True)) # [[30 34 38 42 46]]
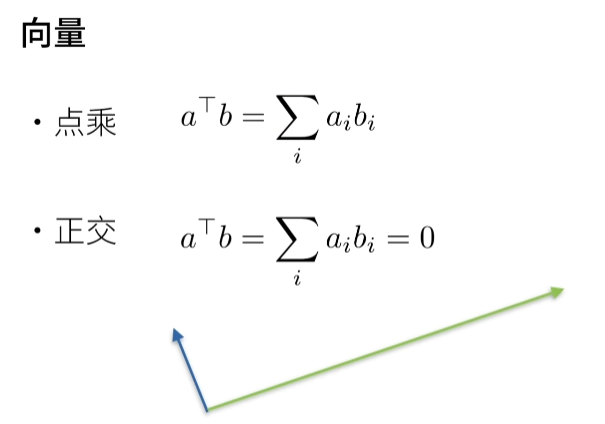
2.3.7. 点积(Dot Product)¶
要求x和y是向量
torch.dot(x,y)
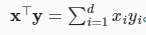
2.3.8. 矩阵-向量积¶
torch.mv(A,x)
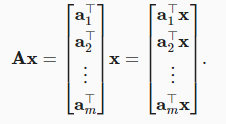
2.3.9. 矩阵-矩阵乘法¶
torch.mm(A,B)
扭曲空间
2.3.10. 范数¶
||x||, 这个数学符号是范数。

2.3.13. 练习¶
1.证明一个矩阵\(A\)的转置的转置是\(A\),即\((A^{T})^{T}=A\)
A = np.arange(4).reshape(2,2)
print(A)
# [[0 1]
# [2 3]]
b = A.T
print(b)
# [[0 2]
# [1 3]]
c = b.T
print(c)
# [[0 1]
# [2 3]]
print(A==c)
# [[ True True]
# [ True True]]
2.给出两个矩阵\(A\)和\(B\),证明“它们转置的和”等于“它们和的转置”,即\(A^{T}\ + \ B^{T} \ = \ (A\ + \ B)^{T}\)
A = np.arange(4).reshape(2,2)
B = np.arange(4).reshape(2,2)
print(A)
# [[0 1]
# [2 3]]
print(B)
# [[0 1]
# [2 3]]
a = A.T + B.T
print(a)
# [[0 4]
# [2 6]]
b = (A+B).T
print(b)
# [[0 4]
# [2 6]]
3.我们在本节中定义了形状(2,3,4)的张量X。len(X)的输出结果是什么?
b = np.arange(20).reshape(1,4,5)
print(b) # 1
4.对于任意形状的张量X,len(X)是否总是对应于X特定轴的长度?这个轴是什么?
c = np.arange(4).reshape(4,1)
d= np.arange(4).reshape(1,4)
e = np.arange(20).reshape(10,2,1)
print(len(c),len(d),len(e)) # 4 1 10 第0轴
5.运行A/A.sum(axis=1),看看会发生什么。你能分析原因吗?
A = torch.tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
print(A.sum(axis=1))
# tensor([ 6, 22, 38, 54, 70])
# 除就相当于乘以倒数,矩阵的乘法要求,满足即可,A是5×4,[1,2,3,4]是4×1即使是除,也是4×1,所以这里可以运算
print(A / torch.tensor([1,2,3,4]))
# tensor([[ 0.0000, 0.5000, 0.6667, 0.7500],
# [ 4.0000, 2.5000, 2.0000, 1.7500],
# [ 8.0000, 4.5000, 3.3333, 2.7500],
# [12.0000, 6.5000, 4.6667, 3.7500],
# [16.0000, 8.5000, 6.0000, 4.7500]])
# A是5×4,A.sum(axis=1)是5×1,不符合要求,所以报错
print(A/A.sum(axis=1))
# RuntimeError: The size of tensor a (4) must match the size of tensor b (5) at non-singleton dimension 1
6.考虑一个具有形状(2,3,4)的张量,在轴0、1、2上的求和输出是什么形状?
参考上面2.3.6.降维
2.4. 微积分¶
2.4.6. 练习
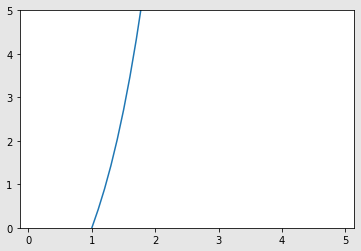
1.绘制函数\(y=f(x)=x^{3}-\frac{1}{x}\)和其在\(x=1\)处切线的图像。
实现函数
def f1(x):
h = 1e-4
return x**3-(1/x)
实现导数计算
def diff(f,x):
h = 1e-4
t = (f(x+h) - f(x-h))/ (2*h)
return t
diff(f1,1) # 4.000000019999117
绘制函数
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0,5.0,0.1)
y = f1(x)
plt.plot(x,y)
plt.ylim(0.0,5.0)
plt.show()
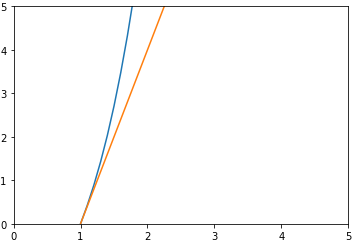
求斜率k和b
def qx(x,y):
# 算斜率
k = diff(f,x)
y = f1(x)
b = y - k*x
return k,b
生成切线
def f2(x,k,b):
return k * x +b
绘制函数和切线图
k,b = qx(1,f1)
x = np.arange(0,5.0,0.1)
# 切线
y2 = f2(x,k,b)
# f(x)
y1 = f1(x)
plt.plot(x,y1)
plt.plot(x,y2)
plt.xlim(0,5.)
plt.ylim(0,5)
plt.show()
2.求函数$f(x)=3x_{1}^{2}\ + \ 5e{x{2}} $在(1,1)的梯度。
定义偏导数函数
def numerical_gradient(f,x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 -fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad
定义函数
import math
def f3(x):
return 3*x[0]**2+5*(math.exp(x[1]**2))
计算
x = np.array([1,1])
numerical_gradient(f3,x)
# array([15000, 42957])
2.5. 自动微分¶
假设我们想对函数\(y=2x^{T}x\)关于列向量x求导。 首先,我们创建变量x并为其分配一个初始值。
import torch
x = torch.arange(4.0)
x
# tensor([0., 1., 2., 3.])
在我们计算y关于x的梯度之前,我们需要一个地方来存储梯度。 重要的是,我们不会在每次对一个参数求导时都分配新的内存。 因为我们经常会成千上万次地更新相同的参数,每次都分配新的内存可能很快就会将内存耗尽。 注意,一个标量函数关于向量x的梯度是向量,并且与x具有相同的形状。
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None
现在让我们计算y。
y = 2 * torch.dot(x, x)
y
# 28
调用反向传播函数来自动计算y关于x每个分量的梯度,并打印这些梯度。
y.backward()
x.grad
# tensor([ 0., 4., 8., 12.])
现在让我们计算x的另一个函数。
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
# tensor([1., 1., 1., 1.]) 在计算图中,这里用的是加法,所以梯度为1
2.5.2. 非标量变量的反向传播¶
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
# tensor([0., 2., 4., 6.]) 可以根据计算图来求这个
2.5.3. 分离计算¶
假设我现在有个函数y,y=x*x。有个函数z,z=x*y,我想求z关于x的偏导数,而不把y带进去了,因为y是关于x的函数,这时候,我需要把y分离出来,相当于把y当做一个常数。而不是z=x*x*x,然后对x求偏导
x = torch.arange(4.0) # tensor([0., 1., 2., 3.])
x.requires_grad_(True) # 这里不写,后面会报错
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
# 把u当做常数,反向传播后得到的梯度是u,z=ux,z关于x的导数不就是u吗
x.grad
# tensor([0., 1., 4., 9.])
接下来就可以计算y的导数了
x.grad.zero_()
y.sum().backward()
x.grad == 2 * x
x.grad # tensor([0., 2., 4., 6.])
这里如果你y没有使用sum(),而是直接y.backward()会报错,调用backward()要求前面的输出是scalar outputs(标量输出)。
一个向量是不进行backward操作的,而sum()后,由于梯度为1,所以对结果不产生影响。反向传播算法一定要是一个标量才能进行计算。
loss.sum().backward()中对于sum()的理解 - 知乎 (zhihu.com)
2.5.6. 练习¶
1.在控制流的例子中,我们计算d关于a的导数,如果我们将变量a更改为随机向量或矩阵,会发生什么?
会报错,调用反向传播时,前面的值必须是scalar outputs
def f(a):
b = a * 2
print(b.norm()) # tensor(0.4766, grad_fn=<CopyBackwards>)
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
print(a) # tensor(1.0685, requires_grad=True)
d = f(a)
d.backward()
a = torch.arange(4.0,requires_grad=True)
d = f(a)
d.backward()
# RuntimeError: grad can be implicitly created only for scalar outputs
尝试
对a进行计算后,没想到还是会报错
a = torch.arange(4.0,requires_grad=True)
a.sum()
d = f(a)
d.backward()
# RuntimeError: grad can be implicitly created only for scalar outputs
对d进行计算后,不报错了
a = torch.arange(4.0,requires_grad=True)
d = f(a)
d.sum().backward()
a.gard # tensor([512., 512., 512., 512.])
范数:一个向量的范数告诉我们一个向量有多大。 这里考虑的大小(size)概念不涉及维度,而是分量的大小。
2.使f(x)=sin(x),绘制f(x)和\(\frac{df(x)}{dx}\)的图像,其中后者不使用f′(x)=cos(x)。
import matplotlib.pyplot as plt
x = torch.arange(0,10,0.1)
x.requires_grad_(True)
y = torch.sin(x)
plt.plot(x.detach(),y.detach(),label='sin(x)')
y.sum().backward()
plt.plot(x.detach(),x.grad,label='x.grad')
plt.legend(loc='upper center')
plt.show()
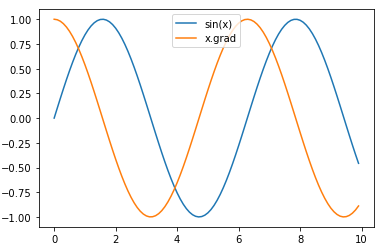
这里不能直接使用plt.plot(x,y) 会报错
RuntimeError: Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
2.6. 概率¶
2.6.1. 基本概率论¶
导包
%matplotlib inline
import torch
from torch.distributions import multinomial
from d2l import torch as d2l
从6个样本中随机抽一个
fair_probs = torch.ones([6]) / 6
multinomial.Multinomial(1, fair_probs).sample()
# tensor([0., 1., 0., 0., 0., 0.]) 1表示抽中
抽10次
multinomial.Multinomial(10, fair_probs).sample()
# tensor([2., 1., 3., 1., 1., 2.]) 抽中的次数分布
抽1000次
# 将结果存储为32位浮点数以进行除法
counts = multinomial.Multinomial(1000, fair_probs).sample()
counts / 1000 # 相对频率作为估计值
# tensor([0.1580, 0.1810, 0.1540, 0.1520, 0.1580, 0.1970]) 概率的分布
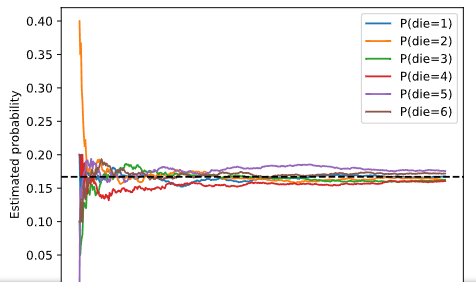
进行500组实验,每一组里面抽10次
counts = multinomial.Multinomial(10, fair_probs).sample((500,))
print(counts.shape) # torch.Size([500, 6])
print(counts)

cum_counts = counts.cumsum(dim=0)
print(cum_counts) # 最后一行加起来刚好等于5000,第一行加起来干好等于10
# 这个矩阵表示每一组抽到的分布(加上前面的分布)

estimates = cum_counts / cum_counts.sum(dim=1, keepdims=True)
print(cum_counts.sum(dim=1, keepdims=True))

d2l.set_figsize((6, 4.5))
for i in range(6):
d2l.plt.plot(estimates[:, i].numpy(), # i是每一列
label=("P(die=" + str(i + 1) + ")"))
d2l.plt.axhline(y=0.167, color='black', linestyle='dashed')
d2l.plt.gca().set_xlabel('Groups of experiments')
d2l.plt.gca().set_ylabel('Estimated probability')
d2l.plt.legend();
2.6.1.1. 概率论公理¶
在处理骰子掷出时,我们将集合S={1,2,3,4,5,6} 称为样本空间(sample space)或结果空间(outcome space),其中每个元素都是结果(outcome)。事件(event)是一组给定样本空间的随机结果。如果一个结果属于这个随机结果,可以说事件发生了。
3.线性神经网络
08 线性回归 + 基础优化算法【动手学深度学习v2】_哔哩哔哩_bilibili
3.1. 线性回归¶
回归经常用来表示输入和输出之间的关系。
线性模型

3.1.3. 正态分布与平方损失¶
正态分布概率密度函数如下:
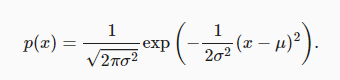
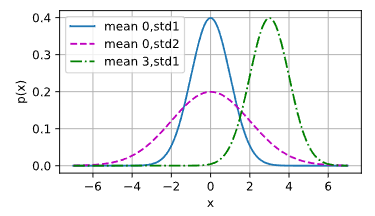
代码实现
%matplotlib inline
import math
import time
import numpy as np
import torch
from d2l import torch as d2l
def normal(x,mu,sigma):
p = (1/math.sqrt(2*math.pi*sigma**2))
return p*np.exp((-0.5/sigma**2)*((x-mu)**2))
绘制图形
x = np.arange(-7,7,0.01)
# 均值和标准差对
params = [(0,1),(0,2),(3,1)]
d2l.plot(x,[normal(x,mu,sigma) for mu,sigma in params], # 这个列表生成式,可以理解为生成多个y
xlabel='x',
ylabel='p(x)',figsize=(4.5,2.5),
legend=[f'mean {mu},std{sigma}' for mu,sigma in params])
3.2. 线性回归的从零开始实现¶
3.2.1. 生成数据集¶
导包
%matplotlib inline
import random
import torch
from d2l import torch as d2l
我们生成一个包含1000个样本的数据集, 每个样本包含从标准正态分布中采样的2个特征。 我们的合成数据集是一个矩阵\(X ∈ R^{1000×2}\)。使用线性模型\(W = [2,-3.4]^{T}\),b = 4.2和噪声项ε生成数据集及其标签:
# 这里的num_examples设为5方便理解
def synthetic_data(w,b,num_examples):
# 生成 y = xw + b + 噪声
X = torch.normal(0,1,(num_examples,len(w)))
y = torch.matmul(X,w) + b
print(y)
# tensor([ 5.6970, -2.7800, 5.9361, 0.1433, -0.4529])
y += torch.normal(0,0.01,y.shape)
return X,y.reshape((-1,1))
true_w = torch.tensor([2,-3.4])
true_b = 4.2
features,labels = synthetic_data(true_w,true_b,5)

【Pytorch】torch.normal()使用 - 知乎 (zhihu.com)
torch.normal(means, std, out=None)
参数:
- means (Tensor) – 均值
- std (Tensor) – 标准差
- out (Tensor) – 可选的输出张量
(20条消息) Python的reshape(-1,1)_lxlong89940101的博客-CSDN博客_reshape(-1,1)
reshape(-1,1)
转换为1列
reshape(1,-1)
转换为1行
torch.matmul()
多维矩阵乘法
features中的每一行都包含一个二维数据样本, labels中的每一行都包含一维标签值(一个标量)。
print('features:',features[0],'\nlabel:',labels[0])
features: tensor([0.0639, 0.3696])
label: tensor([3.0768])
绘制散点图
d2l.set_figsize()
d2l.plt.scatter(features[:,1].detach().numpy(),labels.detach().numpy(),1)
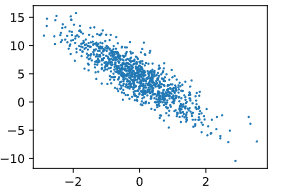
定义一个data_iter函数, 该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签。
3.2.2. 读取数据集¶
def data_iter(batch_size,features,labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0,num_examples,batch_size):
batch_indices = torch.tensor(
indices[i:min(i + batch_size,num_examples)] # min作用是防止越界
)
yield features[batch_indices],labels[batch_indices]
indices是从0到len(features)长度的list,然后经过打乱,for循环中,每次取batch_size大小的数据,这些数据是之前打乱的list的值
batch_size = 10
# 这里data_iter只有batch_size为10的数据,想要更多需要多次调用生成器
for X,y in data_iter(batch_size,features,labels):
print(X,'\n',y)
break

3.2.3. 初始化模型参数¶
定义初始化模型参数
w = torch.normal(0,0.01,size=(2,1),requires_grad=True)
b = torch.zeros(1,requires_grad=True)
3.2.4. 定义模型¶
定义模型,然后用这个模型去训练,找出最优w和b
def linreg(X,w,b):
# 线性回归模型
return torch.matmul(X,w) + b
3.2.5. 定义损失函数¶
def squared_loss(y_hat,y):
return 0.5*(y-hat - y.reshape(y_hat.shape))**2
3.2.6. 定义优化算法¶
def sgd(params,lr,batch_size):
# 小批量随机梯度下降
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
3.2.7. 训练¶
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
# 更新w和b
for X,y in data_iter(batch_size,features,labels):
l = loss(net(X,w,b),y)
l.sum().backward()
# sgd里面是要求偏导数,这个导数是通过前面的反向传播求出来的
sgd([w,b],lr,batch_size)
# 把更新后的w和b去算loss值
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
w,b
# true_w = torch.tensor([2,-3.4])
# true_b = 4.2
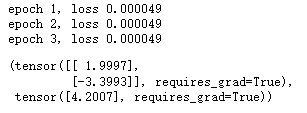
流程
自己指定w和b然后使用一个线性模型生成训练数据,然后定义损失函数,建立模型,最后开始训练(这时的w和b是随机数据,要考自己找出来),训练的目的就是找一个w和b和最初的w和b很相近,也可以简单理解为,我生成数据时,知道x,y,w,b。但是训练时我只知道x和y,需要自己去找w和b
3.3. 线性回归的简洁实现¶
3.3.1. 生成数据集¶
通过使用深度学习框架来简洁地实现线性回归模型生成数据集
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2,-3.4])
true_b = 4.2
features,labels = d2l.synthetic_data(true_w,true_b,1000)
3.3.2. 读取数据集¶
def load_array(data_arrays,batch_size,is_train=True):
# 构造一个pytorch数据迭代器
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset,batch_size,shuffle=is_train)
batch_size = 10
data_iter = load_array((features,labels),batch_size)
next(iter(data_iter))
*表示该参数是一个元祖,** 表示该参数是一个字典。

3.3.3. 定义模型¶
使用框架的预定义好的层
from torch import nn
net = nn.Sequential(nn.Linear(2,1))
3.3.4. 初始化模型参数¶
net[0].weight.data.normal_(0,0.01) # 均值为0,方差为0.01
net[0].bias.data.fill_(0)
tensor([0.])
3.3.5. 定义损失函数¶
计算均方误差使用的是MSELoss类,也称为L2平方范数
loss = nn.MSELoss()
3.3.6. 定义优化算法¶
实例化SGD实例
trainer = torch.optim.SGD(net.parameters(),lr=0.03)
3.3.7. 训练¶
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
# step()是使用form torch import nn之后,使用nn来sequentail来添加网络后才会用到step()更新,具体的区别可以认真去看线性回归从零开始和线性回归简洁实现
trainer.step() # 模型的更新
l = loss(net(features),labels)
print(f'epoch {epoch + 1},loss {l:f}')
问题
1.为啥使用平方损失而不是绝对差值呢?
答:简单,它们的差别不大
2.损失为什么要求平均?
答:不管样本有多大,使得我求得的梯度都差不多
3.线性回归损失函数是不是通常都是mse?
答:是的
4.batchsize是否会最终影响模型结果? batchsize过小是否可能导致最终累计的梯度计算不准确?
答:小点好些
5.针对batchsize大小的数据集进行网络训练的时候,网络中每个参数更新时的减去的梯度是batchsize中每个样本对应参数梯度求和后取得平均值吗?
答:是的
6.随机梯度下降中的"随机”是指的批量大小是随机的吗?
答:不是,而是样本的随机
7.在深度学习上,设置损失函数的时候,需要考虑正则吗?
答:需要
8.学习率怎么除N呀,设置学习率的时候吗?
答:是的
9.请问detach()是什么作用?
答:如果我要把数据传到numpy的话,我就不需要算梯度,需要从梯度计算里面拿出来
10.这样的data-iter写法,每次都把所有输入load进去,如果数据多的话,最后内存会爆掉吧?有什么好的办法吗?
答:是的,内存会爆掉
11.这里的Indices为什么要转化成tensor,直接用列表不行吗?
答:不行
12.每次都是随机取出一部分,怎么保证最后所有数据都被拿过了?
答:首先先把0到1000数字打乱,然后顺序读取可以确保数据都拿过了
13.这里使用生成器生成数据有什么优势呢相比return?
答:return是把所有数据都生成完,生成器是你要用我就生成,更节约内存
14.如果样本大小不是批量数的整数倍,那需要随机剔除多余的样本吗?
答:不需要
15.本质上我们为什么要用SGD,是因为大部分的实际loss太复杂,推导不出导数为0的解么?只能逐个batch去逼近?
答:是的
16.请问w为什么要随机初始化,不能用同样的值呢?
答:应该不能用同样的值吧?否则w向量的每个分量的梯度也都一样,不管怎么更新,w向量里每个值都一样。吴恩达说的是必须随机初始化,否则每层网络仅等价于一个神经元。
17.外层for循环中最后一行l=loss(net(),labels)就是为 了print吗?这里梯度要不要清零呢?会不会有影响?
答:是的,这里梯度不需要清零,因为没有调用backward
18.每个batch计算的时候,为什么需要把剃度先清零呀?
答:因为pytorch不帮你清零,如果不清零会在上一个梯度上累加
3.4. softmax回归¶
09 Softmax 回归 + 损失函数 + 图片分类数据集【动手学深度学习v2】_哔哩哔哩_bilibili
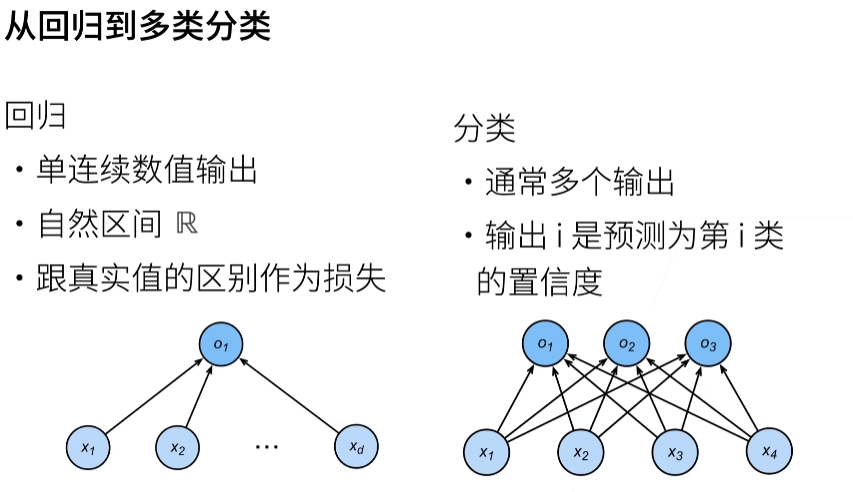
从回归到多类分类-均方损失
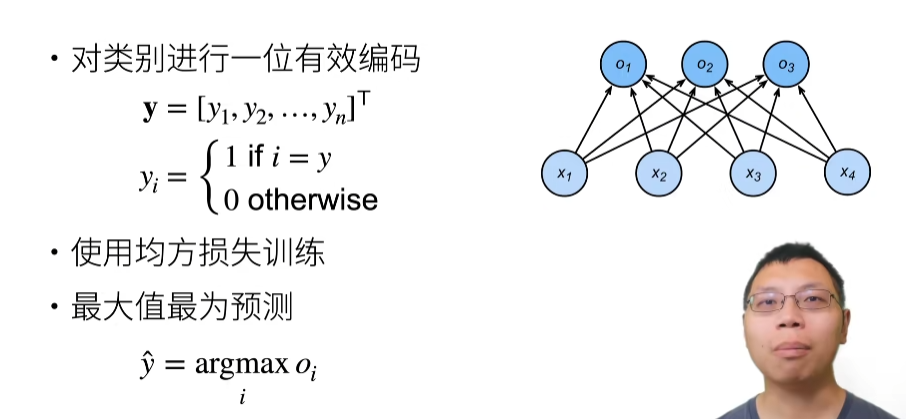
从回归到多类分类一无校验比例
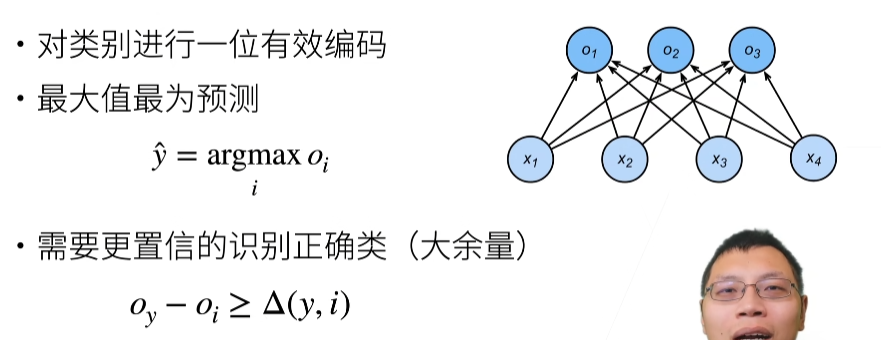
从回归到多类分类-校验比例
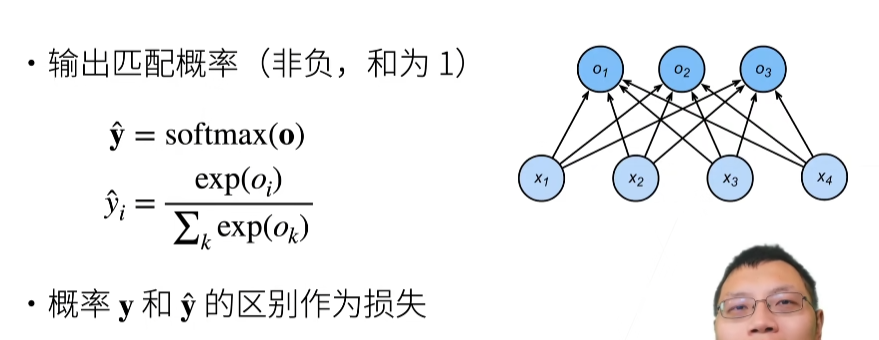
Softmax和交叉熵损失

总结
似然函数就是最可能的分布函数
损失函数
- 绝对值损失
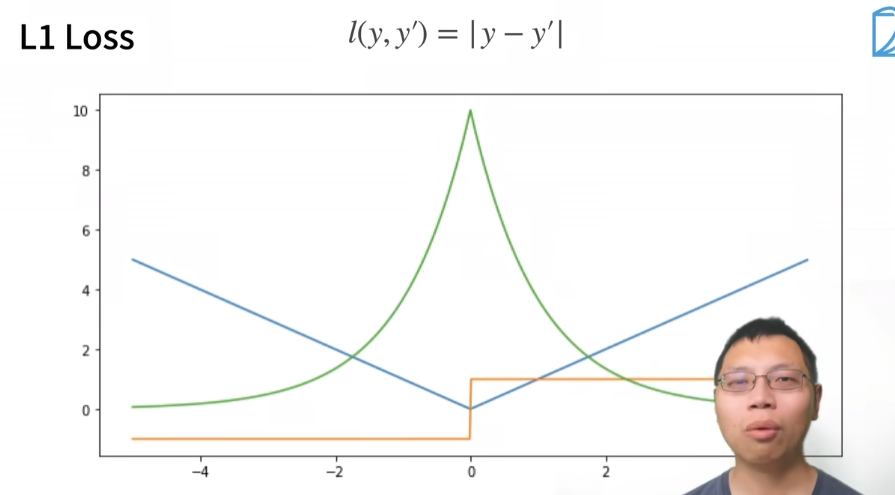
这个“最有可能”,就是概率,就是似然函数的值,也是对应了绿色曲线的顶点,从图可以看到,在y=0的时候,当某个参数使得y`能取值为0,那么这个参数是最有可能接近样本参数的。绿色的线似然函数代表了y在哪儿取值时,这个y对应的参数概率是最大的,按我的理解:y固定,y`变化,蓝色的线代表了y`偏离y的程度。
3.5. 图像分类数据集(Fashion-MNIST)
FashionMNIST — Torchvision main documentation (pytorch.org)
3.5.1. 获取数据集¶
MNIST数据集是图像分类中广泛使用的数据集之一,但作为基准数据集过于简单。我们将使用类似但更复杂的Fashion-MNIST数据集
导包
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()
通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(
root='D:/programing/JupyterWork/动手学深度学习/data',
train=True,
transform=trans,
download=True
)
mnist_test = torchvision.datasets.FashionMNIST(
root='D:/programing/JupyterWork/动手学深度学习/data',
train=False,
transform=trans,
download=True)
len(mnist_train),len(mnist_test)
(60000, 10000)
mnist_train[0][0].shape # torch.Size([1, 28, 28]) 1是通道数
mnist_train[0][0] # feature
mnist_train[0][1] # label
两个可视化数据集的函数
def get_fashion_mnist_labels(labels):
# 返回fashion-mnist数据集的文本标签
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def show_images(imgs,num_rows,num_cols,titles=None,scale=1.5):
figsize = (num_cols * scale,num_rows * scale) # 调整图片的尺寸
_,axes = d2l.plt.subplots(num_rows,num_cols,figsize=figsize)
axes = axes.flatten()
for i,(ax,img) in enumerate(zip(axes,imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy()) # 如果是tensor类型需要进行转换格式
else:
# PIL图片
ax.imshow(img)
- axes = axes.flatten()
在用plt.subplots画多个子图中,axes = axes.flatten()将ax由n*m的Axes组展平成1*nm的Axes组
(20条消息) plt.subplots中的ax = ax.flatten()_Mr.Jcak的博客-CSDN博客_ax.flatten()
- subplots
fig, ax = plt.subplots(2,2)中的ax就是存放四个子图的地方
Python:matplotlib subplots 用法 – 羔羊的实验纪录簿 (yia.app)
- enumerate
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
Python enumerate() 函数 | 菜鸟教程 (runoob.com)
- zip
zip 将列表,元祖或其他序列的元素配对,新建一个元祖构成的列表
(20条消息) Python中enumerate,zip函数的结合使用_weixin_43408110的博客-CSDN博客_enumerate和zip一起用
- for i,(ax,img) in enumerate(zip(axes,imgs))中的(ax,img)
可以理解ax就是axes,img就是img
几个样本的图像及其相应的标签
X, y = next(iter(data.DataLoader(mnist_train,batch_size=18))) # batch_size=18表示挑选18张图片
# X是图片
# y是label
print(len(X)) # 18
print(len(y)) # 18
print(y) # tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5, 0, 9, 5, 5, 7, 9, 1, 0])
show_images(X.reshape(18,28,28),2,9,titles=get_fashion_mnist_labels(y)) # 不reshape会报错
y中0-9对应不同的类别衣服,然后根据这个数字传给get_fashion_mnist_labels生成相应的标签
iter() 函数用来生成迭代器。
Python iter() 函数 | 菜鸟教程 (runoob.com)

读取一小批量数据,大小为batch_ size
batch_size = 256
def get_dataloader_workers():
# 使用4个进程来读取的数据
return 4
train_iter = data.DataLoader(mnist_train,batch_size,shuffle=True,num_workers=get_dataloader_workers())
timer = d2l.Timer()
for X,y in train_iter:
continue
f'{timer.stop():.2f}sec'
'4.07sec'
定义load_data_fashion_mnist函数
def load_data_fashion_mnist(batch_size,resize=None):
# 下载fashion-mnist数据集,然后将其加载到内存中
trans = [transforms.ToTensor()] # 定义要转换的格式列表
if resize:
trans.insert(0,transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root='D:/programing/JupyterWork/动手学深度学习/data',
train=True,
transform=trans,
download=True
)
mnist_test = torchvision.datasets.FashionMNIST(
root='D:/programing/JupyterWork/动手学深度学习/data',
train=False,
transform=trans,
download=True
)
return (
data.DataLoader(mnist_train,batch_size,shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test,batch_size,shuffle=True,
num_workers=get_dataloader_workers()))
train_iter = load_data_fashion_mnist(4)
timer = d2l.Timer()
for X,y in train_iter[0]: # train_iter[0]表示trian数据
continue
f'{timer.stop():.2f}sec'
'4.62sec'
3.6. softmax回归的从零开始实现¶
就像我们从零开始实现线性回归一样,你应该知道实现softmax的细节
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
将展平每个图像,将它们视为长度为784的向量。因为我们的数据集有10个类别,所以网络输出维度为10
num_inputs = 784
num_outputs = 10
# 创建一个均值为0,方差为0.01分布的784×10的features,第一层的神经元有10个
W = torch.normal(0,0.01,size=(num_inputs,num_outputs),requires_grad=True)
print(W.shape) # torch.Size([784, 10])
# 创建一个bias,10维
b = torch.zeros(num_outputs,requires_grad=True)
print(b.shape) # torch.Size([10])
给定一个矩阵X,我们可以对所有元素求和
X = torch.tensor([[1.0,2.0,3.0],[4.0,5.0,6.0]])
X.sum(0,keepdim=True),X.sum(1,keepdim=True)
(tensor([[5., 7., 9.]]),
tensor([[ 6.],
[15.]]))
实现softmax
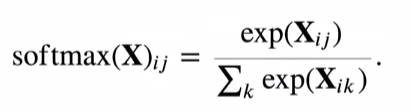
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1,keepdim=True)
return X_exp / partition
我们将每个元素变成一个非负数。此外,依据概率原理,每行总和为1
X = torch.normal(0,1,(2,5))
X_prob = softmax(X)
X_prob,X_prob.sum(1),X_prob.sum(1,keepdim=True)
(tensor([[0.1685, 0.0206, 0.1170, 0.4201, 0.2738],
[0.1834, 0.1536, 0.2192, 0.3798, 0.0640]]),
tensor([1.0000, 1.0000]),
tensor([[1.0000],
[1.0000]]))
实现softmax回归模型
def net(X):
return softmax(torch.matmul(X.reshape((-1,W.shape[0])),W) + b) # 返回属于每个类别的概率
X = torch.normal(0,1,(28,28))
print(X.shape) # torch.Size([28, 28])
X = X.reshape((-1,784)) # 1×784,1行784列
print(X.shape) # torch.Size([1, 784])
X:1×784
W:784×10
B: 10
创建一个数据y_ hat,其中包含2个样本在3个类别的预测概率,使用y作为y_ hat中概率的索引
y = torch.tensor([0,2])
y_hat = torch.tensor([[0.1,0.3,0.6],[0.3,0.2,0.5]])
y_hat[[0,1],y] # y_hat[[0,1],[0,2]] 0行0列是0.1,1行2列是0.5
tensor([0.1000, 0.5000])
查看链接的多个维度python通过fancy indexing把数组转换为one hot编码的numpy array - 腾讯云开发者社区-腾讯云 (tencent.com)
实现交叉熵损失函数
def cross_entropy(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)),y])
为什么用这种写法可以参考《深度学习入门》p91
- label是one-hot
return -torch.sum(t * np.log(y + 1e-7)) / batch_size
- label不是one-hot
return -np.sum(np.log(y[np.arange(batch_size),t]+1e-7)) / batch_size
将预测类别与真实y元素进行比较
def accuracy(y_hat,y):
# 计算预测正确的数量
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
accuracy(y_hat,y) / len(y) # 0.5
y_hat = torch.tensor([
[0.1,0.3,0.6],
[0.3,0.2,0.5]
])
y = torch.tensor([0,2])
# y_hat中第一行最大值是0.6,它的索引值是2,第二行中最大值是0.5,它的索引值是2,最后得到向量[2,2],而y是[0,2],只有y_hat中第二个元素和y中第二个元素相同,所以这里正确率是0.5
y_hat里面是每个类别的预测概率,经过argmax后取出最大值概率的索引值(整数且大于0),然后与标签y进行比较,计算相同的,然后除以总数就是正确率了。
我们可以评估在任意模型net的准确率
def evaluate_accuracy(net,data_iter):
# 计算在指定数据集上模型的精度
if isinstance(net,torch.nn.Module):
net.eval() # 将模型设置为评估模式,不设也没关系,一个习惯
metric = Accumulator(2) # 正确预测数,预测总数
i= 0
# 每次遍历是一个batch_size,10000个样本,batch_size是256,for循环执行40次
for X,y in data_iter:
i+=1
# 分别累加精度和个数
# https://www.bilibili.com/video/BV1K64y1Q7wu?p=4&vd_source=91219057315288b0881021e879825aa3&t=682.7
metric.add(accuracy(net(X),y),y.numel()) # y.numel()是个数
print(X.shape) # torch.Size([256, 1, 28, 28]) 256是batch_size,1是通道数
print(i) # 40 ,10000/256=40
print(metric[0],metric[1]) # 517.0 10000.0分别是精度的累加和样本总数
return metric[0] / metric[1]
- instance()函数
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
Python isinstance() 函数 | 菜鸟教程 (runoob.com)
- Accumulator(自己实现的)
迭代器
(20条消息) Python itertools accumulate函数详解_奋力翻身的咸鱼=_=的博客-CSDN博客_accumulate python
- numel()
返回数组中元素的个数
(20条消息) python中的numel()函数_codebrid的博客-CSDN博客_numel()
Accumulator实例中创建了2个变量,用于分别存储正确预测的数量和预测的总数量
class Accumulator:
# 在n个变量上累加
def __init__(self,n):
self.data = [0.0] * n
def add(self,*args):
self.data = [a + float(b) for a,b in zip(self.data,args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self,idx):
return self.data[idx]
- [0.0] * n

