
跟着李宏毅需机器学习
机器学习基本概念简介
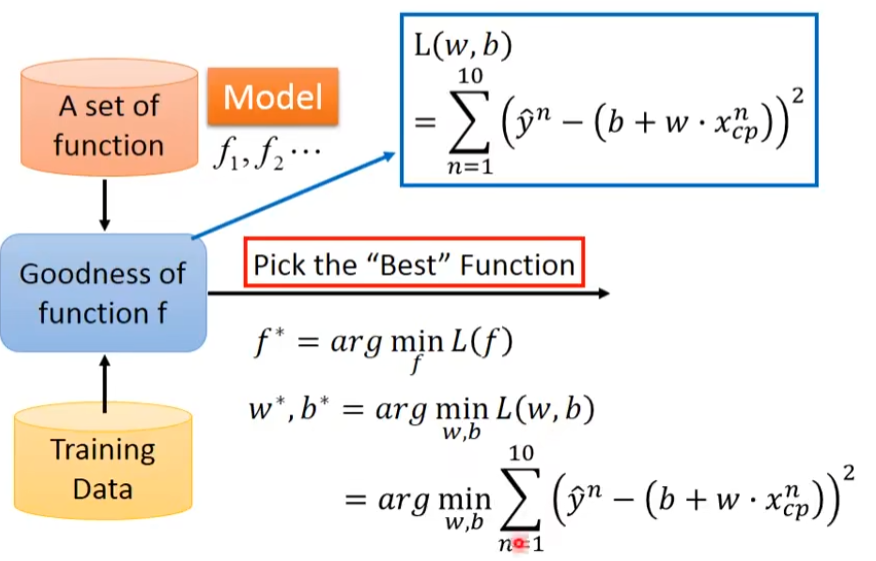
怎样找出这个函数-三个步骤
1.Function with Unknown Parameters
简单说就是,我们先猜测以下我们打算找的这个函数,它的数学公式是什么样子,比如说函数和的输入和输出是什么关系呢?,下面通过预测youtub的观看人数为例:
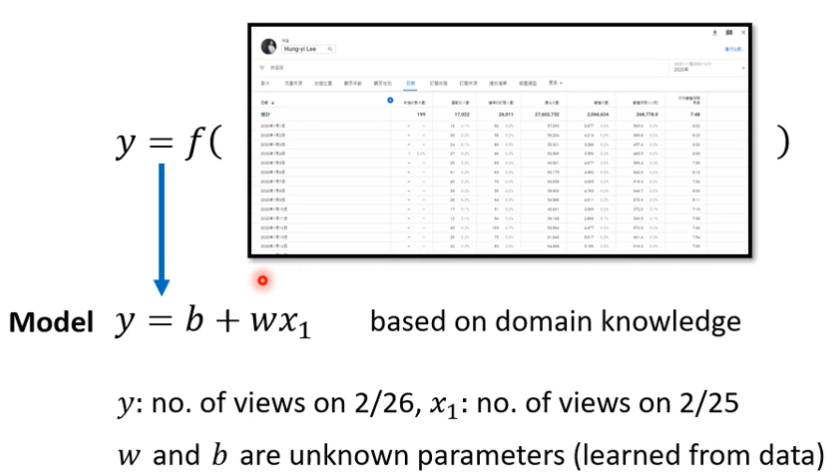
y是需要预测的东西,x1是前一天点赞的人数,b和w是未知的参数,是随便猜测,后期再改。
Model是带有未知的Parameterd的Function,
feature是前一天的点赞数量,是已经知道的值,这里的x1就是feature
w,b我们是不知道的,它是unknown的parameter
2.Define Loss from Training Data
Loss也是一个function,它的输入是model里面的参数,可以判断这个参数好不好

怎样计算Loss呢?
我们需要通过这个训练数据来进行计算,这个训练数据是什么呢?可以是之前的数据

如果1月1号的点赞数是4.8k,那么1月2号的点赞预测值是5.3k,这时候我们再和真正的结果(4.9k)进行比较,看下差距有多大,y是5.3k,ŷ是4.9k,e1是差距0.4k,需要取绝对值,这个真实的值我们称之为label,label指的是正确的数值

接下来计算1月3号的预测值,e2为2.1k

继续算下去,把三年的误差可以通通算出来

然后我们这三年的误差加起来,取平均值,这个L值越大,说明这一组参数越不好
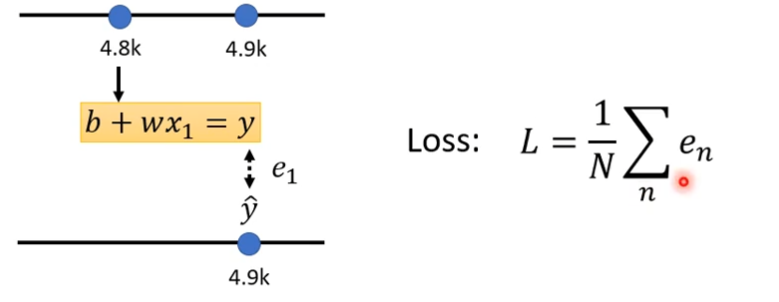
e的计算方法
- MAE
- MSE

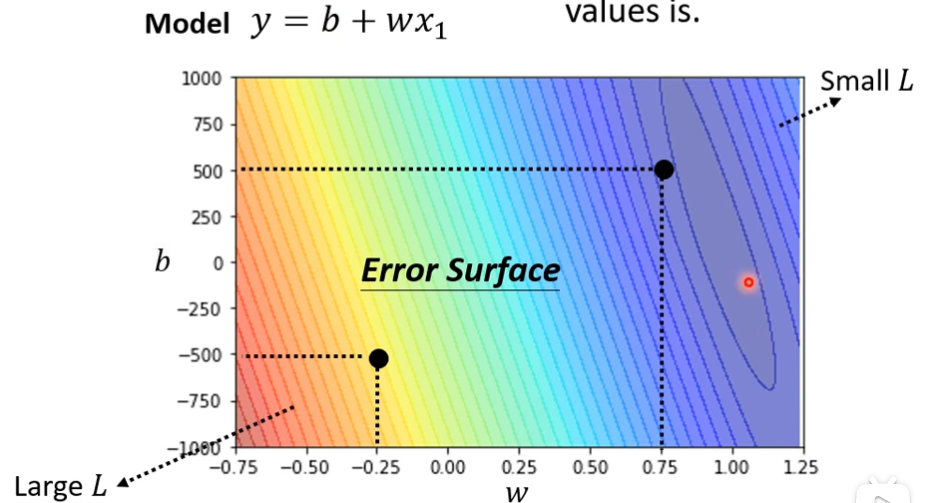
不同的w和b的组合结果的高线图,越偏红色,说明w和b的组合非常差,越偏蓝色,说明w和b的组合比较好,计算了不同的参数,然后画出来的高线图叫做error surface
3.Optimization
找一个w和b,看带那一个数值进去,可以让我们的L也就是Loss值最小,那就是我们要找的w和b,我们要找的w和b称为w,b**
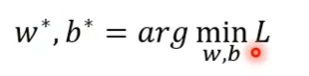
我们会用到的方法是Gradient Descent,根据已有的数据的分布来预测可能的新数据,这是回归,希望有一条线将数据分割成不同的类别,这是分类,梯度下降就是沿着梯度所指出的方向,一步一步向下走,去寻找最小损失函数值的过程。沿着梯度向量的方向就是(∂f/∂x0, ∂f/∂y0)T的方向是f(x,y)增加最快的地方。或者说,沿着梯度向量的方向,更加容易找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是 -(∂f/∂x0, ∂f/∂y0)T的方向,梯度减少最快,也就是更加容易找到函数的最小值。
只有一个参数的情况下
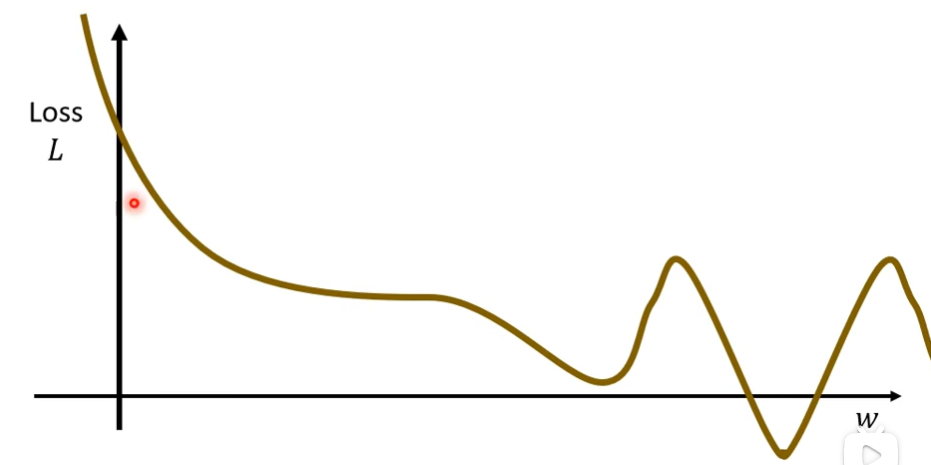
(1)我们先假设没有b这个参数
w取不同的值,我们会得到不同的Loss
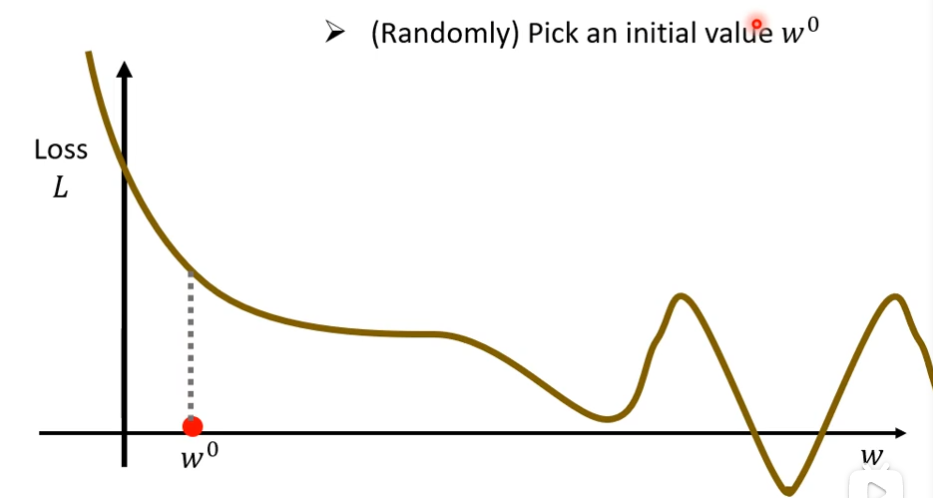
(2)然后,随机选取一个初始的点叫做w0
(3)接下来计算w等于w0处的偏导数,也就是error surface在这个点的切线斜率
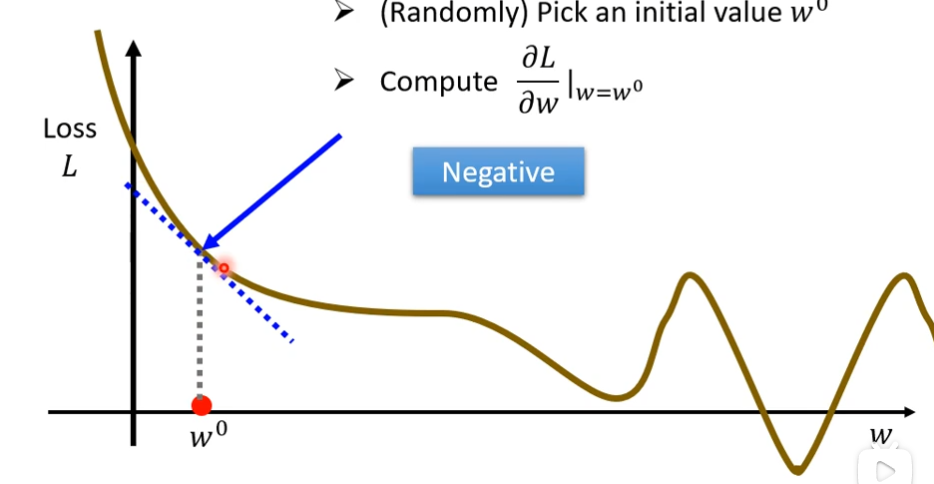
如果这个斜率的值是负的代表左边比较高,右边比较低,这时候,我们需要增大w的值,这样Loss的值就可以变小
如果这个斜率的值是正的代表左边比较低,右边比较高,这时候,我们需要减少w的值,这样Loss的值就可以变小
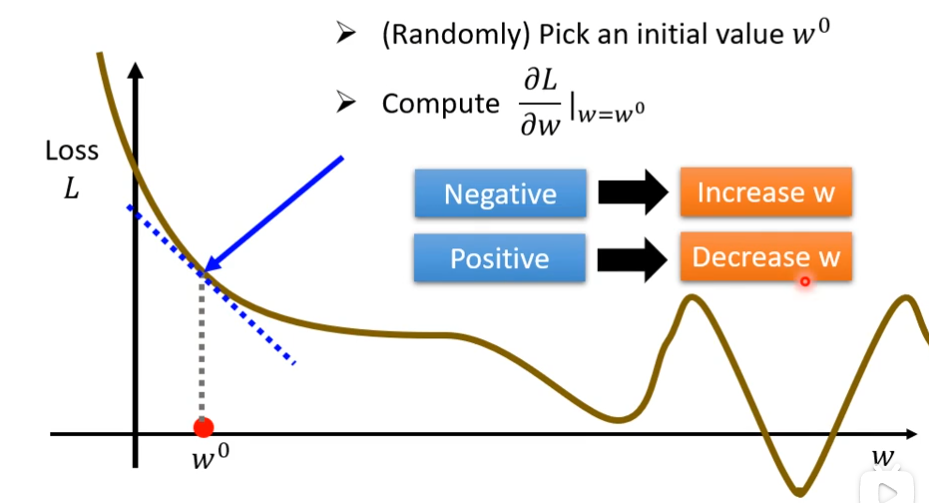
切线斜率,可以比作一个人在一个点左顾右盼,看那边低就往哪边跨一步,那么一步要跨多大呢?
这一步的步伐的大小取决于两件事情
-
这个地方的斜率有多大,斜率大,步伐就跨大一点,斜率小,步伐就跨小一点
-
学习速率(learning rate)也就是η,这个是自己设定的
在做机器学习时,自己设定的东西叫做hyperparameters
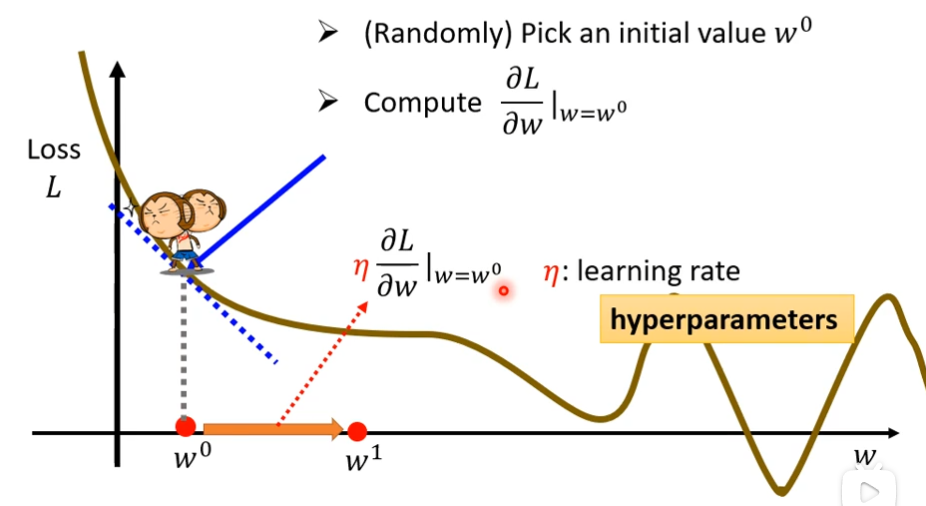
为什么Loss可以是负的呢?
答:因为Loss这个function是你自己决定的,所以可能有负的。
(4)接着,我们把w0右移一步得到一个新的位置叫做w1, 这一步的步伐就是η乘以微分的结果,用数学表达式就是w0减去η乘上微分的结果得到w1
(5)接下来,就是计算w1微分的结果,再决定从w1跨多大的步伐到w2
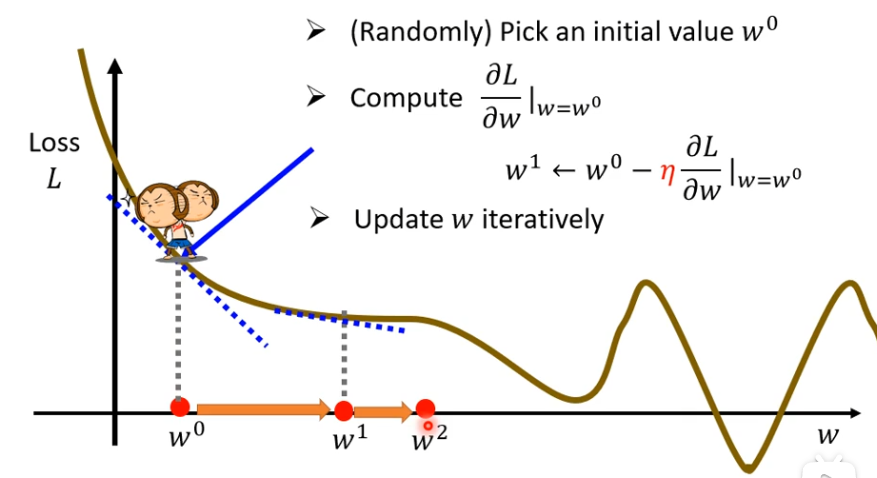
(6)不断反复重复同样的操作,不断的把w移动位置,最后会停下来
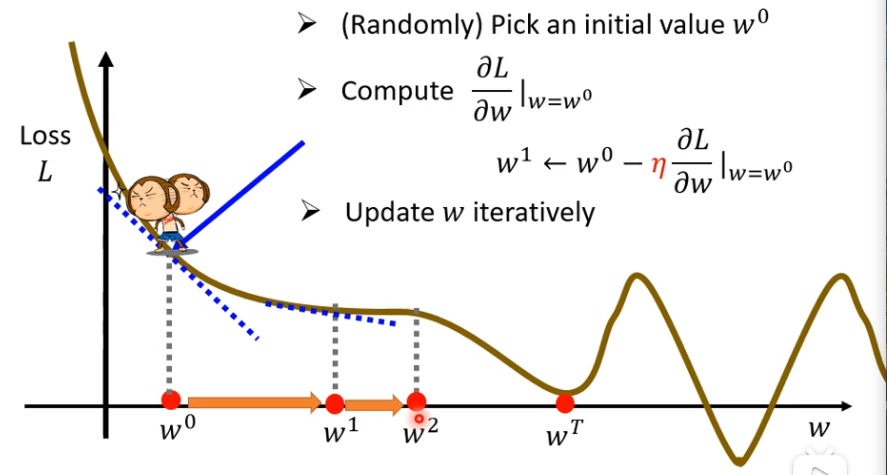
停下来往往有两种状况
-
第一种失去耐心,比如说我设定今天要更新1百万次,超过这个了,我就不更新了,这个决定更新多少次也是hyperparameter
-
还有一种就是某个点处的微分值是0的时候,0×learning rate还是0,这时候就不会更新了
Gradient Descent的一个缺点是,我们有时没能找到可以让Loss最小的那个点w , 例如下图到wT就停止了,如果设置初始的点为w0,那么走到wT这里就停止了。可以Loss的值达到最小的点叫做global minima,wT这个位置叫做Local minima,
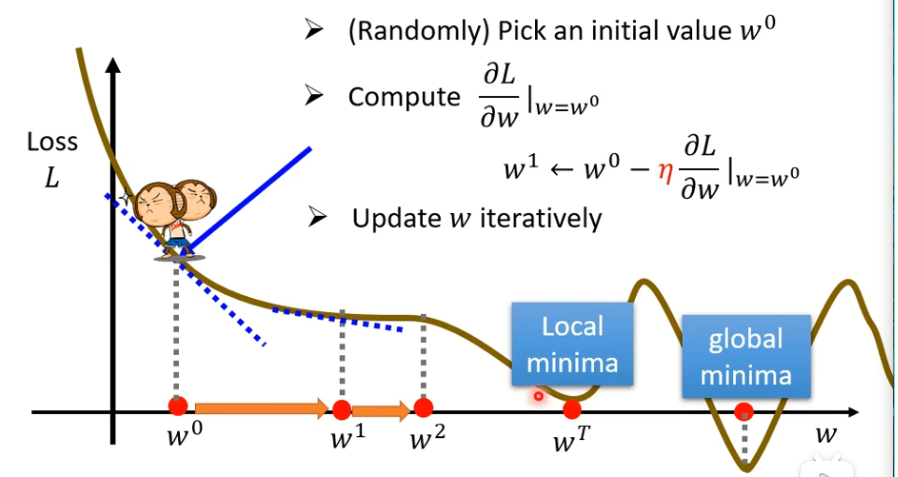
两个参数的情况下
(1)随机取两个初始值w0,b0

(2)分别求偏导,然后更新w1,b1,微分这些东西python会帮你算的
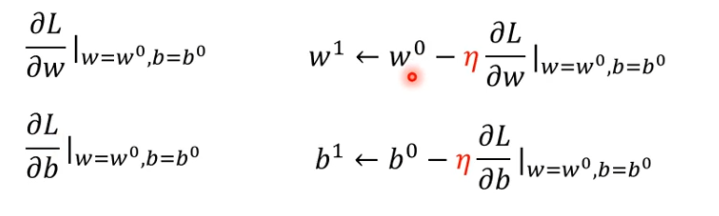
(3)反复重复同样的步骤,不断更新w和b,最后就会找到最好的w和b**
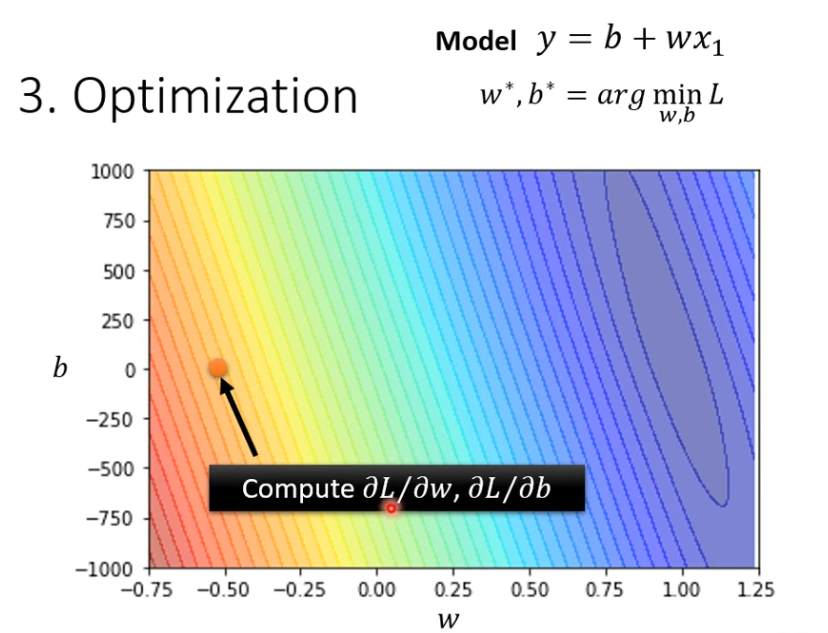
举例
(1)先计算微分
(2)更新w和b,更新的方向就是(-η ∂L / ∂w,-η ∂L / ∂b)
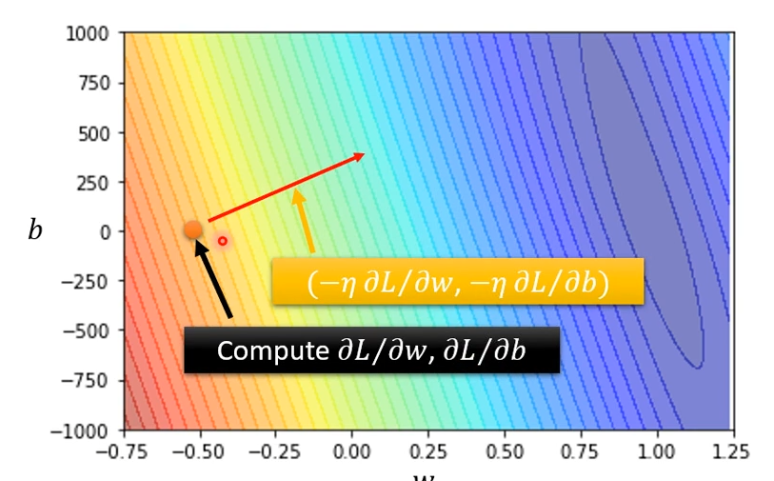
再计算一次,决定更新的方向
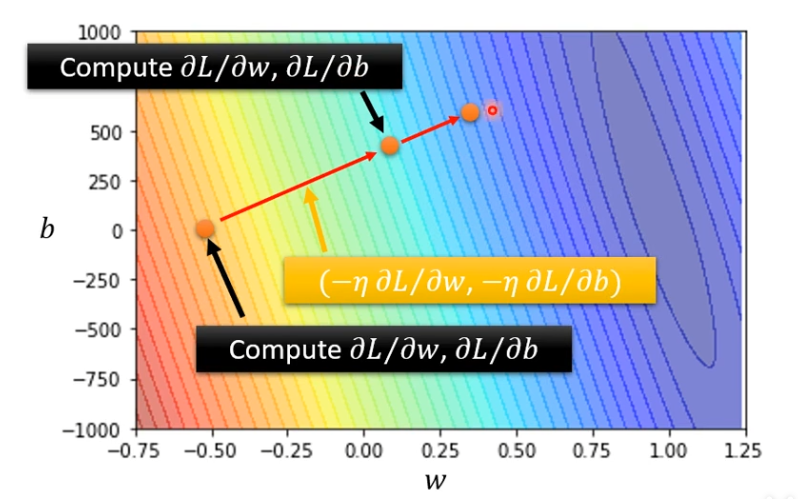
就这样一直移动,直到找出一组不错的w和b
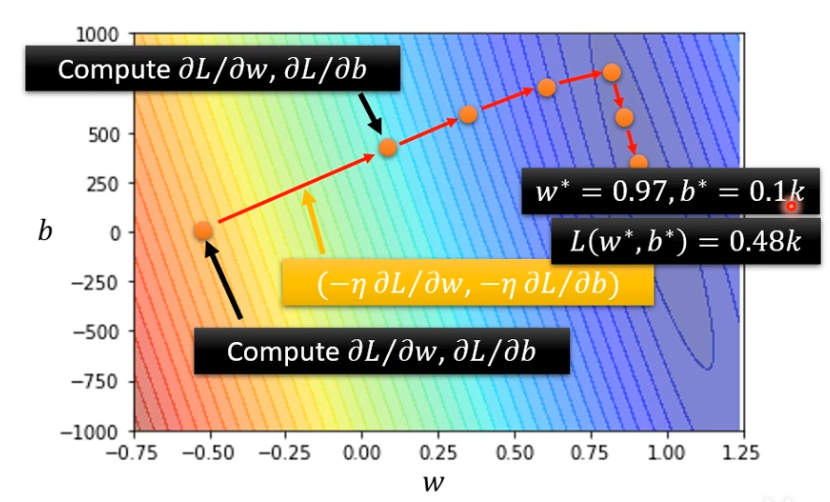
总结
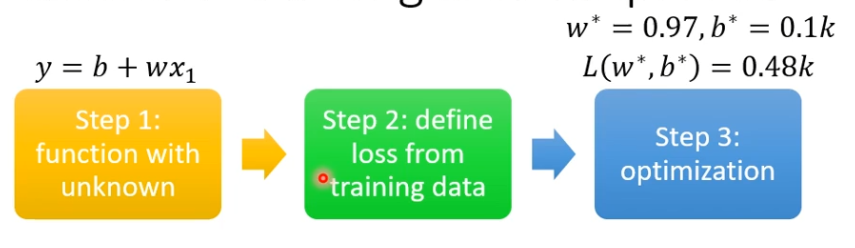
找出函数的步骤
(1)写出带参数的函数
(2)定义了一个叫做Loss的function
(3)优化,找到一组w和b能让Loss最小
上述三个步骤叫做训练
函数的优化
预测点赞数量和实际点赞数量图如下所示,可以看出一个规律,每隔一个星期为一个周期,我们可以考虑优化一下模型,把天数带进去。
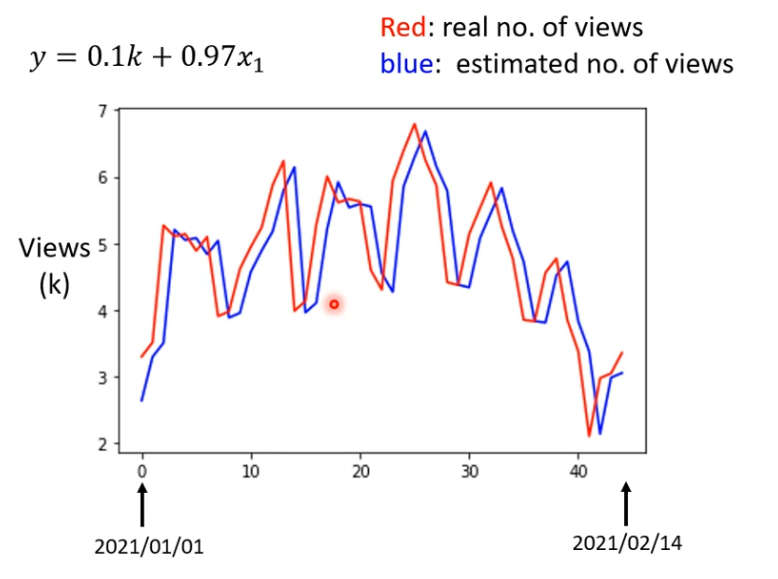
一开始写的这个模型很烂,因为每天的预测需要看前一天,如果每隔7天一个循环,我们需要看7天的数据,如果我们把前7天的数据拿来当做预测,也许会更准。考虑一天是0.58的误差,考虑7天是0.49的误差
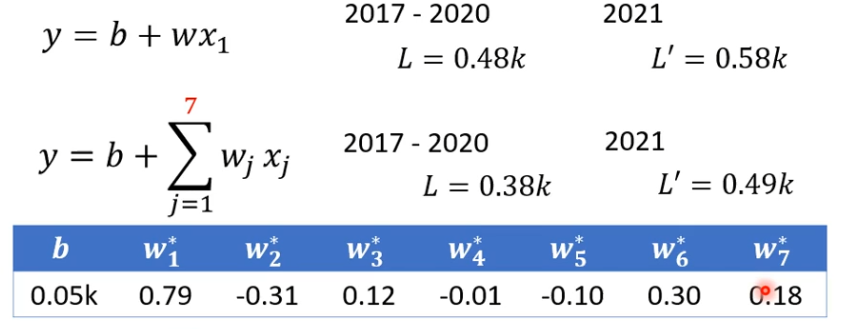
7天比1天的误差小些,那么会不会天数再大点误差会更小呢?
果然28天的误差比7天的误差小点
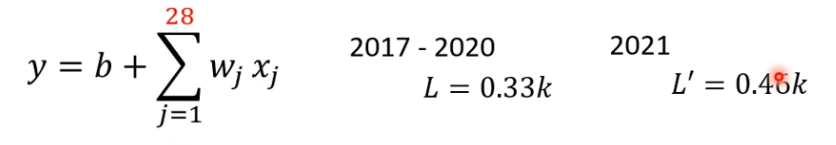
再试试,增加天数,发现56天,已经无法提升了。
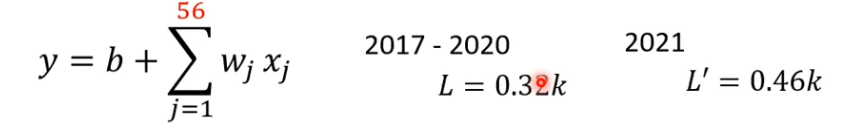
xj称为feature,乘上weight,在加上bias就是预测结果了。这样模型有一个共同的名字叫做Linear Model
Linear Model
线性模型无论怎么变,y都是随着x的增大而增大,现实中,这种情况不多。线性模型有很大的局限性,这种来自model的限制叫做的model的bias。
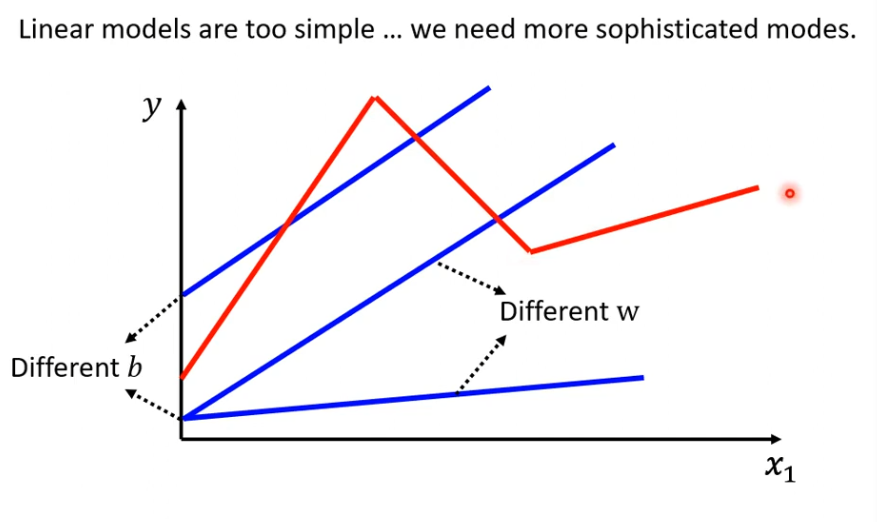
现实中的数据可能是红线那种样子,我们需要写一个更复杂,带有未知参数的Function,Linear的Model显然不够。那么如何写出一个复杂的又带有未知参数的Function呢?
我们可以把红色线段看做一个常数加上一群蓝色的Function,蓝色线段可以看做当x轴的值小于某一个点的threshold的时候,它是某一个定值,大于某个threshold的时候,是另一个定值,中间有一个斜坡,先水平再斜坡,然后再水平。
Piecewise Linear Curves(分段线性曲线)
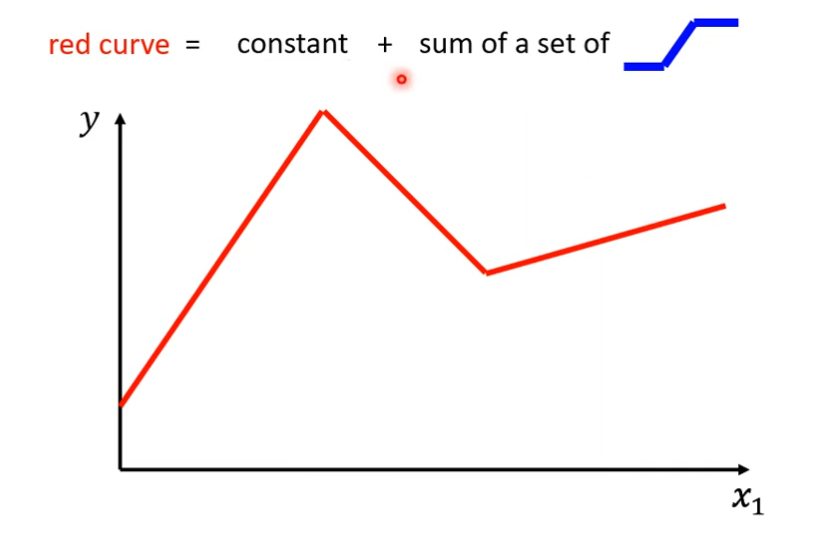
那么这个常数值要多大呢?
答:需要看这个红色的线跟y轴的交点是多少
怎样加上蓝色的线然后就变成红色的这条线呢?
答:
(1)蓝色线段这个斜坡的起点,设在红色线段起始的地方,斜坡的终点设在红色线段的第一个转角处,接着让蓝色线段的斜坡和红色线段的第一个斜坡的斜率一样。
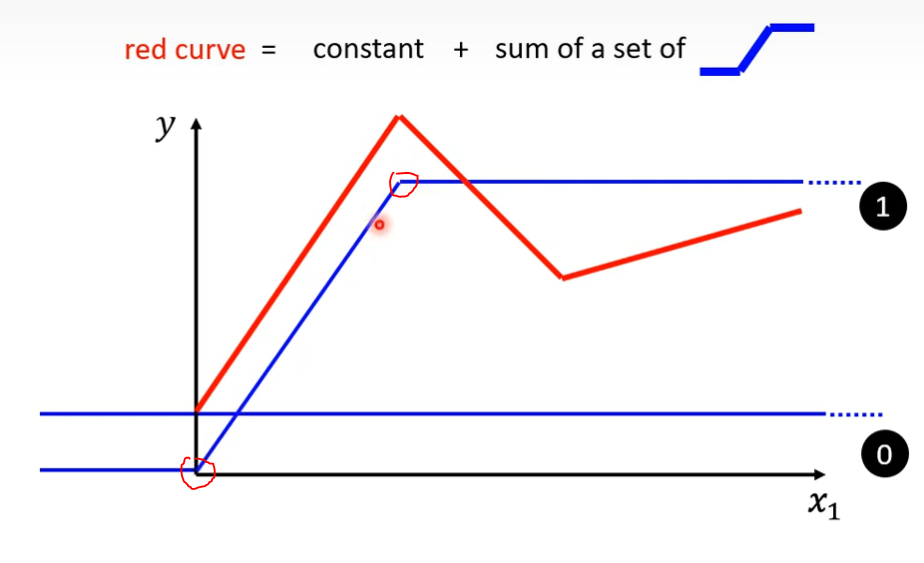
(2)这时候把0(不是数字0,是constant)加上1(不是数字1,是蓝色线段),就可以得到红色线段的第一斜坡的数据,也就是绿色方框内的红色线段
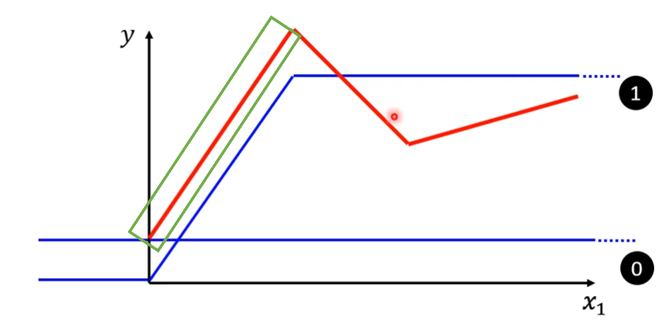
(3)这时候再找第二个蓝色线段,这个蓝色线段的斜率要和红色线段的第二个斜坡的斜率相同,蓝色线段的斜坡要在红色线段的第一个转折点和第二个转折点之间,也就是两条黄色虚线之间。
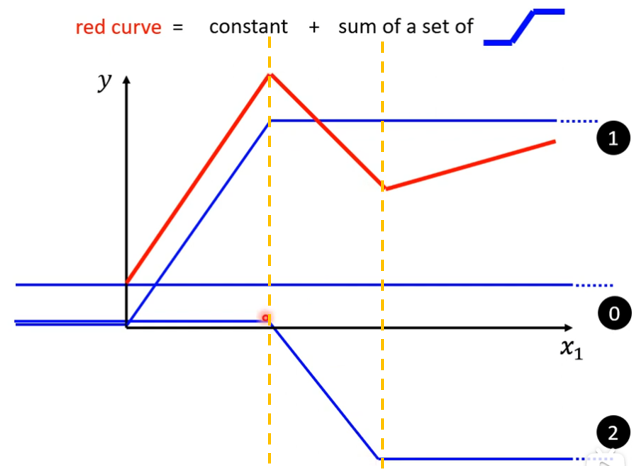
(4)接下来就是找第三个蓝色线段,最后0+1+2+3就等于红色线段,所以红色线段可以看做一个常数+若干个蓝色线段组合而成。

我们发现这些Piecewise Linear可以用一个常数项加一大堆的蓝色Function组合出来,只是这些蓝色Function不见得一样
如果线段是个曲线怎么办,就如下图那样?
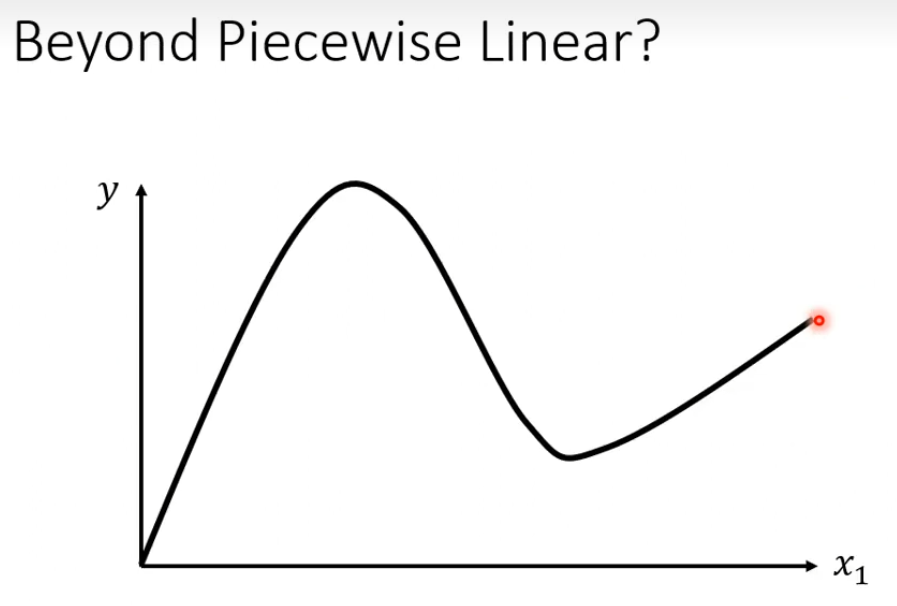
答:我们可以在这些曲线上先取一些点,然后再把这些点连起来,就像下图那样,这样构成piecewise linear和曲线非常接近,点取的越多就越接近
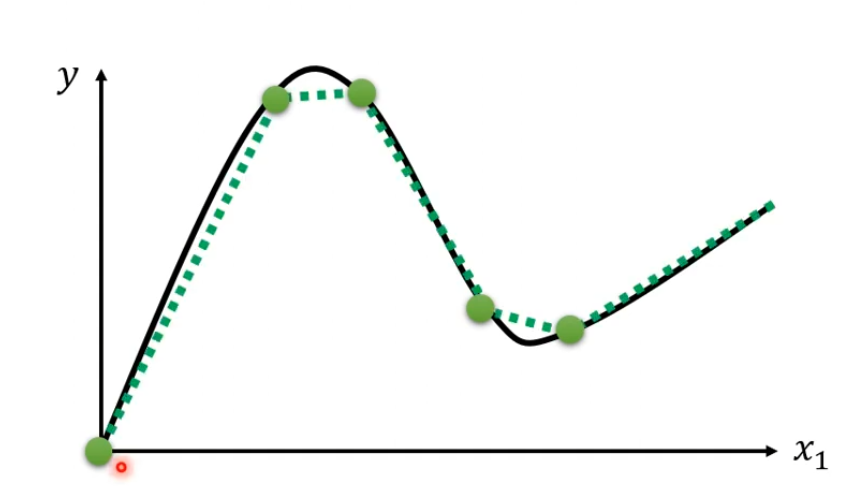
如何表达出蓝色Function
有时候蓝色线段不好表达出来,但是可以用一条曲线来逼近它,那么用什么曲线来逼近它呢?
答:用一个Sigmoid的Function,Sigmoid function 逼近的蓝色Function我们称为Hard Sigmoid
(Sigmoid 是常用的非线性的激活函数,可以将全体实数映射到(0, 1)区间上,其采用非线性方法将数据进行归一化处理;sigmoid函数通常用在回归预测和二分类(即按照是否大于0.5进行分类)模型的输出层中。)
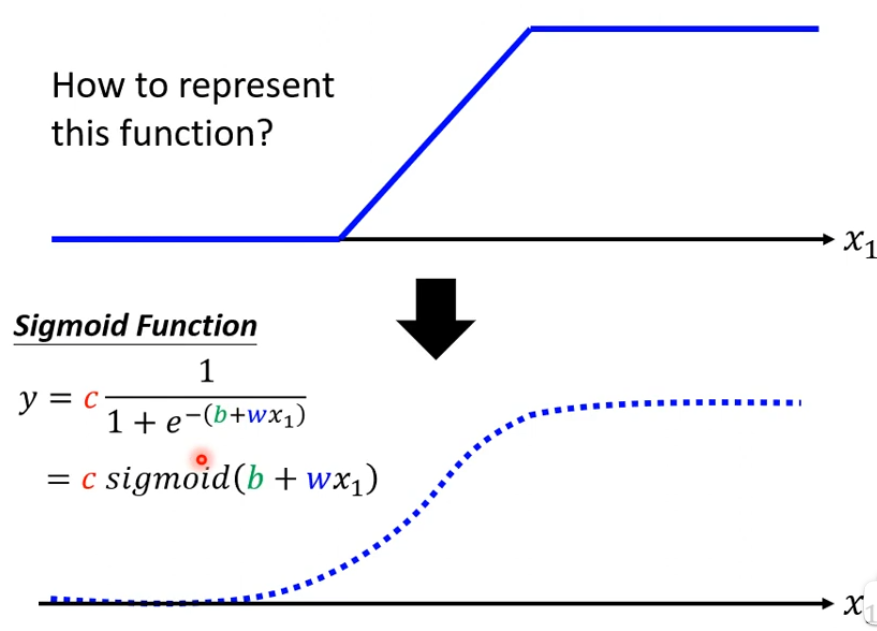
我们需要各种不同的蓝色的Function,而这些蓝色的Function就需要调整这里的b和w和c来制造出来,调整b和w和c就可以制造各种不同形状的Sigmoid Function,然后用这些去逼近这些蓝色的Function,调节b和w和c的效果如下:
调节w会改变斜率,也就是斜坡的坡度
调节b会让sigmoid function左右移动
调节c会就会改变高度
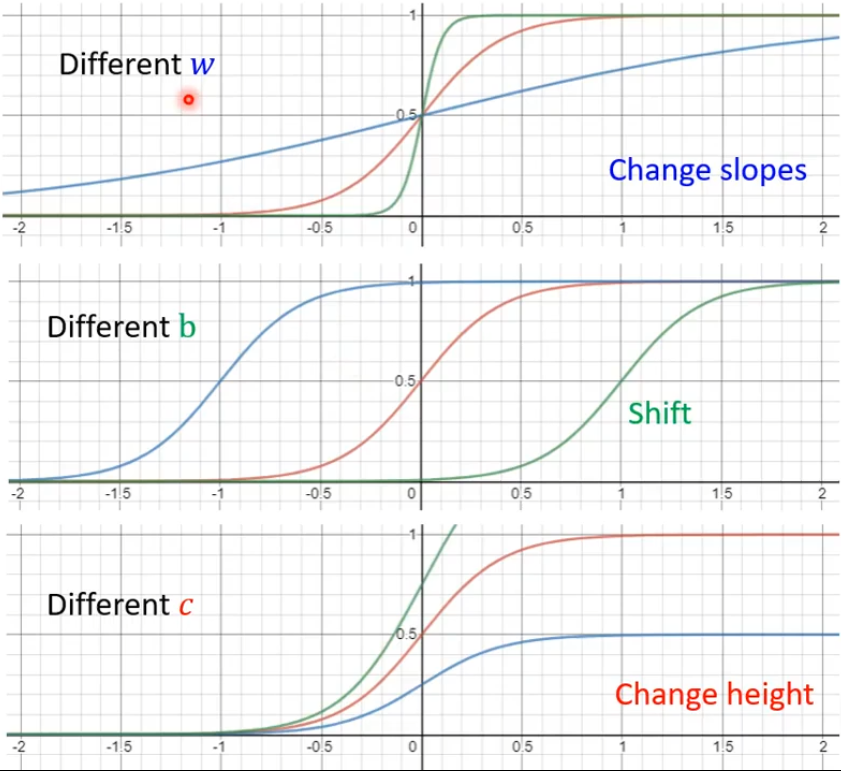
各种不同的Sigmoid Function可以逼近各种不同的Piecewise Linear Curves,然后Piecewise Linear Curves可以逼近不同的Continuous Function。这个y就是piecewise linear curves的近似值。
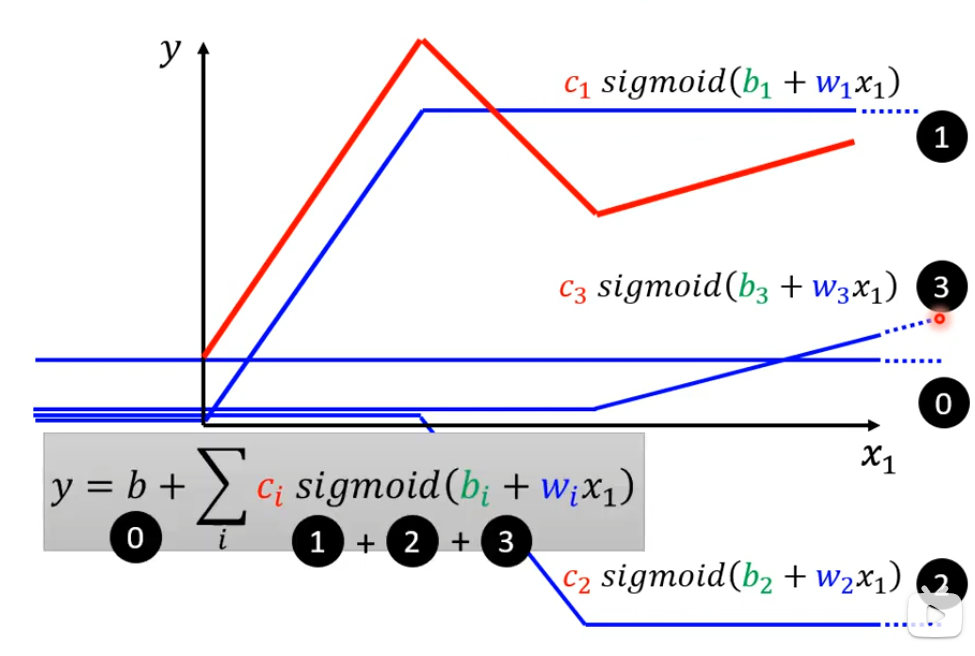
含有sigmoid的机器学习第一步
Linear Model有非常大的限制,这个限制叫做Model的Bias,我们可以写一个弹性的,有未知参数的Function,如下图。
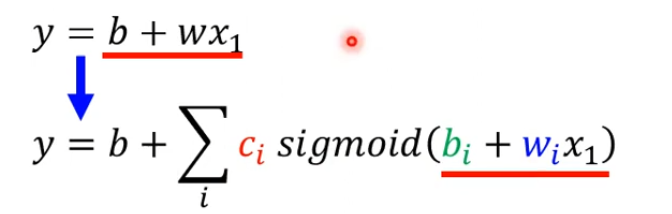
当我们用的是多个feature,这个j是feature的编号,考虑28天的话就是1到28,扩展一下就是下图这样
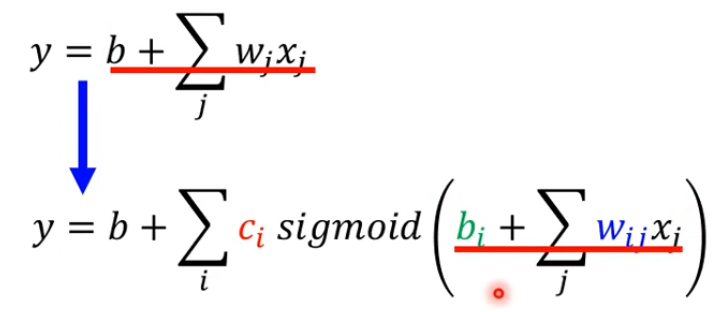
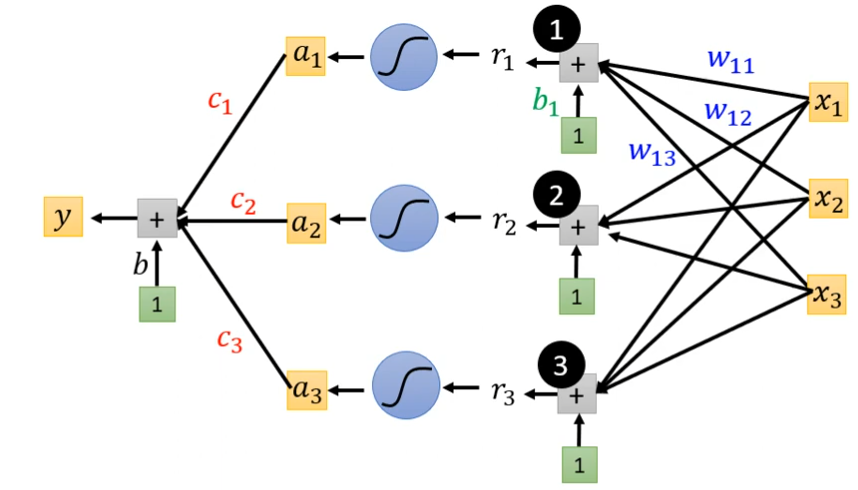
如果上图的式子,看不太懂,可以把这个式子画出来,我们先只考虑前3天的情况,x1,x2,x3都是feature分别对应前几天点赞人数,每一个i就代表了一个蓝色的Function,j是三个feature的情况。我现在需要根据前3天来预测第4天的点赞人数,我们假设需要三个sigmoid函数来计算(4个,5个,甚至更多都可以,越多就会产生越多的线段,越逼近复杂的Function)。wij来代表第i个sigmoid函数里面乘以第j个feature的weight。
个人认为上述式子可以理解:对前3天的数据(暂且比作上面的red curve),进行近似,sigmoid越多,越接近这3天的真实数据,当然越多也就越复杂
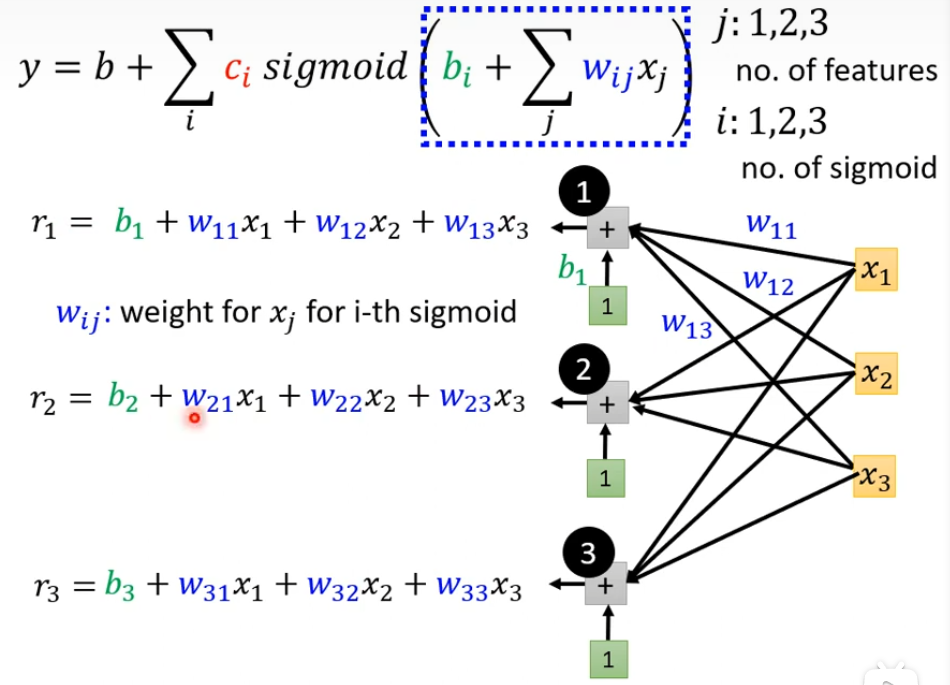
可以把r1,r2,r3简化成矩阵的形式

再简化就是下图那样,r=b+wx是虚线方框里面做的事情
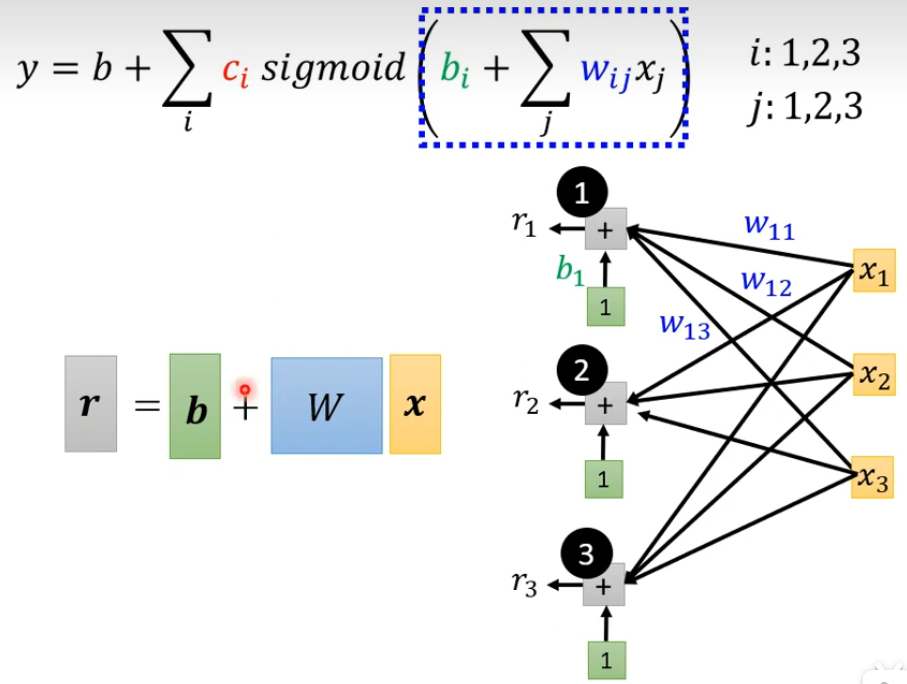
然后r1,r2,r3分别通过Sigmoid Function的方式变成a1,a2,a3,这是下面蓝色虚线方框做的事情,可以简写成a=σ(r)(西格玛)。全连接层可以理解这里的Σ让wijxj和bi连接起来
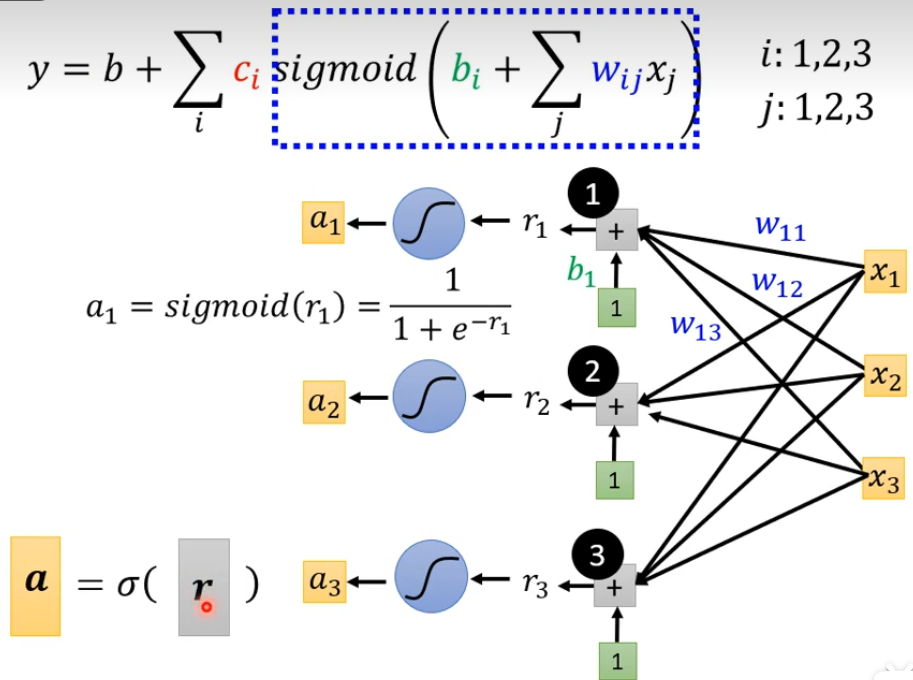
将a1,a2,a3拼起来叫这个向量a,c1,c2,c3拼起来叫一个向量c,并把这个c转置,cT乘上a然后加上b最后得到y
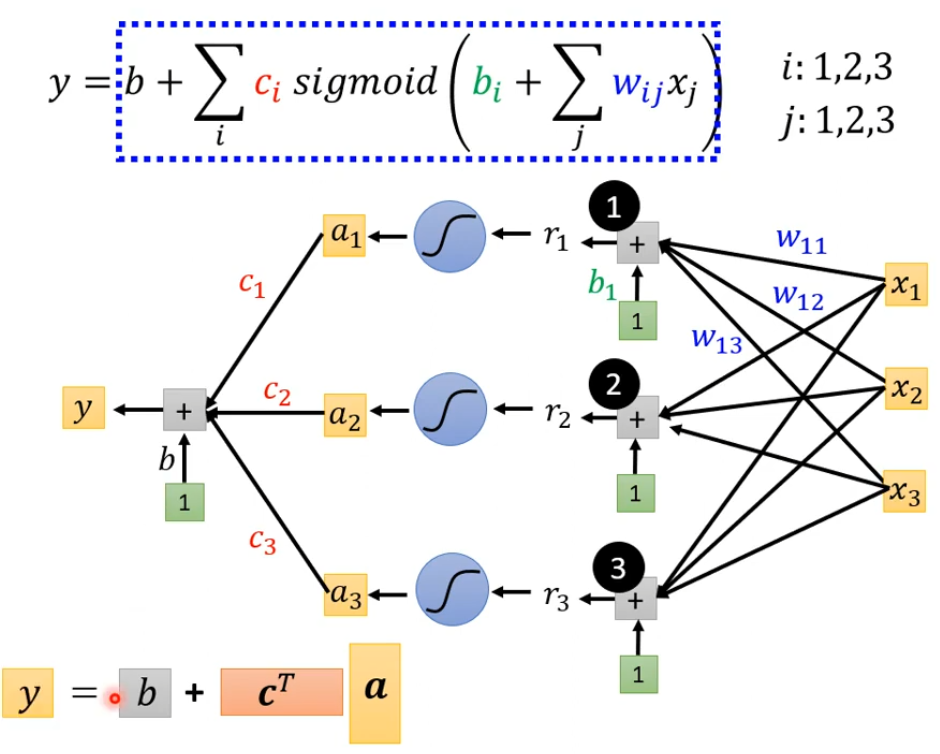
最后简化就是x向量乘上矩阵w加上向量b得到向量r,然后把向量r通过sigmoid function得到向量a
,接着a乘上cT在加上b得到y,如下图所示
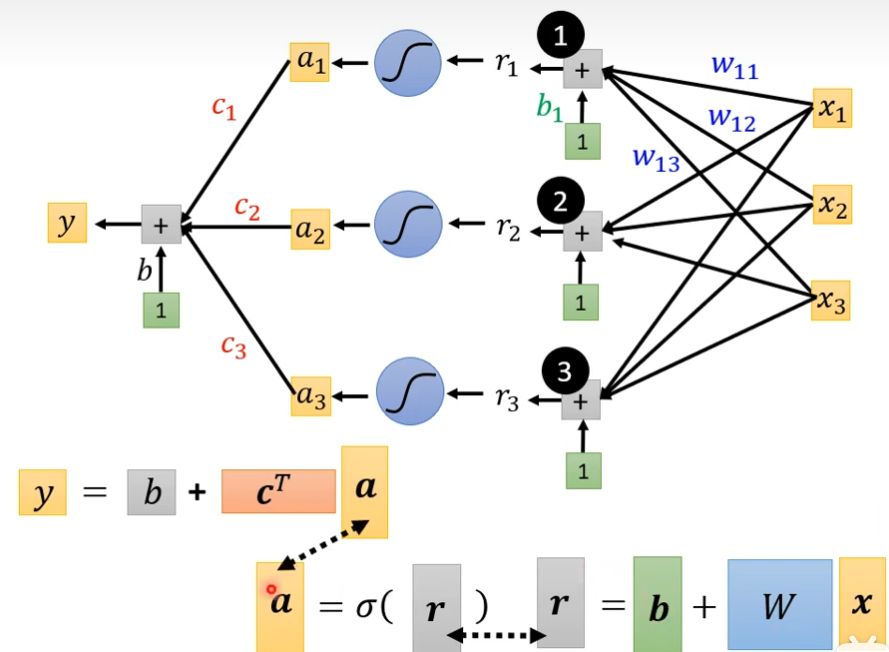
把相同的东西并起来就是下图这样子(线性代数的表示方式)
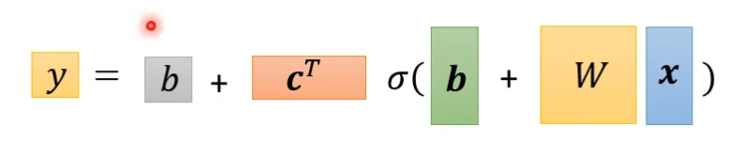
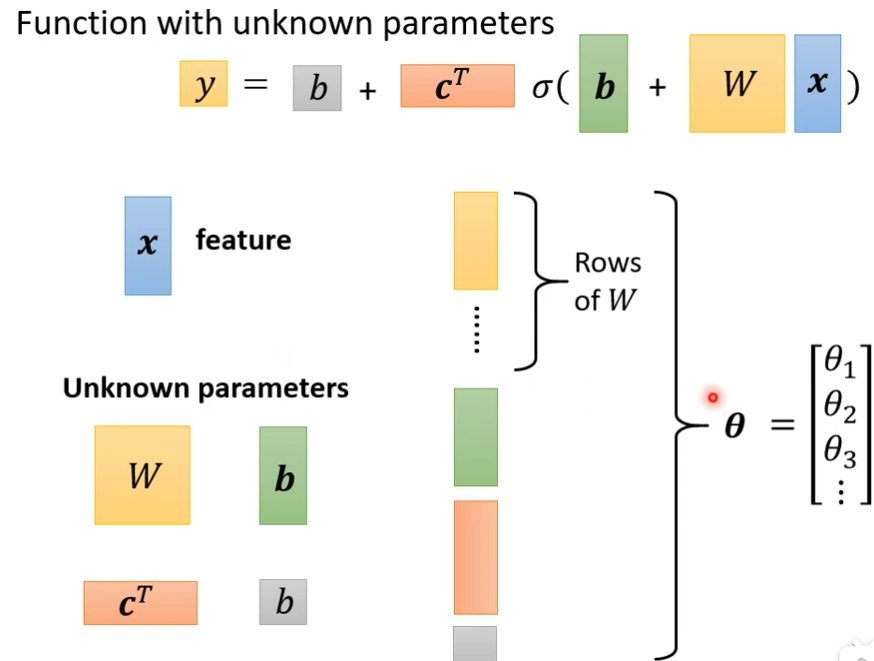
图形化的表示方式:
我们把这些unknown parameter拉直,拼成一个很长的向量,把w的每一行或每一列拿出来拼成一个很长的向量,把b拼上来,c拼上来,b(灰色)拼上来组成一个长的向量叫做θ(西塔),这个θ由θ1,θ2,θ3......组成,θ里面有一些数值是来自w或b或cT等等,反正我们统称θ为所有的未知参数
这样的话,我们就更改机器学习的第一步,重新定义了一个有未知参数的Function
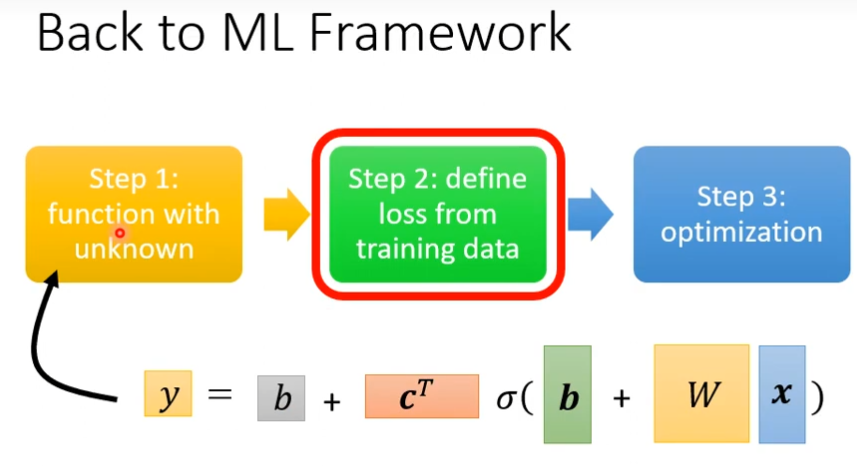
如果未知参数很少,可以暴力搜索找出来,但是多的话就不行
为什么上面sigmoid是有3个?
答:这里是假设sigmoid有3个,可以多点或者少点,sigmoid数量是自己定义的
含有sigmoid的机器学习第二步
我们直接用θ代表所有的未知数,还是那样子,先输入那些未知数看下和真实的label之间的差距
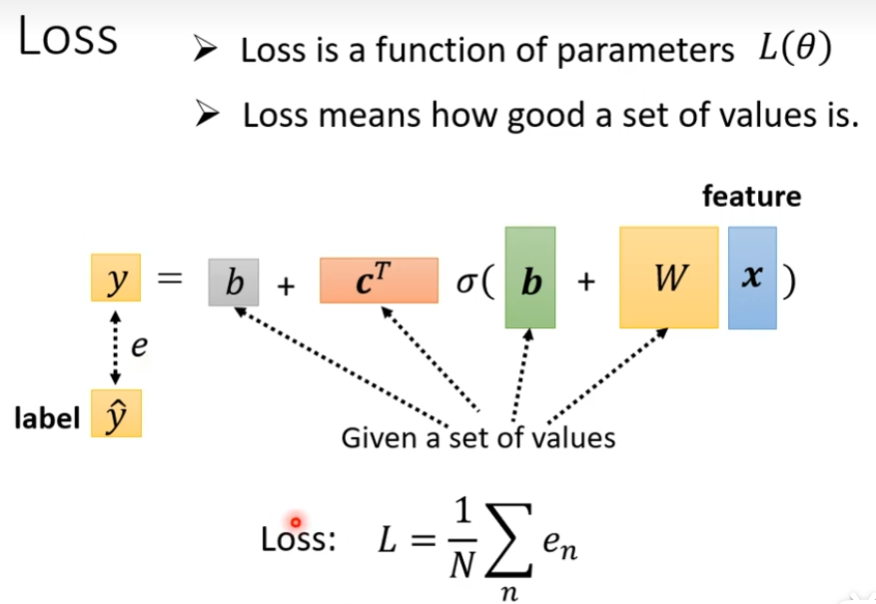
含有sigmoid的机器学习第三步
首先随机挑选一个初试的数值θ0
接下来计算微分,每个未知的参数都要进行计算,然后集合起来就是一个向量,如果θ里面有一个1000个未知数,那么这个向量的长度就是1000。
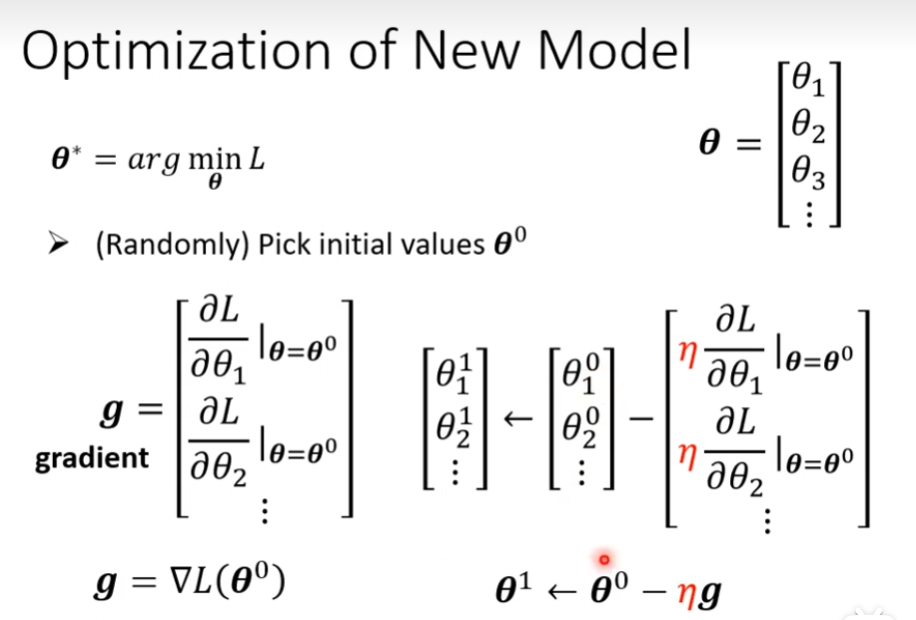
整体流程如下,当这个g为0向量的时候就要停止了

实际上,我们在做Gradient(梯度)的时候,假设我们这边资料为大N,然后把这大N资料随机分成大B组资料,一组叫batch,之前我们是把所有的Data拿出来算一个Loss,我们现在只拿一个batch里面的data来计算一个Loss叫做L1,然后根据这个L1来计算Gradient,然后取第二个batch里面的data来计算一个Loss叫做L2,然后根据这个L2来计算Gradient......
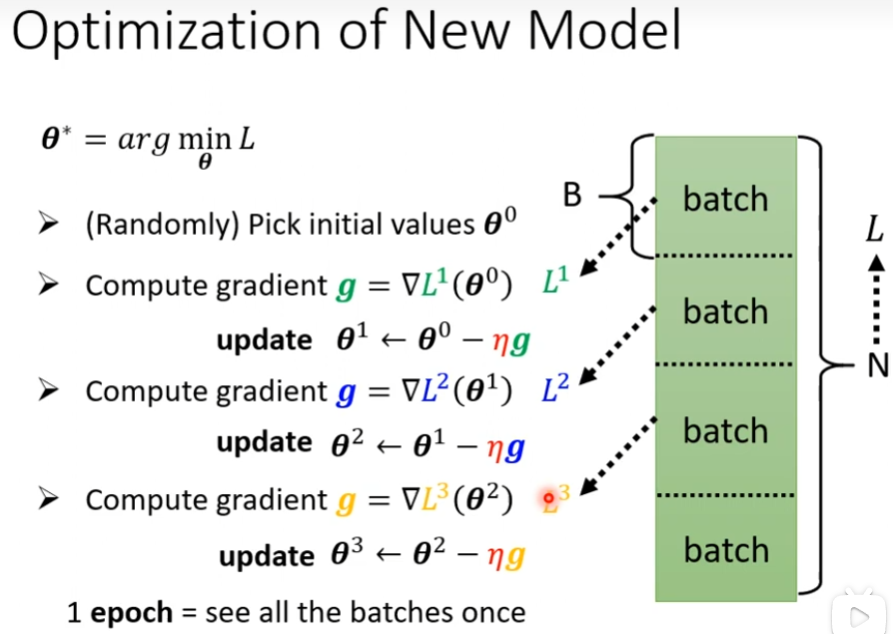
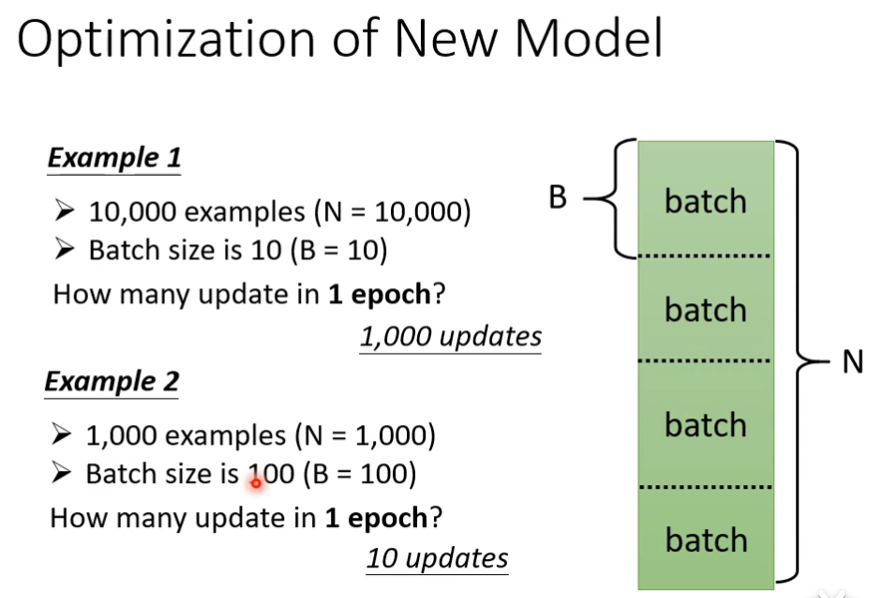
一个epoch并不一定只更新一次,更新多少次取决于batchsize的大小
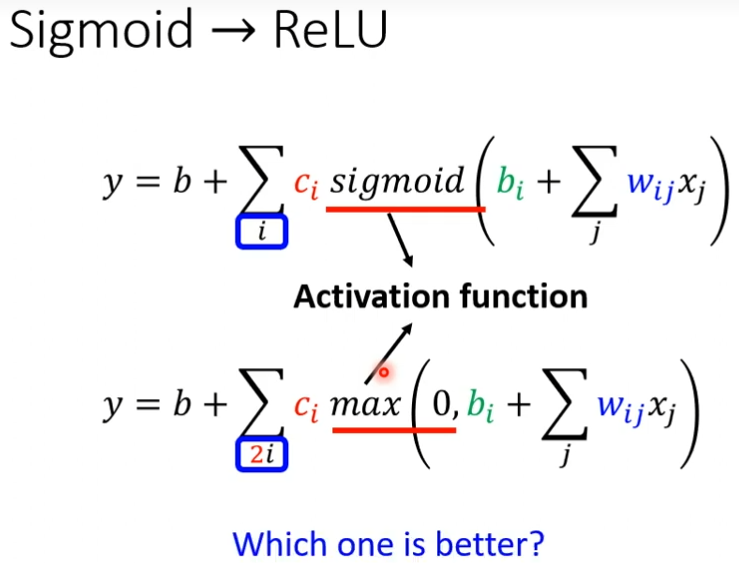
Sigmoid->ReLU
除了sigmoid来近似以外,还有个叫做Rectified Linear Unit,把两个ReLU加起来就变成了Hard Sigmoid
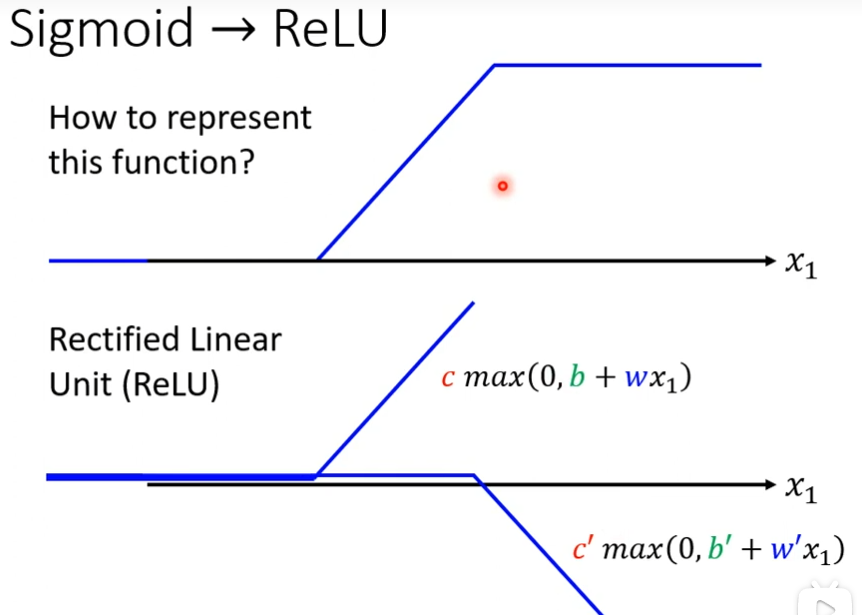
如果我不用Sigmoid,可以用ReLU,Sigmoid和ReLU在机器学习里面,我们叫它Activation Function
我们发现10个ReLU和linear差不多,但是100个ReLU差别就比较大了,我们就可以制造比较复杂的曲线了,把ReLU增加,发现差别不太大

我们可以把已经完成的事,再多做几次
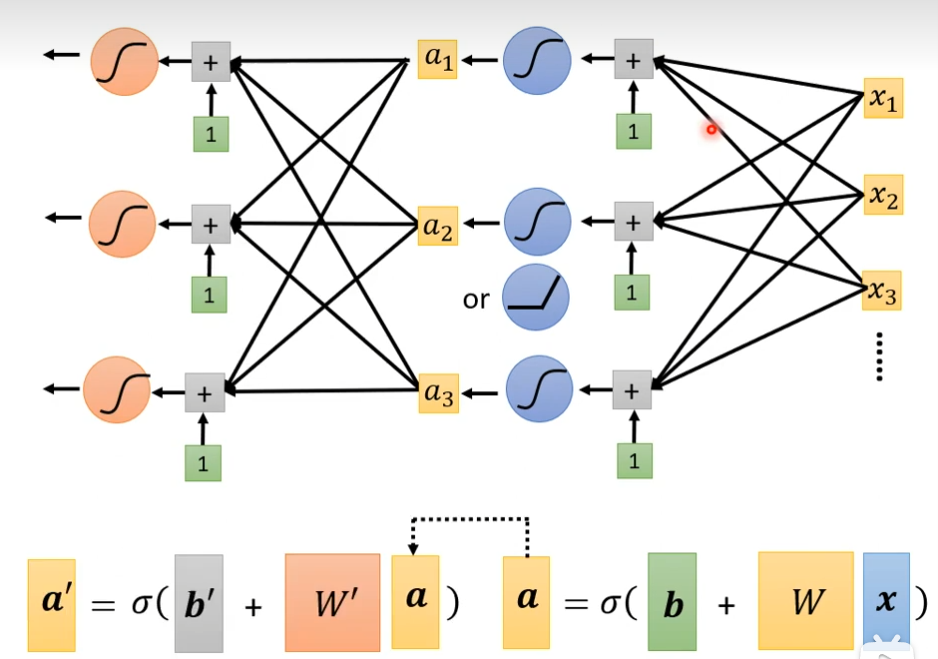
我们把100ReLU按照上图多做几次结果如下:
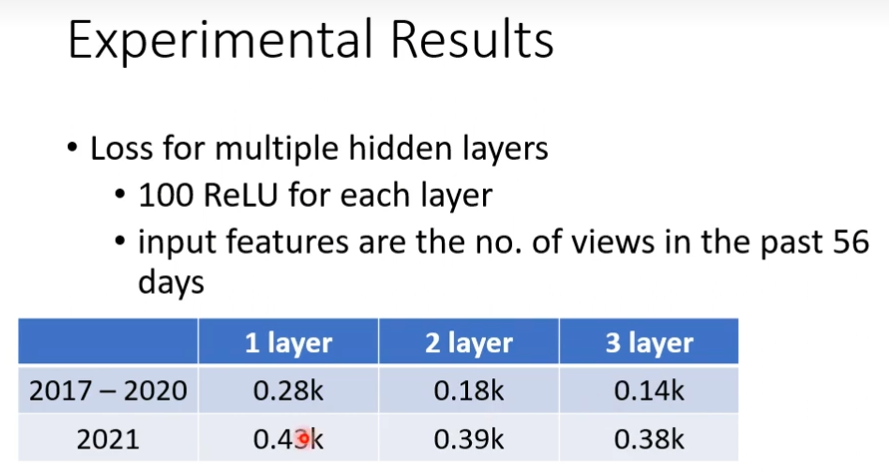
可以发现机器对低的结果预测比较准
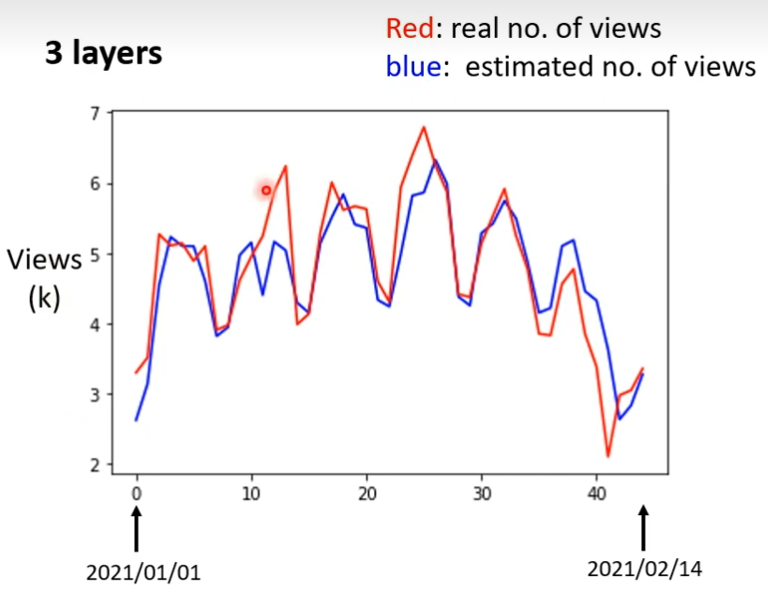
这些Sigmoid,ReLU,它们叫做Neuron,很多的Neuron叫做Neuron Network。每一排Neuron叫做叫Hidden Layer,有很多Hidden Layer就叫做Deep,这套技术就叫做Deep Learning。
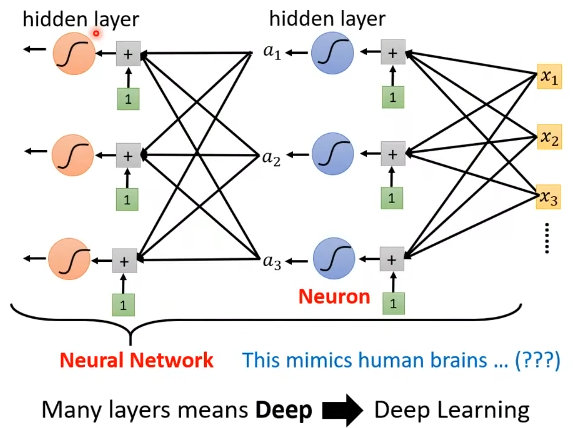
Hidden Layer并不是越多越好
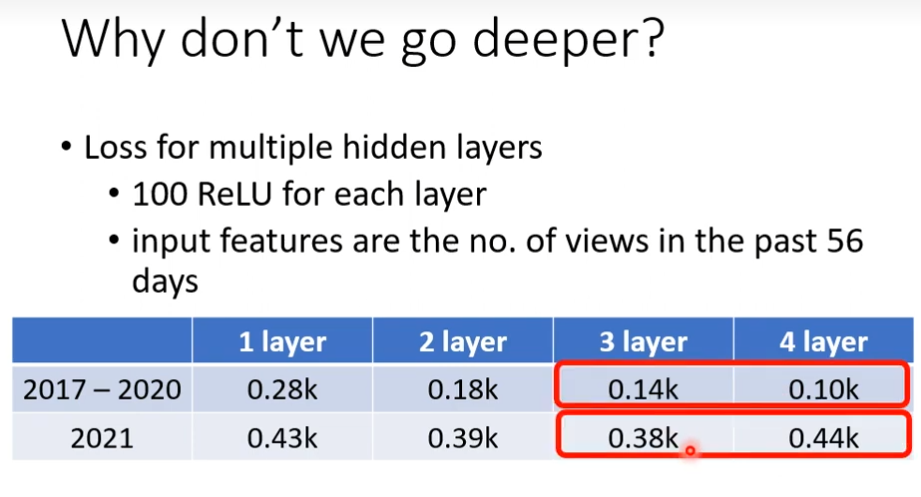
深度学习简介(选修)
深度学习的三个步骤
第一步 Neural Network