- [a + float(b) for a,b in zip(self.data,args)]

evaluate_accuracy(net,test_iter) # 0.0517
Softmax回归的训练
def train_epoch_ch3(net,train_iter,loss,updater):
if isinstance(net,torch.nn.Module):
net.train()
metric = Accumulator(3)
for X,y in train_iter:
y_hat = net(X)
l = loss(y_hat,y)
# 如果updater是pytorch里面的优化器的话
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad() # 梯度清零
l.backward() # 反向传播
updater.step() # 更新参数
metric.add(
float(l) * len(y),accuracy(y_hat,y), # ? 为什么要float乘len(y)
y.size().numel()) # ? 为什么不直接使用y.numel()
else:
l.sum().backward()
updater(X.shape[0]) # 更新batch_size
metric.add(float(l.sum()),accuracy(y_hat,y),y.numel())
return metric[0]/metric[2],metric[1]/metric[2] # 返回损失和精度
- l.sum().backward()
loss.sum().backward()中对于sum()的理解 - 知乎 (zhihu.com)
y2 = torch.tensor([1,2,3])
print(y2.size()) # torch.Size([3])
print(y2.size().numel()) # 3
定义一个在动画中绘制数据的实用程序类
class Animator:
"""在动画中绘制数据。"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes,]
self.config_axes = lambda: d2l.set_axes(self.axes[
0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
训练函数
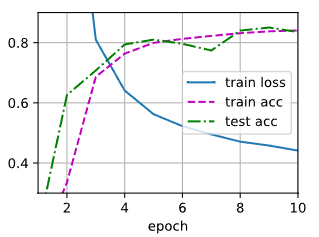
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型(定义见第3章)。"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
- assert
assert(断言),判断assert后的表达式是否为true,若为true就继续执行下面的代码,若为false,则触发异常
python assert的作用 - 简书 (jianshu.com)
小批量随机梯度下降来优化模型的损失函数
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
训练模型10个迭代周期
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
- epoch
深度学习中 number of training epochs 中的 epoch到底指什么? - 知乎 (zhihu.com)
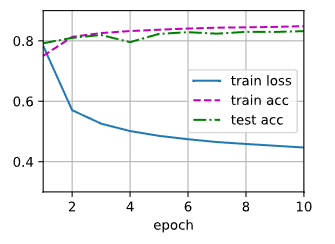
对象图像进行分类预测
def predict_ch3(net, test_iter, n=6):
"""预测标签(定义见第3章)。"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y) # label值
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1)) # 输出值
titles = [true + '\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)
3.7. softmax回归的简洁实现¶
通过深度学习框架的高级API能够使实现softmax回归变得更加容易
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
Softmax回归的输出层是一个全连接层
# 从零实现的net,这里是参考用,不要参与到简洁实现中
def net(X):
return softmax(torch.matmul(X.reshape((-1,W.shape[0])),W) + b)
# PyTorch不会隐式地调整输入的形状
# 因此,我们定义了展平层(flatten)在线性层前调整网络输入的形状
net = nn.Sequential(nn.Flatten(),nn.Linear(784,10))
# 赋初值,固定写法,先定义sequential,再定义init_weights函数,再net.apply
def init_weights(m):
if type(m) == nn.Linear: # 对linear子层进行初始化参数
print(m.weight.shape) # [10,784]
nn.init.normal_(m.weight,std=0.01) # 均值为0,方差为0.01
net.apply(init_weights)
# 为什么init_weights里面要对linear进行初始化值
# 因为最初始的net(X)里面是先reshape的,reshape不需要赋初始值,reshape后进行矩阵相乘时才需要初始值w和b,torch中对应的是对linear层赋初值w,从下面输出结果也可以看到linear这里有bias
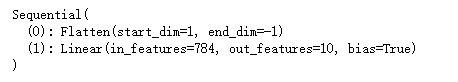
- 展平层
flatten就是把tensor,除了保留0维(0维是batch_size)的,剩下的纬度全部变为一个向量,输入数据是256×1×28×28,经过展平层变为256×784
深度学习中Flatten层的作用_mob604756e75222的技术博客_51CTO博客
- 全连接层
PyTorch 13:nn 网络层:池化层、线性层和激活函数层 - YEY 的博客 | YEY Blog
- 初始值
python - How do I initialize weights in PyTorch? - Stack Overflow
- 为什么m.weight.shape是10×784
Linear — PyTorch 1.12 documentation
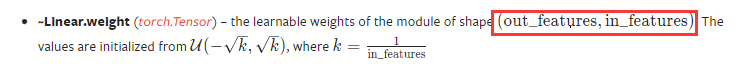
- 为什么linear里面是(784,10)
因为flatten后shape是(256,784),所以这里linear的in_feature是784,然后输出10个类别,所以这里填10
- net.apply()用法
下面链接解释了为什么要用type(m) == nn.Linear
(20条消息) model.apply(fn)或net.apply(fn)_qq_37025073的博客-CSDN博客_net.apply
在交叉熵损失函数中传递未归一化的预测,并同时计算softmax及其对数
loss = nn.CrossEntropyLoss()
使用学习率为0.1的小批量随机梯度下降作为优化算法
trainer = torch.optim.SGD(net.parameters(),lr=0.01)
# 为什么这里不需要指定batch_size?
# 个人觉得前面的flatten会保留0维,也就是batch_size,所以这里不需要指定,优化器自动通过数据集的shape来获取batch_size
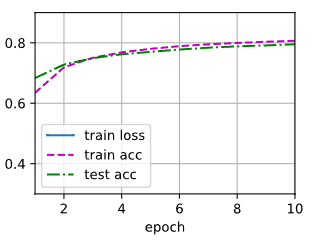
调用之前定义的训练函数来训练模型
num_epochs = 10
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
问答
1.softmax回归和logistic回归分析是一样的吗,如果不一样的话,哪些地方不同?
答:逻辑回归可以用在你只要进行二分类问题的时候,深度学习中很少遇到逻辑回归
2.y*logy^ 我们什么只关心正确类,不关心不正确类呢,如果关心不正确类效果有没有可能更好呢
答:因为y是one-hot编码,不正确的类会变为0
3.这个似然函数曲线是怎么得出来的?有什么参考意义?在其他次优解是不是似然值也很高呢?
答:最小化损失就等价于最大化似然函数
4.Dataloader()的num workers 是并行了嘛?
答:是的
5.pytorch训练好模型,测试的的时候发现无论batchsize设为1还是更多,测试的总时间都差不多但正常理解如果设成4不应该是设为1的4倍速度吗
答:不管你batch_size等于几,你的计算量是不会发生变化的,发生变化的是你并行度
6.为什么不在accuracy函数中把除以len(y)做完呢?
答:因为最后一个batch可能没有满,
4. 多层感知机¶
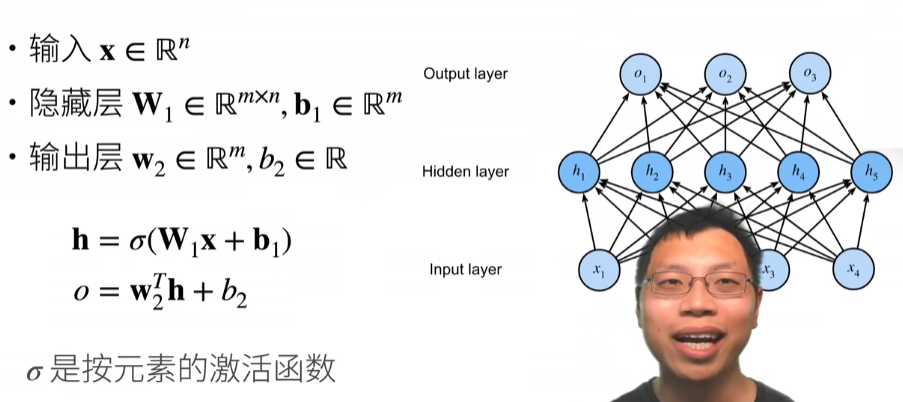
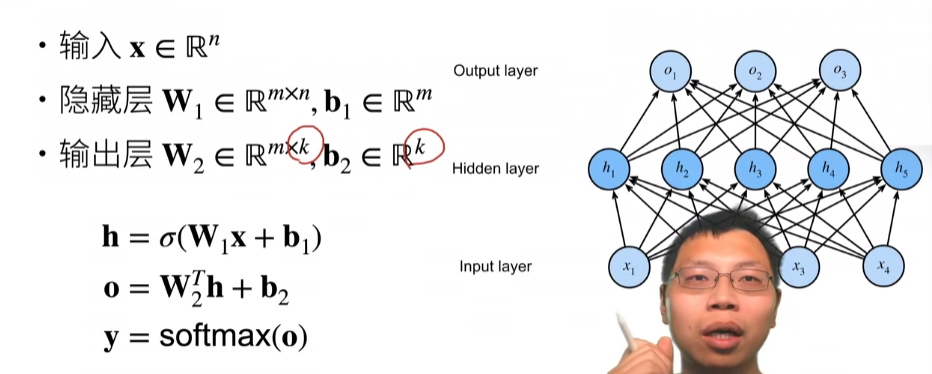
多层感知机(Multi-Layer Perceptron)是由单层感知机推广而来,最主要的特点是有多个神经元层。一般将MLP的第一层称为输入层,中间的层为隐藏层,最后一层为输出层。MLP并没有规定隐藏层的数量,因此可以根据实际处理需求选择合适的隐藏层层数,且对于隐藏层和输出层中每层神经元的个数也没有限制。
单层感知机
包括线性回归和softmax回归在内的单层神经网络,我们把需要计算的层次称之为“计算层”,并把拥有一个计算层的网络称之为“单层神经网络”。技术篇:单层神经网络是什么,看完这篇文章你就懂了 - 腾讯云开发者社区-腾讯云 (tencent.com)
感知机
深度学习入门p31
感知机接收多个信号,输出一个信号,可以理解输入信号被送往神经元时,会分别乘以固定的权重,然后神经元计算这些信号的总和,只有超过某个阈值,才会输出,称为神经元激活
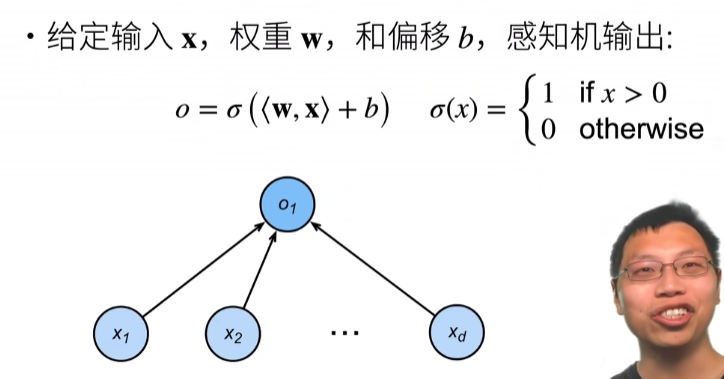

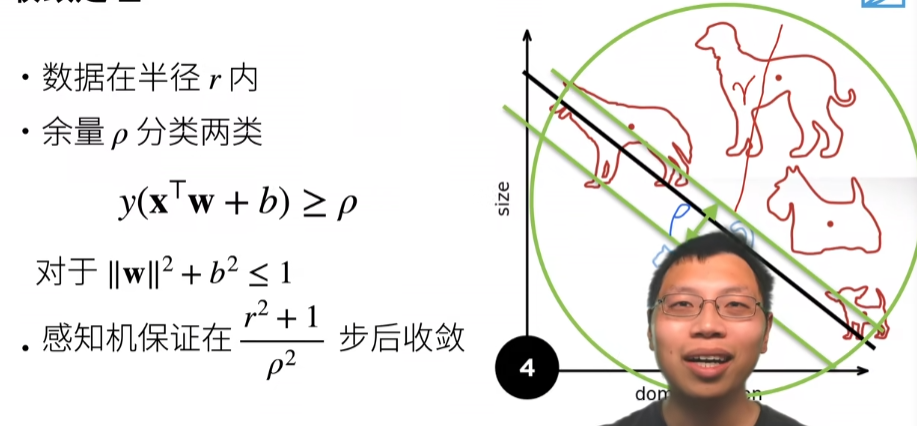
训练感知机

收敛定理
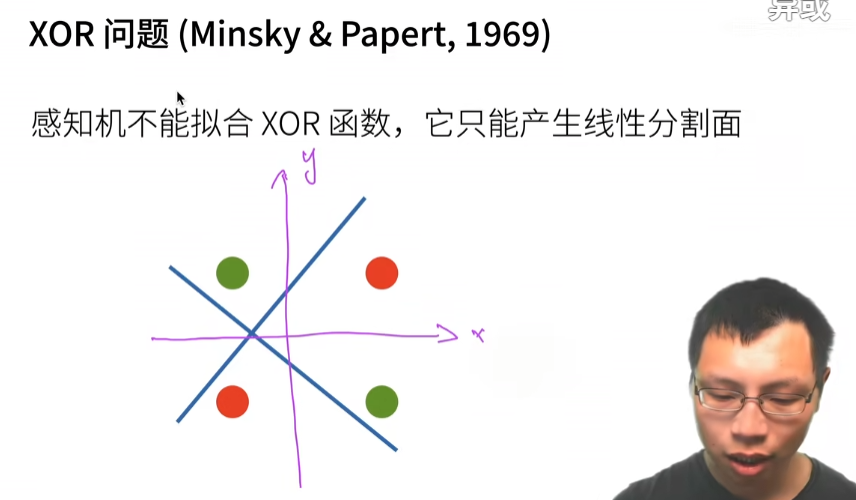
XOR问题
总结

学习XOR
用蓝色的线来划分1,2,3,4并不能将1和4划分到一块,用黄色的线划分也同样不能将1和4划分到一块,但是我把蓝色线的结果和黄线的结果弄在一起就可以了。
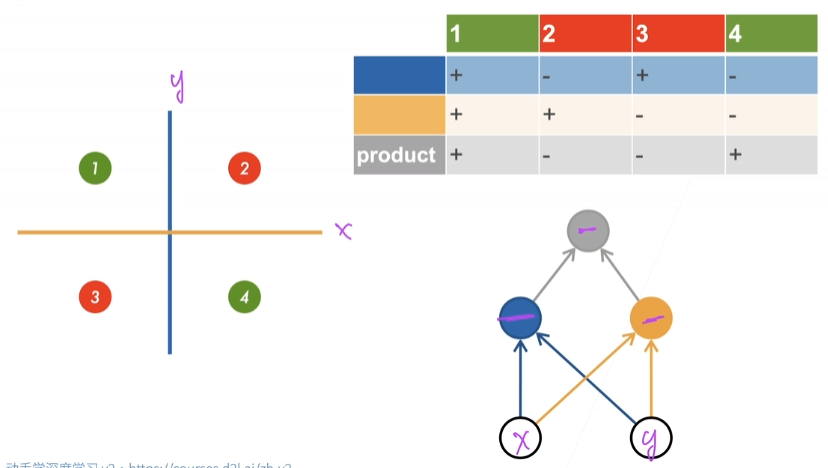
单隐藏层
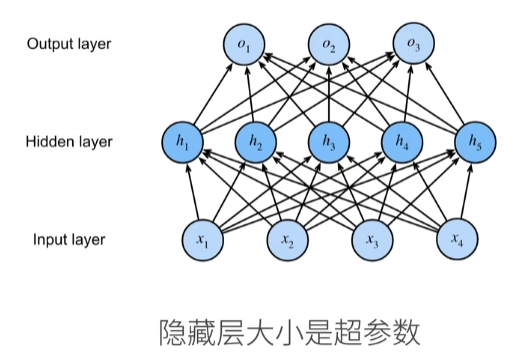
单隐藏层-单分类
神经网络的激活函数必须使用非线性函数,如果不是非线性函数,加深神经网络的层数没有意义【深度学习入门p49】
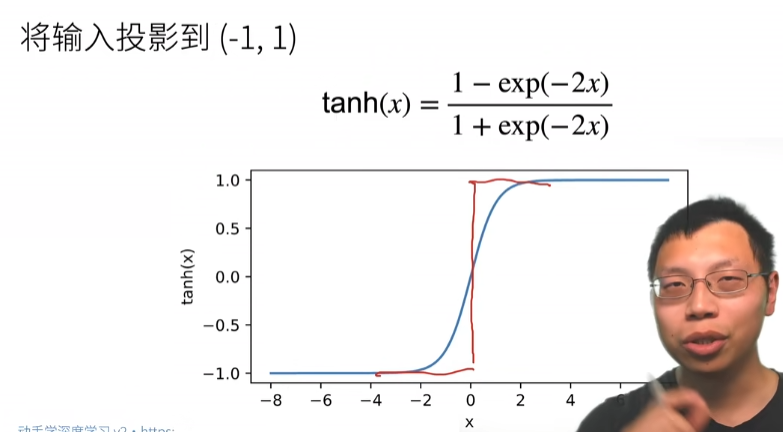
Tanh激活函数
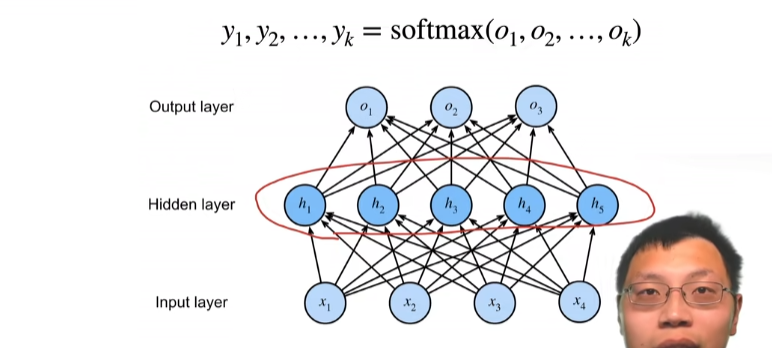
多类分类
如果我加了一层隐藏层,那么就是多层感知机,没有的话就是softmax
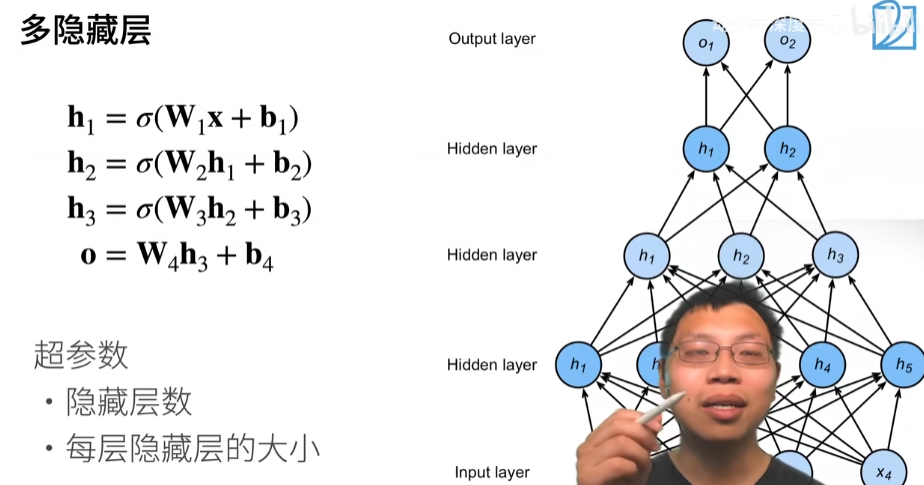
多隐藏层
每个隐藏层都有w和b,激活函数不能少,少了的话,层数就减一了。
总结

4.2. 多层感知机的从零开始实现¶
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
实现一个具有单隐藏层的多层感知机,它包含256个隐藏单元
num_inputs,num_outputs,num_hiddens = 784,10,256
W1 = nn.Parameter(torch.randn(num_inputs,num_hiddens,requires_grad=True))
B1 = nn.Parameter(torch.randn(num_hiddens,requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens,num_outputs,requires_grad=True))
B2 = nn.Parameter(torch.randn(num_outputs,requires_grad=True))
params = [W1,B1,W2,B2]
print(W1.shape) # torch.Size([784, 256])
print(B1.shape) # torch.Size([256])
print(W2.shape) # torch.Size([256, 10])
print(B2.shape) # torch.Size([10])
实现ReLU激活函数
def relu(X):
a = torch.zeros_like(X) # 创建一个0向量和X的值逐个比较,小于0的返回0
return torch.max(X,a)
X = torch.tensor([1,2,3,-1])
relu(X) # tensor([1, 2, 3, 0])
实现我们的模型
def net(X):
X = X.reshape((-1,num_inputs))
H = relu(X @ W1 + B1)
return (H * W2 + B2)
loss = nn.CrossEntropyLoss()
多层感知机的训练过程与softmax回归的训练过程完全相同
num_epochs,lr = 10,0.1
updater = torch.optim.SGD(params,lr=lr)
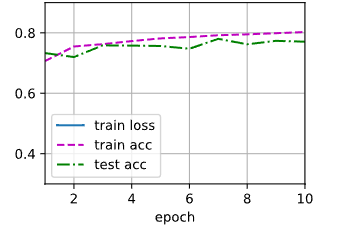
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,updater)
4.3. 多层感知机的简洁实现多层感知机的简洁实现
https://zh-v1.d2l.ai/chapter_deep-learning-basics/mlp-gluon.html#
通过高级API更简洁地实现多层感知机
import torch
from torch import nn
from d2l import torch as d2l
隐藏层包含256个隐藏单元,并使用了ReLU激活函数
net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std=0.1)
net.apply(init_weights)
训练过程
batch_size,lr,num_epochs = 256,0.1,10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(),lr=lr)
trainer_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
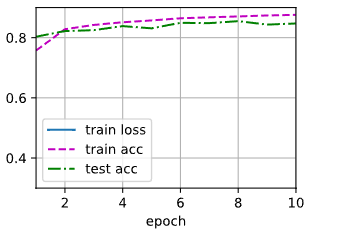
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
问题
1.请问老师神经网络中的一层网络到底是指什么?是一层神经元经过线性变换后称为一层网络,还是一层神经元经过线性变化加非线性变换后称为一层?
答:带权重的称为一层
2.老师,relu为什么管用,它在大于0的部分也就只是线性变换啊。。为什么能促进学习呢,激活的本质是要做什么事?不是引入非线性?
答:relu不是线性函数,线性函数是f(x)=ax+b这种,relu是分段函数
4.4. 模型选择、欠拟合和过拟合模型选择、欠拟合和过拟合
https://zh-v1.d2l.ai/chapter_deep-learning-basics/underfit-overfit.html#
4.4.1. 训练误差和泛化误差¶

4.4.2. 模型选择模型选择
https://zh-v1.d2l.ai/chapter_deep-learning-basics/underfit-overfit.html#
4.4.2.1. 验证集

测试数据集不能用调你的超参数
4.4.2.2. K折交叉验证

总结

4.4.3. 欠拟合还是过拟合?
出现过拟合的原因
造成原因主要有以下几种:
1、训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
2、训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,忽略了真实输入和输出之间的关系。
3、模型过于复杂。模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
欠拟合、过拟合及如何防止过拟合 - 知乎 (zhihu.com)

模型容量

模型容量的影响
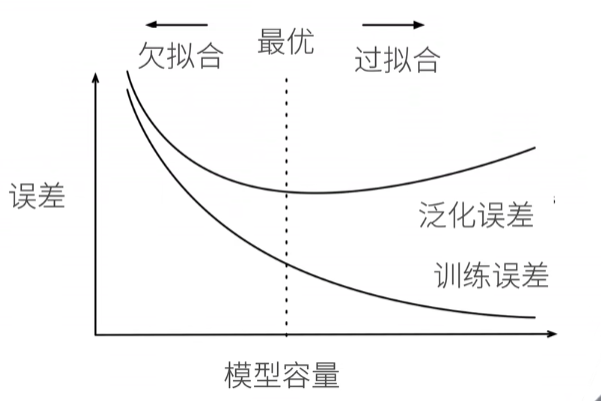
过拟合就是模型在训练数据上的损失不断减小,在测试数据上的损失先减小再增大,这才是过拟合现象
估计模型容量
估计模型容量有两个重要的因素
- 参数的个数
- 参数值的选择范围
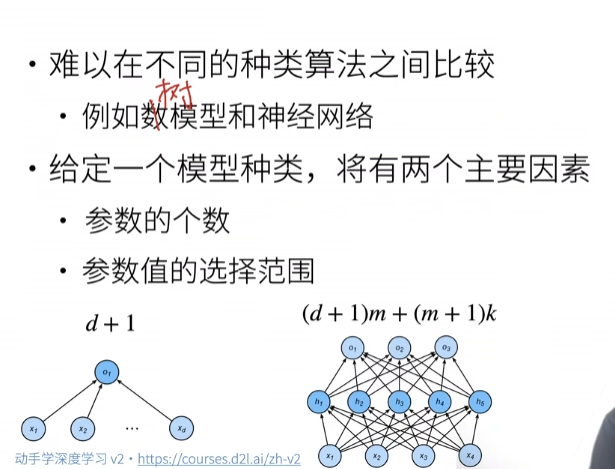
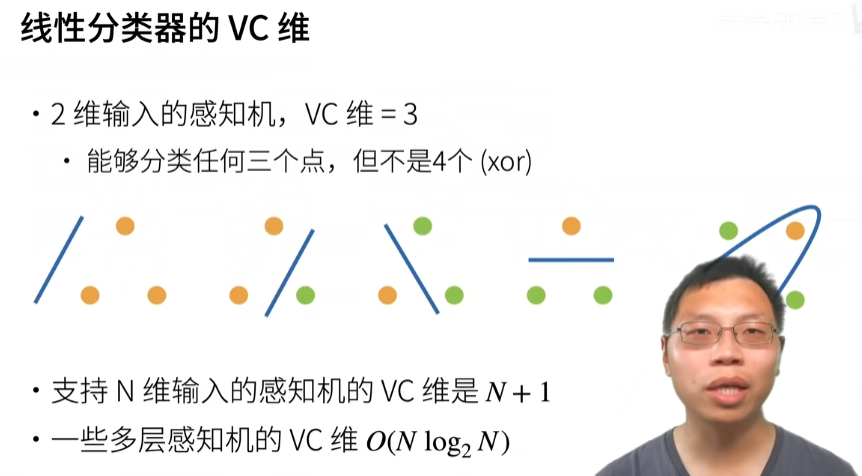
VC维


数据复杂度

总结

通过多项式拟合来交互地探索这些概念
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
使用以下三阶多项式来生成训练和测试数据的标签
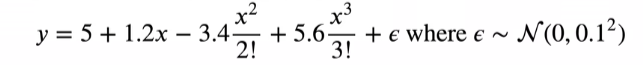
max_degree = 20 # 特征为20
n_train,n_test = 100,100 # 训练样本和测试样本各为100个
true_w = np.zeros(max_degree) # 产生一个20维的向量,只有前面4个是有值的
true_w[0:4] = np.array([5,1.2,-3.4,5.6])# 后面的全是0,都是噪音项
features = np.random.normal(size=(n_train + n_test,1))
np.random.shuffle(features)
poly_features = np.power(features,np.arange(max_degree).reshape(1,-1)) # 生成x,x^2,x^3.....
poly_features.shape # (200, 20)
poly_features[:,0:1] # x^ 0是1
for i in range(max_degree):
# print(i,math.gamma(i+1))
poly_features[:,i] /= math.gamma(i+1)
labels = np.dot(poly_features,true_w)
# 最后再加点噪音数据
labels += np.random.normal(scale=0.1,size=labels.shape)
- normal中size,scale的作用

size指定输出尺寸
scale指定方差
(20条消息) numpy.random.normal函数_linyi_pk的博客-CSDN博客_np.random.normal函数
- np.power(features,np.arange(max_degree).reshape(1,-1))
对features中每个元素,分别求0次方,1次方,2次方,3次方...。就像下面分别对1,2,3,4求1次方,2次方

- features
可以理解为x
- poly_features
可以把poly_features看做\([x^0,x^1,x^2,x^3.......x^{19}]\),而且里面的每一个x是200维的向量
- math.gamma
阶乘,需要注意的是,math.gamma(x),其实算的是x-1的阶乘,例如math.gamma(3)就是算2的阶乘结果为2
Python math.gamma() 方法 | 菜鸟教程 (runoob.com)

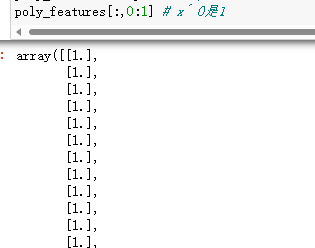
- poly_features的第一列数据
第一列是x的0次方,所以全部是0
- 思路总结
第一步生成200个样本,每个样本里面有20个项,也就是纬度是200×20,这是features做的事情
第二步对每个样本算其的n次方,也就是poly_features做的事
第三步每个项除以阶乘
第四步乘以每个项前面的系数(前4个是真实值,后面全是噪音)
第五步加上噪音项
实现一个函数来评估模型在给定数据集.上的损失
def evaluate_loss(net,data_iter,loss):
# 评估给定数据集上模型的损失
metric = d2l.Accumulator(2)
for X,y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out,y)
metric.add(l.sum(),l.numel())
return metric[0] / metric[1]
看一下前2个样本
true_w,features,poly_features,labels = [
torch.tensor(x,dtype=torch.float32)
for x in [true_w,features,poly_features,labels]]
features[:2],poly_features[:2,:],labels[:2]

定义训练函数
def train(train_features,test_features,train_labels,test_labels,num_epochs=400):
loss = nn.MSELoss()
print(train_features.shape) # torch.Size([100, 4])
input_shape = train_features.shape[-1]
print(input_shape) # 4
# net就是一个简单的线性网络,这里不需要bias,这里有linear会自动生成weight
net = nn.Sequential(nn.Linear(input_shape,1,bias=False))
# 这里的input_shape是4,也就是linear层的input_features是4,output_features是1,其所有的weight的shape是1×4
print(next(net.parameters()).shape) # torch.Size([1, 4])
batch_size = min(10,train_labels.shape[0])
train_iter = d2l.load_array((train_features,train_labels.reshape(-1,1)),
batch_size)
test_iter = d2l.load_array((test_features,test_labels.reshape(-1,1)),
batch_size,is_train=False)
trainer = torch.optim.SGD(net.parameters(),lr=0.01)
animator = d2l.Animator(xlabel='epoch',ylabel='loss',yscale='log',
xlim=[1,num_epochs],ylim=[1e-3,1e2],
legend=['train','test']
)
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net,train_iter,loss,trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch+1,(evaluate_loss(
net,train_iter,loss),evaluate_loss(net,test_iter,loss)))
# 下面两句代码等价
print('weight:',next(net.parameters()).detach().numpy()) # 不加detach报错
print('weight:',net[0].weight.data.numpy())
- shape[0],shape[1],shape[-1]
shape[0]第0维中的数量
shape[1]第1维中的数量
shape[-1]最后一维的数量
[(20条消息) python中shape-1],shape[0],shap[1]_好事要发生的博客-CSDN博客_shape[-1]
- net[0]
net的输出如下图,net[0]就是linear层
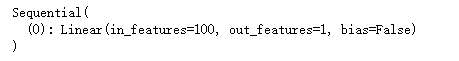
三阶多项式函数拟合(正态)
train(poly_features[:n_train,:4],poly_features[n_test:,:4],
labels[:n_train],labels[n_test:])
通过训练得到weight和生成数据用的weight如下
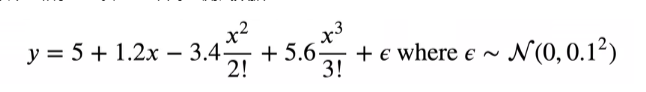
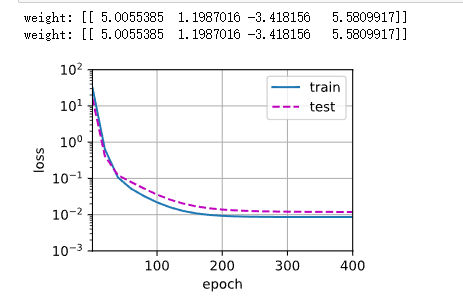
- poly_features[:n_train,:4],poly_features[n_train:,:4]
为什么这里只取每个样本的前4个?因为,后面的16个项全是噪音,仅仅实在生成数据的时候有用,现在我要weight,也就是只找前4个
线性函数拟合(欠拟合)
train(poly_features[:n_train,:2],poly_features[n_train:,:2],labels[:n_train],labels[n_train:])
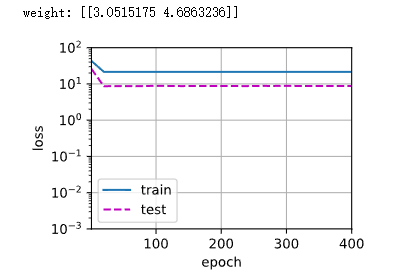
高阶多项式函数拟合(过拟合),就像李宏毅说的,多项式不能太复杂也不能太简单,复杂容易过拟合,简单容易欠拟合
train(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:], num_epochs=1500)
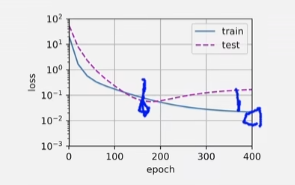
问答
鲁棒性就是泛化能力
1.如果是时间序列上的数据,训练集和验证集可能会有自相关,这时候应该怎么处理呢?
答:可以按照时间来划分数据集
2.老师,深度学习一般训练集合比较大,所以K则交叉险证在深度学习中是不是没什么应用?训练成本太高了吧?
答:所以k折一般用在数据比较少的时候
3.为什么cross validation就好呢,他其实也并没有解决数据来源的问题?
答:cross validation主要解决超参数的问题
4.k则交叉验证中的k怎么确定?有什么方法吗?
答:k看自己能承担多少
5.老师,模型参数和超参数不一样吗?
答:模型的参数指的是w和b,超参数指的是我选的是线性层还是感知机,如果是感知机,有多少层,每层有多大,学习率有多大。
6.所以validation出现的误差是什么误差?
答:训练误差
7.模型容量一般指的是什么?
答:拟合函数的能力
8.我在训练的时候,x轴是迭代次数,在验证集上loss也会发生这种先下降后上升的趋势,是不是错的?是因为发生了过拟合?
答:是发生了过拟合
4.5. 权重衰减¶
视频链接:12 权重衰退【动手学深度学习v2】_哔哩哔哩_bilibili
如何控制模型的容量?
答:1.把模型变得比较小(里面参数比较少),2.每个参数的选择范围比较小
使用均方范数作为硬性限制
\(\ell(\mathbf{w}, b)\)是损失函数