define a set of function其实就是定义Neural Network,我们把这个Logistic Regression,就是下图
把它们前后连接在一起,把一个Logistic Regression称之为Neuror,整个的称之为Neural Network,不同的连接方式会造就不同的机构。每一个Logistic Regression都有自己的weight跟自己的bias,这些weight和bias集合起来就是network的parameter,我们用θ(西塔)来表示。
连接neural的方式
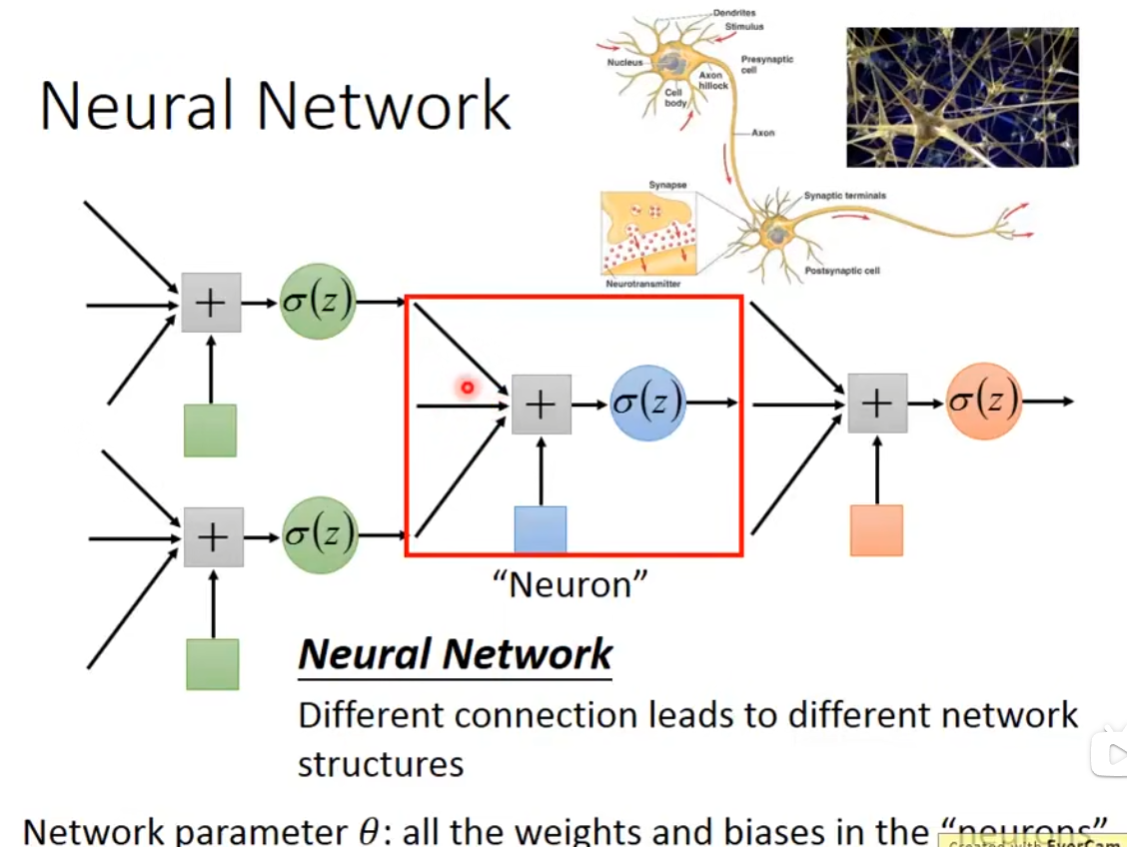
- Fully Connect FeedforwardNetwork(最常用的)
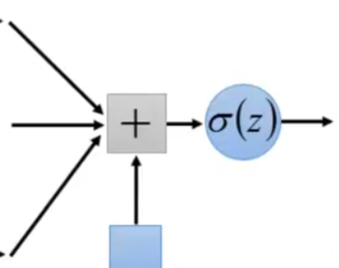
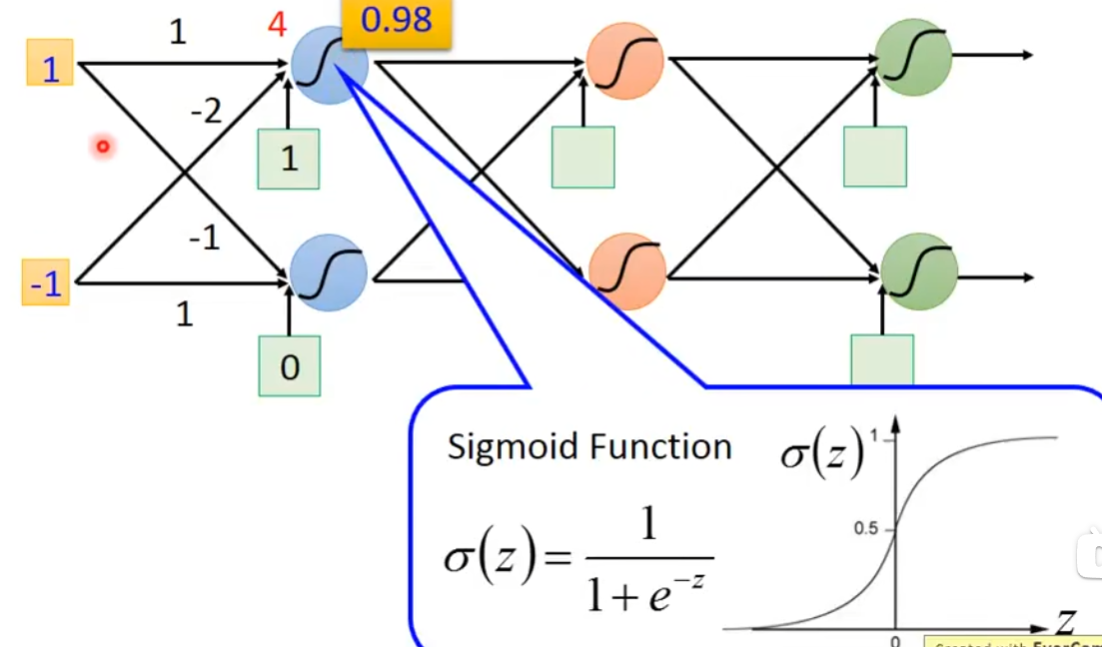
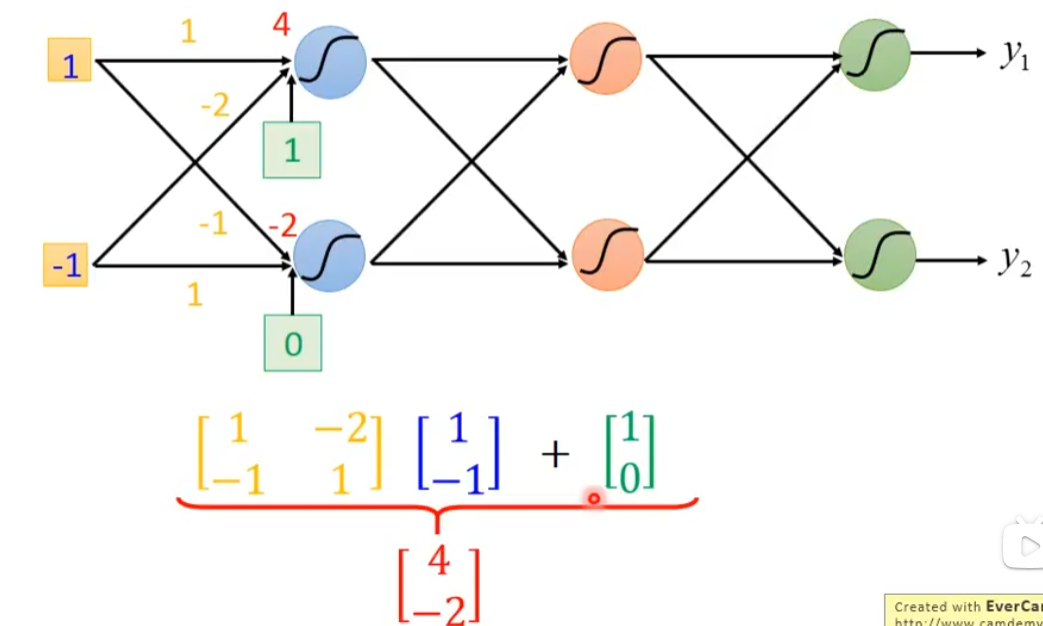
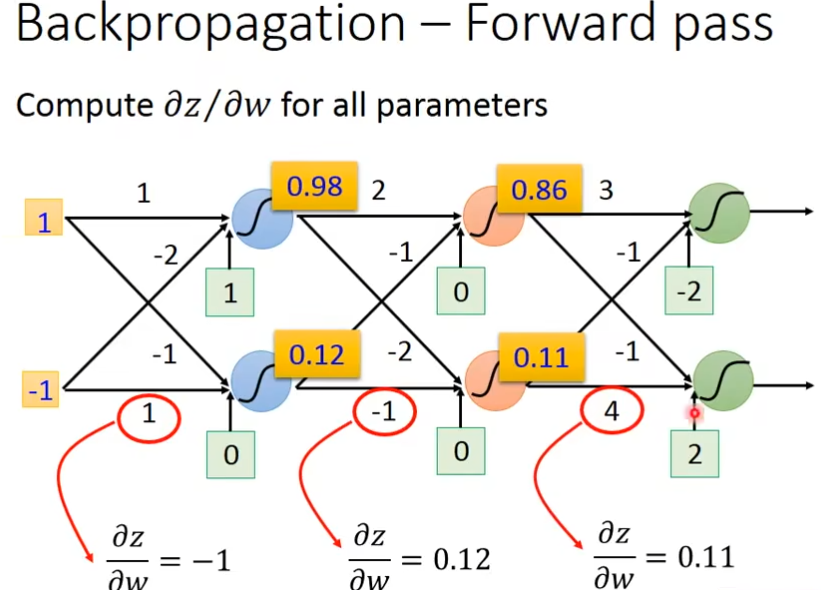
把neural排成一排一排的,每个neural都有weight和bias,第一个上面蓝色neural的weight是1和-2,输出是3(1×1+(-1)×(-2)=3),bias是1(自己定的),这个3再加上bias也就是1,通过sigmoid就得到了0.98
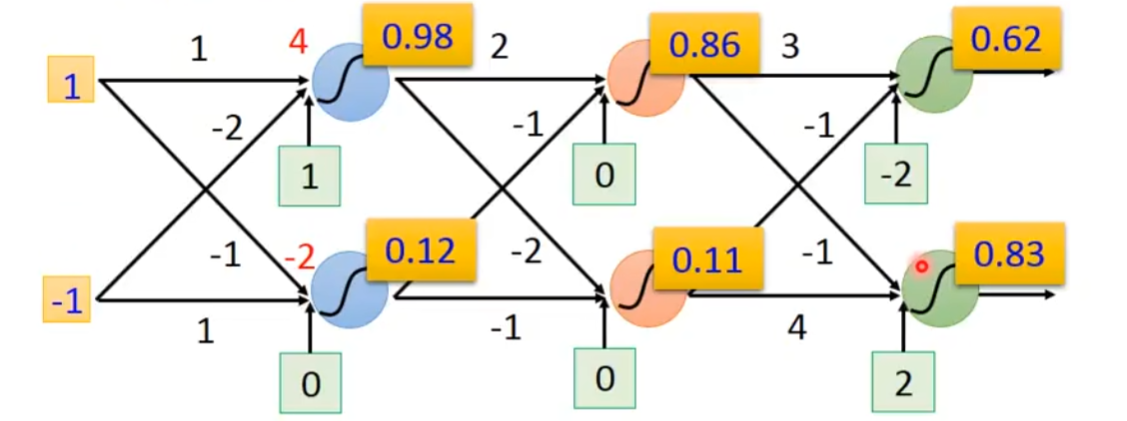
然后,0.98×2-0.12 = 1.84再加上bias也就是0,这个1.84通过上面那个公式得到0.86。
接着0.86×3-0.11-2=0.47,通过sigmoid就是0.62
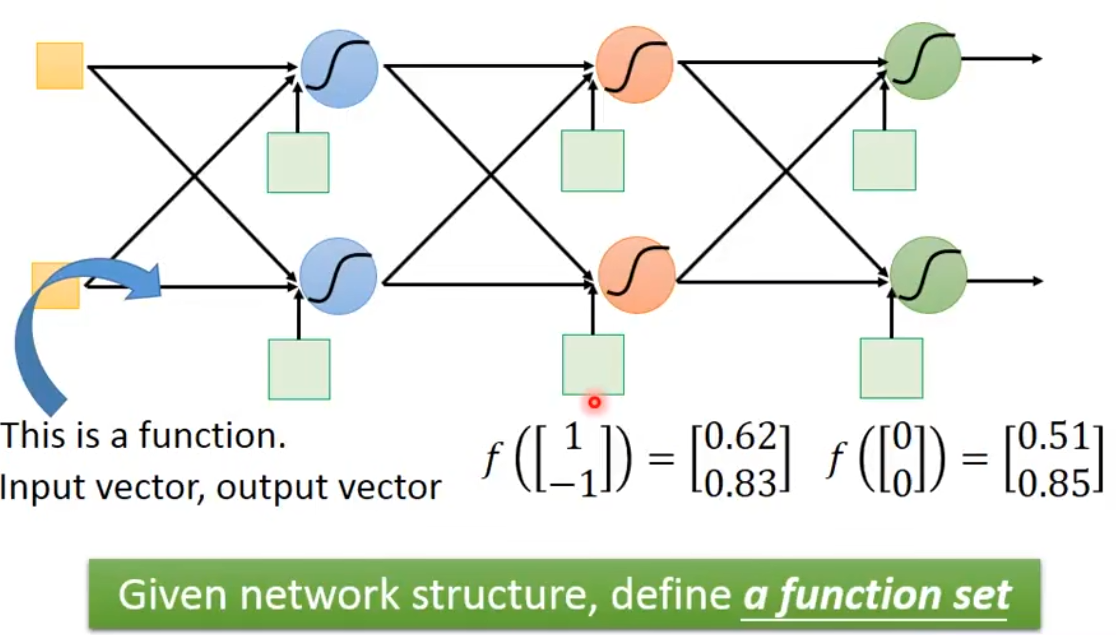
neural可以理解为一个function,一个network,如果我们已经把参数设上去的话,它就是一个function,如果我们还不知道参数,只是定出了这个network的structure(就是这些neural之间怎么连接),就相当于定义了一个function set(函数集合),可以给这个network设定不同的参数,它就变成不同的function,把这些可能的function通通集合起来,就得到了一个function set。所以一个neural network,你还没有确认参数,只是把它架起来,你决定这些neural要怎么连接,当你把连接的图画出来的时候,其实就决定了一个function set
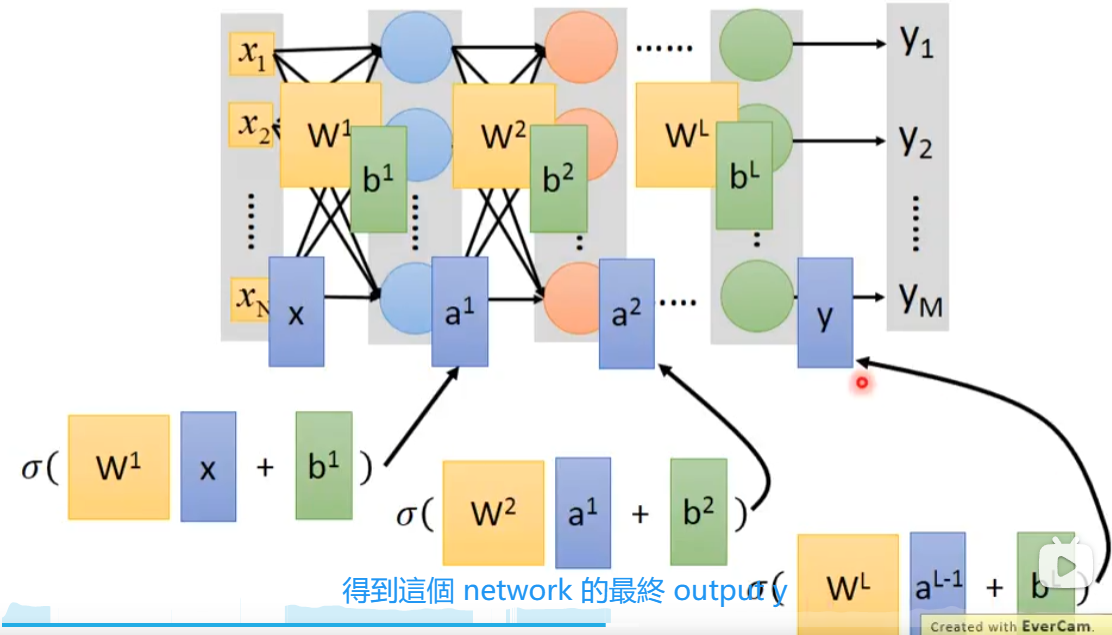
Matrix Operation
计算结果经过sigmoid得到
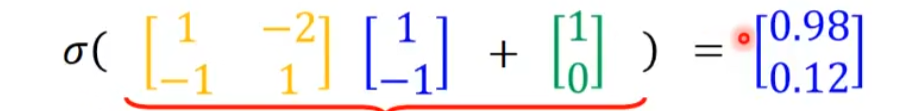
我们把输入(x1,x2...xn)当做一个矩阵,第一个weight当做一个矩阵w1,第一个bias当做一个矩阵b1,为什么是什么w1乘x呢,可以参考上图,把w1x+b1经过sigmoid后得到a1,将a1作为下一层的输入。
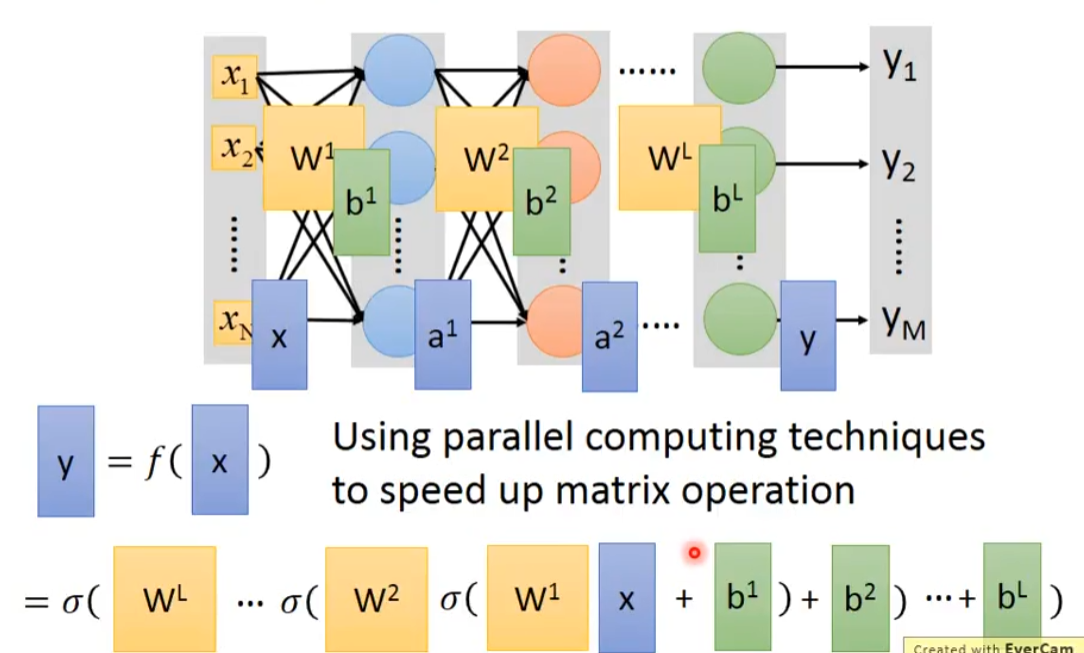
把过程简化一下就是y=f(x),弄成矩阵的话,方便进行GPU进行运算,这里的σ是激活函数
第二步 goodness of function
怎样决定一组参数的好坏呢?
答:假设我要做手写识别,我有一张image,跟它的label,这是一个多类别分类问题,这个label 1,告诉我们现在的target是一个vector向量(10维的),然后将这个数字1的输入到neural network中,接着你会得到一个output,这个output我们称之为y,将target称之为ŷ,接下来就是计算y和ŷ之间的交叉熵,接下来需要调整network的参数,使得cross entropy越来越小
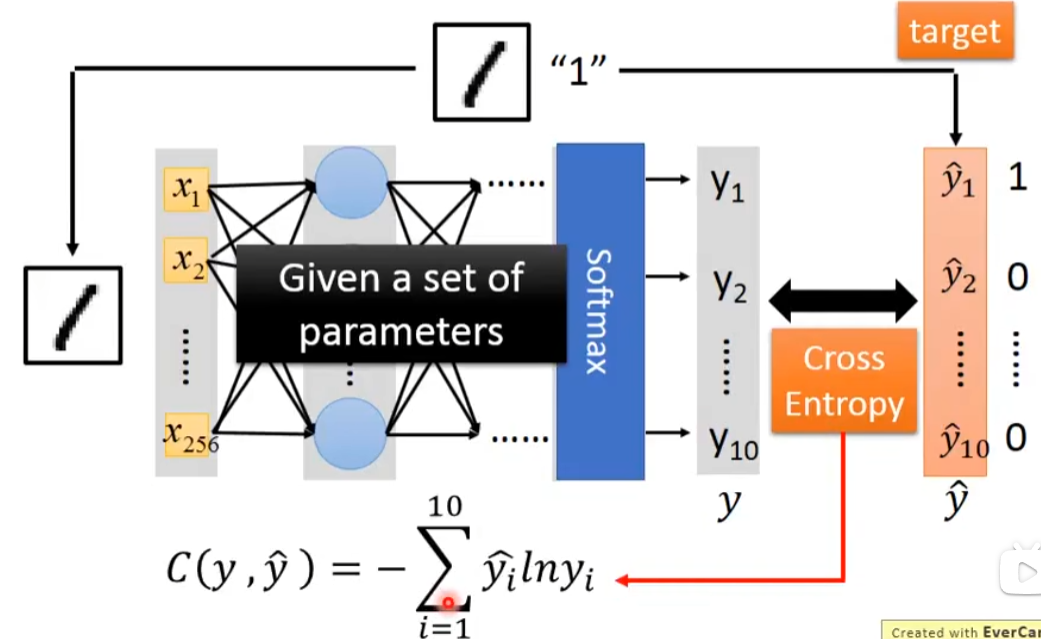
第三步 pick the best function
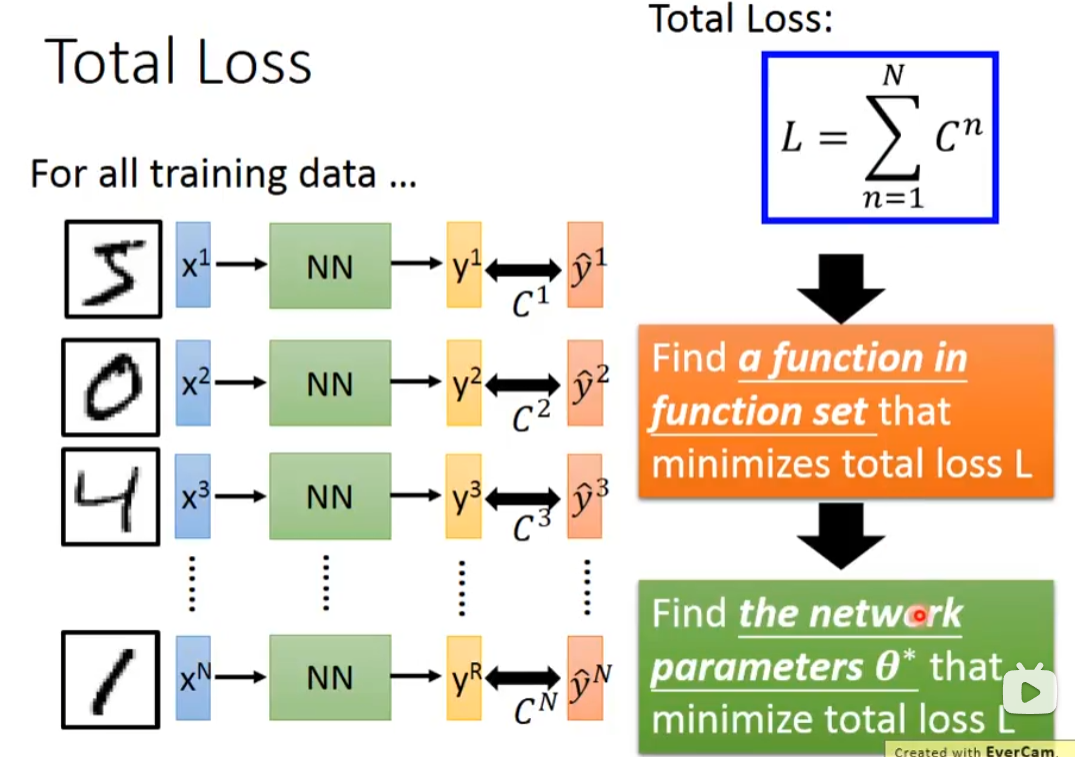
我们把所有手写的数字输入进去,计算总的Loss,尽量使得Loss值变小,一种是找一个function,一种是找参数(用gradient descent)
反向传播(backpropagation 选修)
根据网络输出的答案与正确答案之间的误差,不断调整网络的参数,容易导致过拟合,测试数据上很好,但是不认识新数据,这时可以采用提前停止策略,将数据按一定比例划分为训练集和验证集,用训练集调整参数,用验证集估算误差,如果训练集误差降低的同时,验证集的误差在升高,代表网络开始过于适应训练集,这时可以结束训练
gradient descent的计算方法
首先取任意值,算微分,然后更新,一直算下去

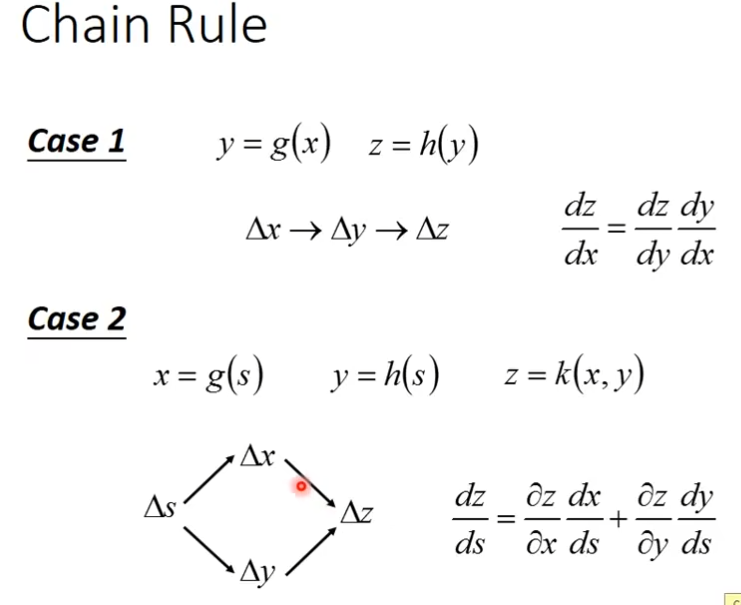
Chain Rule(链式法则)
Forward pass和Backward pass
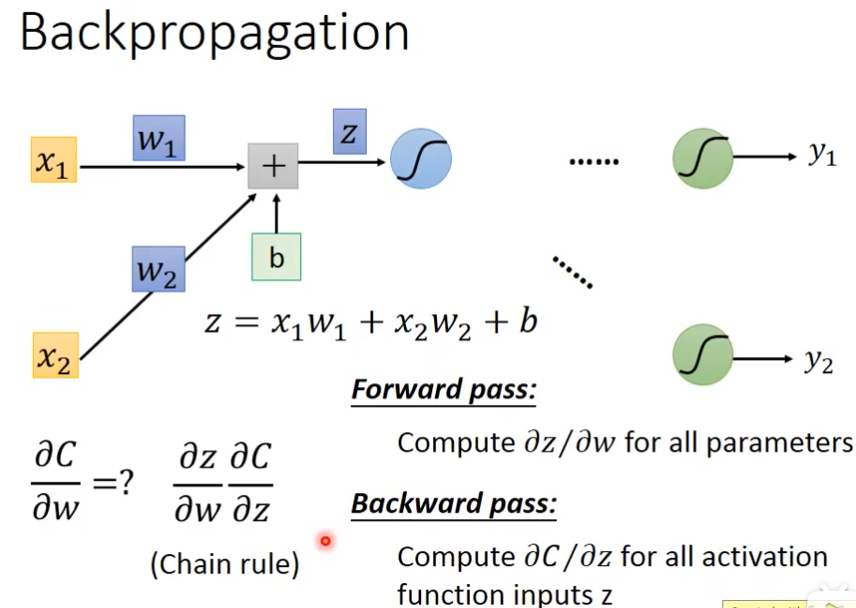
为所有parameters计算∂z/∂w,就是w的input是什么,它就是什么,比如∂z/∂w1就是x1,∂z/∂w2就是x2
计算∂C/∂z,这里的C是Loss也就是y-ŷ
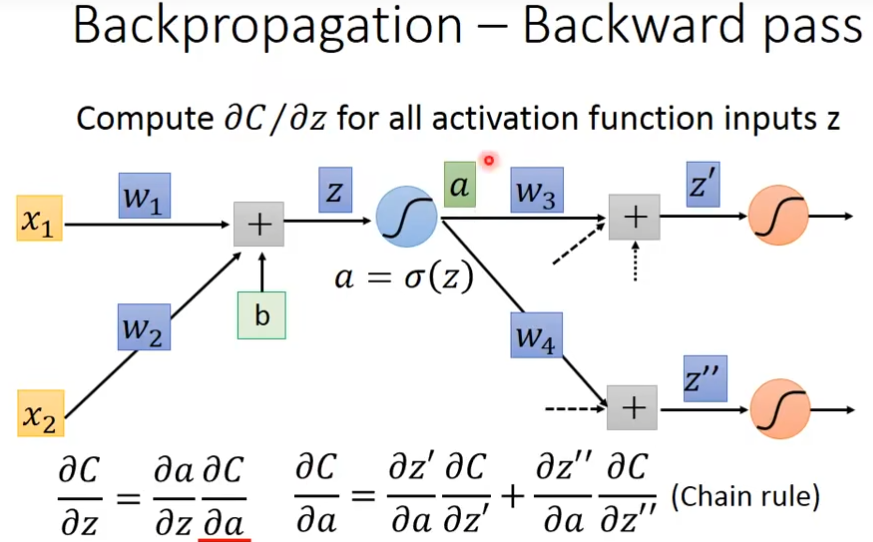
这里的∂z'/∂a就是前面的w
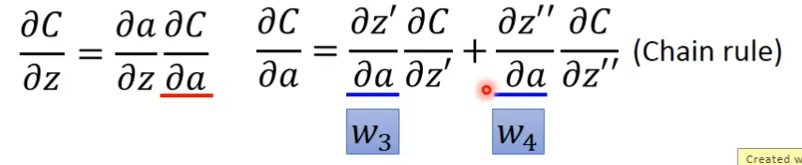
这里我们假设知道∂C/∂z'和∂C/∂z'',那么∂C/∂z就等于,关系就相当于这样( C = C[ z'{ a( z ) } ] )
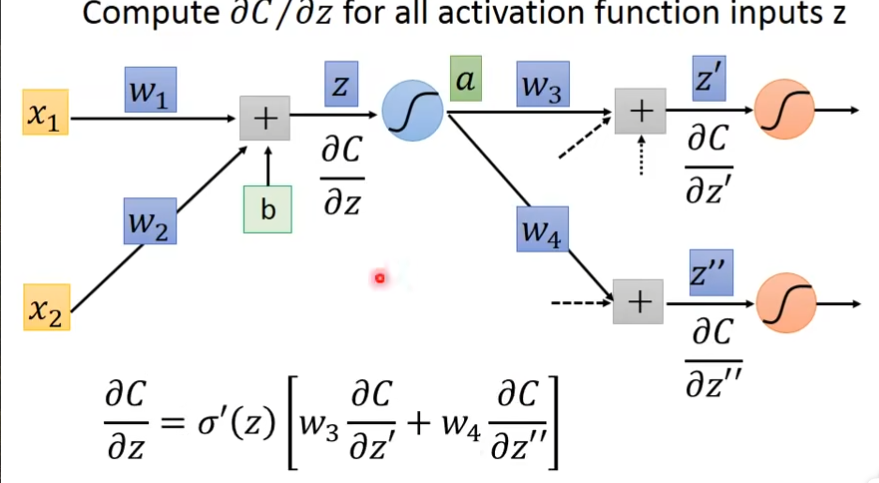
怎样计算∂C/∂z'和∂C/∂z''呢?
- 第一种把最后一层当做output layer,关系就是C = C( y1[ z'{ a(z) } ] )
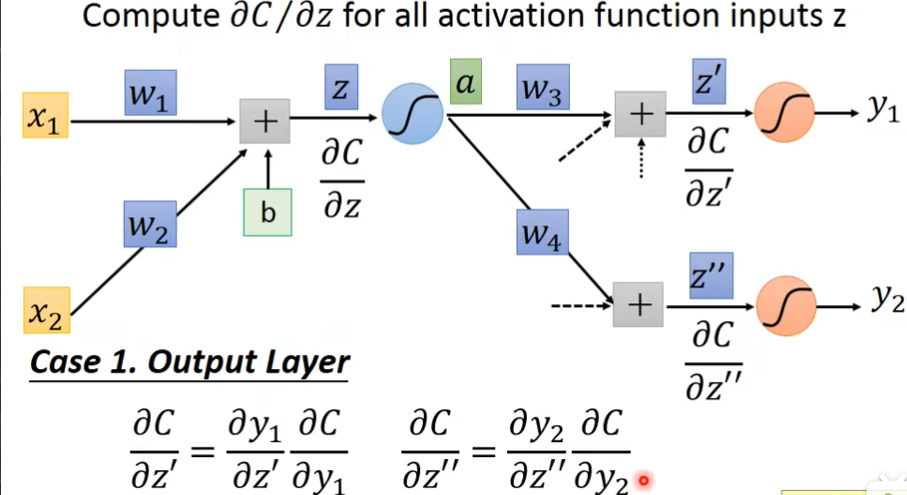
- 第二种就是最后一层不是输出层
总结
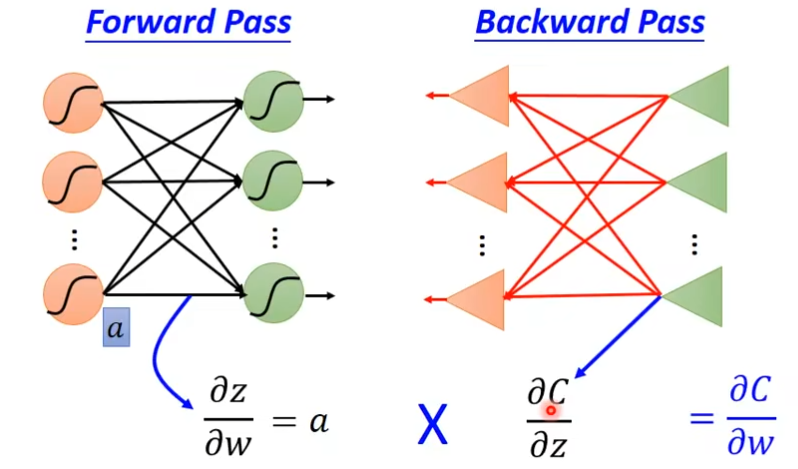
首先先做一个forward pass,只要你知道每一个activation function的output,那么这个activation function的output就是它所连接的weight的∂z/∂w。
其次,做一个backward pass把原来的neural network的方向倒过来,那在这个倒过来的neural network,它的每一个三角形的output就是∂C/∂z。
然后乘起来,就知道某一个weight 对w的偏微分是什么了
预测宝可梦(选修)
第一步 model

第二步 goodness of function
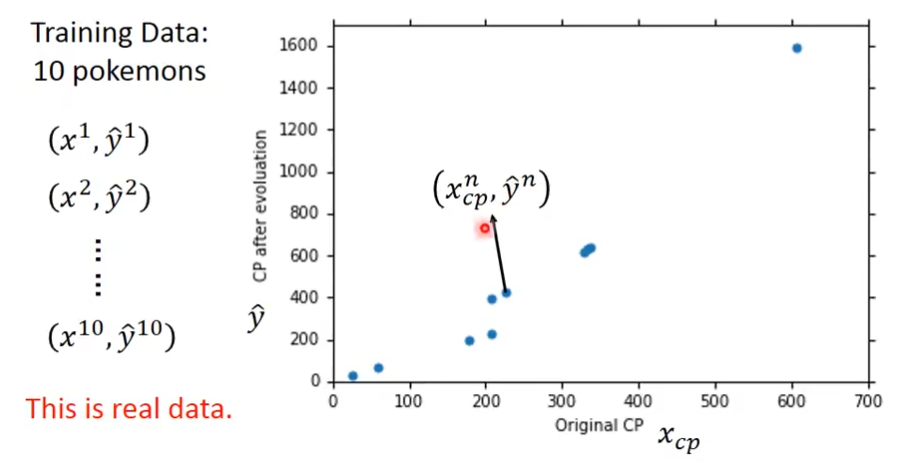
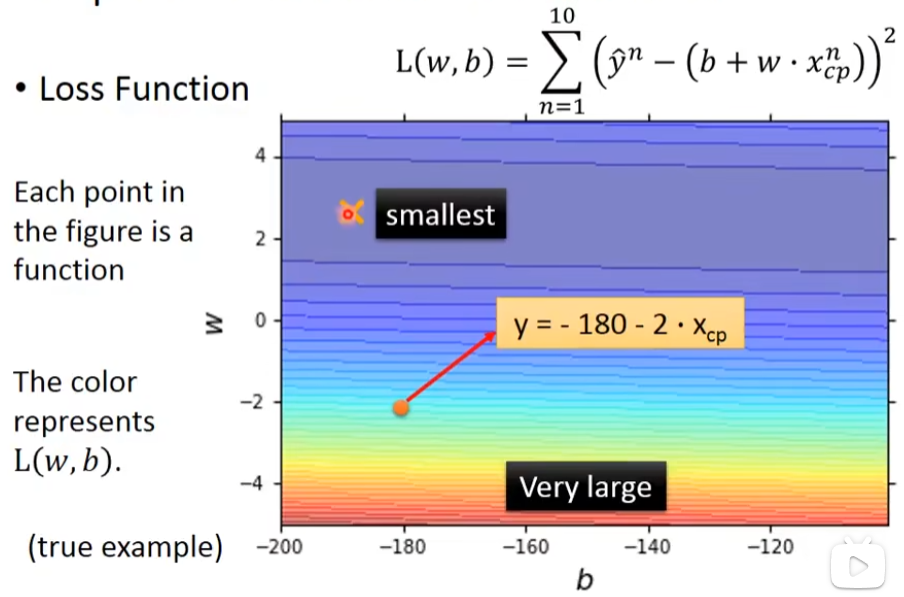
横轴是xcp(初始cp值),纵轴是ŷ(升级后的cp值)
我们还要定义一个Loss function,用来判断这个function有多不好,然后把这些误差加起来

可以把Loss function画出来,越偏红越差,越偏蓝越好
第三步 Best Function
就是一个可以让loss function最小的函数
使用Gradient Descent来帮忙挑选最小的函数,计算方法上面有
▽L就是把L对w的偏微分和L对b的偏微分排成一个向量
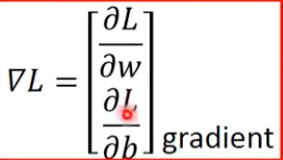
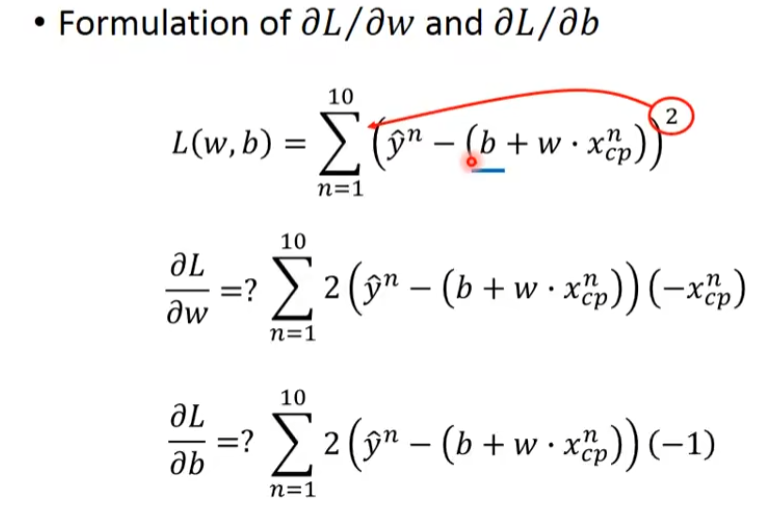
模型不是越少越好,不同的物种,其预测结果也不同,要用不同的function
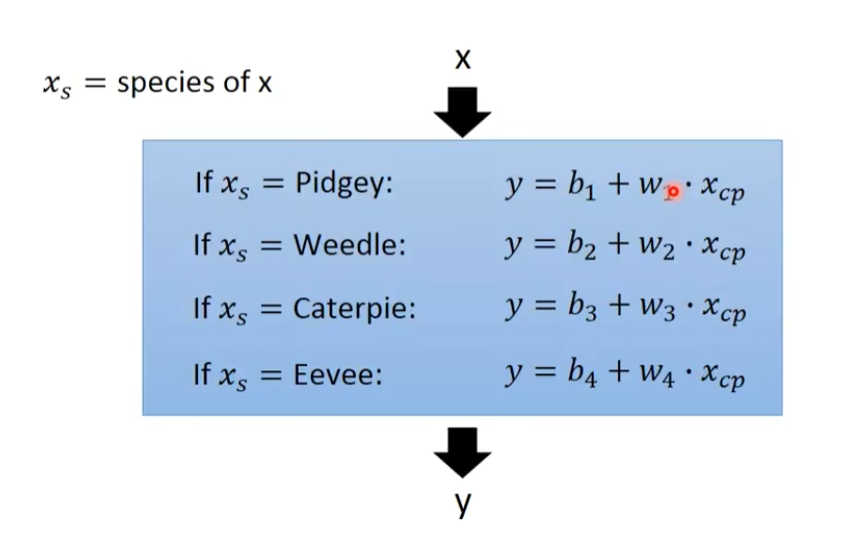
含有if的function

如果不是这个物种,值就会为0

加上这个λ更平滑,regularization就是增加一个额外的term就是下图的红色框框,在做regularization的时候,不需要考虑bias的,bias只是将图像上移或下移,不影响函数的平滑。正则化,可以缓解过拟合

分类神奇宝贝(选修)
一个宝可梦有7个属性,用一个向量保存这些属性,

从C1中抽到x的几率是P(x|C1),从从C2中抽到x的几率是P(x|C2),那当我给定x时,它属于C1的几率是下图

计算x的几率,叫generative model,公式如下
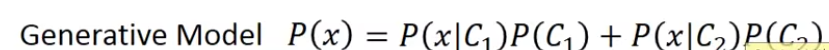
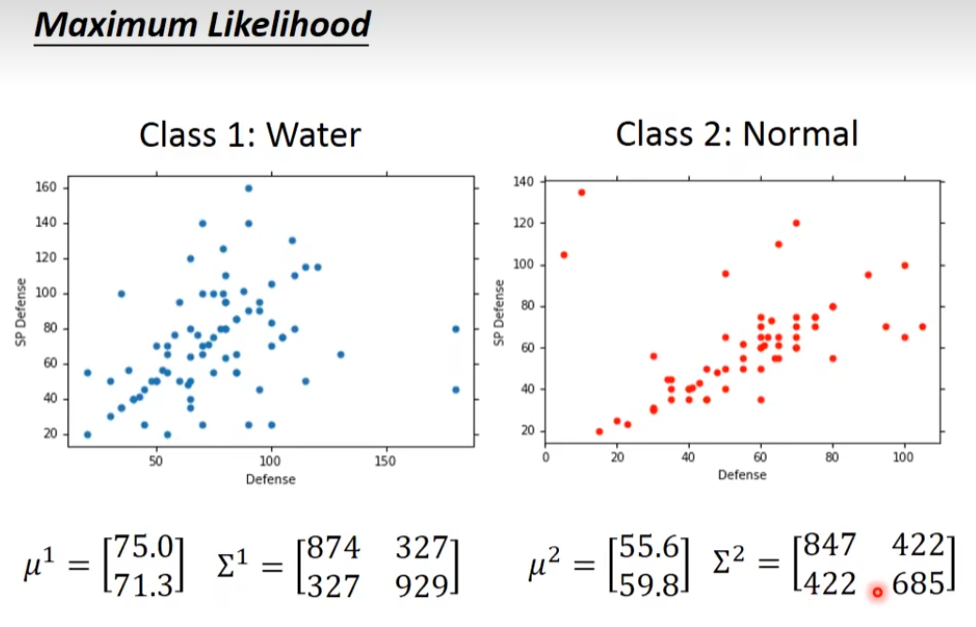
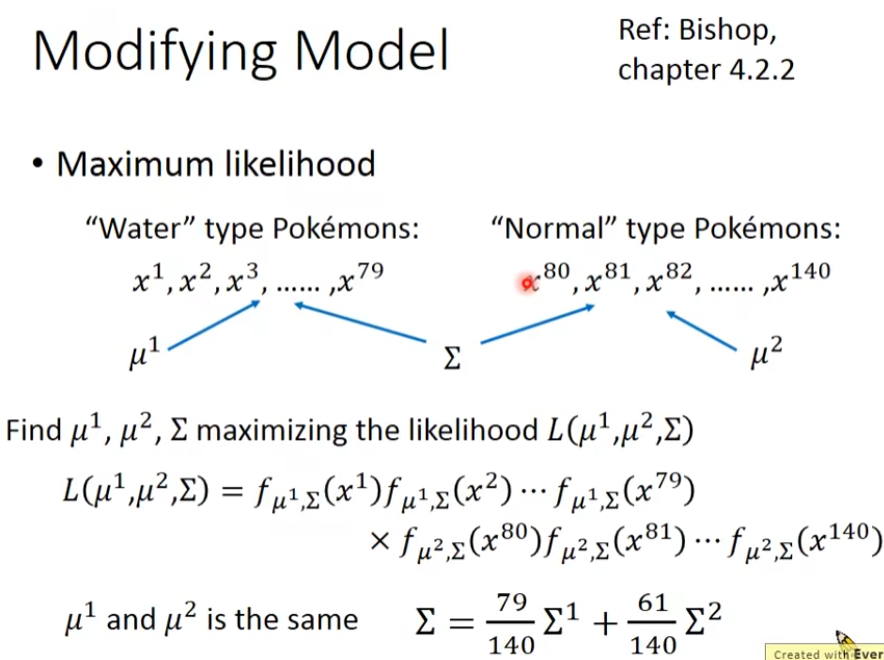
假设有两个类别一个是water系 class 1,一个是normal系 class 2,把water和normal系的id小于400当做训练数据,其余的当做测试数据。测试数据中有79个water系,61个normal系的,water系的概率为P(C1)=79 / (79 + 61) = 0.56,water系的概率为P(C2)=61 / (79 + 61) = 0.44。那么从water系里面,挑一只出来是海龟的几率有多大呢?每一个宝可梦都一个向量来描述,这个向量里面的值,就是它的各种的特征值,所以,这个vector,我们称之为一个feature

我们把water系的宝可梦,它们的防御力和特殊防御力画出来,每一个点代表一个宝可梦
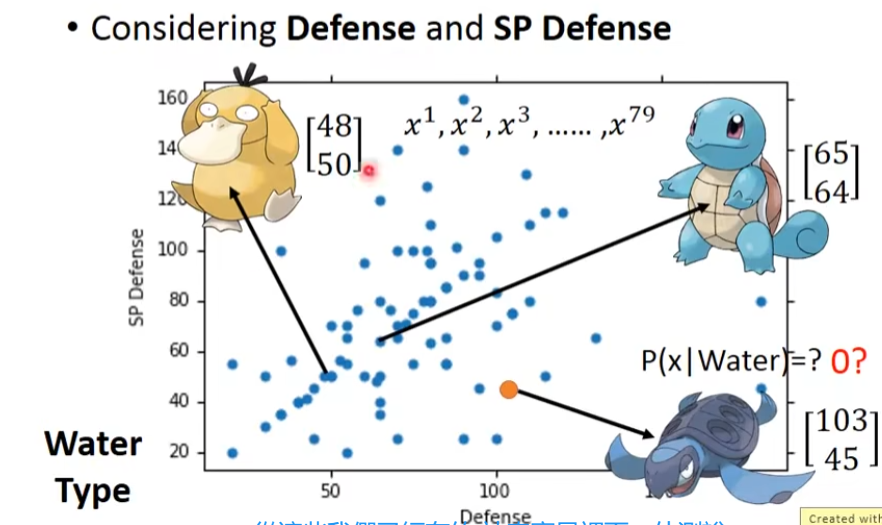
我们假设说,这79个点,是从一个gaussian的distribution里面sample出来的,

高斯分布,输入是一个向量,代表某一个宝可梦的数值,它的输出就是这一个宝可梦从这一个distribution里面,被sample出来的概率,这个概率的分布由两个东西决定,一个是μ(mean 均值),一个是Σ(covariance matrix 协方差矩阵),μ是向量,Σ是矩阵。
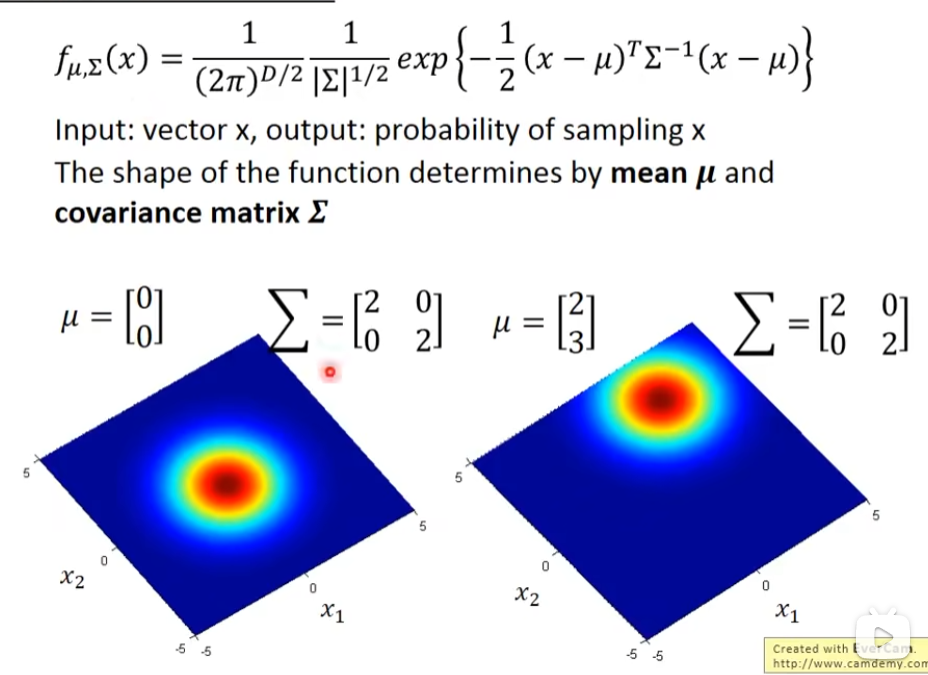
我们假设有一个guassian存在,然后sample出这79个点,那,到底这个gaussian长什么样?假设我们可以根据这个79个点,估测这个gaussian的μ的位置是[75.0,71.3]和Σ的分布,可以理解为由样本生成高斯分布,再用海龟的数据去找到在高斯分布的位置。我们知道μ和Σ后,把公式写出来,这时有一个新的点x,把这个x带入进去,就知道x被sample的概率了。x越接近中心点,被sample出来的概率越大,否则就越小。
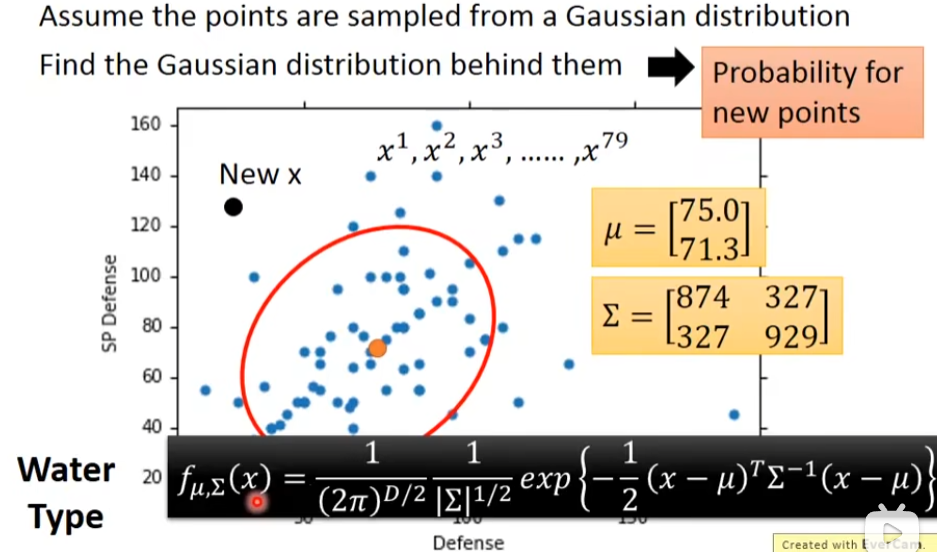
那么怎么去找μ和Σ了?这里需要用的是maximum likelihood(极大似然估计),任何一个guassian都有可能sample出这79个点,不管μ在什么位置,只有有些地方概率高,有些低,但是没有一个等于0。
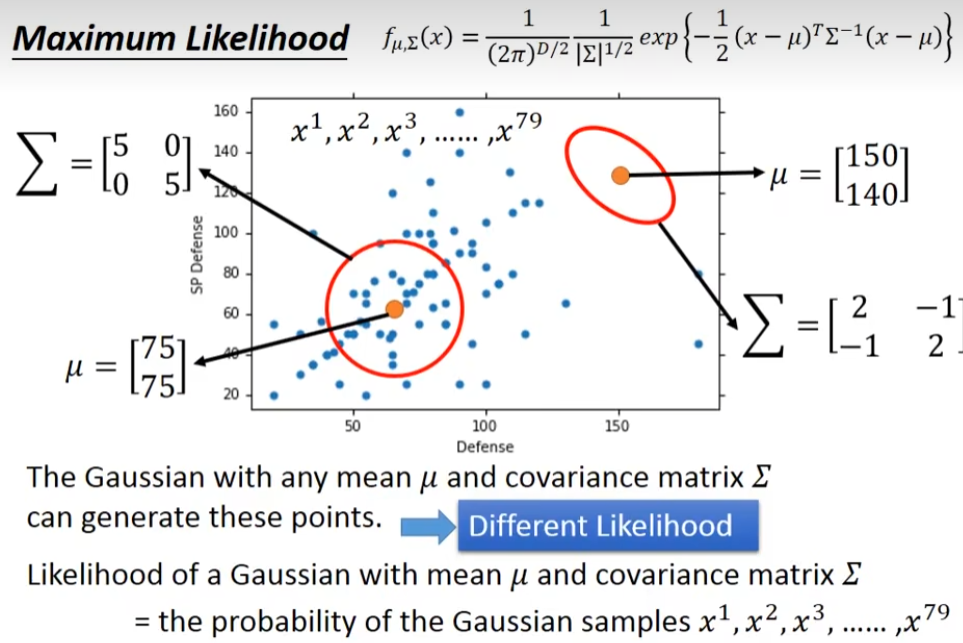
给我们一个gaussian的μ和Σ,我们就可以这个gaussian,sample出这79个点的概率,这个概率我们写成这个样子,第一个点的概率×第二个点的概率×.....第79个点的概率
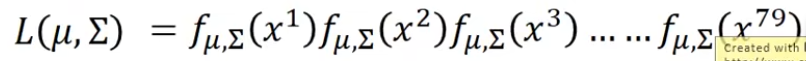
接下来就是找一个gaussian,它sample出这79个概率最大,这个由μ和Σ决定,概率最大的μ和Σ我们称之为μ*和Σ*,平均值可以让μ*最大,