使用均方范数作为柔性限制

演示对最优解的影响
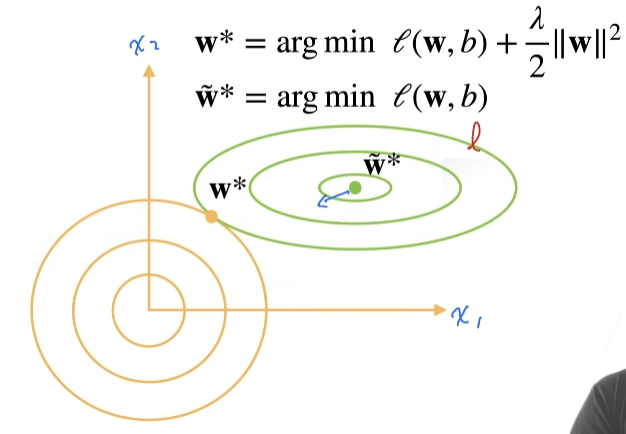
绿线是损失函数的取值, 黄线是惩罚项的取值, 两者都是圈越大取值越大,那么取两个线的交界点就是最优化点
参数更新法则
因为nλ小于1,w乘以小于的数,权重会衰退,所以叫做权重衰退(weight decay)

总结

代码实现
权重衰减是最广泛使用的正则化的技术之一
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
像以前一样生成一些数据
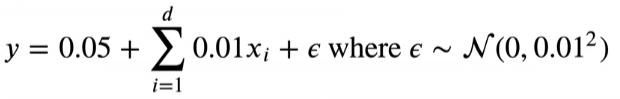
# 训练数据越小,越容易过拟合(当你的数据越简单,模型越复杂越容易过拟合),所以这里n_train取20,
n_train,n_test,num_inputs,batch_size = 20,100,200,5 # num_inputs是特征维,也就是上面的d,x里面num_inputs个数据
true_w,true_b = torch.ones((num_inputs,1)) * 0.01,0.05
# print(true_w) # 生成一个200×1的矩阵,里面的值全部是0.01
train_data = d2l.synthetic_data(true_w,true_b,n_train)
train_iter = d2l.load_array(train_data,batch_size)
test_data = d2l.synthetic_data(true_w,true_b,n_test)
test_iter = d2l.load_array(test_data,batch_size,is_train=False)
初始化模型参数
def init_params():
# 之前已经生成了w,然后根据w和x再加上b知道了label,现在把w和b假装不知道,知道x和label,来反推w和b
w = torch.normal(0,1,size=(num_inputs,1),requires_grad=True)
b = torch.zeros(1,requires_grad=True)
return [w,b]
定义\(L_{2}\)范数惩罚
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
定义训练代码
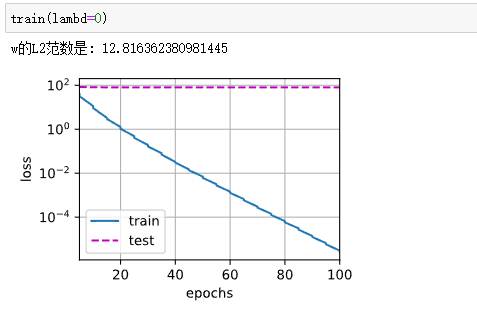
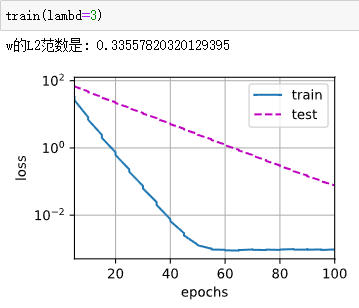
def train(lambd):
w,b = init_params()
net,loss = lambda X:d2l.linreg(X,w,b),d2l.squared_loss # 平法误差
num_epochs,lr = 100,0.003
animator = d2l.Animator(xlabel='epochs',ylabel='loss',yscale='log',
xlim=[5,num_epochs],legend=['train','test'])
for epoch in range(num_epochs):
for X,y in train_iter:
l = loss(net(X),y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w,b],lr,batch_size)
if(epoch + 1) % 5 == 0:
animator.add(epoch + 1,(d2l.evaluate_loss(net,train_iter,loss),
d2l.evaluate_loss(net,test_iter,loss)))
print('w的L2范数是:',torch.norm(w).item())
- 为什么不使用step()更新参数
step()是使用form torch import nn之后,使用nn来sequentail来添加网络后才会用到step()更新,具体的区别可以认真去看线性回归从零开始和线性回归简洁实现
- norm()函数
torch - PyTorch中文文档 (pytorch-cn.readthedocs.io)
- item()
(20条消息) pytorch loss.item()大坑记录(非常重要!!!)_StarfishCu的博客-CSDN博客_loss.item() pytorch
(20条消息) python中.item()的讲解_爱听许嵩歌的博客-CSDN博客_python中item
忽略正则化直接训练,由于样本数据小,所以容易过拟合
使用权重衰减
简洁实现
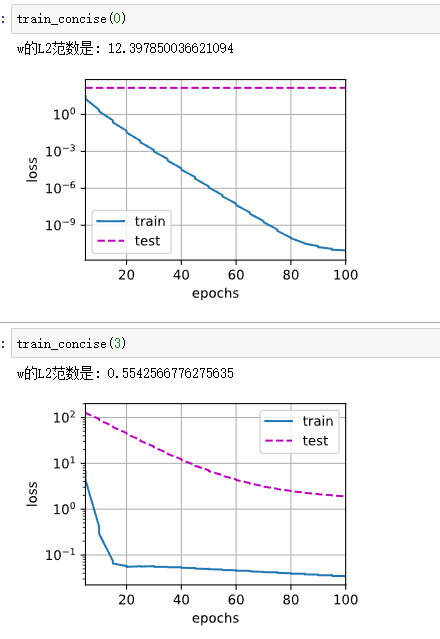
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs,1))
for param in net.parameters():
param.data.normal_() # 初始化参数
loss = nn.MSELoss()
num_epochs,lr = 100,0.003
trainer = torch.optim.SGD([
{
"params":net[0].weight,
"weight_decay":wd }, # weight_decay,pytorch里面是L2范数
{
"params":net[0].bias,
}
],lr = lr)
animator = d2l.Animator(xlabel='epochs',ylabel='loss',yscale='log',
xlim=[5,num_epochs],legend=['train','test'])
for epoch in range(num_epochs):
for X,y in train_iter: # train_iter在上面的代码实现
trainer.zero_grad()
l = loss(net(X),y)
l.backward()
trainer.step()
if(epoch + 1) % 5 == 0:
animator.add(epoch + 1,(d2l.evaluate_loss(net,train_iter,loss),
d2l.evaluate_loss(net,test_iter,loss)))
print('w的L2范数是:',torch.norm(net[0].weight).item())
- zero_grad()梯度清零
在调用backward()之前要将梯度清零
(20条消息) pytorch中为什么要用 zero_grad() 将梯度清零_Christopher_Liu_lzh的博客-CSDN博客_为什么需要清空梯度
问答
1.实践中权重衰减的值一般设置多少为好呢变之前在跑代码的时候总感觉权重衰减的效果并不那么好?
答:一般设为1e-3或者1e-4
4.6. 暂退法(Dropout)¶
13 丢弃法【动手学深度学习v2】_哔哩哔哩_bilibili
无偏差的加入噪音
假设x是到下一层之间的输出的话,我们给x加入噪音得到x‘,虽然我加了噪音,但是我不想改变我的期望。然后把p概率的xi变为0,这时候整体上x的数据变小,我需要把剩下不是0的数据变大点(变大是为了弥补那些变成0 的神经元权重,分母小于1的话,值会大点)

根据期望公式
推出
使用丢弃法
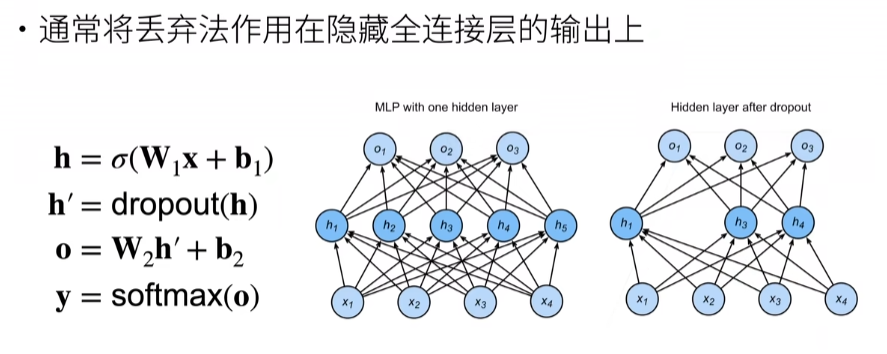
推理中的丢弃法

总结

代码实现
我们实现dropout_ layer 函数,该函数以dropout的概率丢弃张量输入X中的元素
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X,dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X)
if dropout == 0:
return X
mask = (torch.randn(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
- assert
assert(断言),判断assert后的表达式是否为true,若为true就继续执行下面的代码,若为false,则触发异常
- mask
mask本来是一个Boolean类型的矩阵,但是后面有个float,使得mask的值是0或者1,然后mask与X相乘就可以保留一些值,让一些值为0了。mask相当于下图的ξi,return后面的就是下面的公式
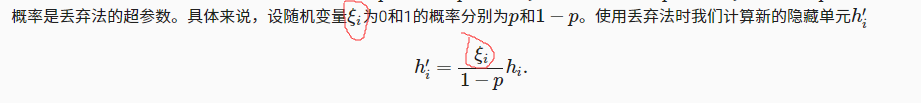
3.13. 丢弃法 — 《动手学深度学习》 文档 (d2l.ai)
测试dropout_ layer 函数
X = torch.arange(16,dtype=torch.float32).reshape((2,8))
print(X)
print(dropout_layer(X,0))
print(dropout_layer(X,0.5))
print(dropout_layer(X,1))

定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元
num_inputs,num_outputs,num_hiddens1,num_hiddens2 = 784,10,256,256
dropout1,dropout2 = 0.2,0.5
class Net(nn.Module):
def __init__(self,num_inputs,num_outputs,num_hiddens1,num_hiddens2,is_training=True):
super(Net,self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs,num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1,num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2,num_outputs)
self.relu = nn.ReLU()
def forward(self,X):
H1 = self.relu(self.lin1(X.reshape((-1,self.num_inputs))))
if self.training == True:
H1 = dropout_layer(H1,dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
H2 = dropout_layer(H2,dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs,num_outputs,num_hiddens1,num_hiddens2)
训练和测试
num_epochs,lr,batch_size = 10,0.5,256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(),lr=lr)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
简洁实现
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256,256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256,10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std=0)
net.apply(init_weights)
对模型进行训练和测试
trainer = torch.optim.SGD(net.parameters(),lr=lr)
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)
问答
1.dropout随机置0对求梯度和反向传播的影响是什么?
答:置0的梯度会变为0,相应的参数不会更新
2.请问老师,在使用BN的时候,还有必要使用dropout吗?
答:BN是给卷积层用的,dropout是给全连接层用的
3.老师,请问可以再解释一下 为什么“推理中的dropout是直接返回输入”吗?
答:在做预测的时候,所谓的预测就是不对我的权重做更新的时候,这时候dropout是不用的,因为dropout是一个正则项,正则项的作用是在更新权重的时候,让你模型的复杂度变低一点,但是你在推理的时候,不会更新你的模型,所以不需要dropout。
4.8. 数值稳定性和模型初始化数值稳定性和模型初始化
https://zh-v1.d2l.ai/chapter_deep-learning-basics/numerical-stability-and-init.html#
神经网络的梯度

数值稳定性的常见两个问题
因为矩阵乘法过多,容易造成两个问题
- 梯度爆炸
- 梯度消失


- diag
对角矩阵
梯度爆炸

梯度爆炸的问题

梯度消失

梯度消失的问题

总结

让训练更加稳定

让每层的方差是一个常数
期望就是均值,均值就是期望
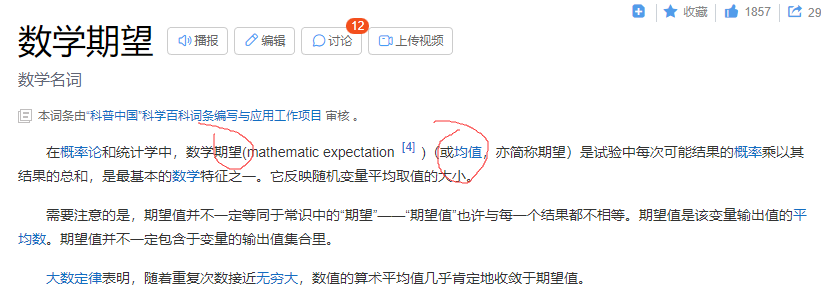

h是hidden的简称,代表第t个隐藏层的第i个元素
权重初始化

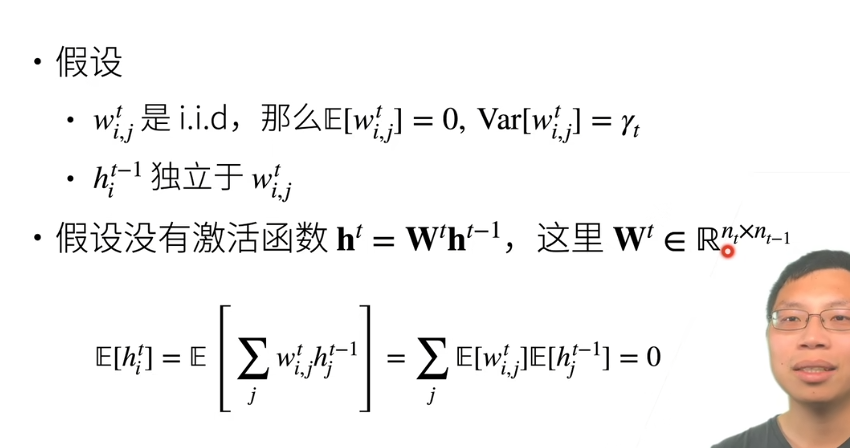
- i.i.d
独立同分布

如果随机变量X只可能取有限个或至多可列个值,则称X为离散型随机变量。
- 当X和Y相互独立时, E(XY)=E(X)E(Y)
正向方差

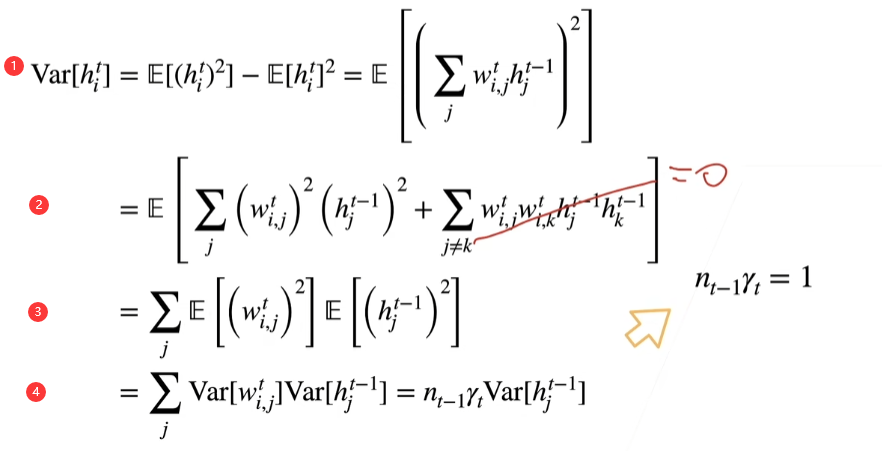
因为均值是0,所以\(E[h^t_{i}]^2=0\),\(E[h^t_{i}]\)根据权重初始化里面公式可以进行替换
第一步可以通过上面的公式推出来,第三步到第四步可以通过第一步的var=E[x2]-E[x]2推出来
\(n_{t-1}\)表示第t层输入维度,对t-1层的\(Var[w_{i,j}^{t}]\)求和就是\(n_{t-1}γ_{t}\)
反向均值和方差

Xavier初始
https://www.bilibili.com/video/BV1u64y1i75a?p=2&vd_source=91219057315288b0881021e879825aa3&t=1031.6
如果我们要方差一样的话有两个条件,如下
- \(n_{t-1}γ_{t}=1\)表示前向输出方差是一致的
- \(n_{t}γ_{t}=1\)表示梯度是一样的
但是这两个条件很难满足, \(n_{t-1}\)表示t层的输入维度,\(n_{t}\)表示输出维度,除非你输入维度刚好等于输出维度,否则无法同时满足这两个条件。有个想法叫做Xavier,它的想法是既然我无法同时满足两个条件,那我就折中。\(γ_{t}\)是第t层权重的方差,满足输入维度加上输出维度再除以2等于1,也就是只要你告诉我当前输入维度和输出维度的带下,我就可以知道当前层维度的方差的大小

Xavier是一种常见的权重初始化的方法,它的方差是根据输入维度和输出维度的大小而决定的
假设线性的激活函数
这里的期望(均值)也就是E[*]=0
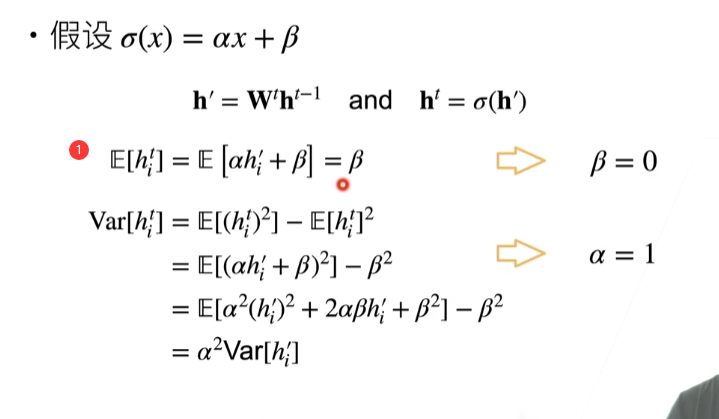
图片中的第一步是线性变化的期望
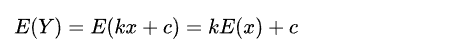
所以,最后第一步的结果等于β
最后一步,\(a^2\)提出来,\(E[(h^{'}_{i})^2]\)等于\(Var[h^{'}_{i}]\),可以根据方差等于平方的期望减期望的平方(\(Var(x)=E[x^2]-E[x]^2\))
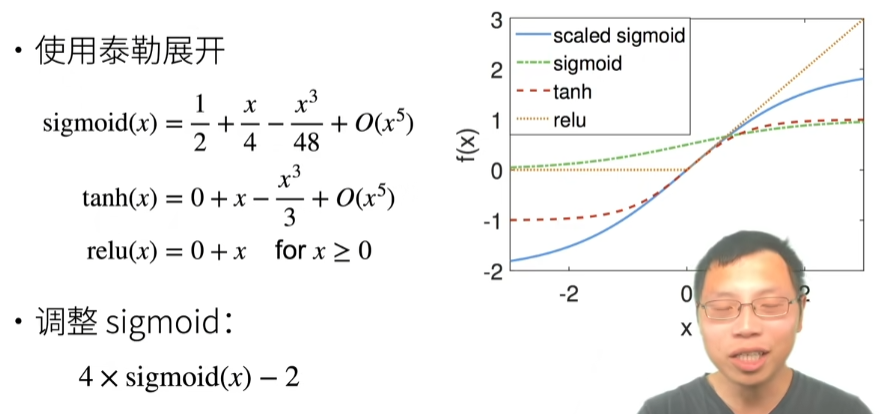
检查常用激活函数
总结

问答
1.老师可以讲一下nan, inf是怎么产生的以及怎么解决吗?
答:nan一般是除以0了,inf是值太大了,合理的初始化你的权重,激活函数不要选错,学习率不要选太大,可以一直把学习率往小的调,直到nan不出现
2。随机初始化,有没有- -种最好的/最推荐的概率分布来找到初始随机值吗?
答:Xaiver
3.请问一下为什么在做这些假设时都需要加入前提独立同分布?非独立同分布的计算会更复杂么?
答:独立同分布是为了简单
4.-般权重是在每个epoch结束以后更新的吧?
答:权重是在batch后更新
4.10. 实战Kaggle比赛:预测房价¶
15 实战:Kaggle房价预测 + 课程竞赛:加州2020年房价预测【动手学深度学习v2】_哔哩哔哩_bilibili
实现几个函数来方便下载数据
import hashlib
import os
import tarfile
import zipfile
import requests
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
def download(name, cache_dir=os.path.join('..', 'data')):
"""下载一个DATA_HUB中的文件,返回本地文件名。"""
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}."
url, sha1_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True)
fname = os.path.join(cache_dir, url.split('/')[-1])
# 判断文件名是否存在
if os.path.exists(fname):
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
return fname
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
return fname
def download_extract(name, folder=None):
"""下载并解压zip/tar文件。"""
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, '只有zip/tar文件可以被解压缩。'
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
def download_all():
"""下载DATA_HUB中的所有文件。"""
for name in DATA_HUB:
download(name)
- url, sha1_hash
url:http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_train.csv
sha1_hash:585e9cc93e70b39160e7921475f9bcd7d31219ce
url:http://d2l-data.s3-accelerate.amazonaws.com/kaggle_house_pred_test.csv
sha1_hash:fa19780a7b011d9b009e8bff8e99922a8ee2eb90
- fname
kaggle_house_pred_train.csv
kaggle_house_pred_test.csv
- hashlib.sha1()
hashlib - 廖雪峰的官方网站 (liaoxuefeng.com)
使用pandas读入并处理数据
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
DATA_HUB['kaggle_house_train'] = (
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = (
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
print(train_data.shape)
print(test_data.shape)

前四个和最后两个特征,以及相应标签
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
在每个样本中,第一个特征是ID, 我们将其从数据集中删除
all_features = pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]))
all_features.shape # (2919, 79)
- [:,1:-1]与[:,1:]区别

将所有缺失的值替换为相应特征的平均值。 通过将特征重新缩放到零均值和单位方差来标准化数据
# 既然要填充平均值,那么列类型肯定不能是字符类型,所以先把不是字符类型的筛选出来,筛选出来的都是数值类型
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
numeric_features

# 标准化数据 batch normalization 批量归一化
all_features[numeric_features] = all_features[numeric_features].apply(lambda x:(x-x.mean()) / (x.std()))
# 填充缺失值,这里是用0来填充
all_features[numeric_features] = all_features[numeric_features].fillna(0)
- dtypes
获取Dataframe的列类型
Python Pandas DataFrame.dtypes用法及代码示例 - 纯净天空 (vimsky.com)
- object
字符串类型
[译] Pandas 数据类型概览 - 掘金 (juejin.cn)
处理离散值。我们用一次独热编码替换它们
all_features = pd.get_dummies(all_features,dummy_na=True)
all_features.shape # (2919, 331)
(20条消息) pandas.get_dummies 的用法_魔术师_的博客-CSDN博客_pandas.get_dummies
从pandas格式中提取NumPy格式,并将其转换为张量表示
n_train = train_data.shape[0]
n_train # 1460
# 前面已经进行独热编码了,所以这里可以对value进行float32转换
train_features = torch.tensor(all_features[:n_train].values,
dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values,
dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1,1),
dtype=torch.float32)
train_labels.shape # 1460
如果没有进行独热编码直接进行转换会报错

训练
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,1))
return net
我们更关心相对误差$\frac{y-ŷ}{y} $,解决这个问题的一种方法是用价格预测的对数来衡量差异,因为比如说有的房子贵,有的便宜,如果那贵的去算误差,那么贵的所占的权重就比较大,便宜的权重比较小,所以这里更关注于相对误差
def log_rmse(net,features,labels):
clipped_preds = torch.clamp(net(features),1,float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
return rmse.item()
- torch.clamp()
将输入元素,限定在某个区间
(20条消息) pytorch:torch.clamp()_大雄没有叮当猫的博客-CSDN博客_clamp torch
- torch.log()
取对数是方便处理和计算,一般y取log以后会更接近正态分布,用回归性质会比较好
- rmse(均方根误差)
(20条消息) 均方误差(MSE)和均方根误差(RMSE)和平均绝对误差(MAE)_医学影像处理的博客-CSDN博客_mse和rmse的区别
我们的训练函数将借助Adam优化器
def train(net,train_features,train_labels,test_features,test_labels,num_epochs,learning_rate,weight_decay,batch_size):
train_ls,test_ls = [],[]
train_iter = d2l.load_array((train_features,train_labels),batch_size)
optimizer = torch.optim.Adam(net.parameters(),lr=learning_rate,
weight_decay=weight_decay)
for epoch in range(num_epochs):
for X,y in train_iter:
optimizer.zero_grad()
l = loss(net(X),y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net,train_features,train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net,test_features,test_labels))
return train_ls,test_ls
K折交叉验证
def get_k_fold_data(k,i,X,y):
assert k > 1
fold_size = X.shape[0] // k
X_train,y_train = None,None
for j in range(k):
# 划分区间
idx = slice(j * fold_size,(j+1) * fold_size)
X_part,y_part = X[idx,:],y[idx]# X中加:表示取所有列,因为X中不止一列
if j == i: # 第i个作为验证集
X_valid,y_valid = X_part,y_part
elif X_train is None: # 第一次没有值的时候,如果这个判断不写的话,连接的时候,会把None和数据连接在一块
X_train,y_train = X_part,y_part
else:
X_train = torch.cat([X_train,X_part],0) # 0表示axis=0,第0维
y_train = torch.cat([y_train,y_part],0)
return X_train,y_train,X_valid,y_valid
- slice
Python slice() 函数 | 菜鸟教程 (runoob.com)
- cat
Pytorch中的torch.cat()函数_荷叶田田_的博客-CSDN博客_python torch.cat
- concat
[Python3]pandas.concat用法详解_Asher117的博客-CSDN博客_panda.concat
返回训练和验证误差的平均值
def k_fold(k,X_train,y_train,num_epochs,learning_rate,weight_decay,batch_size):
train_l_sum,valid_l_sum = 0,0
for i in range(k):
data = get_k_fold_data(k,i,X_train,y_train)
net = get_net()
train_ls,valid_ls = train(net,*data,num_epochs,learning_rate,weight_decay,batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1,num_epochs+1)),[train_ls,valid_ls],
xlabel='epoch',ylabel='rmse',xlim=[1,num_epochs],
legend=['train','valid'],yscale='log')
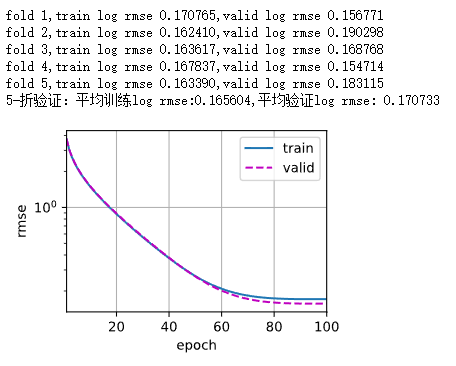
print(f'fold {i + 1},train log rmse {float(train_ls[-1]):f},'
f'valid log rmse {float(valid_ls[-1]):f}')
return train_l_sum / k,valid_l_sum / k
模型选择
k,num_epochs,lr,weight_decay,batch_size = 5,100,5,0,64
train_l,valid_l = k_fold(k,train_features,train_labels,num_epochs,lr,
weight_decay,batch_size)
print(f'{k}-折验证:平均训练log rmse:{float(train_l):f},'
f'平均验证log rmse: {float(valid_l):f}')
提交你的Kaggle预测
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
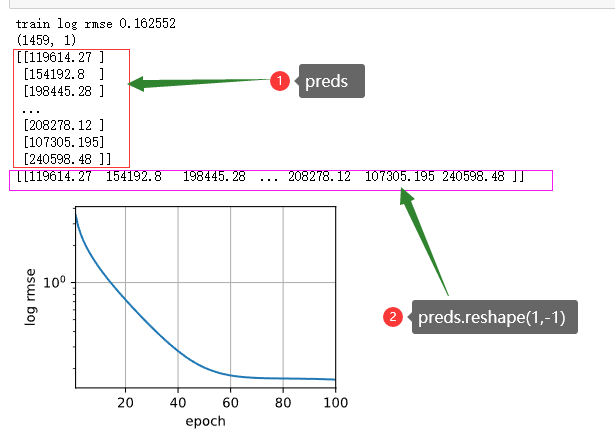
print(f'train log rmse {float(train_ls[-1]):f}')
preds = net(test_features).detach().numpy()
print(preds.shape) # (1459, 1)
print(preds)
print(preds.reshape(1,-1))
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
kaggle比赛
- 五层隐藏层
in_features = train_features.shape[1]
out_features = 1
num_hiddens1 = 30
num_hiddens2 = 30
num_hiddens3 = 30
num_hiddens4 = 30
num_hiddens5 = 30
def get_net():
net = nn.Sequential(
nn.Linear(in_features,num_hiddens1),
nn.ReLU(),
nn.Linear(num_hiddens1,num_hiddens2),
nn.ReLU(),
nn.Linear(num_hiddens2,num_hiddens3),
nn.ReLU(),
nn.Linear(num_hiddens3,num_hiddens4),
nn.ReLU(),
nn.Linear(num_hiddens4,num_hiddens5),
nn.ReLU(),
nn.Linear(num_hiddens5,out_features))
return net
net = get_net()
net[0].weight.data.normal_(0,0.01)
net[0].bias.data.fill_(0)
net[2].weight.data.normal_(0,0.01)
net[2].bias.data.fill_(0)
net[4].weight.data.normal_(0,0.01)
net[4].bias.data.fill_(0)
net[6].weight.data.normal_(0,0.01)
net[6].bias.data.fill_(0)
net[8].weight.data.normal_(0,0.01)
net[8].bias.data.fill_(0)
net[10].weight.data.normal_(0,0.01)
net[10].bias.data.fill_(0)
num_epochs,lr,weight_decay,batch_size = 300,0.01,0.5,50 train log rmse 0.000764
num_epochs,lr,weight_decay,batch_size = 300,0.01,0.5,45 train log rmse 0.000713
num_epochs,lr,weight_decay,batch_size = 300,0.01,0.5,58 train log rmse 0.000884
num_epochs,lr,weight_decay,batch_size = 300,0.01,0.5,59 train log rmse 0.000692
num_epochs,lr,weight_decay,batch_size = 200,0.01,0.5,58 train log rmse 0.000707
num_epochs,lr,weight_decay,batch_size = 300,0.01,0.1,50 train log rmse 0.000795
num_epochs,lr,weight_decay,batch_size = 300,0.01,0.6,100 train log rmse 0.000840
num_epochs,lr,weight_decay,batch_size = 400,0.01,0.5,60 train log rmse 0.000529
num_epochs,lr,weight_decay,batch_size = 500,0.01,0.3,60 train log rmse 0.000567
num_epochs,lr,weight_decay,batch_size = 600,0.01,0.3,60 train log rmse 0.000614
num_epochs,lr,weight_decay,batch_size = 1500,0.01,0.5,50 train log rmse 0.000781
- 8层和10层效果不好
5. 深度学习计算¶
16 PyTorch 神经网络基础【动手学深度学习v2】_哔哩哔哩_bilibili
层和块
16 PyTorch 神经网络基础【动手学深度学习v2】_哔哩哔哩_bilibili
首先,我们回顾一下多层感知机
import torch
from torch import nn
from torch.nn import functional as F
# 单层神经网络
net = nn.Sequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
X = torch.rand(2,20)
print(X)
net(X)
nn.Sequential定义了一种特殊的Module

自定义块
module可以认为是任意一个层和神经网络都是module的子类
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20,256)
self.out = nn.Linear(256,10)
def forward(self,X):
return self.out(F.relu(self.hidden(X)))
实例化多层感知机的层,然后在每次调用正向传播函数时调用这些层
net = MLP()
net(X)
顺序块
class MySequential(nn.Module):
def __init__(self,*args):
super().__init__()
for block in args:
self._modules[block] = block
def forward(self,X):
for block in self._modules.values():
X = block(X)
return X
net = MySequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
net(X)

*的作用:在函数定义中,收集所有位置参数到一个新的元组,并将整个元组赋值给变量
** 的作用:在函数定义中,收集关键字参数到一个新的字典,并将整个字典赋值给变量kwargs
python中的 * 和 ** 作用含义 - 末年926 - 博客园 (cnblogs.com)
在正向传播函数中执行代码
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
self.rand_weight = torch.rand((20, 20), requires_grad=False)
self.linear = nn.Linear(20, 20)
def forward(self, X):
X = self.linear(X)
X = F.relu(torch.mm(X, self.rand_weight) + 1)
X = self.linear(X)
while X.abs().sum() > 1:
X /= 2
return X.sum()
net = FixedHiddenMLP()
net(X)
混合搭配各种组合块的方法
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU())
self.linear = nn.Linear(32, 16)
def forward(self, X):
return self.linear(self.net(X))
chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
chimera(X)
参数管理
我们首先关注具有单隐藏层的多层感知机
import torch
from torch import nn
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
net(X)
参数访问
# 把每一层的参数拿出来
print(net[2].state_dict())
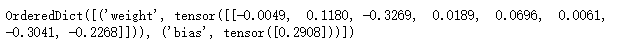
目标参数
print(type(net[2].bias))
print(net[2].bias)
print(net[2].bias.data)

net[2].weight.grad == None # True
一次性访问所有参数,模型参数
print(net[0].named_parameters())
print(*[(name, param.shape) for name, param in net[0].named_parameters()])
print(*[(name, param.shape) for name, param in net.named_parameters()])

net.state_dict()['2.bias'].data # tensor([0.2908])
从嵌套块收集参数
def block1():
return nn.Sequential(nn.Linear(4,8),nn.ReLU(),nn.Linear(8,4),nn.ReLU())
def block2():
net = nn.Sequential()
for i in range(4):
net.add_module(f'block {i}',block1())
return net
rgnet = nn.Sequential(block2(),nn.Linear(4,1))
print(rgnet)
rgnet(X)