我们算water系和normal系的
接下来我们开始分类

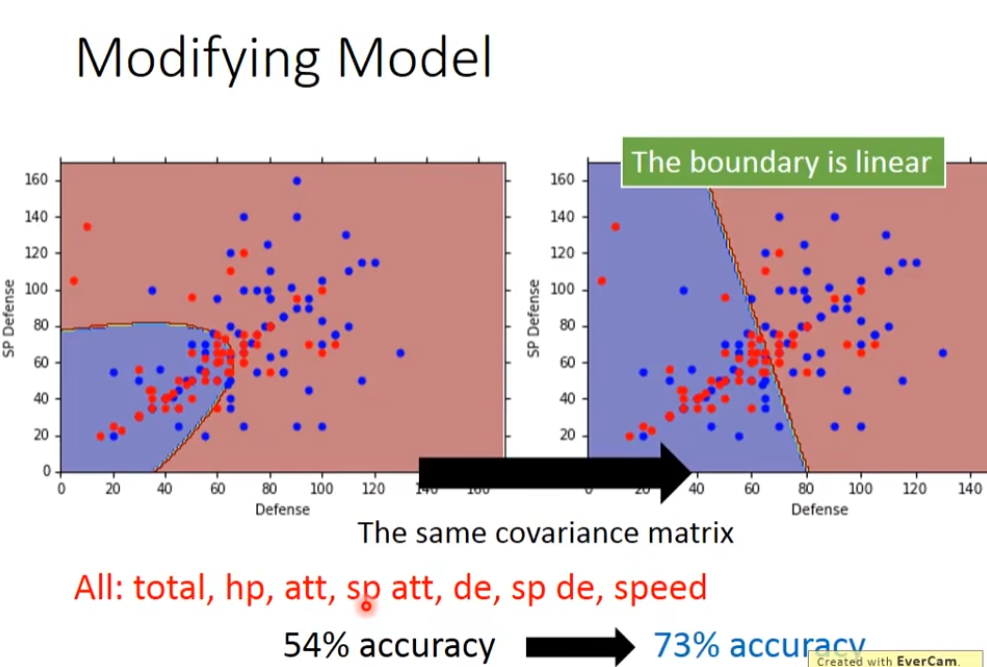
每个class的gaussian都有μ和Σ,比较常见的做法是,不同的class拥有相同的Σ,如果把两个不同class的gaussian都给不同的Σ,那么model的参数可能就太多了,model参数多,方差就大,也就是容易过拟合,所以,如果我们要有效减少参数的话,我们可以给这两个class的feature分布的gaussian故意给他们同样的Σ,这样就需要比较少的parameter
共用Σ,考虑7个向量的正确率明显上升
步骤

这里并不是非要用gaussian,你可以用你自己喜欢的,下图就是朴素贝叶斯

Posterior probability(后验概率)

贝叶斯,sigmoid ,等数学公式


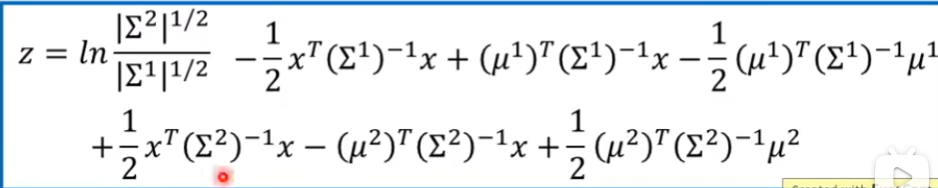 如果Σ1和 Σ2相等的话,下面第一项就是ln1 也就是0
如果Σ1和 Σ2相等的话,下面第一项就是ln1 也就是0

Logistic Regression(逻辑回归)
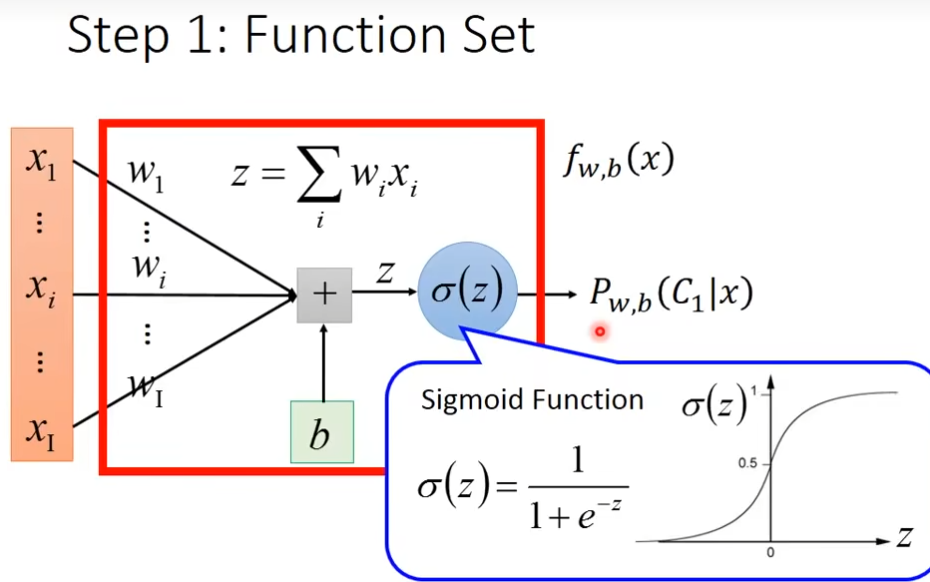
第一步 function set

用图像化的方式来描述的话,有两组参数,w和b
第二步 goodness of a function
现在有一批training data,你需要说明它属于哪一个class,给我们一个w和b,决定了posterior probability,产生N个training data 的概率,那么产生的xi属于C1的概率是多少了?

下图-lnL(w,b)左右两边都相等

把ŷ带入
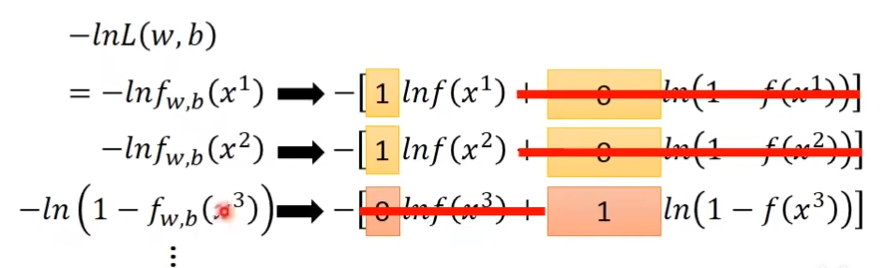
左右两边取负的

第三步 find the best function
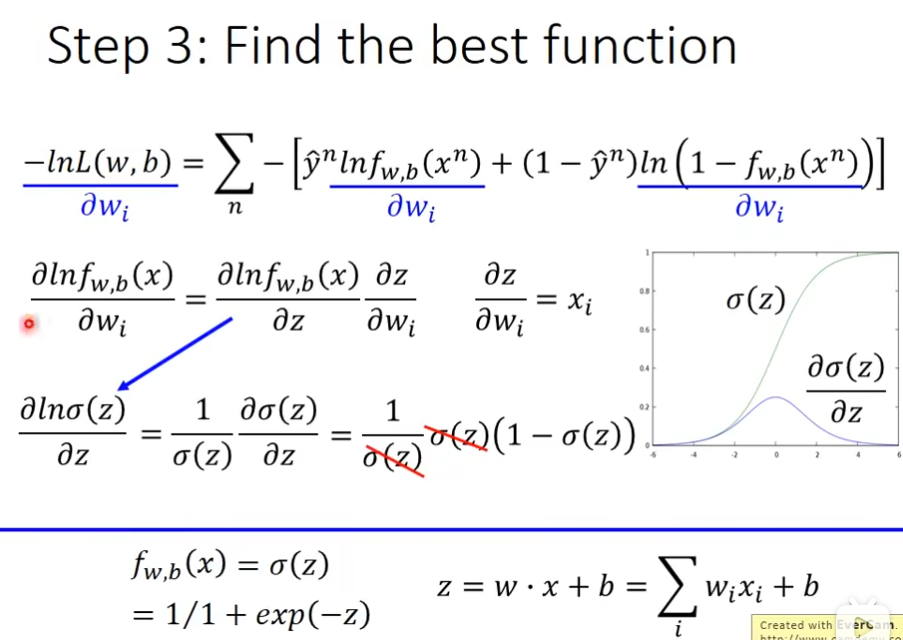
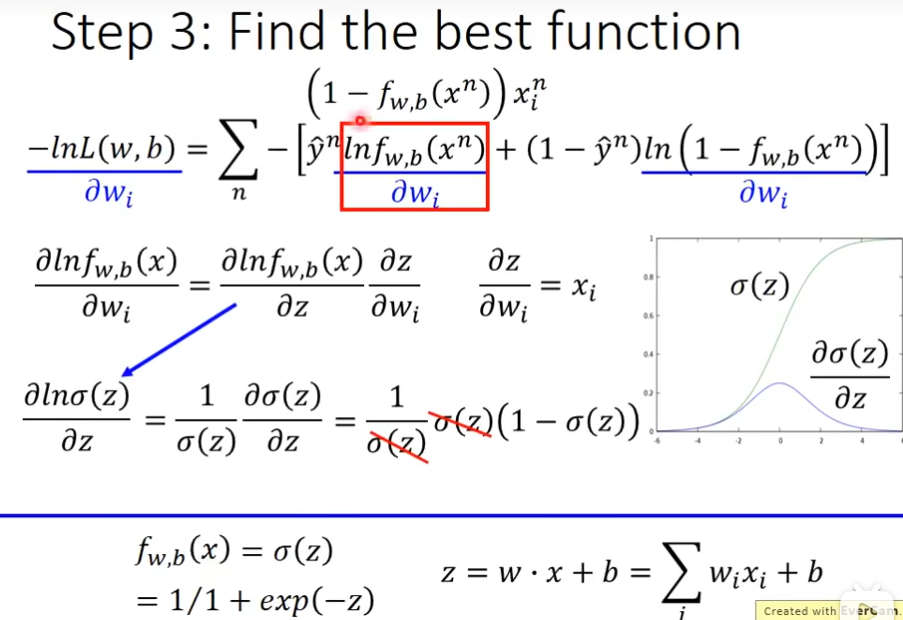


logistic regression 和 linear regression的对比
logistic regression的值是在0到1之间,而linear regression的值是任意的

gradient descent的时候,参数更新方式
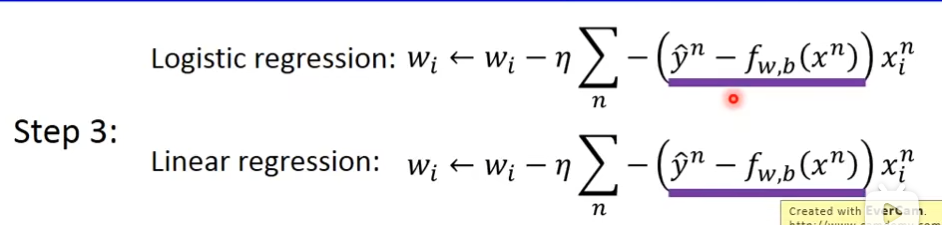
Logistic Regression + Square Error

cros entropy距离目标很远的时候,更新速度越快,而square error的话它的为微分值比较小,所以移动的速度是非常慢的
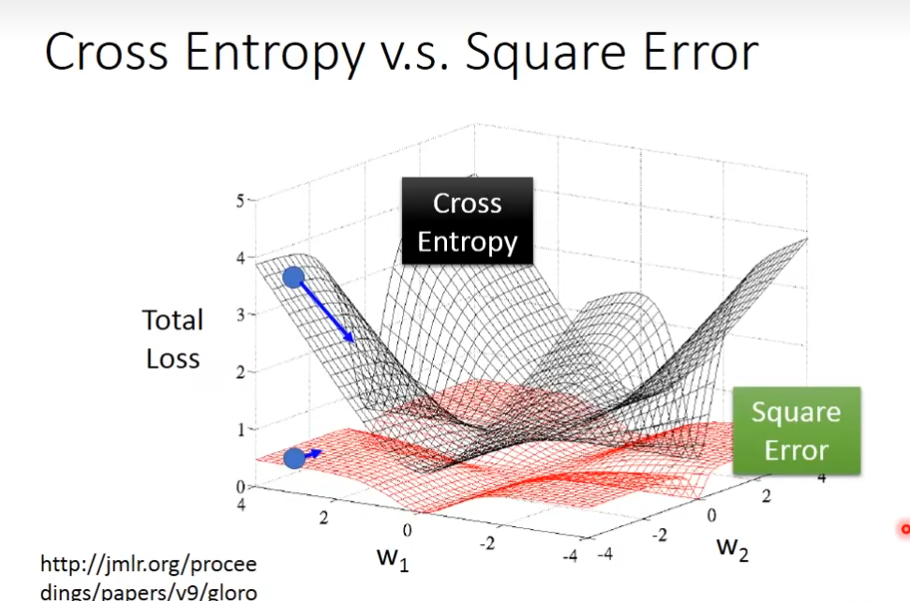
Logistic Regression的方法称为discriminative的方法,用gaussian来描述posterior probability的这件事呢,我们称之为generative的方法,在做概率模型的时候,把covariance matrix设置为share的,那么它们的model是一样的
机器学习任务攻略
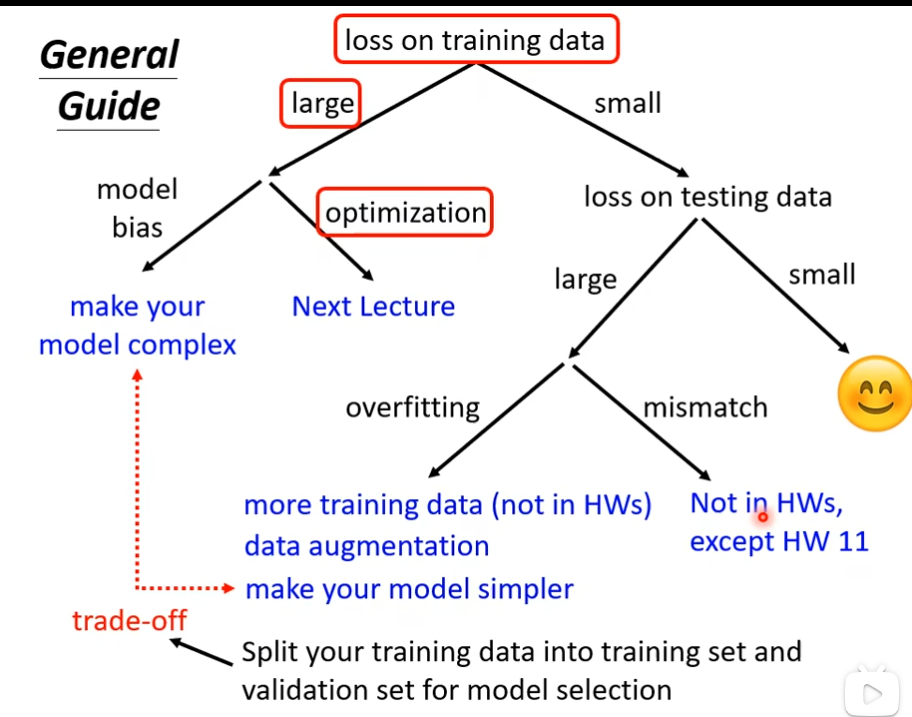
训练上loss值很大
当我们的在训练数据上,loss值很大的时候,我们考虑两个问题
- model bias
- optimization
如果是model bias的话,尝试去加更多的feature,或者更多的neural

如果是optimization的话,可能会卡在localminima,那没办法
如何判断是model bias 还是opimization问题
1.通过对比
通过下图对比可知,56层的还没有20层的优化好,这时候就是optimization的问题,假设56层的前20层不变,后面36层只是复制前面的结果,都不该那么高,56层有更高的弹性,这不是overfitting,也不是model bias
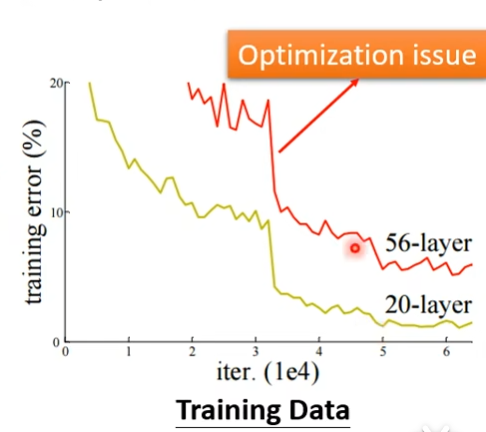
2.可以先跑一些比较小的,比较浅的network,甚至不是deep learning的方法(比如linear model,support vector machine)
如果深的model的loss比浅的model更大,那就是optimization的问题
测试上loss值很大
如果测试上loss值很大,有可能是overfitting(train loss小,test loss大)
如何解决overfitting
-
增加训练数据
-
data augmentation
例如把图片左右变化,截取

但是,要合理,不能像下图那样

-
-
不要让模型有那么大的弹性,比如给模型添加限制
如何给模型添加限制?
-
如果是deep learning的话,给它比较少的神经元的数目
-
让model共用参数
-
更少的feature
-
Early stopping
-
Regularization
-
Dropout
但是不能给模型太多的限制
-
类神经网络训练不起来
局部最小值(local minima)与鞍点(saddle point)
如果卡在localminima的话,就无路可走,如果卡在saddle point的话,可以有路走
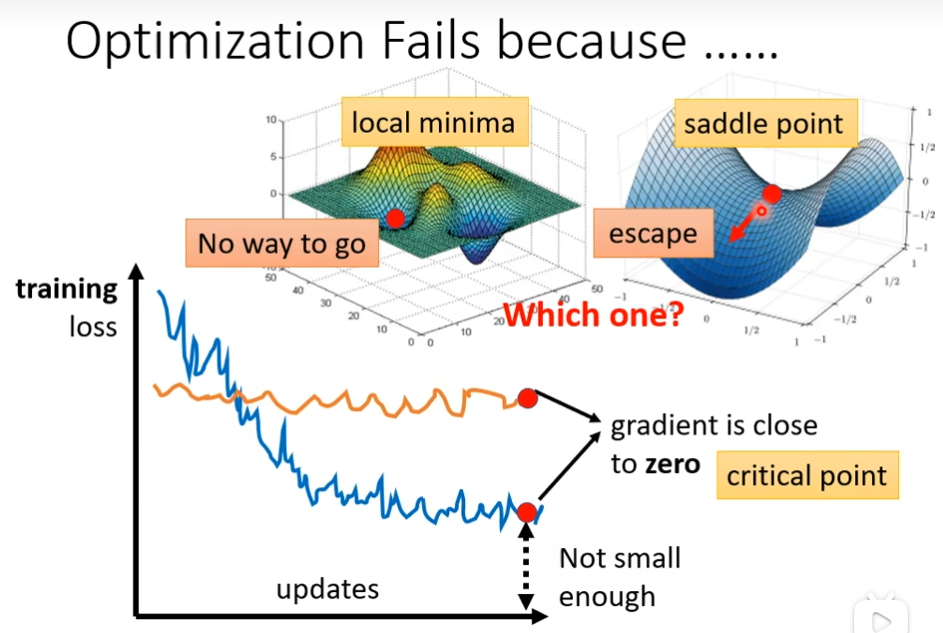
如何判断是卡在localminima还是卡在saddle这个点
可以用泰勒展开,下面那个式子和gradient和hessian有关

如果走到了critical point那么意味着gradient为0,当在critical point的时候,这个loss function可以近似为L(θ')+红色方框的,就知道在θ'的附近到底是长什么样子,我们可以根据红色的这一项来判断说在θ'附近的error surface到底长什么样子,知道error surface长什么样子,就可以知道θ'是一个local minima还是local maxima还是saddle point,这个就是hessian
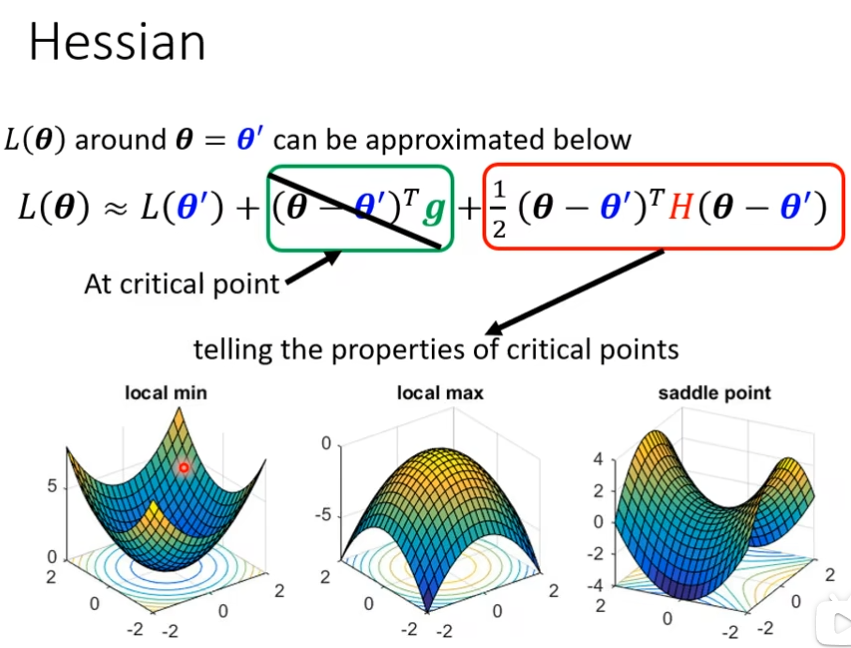
怎样根据hessian来判断θ'的附近的地貌?
如果红色方框所有参数值大于0,代表L(θ')是最低点,所以它是local minima
如果红色方框所有参数值小于0,代表L(θ')是最高点,所以它是local maxima
如果红色方框所有参数,有时候大于0,有时候小于0,那么它就是saddle point
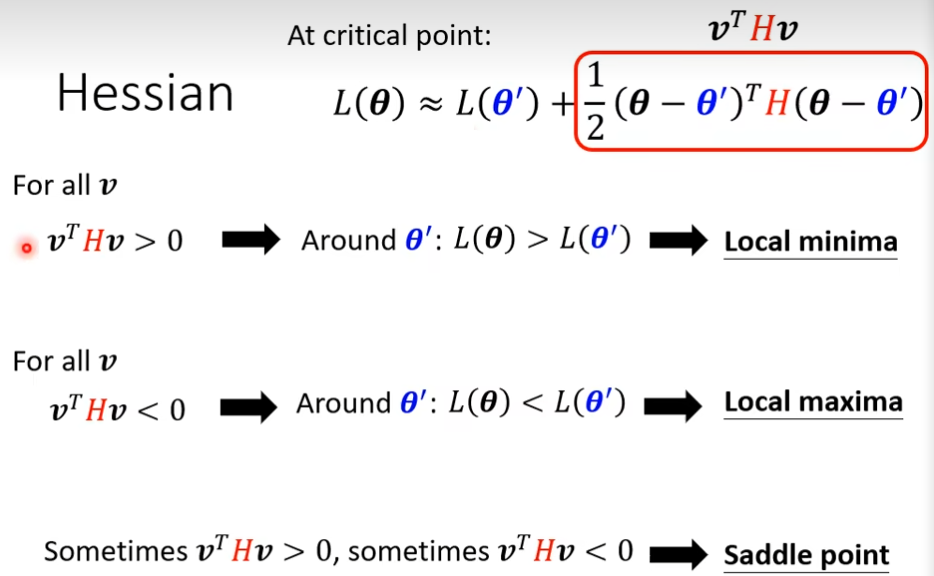
但是我们不可能把所有值都带入进去算,那怎么办
如果所有的vTHv都大于0,这种矩阵叫positive definite,其所有的eigen value(特征值)都是正的,对应local minima
如果所有的vTHv都小于0,这种矩阵叫negative definite,其所有的eigen value(特征值)都是负的,对应local maxima
如果eigen value有正的也有负的,那么就是saddle point
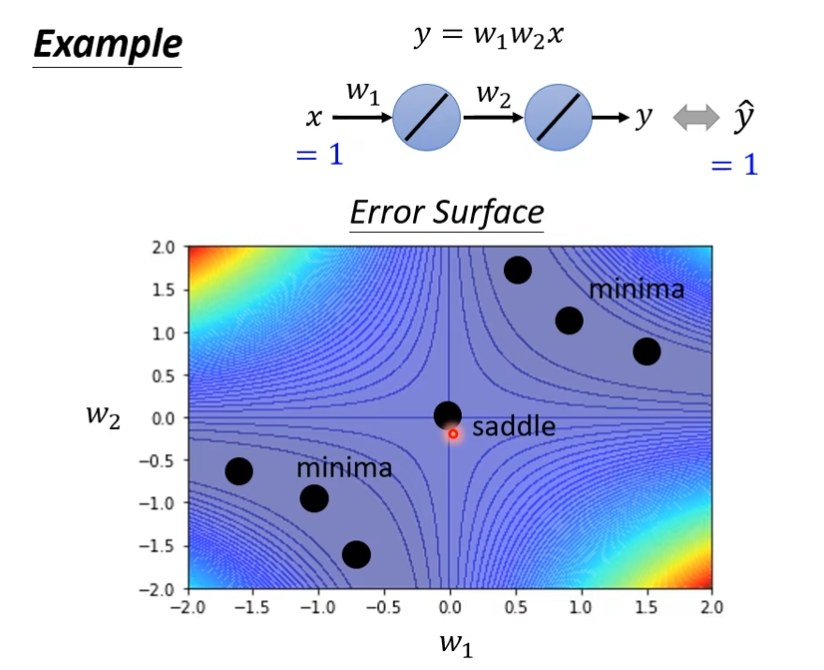
例子
黑色的点是critical point,而中心的是saddle point,因为从这个点出发,它的左上和右下的值都很高,而左下和右上的值很小,符合saddle point的特征,而其他的是minima
我们把loss function写出来,然后把gradient( g = [ ∂L/∂W1, ∂L/∂W2]T )求出来,如果gradient的值都为0,那么就是critical point,接下来通过H(hessian)来判断是minima ,还是maxima,还是saddle point,这个H是由二阶偏导数组成的矩阵,接下来计算其特征值,就可以知道是saddle point还是minima
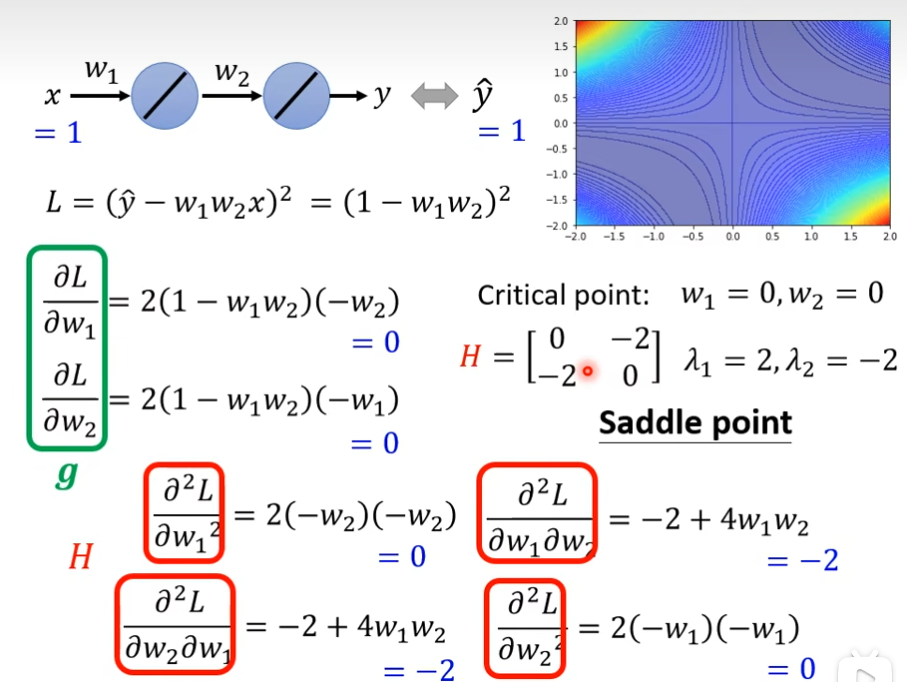
H不仅告诉我们是什么类型,而且还告诉我们了更新方向,如果λ小于0,那么红色方框里面就是小于0,也就是L(θ) < L(θ'),假设θ - θ' = u,也就是θ = θ' + u,在θ'的位置上沿着u的方向做update得到θ就可以让Loss变小

H有一个负特征值:-2,那么-2对应的特征向量是[1,1]T,随着这个特征向量的方向去更新参数,就可以找到更低的点
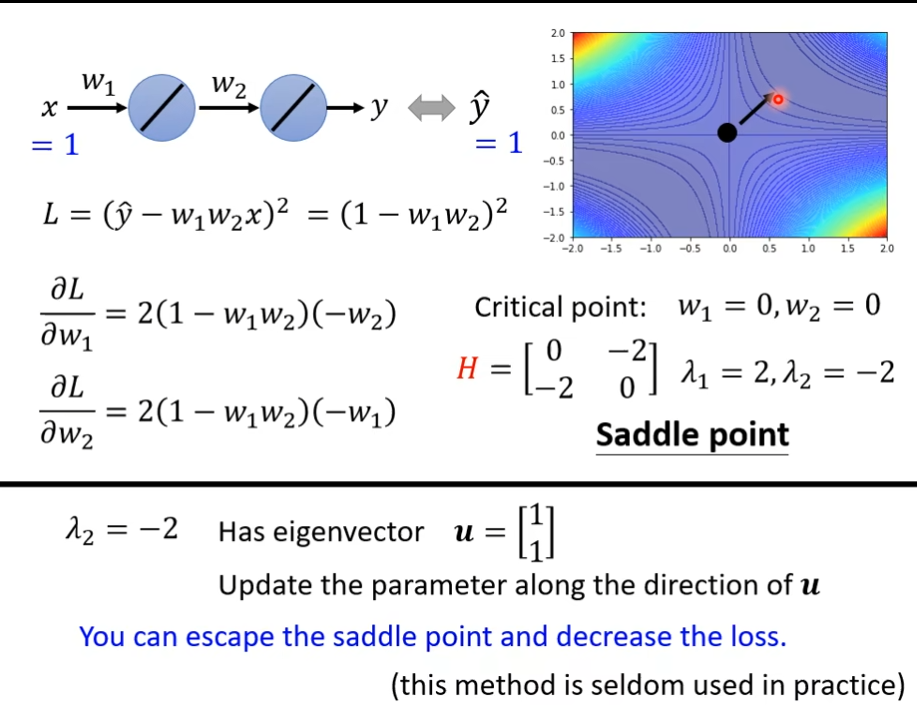
批次(batch)动量(momentum)
batch
左边是没有用batch,也叫full batch,我们的model必须把20个资料全部看完才能计算Loss和gradient,右边是batch_size设置为1,我们每次更新参数只需要看一个资料就好,看着一个资料就可以计算loss和gradient

但有时并不是full batch的运行时间时间比较长,因为gpu是进行并行计算,一个大的batch反而是时间花的比较少的。
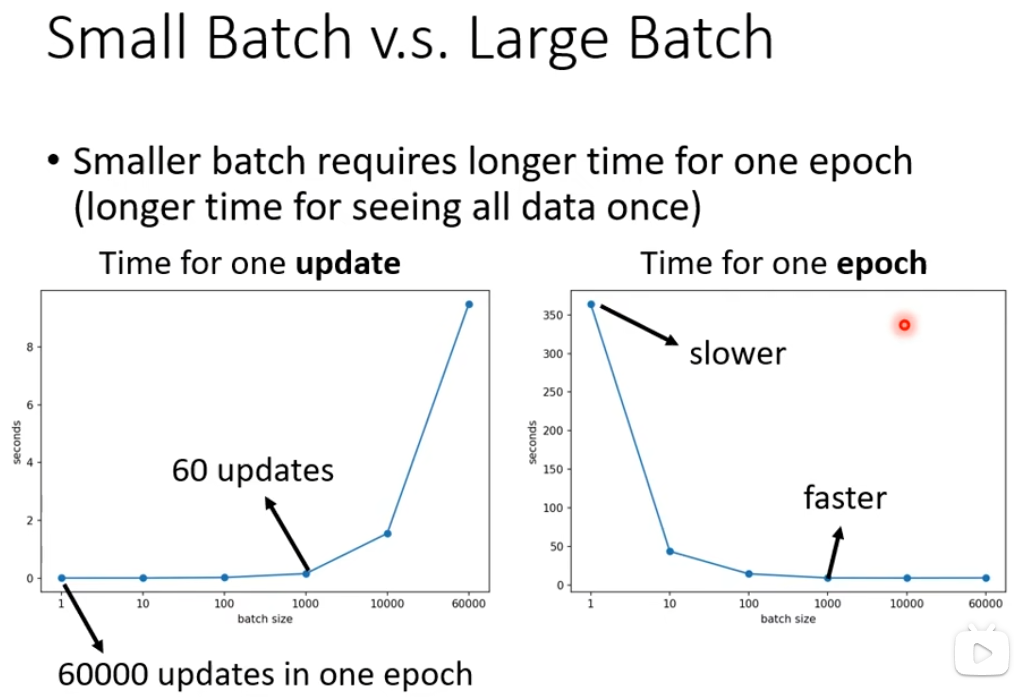
但是用在mnist(手写辨识)和cifar-10上,batch_size越小,准确率越高
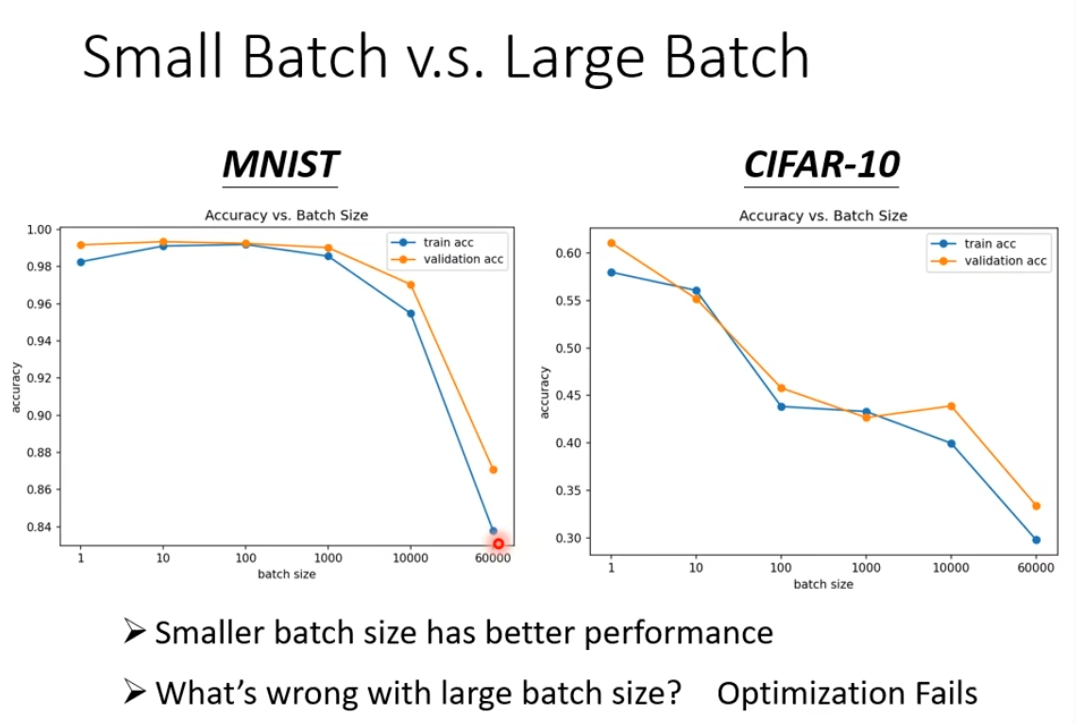
小batch在训练上表现更好,加入在L1上某个点卡住了,但是在L2上未必卡住,而full batch沿着一个loss function更新的时候,卡住就真的卡住了,有时候noisy 反而适合训练

small batch 和large batch的对比,这个batch_size是一个hyperparameter需要你自己决定
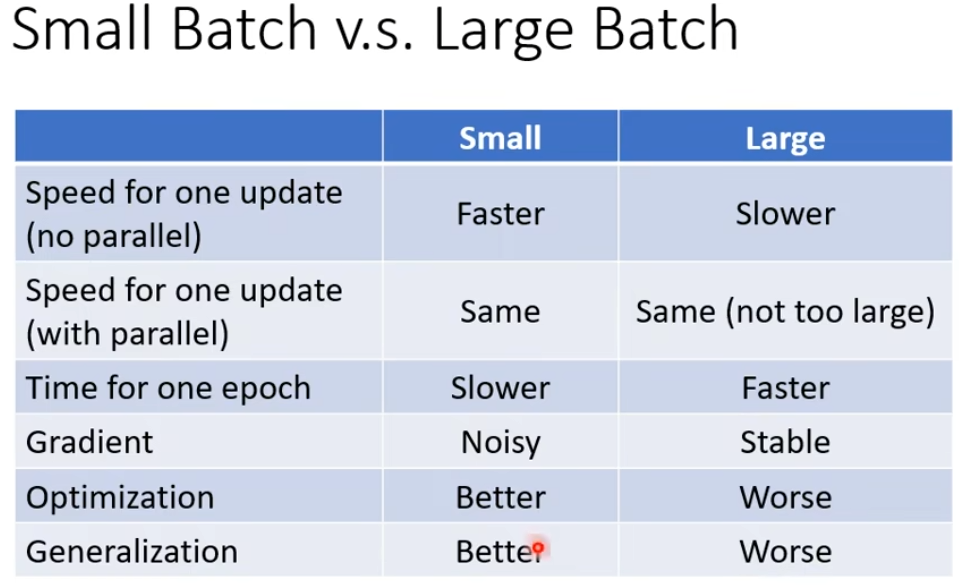
Momentum
momentum是可能对抗saddle point 和local minima的技术
假设Error surface是真正的斜坡,而参数是一个球,球可能走到saddle point或者local minima就停下来,但是在现实生活中,球可能依靠惯性走出这个saddle point和local minima。
一般的gradient descent方法
1 更新参数
2 计算梯度
3 往梯度的反方向update参数
4 重复上述
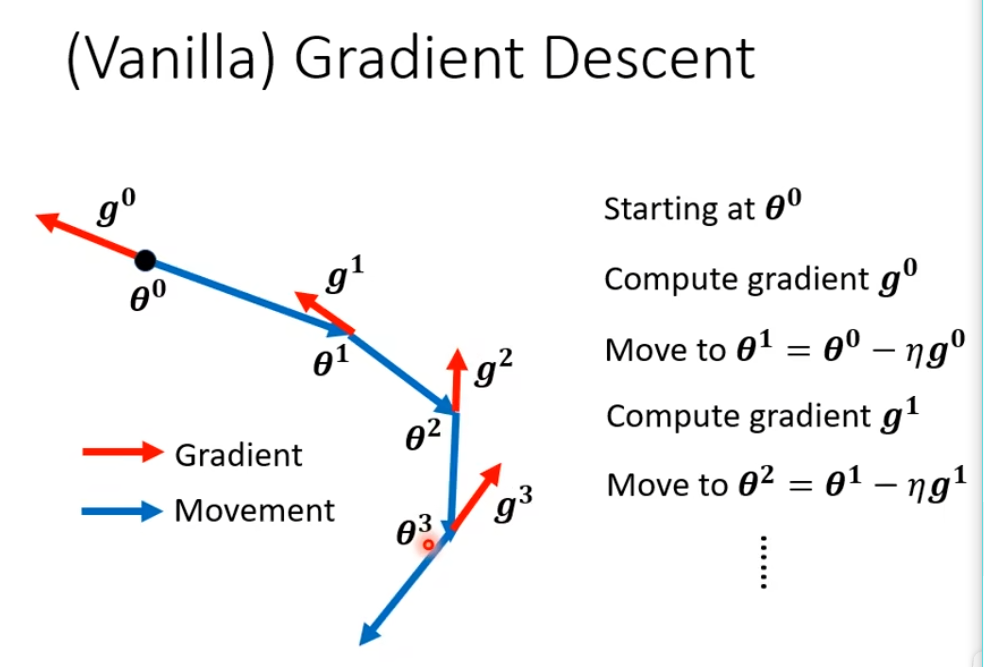
momentum+gradient descent
使用momentum的话,我们不只是往gradient的反方向来移动参数,还需要加上前一步移动的方向,两者加起来的结果,去调整我们的参数
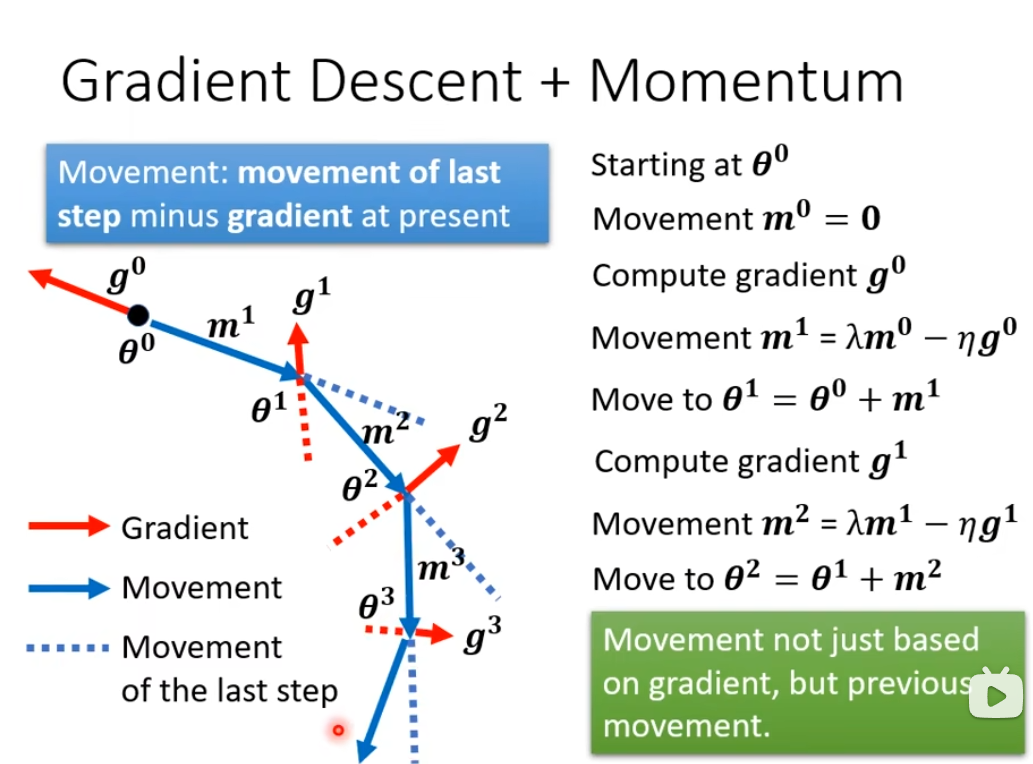

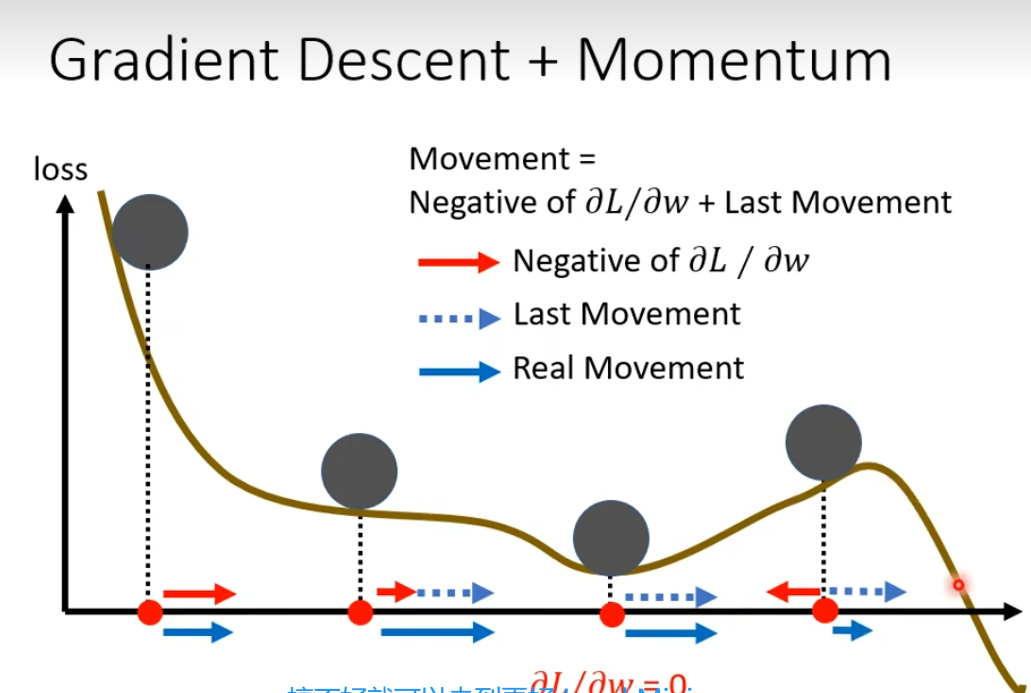
例子,下面前3个小球的梯度都是负的,但是要往梯度的反方向走,也就要往右边走(右边是正的),第4个小球的梯度是正的,要反方向走(也就是左边),但是需要考虑上一步移动的方向,所以就还是往右边走
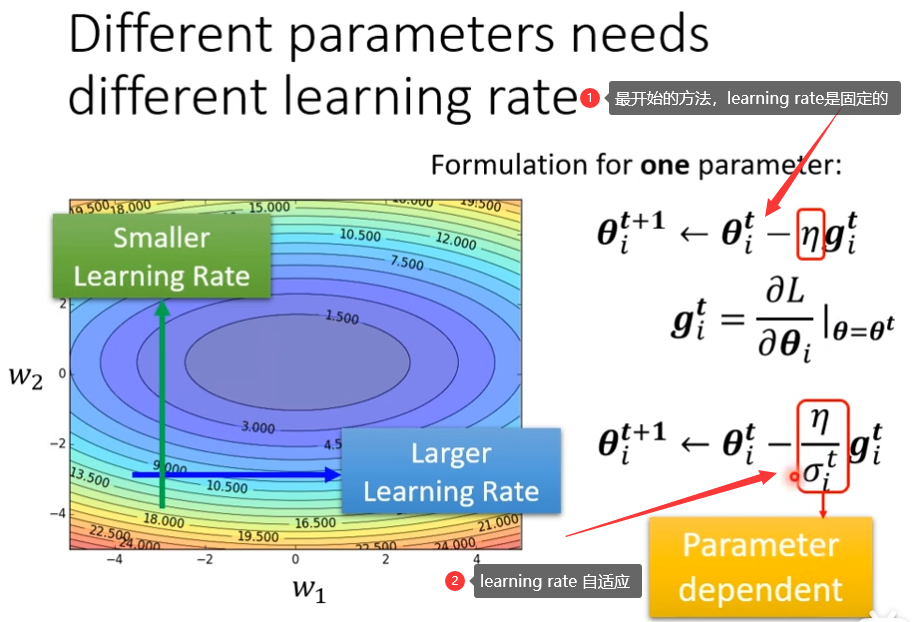
自动调整学习率(Learning Rate)
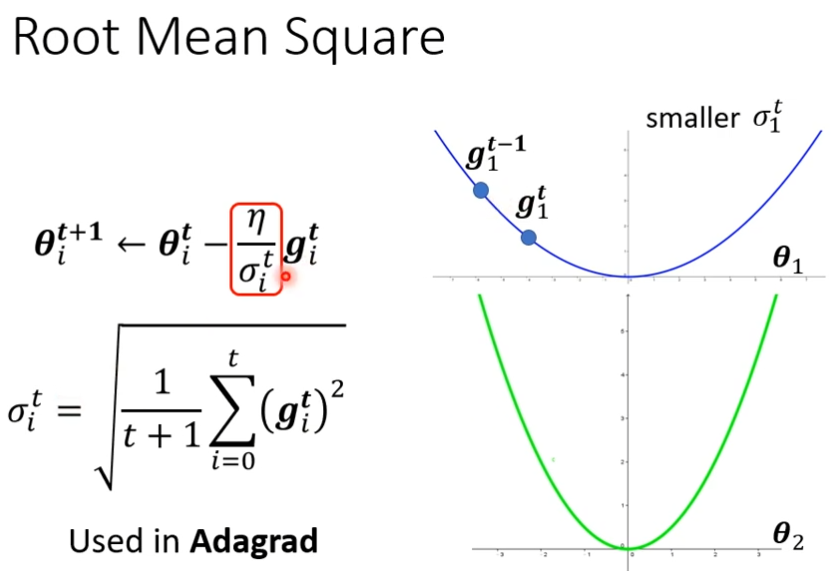
当你训练一个network的时候,训练到最后,loss不再下降的时候,不一定是卡在criticla point,有可能是learning rate,不同的参数需要不同learning rate,如果gradient的值很小,那么我们希望learning rate大一点,如果gradient比较大,希望learning rate小一点
root mean square(均方根)
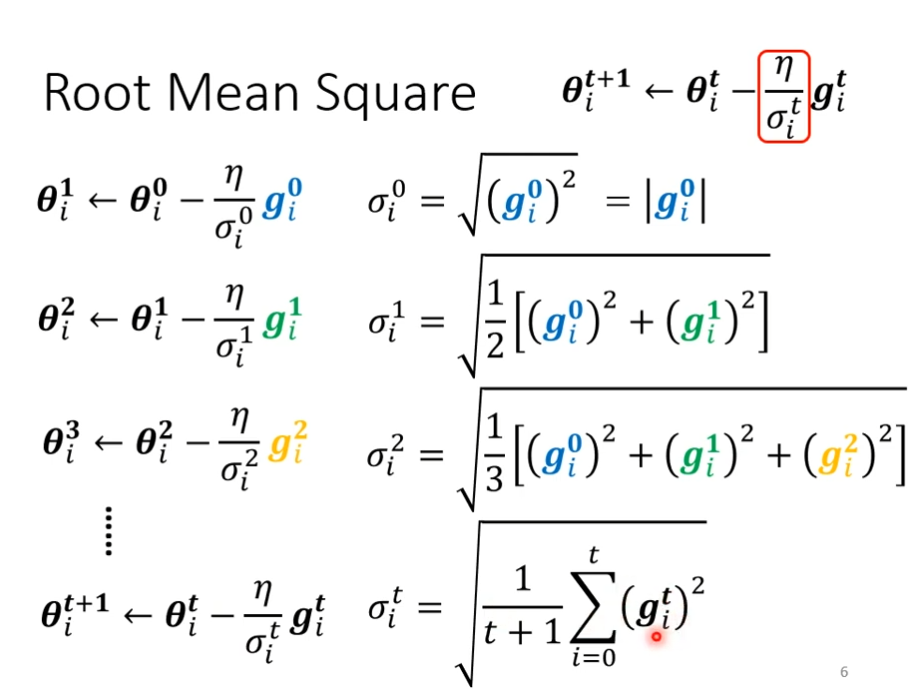
RMSProp
上面的均方根会随着时间的变化而变化
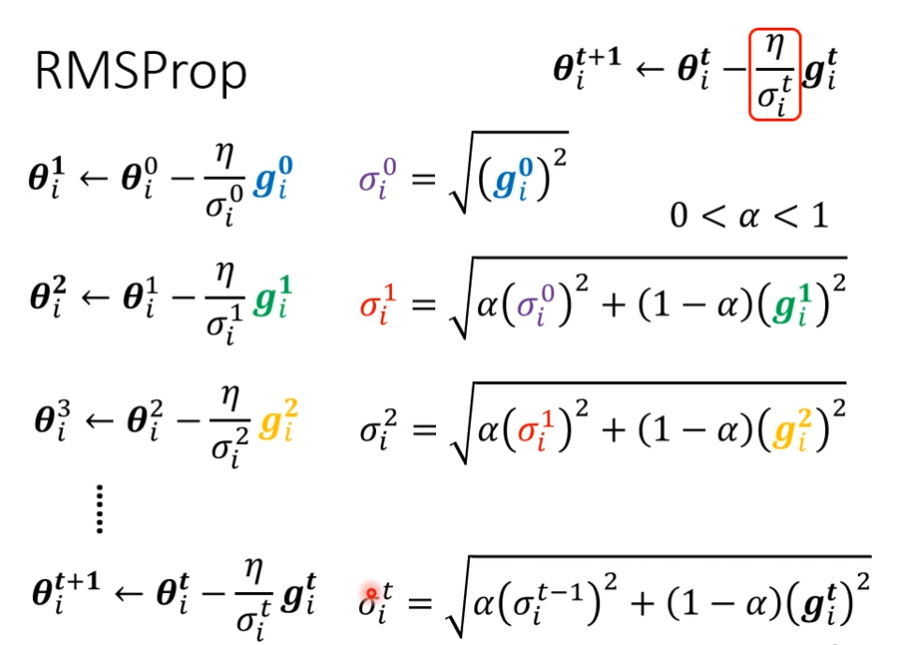
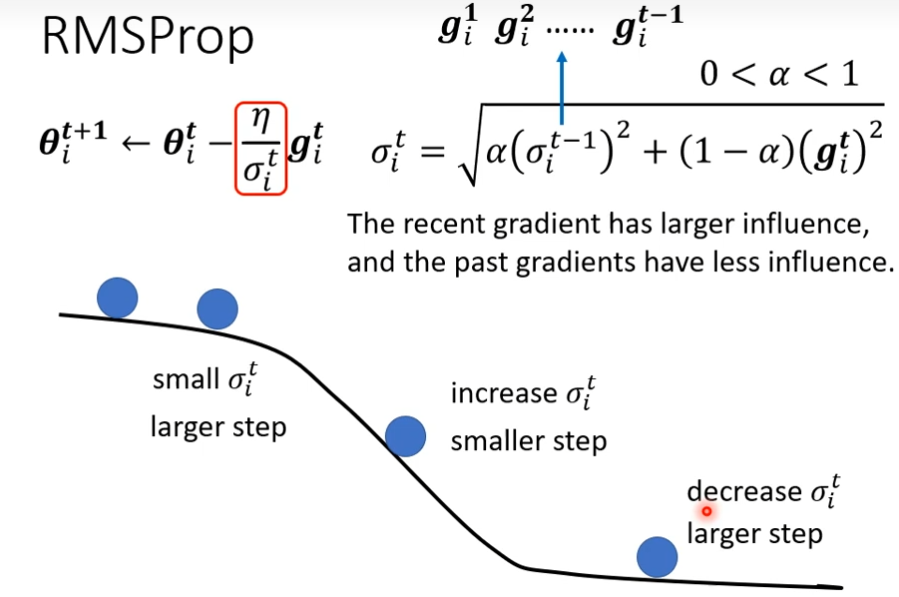
Adam: RMSProp + Momentum
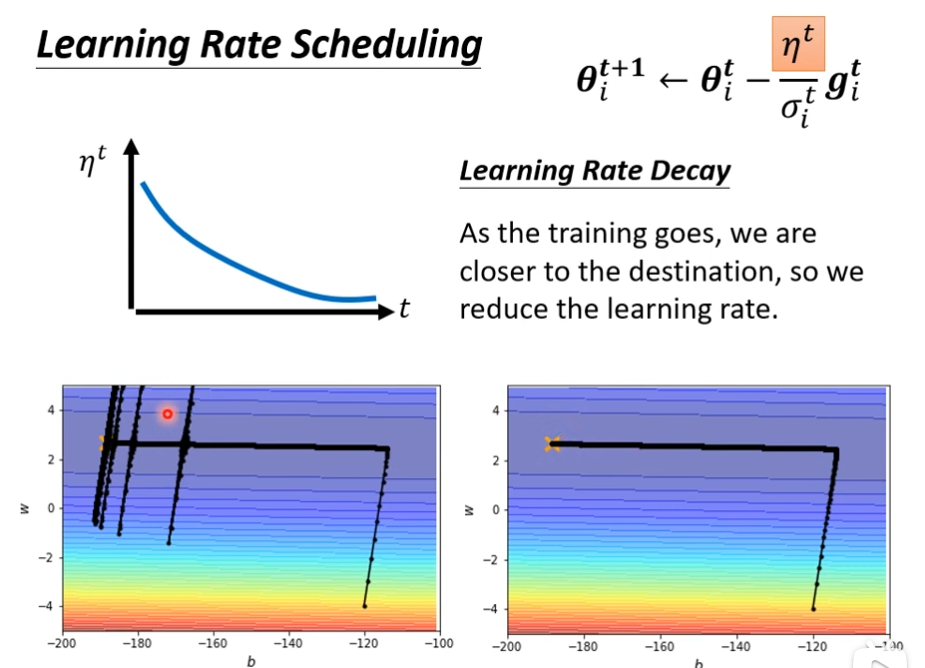
Learning Rate Scheduling
和时间有关,均方根的方法加上这个,会让点很平滑的走到终点
Learning rate decay
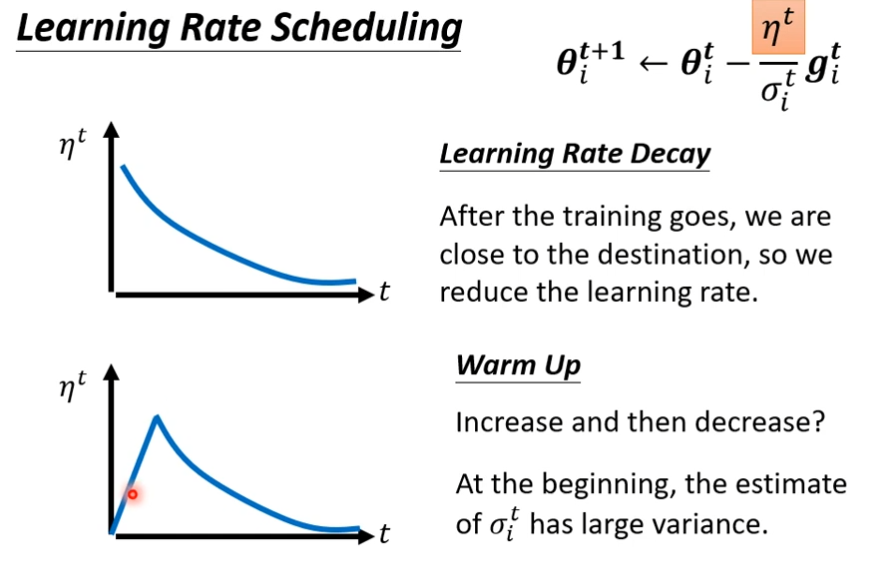
warm up(bert可能用到)
先让它在初始的地方慢慢探索,一开始learning rate比较小,等σ统计的比较准的时候,再让learning rate慢慢爬升
optimization的总结
momentum把过去所有的gradient方向求和,当做更新的方向,它会考虑往左走还是往右走,update多少由对梯度的均方根决定,均方根不考虑gradient的方向,只考虑大小(计算的时候都要取平方项)

损失函数(Loss)可能有影响
Classification as Regression
- regression
输入一个向量,然后输出一个数值,我们希望输出的数值跟某一个label(学习的目标)越接近越好,

- Classification as Regression
输入一个向量,然后输出一个数值,这个y,我们要让它跟正确答案的class越接近越好,y是一个数字,我们必须把class也变为一个数字,比如说class1就是1,class2就是2...。接下来就是希望y跟class的编号越接近越好。但是有时候class1和class2就比较近,而class1和class2就比较远。
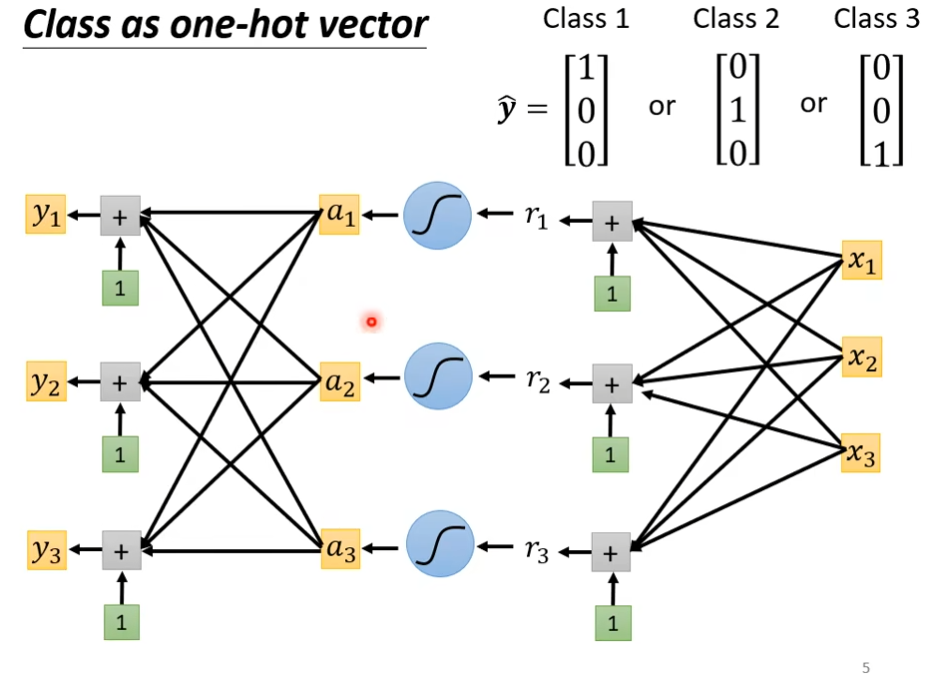
这时候一个普遍的做法将class转换为向量(class as one-hot vector),用这种方式来说,就没有class1和class2比较接近,class1和class3远的,这一说法了,把这个矩阵之间计算距离,两两之间都是一样的。
如果ŷ是三个数值的向量,那么我们的network的output也需要有三个输出,但是现在output只有一个数值,只需要把output的方法重复三遍就可以了。乘上不同的w加上不同的b就可以了。
Regression 和 Classification的对比
- regression
regression是输出一个y(数值),只要和ŷ越接近越好

- classification
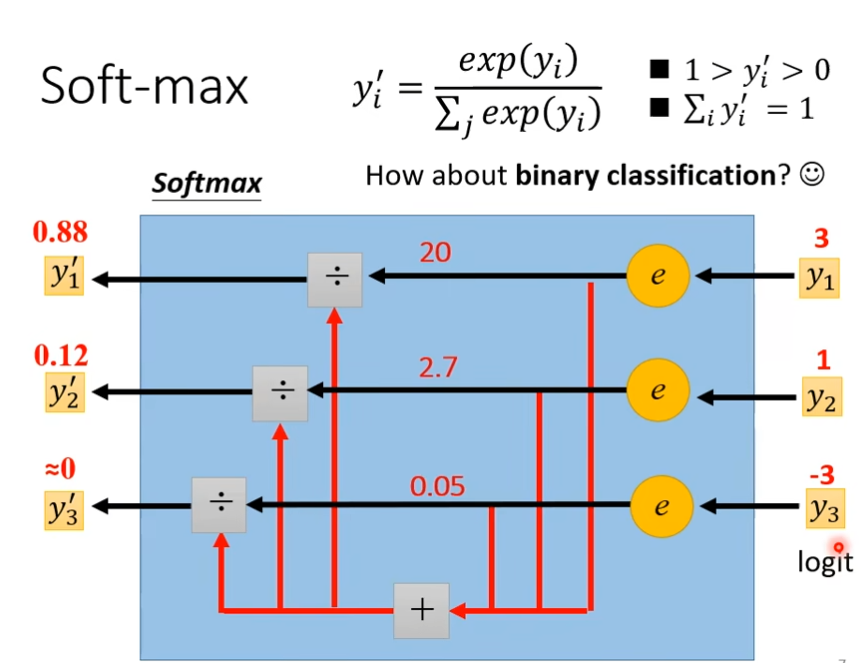
这个W'是上图class as one-hot vector里面的乘上不同的w组成的矩阵,b'同样如此,但是这里的y是一个向量,但是在做classification的时候,我们往往会把y通过一个softmax()函数得到y',然后再计算y'和ŷ之间的距离。这个softmax有一个通俗的解释是,假设ŷ里面要么是0要么是1,而y里面可以是任何值,所以我们用将y转换下,normalize,移到0到1之间
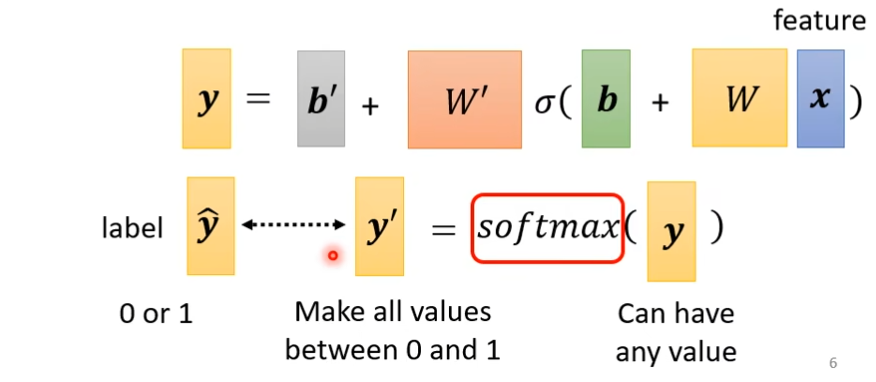
softmax
图示法如下
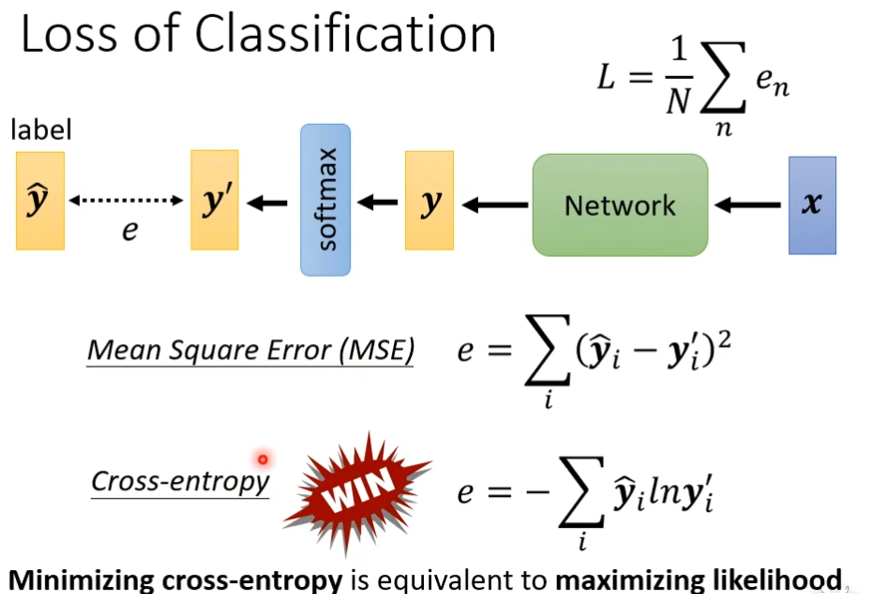
loss of classification
cross-entropy比mse更好
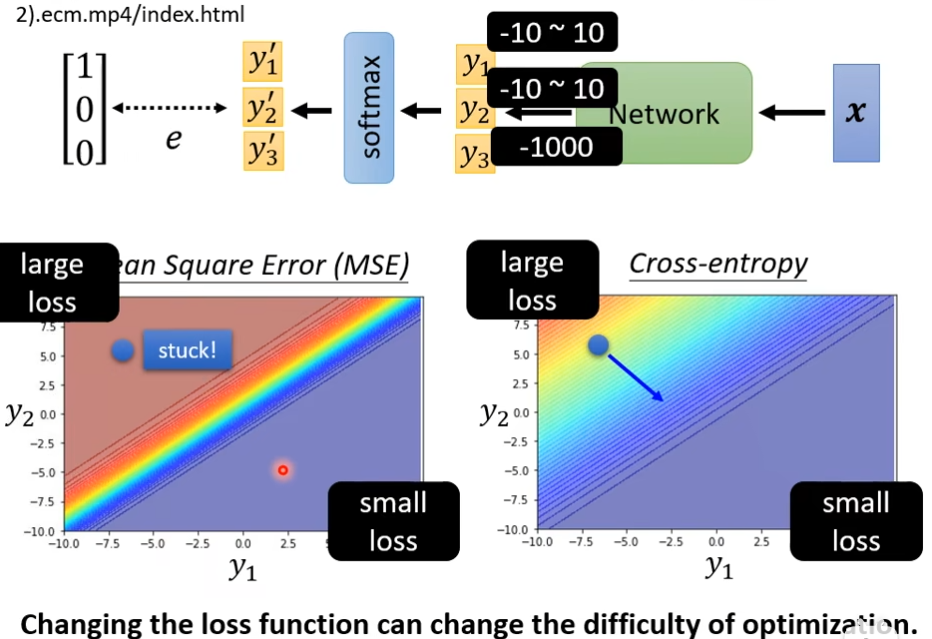
为什么cross-entropy比mse好?在下面的图片可以看出,在gradient比较大的地方,mse容易卡住,而cross-entropy不会。如果在做classification,选mse可能训练不起来,
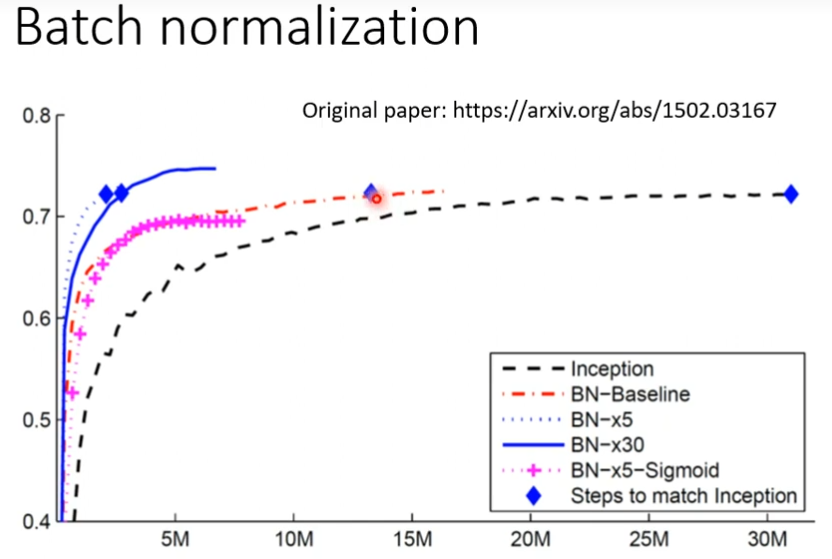
批次标准化(batch normalization)
batch normalization就是想把崎岖的山铲平的想法
假设现在两个参数,它们对loss的斜率差别非常大,在w1这个方向上斜率变化很小,在w2这个方向上斜率变化很大,如果是固定的learning rate可能很难得到好的结果,需要adaptive的learning rate,你需要adam等等比较进阶的optimization的方法,现在换个角度,把难做的error surface把它改掉。首先,我们要知道为什么w1和w2它们的斜率差很多的这种情况到底是从什么地方来的。
现在有一个简单的例子,输入有x1和x2,对应的weight是w1和w2是一个linear model,什么情况导致不好训练了?如果w1有改变的话,那么Loss也会跟着变,那么什么时候w1的改变会对L的影响很小呢,在errorr surface上的斜率很小了?一种可能性是当你的x1的input很小的时候,w1乘上input的值,对y的影响很小,从而对L的影响也很小
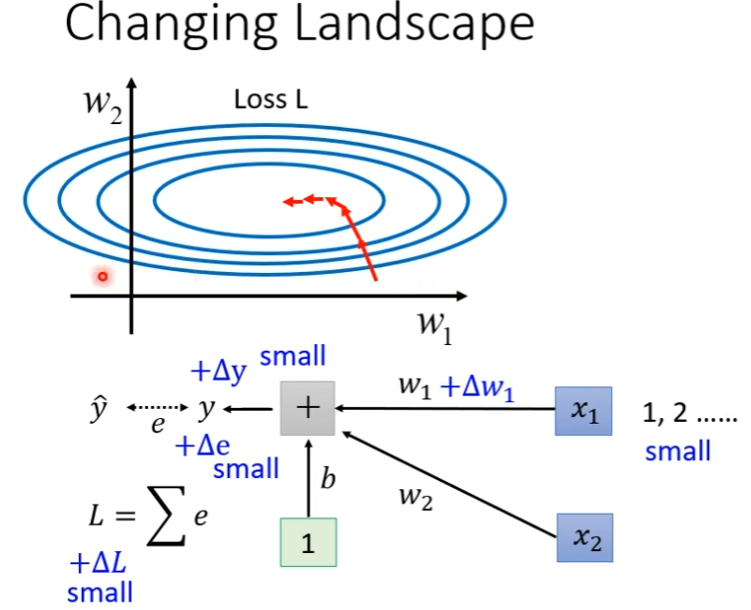
如果是x2的input很大的时候,w2的小小变化,也会让y的变化很大,当我们input feature每一个dimension的值它的scale差距很大的时候,我们可能就产生了这样子的error surface,不同方向的,它的斜率非常不同的,如果我们给feature里面不同的dimension(例如x1的1和x2的100,这叫一个dimension),让它有同样的数值范围,这时可能就可以制造比较好的error surface让训练变的容易一点
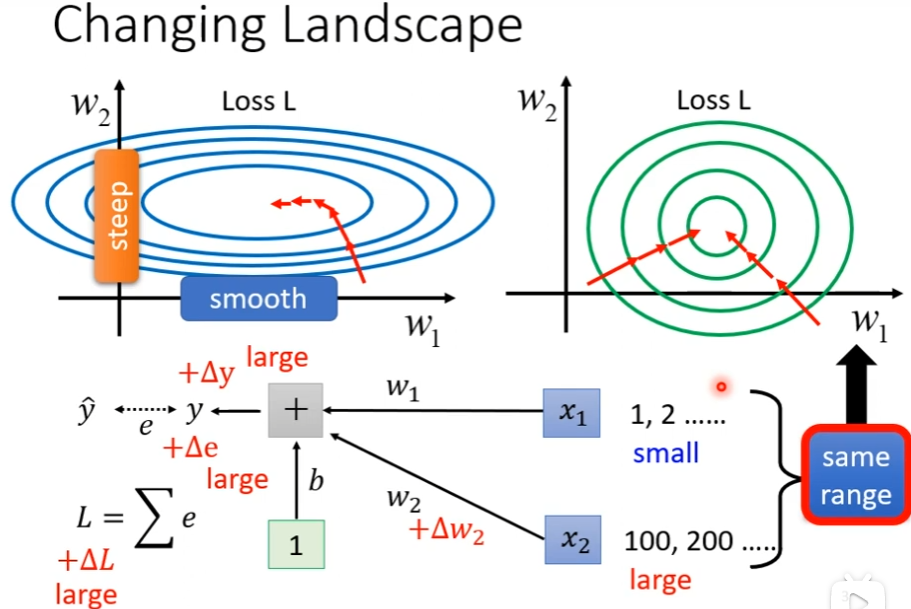
那怎么让不同的dimension有类似的,有接近的数值的范围呢,这种方法称为feature normalization
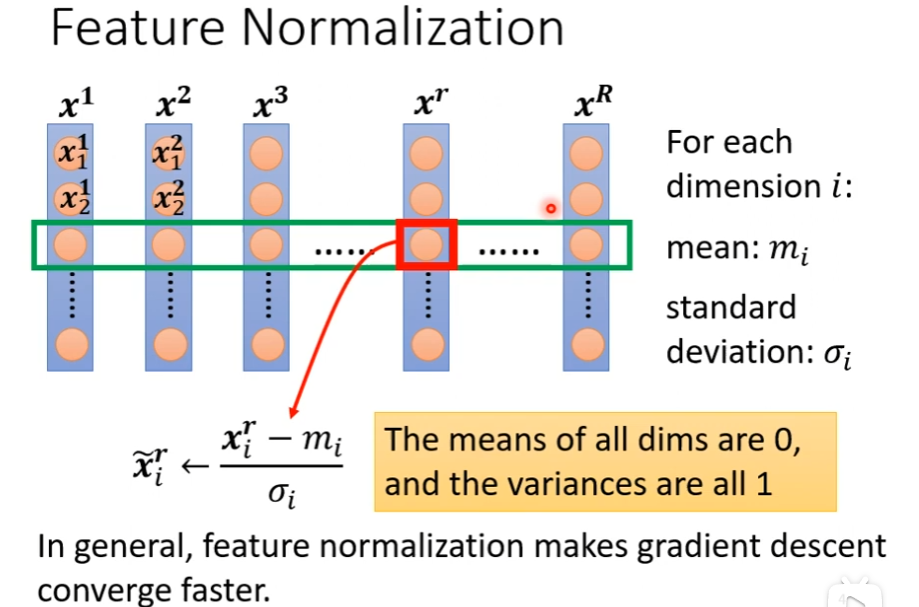
feature normalization
我们把所有要训练的vector集合起来,我们把不同feature vector里面的同一个dimension里面的数值,把它取出来,然后计算某一个dimension的mean,这里叫mi,计算某一个dimension的standard deviation(标准偏差),叫σi,接下来做normalization(标准化),然后用这个x减掉这一个dimension的mean,然后除以σi,这之后这个dimension上面的数值就会平均值是0,它的variance(方差,参考链接:如何计算方差: 8 步骤(包含图片) (wikihow.com))就会是1,所以这一排的数值就会分布在0上下,然后对每一个dimension做同样的事,这时你可能就制造比较好的error surface,这种方式会对你的训练有帮助,可以帮助你在gradient descent的时候这个loss会收敛的快一点
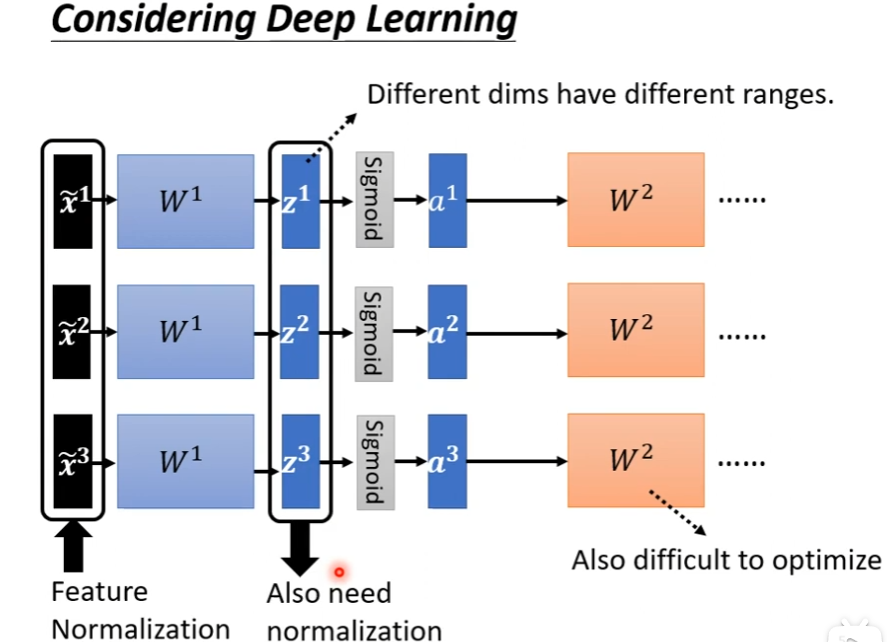
deep learning可以做feature normalization,做完feature normalization后,丢到deep network里面,进行后面的训练,但是对于W2来说前面的z1,z2,z3和a1,a2,a3也是另外一个input,虽然x已经经过normalize了,但是经过W1后,这个dimension之间有数值的分布仍然有很大的差异的话,这时候如果想要训练W2这层可能有点困难,所以我们应该要对a和z做feature normalization,在激活函数前还是激活函数后做normalization差别不大(李沐说不能在激活函数后做BN),如果激活函数是sigmoid的话,那么推荐做feature normalization
那怎么对z做feature normalization呢?
答:把z当做feature嘛,计算它的μ和σ
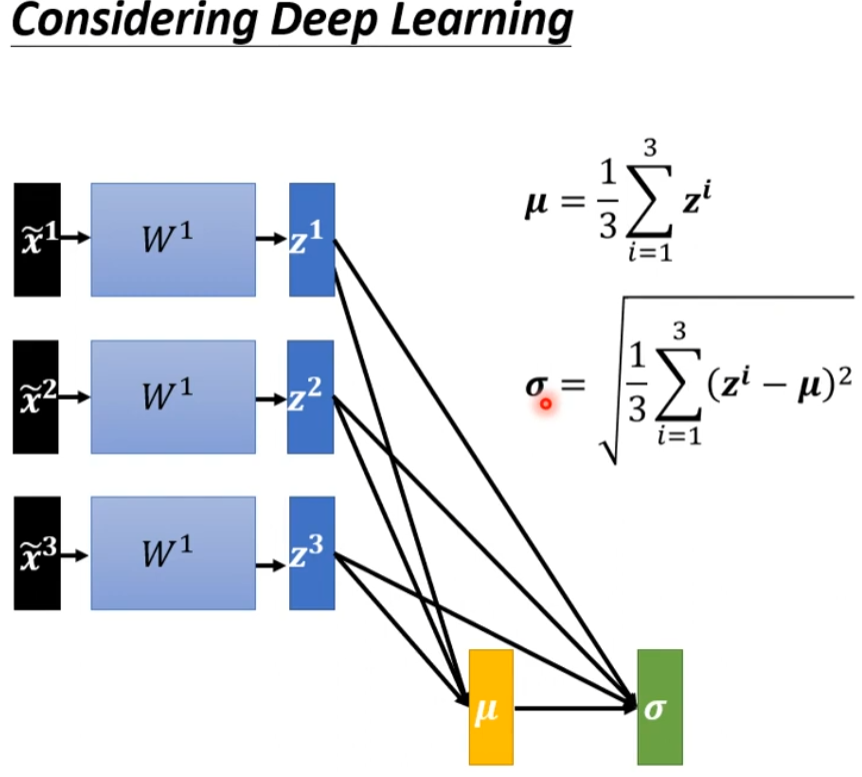
然后
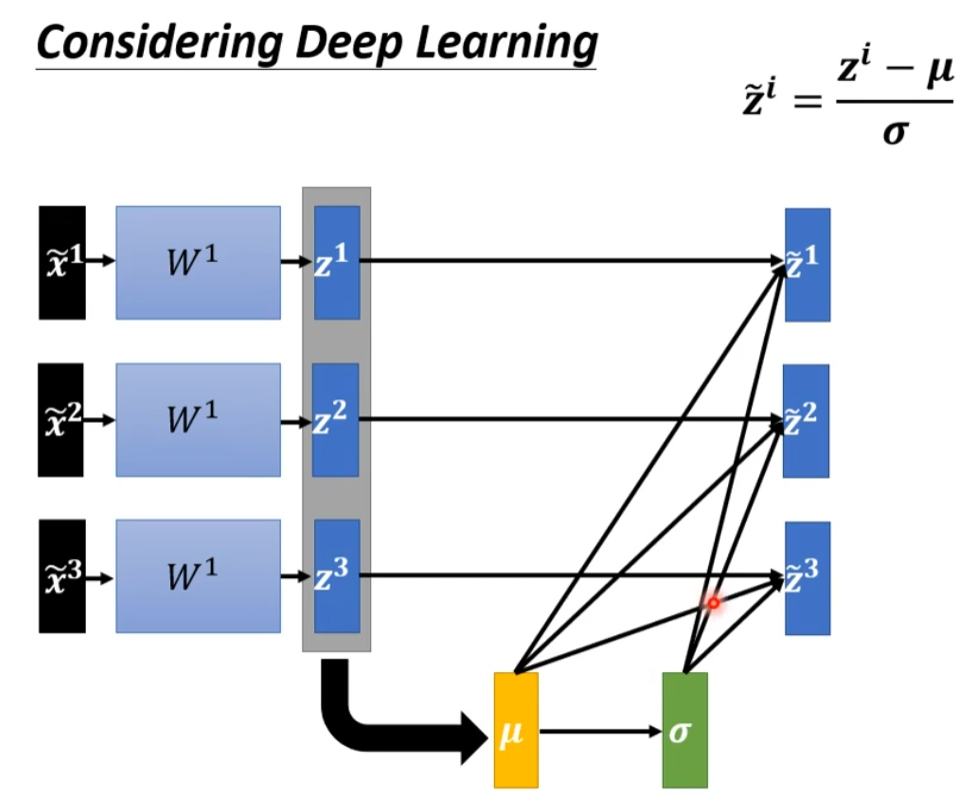
我们发现现在z1和z2和z3经过normalization后这三个x开始变的关联了,z1发生改变时,\(\tilde{z2}\),a2,a3都会发生改变,这里是不是可以简单理解为:因为均值和方差涉及到了其他数据,所以后面的输出与前面的几个数据都产生了联系。
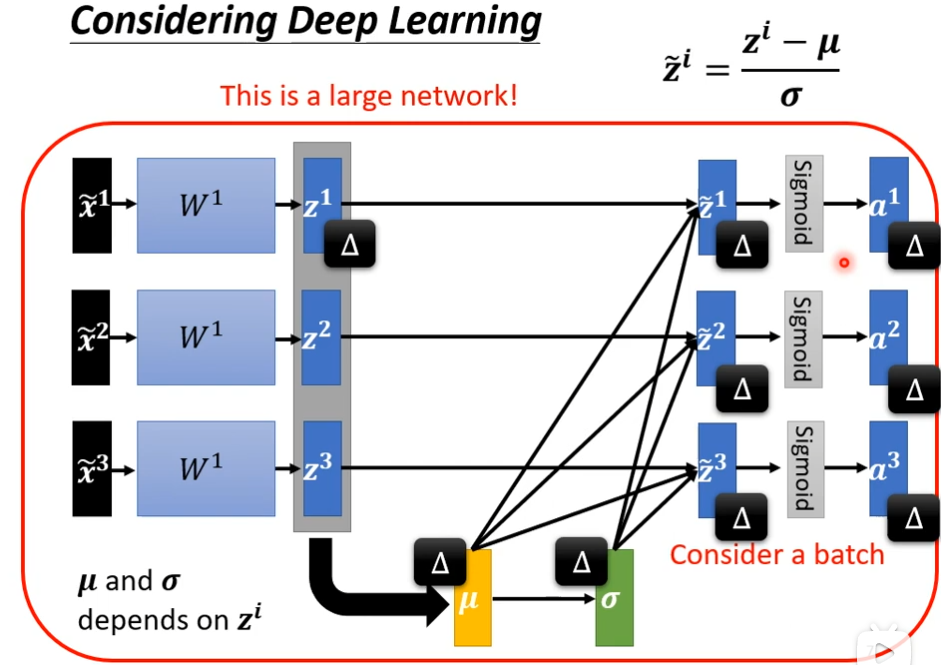
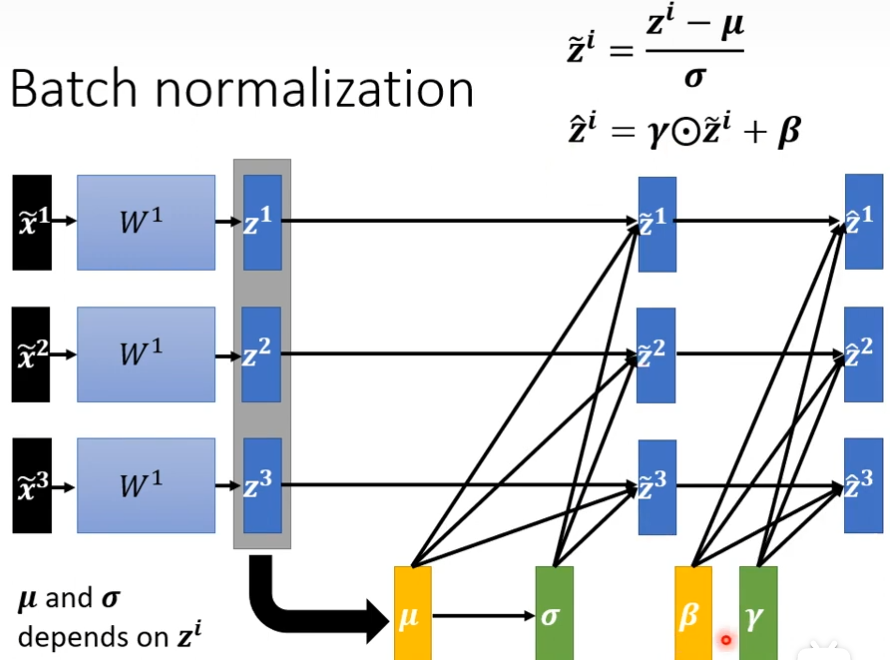
你的训练资料里面,你的data非常多,如果有上百万资料丢到network里面,gpu是无法算出来的,实际中,你不会考虑整个training data里面的所有example,你会考虑一个batch里面的example,举例说,你batch设为64,你就比64个data带进去,然后算64个data的μ,然后算64个data的σ,64个data的normalization,实际中我们会对一个batch里面的data做normalization,所以叫做batch normalization,要求比较大的batch_size,才能算出μ和σ,然后再对$ \tilde{z} \(做element-wise相乘γ(对应元素逐个相乘,参考链接[element-wise 相乘的直观意义是什么? - 知乎 (zhihu.com)](https://www.zhihu.com/question/65866370))然后加上β得到\) \hat{Z} $,而β和γ可以看做是network的参数,是你自己决定
为什么要加β和γ呢?
答: $ \tilde{z} $做normalization后,它的平均值可能是0,0会给network一些限制,这些限制可能会带来某些负面的影响,我把β和γ,让hidden layr的output的平均值不是0
现在乘上γ加上β会不会让同一个dimension的range分布不一样?
答:有可能呢,这里γ全是1的vector,β全是0的vector,所以一开始在训练的时候,让每一个dimension的分布是比较接近的
batch normalization-Testing
这个μ和σ是根据batch而算来的,如果今天没有batch怎么办?
答:做滑动平均(moving average)