内置初始化
# 初始化一个正太分布的参数
def init_normal(m): # m就是module
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.zeros_(m.bias)
net.apply(init_normal)
net[0].weight.data[0], net[0].bias.data[0]
# (tensor([-0.0178, 0.0063, 0.0167, -0.0003]), tensor(0.))
# 初始化一个常数的参数
def init_constant(m):
if type(m) == nn.Linear:
nn.init.constant_(m.weight, 1)
nn.init.zeros_(m.bias)
net.apply(init_constant)
net[0].weight.data[0], net[0].bias.data[0]
# (tensor([1., 1., 1., 1.]), tensor(0.))
对某些块应用不同的初始化方法
def xavier(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
#在《银河系漫游指南》小说中,有一个超级先进的文明为了寻找宇宙的终极答案,造了一台超级计算机,经过750万年的计算,最后超级计算机告诉他们终极答案就是“42”。
def init_42(m):
if type(m) == nn.Linear:
nn.init.constant_(m.weight, 42)
net[0].apply(xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)
#tensor([ 0.1933, -0.2927, -0.0297, 0.0450])
#tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])
自定义初始化
def my_init(m):
if type(m) == nn.Linear:
print(
"Init",
*[(name, param.shape) for name, param in m.named_parameters()][0])
nn.init.uniform_(m.weight, -10, 10)
m.weight.data *= m.weight.data.abs() >= 5
net.apply(my_init)
net[0].weight[:2]

- print(*objects, sep=' ', end='\n', file=sys.stdout)
objects --表示输出的对象。输出多个对象时,需要用 , (逗号)分隔。
sep -- 用来间隔多个对象。
end -- 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符。
file -- 要写入的文件对象。
Python输出函数print()总结(python print())_THEAQING的博客-CSDN博客_print()函数
print(net[0].weight.data[:])
net[0].weight.data[:] += 1
print(net[0].weight.data[:])
net[0].weight.data[0, 0] = 42
print(net[0].weight.data[0, 0])
net[0].weight.data[0]
print(net[0].weight.data[0])

参数绑定(共享参数)
shared = nn.Linear(8, 8)
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), shared, nn.ReLU(), shared,
nn.ReLU(), nn.Linear(8, 1))
net(X)
print(net[2].weight.data[0] == net[4].weight.data[0])
net[2].weight.data[0, 0] = 100
print(net[2].weight.data[0] == net[4].weight.data[0])

自定义层
构造一一个没有任何参数的自定义层
import torch
import torch.nn.functional as F
from torch import nn
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self,X):
return X - X.mean()
layer = CenteredLayer()
layer(torch.FloatTensor([1,2,3,4,5]))
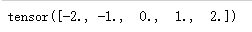
将层作为组件合并到构建更复杂的模型中
net = nn.Sequential(nn.Linear(8,128),CenteredLayer())
Y = net(torch.rand(4,8))
print(Y.shape)
Y.mean()
# torch.Size([4, 128])
# tensor(-4.6566e-09, grad_fn=<MeanBackward0>)
带参数的层
class MyLinear(nn.Module):
def __init__(self,in_units,units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units,units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self,X):
linear = torch.matmul(X,self.weight.data) + self.bias.data
return F.relu(linear)
dense = MyLinear(5,3)
dense.weight
# Parameter containing:
# tensor([[-0.2186, 1.7662, -0.9042],
# [ 0.8377, 0.1073, -0.9526],
# [ 0.9261, -0.0935, 1.6855],
# [-0.5578, -0.2627, 0.0807],
# [-2.2396, -0.9614, 0.8418]], requires_grad=True)
使用自定义层直接执行正向传播计算
dense(torch.rand(2,5))
#tensor([[0.0000, 0.5799, 0.0000],
# [0.0000, 0.0000, 0.0000]])
使用自定义层构建模型
net = nn.Sequential(MyLinear(64,8),MyLinear(8,1))
net(torch.rand(2,64))
# tensor([[0.0000],
# [0.1724]])
读写文件
加载和保存张量
import torch
from torch import nn
from torch.nn import functional as F
x = torch.arange(4)
torch.save(x,'x-file')
x2 = torch.load('x-file')
x2
# tensor([0, 1, 2, 3])
存储一个张量列表,然后把它们读回内存
y = torch.zeros(4)
torch.save([x,y],'x-files')
x2,y2 = torch.load('x-files')
(x2,y2)
# (tensor([0, 1, 2, 3]), tensor([0., 0., 0., 0.]))
写入或读取从字符串映射到张量的字典
mydict = {'x':x,'y':y}
torch.save(mydict,'mydict')
mydict2 = torch.load('mydict')
mydict2
# {'x': tensor([0, 1, 2, 3]), 'y': tensor([0., 0., 0., 0.])}
加载和保存模型参数
class MLP(nn.Module):
def __init__(self):
super().__init__()
print('init方法')
self.hidden = nn.Linear(20,256)
self.output = nn.Linear(256,10)
def forward(self,x):
print('forward方法')
return self.output(F.relu(self.hidden(x)))
net = MLP() # 调用init方法
X = torch.rand(size=(2,20))
Y = net(X) # 调用forward方法
Y
将模型的参数存储为一个叫做“mlp.params”的文件
torch.save(net.state_dict(),'mlp.params')
实例化了原始多层感知机模型的一个备份。 直接读取文件中存储的参数
clone = MLP()
clone.load_state_dict(torch.load('mlp.params'))
clone.eval() # eval()是进入测试模式
#MLP(
# (hidden): Linear(in_features=20, out_features=256, bias=True)
# (output): Linear(in_features=256, out_features=10, bias=True)
#)
- eval()
train模式(net.train())和eval模式(net.eval())。一般的神经网络中,这两种模式是一样的,只有当模型中存在dropout和batchnorm的时候才有区别。
Y_clone = clone(X)
Y_clone == Y
#tensor([[True, True, True, True, True, True, True, True, True, True],
# [True, True, True, True, True, True, True, True, True, True]]
6. 使用和购买 GPU
17 使用和购买 GPU【动手学深度学习v2】_哔哩哔哩_bilibili
使用GPU
查看GPU
!nivdia-smi
计算设备
import torch
from torch import nn
torch.device('cpu'),torch.cuda.device('cuda'),torch.cuda.device('cuda:1')
#(device(type='cpu'),
# <torch.cuda.device at 0x17441a87700>,
# <torch.cuda.device at 0x1743a9fb310>)
查询可用gpu的数量
torch.cuda.device_count()
# 1
这两个函数允许我们在请求的GPU不存在的情况下运行代码
def try_gpu(i=0):
"""如果存在,则返回gpu(i),否则返回cpu()。"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus():
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]。"""
devices = [
torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()
查询张量所在的设备
x = torch.tensor([1,2,3])
x.device
# device(type='cpu')
存储在GPU上
X = torch.ones(2,3,device=try_gpu())
X
# tensor([[1., 1., 1.],
# [1., 1., 1.]], device='cuda:0')
第二个GPU上创建一个随机张量(我这里只有一个GPU)
Y = torch.rand(2,3,device=try_gpu(1))
Y
# tensor([[0.4715, 0.7644, 0.9245],
# [0.7446, 0.4850, 0.3053]])
要计算X + Y,我们需要决定在哪里执行这个操作,计算时X和Y必须是在同一个GPU或者更CPU
Z = X.cuda(0)
print(X)
print(Z)
否者会报错

现在数据在同一个GPU上(Z和Y都在),我们可以将它们相加
Y + Z # Y是在cpu上,Z是在cuda:0上相加会报错

CPU和GPU之间的转换
# CPU -> GPU
Y = Y.cuda(0)
print(Y)
#tensor([[0.0572, 0.3974, 0.2410],
# [0.3487, 0.1877, 0.5901]], device='cuda:0')
# GPU -> CPU
device = torch.device('cpu')
Z = Z.to(device)
print(Z.device)
# cpu
判断在那个gpu
Y.cuda(0) is Y
# true
神经网络与GPU
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())
net(X)
# tensor([[-0.6617],
# [-0.6617]], device='cuda:0', grad_fn=<AddmmBackward0>)
确认模型参数存储在同一个GPU上
net[0].weight.data.device
# device(type='cuda', index=0)
问答
1.一般使用gpu训练,data在哪一步to gpu比较好
答:在network之前最好
2.tensor.cuda和to(device)有什么区别
答:module只能用to(device)
3.想问一下在GPU上的推理是什么意思?这里的推理具体是指的什么?
答:就是做inference,不做training,在GPU上forward
7. 卷积
19 卷积层【动手学深度学习v2】_哔哩哔哩_bilibili
从全连接到卷积
分类猫和狗的图片

回顾:单隐藏层MLP
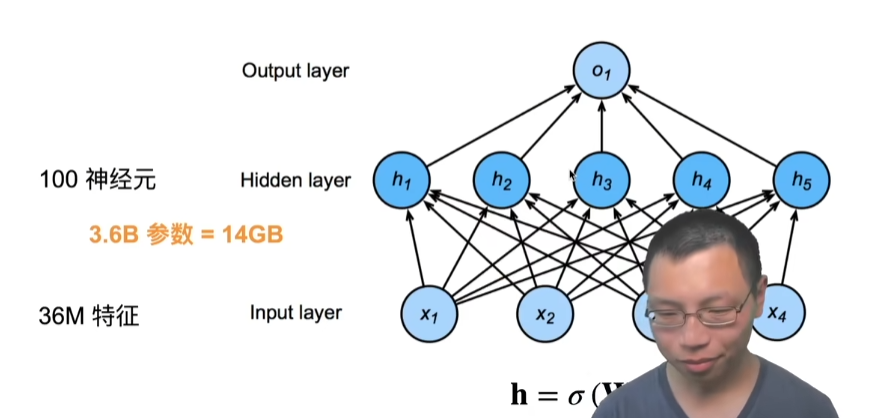
重新考虑全连接层
之前全连接层,虽然一个图片有高和宽,是一个矩阵,但是我们把它作为一个一维的向量,现在我们是要还原成一个矩阵,因为要考虑空间的信息,必须要用矩阵来存。
这里我们将输入和输出从向量变成一个矩阵,这个矩阵有宽度和高度这两个维度。那么对应的,我们可以把权重变为4维的张量(之前是输入长度的变化到输出长度的变化,现在是输入高宽到输出高宽的变化,所以可以reshape成一个4维的张量),想一下,如果是输入x是一个向量,那么它的w是二维的,现在x变成2维的,那么w是不是也要跟着变。

-
hi,j是输出,之前是hi,现在变成2个纬度,所以i变成了i和j
-
x是输入,变成矩阵后,有个k和l选项
-
w就是之前全连接层的权重,之前是二维,现在变成四维,我们知道我们得到输出的值是矩阵的一行乘以输入的向量(wx,相乘时是w的一行去乘以x,x是输入),现在我们变为矩阵了,求和的是k和l这两个坐标了,这么想:W是个二维矩阵(平面), Wij是平面上的点,这个点上塞了个宽为k,高为l的二维矩阵(矩形)
-
V是W的重新索引
两个原则
- 平移不变性,在图片任何一个地方识别一个东西,这个识别器不会发生变化
- 局部性
平移不变性

x如果偏移一点的话,对应的V也会发生变化,i和j变化应该不引起V的变化,不管你i和j怎么变,V应该是要不变的,需要加一个限制使得vi,j,a,b=va,b,相当于v的前两个维度不变的是常数,然后把前面两个纬度i和j抹掉。
不管i和j怎么变化(不管输出位置的变化),在哪个位置我那个识别器是不变的,a和b是不会发生变化的,一般叫这个是2维卷积(交叉相关)
局部性
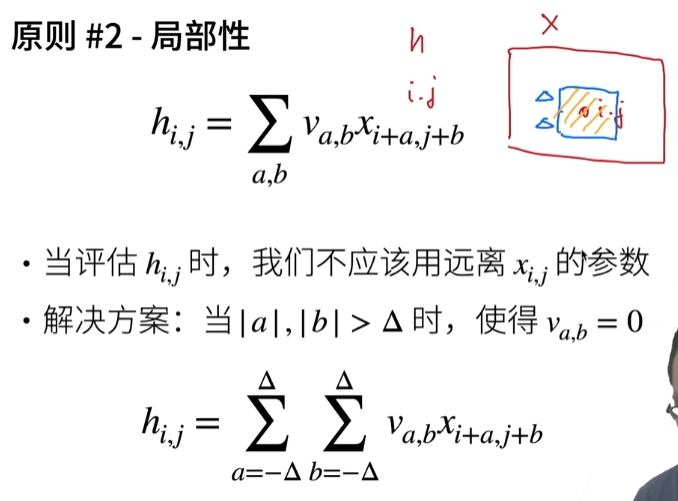
我在算hi,j的输出,以i和j为中心,a和b可以任意变化,但是我要限制a和b的范围,不用看那么远,hi,j的结果只应该由xi,j输入附近的那些点就行了。在i和j那个点,超过Δ范围,我不看,a和b的取值范围是-Δ到Δ
总结
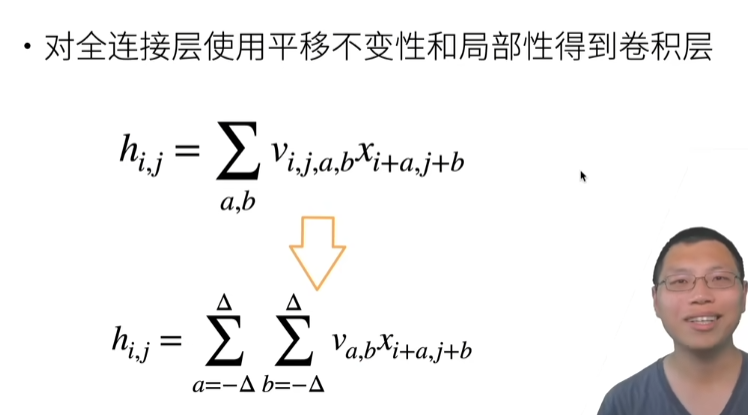
卷积是一个特殊的全连接层
卷积层
二维交叉相关
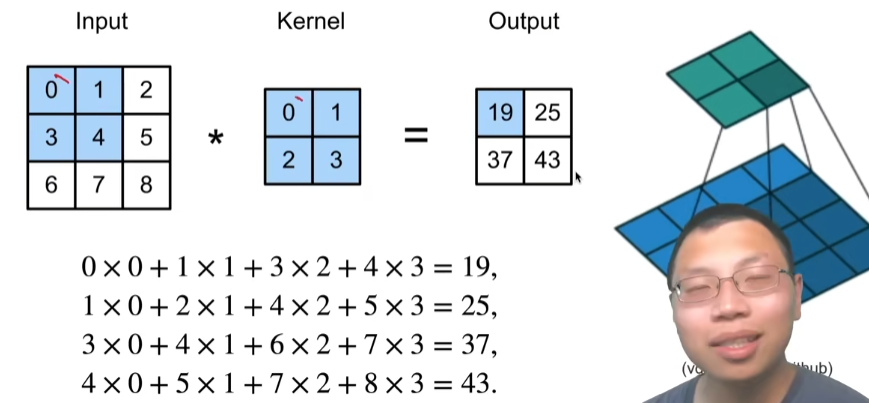
这里kernel为2×2,stride=1(delta=1,对应上面的Δ)
二维卷积层
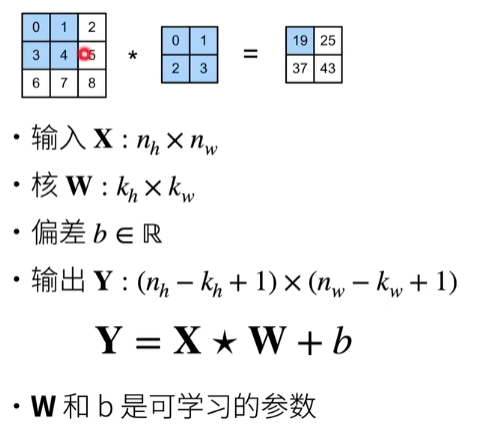
例子

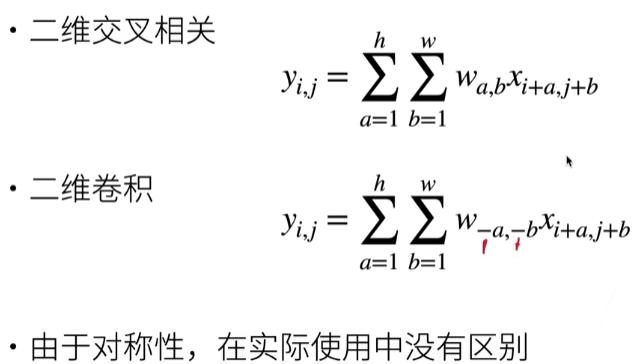
交叉相关VS卷积
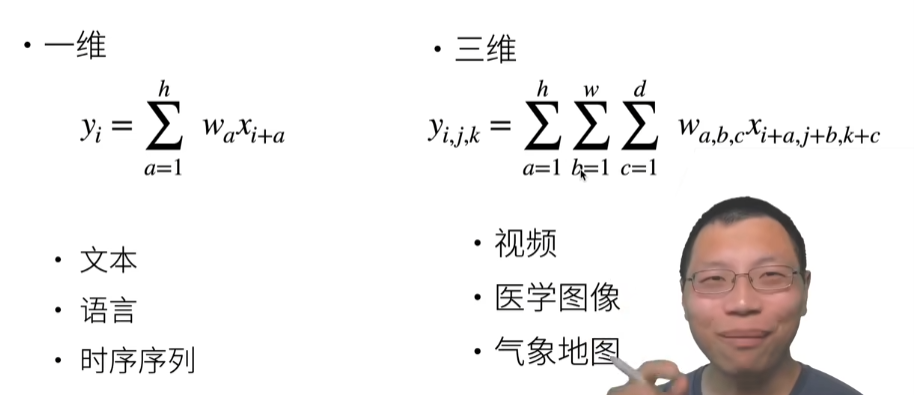
一维和三维交叉相关
总结

代码
互相关运算
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X,K):
# 计算二维互相相关
h,w = K.shape
# 定义Y的输出尺寸
Y = torch.zeros((X.shape[0] - h + 1,X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i,j] = (X[i:i+h,j:j+w] * K).sum()
return Y
验证上述二维互相关运算的输出
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
corr2d(X,K)
# tensor([[19., 25.],
# [37., 43.]])
实现二维卷积层
class Conv2D(nn.Module):
# 初始化对象会调用
def __init__(self,kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
# 调用生成好的对象时会调用forward方法
def forward(self,x):
return corr2d(x,self.weight) + self.bias
卷积层的一个简单应用: 检测图像中不同颜色的边缘
X = torch.ones((6,8))
X[:,2:6] = 0
X
# tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
# [1., 1., 0., 0., 0., 0., 1., 1.],
# [1., 1., 0., 0., 0., 0., 1., 1.],
# [1., 1., 0., 0., 0., 0., 1., 1.],
# [1., 1., 0., 0., 0., 0., 1., 1.],
# [1., 1., 0., 0., 0., 0., 1., 1.]])
K = torch.tensor([[1.0,-1.0]])
输出Y中的1代表从白色到黑色的边缘,-1代表从黑色到白色的边缘
Y = corr2d(X,K)
Y
# tensor([[ 0., 1., 0., 0., 0., -1., 0.],
# [ 0., 1., 0., 0., 0., -1., 0.],
# [ 0., 1., 0., 0., 0., -1., 0.],
# [ 0., 1., 0., 0., 0., -1., 0.],
# [ 0., 1., 0., 0., 0., -1., 0.],
# [ 0., 1., 0., 0., 0., -1., 0.]])
卷积核K只可以检测垂直边缘
corr2d(X.t(),K)
# tensor([[0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.]])
学习由X生成Y的卷积核
Conv2d — PyTorch 1.12 documentation

# 输入通道数 1:黑色图片 3:彩色图片
conv2d = nn.Conv2d(1,1,kernel_size=(1,2),bias=False)
X = X.reshape((1,1,6,8)) # batch_size in_channel height width
Y = Y.reshape((1,1,6,7))
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y)**2
conv2d.zero_grad()
l.sum().backward()
conv2d.weight.data[:] -= 3e-2 * conv2d.weight.grad
if(i + 1) % 2 == 0:
print(f'batch {i+1},loss {l.sum():.3f}')
# batch 2,loss 10.173
# batch 4,loss 1.933
# batch 6,loss 0.417
# batch 8,loss 0.108
# batch 10,loss 0.034
所学的卷积核的权重张量
# 这里的weight就是kernel
conv2d.weight.data.reshape((1,2))
# tensor([[ 1.0010, -0.9674]])
问答
1.100个神经元的单mlp,跟100维的全连接层,区别是什么?
答:没有什么区别,100个神经元的mlp的输出是100维的全连接层
2.在做房价竞赛时,自己构建的模型,画出来的损失随迭代次数变化图抖动的特别厉害,而不是像老师书上的例子,随着迭代次数增加损失很平滑的越来越小,这是什么原因呢?
答:一种是学习率,可以把学习率调大点,一种是数据的突然性比较大,可以把batch弄大点
8. 卷积层里的填充和步幅
20 卷积层里的填充和步幅【动手学深度学习v2】_哔哩哔哩_bilibili
填充和步幅
填充(pytorch里面是padding)

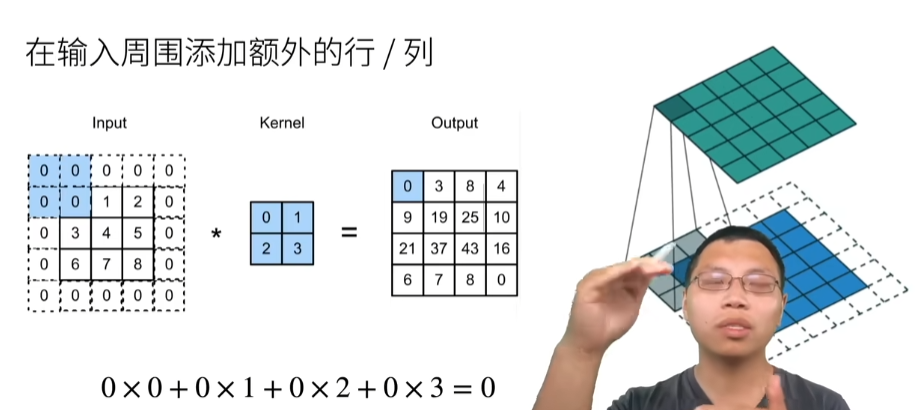

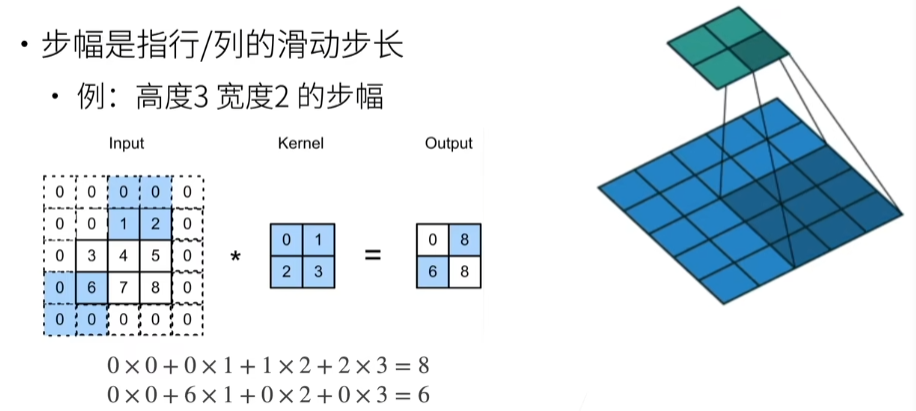
步幅(pytorch里面是stride)
这里是55层


总结

代码实现

在所有侧边填充1个像素
import torch
from torch import nn
def comp_conv2d(conv2d,X):
print(X.shape) # torch.Size([8, 8])
X = X.reshape((1,1) + X.shape) # 进行卷积操作前,需要reshape
print(X.shape) # torch.Size([1, 1, 8, 8]) # batch_size ,in_channel,height,width
Y = conv2d(X) # Y的shape是batch_size,out_channel,height,width
return Y.reshape(Y.shape[2:]) # 只取原来尺寸的height和width
conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1) # in_channel,out_channel,kernel_size,padding
# nn.Conv2d(input,kernel,padding=1) 可以通过这种方法指定kernel
print(conv2d.weight)
# tensor([[[[-0.1473, 0.3303, 0.0216],
# [-0.0944, 0.0517, -0.0717],
# [ 0.0217, 0.1375, 0.3177]]]], requires_grad=True)
X = torch.rand(size=(8,8))
comp_conv2d(conv2d,X).shape # torch.Size([8, 8])
填充不同的高度和宽度
conv2d = nn.Conv2d(1,1,kernel_size=(5,3),padding=(2,1))
comp_conv2d(conv2d,X).shape # torch.Size([8, 8])
将高度和宽度的步幅设置为2
conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1,stride=2)
comp_conv2d(conv2d,X).shape # torch.Size([4, 4])
一个稍微复杂的例子
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape # torch.Size([2, 2])
9. 卷积层里的多输入多输出通道
21 卷积层里的多输入多输出通道【动手学深度学习v2】_哔哩哔哩_bilibili
多个输入通道
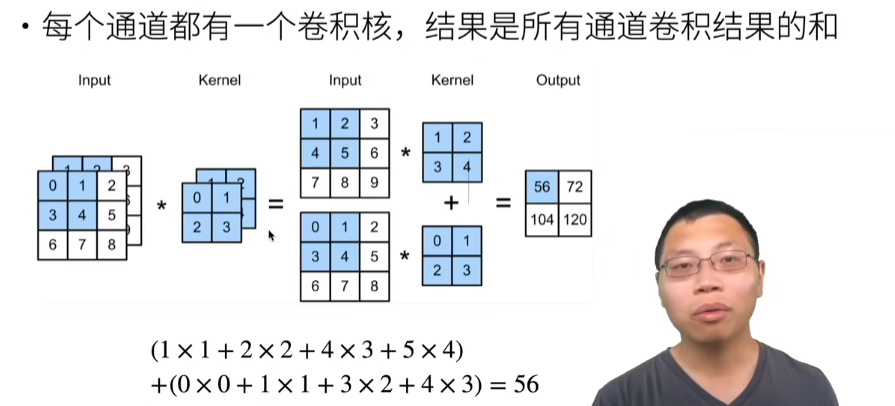
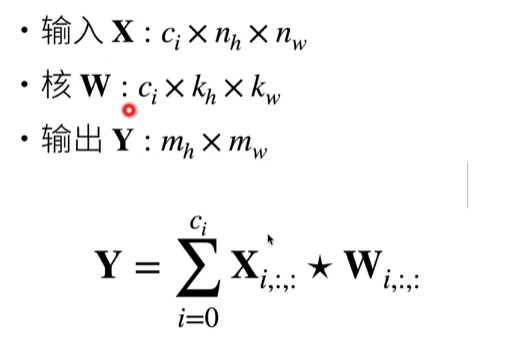
多个输出通道
co是输出通道数,ci是输入通道数。输出通道数==卷积核个数

多个输入和输出通道

1×1卷积层
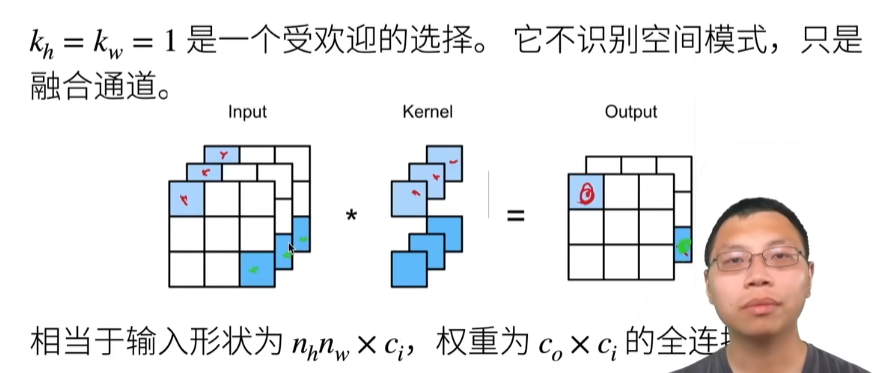
二维卷积层
下面kh=kw=5图片中是h(应该打错了)

总结

代码实现
实现一下多输入通道互相关运算
import torch
from d2l import torch as d2l
def corr2d_multi_in(X,K):
return sum(d2l.corr2d(x,k) for x,k in zip(X,K))
验证互相关运算的输出
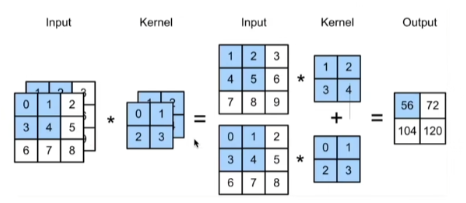
X = torch.tensor([
[
[0.0, 1.0, 2.0],
[3.0, 4.0, 5.0],
[6.0, 7.0, 8.0]
],
[
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0]
]
])
K = torch.tensor([
[
[0.0, 1.0],
[2.0, 3.0]
],
[
[1.0, 2.0],
[3.0, 4.0]
]
])
corr2d_multi_in(X,K)
# tensor([[ 56., 72.],
# [104., 120.]])
计算多个通道的输出的互相关函数
def corr2d_multi_in_out(X,K):
return torch.stack([corr2d_multi_in(X,k) for k in K],0)
K = torch.stack((K,K+1,K+2),0) # 0是按第0维进行堆叠
print(K)
K.shape

corr2d_multi_in_out(X,K)

1x1卷积
def corr2d_multi_in_out_1x1(X,K):
c_i,h,w = X.shape
c_o = K.shape[0]
print('---')
print(c_o) # 2
X = X.reshape((c_i,h * w))
print(X.shape) # torch.Size([3, 9])
K = K.reshape((c_o,c_i))
print(K.shape) # torch.Size([2, 3])
Y = torch.matmul(K,X)
print(Y.shape) # torch.Size([2, 9])
return Y.reshape((c_o,h,w))
#输入通道数=每个核的通道数,输出通道数=卷积核的个数
X = torch.normal(0,1,(3,3,3))
K = torch.normal(0,1,(2,3,1,1)) # out_channel,in_channel,height,width
print(X)
print(K)
Y1 = corr2d_multi_in_out_1x1(X,K)

10. 池化层
22 池化层【动手学深度学习v2】_哔哩哔哩_bilibili

- x最左边第二列和第三列中间有一个边缘,如果用一个1*2的卷积核(一边是1,一边是-1),就会在输出的第二列全部为1,也就意味着将边缘全部检测出来了,但是这一列的左边是0右边也是0,也就是说它对位置是非常敏感的,一个像素的偏移就会导致0输出
- 所以这不是一件特别好的事情,因为边缘在真实图片中很有可能不是很规矩,可能会有弯曲的地方,而且相机的抖动或者物体的移动都会导致边缘发生变化,所以需要一定的平移不变性(输入稍微有一点改动,输出不会有太大的变化,减低卷积核对位置的敏感程度) 作者:如果我是泡橘子 https://www.bilibili.com/read/cv14568802?from=note 出处:bilibili
二维最大池化层
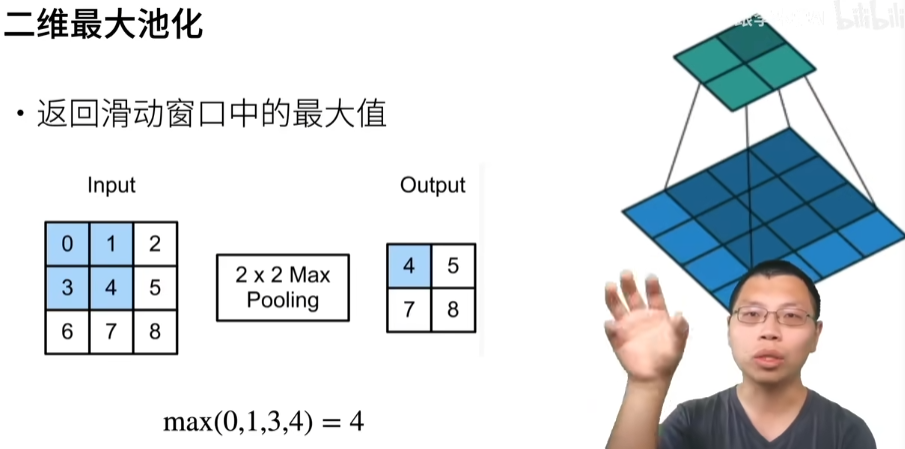
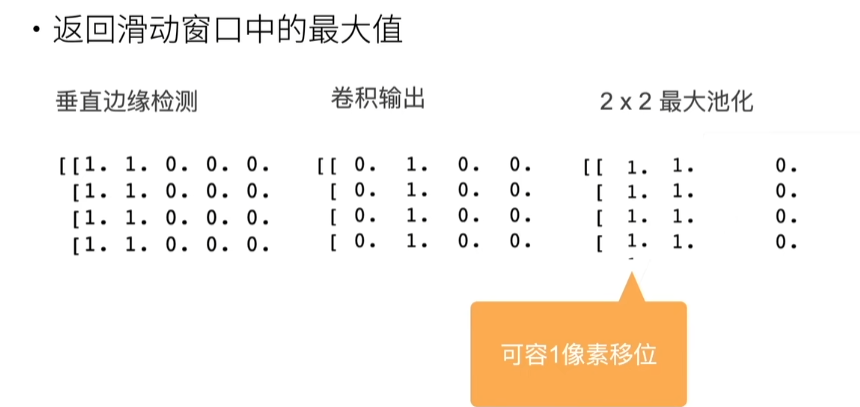
填充,步幅和多个通道

平均池化层

总结

代码实现
实现池化层的正向传播
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X,pool_size,mode='max'):
p_h,p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1,X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i,j] = X[i:i + p_h,j:j + p_w].max()
elif mode == 'avg':
Y[i,j] = X[i:i + p_h, j:j + p_w].mean()
return Y
验证二维最大池化层的输出
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
pool2d(X, (2, 2))
# tensor([[4., 5.],
# [7., 8.]])
验证平均池化层
pool2d(X, (2, 2), 'avg')
# tensor([[2., 3.],
# [5., 6.]])
深度学习框架中的步幅与池化窗口的大小相同

X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
X
pool2d = nn.MaxPool2d(3)
pool2d(X)
池化层在每个输入通道上单独运算
X = torch.cat((X, X + 1), 1)
X
# tensor([[[[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.]],
# [[ 1., 2., 3., 4.],
# [ 5., 6., 7., 8.],
# [ 9., 10., 11., 12.],
# [13., 14., 15., 16.]]]])
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
# tensor([[[[ 5., 7.],
# [13., 15.]],
# [[ 6., 8.],
# [14., 16.]]]])
11. 经典卷积神经网络LeNet
23 经典卷积神经网络 LeNet【动手学深度学习v2】_哔哩哔哩_bilibili
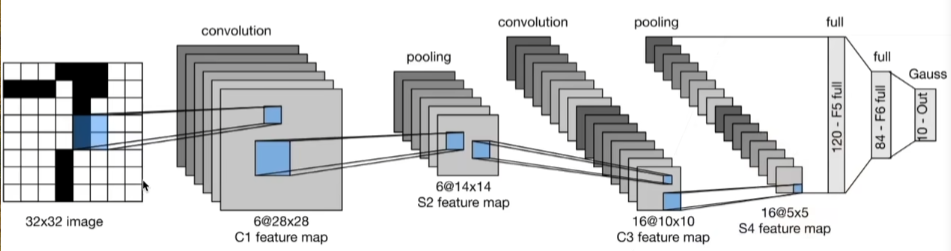
总结

代码实现
LeNet(LeNet-5)由两个部分组成: 卷积编码器和全连接层密集块
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self,x):
return x.view(-1,1,28,28) # -1就是根据输入和其他参数自动补齐这个维度,不需要你去计算了
net = torch.nn.Sequential(
Reshape(),
nn.Conv2d(1,6,kernel_size=5,padding=2),
nn.Sigmoid(), # 得到非线性
nn.AvgPool2d(kernel_size=2,stride=2), # kernel_size,stride是根据论文复现的
nn.Conv2d(6,16,kernel_size=5),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5,120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
- x.view()
【Pytorch】:x.view() view()方法的使用_mob604756f99da6的技术博客_51CTO博客
进行维度的变化
- 为什么不用ReLU
LeNet出来的时候还没有ReLU
- padding=2
输入要求是32,原始输入是28,加上两个padding后28 + 2* 2 = 32
检查模型,查看每一层的模型参数
X = torch.rand(size=(1,1,28,28),dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)

LetNet在Fashion-MNIST数据集上的表现
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
对 evaluate_accuracy函数进行轻微的修改
def evaluate_accuracy_gpu(net,data_iter,device=None):
# 使用GPU计算模型在数据集上的精度
if isinstance(net,torch.nn.Module):
net.eval()
if not device:
device = next(iter(net.parameters())).device
metric = d2l.Accumulator(2)
for X,y in data_iter:
if isinstance(X,list):
X = [x.to(device) for x in X]
else: # tensor类型
X = X.to(device)
y = y.to(device)
# 累加精度和个数,最后总精度除以总数就是精度值了
metric.add(d2l.accuracy(net(X),y),y.numel())
return metric[0] / metric[1]
为了使用 GPU,我们还需要一点小改动
def train_ch6(net,train_iter,test_iter,num_epochs,lr,device):
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on',device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(),lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer,num_batches = d2l.Timer(),len(train_iter)
for epoch in range(num_epochs):
metric = d2l.Accumulator(3)
net.train()
for i,(X,y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X,y = X.to(device),y.to(device)
y_hat = net(X)
l = loss(y_hat,y)
l.backward()
optimizer.step()
metric.add(l * X.shape[0],d2l.accuracy(y_hat,y),X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
- net.train() net.eval()
Pytorch的net.train 和 net.eval的使用_Never-Giveup的博客-CSDN博客_net.eval
【pytorch学习笔记4】net.train()和net.eval() - 知乎 (zhihu.com)
训练和评估LeNet-5模型
lr,num_epochs = 0.9,10
train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())
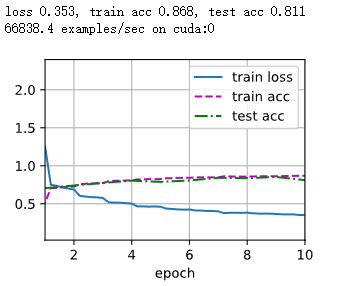
问答
1.池化和卷积是不是更适合图像这类型的数据,而对于时序性数据(做分类)是不是不适用这类数据?
答:时序是可以用卷积的(一维卷积),池化这个建议用一下,用了也没有什么坏处
2.LeNet的第二个卷积层通道数增加到了16,这意味信息被放大了吗?或者说信息在通道中是怎么流通的?
答:通常做法是高宽减半的时候,我会把通道数加两倍,虽然高宽减少,通道数增加,但是总体上信息还是减少了
3.为什么用view而不用reshape呢?
答:view不会对数据的构造发生变化,reshape比view功能更高,可以帮你挪数据,可能会比较慢,reshape会改变内容存储位置,view不会改变,有些情况下会报错
4.Conv2d 6->16, 16个通道是怎么取前面6个通道的信息的(每个都取,还是按一定组合取) ?
答:16个核 每个核都去卷6个通道求和再输出(参考上面的多通道输出)
5.输出通道增多,这些增加的信息是些什么?可以理解是随机扩充的图片信息么?
答:输出通道很大程度上可以理解为匹配的某种特征和模式
6.池化层一般用max还是avg, 用max的话会不会损失很多信息?
答:max只关心里面最大的信号,比如说你要找图片里面有没有狗,我关心里面有没有出现最大的那个pattern,如果这个pattern出现,那么它的值会很大
7.老师,为什么用了一层卷积,就从1个通道变成了6个通道?是每个通道用了不同的卷积核吗?
答:输出通道数==卷积核个数
8.在跑的动的情况下,中间计算层的输出通道尽量调大么?
答:不一定,大的话,偶尔会过拟合
12. 深度卷积神经网络AlexNet
24 深度卷积神经网络 AlexNet【动手学深度学习v2】_哔哩哔哩_bilibili
AlexNet架构
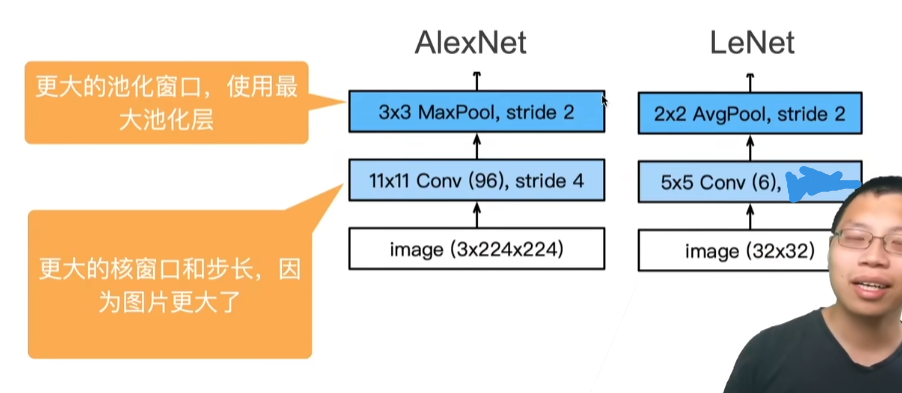
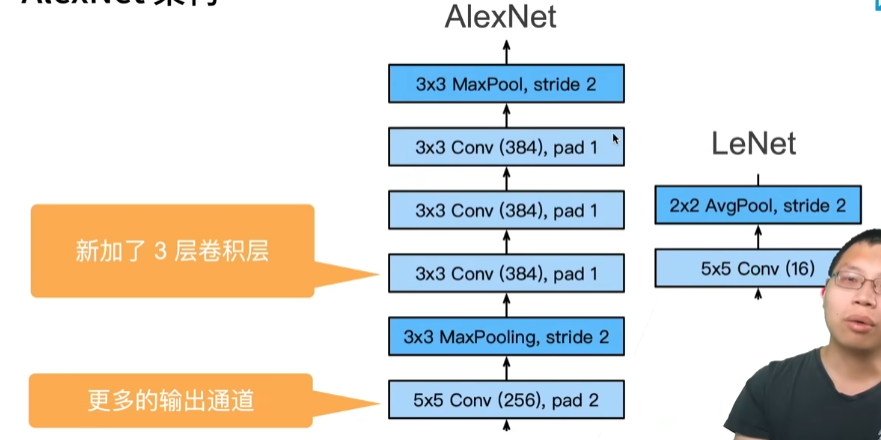
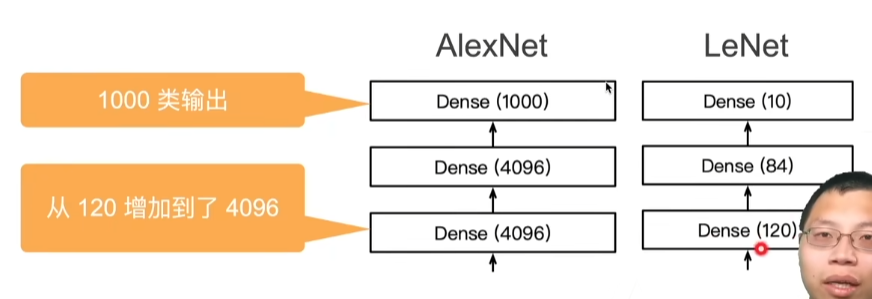
- dense
全连接
更多细节

总结

代码实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1,96,kernel_size=11,stride=4,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(96,256,kernel_size=5,padding=2)
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(256,384,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(384,384,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(384,256,kernle_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Flatten(),
nn.Linear(6400,4096),
nn.ReLU(),
nn.Dropout(p=0.5)
nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(p=0.5)
nn.Linear(4096,10)
)
我们构造一个 单通道数据,来观察每一层输出的形状
X = torch.randn(1,1,224,224)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
下图中的1是batch_size

Fashion-MNIST图像的分辨率 低于ImageNet图像。 我们将它们增加到 224×224
batch_size = 128
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
训练AlexNet
lr,num_epochs = 0.01,10
d2l.train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())
速度太慢了,而且显卡温度提起来,所以就没跑了
13. 使用块的网络 VGG
25 使用块的网络 VGG【动手学深度学习v2】_哔哩哔哩_bilibili
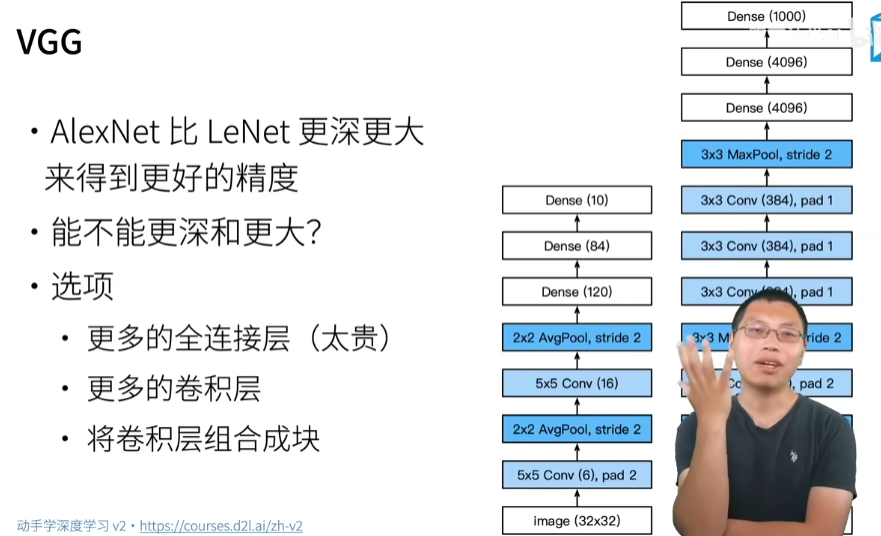
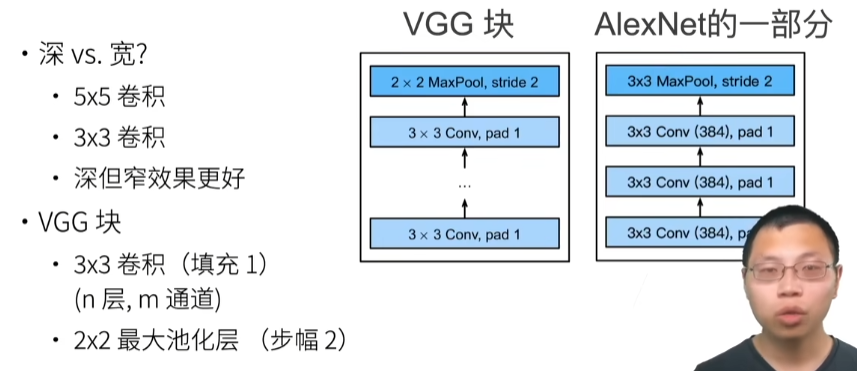
VGG架构
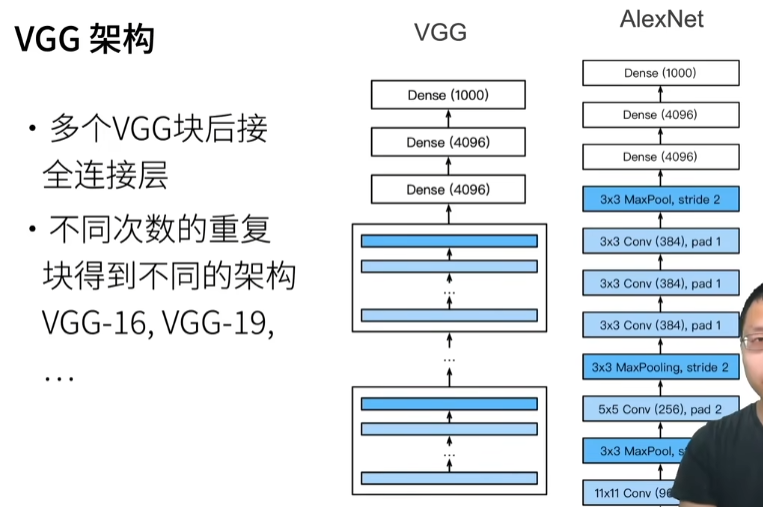
进度
总结

代码实现
VGG块
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs,in_channels,out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1))
layers.append(nn.ReLU())
in_channels = out_channels # 下一层的in_channels就是上一层的out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
VGG网络
conv_arch = ((1,64),(1,128),(2,256),(2,512),(2,512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs,out_channels) in conv_arch:
conv_blks.append(vgg_block(
num_convs,in_channels,out_channels
))
in_channels = out_channels # 下一层的in_channels就是上一层的out_channels
return nn.Sequential(
*conv_blks,
nn.Flatten(),
nn.Linear(out_channels * 7 * 7,4096),
nn.ReLU(),
nn.Dropout(0.5),nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(0.5),nn.Linear(4096,10)
)
net = vgg(conv_arch)
net

观察每个层输出的形状
X = torch.randn(size=(1,1,224,224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape: \t',X.shape)
图中的1是batch_size也就是输出后参数里面N,不是输入参数里面的in_channels,下图都是输出的结果,输出的参数里面第一个是N(batch_size)

由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络
ratio = 4
# 把所有的通道数除以4
small_conv_arch = [(pair[0],pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
net
模型训练
lr,num_epochs,batch_size = 0.05,10,128
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
d2l.train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())
问答
1.训练loss-直下降测试loss从开始起就一点不降 成水平状是什么原因呢?
答:1.代码写错了,2.过拟合了,测试数据和训练数据完全不一样
14. NiN网络中的网络
26 网络中的网络 NiN【动手学深度学习v2】_哔哩哔哩_bilibili
全连接层的问题

因为卷积后第一个全连接层比较大,所以导致以下问题
- 需要用很大的内存
- 占用很多的计算带宽
- 很容易过拟合
为了解决这个问题NIN的思想是,我完全不要全连接层
NiN块
1×1的卷积层相当于全连接层,作用把通道做一些融合,这个块可以看做一个非常简单的卷积网络,只有一个卷积层和两层全连接层(1×1卷积层),不同的是这里全连接层是对每一个像素做全连接
NiN架构

总结

这几个模型有几个共同特征:1、全连接层很占内存 2、卷积核越大越占内存 3、层数越多越占内存 4、模型越占内存越难训练 得出一个结论:多用11、33 卷积、 AdaptiveAvgPool2d替代全连接 既可以加快速度,又可以达到与全连接、大卷积核一样的效果。还有一个规律,就是图像尺寸减半,同时通道数指数增长,可以很好地保留特征。
代码实现
NiN块
import torch
from torch import nn
from d2l import torch as d2l
# 注意conv2d和maxpool里面的是步幅是stride,后面没有加s,这里的strides只是个参数而已
def nin_block(in_channels,out_channels,kernel_size,strides,padding):
return nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size,strides,padding),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU()
)
NiN模型
net = nn.Sequential(
nin_block(1,96,kernel_size=11,strides=4,padding=0),
nn.MaxPool2d(3,stride=2),
nin_block(96,256,kernel_size=5,strides=1,padding=2),
nn.MaxPool2d(3,stride=2),
nin_block(256,384,kernel_size=3,strides=1,padding=1),
nn.MaxPool2d(3,stride=2),nn.Dropout(0.5),
nin_block(384,10,kernel_size=3,strides=1,padding=1),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten()
)
查看每个块的输出形状
X = torch.rand(size=(1,1,224,224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)

训练模型
lr,num_epochs,batch_size = 0.1,10,128
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size,resize=224)
d2l.train_ch6(net,train_iter,test_iter,num_epochs,lr,d2l.try_gpu())
问答
1.一个超级宽的:单隐藏层难以训练是因为显存不够大吗?
答:不是显存问题,它是很容易过拟合,效果很差
15. GoogleNet含并行连结的网络
27 含并行连结的网络 GoogLeNet / Inception V3【动手学深度学习v2】_哔哩哔哩_bilibili
Inception块
只改变高宽,不改变通道数
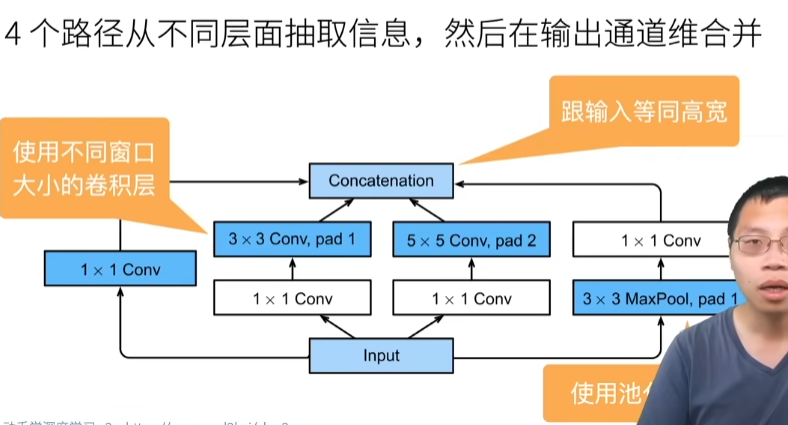
- 白色卷积是变更通道数
- 蓝色卷积可以是抽取信息
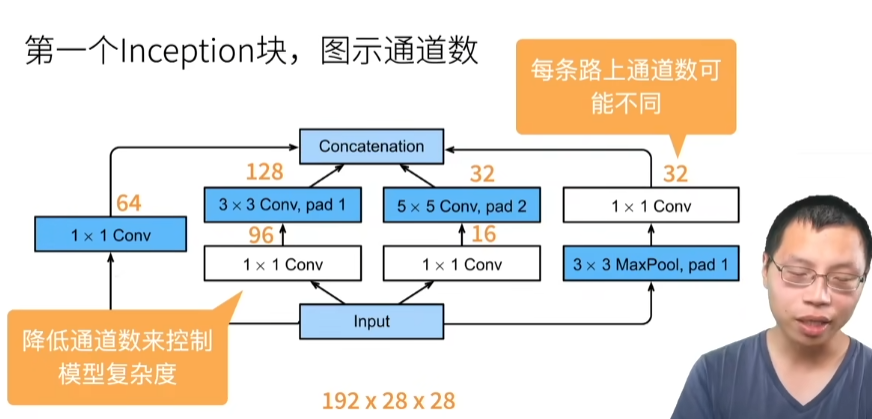
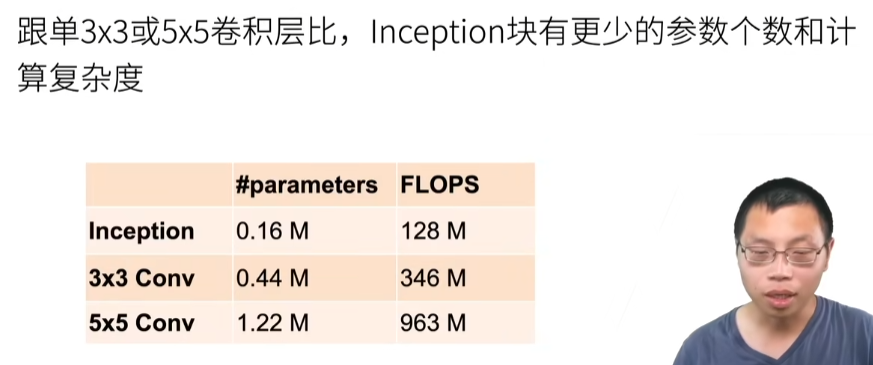
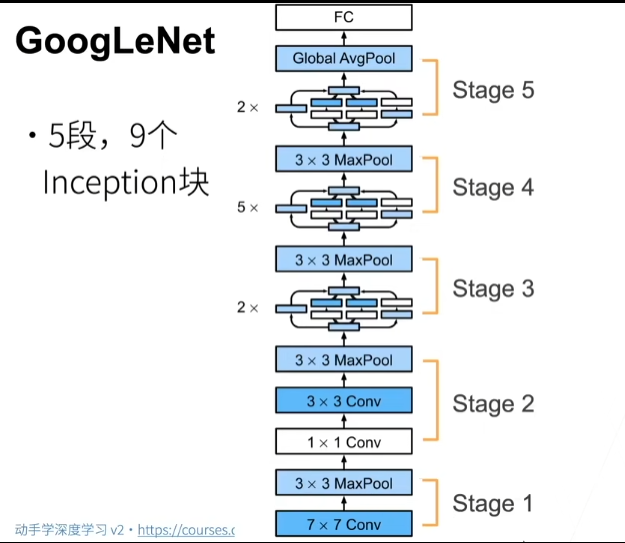
段1&2
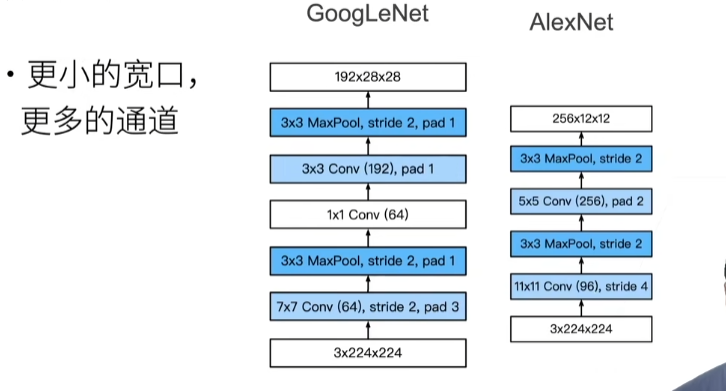
段3
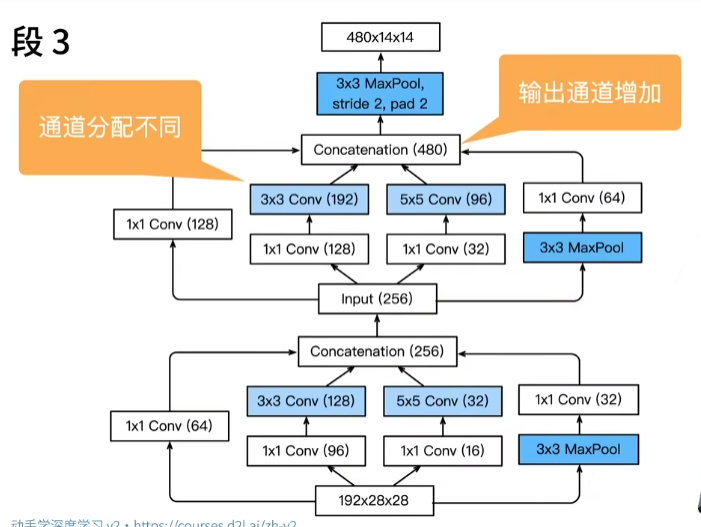
段4 & 5
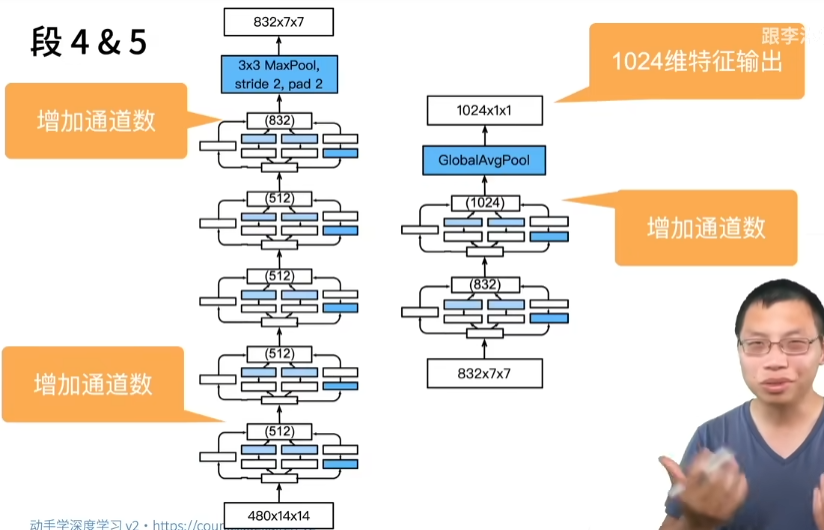

总结

代码实现
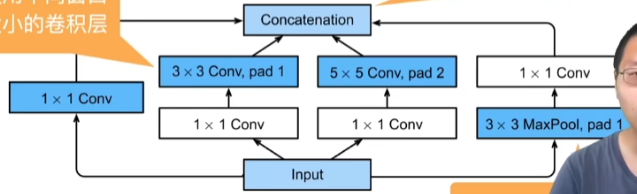
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
def __init__(self,in_channels,c1,c2,c3,c4,**kwargs):
super(Inception,self).__init__(**kwargs)
self.p1_1 = nn.Conv2d(in_channels,c1,kernel_size=1)
self.p2_1 = nn.Conv2d(in_channels,c2[0],kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0],c2[1],kernel_size=3,padding=1)
self.p3_1 = nn.Conv2d(in_channels,c3[0],kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0],c3[1],kernel_size=5,padding=2)
self.p4_1 = nn.MaxPool2d(kernel_size=3,stride=1,padding=1)
self.p4_2 = nn.Conv2d(in_channels,c4,kernel_size=1)
def forward(self,x):
p1 = F.relu(self.p1_1)
p2 = F.relu(self.p2_2(F.relu(self.p2_1)))
p3 = F.relu(self.p3_2(F.relu(self.p3_1)))
p4 = F.relu(self.p4_2(self.p4_1))
return torch.cat((p1,p2,p3,p4),dim=1)
- nn.ReLU()和F.relu()
其实这两种方法都是使用relu激活,只是使用的场景不一样,F.relu()是函数调用,一般使用在foreward函数里。而nn.ReLU()是模块调用,一般在定义网络层的时候使用。
pytorch:F.relu() 与 nn.ReLU() 的区别_Caesar6666的博客-CSDN博客_nn.relu和f.relu
- super()
【Pytorch】self参数, __ init__ ()方法 和 super(Model, self).init() - 知乎 (zhihu.com)
GoogLeNet模型
b1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
)
b2 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=1),
nn.ReLU(),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
b3 = nn.Sequential(
Inception(192,64,(96,128),(16,32),32),
Inception(256,128,(128,192),(32,96),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=2)
)
b4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten()
)
net = nn.Sequential(b1,b2,b3,b4,b5,nn.Linear(1024,10))
为了使Fashion-MNIST上的训练短小精悍,我们将输入的高和宽从224降到96
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)

- torch.rand()和torch.randn()
rand():均分分布,包含了从区间[0, 1)的均匀分布中抽取的一组数
randn():正太分布,均值为0,方差为1,即高斯白噪声
- padding要求比较小或者是kerne_size的一半

训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
问答
1.3×3和5×5也可以减低通道数,为什么前面还要用1×1的?
答:如果不降低通道数,计算量太大了,1×1可以把复杂度降下来,如果没有1×1的话,后面的计算量太大了。
16. 批量归一化Batch Normalization
28 批量归一化【动手学深度学习v2】_哔哩哔哩_bilibili

底部的数据一变,上面的会跟着变,会导致收敛比较慢,所以我们可以在学习底部的时候,避免底部的重新训练。
为什么会变?
因为方差和均值整个分布会在不同层变化,一个简单方法是我把分布固定住了,就比较稳定了。
批量归一化的思想是尝试把一个小批量在不同层的不同地方的输出的均值固定了

μB是均值,σB是开根号后的方差,图中写错了
这里的B就是我的小批量

为什么放在激活函数之前?
如果你放在relu之后,relu把所有的数变为正数,又要重新训练,批量归一化是一个线性变化。
对全连接层作用在特征维(输入的数据是一个二维数组,每一行是样本,每一列是特征)
在每个批量里,1个像素是1个样本。与像素(样本)对应的通道维,就是特征维
1×1的卷积层等价于全连接层,等价的意思是对每一个像素,如果你的通道数是100的话,这个像素有一个长为100维的向量,那么这个向量可以是像素的特征,对于一个卷积层来说,你的输入如果是批量大小×高×宽×通道数的话,那么你的样本数是批量大小×高×宽,就是整个批量里面所有的像素都是一个样本,那么它对应的通道就是一个特征。

总结

用了批量归一化,可以把学习率调大一点,那么收敛速度会快一点,可以避免梯度爆炸和梯度消失问题
代码实现
import torch
from torch import nn
from d2l import torch as d2l
# X 输入的那个样本
# gamma和beta是可以学习到的,在recover里面的
# gamma是一个向量,向量长度等于你的数据里面它的特征纬度的个数
# moving_mean,moving_var 全局的均值和方差,在做推理(预测)的时候用的
# eps 避免除0的东西
# momentum,更新moving_mean和var的东西
def batch_norm(X,gamma,beta,moving_mean,moving_var,eps,momentum):
# 做预测的时候
if not torch.is_grad_enabled():
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else: # 做训练的时候
assert len(X.shape) in (2,4) # 2是全连接层,4是卷积层
if len(X.shape) == 2:
mean = X.mean(dim=0) # 0意味着跨行算每一列的均值
var = ((X - mean)**2).mean(dim=0) # 对于全连接层,作用在特征维上
else:
mean = X.mean(dim=(0,2,3),keepdim=True)
var = ((X - mean)**2).mean(dim=(0,2,3),keepdim=True) # 对于卷积层,作用在通道上
X_hat = (X - mean) / torch.sqrt(var + eps)
# 滑动平均
moving_mean = momentum * movin_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta
return Y,moving_mean.data,moving_var.data
- 2维和4维
2 代表全连接层 (batch_size, feature) ,4 代表2D卷积层 (batch_size, channels, height, width)
创建一个正确的 BatchNorm 图层
class BatchNorm(nn.Module):
def __init__(self,num_features,num_dims):
super().__init__()
if num_dims == 2:
shape = (1,num_features)
else:
shape = (1,num_features,1,1)
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self,X):
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
Y,self.moving_mean,self.moving_var = batch_norm(
X,self.gamma,self.beta,self.moving_mean,self.moving_var,
eps = 1e-5,momentum=0.9
)
return Y
- nn.Parameter()
将一个固定不可训练的tensor转换成可以训练的类型parameter
PyTorch37.torch.nn.Parameter() - 知乎 (zhihu.com)
- gamma和beta是要被迭代的
应用BatchNorm 于LeNet模型
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4),
nn.Sigmoid(), nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16,
kernel_size=5), BatchNorm(16, num_dims=4),
nn.Sigmoid(), nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(), nn.Linear(16 * 4 * 4, 120),
BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2),
nn.Sigmoid(), nn.Linear(84, 10))
在Fashion-MNIST数据集上训练网络
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
print(next(iter(train_iter))[0].shape) # torch.Size([256, 1, 28, 28])
d2l.train_ch6(net,train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
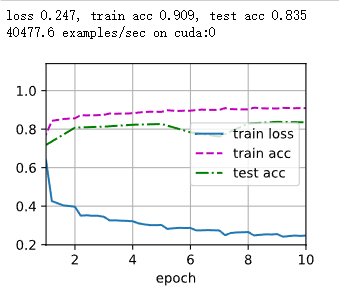
简洁实现
net = nn.Sequential(
nn.Conv2d(1,6,kernel_size=5),
nn.BatchNorm2d(6),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),
nn.BatchNorm2d(16),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(256,120),
nn.BatchNorm1d(120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.BatchNorm1d(84),
nn.Sigmoid(),
nn.Linear(84,10)
)
问答
1.BN层是不是一般用于深层网络,浅层MLP加上BN效果好像不好
答:是的
2.不太理解,为啥加了batch norm收敛时间变短
答:用了batch norm后可以使用大的learning rate,batch norm本身会使梯度变大一点
3.batch horm可以加在激活函数之后么?
答:不行
17. 残差网络ResNet
29 残差网络 ResNet【动手学深度学习v2】_哔哩哔哩_bilibili
模型越复杂不一定精度越高,例如左边F6离f'的距离就明显小于F1和F2,虽然模型比较复杂,但是可能学偏了,可能学的那块还不如小模型和最优解离得近,就像下图中左边那个None-nested function classes。
那么怎么做了,如果我每次增加模型复杂度,每一次更复杂的模型是包含前面的模型,模型会更大,至少不会变差。就如右边的Nested function classes
核心思想
残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一
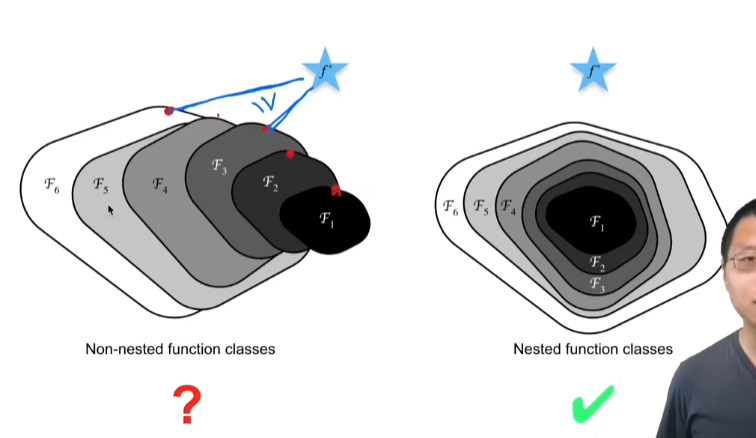
残差块
左图是正常块,右图是残差块
当f(x)不起作用的时候,我还是包括一个小模型,因为学习的就是残差,y=x+residual
ResNet块细节
不同的残差块
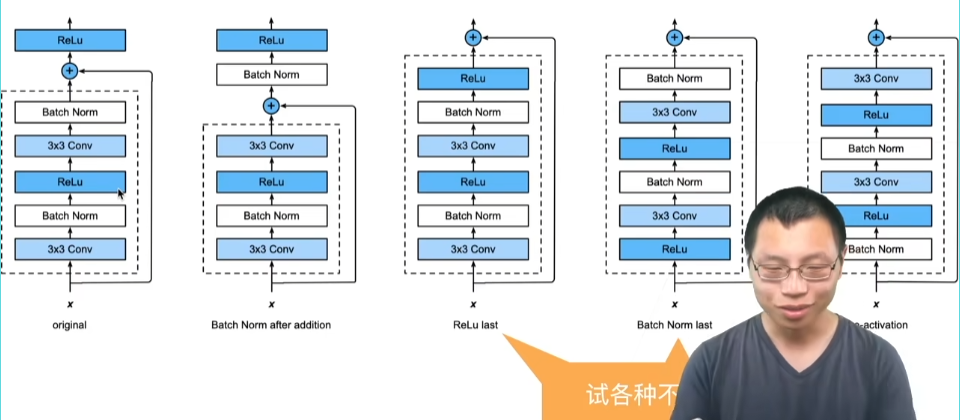
ResNet块
ResNet架构
总结