黑色曲线是没有经过batch normalization的,红色曲线是经过batch normalization的,虽然可能最后的准确度差不多,但是,红色曲线花更少的时间就到了一个不错的准确度
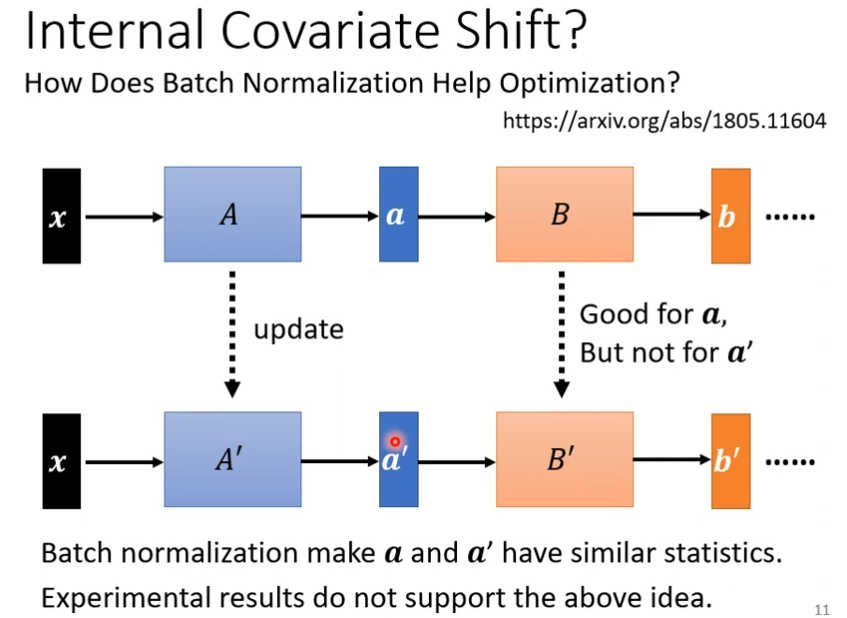
Internal Covariate Shift?
batch normalization的作者考虑到以下问题
在做gradient descent的时候,A更新成A‘,B更新成B’,我们在计算B更新到B‘的gradient的时候,这时候前一层的参数是A,output是a,a就变成了a',但是我更新的B到B‘的时候,是根据a算出来的,a'不一定适应,但是别人经过实验发现差距不大,其他不赞同作者的观点
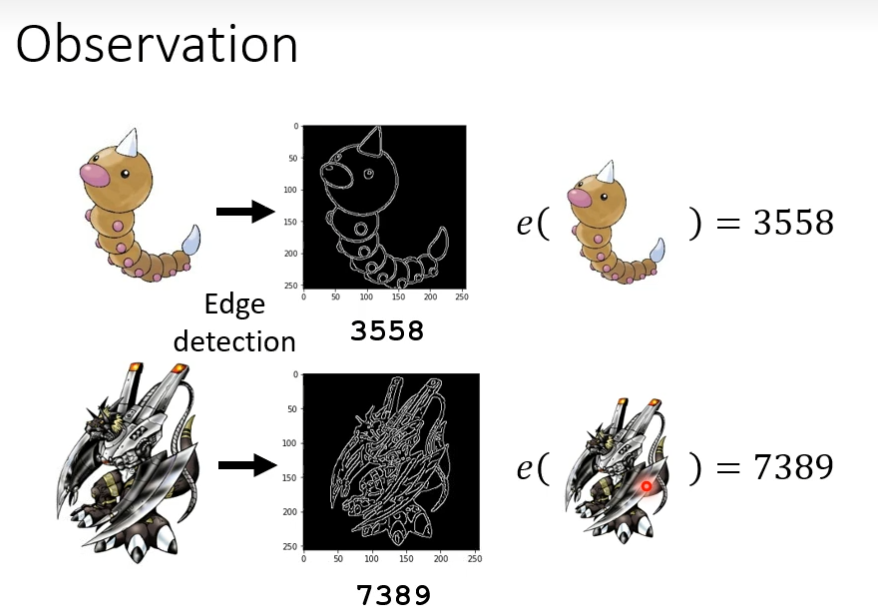
再探宝可梦教码宝贝分类-浅谈机器学原理
我们需要一个函数,这个函数能够分清宝可梦和数码宝贝,通过观察,我们发现数码宝贝线条比较复杂,而宝可梦线条比较简单,我们可以通过edge detection
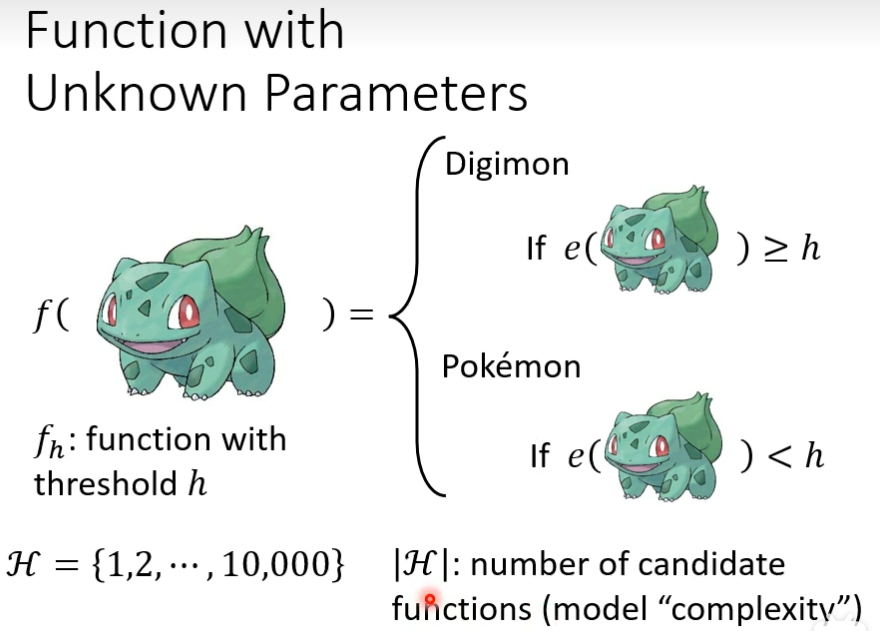
第一步 定义function
然后定义一个function可以来分别宝可梦还是数码宝贝,输入一个物种,如果线条的复杂程度大于某一数值就是数码宝贝,否则就是宝可梦,现在就不知道这个h应该取多少,我把h所有可能参数组成一个集合,|h|是函数的可能参数数量,模型很复杂就是函数的参数范围很广
第二步 定义loss function
输入为h和D,我们看哪一个h会让loss值越低,这个右边的小l函数的作用是上图,把小h当做阈值,图像当做输入,如果输出结果x对应的label不符合,返回1,否则返回0。然后统计不同h的loss值,最小的就是最好的阈值

进入训练环节

训练结果
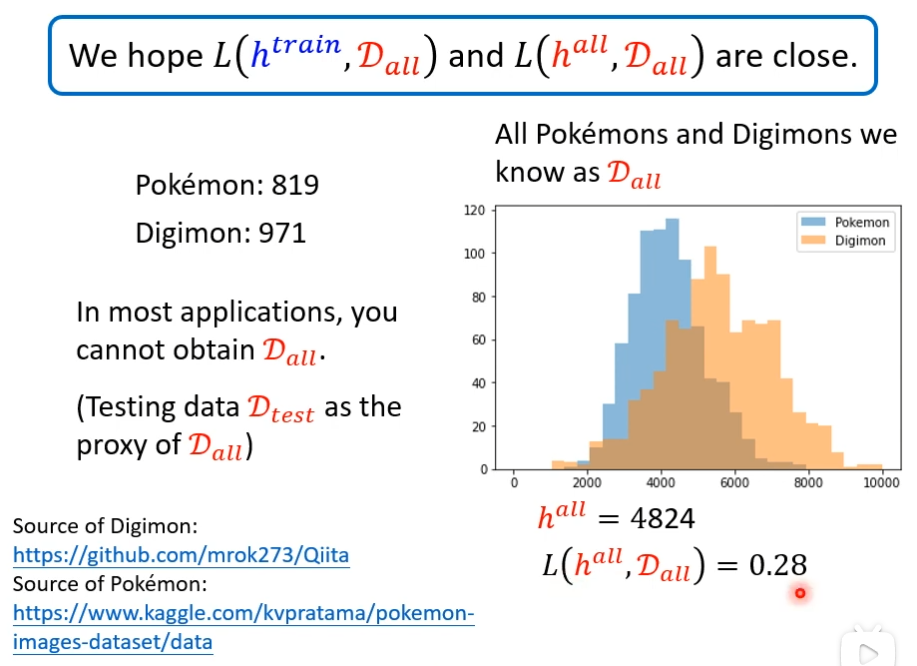
现实是我们获取不了所有的数据,我们抓取200只,当做Dtrain1发现找出来的阈值和loss值,比数据集中包括所有的差不了多少,但这只是运气好而已
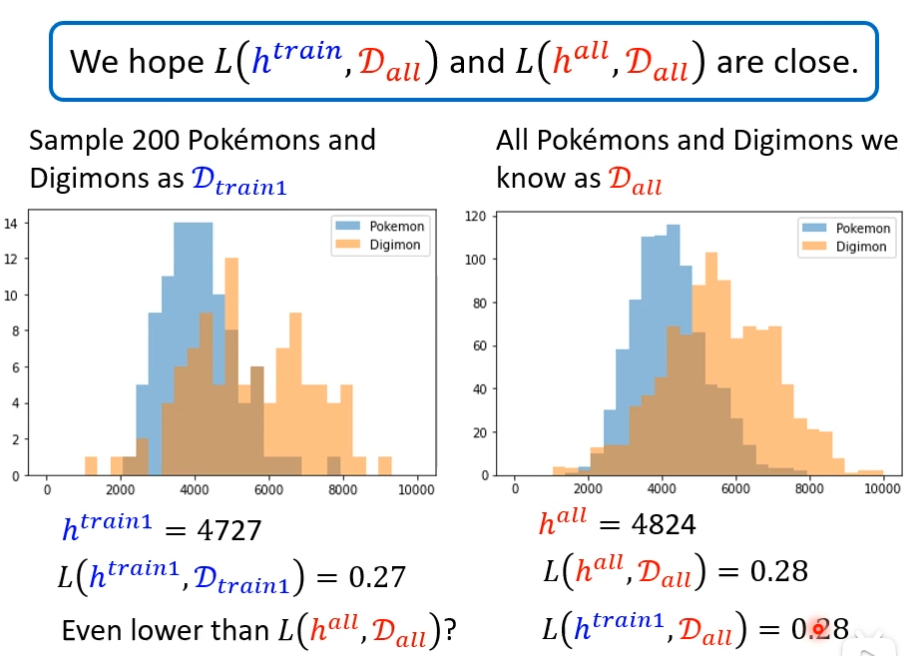
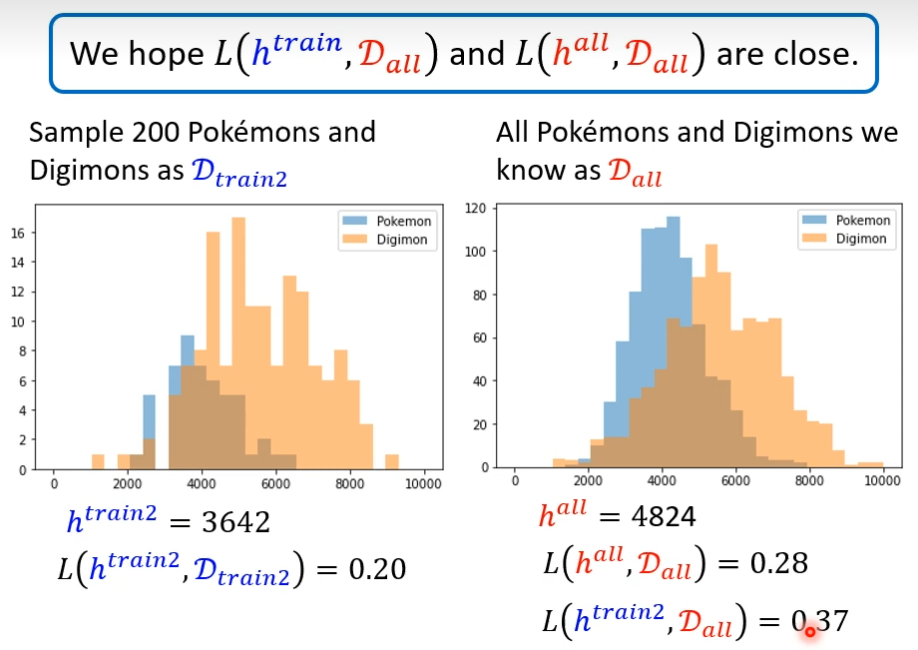
并不是任何时候运气都那么好,我们又随机抽200只,这时候和hall差距很大,把htrain用在Dall上准确率就比较差
我们希望的是,训练和所有样本的loss值小于某个值δ,这个δ由你决定,如果满足第二个蓝色方框的公式,那么理想和现实就比较接近,公式的含义是穷举所有的H,如果在训练上的loss-所有样本上的loss它们的差的绝对值,小于δ/2,

- 接下来的讨论和模型没有关系
- 我们不假设模型分布
- 可以使用任何loss函数
失败的概率(公式为|L(h,Dtrain) - L(h,Dall) | > ε),等于所有黄点,穷举所有的h,找出让Dtrain差的h,然后让这些h并起来,就是Dtrain差的概率,会小于让Dtrain差的h的累加
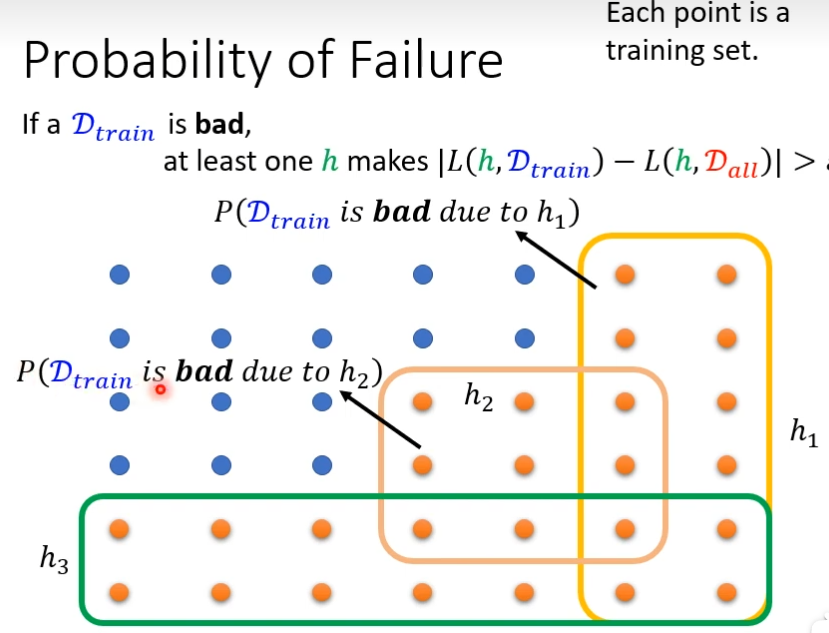
Dtrain是从Dall里面sample出来的部分数据集

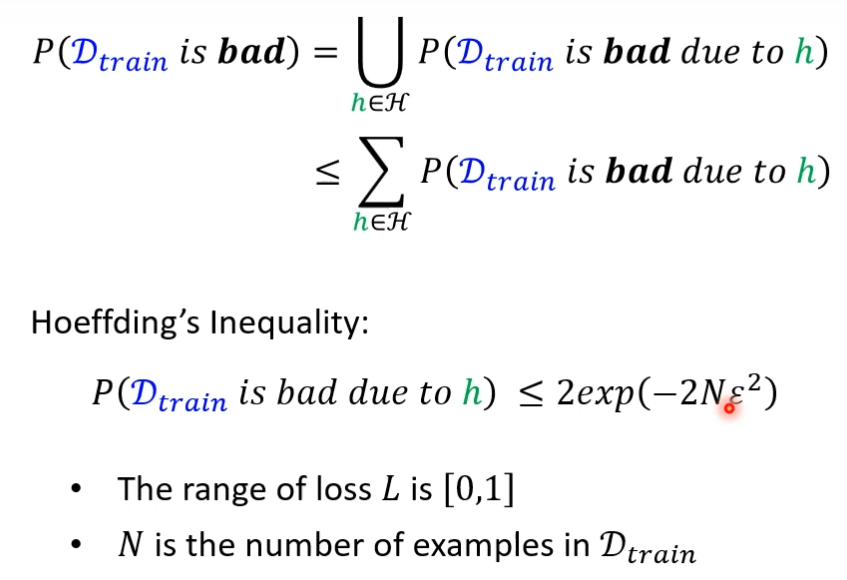
霍夫丁不等式
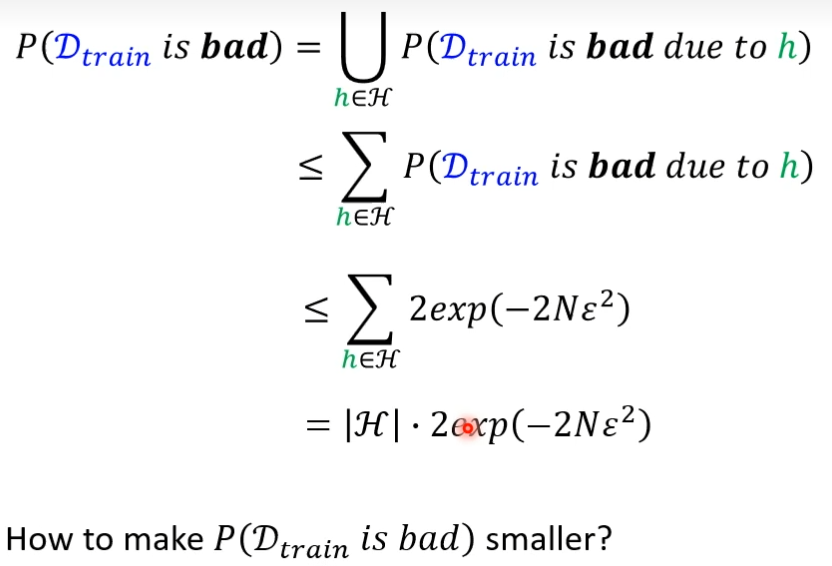
如何让Dtrain是坏的概率更小了?
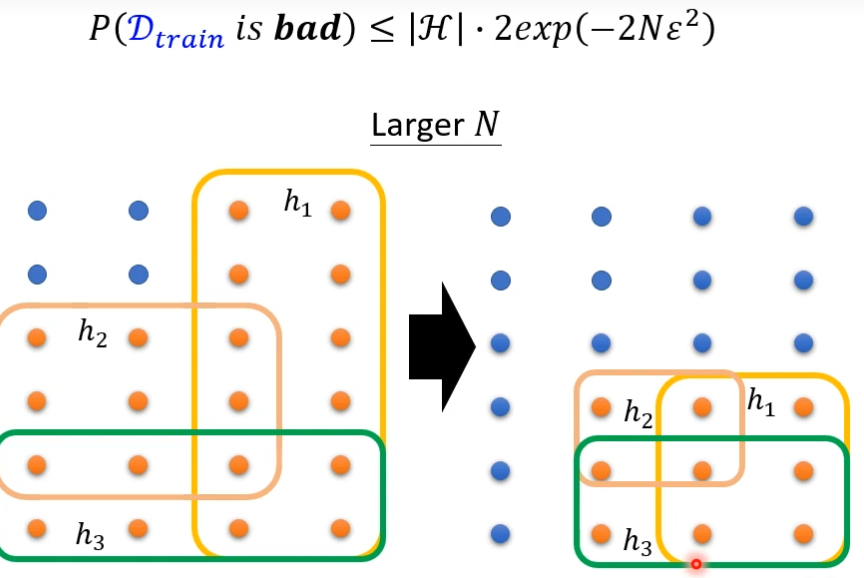
通过霍夫丁公式,让N越大,被弄坏的概率就越小
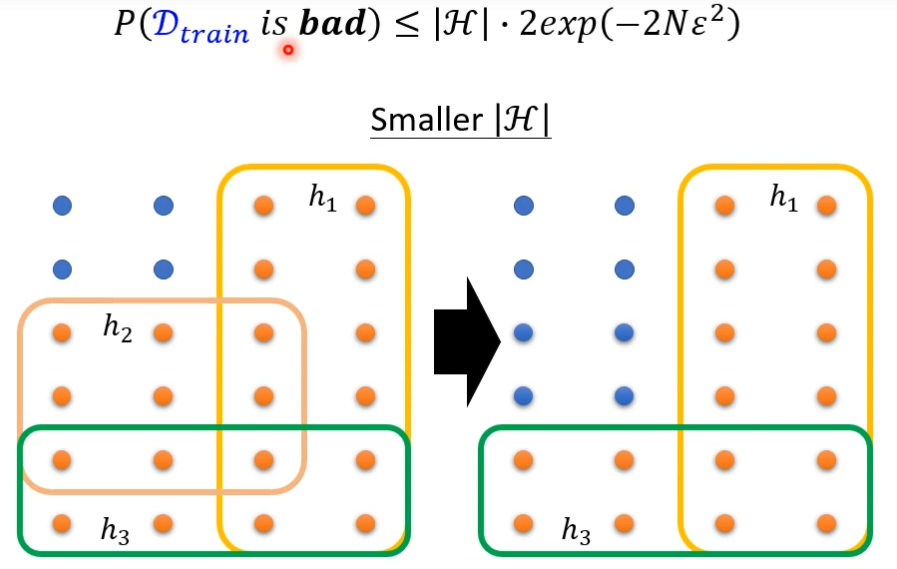
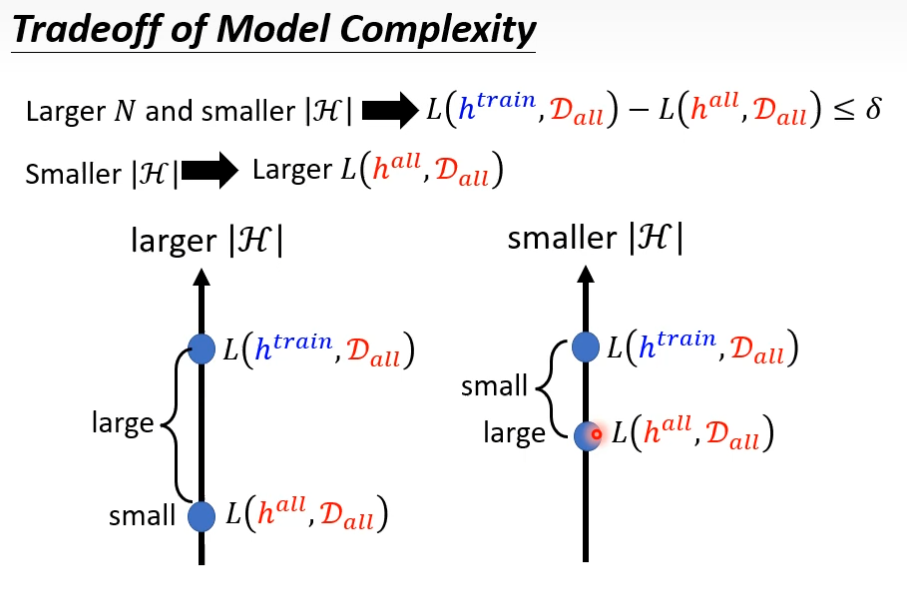
让|H|变小
前者是说,训练集中实例数多了,直观看,实例越多,越接近真实分布,自然不容易得到坏模型;后者是说模型变简单了,少了一些参数,自然得到坏模型的概率就小了。


|H|不能太小,太小可供选择的参数小,可能会让loss变大

我们知道,如果想让错误率低的话,要么增大N和减少|H|,但是N不能太大,那就去调小|H|,发现调小|H|,可能让Loss变大
卷积神经网络(CNN)
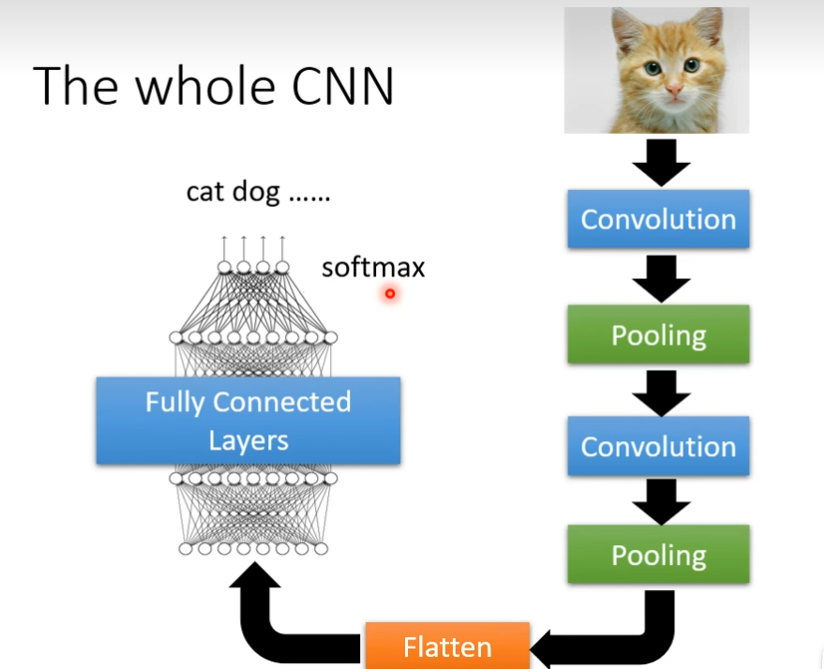
使用卷积对图像等数据作出处理,就是卷积神经网络,卷积神经网络的核心当然是卷积,经过卷积的后得到矩阵叫做feature map(特征图),不同的卷积核就可以找到各种各样的特征,对于CNN来说,训练就是让网络根据已有的数据和它们的标签,自动确定卷积核中的数值,CNN还有另外两个重要配件,池化层和全连接层,池化层能选取图像的主要特征,全连接层放在最后将提取到的特征集合在一起,给出图片是某种事物概率,CNN擅长处理图像,将声音当做图谱处理可以完成语音识别,将词语作为向量处理可以完成机器翻译
Image Classifcation
对于电脑来说一张图片由一个3纬度的Tensor组成,tensor就是纬度大于2的矩阵,3个纬度分别是宽,高,channels数目(rgb是3,png是4),接下来我们要把一个三维的Tensor,把它拉直