- 恒等映射,网络退化
深度残差网络——ResNet学习笔记 - 我的明天不是梦 - 博客园 (cnblogs.com)
代码实现
定义残差块
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module):
def __init__(self,input_channels,num_channels,use_1x1conv=False,strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels,num_channels,kernel_size=3,
padding=1,stride=strides)
self.conv2 = nn.Conv2d(num_channels,num_channels,kernel_size=3,
padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels,num_channels,kernel_size=1,stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True) # inplace会损失一些内存
def forward(self,X):
Y = F.relu(self.bn1(self.conv2(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
输入和输出形状一致
blk = Residual(3,3)
X = torch.rand(4,3,6,6) # 没有增加通道数的话,输入和输出形状一致
Y = blk(X)
Y.shape
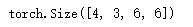
增加输出通道数的同时,减半输出的高和宽
blk = Residual(3, 6, use_1x1conv=True, strides=2)
blk(X).shape # torch.Size([4, 6, 3, 3])
ResNet模型
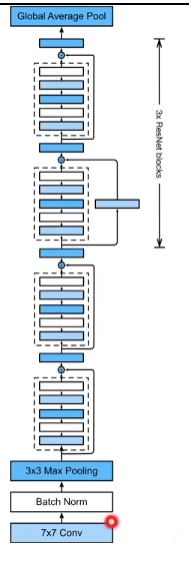
b1 = nn.Sequential(nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
def resent_block(input_channels,num_channels,num_residuals,first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels,num_channels,use_1x1conv=True,
strides=2)) # stride=2,会让高宽减半,通道数增加
else:
blk.append(Residual(num_channels,num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64,64,2,first_block=True))
b3 = nn.Sequential(*resnet_block(64,128,2))
b4 = nn.Sequential(*resnet_block(128,256,2))
b5 = nn.Sequential(*resnet_block(256,512,2))
net = nn.Sequential(b1,b2,b3,b4,b5,nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),nn.Linear(512,10))
- b1
相当于最下面的一个7×7卷积核,BN,3×3池化
- b2
b2中指定num_residual的个数是2,而且没有指定使用1×1conv
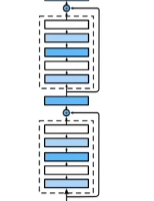
- b3,b4,b5
b3,b4,b5中指定使用了1×1conv,使用了1×1conv后,可以接多个residual,这些residual的高宽不变
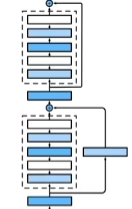
观察一下ResNet中不同模块的输入形状是如何变化的
X = torch.rand(size=(1,1,224,224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)

-
第一个56是224÷4=56
-
第二个是residual block
-
其他的残差网络都高宽减半,通道数增加了
训练模型
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
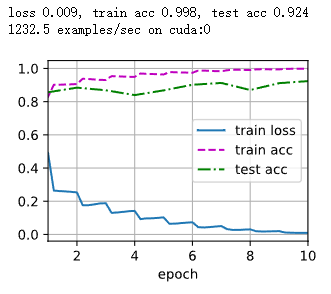
问答
1.f(x)=X+ g(x),这样就能保证至少不会变坏吗?如果g(x)不是变好,也不是什么都不干,而是变坏了呢?
答:如果我发现模型g(x)不好训练,它就不会拿到梯度,如果发现直接拿X过去,效果已经很好了,那么加个g(x)对我的loss没有影响,resnet在加深的时候,通常不会让模型变坏
2.为什么可以训练1000层?
答:如果只是普通的堆叠,根据链式法则可以求出梯度,这时候是乘法,如果某一项比较小,可能导致整个式子比较小,越到底层乘积就越小。解决方法是把乘法变为加法,大数加上一个小数还是一个大数,但是大数乘以一个小数就可能变成小数。
3.问题2:为什么深层的网络,底层比较难训练?是因为它拿到的梯度一- 般比较小?
答:如果你梯度是累乘,到最后你的梯度会变得很小,从误差的角度来讲,你的梯度回传的时候,预测值的误差,会随着网络的增加往下减,梯度和误差值有一定的关系,前面的层会吸收一些误差,遇到下面误差越来越小
18. 图片分类
问题
- loss值为nan,测试和训练精度不变
把lr调低点,或者添加BN
- 内存不够
把batch_size调小点
- 训练精度高,测试精度低
目前尚未解决,训练速度太慢了,测试精度上不去,有时候loss为nan
19. 序列模型
51 序列模型【动手学深度学习v2】_哔哩哔哩_bilibili
序列数据


统计工具
这里的t是不随机变量(这也是时序序列与之前的序列的区别),把这T个随机变量的联合分布记作p(x),所有的机器学习模型基本都是对p(x)建模

条件概率公式
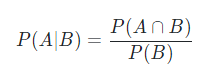
\(P(A \cap B)\) (A交B)意思是A和B共同发生的概率,称为联合概率。也可以写作 P(A,B) 或 P(AB)。
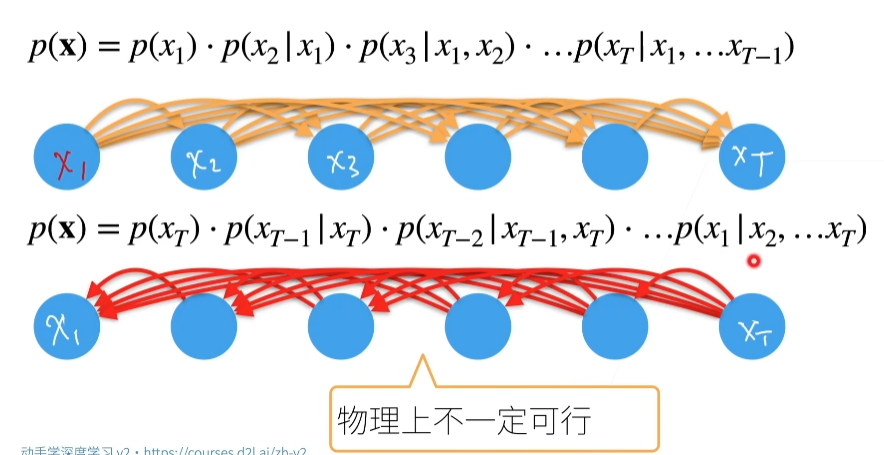
条件概率的链式法则
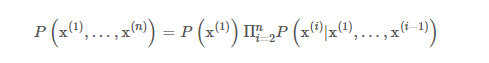
序列模型

马尔科夫假设
当前数据只跟前面τ个数据点相关,而不是跟前面所有数据相关
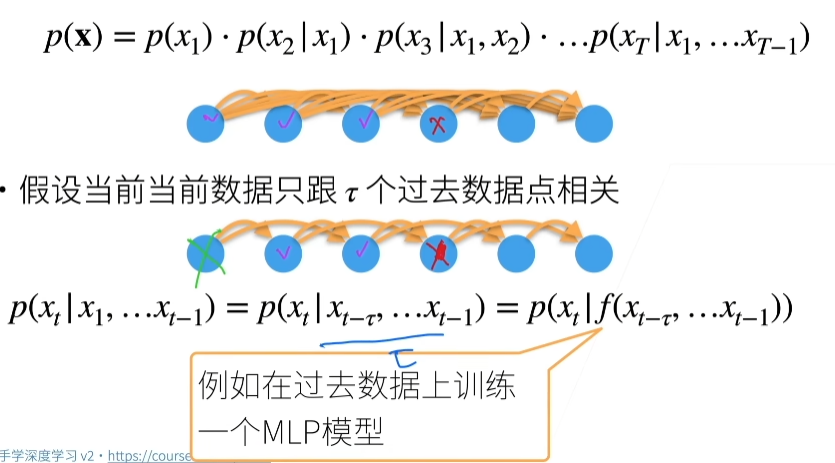
潜变量模型
用潜变量概括历史信息,这样子模型变为2块
- 用现有信息更新潜变量
- 用潜变量预测未来信息
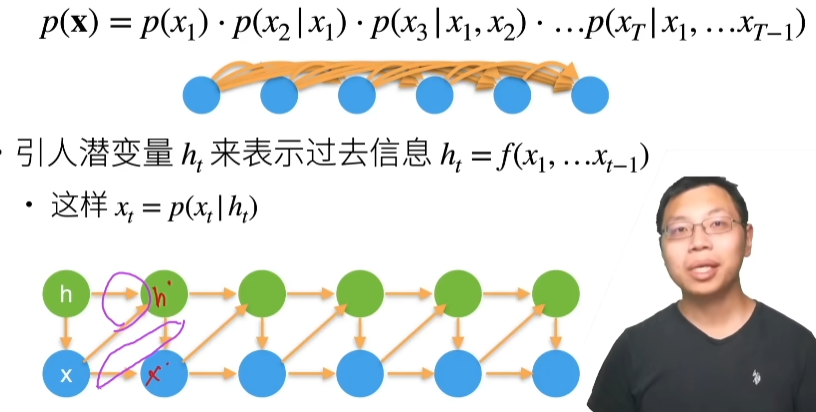
总结

代码实现
使用正弦函数和一些可加性噪声来生成序列数据,时间步为 \(1, 2, \ldots, 1000\)
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
T = 1000
time = torch.arange(1,T+1,dtype=torch.float32)
x = torch.sin(0.01 * time) + torch.normal(0,0.2,(T,))
print(x.shape) # torch.Size([1000])
d2l.plot(time,[x],'time','x',xlim=[1,1000],figsize=(6,3))
将数据映射为数据对yt=xt 和 xt=[xt-τ,…,xt−1]
tau = 4
features = torch.zeros((T - tau,tau))
print(features)
print(features.shape)
for i in range(tau):
# 将features的第i列赋值为x的值
features[:,i] = x[i:T - tau + i]
# f[:,0] = x[0:996]
# f[:,1] = x[1:997]
# f[:,2] = x[2:998]
# f[:,3] = x[3:999]
print(features)
labels = x[tau:].reshape((-1,1))# -1表示自动填充,
# labels = [4,5.....1000]
batch_size,n_train = 16,600
train_iter = d2l.load_array((features[:n_train],labels[:n_train]),batch_size,is_train=True)

- features
是一个996×4的矩阵,从0开始每次取996个数据赋值给features的列,重复τ次,features中的数据可以参考如下
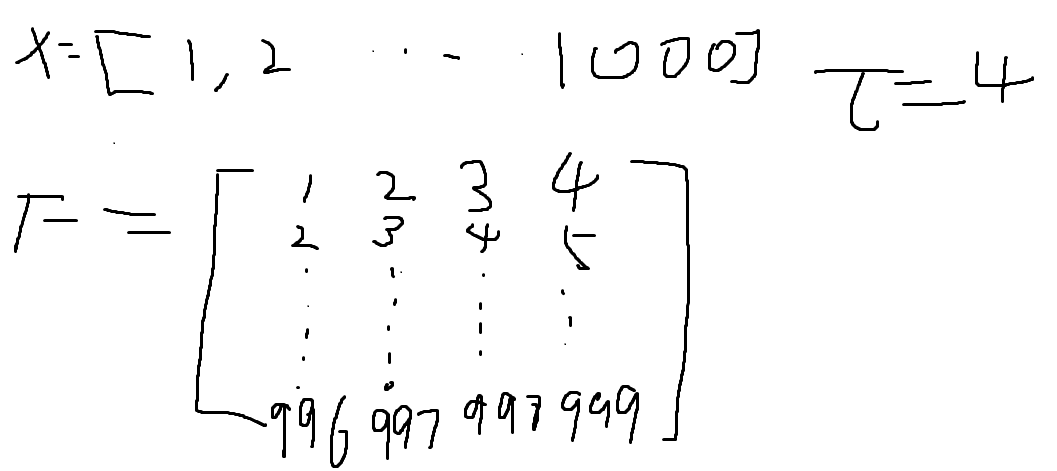
使用一个相当简单的结构:只是一个拥有两个全连接层的多层感知机
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
def get_net():
net = nn.Sequential(nn.Linear(4,10),nn.ReLU(),nn.Linear(10,1))
net.apply(init_weights)
return net
# 回归问题,所以使用MSE
loss = nn.MSELoss()
训练模型
def train(net,train_iter,loss,epochs,lr):
trainer = torch.optim.Adam(net.parameters(),lr)
for epoch in range(epochs):
for X,y in train_iter:
trainer.zero_grad()
l = loss(net(X),y)
l.backward()
trainer.step()
print(f'epoch {epoch + 1},loss:{d2l.evaluate_loss(net,train_iter,loss)}')
net = get_net()
train(net,train_iter,loss,5,0.01)
- 简单思路
每次从features取一行数据,假如现在取的数据是[1,2,3,4],预测x中的下一位的数据是多少
模型预测下一个时间步
onestep_preds = net(features)
d2l.plot(
[time,time[tau:]], # time[tau:] 不加tau会报错
[x.detach().numpy(),onestep_preds.detach().numpy()],'time','x',
legend=['data','1-step preds'],xlim=[1,1000],figsize=(6,3)
)
进行多步预测
# 生成一个长度为1000的向量
multistep_preds = torch.zeros(T)
multistep_preds[:n_train + tau] = x[:n_train + tau] # 为前604的值赋值
# 对从604到1000的数据进行预测
for i in range(n_train + tau,T):
multistep_preds[i] = net(multistep_preds[i - tau:i].reshape((1,-1)))
d2l.plot([time,time[tau:],time[n_train + tau:]],[
x.detach().numpy(),
onestep_preds.detach().numpy(),
multistep_preds[n_train + tau:].detach().numpy()],'time','x',
legend=['data','1-step preds','multistep preds'],xlim=[1,1000],figsize=(6,3)
)
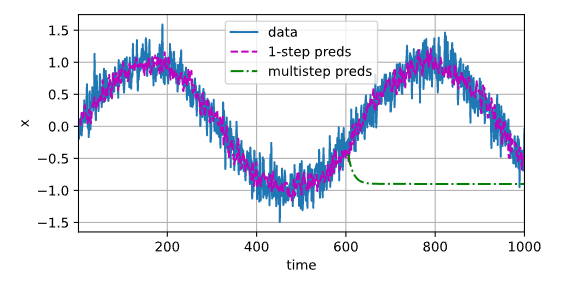
因为你每一次预测都有误差,然后你的误差是不断累加的,就是你的预测误差进入到你的数据,然后误差增加,然后预测效果很差
max_steps = 64
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
print(features.shape) # torch.Size([933, 68])
for i in range(tau):
features[:, i] = x[i:i + T - tau - max_steps + 1]
# 不止预测后一步,预测多个
for i in range(tau, tau + max_steps):
# 把[i - tau:i]列的值赋值给第i列
features[:, i] = net(features[:, i - tau:i]).reshape(-1)
steps = (1, 4, 16, 64)
d2l.plot([time[tau + i - 1:T - max_steps + i] for i in steps],
[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time',
'x', legend=[f'{i}-step preds'
for i in steps], xlim=[5, 1000], figsize=(6, 3))
1-step,4-step,16-step,64-step分别为预测后1位,4位,16位,64位
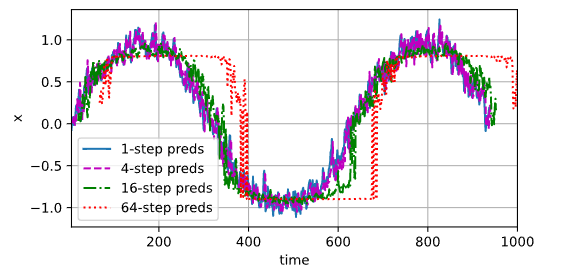
20. 文本预处理
52 文本预处理【动手学深度学习v2】_哔哩哔哩_bilibili
import collections
import re
from d2l import torch as d2l
将数据集读取到由文本行组成的列表中
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
with open(d2l.download('time_machine'),'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+',' ',line).strip().lower() for line in lines]
lines = read_time_machine()
print(lines[0])
print(lines[10])

- re库
正则表达式
Python中的Re库简要总结 - HuskySir - 博客园 (cnblogs.com)
- re.sub(pattern, repl, string, count)
将pattern替换为repl
关于python 的re.sub用法_sissi_shen的博客-CSDN博客_python re.sub
- [^A-Za-z]+
匹配除了A到Z,a到z以外的字符,1次或者多次
Python 正则表达式 | 菜鸟教程 (runoob.com)
- strip()
删除字符中头尾处指定的字符(默认为空格和换行符)
每个文本序列被拆分成一个标记列表
def tokenize(lines,token='word'):
# 将文本行拆分为单词或者字符标记
if token == 'word': # 单词
return [line.split() for line in lines]
elif token == 'char': # 字母
return [list(line) for line in lines]
else:
print('错误:未知令牌类型'+token)
tokens = tokenize(lines)
for i in range(11):
print(tokens[i])
tokens = tokenize(lines,'char')
for i in range(11):
print(tokens[i])
- token==word

- token=char

构建一个字典,通常也叫做词表(vocabulary),用来将字符串标记映射到从0开始的数字索引中
# 定义一个统计字符出现次数的函数
def count_corpus(tokens):
"""统计标记的频率。"""
if len(tokens) == 0 or isinstance(tokens[0], list):
tokens = [token for line in tokens for token in line]
print(tokens)
return collections.Counter(tokens)
tokens = [
['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him'],
['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and'],
['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
]
print(count_corpus(tokens))

class Vocab:
def __init__(self,tokens=None,min_freq=0,reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# count_corpus会去重
counter = count_corpus(tokens)
# 根据出现频率的次数进行排序
self.token_freqs = sorted(counter.items(),key=lambda x:x[1],reverse=True)
# unk表示token是未知的,默认初始值是0
self.unk,uniq_tokens = 0,['<unk>']+reserved_tokens
# uniq_tokens:唯一的词元(count_corpus已经去过重)
uniq_tokens += [
token for token,freq in self.token_freqs if freq >= min_freq and token not in uniq_tokens
]
print('---------------------uniq_tokens----------------')
print(uniq_tokens)
# idx是索引值,不是重复的次数,用来表示词元重复的优先级
self.idx_to_token,self.token_to_idx = [],dict()
# 根据出现次数来操作
for token in uniq_tokens:
# 根据idx获取token,这里的idx是list的索引下标
self.idx_to_token.append(token)
# 根据token获取idx,使用字典,token对应的value是刚好是idx_to_token的长度,长度会不断增加,value也不断增加
self.token_to_idx[token] = len(self.idx_to_token) - 1
print('---------------------idx_to_tokens----------------')
print(self.idx_to_token)
print('---------------------tokens_to_idx----------------')
print(self.token_to_idx)
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self,tokens):
# 递归
if not isinstance(tokens,(list,tuple)):
return self.token_to_idx.get(tokens,self.unk) # self.unk是没有找到,返回的默认值
# 如果传进来的tokens是整个文章
return [self.__getitem__(token) for token in tokens]
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
- 列表生成式,双重循环
python用列表生成式写嵌套循环_bymaymay的博客-CSDN博客
- get方法
dict.get(key, default=None)
key:需要查找的键。
default:如果查找的键不存在的话,返回default的值。默认为None。
Python 字典的get()用法_乖乖的函数的博客-CSDN博客_get函数python
- _len_()方法
python len(self)详解_一米半的博客-CSDN博客
构建词汇表
vocab = Vocab(tokens)
print('---------------------vocab----------------')
print(list(vocab.token_to_idx.items())[:10])

将每一行文本转换成一个数字索引列表
for i in [0,10]:
print('words:',tokens[i])
print('indices:',vocab[tokens[i]])
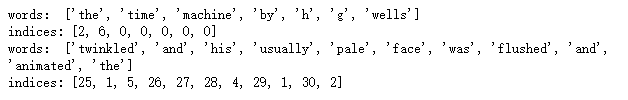
将所有内容打包到load_corpus_time_machine函数中
def load_corpus_time_machine(max_tokens=-1):
# 返回时光机器数据集的标记索引列表和词汇表
lines = read_time_machine()
tokens = tokenize(lines,'char')
vocab = Vocab(tokens) # 创建一个对象,建立词典后返回对象
print('-------------vocab-------------')
print(vocab)
# Vocab的实例化对象vocab自动调用__getitem__方法
corpus = [vocab[token] for line in tokens for token in line]
print('-------------corpus是token对应的idx-------------')
print(corpus[:10])
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus,vocab
# corpus存储每一个位置的字符的tokens_to_idx,全文有多少个字符,corpus就有多长
corpus,vocab = load_corpus_time_machine()
print('-------------vocab-------------')
print(vocab)
len(corpus),len(vocab)

- 为什么这里传入tokens【i】就会返回一个index的列表呢
因为_getitem_
- __getitem__方法
凡是在类中定义了这个__getitem__ 方法,那么它的实例对象(假定为p),可以像这样
p[key] 取值,当实例对象做p[key] 运算时,会调用类中的方法__getitem__。
让你秒懂Python 类特殊方法__getitem__ - 知乎 (zhihu.com)
- a[:-1]
a =[1,2,3,4]
print(a[:-1],a[1:3]) # 左闭右开
# [1, 2, 3] [2, 3]
21.语言模型
53 语言模型【动手学深度学习v2】_哔哩哔哩_bilibili

使用计数来建模

n可以理解为整个词的个数(corpus的大小),n(x)是这个词在整个文中出现的个数,n(x,x')理解为x后面跟着x‘长为2的词出现的次数
N元语法
这里的一元可以理解为马尔科夫的里面的τ,一元表示预测一个x出现的概率,不用管前面的

一元:tau=0
二元:tau=1
三元:tau=2
总结

n元语法就是每次看一个长为n的子序列去取数
n元语法的实现
import random
import torch
from d2l import torch as d2l
# read_time_machine:读取文件的内容,删除除了A-Za-z和空格以外的字符
# tokenize:将文本进行拆分
# Vocab:一个类,初始化时会统计每个字符出现个次数,根据次数进行排序,然后生成token映射idx和idx映射token
tokens = d2l.tokenize(d2l.read_time_machine()) # tokens中一个list对应一个行,每个list中存储着拆分的字符
# corpus存储全文中每个位置的词,不去重
corpus = [token for line in tokens for token in line]
print(len(corpus)) # 32775
vocab = d2l.Vocab(corpus) # 统计每个词元出现的次数
vocab.token_freqs[:10]

最流行的词 被称为停用词 画出的词频图
freqs = [freq for token,freq in vocab.token_freqs]
d2l.plot(freqs,xlabel='token:x',ylabel='frequency:n(x)',xscale='log',yscale='log')
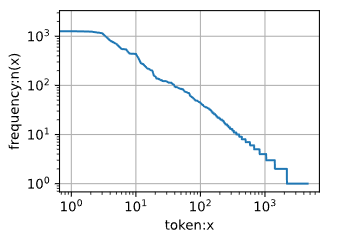
其他的词元组合,比如二元语法、三元语法等等,又会如何呢?
# 首先看下zip的用法
print(corpus[1],corpus[-1])
print([pair for pair in zip(corpus[1],corpus[-1])]) # 效果:[(a[i],b[i]),....(a[n],b[n])]
print(corpus[1:3],corpus[-3:-1]) # 即使是-3:-1也是左闭右开
print([pair for pair in zip(corpus[1:3],corpus[-3:-1])])

# 二元语法
bigram_tokens = [pair for pair in zip(corpus[:-1],corpus[1:])]
print(bigram_tokens[:10])
bigram_vocab = d2l.Vocab(bigram_tokens) # 每一个词元在所有bigram_tokens中重复的次数
bigram_vocab.token_freqs[:10]

# 三元语法
trigram_tokens = [
triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
trigram_vocab.token_freqs[:10]

直接地对比三种模型中的标记频率
bigram_freqs = [freq for token,freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token,freq in trigram_vocab.token_freqs]
d2l.plot([freqs,bigram_freqs,trigram_freqs],xlabel='token:x',
ylabel='frequency:n(x)',xscale='log',yscale='log',
legend=['unigram','bigram','trigram'])
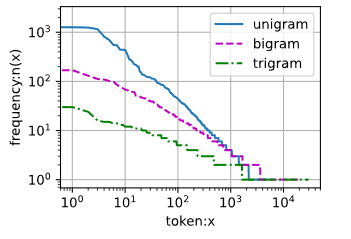
随机地生成一个小批量数据的特征和标签以供读取。 在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列
【方法一】
随机采样长度为T的序列,然后把T后面的当做y(label),这样有个问题前面数据容易使用多次,一个数据可能用在这个序列,也有可能用在下个序列,如下图,红点在当前序列用了一次,但是后面的序列里面还包括它,它又要被用一次。
这里想法是扫一遍,所有数据只用一次,把长度为n的序列切成多块,每一块长度为T,切好后,每次从里面随机取一段,这个有个问题是,如果按黄色图形那样切的话,那么红色区域的数据就遍历不到了

解决这个问题的方法是,我的起始点是随机起始的,在(0,T)之间随机挑选个值k,然后切成长度为T的序列,k前面的不要了

def seq_data_iter_random(corpus,batch_size,num_steps):
# batch_size:每次在initial_indices的取值范围
# num_steps:每个划分区间的长度
"""使用随机抽样生成一个小批量子序列。"""
k = random.randint(0, num_steps - 1)
print('随机起始位置:',k)
corpus = corpus[k:]
print('--------------corpus--------------')
print(corpus)
num_subseqs = (len(corpus) - 1) // num_steps # 切分区间的个数
print('--------------num_subseqs--------------')
print(num_subseqs)
initial_indices = list(range(0, num_subseqs * num_steps, num_steps)) # 每个切分区间的起始下标
print('--------------initial_indices打乱后--------------')
random.shuffle(initial_indices)
print(initial_indices)
def data(pos):
return corpus[pos:pos + num_steps]
num_batches = num_subseqs // batch_size
print('--------------num_batches--------------')
print(num_batches)
print('--------------------------------')
print('batch_size:',batch_size,'num_steps:',num_steps)
print('-------------for循环-------------------')
# 因为batch_size小于num_steps所以X的值不会相同
for i in range(0, batch_size * num_batches, batch_size):
# 每个batch是随机采样的,独立的
print(f'第{i}轮:')
initial_indices_per_batch = initial_indices[i:i + batch_size]
print('----------initial_indices_per_batch----------')
print(initial_indices_per_batch)
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
生成一个从 0 到 34 的序列
my_seq = list(range(35))
print('-------------原始输入---------------')
print(my_seq)
print('-------------------------------------')
for X,Y in seq_data_iter_random(my_seq,batch_size=2,num_steps=5):
print('X:',X,'\nY:',Y)

【方法二】
保证两个相邻的小批量中的子序列在原始序列上也是相邻的,和上面的差不多,只不多上面的打乱了顺序
def seq_data_iter_sequential(corpus,batch_size,num_steps):
print(f'batch_size:{batch_size},num_steps:{num_steps}')
# 使用顺序分区生成一个小批量子序列
offset = random.randint(0,num_steps)
print(f'offset:{offset}')
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
print(f'num_tokens:{num_tokens}')
Xs = torch.tensor(corpus[offset:offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1:offset + 1 + num_tokens])
Xs,Ys = Xs.reshape(batch_size,-1),Ys.reshape(batch_size,-1)
num_batches = Xs.shape[1] // num_steps
for i in range(0,num_steps * num_batches,num_steps):
print(f'第{i}轮:')
print('-------------------------')
X = Xs[:,i:i+num_steps]
Y = Ys[:,i:i+num_steps]
yield X,Y
读取每个小批量的子序列的特征 X 和标签 Y
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)

流程

将上面的两个采样函数包装到一个类中
class SeqDataLoader:
# 加载序列数据的迭代器
def __init__(self,batch_size,num_steps,use_random_iter,max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.dta_iter_fn = d2l.seq_data_iter_sequential
self.corpus,self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size,self.num_steps = batch_size,num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus,self.batch_size,self.num_steps)
最后,我们定义了一个函数 load_data_time_machine ,它同时返回数据迭代器和词汇表
def load_data_time_machine(batch_size,num_steps,use_random_iter=False,max_tokens=10000):
# 返回时光机器数据集的迭代器和词汇表
data_iter = SeqDataLoader(batch_size,num_steps,use_random_iter,max_tokens)
return data_iter,data_iter.vocab
问答
1.在文本预处理中,所构建的词汇表把文本映射成数字,文本数据量越大,映射的数字也就越大,这些数字还需要做预处理吗?例如归一化处理等。是否对模型有影响?
答:这些数字会做成embedding用,这些数字只是个id,随便用什么数字都可以
22. 循环神经网络RNN
54 循环神经网络 RNN【动手学深度学习v2】_哔哩哔哩_bilibili
潜变量自回归模型
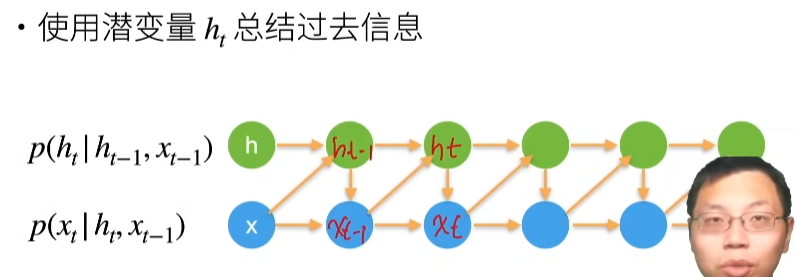
循环神经网络
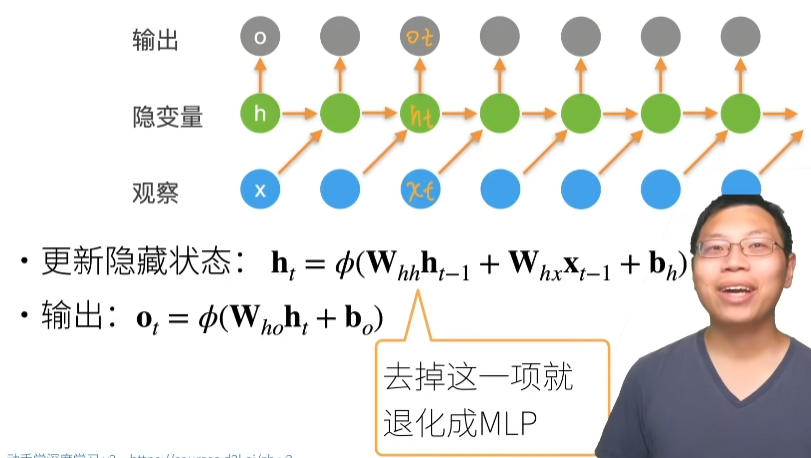
使用循环神经网络的语言模型
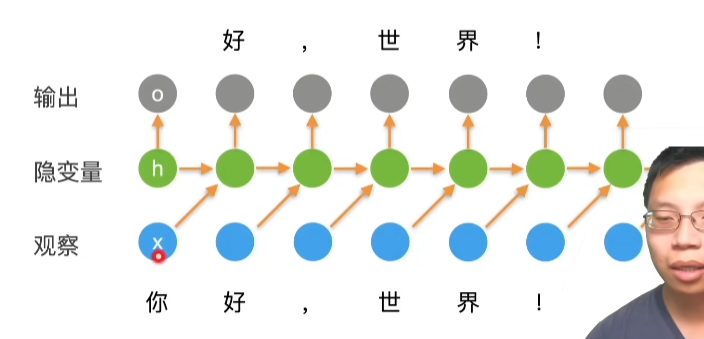
假如我输入的是“你”的话,我会去更新我的隐变量,去预测“好”字,然后我输入“好”字,去预测“,”字。在你生成ot的时候,你看不到你的xt,当前时刻的输出去预测当前的观察,但是你的输出是发生在你的观察之前。
ot是根据ht输出的,但是ht用的是xt-1的东西,然后在计算损失的时候比较ot和xt之间的关系计算损失,你的xt是更新ht挪到下一个时刻的单元。和mlp不一样的是有个时间轴,如果没有时间轴就会回到mlp模型。
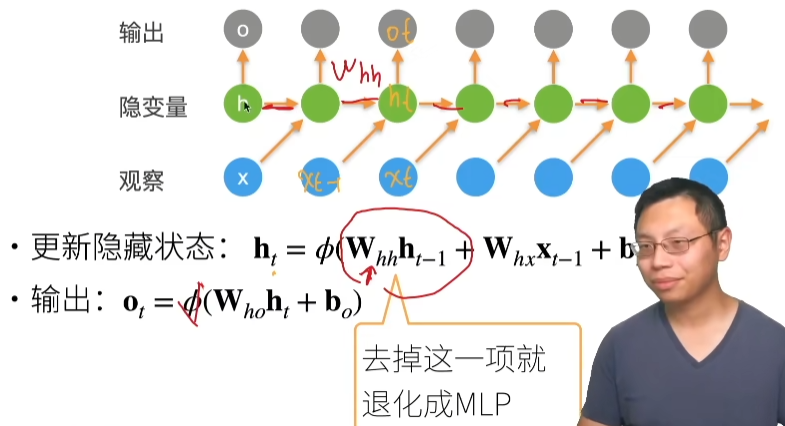
Φ是激活函数,Whx是隐层的weight,xt-1是你的输入,bh是一个偏移,ht还跟前一刻的ht-1相关,
前一刻的ht-1也倍乘了一个Whh,然后输出还是一个隐藏状态(ht)乘以w再加一个bias得到输出。Whh存储的是时序信息。ht-1到ht之间的箭头存储的是时间信息
困惑度(perplexity)

梯度剪裁(gradient clipping)

更多的应用RNNs
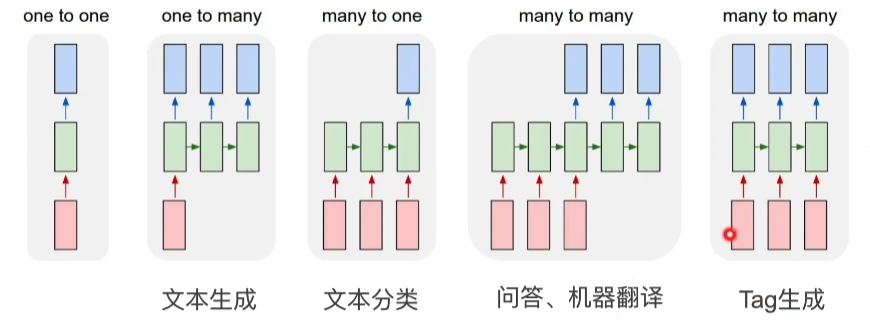
总结

问答
1.中文需不需要分词,可否直接基于字来做?
答:分词会有信息,能分词也可以
23. 循环神经网络的实现
55 循环神经网络 RNN 的实现【动手学深度学习v2】_哔哩哔哩_bilibili
全文一共有4579个单词,这个单词共由27个字符组成(不算‘
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# num_steps:每次看一个多长的序列
batch_size,num_steps = 32,35
train_iter,vocab = d2l.load_data_time_machine(batch_size,num_steps)
独热编码
# 独热编码
print(len(vocab)) # 28,说明以单个字母进行划分
# 将[0,2]转换为独热编码
F.one_hot(torch.tensor([0,2]),len(vocab)) # 0对应第0位的1,2对应的第2位的1
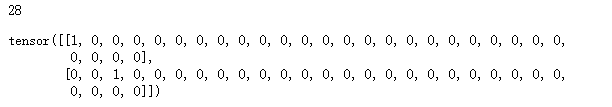
小批量数据形状是(批量大小,时间步数)
X = torch.arange(10).reshape((2,5))
print(X)
F.one_hot(X.T,28).shape # 转置之后第一个维度是时间,后面两个是Xt,这样的好处是我每次访问Xt的话,它是连续的

初始化循环神经网络模型的模型参数
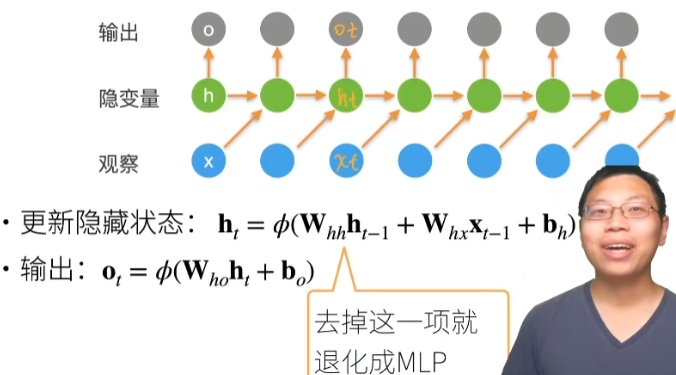
def get_params(vocab_size,num_hiddens,device):
# 因为你输入是一个一个词,通过one_hot变成向量后,它的长度就是vocab_size的向量
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape,device=device) * 0.01 # 乘0.01就是把方差变为0.01
W_xh = normal((num_inputs,num_hiddens))
W_hh = normal((num_hiddens,num_hiddens))
b_h = torch.zeros(num_hiddens,device=device)
W_hq = normal((num_hiddens,num_outputs))
b_q = torch.zeros(num_outputs,device=device)
params = [W_xh,W_hh,b_h,W_hq,b_q]
for param in params:
param.requires_grad_(True)
return params
一个init_rnn_state函数在初始化时返回隐藏状态
def init_rnn_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens,device=device),)
下面的rnn函数定义了如何在一个时间步计算隐藏状态和输出
def rnn(inputs,state,params):
W_xh,W_hh,b_h,W_hq,b_q = params
H, = state
outputs = []
# inputs是时间步数,批量大小,vocab_size,一个3D的tensor
for X in inputs:
# X首先拿到时刻0的对应的x,接下来是时刻1,....
H = torch.tanh(torch.mm(X,W_xh)
+ torch.mm(H,W_hh) # 这里的H是前一个的隐藏状态
+ b_h)
Y = torch.mm(H,W_hq) + b_q # 这里的y是我当前时刻预测下一个时刻的词是谁
outputs.append(Y)
# Y.shape:(2,28)
return torch.cat(outputs,dim=0),(H,)
创建一个类来包装这些函数
class RNNModelScratch:
# 从零开始实现的循环神经网络模型
def __init__(self,vocab_size,num_hiddens,device,get_params,init_state,forward_fn):
self.vocab_size,self.num_hiddens = vocab_size,num_hiddens
self.pararms = get_params(vocab_size,num_hiddens,device)
self.init_state,self.forward_fn = init_state,forward_fn
# forward_fn:传播函数
def __call__(self,X,state): # 这里的X是那个时间机器load进来的X,由(批量大小,时间步数)组成
X = F.one_hot(X.T,self.vocab_size).type(torch.float32) # one-hot得到的是整形,我们要变成了浮点型
return self.forward_fn(X,state,self.params)
# 初始化状态函数
def begin_state(self,batch_size,device):
return self.init_state(batch_size,self.num_hiddens,device)
- _call_()方法
__call__()的作用是使实例能够像函数一样被调用,也就是实例化后的对象被当做函数调用时
检查输出是否具有正确的形状
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state) # 自动调用_call__方法
Y.shape, len(new_state), new_state[0].shape
# 因为有个cat将5个(2,28)矩阵拼接起来,就变成了(10,28)
- torch.tensor()可以进行矩阵运算
- cat()方法

流程如下图(这里的x的shape是(5,2,28)只是举个例子而已
首先定义预测函数来生成prefix之后的新字符
def predict_ch8(prefix,num_preds,net,vocab,device):
# 在prefix后面生成新字符
state = net.begin_state(batch_size=1,device=device) # 初始状态
# prefix[0]:第一个字母“t”
outputs = [vocab[prefix[0]]] # 输入‘t’,通过token_to_idx,获取t的索引值
# outputs:3
get_input = lambda:torch.tensor([outputs[-1]],device=device).reshape((1,1)) # 匿名函数获取output中最后一个tokens的token_to_idx
for y in prefix[1:]:
# 我输入了一段话,已经有正确答案了,不需要你的预测结果了
_,state = net(get_input(),state)
outputs.append(vocab[y]) # vocab实例做p[key]运算时,会调用类中geiitem方法,也就是tokens_to_idx
for _ in range(num_preds):
# get_input().shape: (1,1)
y,state = net(get_input(),state)
print(y.argmax(dim=1))
# y.shape (1,28)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ' '.join([vocab.idx_to_token[i] for i in outputs])
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())

梯度剪裁
def grad_clipping(net,theta):
# 梯度剪裁
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
# 向量范数,每个p也是向量,所以有两个sum
norm = torch.sqrt(sum(torch.sum((p.grad**2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
我给你一个小批量进去,就算只有一个批量,我就只有一个单隐藏层,但是我会做梯度迭代,梯度就是你那个长度(num_steps = 35)
定义一个函数来训练只有一个迭代周期的模型
def train_epoch_ch8(net,train_iter,loss,updater,device,use_random_iter):
# 训练模型一个迭代周期(定义见第8章)
state,timer = None,d2l.Timer()
metric = d2l.Accumulator(2)
for X,Y in train_iter:
# 如果使用随机data_iter,那么我需要重新初始化状态,
#因为前一个时刻的sequence信息和当前的sequence信息不是连续的
# 上一个批量的state不应该用到这一时刻,因为我们在时序上不连续,当前的状态信息,要从头开始
if state is None or use_random_iter:
# 初始化状态
state = net.begin_state(batch_size=X.shape[0],device=device)
else:
# 如果你使用的是sequence_to_data_iter的话,你的下一个小批量和上一个小批量是连续的
# 你可以把上一个批量的state传过来,所以如果是随机采样的话,我就需要重新初始化
if isinstance(net,nn.Module) and not isinstance(state,tuple):
# detach是我不把state的值改掉,只是在做backward的时候,前面的计算图我就不要了,只关心从现在开始的
state.detach_()
else:
for s in state:
s.detach_()
# X和y都是某个数字,在计算的时候,转换为独热矩阵
# 转置是把时间向量放在前面
y = Y.T.reshape(-1)
X,y = X.to(device),y.to(device)
y_hat,state = net(X,state)
print(y_hat.shape)
# 为什么把输出在第一个纬度上concat起来?
# 因为从loss角度上来讲,就是一个多分类问题
l = loss(y_hat,y.long()).mean()
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping()
updater.step()
else:
l.backward()
grad_clipping(net,1)
updater(batch_size=1)
metric.add(l*y.numel(),y.numel())
# metric[0] / metric[1] :平均loss,困惑度
return math.exp(metric[0] / metric[1]),metric[1] / timer.stop()
循环神经网络模型的训练函数既支持从零开始实现,也可以使用高级API来实现
def train_ch8(net,train_iter,vocab,lr,num_epochs,device,use_random_iter=False):
# 训练模型
# 多分类,所以用的是crossentropyloss
loss = nn.CrossEntropyLoss()
aniamtor = d2l.Animator(xlabel='epoch',ylabel='perplexity',legend=['train'],xlim=[10,num_epochs])
if isinstance(net,nn.Module):
updater = torch.optim.SGD(net.parameters(),lr)
else:
updater = lambda batch_size:d2l.sgd(net.params,lr,batch_size)
# 往后预测50个char
predict = lambda prefix:predict_ch8(prefix,50,net,vocab,device)
for epoch in range(num_epochs):
pp1,speed = train_epoch_ch8(net,train_iter,loss,updater,device,use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch+1,[pp1])
print(f'困惑度 {pp1:.1f},{speed:.1f} 标记/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))
开始训练模型
num_epochs,lr=500,1
train_ch8(net,train_iter,vocab,lr,num_epochs,d2l.try_gpu())
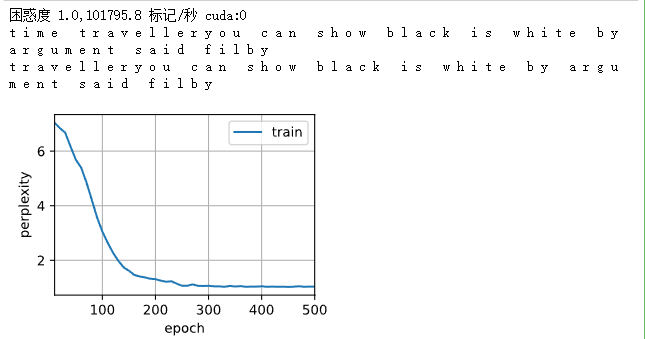
随机抽样方法
train_ch8(net,train_iter,vocab,lr,num_epochs,d2l.try_gpu(),use_random_iter=True)
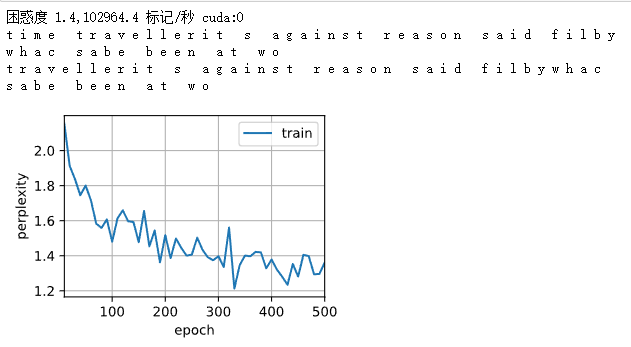
简洁实现
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size,num_steps = 32,35
train_iter,vocab = d2l.load_data_time_machine(batch_size,num_steps)
print(next(iter(train_iter))[0].shape) # torch.Size([32, 35])
定义模型
num_hiddens = 256
# RNN(输入输出大小,隐藏层大小)
rnn_layer = nn.RNN(len(vocab),num_hiddens)
rnn_layer # RNN(28, 256)
使用张量来初始化隐藏状态
state = torch.zeros((1,batch_size,num_hiddens))
state.shape # torch.Size([1, 32, 256])
通过一个隐藏状态和一个输入,我们就可以用更新后的隐藏状态计算输出
# 测试用
X = torch.rand(size=(num_steps,batch_size,len(vocab)))
Y,state_new = rnn_layer(X,state)
Y.shape,state_new.shape
# Y的里面是第一个是时间维度,第二个是批量维度,第三个是输出维度
# (torch.Size([35, 32, 256]), torch.Size([1, 32, 256]))
我们为一个完整的循环神经网络模型定义了一个RNNModel类
class RNNModel(nn.Module):
# 循环神经网络模型
def __init__(self,rnn_layer,vocab_size,**kwargs):
super(RNNModel,self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 双向RNN
if not self.rnn.bidirectional:
self.num_directions = 1
# pytorch没有输出层,需要我们自己指定
self.linear = nn.Linear(self.num_hiddens,self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2,self.vocab_size)
def forward(self,inputs,state):
X = F.one_hot(inputs.T.long(),self.vocab_size)
X = X.to(torch.float32)
# state是最后一个时间步的
Y,state = self.rnn(X,state)
# 把时间维度和批量维度放在一起,最后一个是隐藏层大小,另外可以看到上面定义了的linear第一个参数就是隐藏层大小,把Y做线性之后得到输出,输出只有2个维度
output = self.linear(Y.reshape((-1,Y.shape[-1])))
return output,state
def begin_state(self,device,batch_size=1):
if not isinstance(self.rnn,nn.LSTM):
# 3维张量,时间,批量,隐藏层
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size,self.num_hiddens),device=device)
else:
return (torch.zeros((self.num_directions * self.rnn_num_layers,
batch_size,self.num_hiddens),device=device),
torch.zeros((self.num_directions * self.rnn_num_layers,
batch_size,self.num_hiddens),
device=device))
用一个具有随机权重的模型进行预测
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)
# 'time travellermlmlaaaaaa'
训练
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
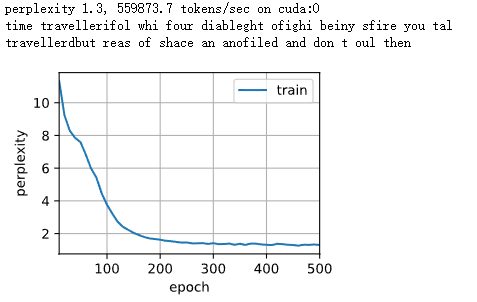
问答
1.请问num _steps做什么用的?
答:num_steps是时间维度,时间维度就是样本的句子的长度输入到小批量里面那个长度,就是T,比如下图,“你好,世界!”的时间维度是6,那么它的num_steps就是6。反过来可以认为这是6个样本的分类问题
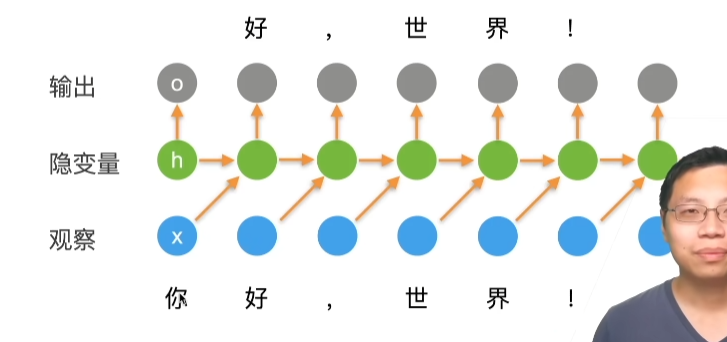
2.为什么是批量大小乘以时间长度?
答:从分类的角度来讲,你给我的小批量里面,我要做的分类次数是批量大小乘以时间长度,对任何一个样本,在任何一个时间点我都要做一次分类
3.H是一个batch更新一次吗? 看刚刚的代码H像是每个batch会覆盖一次但是H难道不应该是每个step都在变化吗?
答:是的,如果你一个batch,一个样本长度为T的话,那么会更新T次(我认为这种前提是你的batch_size是1,如果你的batch_size大于1的话,那么更新次数应该是batch_size乘以T),这里的T是num_steps,根据你的采样不一样,我可以决定要不要把当前batch砍断,通过你下一个batch和前一个batch是不是接在一起来判断
4.batch_ size 和time的区别是什么?
答:time是句子的长度,batch_size是我一次训练多少个样本
5.detach的原理还是没太明白。只影响backward, 不影响forward?被detach之后是梯度不更新、参数不更新的意思吗?
答:state会记录前一个batch里面的操作,如果没有创建新的state的话,还是重用前面的话,它会记住前面的东西,在做误差反传的时候会多算东西,这时候我用detach不要前面的,只关心现在的
6.为什么是预测字符而不是预测一个单词呢?
答:因为单词预测起来比较简单,如果你用字符的话vocabsize是28,单词的话vocabsize可以上千了,这个样本撑不起来,计算太大
7.为什么要把(batch,num_step)换成(num_step,batch)
答:因为num_step是batch中文本的长度,比如我的文本长度是6,那么根据时序要求,从0-5时刻就对应当前时刻的文本了
24. 门控循环单元GRU
56 门控循环单元(GRU)【动手学深度学习v2】_哔哩哔哩_bilibili
关注一个序列

门
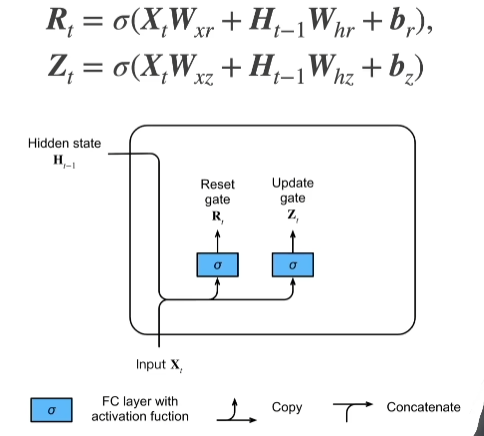
Reset门和Update门的计算方式和RNN中计算隐藏层的方法是一样的。σ是sigmoid
Wxr是Reset门的输入的权重,Whr是上一个隐藏层的权重,br是Reset门的偏置值
候选隐状态
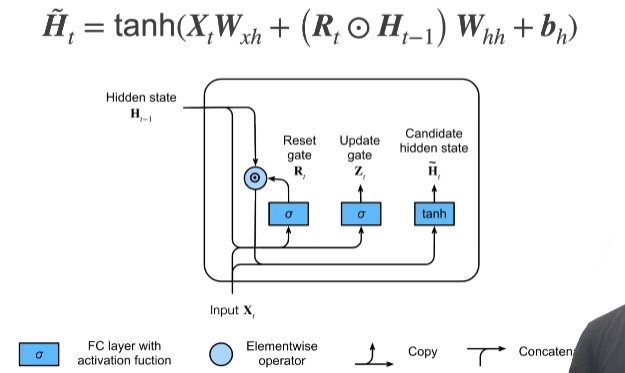
- ⊙表示哈达玛积(element-wise)
哈达玛积 Hadamard Product - 知乎 (zhihu.com)
- Rt的值是在0到1之间,因为sigmoid的值域就在0到1
如果Rt的值靠近0的话,那么Rt⊙Ht-1的结果就会像0,0意味着把上一个时刻的状态忘掉
隐状态
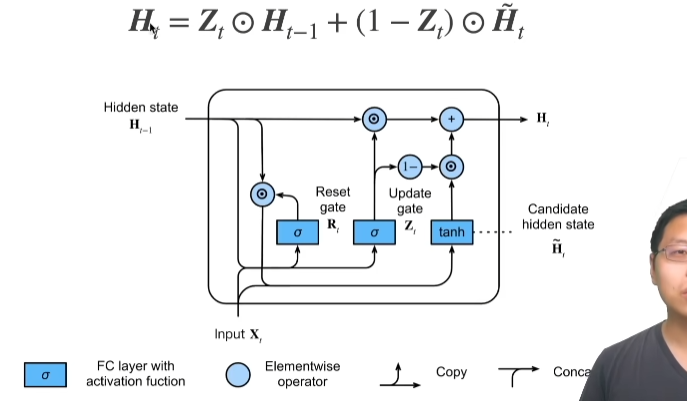
- Zt
假设Zt等于1的话,那么Ht就等于Ht-1了,如果Zt等于0的话,就会更新
总结
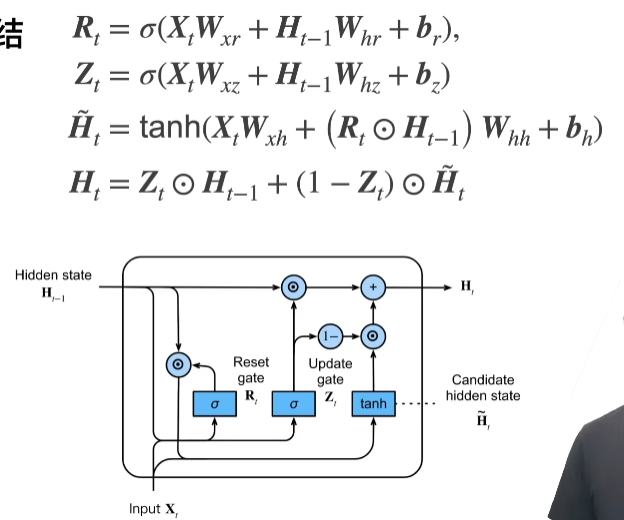
代码实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size,num_steps = 32,35
train_iter,vocab = d2l.load_data_time_machine(batch_size,num_steps)
初始化模型参数
def get_params(vocab_size,num_hiddens,device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape,device=device)*0.01
def three():
return (normal((num_inputs,num_hiddens)),
normal((num_hiddens,num_hiddens)),
torch.zeros(num_hiddens,device=device))
W_xz,W_hz,b_z = three()
W_xr,W_hr,b_r = three()
W_xh,W_hh,b_h = three()
W_hq = normal((num_hiddens,num_outputs))
b_q = torch.zeros(num_outputs,device=device)
params = [W_xz,W_hz,b_z,W_xr,W_hr,b_r,W_xh,W_hh,b_h,W_hq,b_q]
for param in params:
param.requires_grad_(True)
return params
定义隐藏状态的初始化函数
def init_gru_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device=device),)
定义门控循环单元模型
def gru(inputs,state,params):
W_xz,W_hz,b_z,W_xr,W_hr,b_r,W_xh,W_hh,b_h,W_hq,b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H)@ W_hh) + b_h)
H = Z * H +(1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,)
- @和*
@ 表示常规的数学上定义的矩阵相乘;和torch.mm(),torch.mul()没什么区别
*表示两个矩阵对应位置处的两个元素相乘
pytorch 中的 @ 和 * 运算符_DongHappyyy的博客-CSDN博客
训练
vocab_size,num_hiddens,device = len(vocab),256,d2l.try_gpu()
num_epochs,lr = 500,1
model = d2l.RNNModelScratch(len(vocab),num_hiddens,device,get_params,init_gru_state,gru)
d2l.train_ch8(model,train_iter,vocab,lr,num_epochs,device)
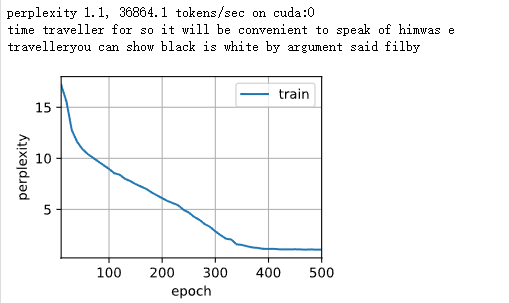
简洁实现
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs,num_hiddens)
model = d2l.RNNModel(gru_layer,len(vocab))
model = model.to(device)
d2l.train_ch8(model,train_iter,vocab,lr,num_epochs,device)
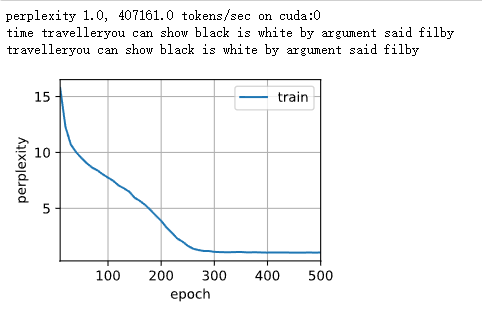
问答
1.rnn在 长文本时候效果不好,请问老师多长算长啊,还是跟rnn的隐藏向量大小有关?
答:多长没有规定,实际中不要用rnn
25. 长短期网络LSTM
57 长短期记忆网络(LSTM)【动手学深度学习v2】_哔哩哔哩_bilibili
长短期记忆网络

门
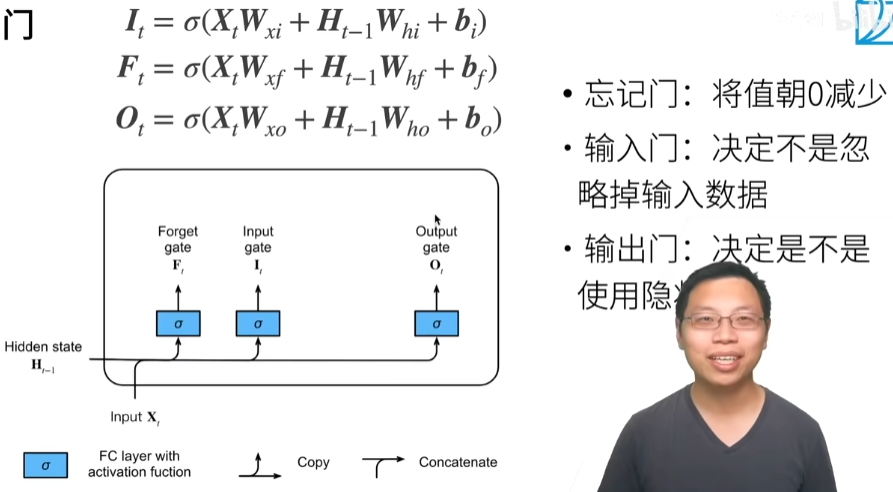
候选记忆单元
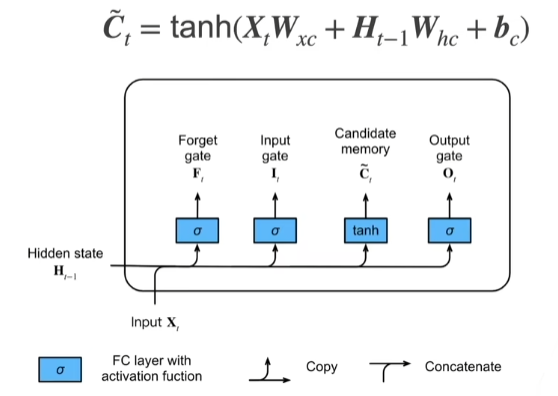
记忆单元
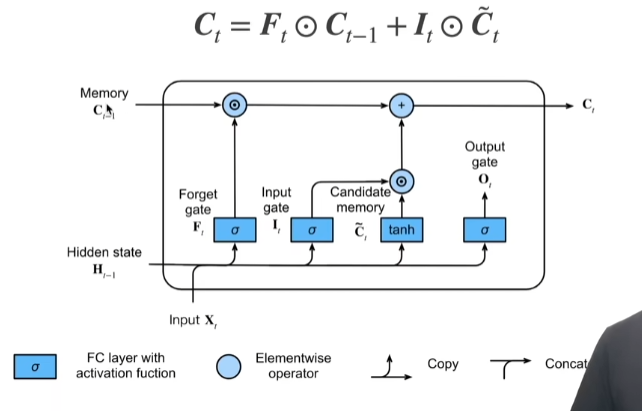
隐状态
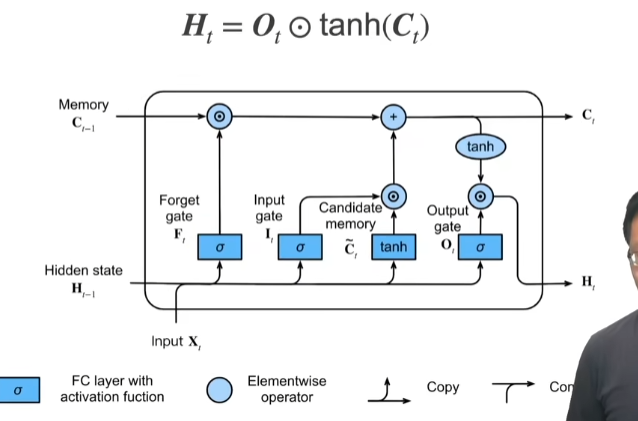
- tanh
Ct的取值范围可以取到-2到2,tanh的作用就是把Ct的值放到-1到1之间,Ot决定要不要输出,不要输出的意思就是说当前的Xt和过去所有信息,我都不要
总结
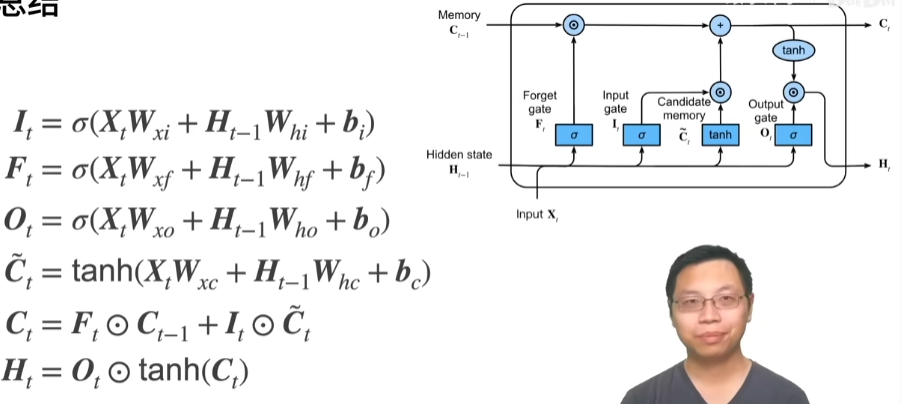
代码实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size,num_steps = 32,35
train_iter,vocab = d2l.load_data_time_machine(batch_size,num_steps)
初始化模型参数
def get_lstm_params(vocab_size,num_hiddens,device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape,device=device) * 0.01
def three():
return (normal((num_inputs,num_hiddens)),
normal((num_hiddens,num_hiddens)),
torch.zeros(num_hiddens,device=device))
W_xi,W_hi,b_i = three()
W_xf,W_hf,b_f = three()
W_xo,W_ho,b_o = three()
W_xc,W_hc,b_c = three()
W_hq = normal((num_hiddens,num_outputs))
b_q = torch.zeros(num_outputs,device=device)
params = [
W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
初始化函数
def init_lstm_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device=device),
torch.zeros((batch_size,num_hiddens),device=device))
实际模型
def lstm(inputs,state,params):
[
W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H,C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,C)
训练
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
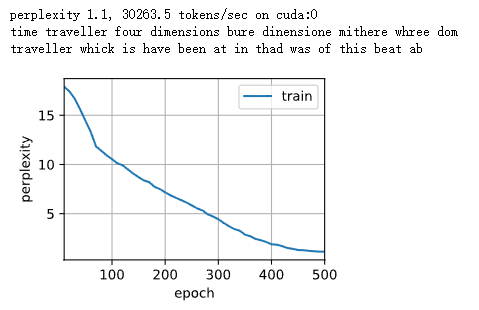
简洁实现
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs,num_hiddens)
model = d2l.RNNModel(lstm_layer,len(vocab))
model = model.to(device)
d2l.train_ch8(model,train_iter,vocab,lr,num_epochs,device)
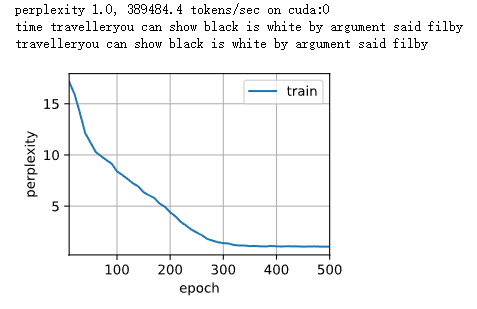
26. 深度循环神经网络
58 深层循环神经网络【动手学深度学习v2】_哔哩哔哩_bilibili
循环神经网络
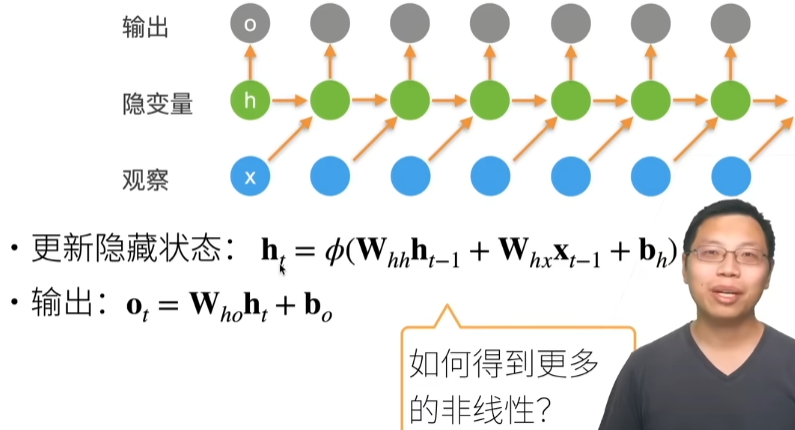
更深
总结

代码实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
通过num_layers的值来设定隐藏层数
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
训练
num_epochs, lr = 500, 2
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
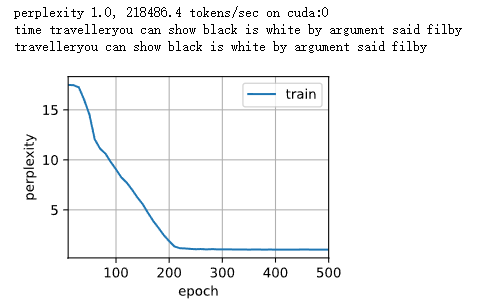
27. 双向循环神经网络
59 双向循环神经网络【动手学深度学习v2】_哔哩哔哩_bilibili
未来很重要

双向RNN
一个正序,一个反序,最后concat起来
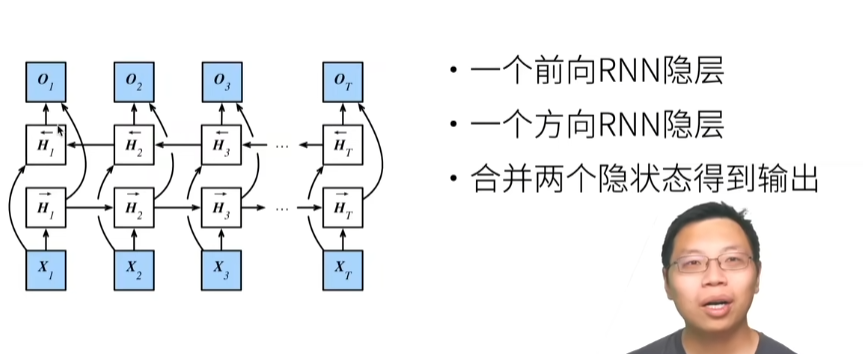
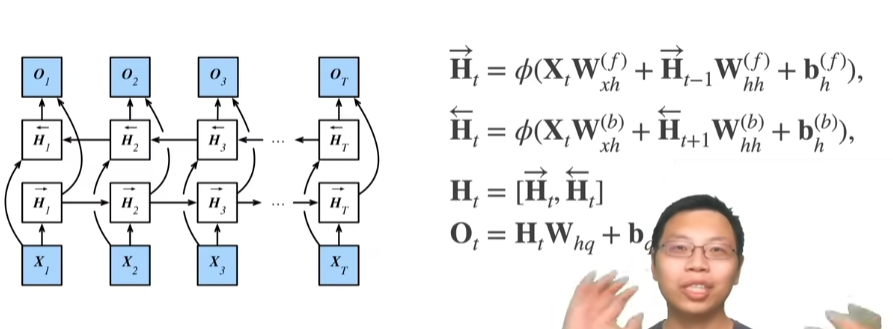
推理
训练比较容易,推理不好推理(几乎不能用推理),适合做特征提取,双向LSTM非常不适合做推理,因为既要看到之前的信息,也要看到未来的信息,主要是对句子做特征提取
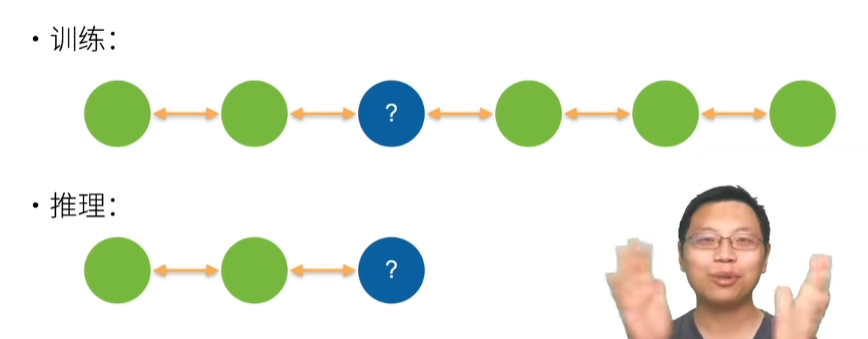
总结