把这个向量作为输入,k的个数为100×100×3,neuron有1000个,一共有1000×1000×1000×3个weight,数目很大,参数越多,我们可以增加模型的弹性,模型的能力,也增加了overfitting,
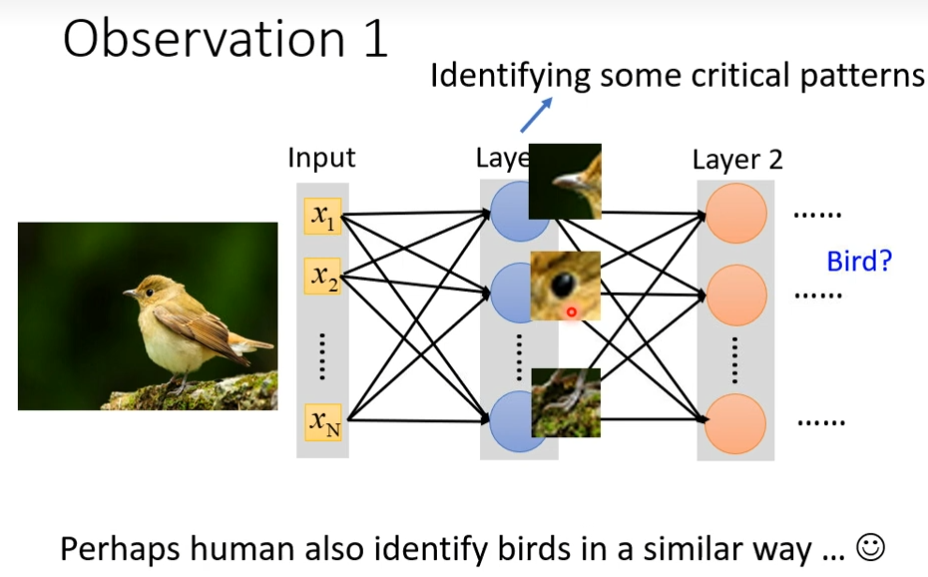
观察1
假设我们想要判断一个动物,对于neuron来说,它要做的就是看这个图片里面,有没有一些关键的pattern,这个pattern是代表某种物件的,比如说某个neuron看到鸟嘴这个pattern,某个neuron看到眼睛这个pattern,某个neuron看到脚这个pattern,看到这些pattern综合起来说我们看到了一只鸟
其实就是判断现在有没有某个pattern出现,我们并不需要每一个neuron都去看一张完整的图片,而且这些pattern远比图片小。
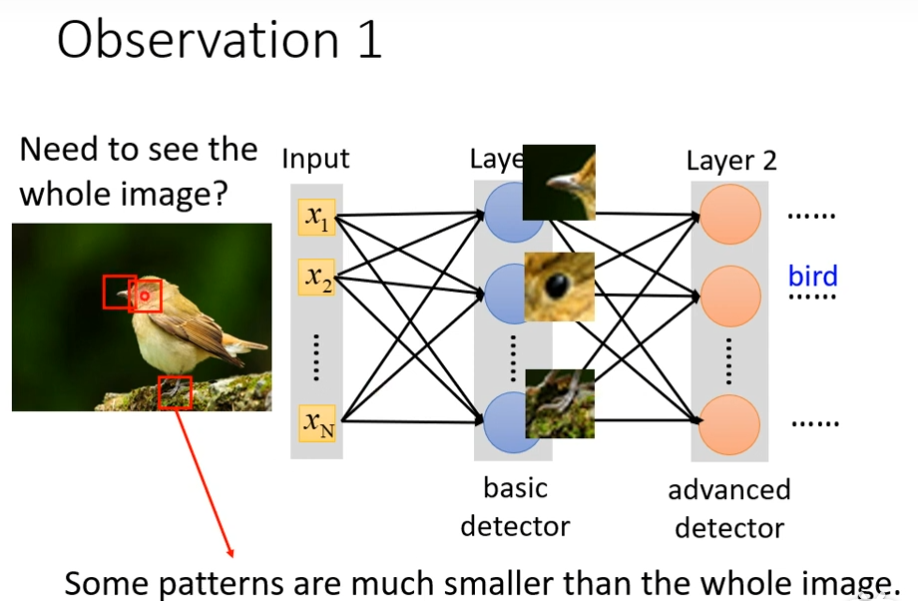
简化1
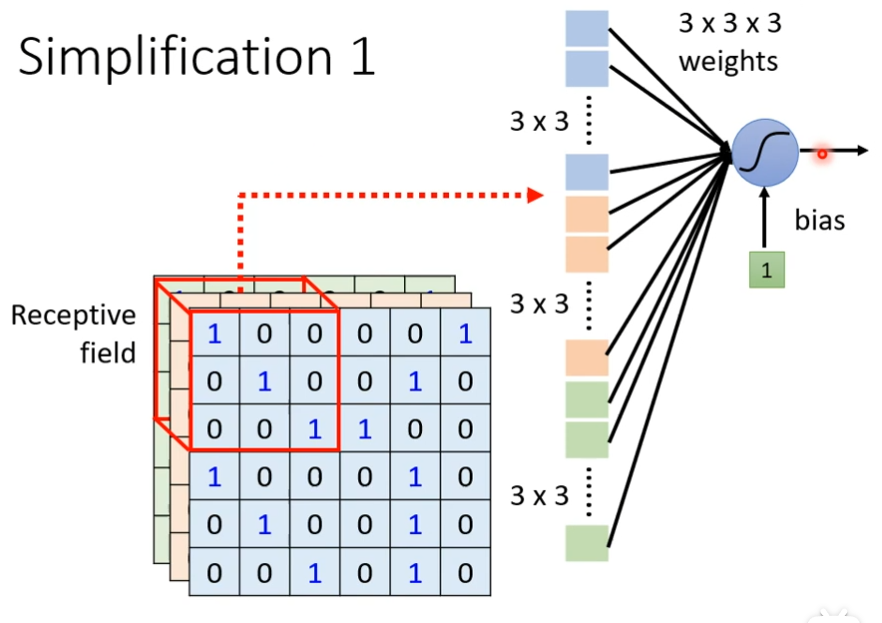
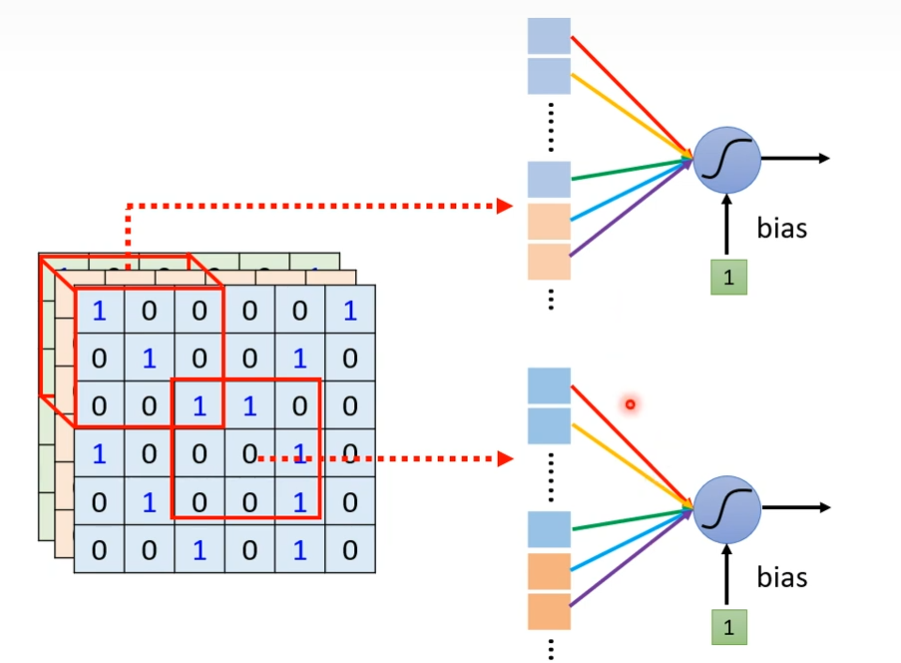
不需要把整张图片当做输入,只需要把图片的一小部分当做输入,就足以让它们侦测某些特别关键的pattern,我们可以进一步简化,本来neuron需要看完整的图片,如果把图片所有的信息都丢给一个neuron,这是full connect network做的事情,在CNN里面,我们会设定一个区域叫做Receptive Field,每一个neuron都只关心自己的Receptive Field,假设现在划分一个区域3×3×3,把这个区域化为27纬度的向量,作为neuron的输入,这个neuron有3×3×3 ,27个weight,再加上bias,输出后,作为下一层neuron的输入
receptive filed是可以重叠的,多个neuron可以看相同的receptive filed
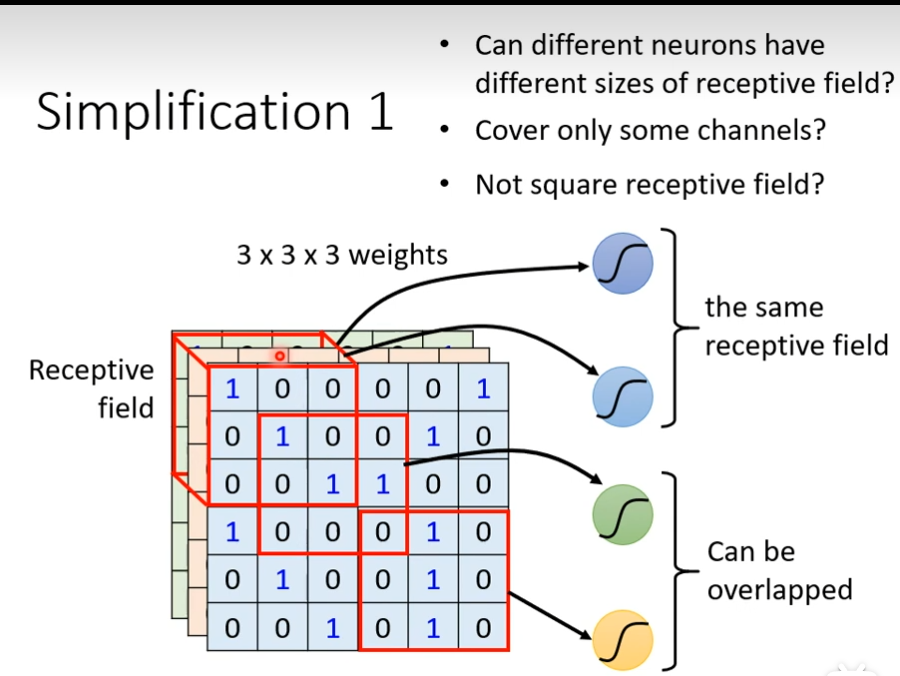
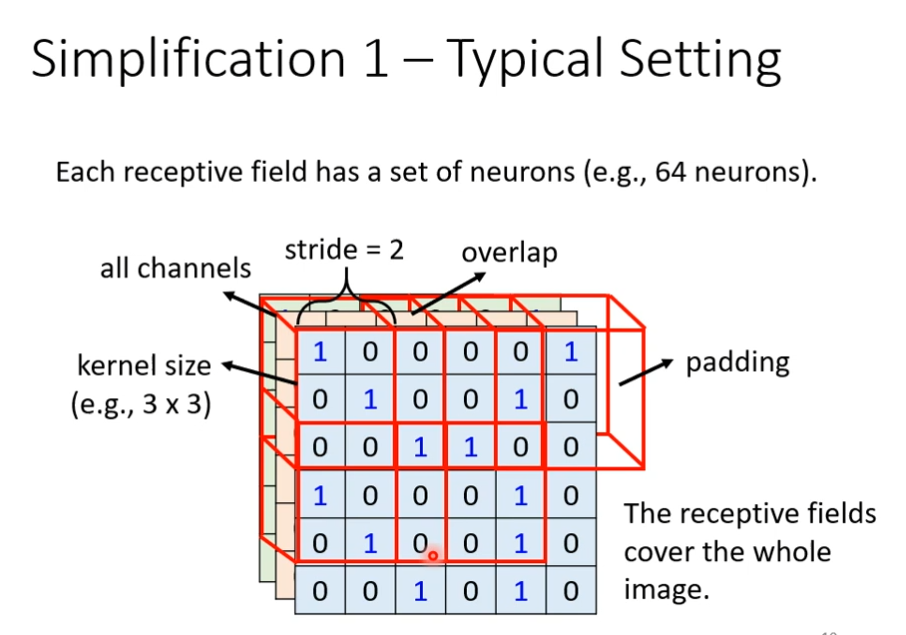
receptive filed 可以任意设计,最经典的安排方式是会看所有的channel,既然会看全部的channel,我们描述一个receptive filed的时候,就只需要关注高度和宽度,不用考虑深度,深度一定是考虑全部的channel,高和宽组合起来叫做kernel size,这里的kernel size 是3×3,一般我们的kernel size不会设定的太大,而且一个receptive filed不会只有一个neuron去观察它,往往会有一组或者一排,下一个receptive filed和上一个receptive filed之间的距离叫做stride,stride不会太大,因为你希望它们之间是有重叠的,因为有时候pattern会出现它们交界的位置上,如果receptive filed超出范围,你可以设置padding,让超出的范围里面都是0
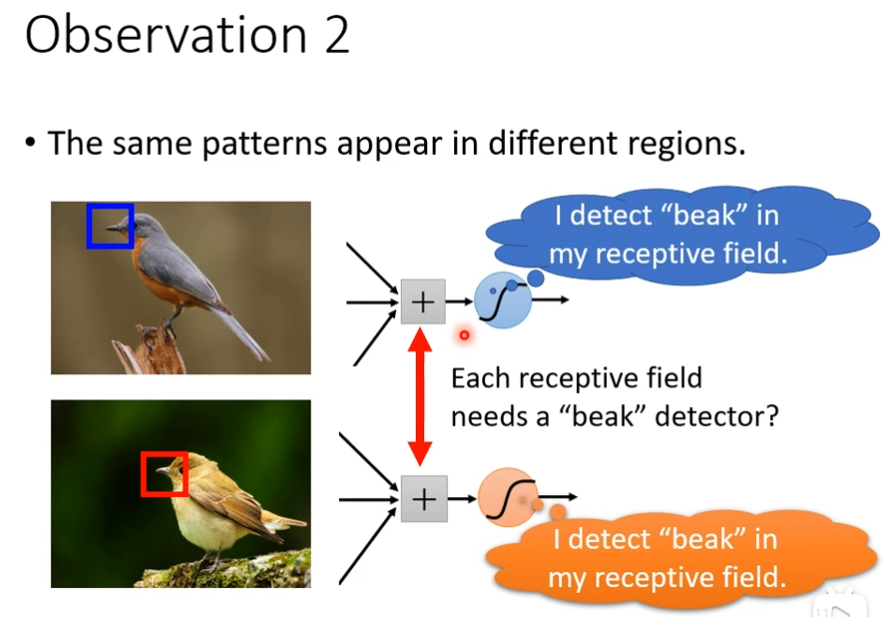
观察2
同样的pattern可能会出现在不同的区域里面,每一个neuron都有自己观察的receptive filed,如果某一个neuron负责观察鸟嘴,而它的receptive filed 里面没有鸟嘴,难道,我需要给其他的每一个neuron都加一个侦测鸟嘴的neuron吗?不需要,就好比工科生需要学高数,难道说要在每个不同的系,都派一个数学班吗?为什么不成立一个单独的数学班,让其共享,让所有的工科生一起来上高数课,放在影像上就是让不同的receptive field的neuron共享参数,如何实现一只猫或狗出现在图像的不同位置也能正常识别出来。正如我们之前所看到的,图像中某一个特定小块的分类结果是由这个小块对应的权重w和偏置b决定的。如果我们希望图片左上角小块中的猫与右下角小块中的猫被相同的分类方法分类,那么左上角的小块和右下角的小块的权重w和偏置b都一致,这样它们的分类结果就会相同,这就是参数共享。所谓的参数共享就是说,给一张输入图片,用一个filter去扫这张图,filter里 面的数就叫权重,这张图每个位置是被同样的filter扫的,所以权重是一样的, 也就是共享。
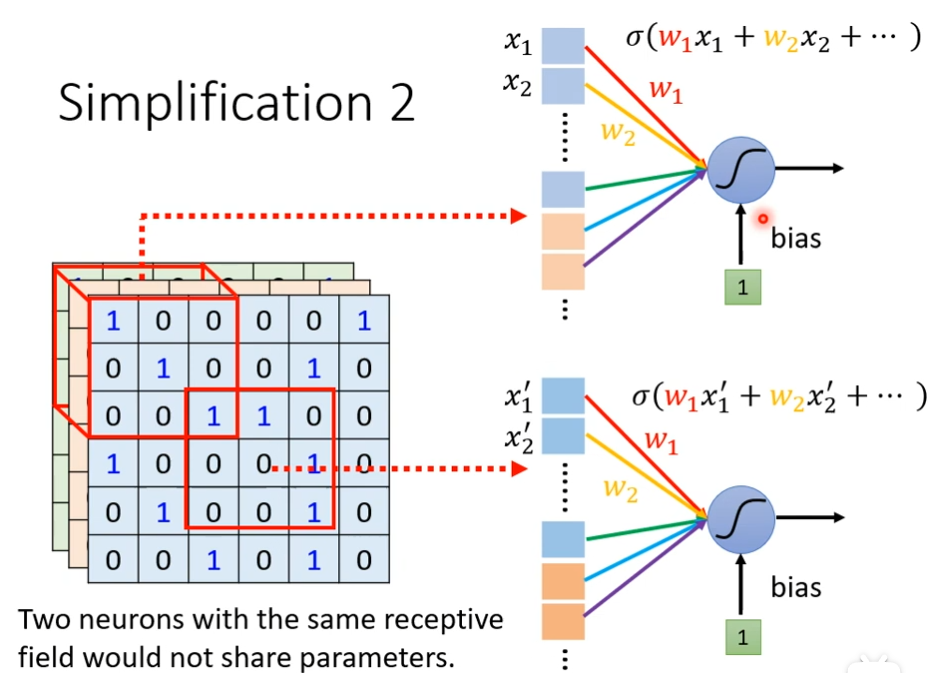
简化2(第一个版本)
我们可以让不同receptive filed的neuron它们共享参数,现在有两个neuron,它们的weight都是一样的,但是它们的输出不一样,因为它们的输入都不一样,因此你不会让两个观察区域一样的neuron共享参数,因为两个观察区域一样的neuron共享参数的话,它们的输出一定都固定会是一样的,如果两个neuron观察的区域不一样,就算它们参数一样,输出也不会是一样的,
常见的共享参数的方法
每一个receptive filed都有一组neuron去观察,假设现在的receptive filed有64个neuron,这边同样的颜色来代表说两个neuron共享一样的参数,每一个receptive都只有一组参数而已,这些参数叫做filter
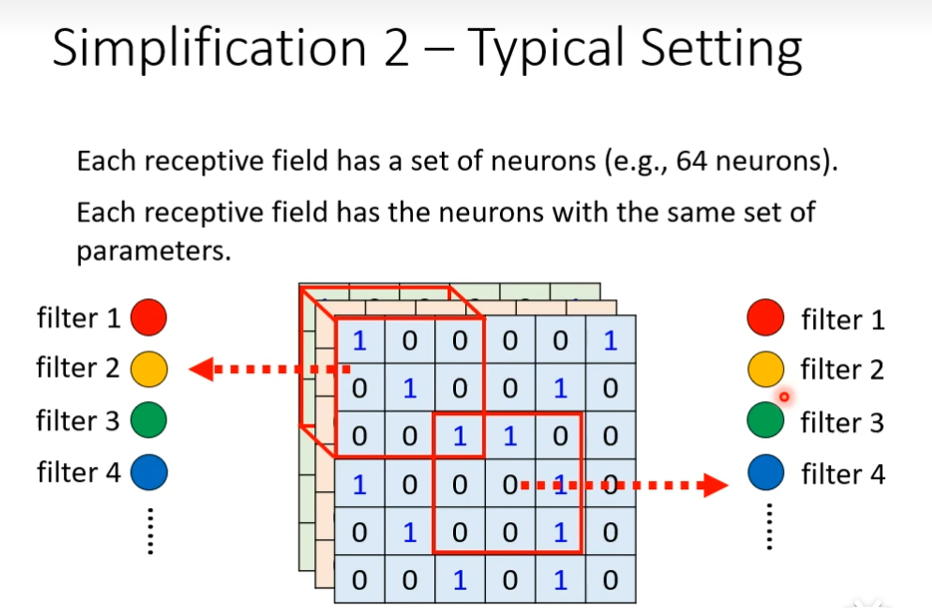
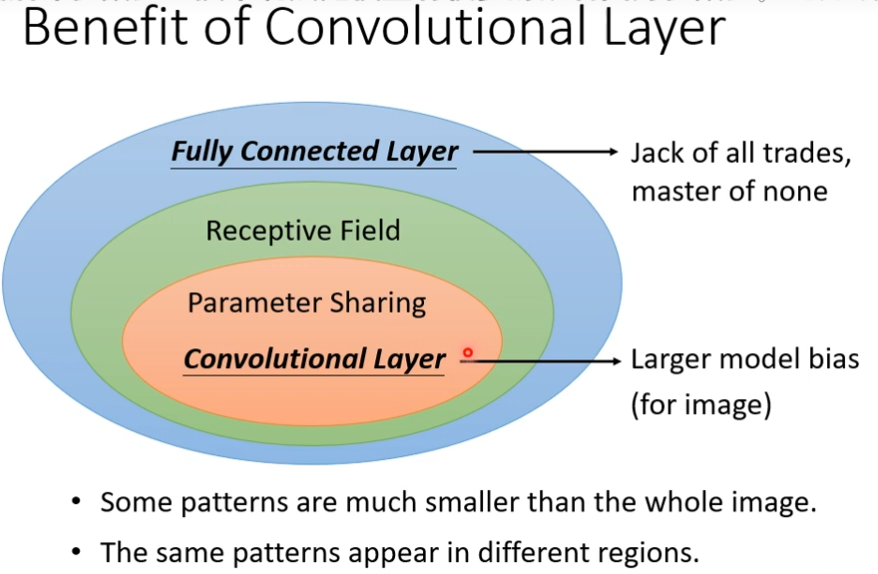
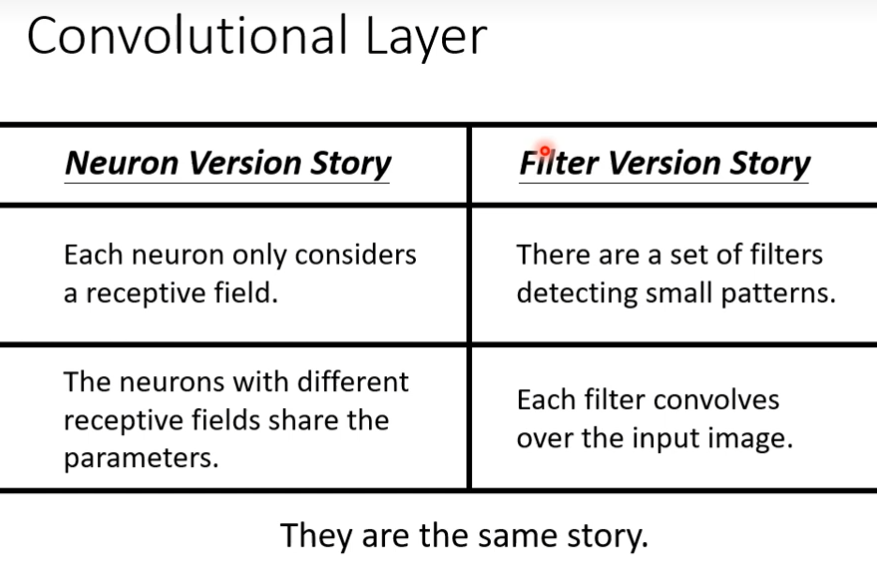
fully connected layer是最具有弹性的,有了receptive field它的弹性会被限制,在加上parameter sharing后,它的弹性会更加受到限制,在加上convolutional layer会更受限制,有用convolutional layer的network叫做convolutional neural network,其实CNN的bias比较大,model bias大不一定是坏事,因为model bias小的时候,model的flexibility很高的时候,它比较容器overfitting,CNN专门为影像设计的,
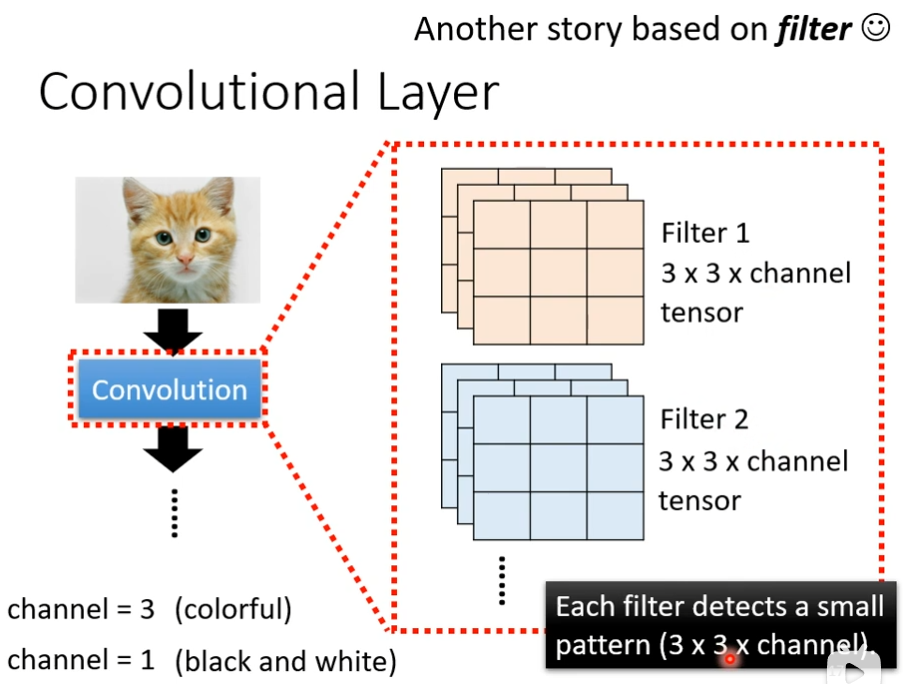
convolutional layer(第二个版本)
就是里面有很多filter,它们的大小是3×3×channel,channel是3,彩色图片,channel是1,黑白图片,每个filter的作用是抓取某一个pattern,假设这些filter的参数是已知的,是一个一个的tensor
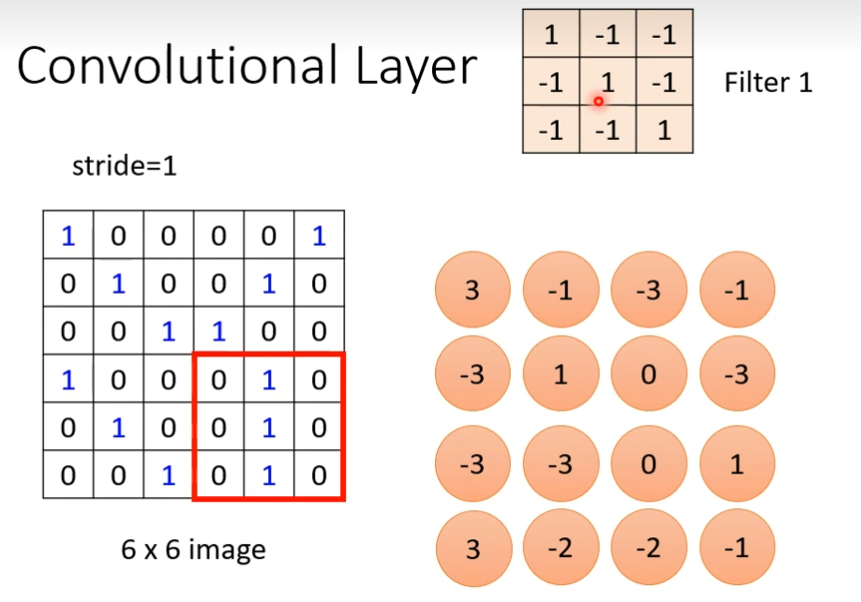
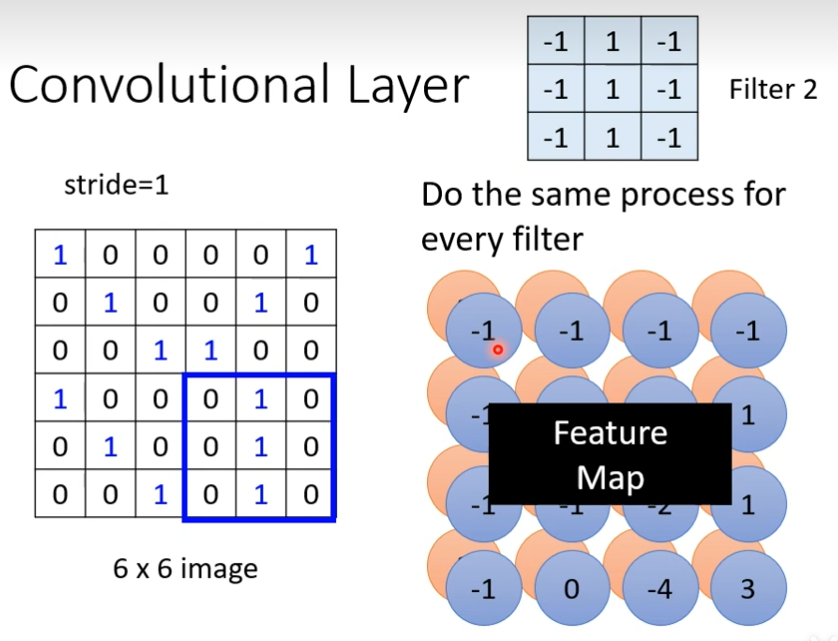
这个tensor里面的数值就是model里面的parameter,这些filter里面的数值,其实是未知的,是需要通过gradient descent找出来的,现在有一个6×6大小的图片,接下来用filter1和这个图片进行inner product,计算后,怎么说filter侦测pattern呢?看这个filter里面对角线的地方都是1,看到image对角线都是1的时候,其数值是最大的,发现左上角和左下角的值最大,说明左上角出现pattern,左下角出现pattern
计算第二个filter,同样的步骤,把图片扫完,我们得到一组数字,每个filter都会给我们一群数字,如果我们有64个filter,我们就会有64群的数字了,这个群数字叫做feature map
当我把一张图片通过一个convolutional layer里面有一堆filter的时候,我们产生出来了一个feature map,假设这个convolutional layer里面有64个filter,产生出来的这个feature map有64组数字,这个feature map可以看做是一个新的图片,只不过这个channel不是grb的channel,它有64个,本来一个图片有3个channel,通过convolutional后,channel数变为64个,这个convolutional layer可以叠很多层的,如果叠第二层,第二层里面也有一堆filter,而这是其channel数目为64,因为第一层的输出后,其channel数是64,所以来到第二层的时候,这里的filter的channel必须是64(第一层channel数由图片的channel数决定),output的channel数,是input的channel数,
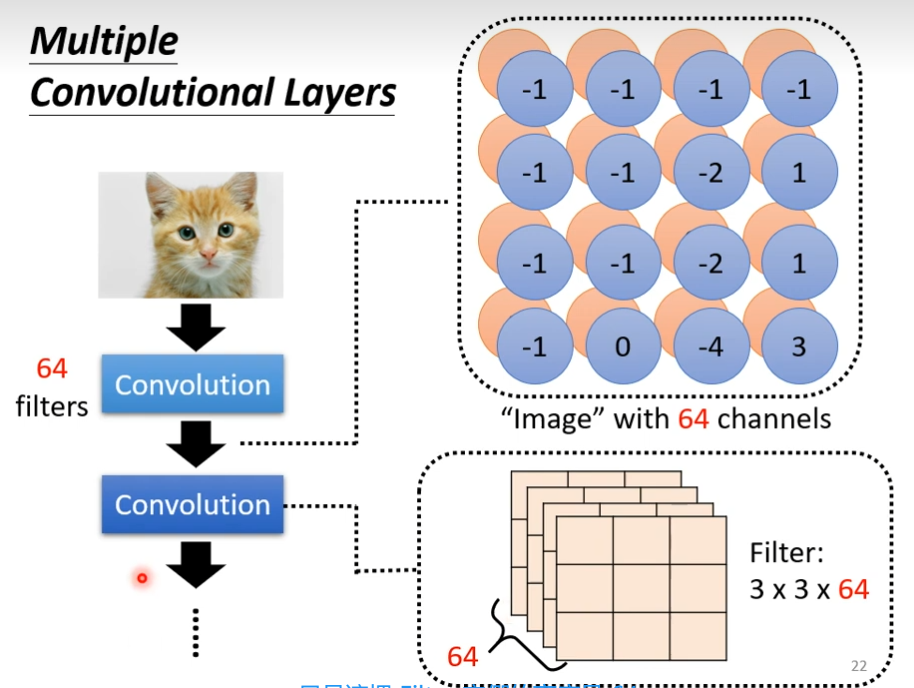
如果我们的filter大小一直设3×3,会不会让我们的network没有看到比较大的pattern呢?
答:不会,假设我们在第二层convolutional的filter大小一样设为3×3,我们现在看的是3×3,但是如果基于最初的图像,看的范围是5×5(因为经过计算后filter map的一个数值对应的是3×3,一行3个对应的就是一行5个),所以如果你的network越深,它还是可以侦测到比较大的pattern
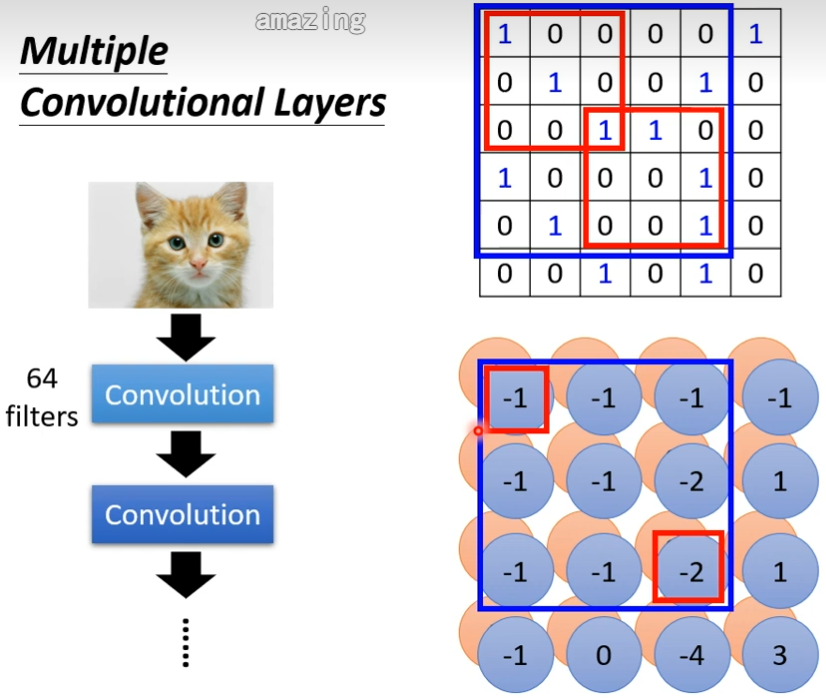
这个两个版本是一样的,第一个版本(简化2)说有些neuron会共用参数,这些共用的参数就是第二个版本的里面filter,两边都是3×3×3个数字
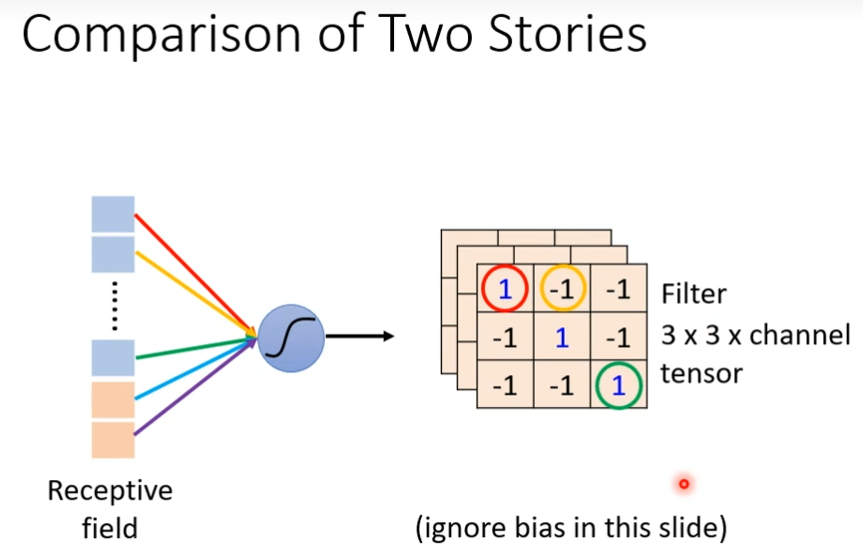
不同的neuron可以share weight,然后观察不同的区域,其实我们把filter扫过一张图片叫做convolution,所谓的把filter扫过图片这件事情,其实就是不同的receptive field 的 neuron可以共用参数(因为进行卷积计算的时候,卷积的是同一个矩阵)
观察3
最大池化 ,把一个矩阵,分成若干个组,只挑选组里面最大的值,往往我们做完convolution以后,会搭配pooling,让图片变小,可以减少计算量
如何用CNN来下围棋呢?
答:输入是棋盘上黑白子的位置,输出是下一步走的位置,输入一个向量,怎么把棋盘表示成一个向量了,创建一个19×19的向量,1是黑子,-1是白字,0是没有。把这个向量输入到网络里面,就可以把下围棋当做一个分类的问题,让这个network去预测,可以用fully connected network解决,但是用cnn的效果更好,把棋盘看做一个19×19的图片,48个channel(别人设计的)
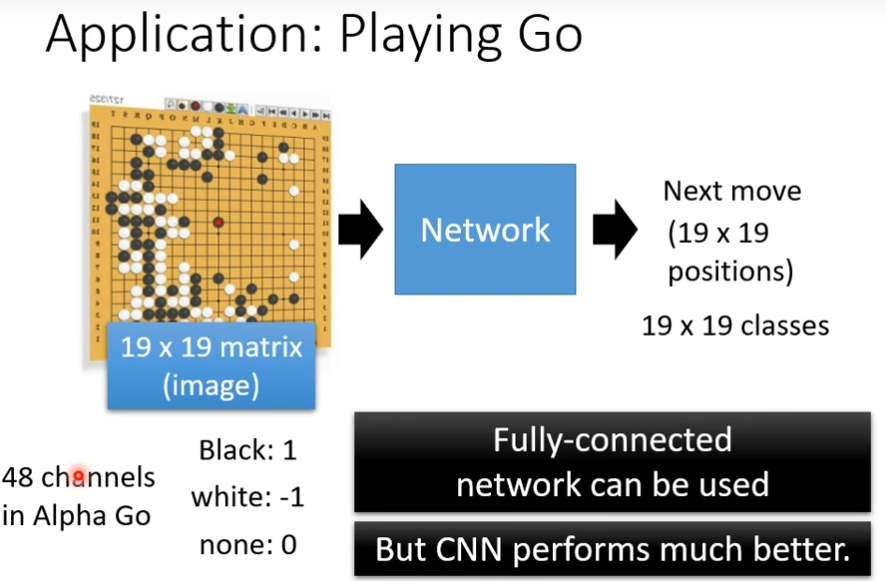
为什么下围棋要用CNN呢?
答:它和图片一样,可以关注个pattern,这里的第一层filter的大小就是5×5,第二个就是“叫吃”这个pattern可以出现在棋盘的任何一个位置,不适合用pooling
CNN并不能处理旋转放大缩小,因为放大和缩小后的张量都不一样,虽然人可以判断,但是机器不行,所以做图像的时候,需要做data augmentation
自注意力机制(self-attention)
attention
在seq2seq的基础结构上,生成每个单词都有意识的从原始句子中提取生成该单词时最需要的信息,摆脱了输入序列的长度限制,RNN需要逐个看完句子中的单词才能给出输出
self-attention会首先生成每个单词的意思,在依据生成的顺序选取所需的信息,这样的结构不仅支持并行计算效率更高,更接近人类的翻译方式
如果输入一个向量那好办,但是如果输入是一系列向量,且长度会变咋弄呢?有了自注意机制,输入可以不受限制
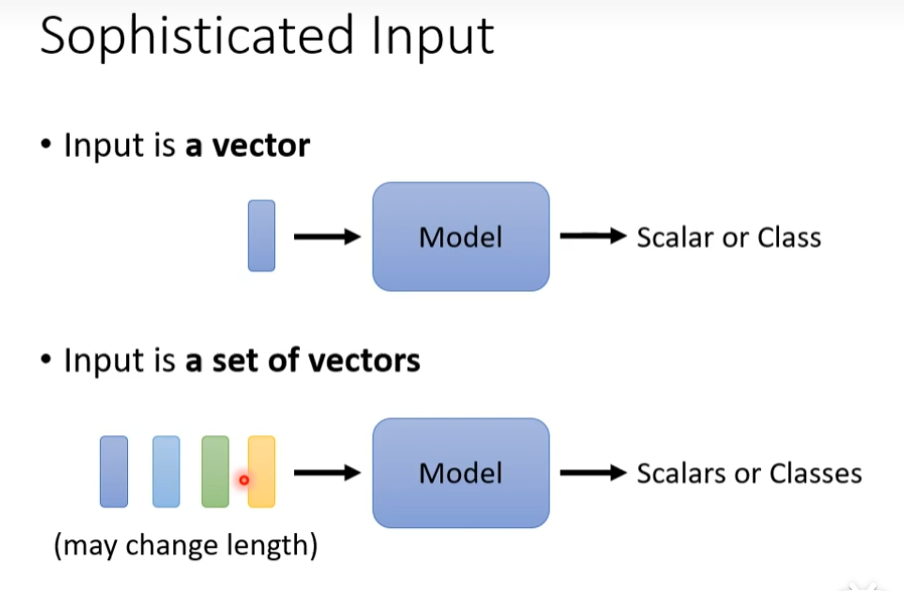
假如现在有一段话“this is a cat"如果把这句话当做输入了
- 第一种,一个单词一个向量,世界上有多少个单词,向量的长度是多少,这种情况不考虑单词之间的联系
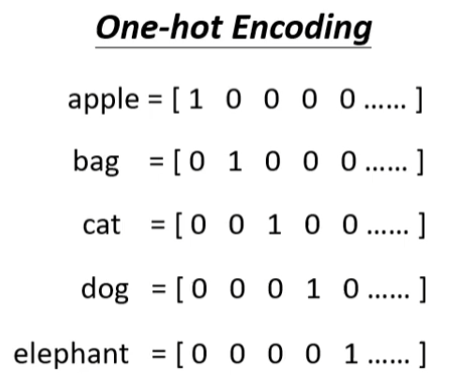
- 第二种,word embedding,给每一次词汇一个向量,而这个向量有语义的资讯
除了一段文字,以后输入也是一堆向量(vector set as input)的例子
- 声音
- 图片
输出的可能性
- 每一个,输出都有一个label,比如每个单词,是动词,还是名词
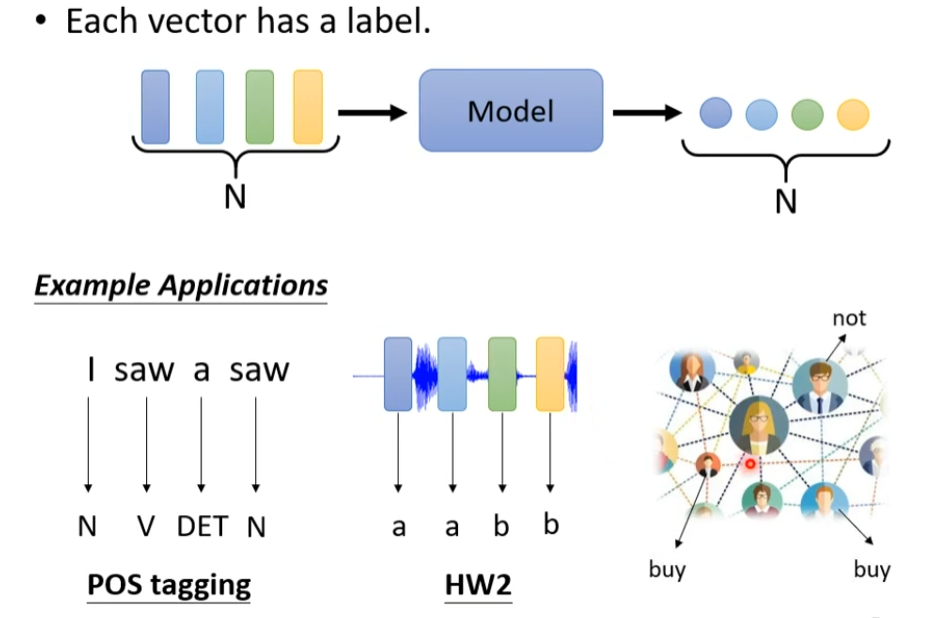
- 整个sequence是一个label,比如说一句话,是正向的,还不是不良的
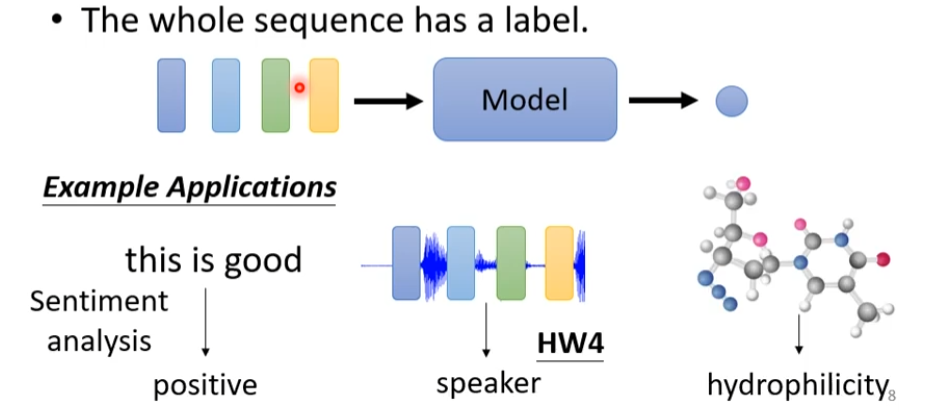
- 不知道输出多少,由机器来决定
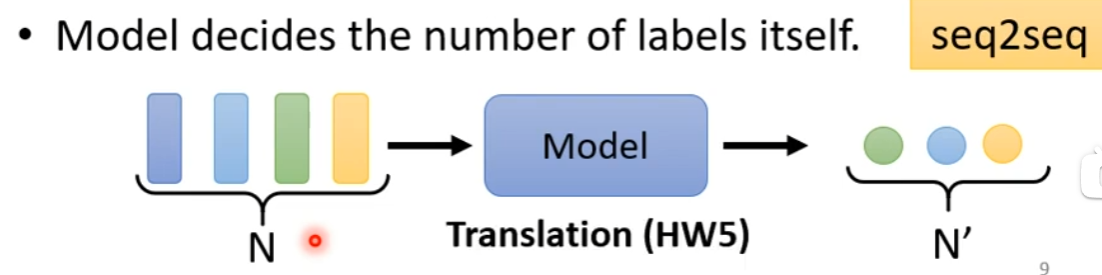
sequence labeling
每一个向量都有一个label,但是假如现在这里有一段话“ i saw a saw",机器无法分辨最后一个saw是名词,这时候需要考虑到上下文。我们可以用window来包括一个范围,机器可以根据这个范围,知道词的词性,但是这个sequence是变长的,不好化,有没有好的方法来input咨询了?用self-attention,self-attention会吃一整个sequence进去,然后input几个vector就输出几个vector,这个vector是考虑一整个sequence得到的(FC,指的是全连接)
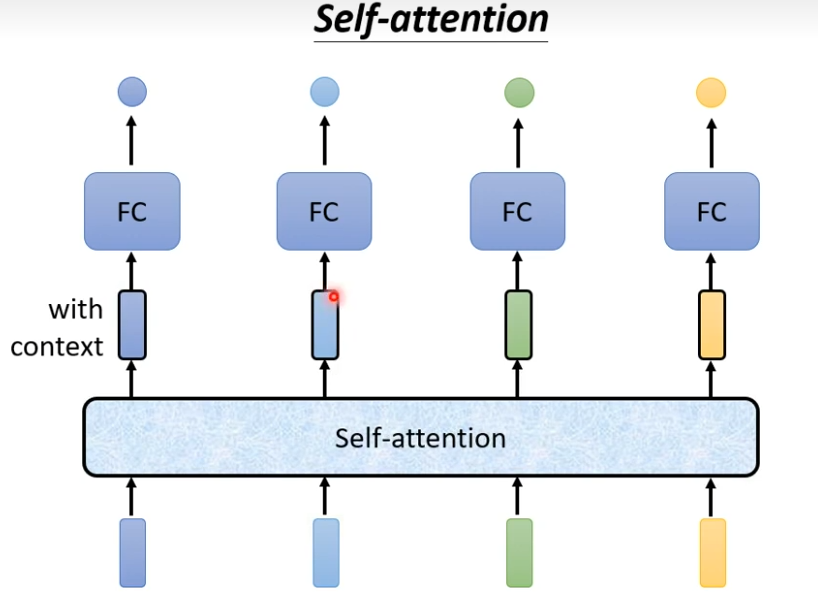
就像下图,b是考虑了所有的a才得出来的
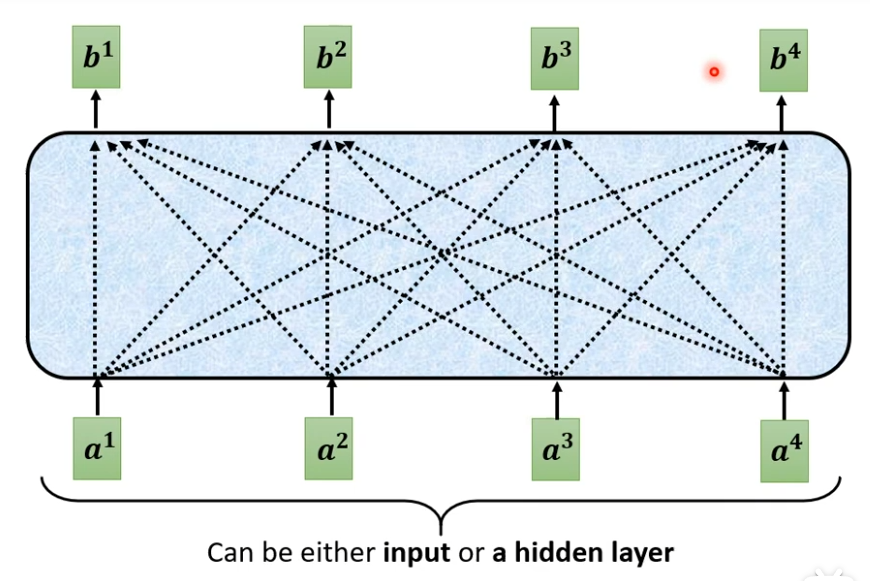
怎样产生b1这个向量?
- 找出这个sequence里面跟a相关的其它向量,每个关联的程度用一个数值α来表示
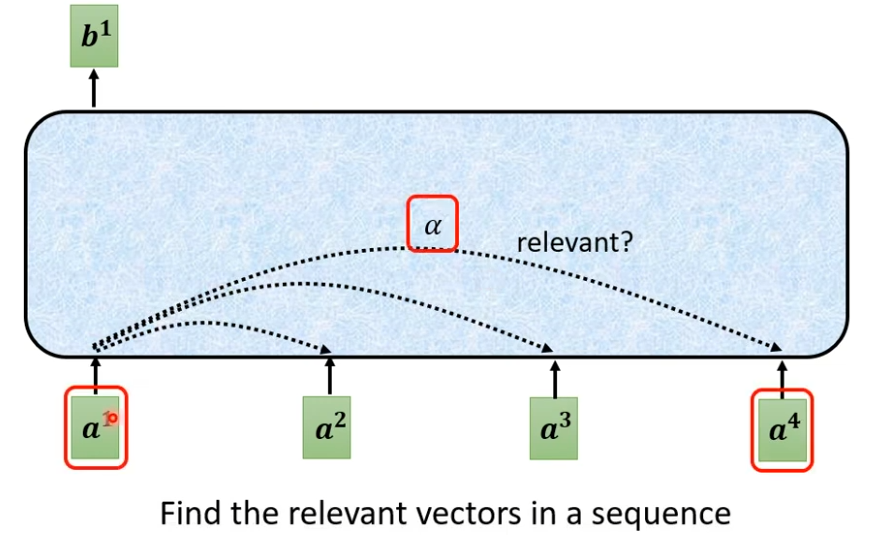
-
怎样决定a1和a4有多相关了,这里需要一个计算attention的模组,输入两个向量,输出关联的程度
-
dot-product(最常用的)
输入的向量,分别乘不同的矩阵,得到q和k这两个向量,这两个向量进行点乘得到α
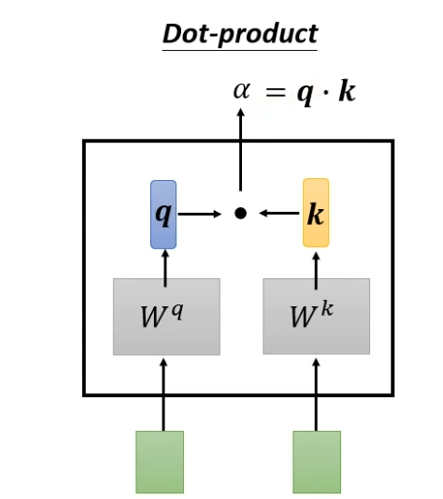
-
additive
输入的向量,分别乘不同的矩阵,得到的矩阵,串起来,然后经过tanh,再经过一个transform就得到了
-
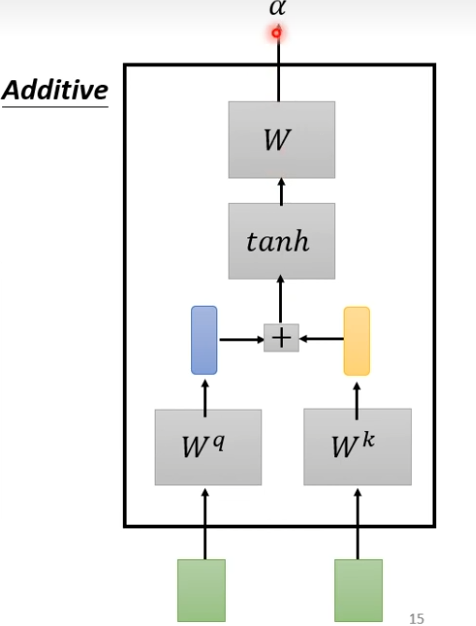
接下来分别计算a1,a2,a3,a4之间的关联性,这里并不一定要用softmax,也可以用其它的激活函数
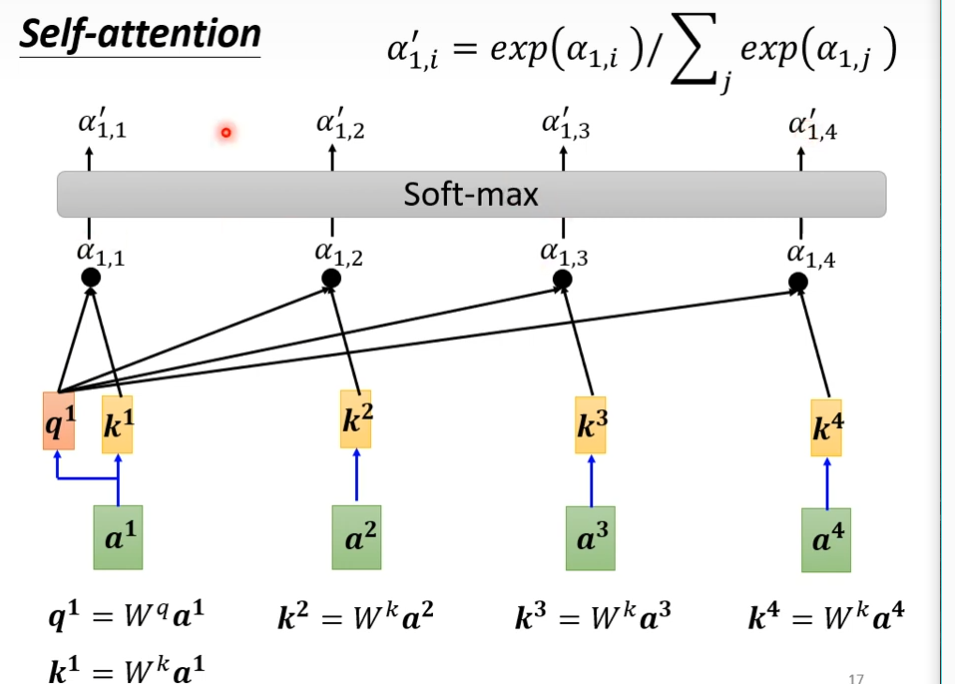
接下来,我们要根据这个α',去抽取这个sequence里面重要的咨询,根据这个α'我们已经知道哪些向量跟a1是最有关系的,接下来根据这个attention的分数来抽取重要的资讯,我们会把a1到a4这边每一个向量,乘上Wv(自己设的)得到新的向量,用v1,v2,v3,v4来表示,接下来每一个v都去乘上attention的分数(α'),然后加起来,得到b1,如果某个向量得到的分数越高,比如a1和a2的关联性很强,这个α'得到的值很大,那么这个b1就比较接近v2
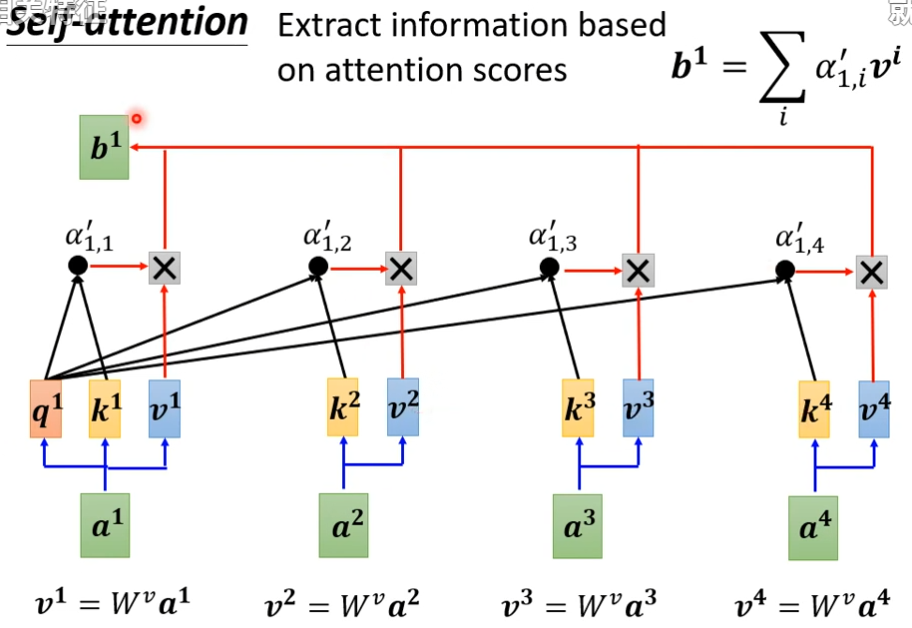
a1×wq=q1,a2×wq=q2,a3×wq=q3,a4×wq=q4,那么可以写成q1q2q3q4 = Wqa1a2a3a4,同理把k和v算出来
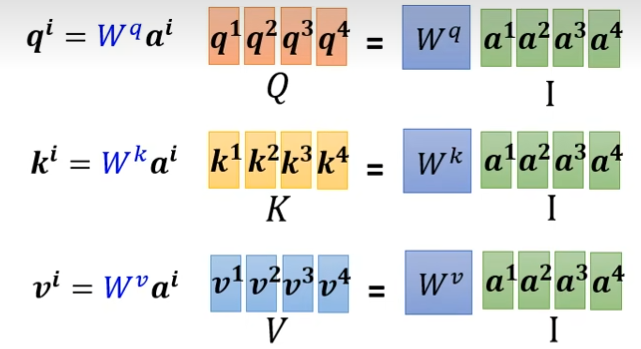
下面的k是转置后的,不转置算不出来值
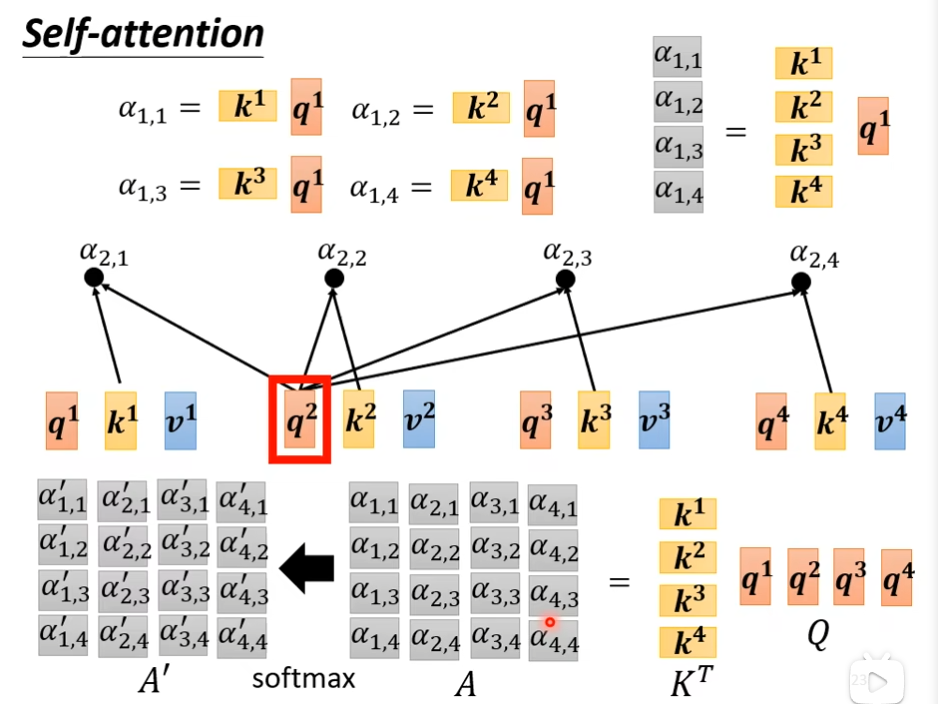
这里是a' 不是a^。这里的V不需要转置,这里的B=VA',是线性组合,还有就是向量要么是1×n(行向量),要么是n×1(列向量),这里的V是向量,不是实数
参考链接:向量组的线性组合 – 四都教育 (sudoedu.com)
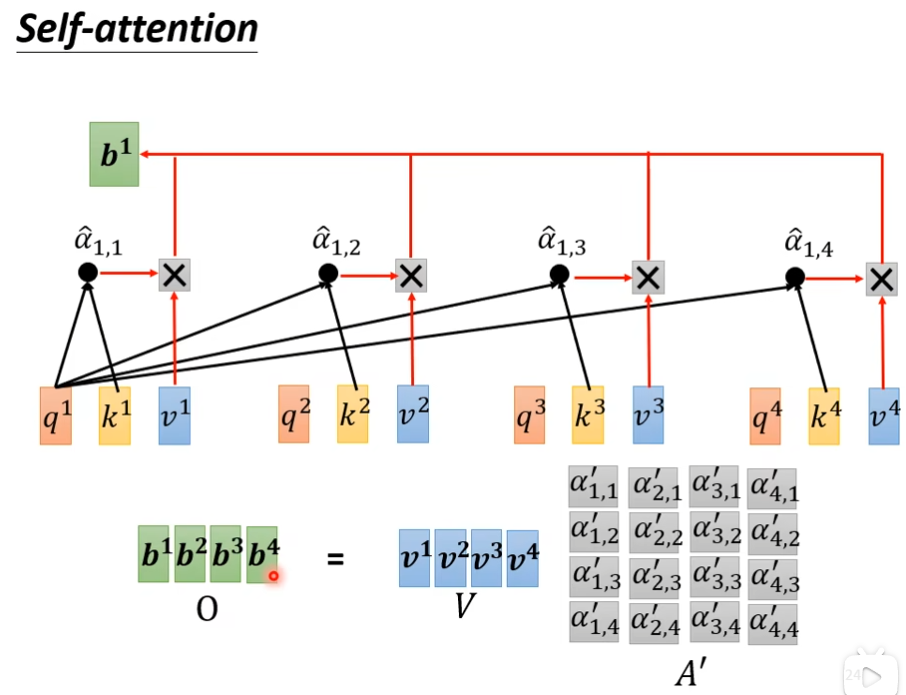
这里只有wp,wk,wv是未知的,是通过train data找出来的,其他的都是已知参数
Multi-head Self-attention
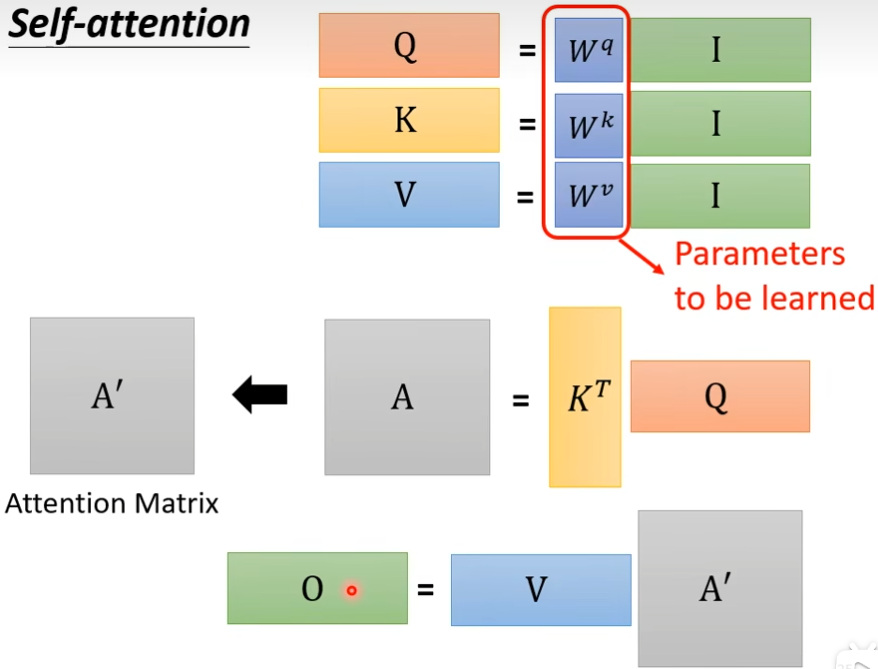
并不是所有的任务都适合用比较少的head,有一些任务,比如说翻译,语音识别用的head比较多,为什么我们需要比较多的head呢?我们在self-attention时,是用q去找相关的k,但是相关这种事情有很多种不同的形式,我们不能只有一个q,要有多个q负责不同的,不同种类的相关性,这里以2个head为例,a×w后得到q,q再乘上另外两个矩阵分别得到q1,q2,可以来找两种不同的相关性,那么k和v都要有两个head,接下来是的1类的一起做,2类的一起做,例如qi,1只需要关注ki,1和kj,1和vi,1和vj,1就行了
下图是求bi,1
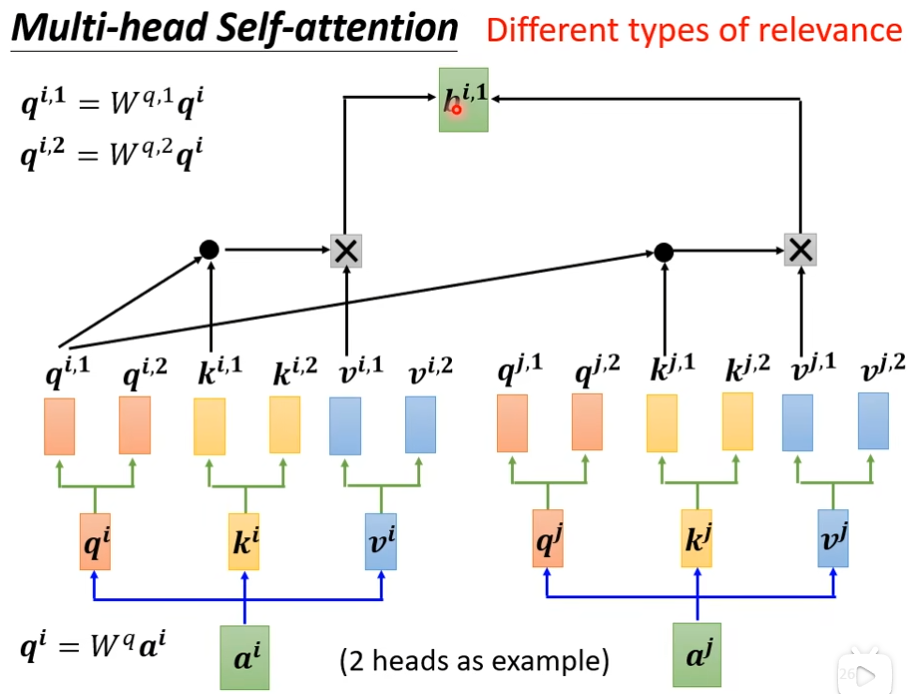
下图是求bi,2
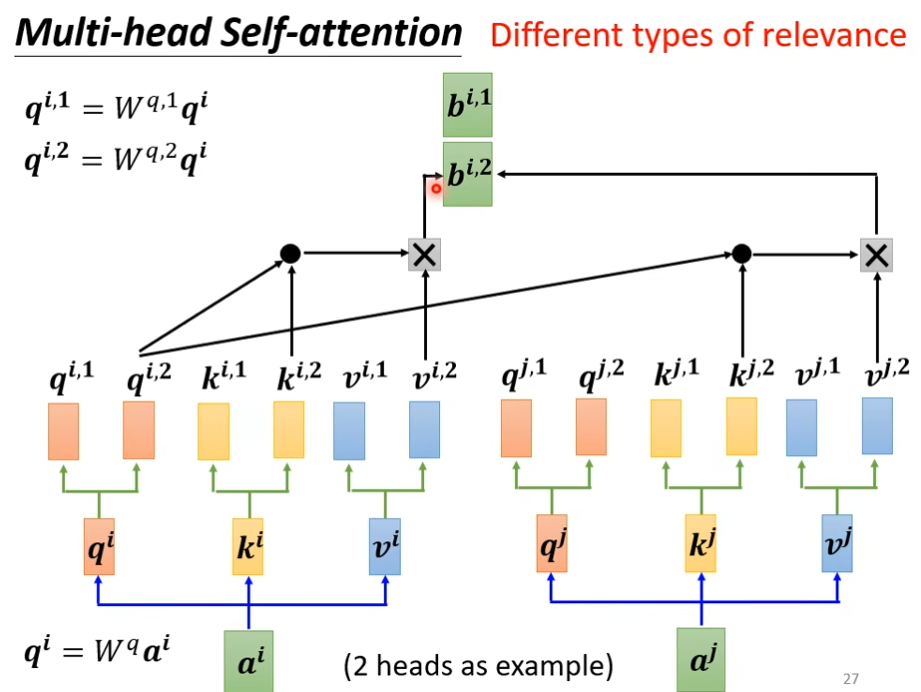
然后把bi,1,bi,2接起来,在通过一个transform得到bi