代码实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
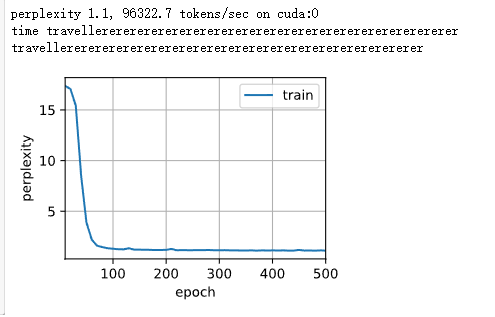
- 不能用双向循环神经网络来训练语言模型
- 因为语言模型是用来预测未来,做预测的时候,没有未来,不要双向循环神经网路做预测
问答
1.双向RNN,反向的初始hidden state是什么?
答:0
2.Lstm为什么要分C和H
答:H是-1到1之间的数字,C是用来存储信息,可以做的比较大
3.时间序列预测,也用双向的吗,这个能从后向前看吗,不太理解
答:不能
4.双向循环神经网络,在正向和反向之间有权重关系没?
答:没有
28. 机器翻译与数据集
60 机器翻译数据集【动手学深度学习v2】_哔哩哔哩_bilibili
import os
import torch
from d2l import torch as d2l
下载和预处理数据集
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
def read_data_nmt():
"""载入“英语-法语”数据集。"""
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding="utf-8") as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])

预处理
def preprocess_nmt(text):
# 预处理
# 判断字符前面有没有空格
def no_space(char,prev_char):
return char in set(',.!?') and prev_char != ' '
# u202f是utf-8里面的全角半角空格,全部换成空格
text = text.replace('\u202f',' ').replace('\xa0',' ').lower()
out = [
# 可以理解为前面如果没有空格就加个空格,否则返回带有空格的char
' ' + char if i > 0 and no_space(char,text[i-1]) else char for i,char in enumerate(text)
]
return ''.join(out)
text = preprocess_nmt(raw_text)
print(text[:80])
print(text.split('\n')[:10])

- 列表生成式中的if else
Python列表解析配合if else_KeeJee的博客-CSDN博客
词元化
def tokenize_nmt(text,num_examples=None):
"词元化"
source,target = [],[]
for i,line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source,target
source,target = tokenize_nmt(text)
source[:6],target[:6]

绘制每个文本序列所包含的标记数量的直方图
d2l.set_figsize()
_,_,patches = d2l.plt.hist([[len(l) for l in source],[len(l) for l in target]],label=['source','target'])
for patch in patches[1].patches:
patch.set_hatch('/')
d2l.plt.legend(loc='upper right')
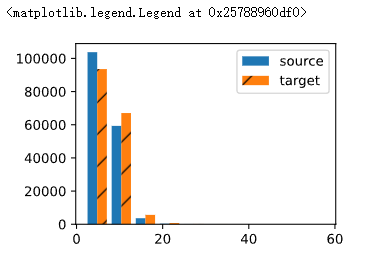
- source

词汇表
src_vocab = d2l.Vocab(source,min_freq=2,reserved_tokens=['<pad>','<bos>','<eos>']) # pad:填充 bos:begin of sentence句子开始 eos:句子结束
len(src_vocab) # 10012
print(list(src_vocab.token_to_idx.items())[:10])
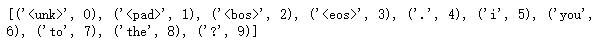
序列样本都有一个固定的长度 截断或填充文本序列
def truncate_pad(line,num_steps,padding_token):
# 截断或填充文本序列
if len(line) > num_steps:
return line[:num_steps]
return line + [padding_token] * (num_steps - len(line))
# source[0] ['go', '.']
truncate_pad(src_vocab[source[0]],10,src_vocab['<pad>'])
# [47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
转换成小批量数据集用于训练
print('---------------line------------')
print(source[:10])
lines = [src_vocab[l] for l in source]
print('--------lines,token_to_idx------------')
print(lines[:10])
lines = [ l + [src_vocab['<eos>']] for l in lines]
print('-----------lines with eos--------------')
print(lines[:10])

print('-------------array------------')
array = torch.tensor([truncate_pad(l,10,src_vocab['<pad>']) for l in lines])
print(array[:10])
print('--------------len-----------')
valid_len = (array != src_vocab['<pad>']).type(torch.int32).sum(1)
print(valid_len[:10])

def build_array_nmt(lines,vocab,num_steps):
# 将机器翻译的文本序列转换成小批量
lines = [vocab[l] for l in lines]
lines = [ l + [vocab['<eos>']] for l in lines]
array = torch.tensor([
# 长度,填充,处理
truncate_pad(l,num_steps,vocab['<pad>']) for l in lines
])
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
# 一个句子里面填了很多东西,valid_len是句子的实际长度,不包括填充的
return array,valid_len
- array != vocab['
']
这种写法,可以参见下图(深度学习入门数据笔记5.5.1ReLU层的实现)

训练模型
def load_data_mnt(batch_size,num_steps,num_examples=600):
# 返回翻译数据集的迭代器和词汇表
text = preprocess_nmt(read_data_nmt())
# 获取source数据和翻译目标数据
source,target = tokenize_nmt(text,num_examples)
# 根据数据分别建立单词索引
src_vocab = d2l.Vocab(source,min_freq=2,reserved_tokens=['<pad>','<bos>','<eos>'])
tgt_vocab = d2l.Vocab(target,min_freq=2,reserved_tokens=['<pad>','<bos>','<eos>'])
# 根据这些索引表,把这些数据变为list
src_array,src_valid_len = build_array_nmt(source,src_vocab,num_steps)
tgt_array,tgt_valid_len = build_array_nmt(target,tgt_vocab,num_steps)
data_arrays = (src_array,src_valid_len,tgt_array,tgt_valid_len)
data_iter = d2l.load_array(data_arrays,batch_size)
return data_iter,src_vocab,tgt_vocab
-
有个疑惑,经过vocab之后source和target,顺序上还会相匹配吗?
答:经过vocab后顺序上source和target的确不匹配,vocab的作用不是确保顺序上相同,而是建议索引表,例如下图中索引后go和va顺序上的确对不上,但是后面经过build_array_nmt函数时,这里的source和target是一一对应的,从而最后得到的索引也是一一对应的
读出“英语-法语”数据集中的第一个小批量数据
train_iter,src_vocab,tgt_vocab = load_data_nmt(batch_size=2,num_steps=8)
for X,X_valid_len,Y,Y_valid_len in train_iter:
print('X:', X.type(torch.int32))
print('valid lengths for X:', X_valid_len)
print('Y:', Y.type(torch.int32))
print('valid lengths for Y:', Y_valid_len)
break
29. 编码器-解码器架构
61 编码器-解码器架构【动手学深度学习v2】_哔哩哔哩_bilibili
重新考察CNN
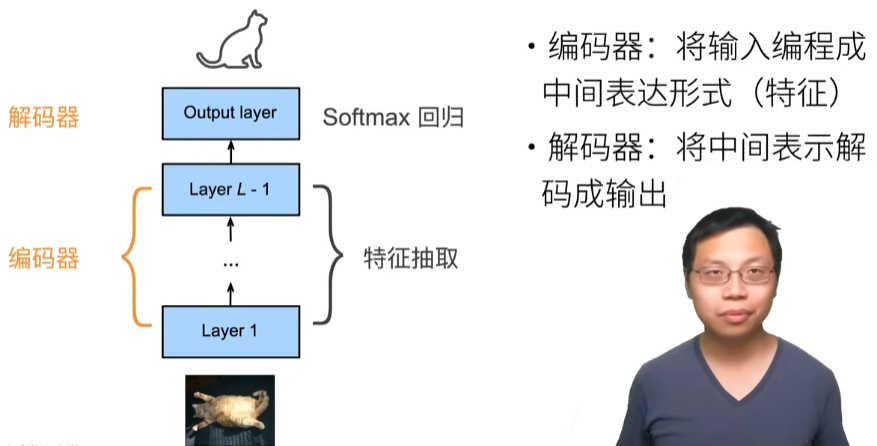
重新考察RNN
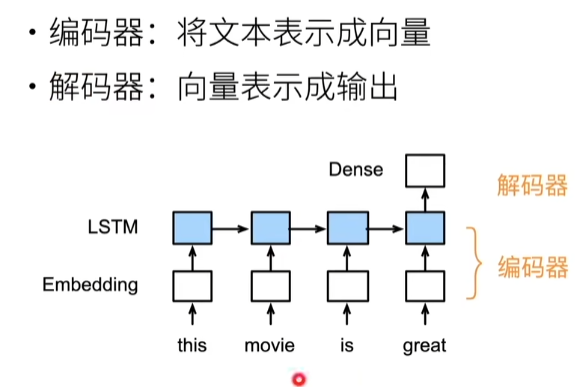
架构
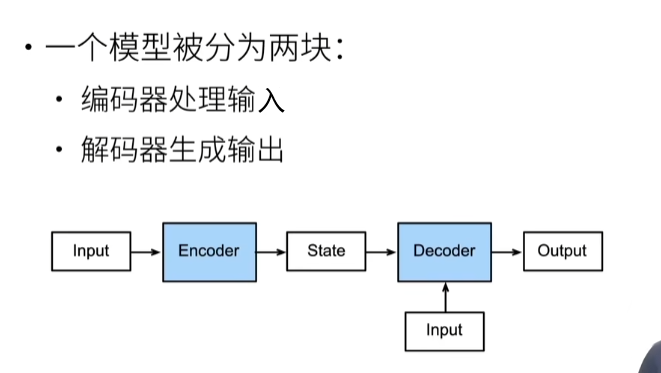
总结

代码实现
编码器
编码器不需要输出
from torch import nn
class Encoder(nn.Module):
# 编码器-解码器结构的基本编码器接口
def __init__(self,**kwargs):
super(Encoder,self).__init__(**kwargs)
def forward(self,X,*args):
raise NotImplementedError
解码器
class Decoder(nn.Module):
# 编码器-解码器的基本解码器接口
def __init__(self,**kwargs):
super(Decoder,self).__init__(**kwargs)
def init_state(self,enc_outputs,*args):
raise NotImplementedError
def forward(self,X,state):
raise NotImplementedError
合并编码器和解码器
class EncoderDecoder(nn.Module):
# 编码器-解码器结构的基类。
def __init__(self,encoder,decoder,**kwargs):
super(EncoderDecoder,self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self,enc_X,dec_X,*args):
enc_outputs = self.encoder(enc_X,*args)
dec_state = self.decoder.init_state(enc_outputs,*args)
return self.decoder(dec_X,dec_state)
30. 序列到序列学习(seq2seq)
62 序列到序列学习(seq2seq)【动手学深度学习v2】_哔哩哔哩_bilibili
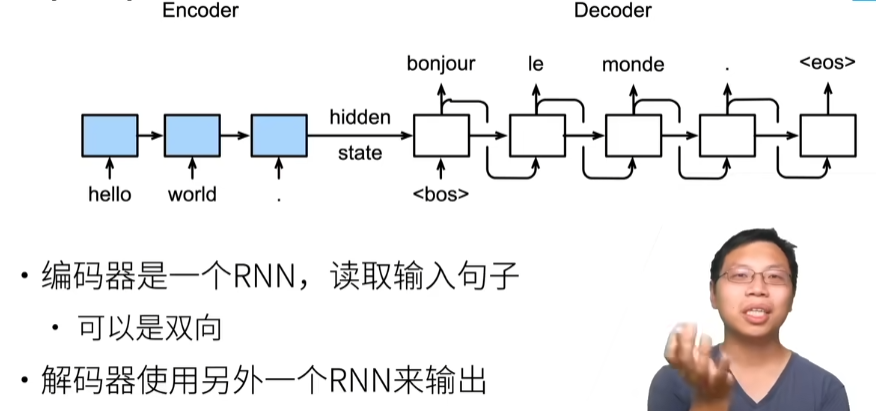
细节
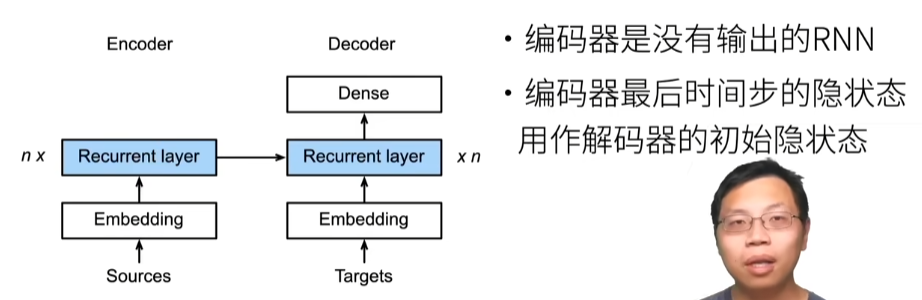
训练
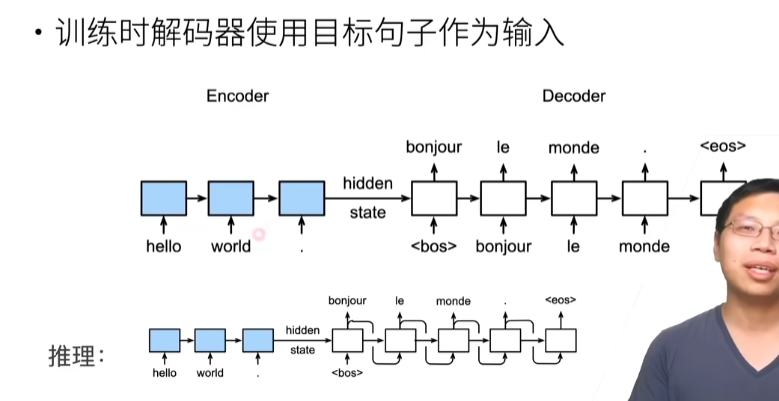
推理时,没有句子作为输入,bos右边就没有输入
衡量生成序列的好坏的BLEU
- unigram一个单词
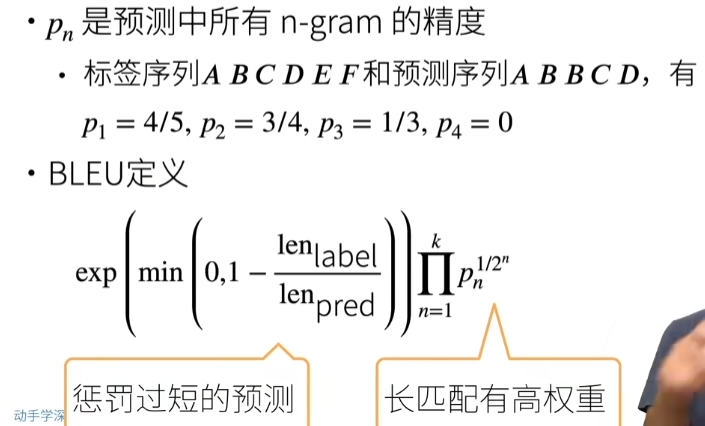
p1是unigram(1个连续词),预测序列里面,5个预测到了4个
p2是bigram(2个连续词),就是AB,BC,CD。预测序列里面有5个词,有4个bigram分别是AB,BB,BC,CD,4个里面预测到了3个
p3是trigram(3个连续词),就是ABC,BCD,CDE。预测序列里面有5个词,有3个bigram分别是ABB,BBC,BCD,3个里面预测到了1个
p4是4-gram(4个连续词),就是ABCD,BCDE。预测序列里面有5个,有2个4-gram分别是ABBC,BBCD。预测到了0个
总结

代码实现
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
实现循环神经网络编码器
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,
dropout=0,**kwargs):
super(Seq2SeqEncoder,self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size,embed_size)
self.rnn = nn.GRU(embed_size,num_hiddens,num_layers,dropout=dropout)
def forward(self,X,*args):
X = self.embedding(X)
X = X.permute(1,0,2) # 将batch和num_step维度交换一下
output,state = self.rnn(X)
return output,state
-
通过叠加LSTM层,可以创建表现力更强的模型,但是这样的模型容易过拟合,抑制过拟合的方法有增加训练数据,二是降低模型的复杂度。除此之外还有给予惩罚项的正则化,例如dropout。
-
permute
进行维度换位https://zhuanlan.zhihu.com/p/76583143

- 为什么要x.permute(1,0,2)
这里的0是batch_size,1是num_step(每个子区间文本的长度),num_step可以当做时序来用,换车(num_step,batch)后,不同的num_step对应不同的文本,符合时序要求
上述编码器的实现
encoder = Seq2SeqEncoder(vocab_size=10,embed_size=8,num_hiddens=16,num_layers=2)
encoder.eval() # dropout不生效
X = torch.zeros((4,7),dtype=torch.long)
output,state = encoder(X)
output.shape # torch.Size([7, 4, 16])
- X = torch.zeros((4,7),dtype=torch.long)
生成一个4行7列的矩阵,全部都是0,经过embedding(shape为【10,8】)层后,X中的0元素对应embedding层的第0行,所以经过embedding后的X的shape为(4,7,8)
state.shape
# torch.Size([2, 4, 16])
- 为什么是2,4,16
根据文档GRU的输入参数GRU — PyTorch 1.12 documentation
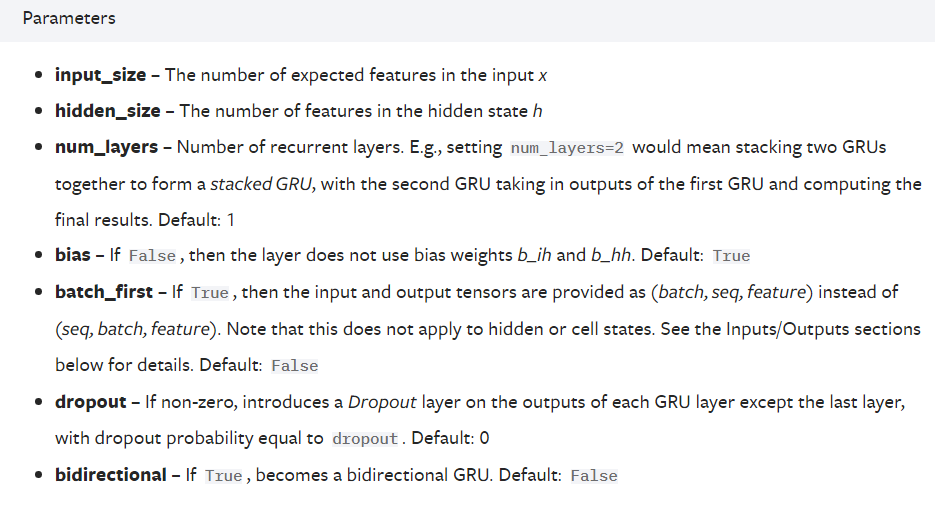
我们得知,embed_size是input_size是8,num_hiddens是hidden_size是16,num_layers是num_layers是2。
又根据输入的参数,这里的X是经过permute后的shape是[7,4,8]

知道输入时X的shape中7是L,4是N,8是Hin。输出后的shape如下图

经过GRU后,2是D*num_layers(这里的D是1,因为不是双向RNN),4是N,16是Hout,所以state.shape的shape是[2, 4, 16]
解码器
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,
dropout=0,**kwargs):
super(Seq2SeqDecoder,self).__init__(**kwargs)
# 解码器的vocab_size和编码器的vocab_size不一样,毕竟这里是法语
self.embedding = nn.Embedding(vocab_size,embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens,num_hiddens,num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
# init_state是enc_outputs是前面解码器的(output,state),enc_outputs[1]就是把state拿出来
def init_state(self,enc_outputs,*args):
return enc_outputs[1]
def forward(self,X,state):
X = self.embedding(X).permute(1,0,2)
# state[-1]是最后一个时刻encoder的输出,把这个输出拿出来,重复多次
context = state[-1].repeat(X.shape[0],1,1)
X_and_context = torch.cat((X,context),2)
output,state = self.rnn(X_and_context,state)
output = self.dense(output).permute(1,0,2)
return output,state
实例化解码器
decoder = Seq2SeqDecoder(vocab_size=10,embed_size=8,num_hiddens=16,num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output,state = decoder(X,state)
output.shape,state.shape
# (torch.Size([4, 7, 10]), torch.Size([2, 4, 16]))
通过零值化屏蔽不相关的项
def sequence_mask(X,valid_len,value=0):
maxlen = X.size(1)
print(maxlen) # 3
mask = torch.arange((maxlen),dtype=torch.float32,device=X.device)[None,:] < valid_len[:,None]
X[~mask] = value
return X
X = torch.tensor([[1,2,3],[4,5,6]])
# 假如现在有两个句子,第一个句子的长度为1,第二个句子的长度为2,那么后面的会被置为0
sequence_mask(X,torch.tensor([1,2]))
# tensor([[1, 0, 0],
# [4, 5, 0]])
通过扩展softmax交叉熵损失函数来遮蔽不相关的预测
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction = 'none'
unweighted_loss = super().forward(pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
代码健全性检查
loss = MaskedSoftmaxCELoss()
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long),
torch.tensor([4, 2, 0]))
训练
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型。"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2)
for batch in data_iter:
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1)
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward()
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
创建和训练一个循环神经网络“编码器-解码器”模型
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
将几个英语句子翻译成法语
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')

31. 束搜索
63 束搜索【动手学深度学习v2】_哔哩哔哩_bilibili
贪心搜索
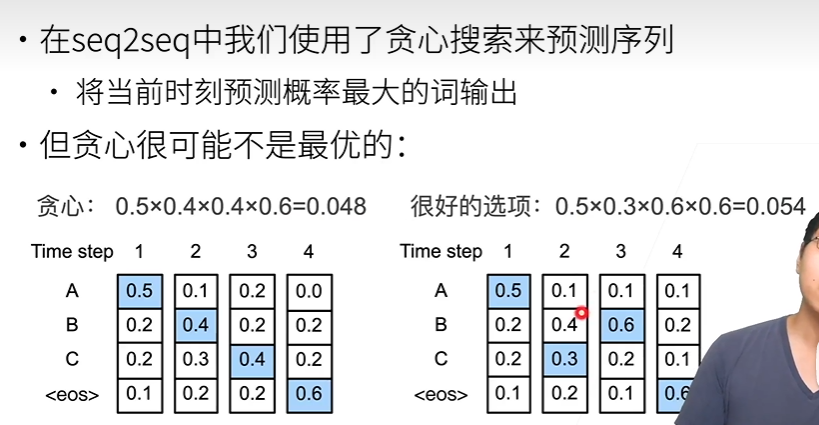
穷举搜索

束搜索
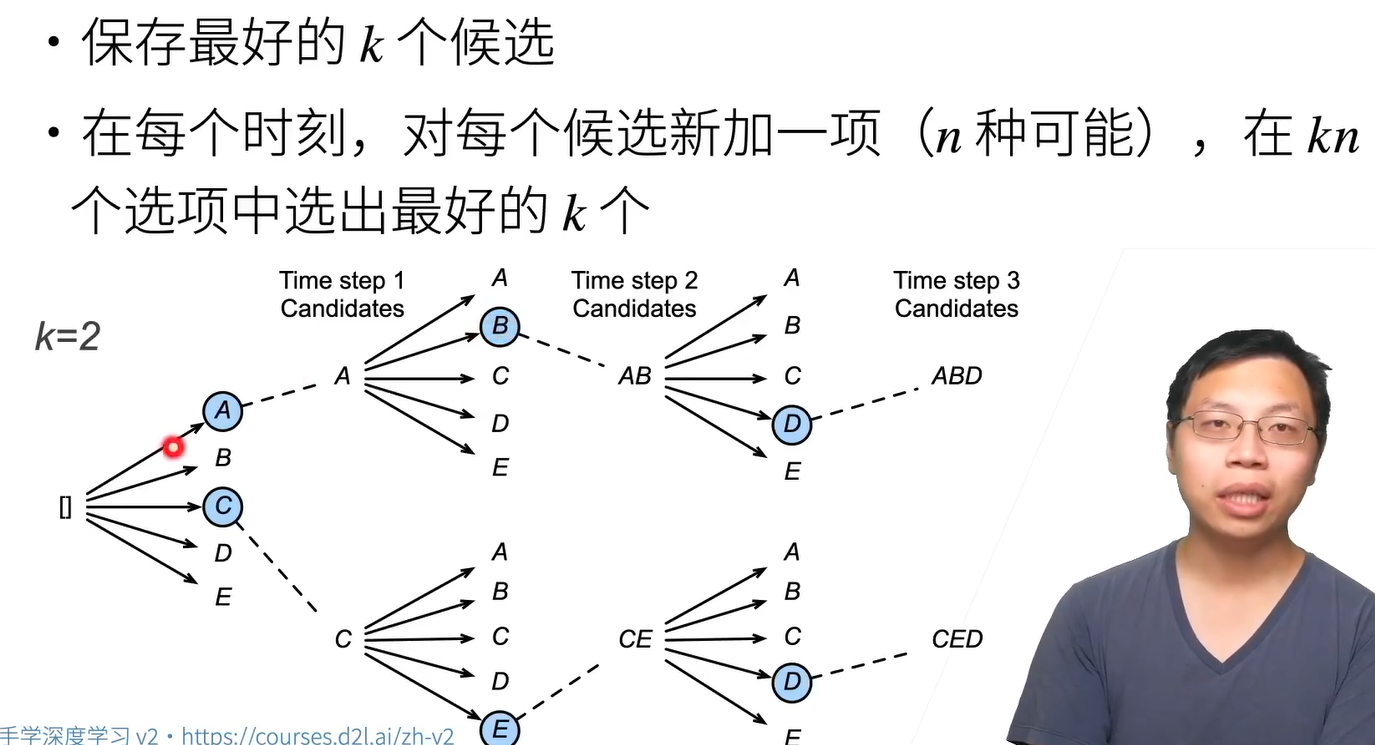

总结
这里k=n不是穷举

32. 注意力机制
64 注意力机制【动手学深度学习v2】_哔哩哔哩_bilibili
这个博客不错:https://www.cnblogs.com/nickchen121/p/16470711.html
随意线索
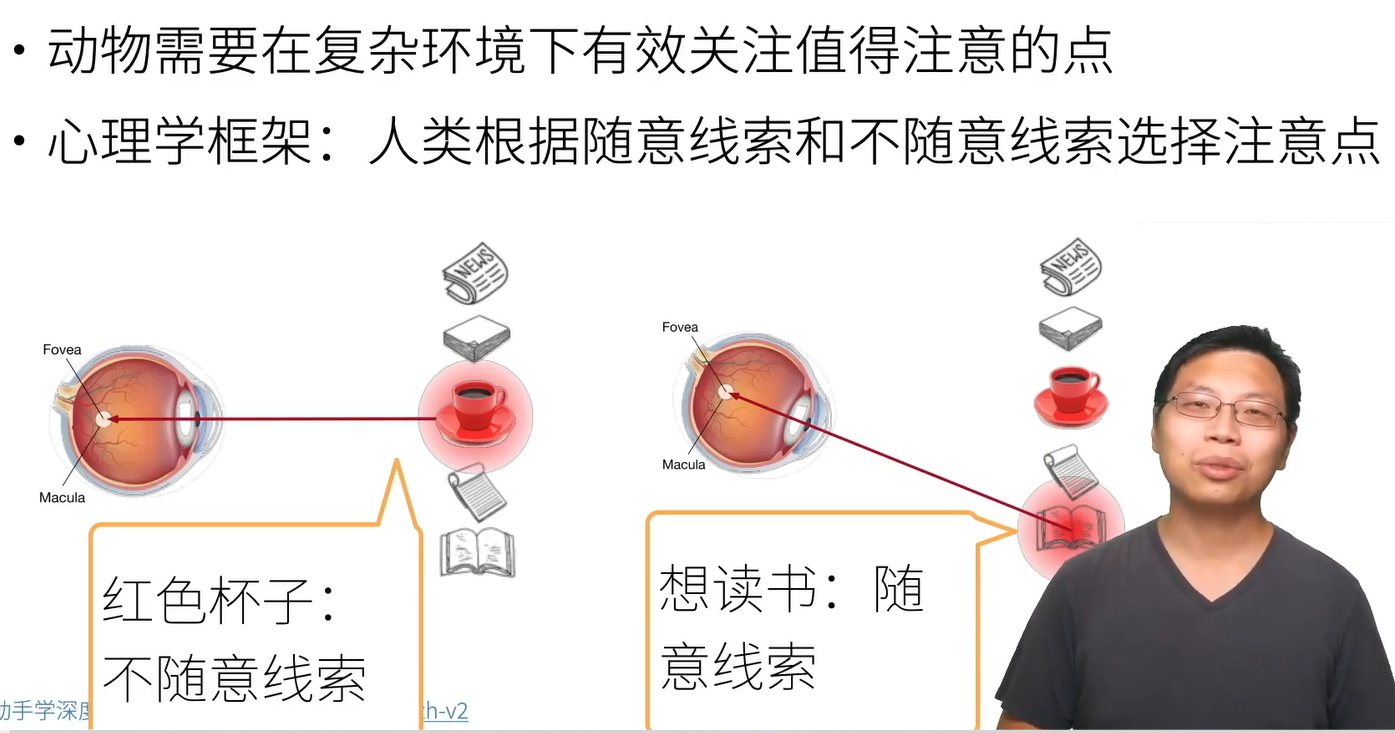
注意力机制
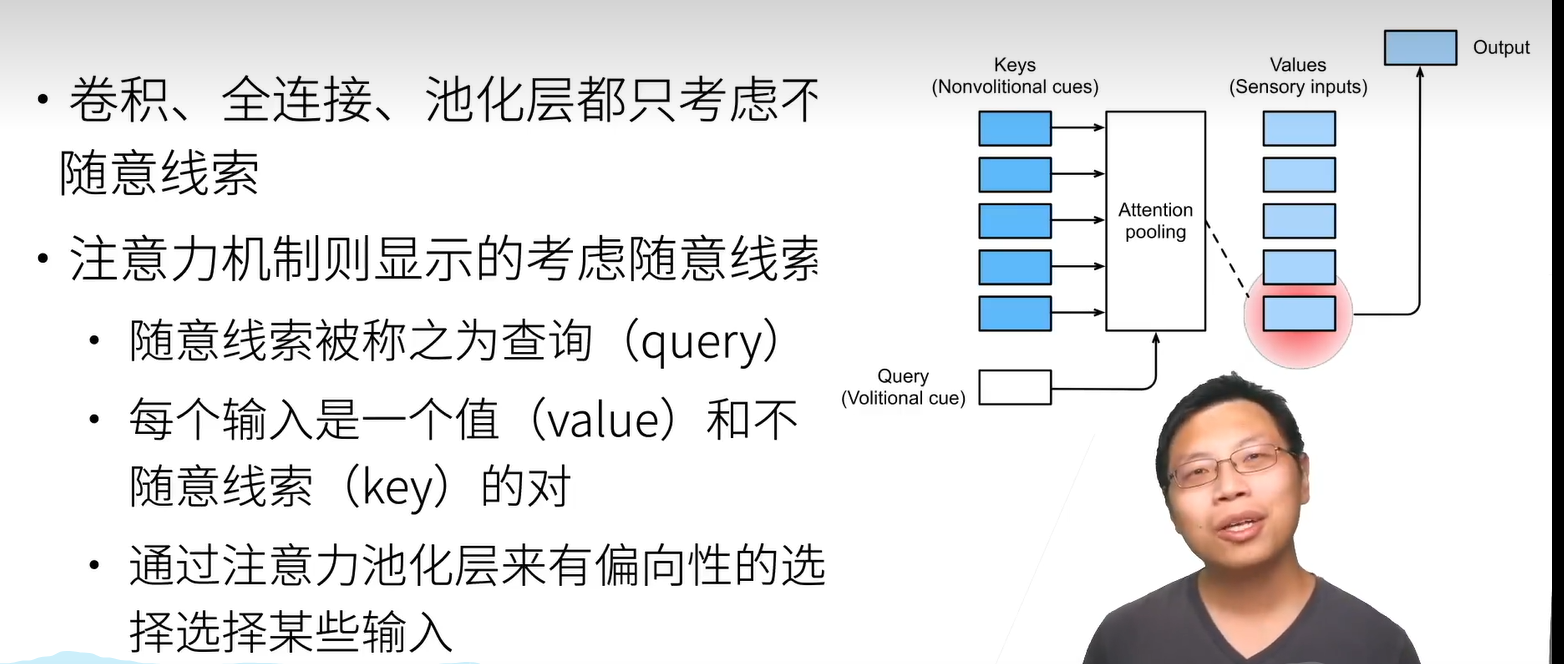
非参注意力池化层
x是你的query,K是个函数

Nadaraya-watson核回归

参数化的注意力机制

总结

33. 注意力分数
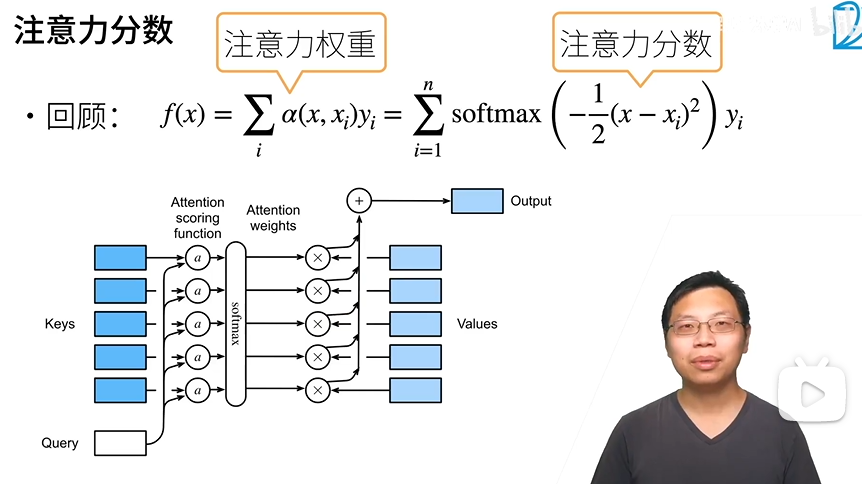
扩展到高纬度

Additive Attention

Scaled Dot-Product Attention

总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号