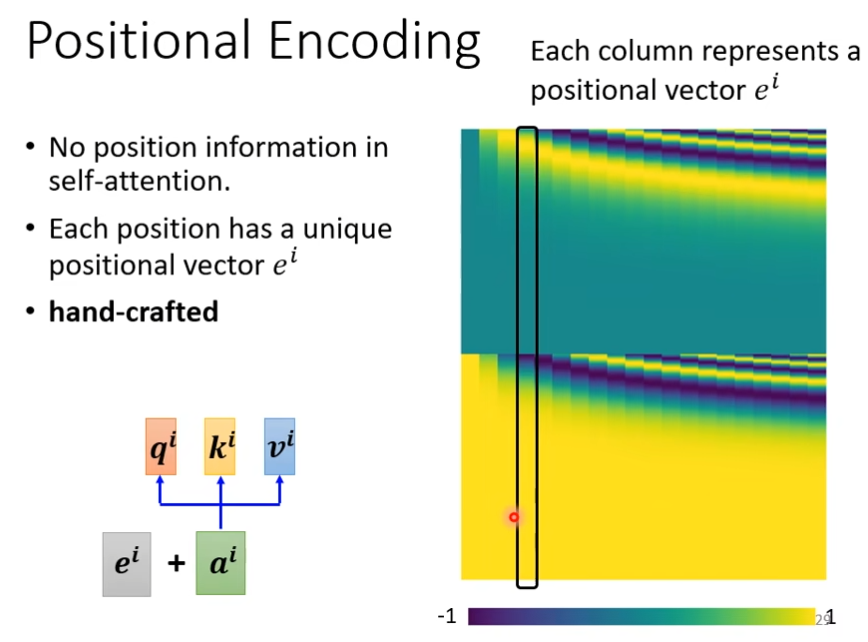
positional encoding
在处理一句话时候,你如果决定单词在这句话中所处的位置也很重要,就比如动词一般不出现在句首,这时候,为每一个位置设定一个vector,叫做positional vector用ei来表示,然后把这个ei加到ai上就可以了
Self-attention v.s. CNN
用self-attention来处理照片代表说,一个pixel产生query,其他pixel产生key,在做inner product(内积)的时候你考虑的不是一个小的范围间距,而是整张影响的资讯

Self-attention v.s. RNN
RNN只考虑前面的,不是并行的,运算速度上,self-attention会比RNN更有效率
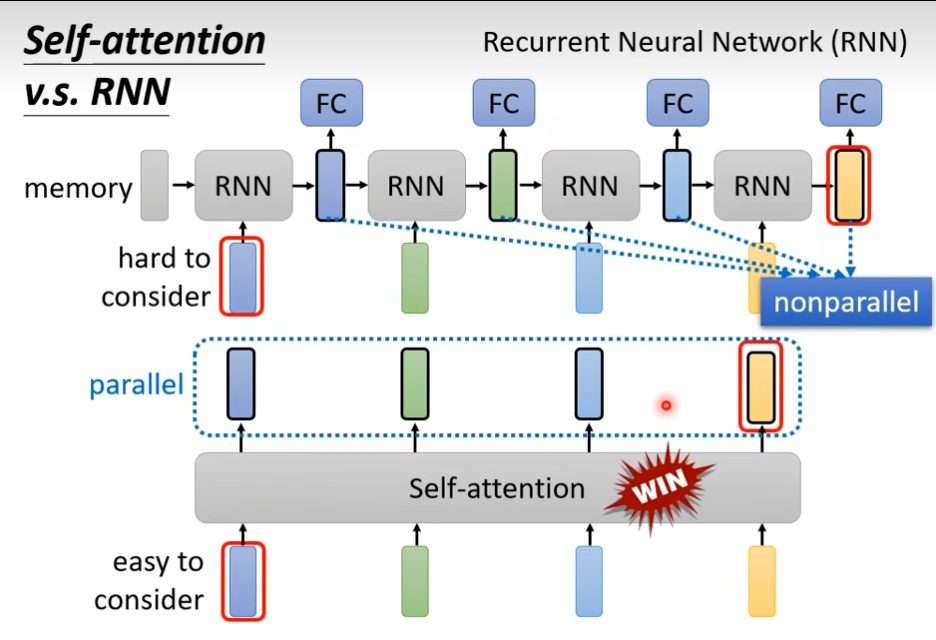
如果输入是一堆vector,那么就可以用self-attention来处理
Recurrent Neural Network
一个高度重视序列信息的网络,序列就是数据的前后关系,RNN的基础结构仍然是神经网络,只不过多一个记录数据输入时网络的状态,在下一次输出数据时,网络必须考虑这其中保存的信息,随着数据的一次次输入,存储信息也在不断的更新,存储的信息被称为隐状态,RNN最常用的领域是NLP,有个缺陷是数据输入的越早,在隐状态中的占据的影响就越小,也就是输入的越多,RNN就会忘记最开始说了什么了,于是就有了改良版LSTM
应用样例
slot filling
一句话里面,有些单词属于某个slot里的部分
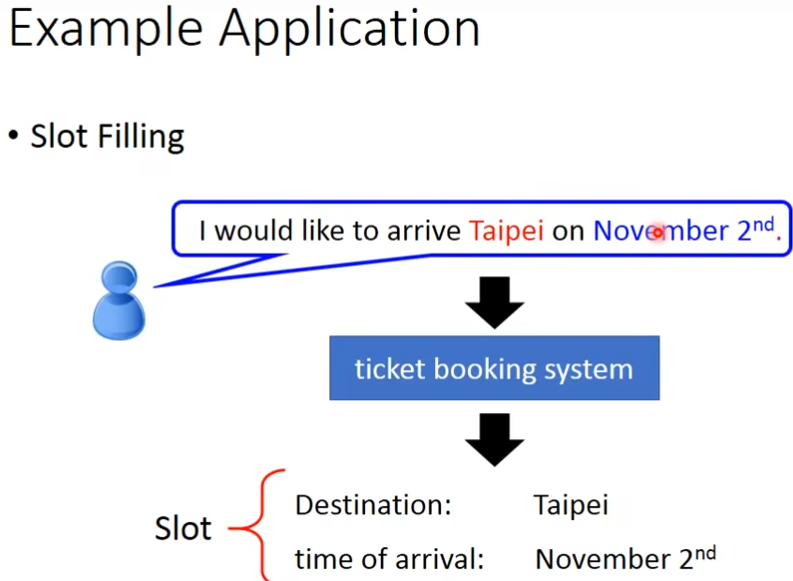
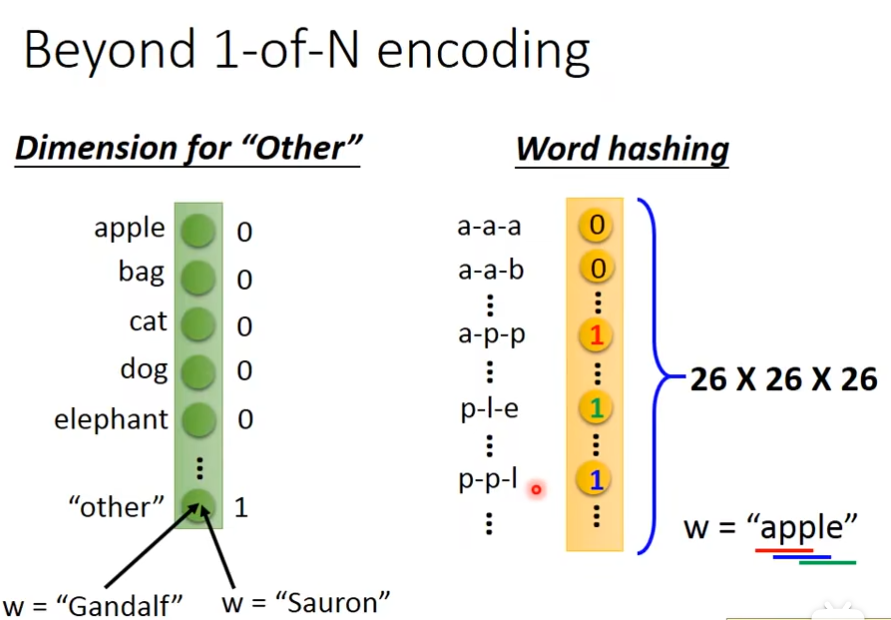
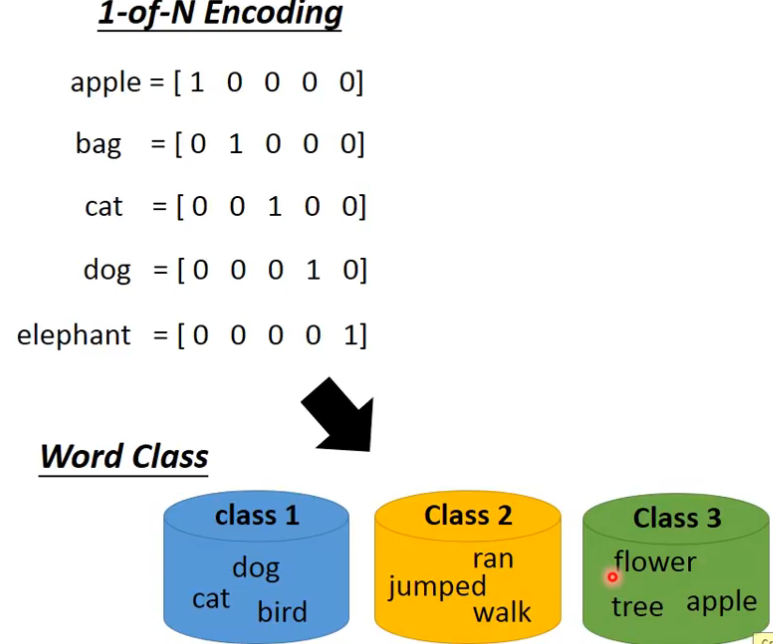
但是其他的词汇,就不属于任何slot里面,这个问题可以用feedforward,如果你要把一个词汇当做一个向量来表示,最常用的方法是1-of-N encoding,如果某个单词不在向量里面,可以增加一个“other”来表示这些词,还有一种方法就是word hashing
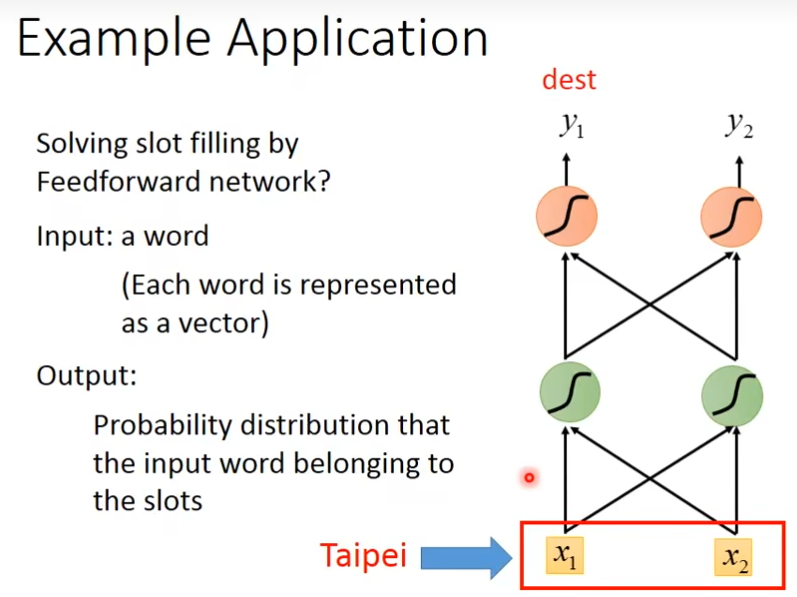
当我们把一个词变成vector后,丢到一个feedforward的network里面去,那在slot filling这个task里面,你就会希望你的output是一个probability distribution,这个probability distribution代表说我们现在input的这个单词属于哪一个slot的概率,比如说taibei属于destination还是属于time of arrival的概率
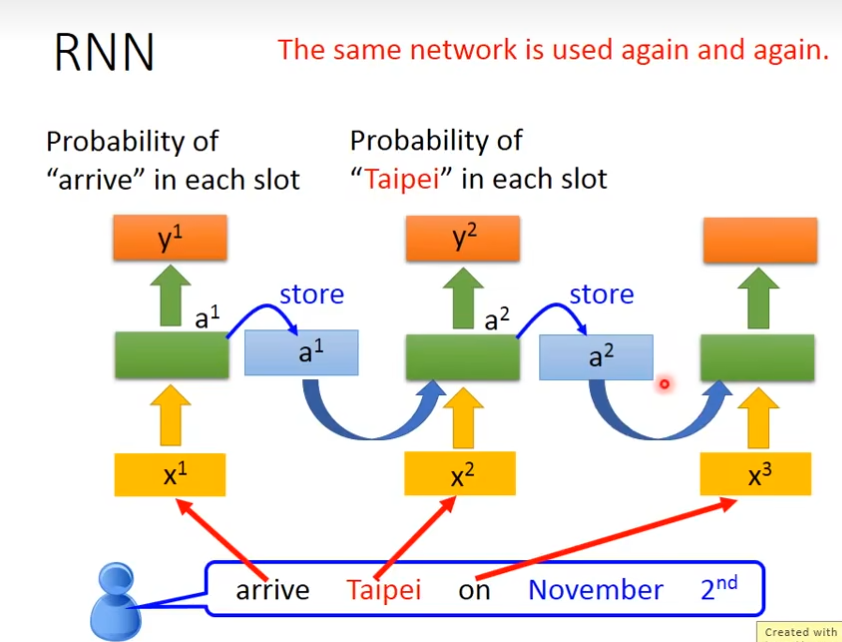
但是,光只有这个是不够的,feedforward network没有办法这个问题,假设,有一个使用者说了两句话,一个到达台北,一个是离开台北,这时候系统无法辨认出这个台北是出发地,还是目的地,这时候,我们希望这个neural network它是有记忆力的,它就可以根据这一段话的上下文,推断出这个台北是目的地,还是出发地,有记忆力的话,就可以解决input同样的词汇,但是output必须是不同的这个问题,这种有记忆力的network叫做recurrent neural network
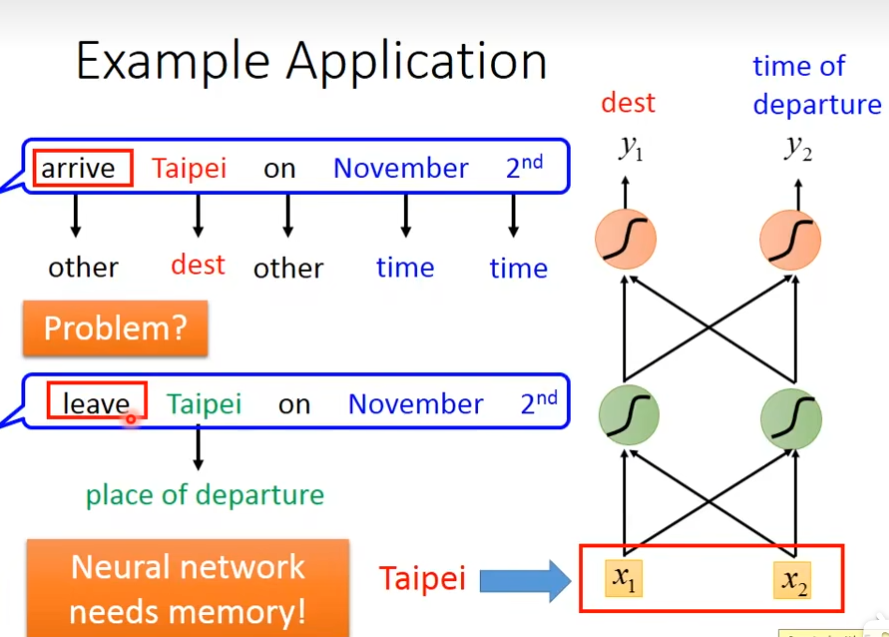
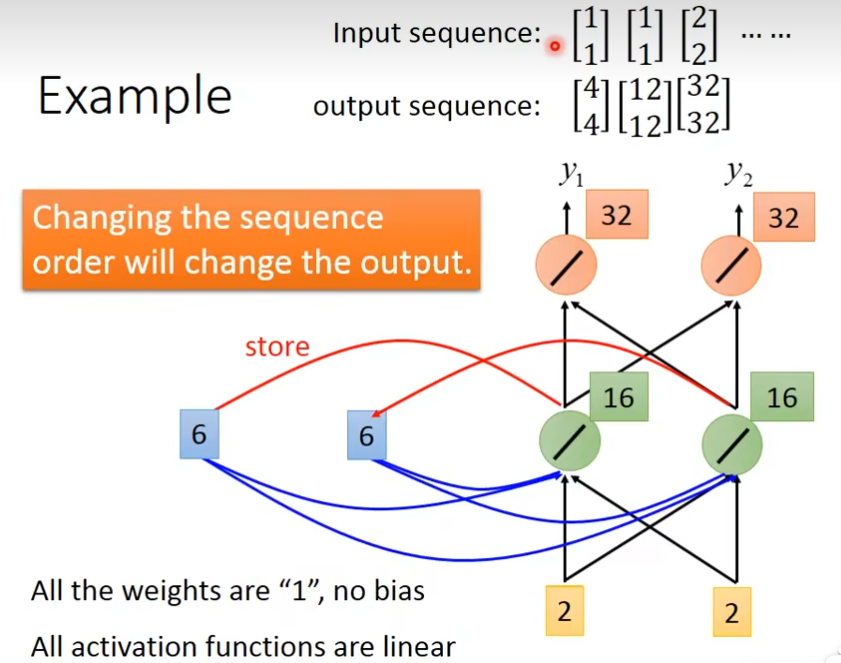
在RNN里面,每一次我们的hidden layer里面的neuron产生output的时候,这个output都会被存到memory里面去,当这些hidden layer里面neuron有output的时候,它就被存到memory里面,下一次如果有hidden layer的时候,这个hidden layer,不只考虑输入值,还会考虑这个memory里的值
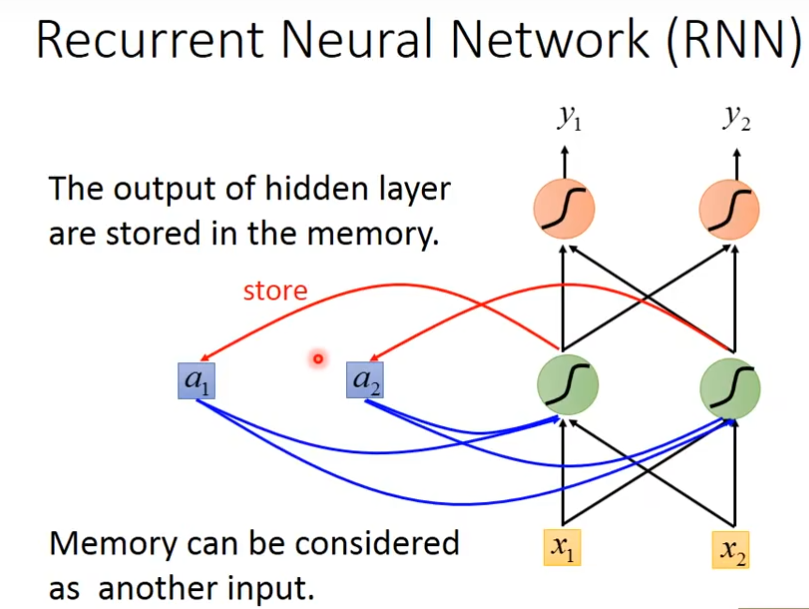
例子
在你要开始使用这个recurrent neural network的时候呢,你必须要给memory起初始值,假如现在输入[1,1],对这个neuron(绿色)来说,除了接到[1,1]以外,还知道memory的[0,0],因为w都是1,所以输出是[2,2],经过这个neuron(红色)后,输出就是[4,4],绿色neuron他的output会存在memory里面,memory更新参数值
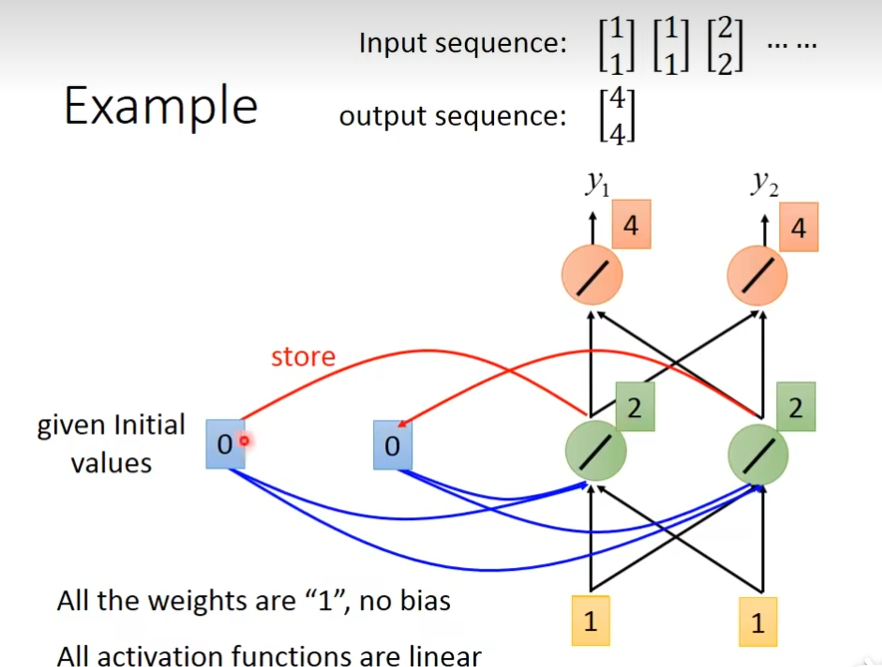
memory更新后,再输入[1,1],现在的input有四个(加上memory里面的[2,2]后),最后得到的结果为6,最后红色neuron的输出就是6+6=12
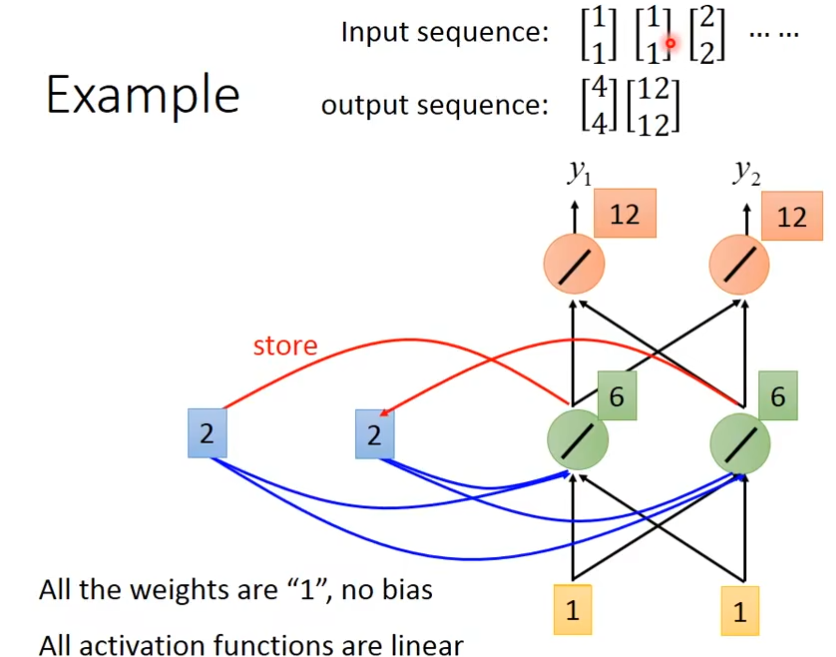
[6,6]存到memory里面后,经过绿色neuron的output就是32,RNN会考虑你输入参数的顺序
今天如果我们要用recurrent neural network来处理slot filling这个问题的话,每输入一个单词,处理后,会存在memory里,然后供下一个单词输入作参考
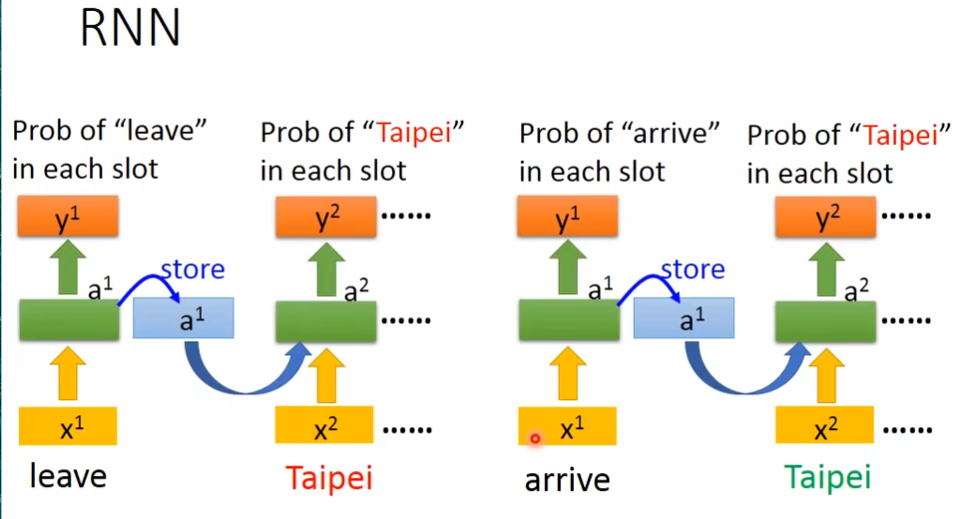
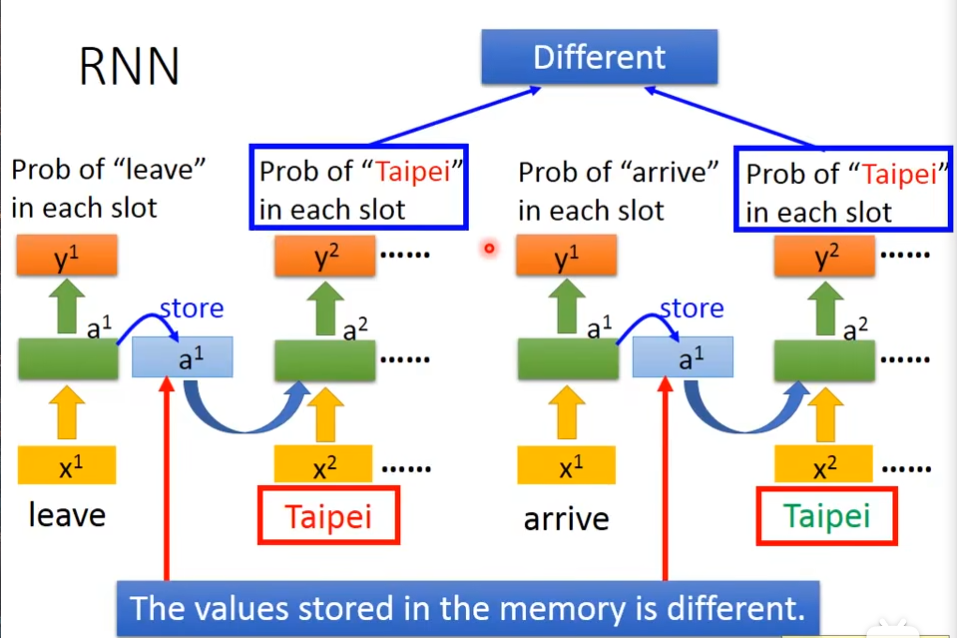
同样输入的是taibei,但是memory里面的值不同,这时候taipei有不同的含义
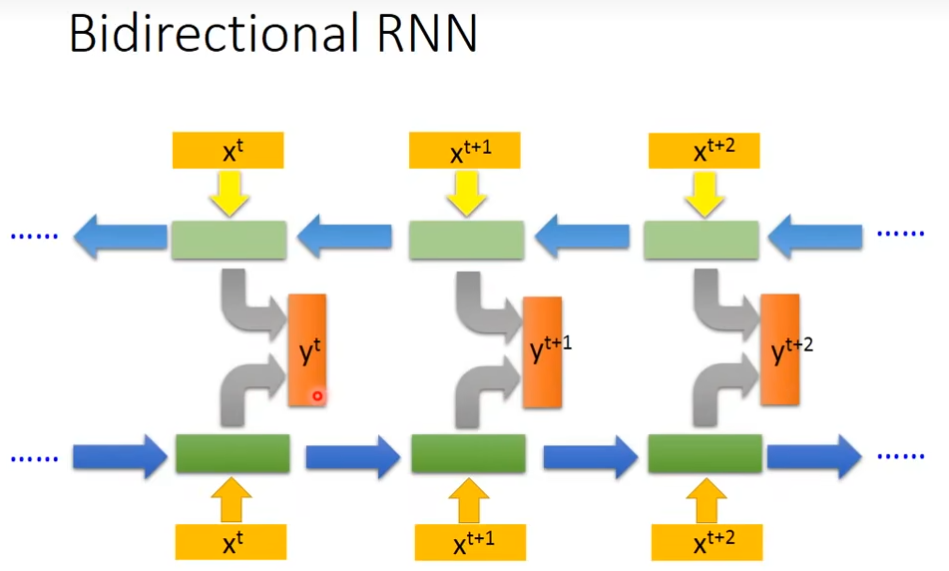
双向RNN(Bidirectional RNN)
看的范围比较广,比如说看一个句子时,就不只是看句首,还有句尾
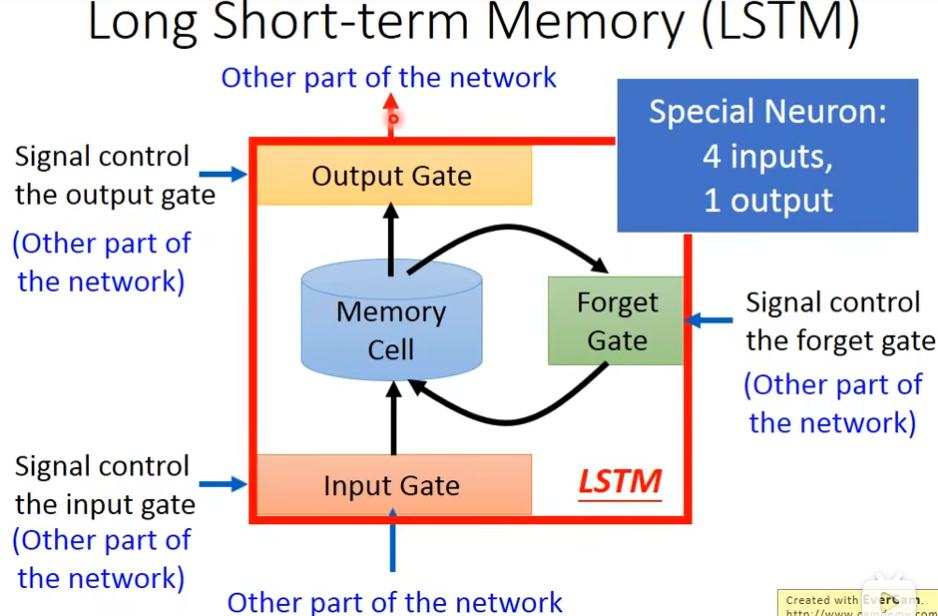
Long Short-term Memory (LSTM)
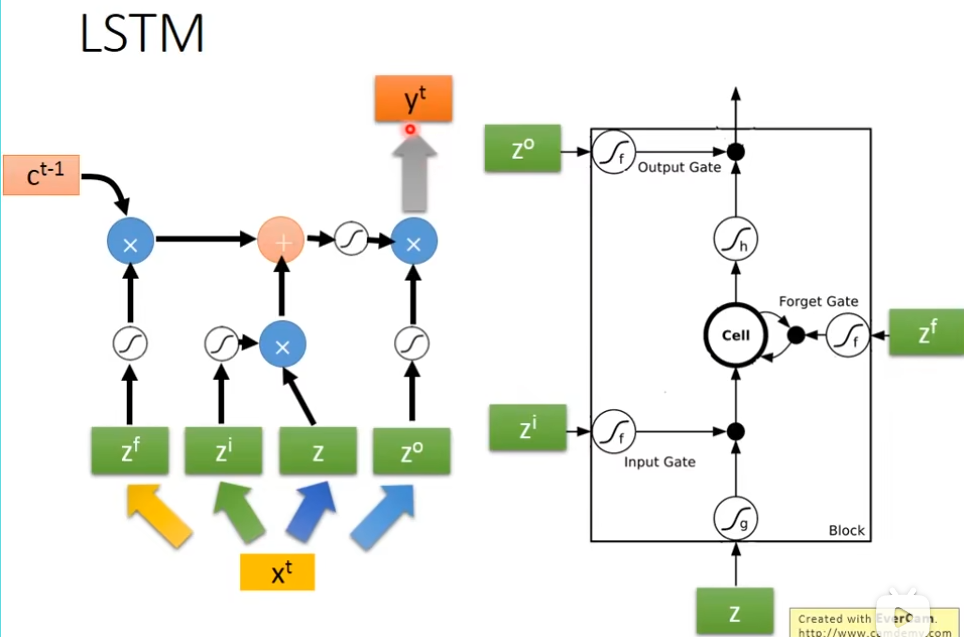
它有3个gate,当neuron的output想要被放到memory cell里面的时候,必须要通过一个闸门,通过一个input gate,这个input gate必须打开才能存放 值,输出的地方也有个gate,叫做output gate,打开时,外面才可以从memory里面把值取出来,第三个gate叫做forget gate,决定什么时候要把过去记得的东西忘掉,这个三个gate怎么用,还是要network自己去学,有个四个输入(三个信号,一个值)
举例
x2=1时,把x1的值存入到内存中去
x2=-1时,重置memory里的值
x3=1时,输出memory里的值

下图的weight和bias是通过trainng data 和 gradient descent来学到的,100和-10,10都是weight,用来决定这个gate是否打开,现在输入一个三维向量[3,1,0], input gate这里是1×100 - 10 = 90,经过sigmoid后约等于1,输入[3,1,0]
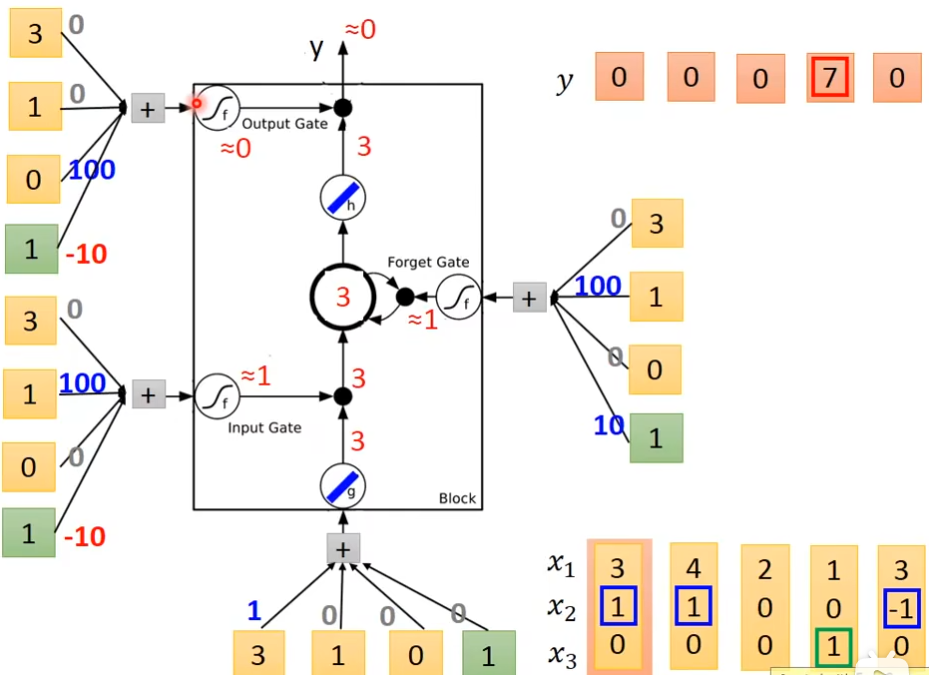
输入[4,1,0]
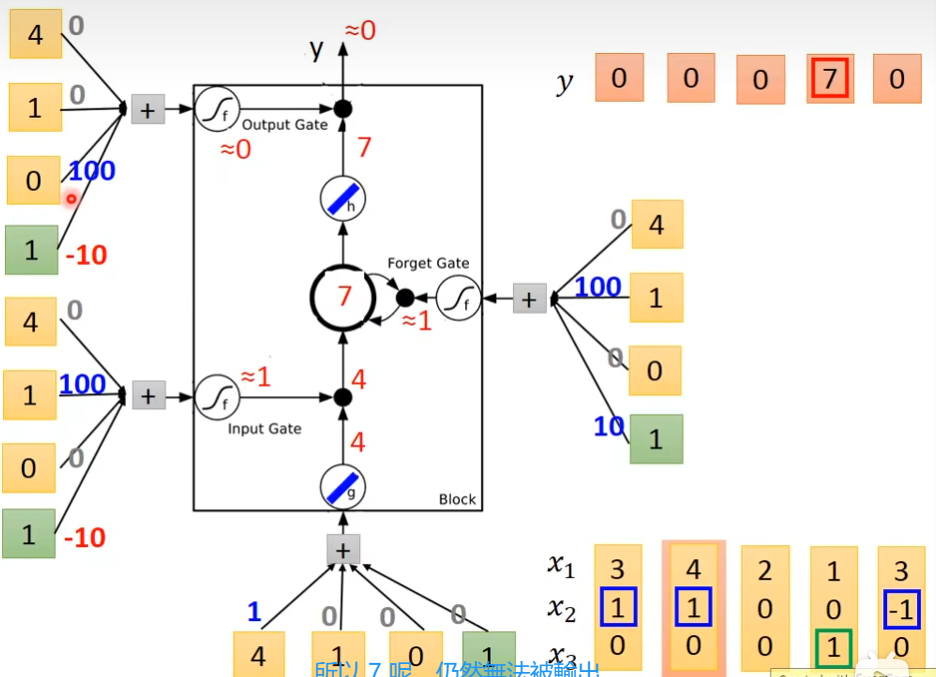
输入[2,0,0]
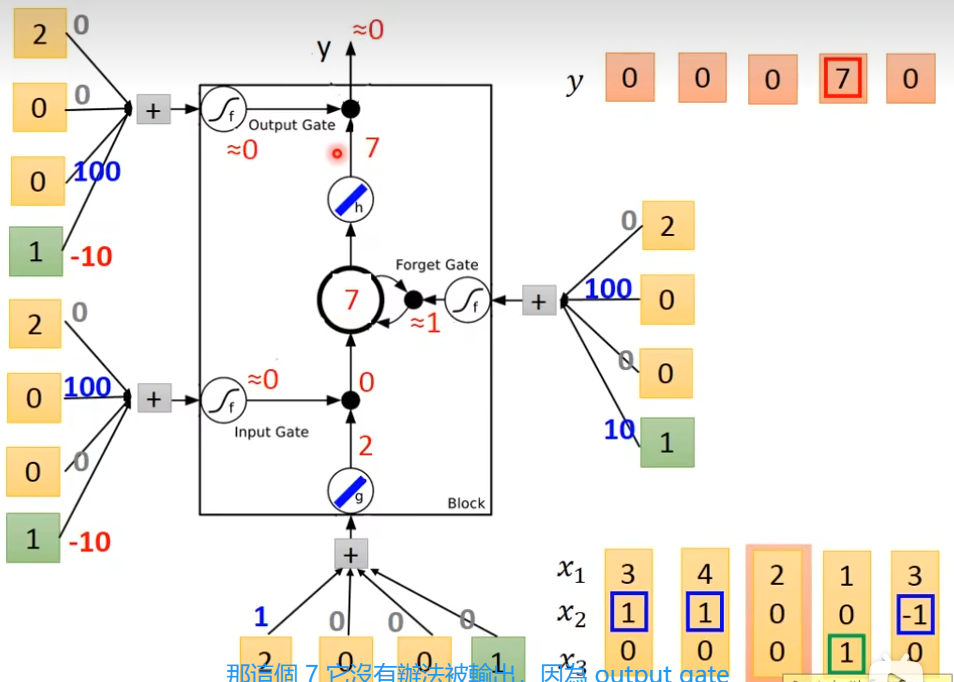
输入[1,0,1]
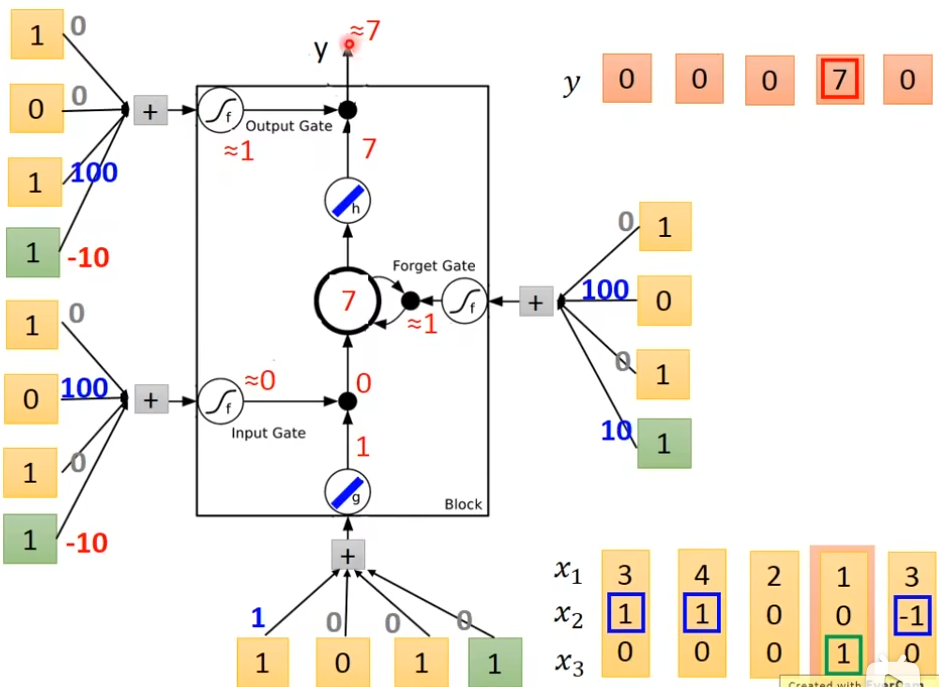
输入[3,-1,0]
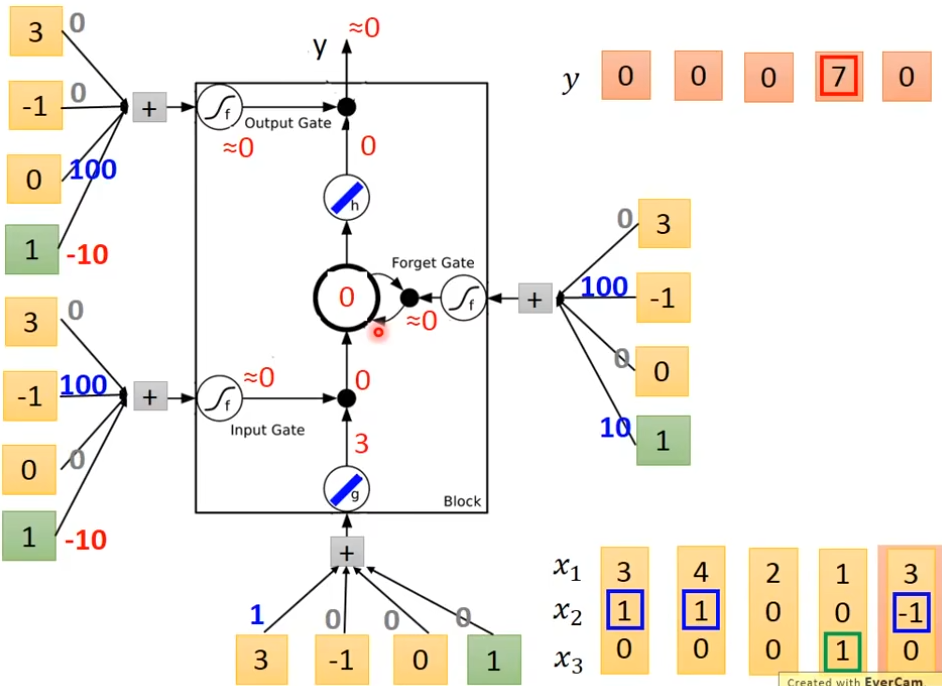
原始的network
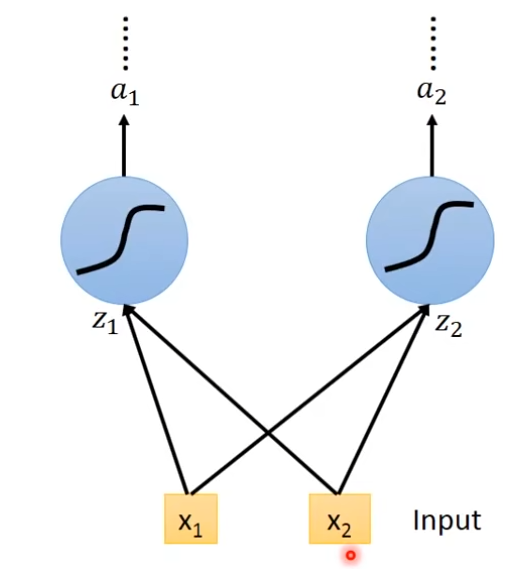
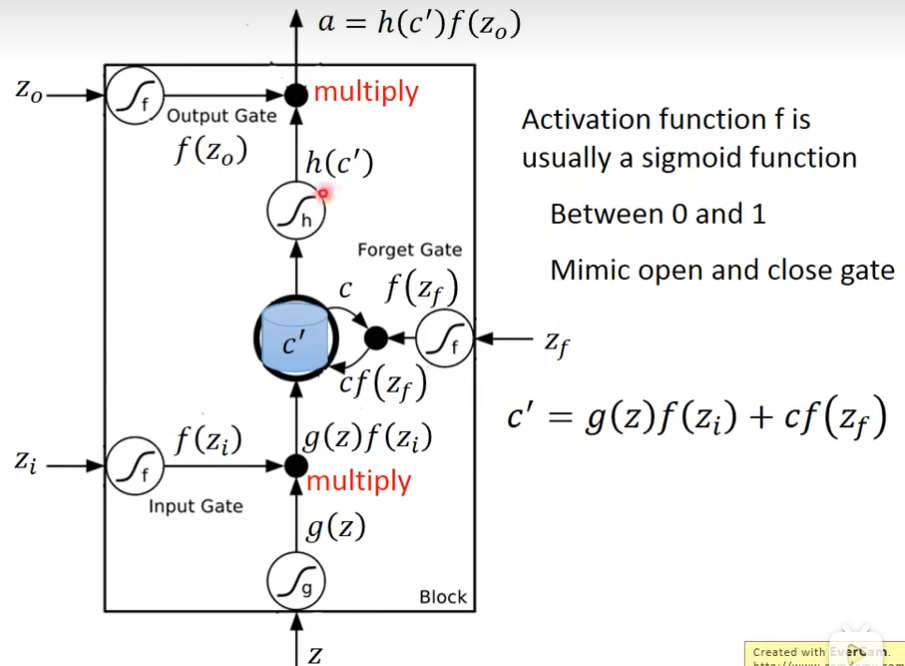
如果想要使用lstm,只需要把neuron换成lstm就可以了,另外还需要4个输入
这四个z都是vector
zf是memory里面存的值
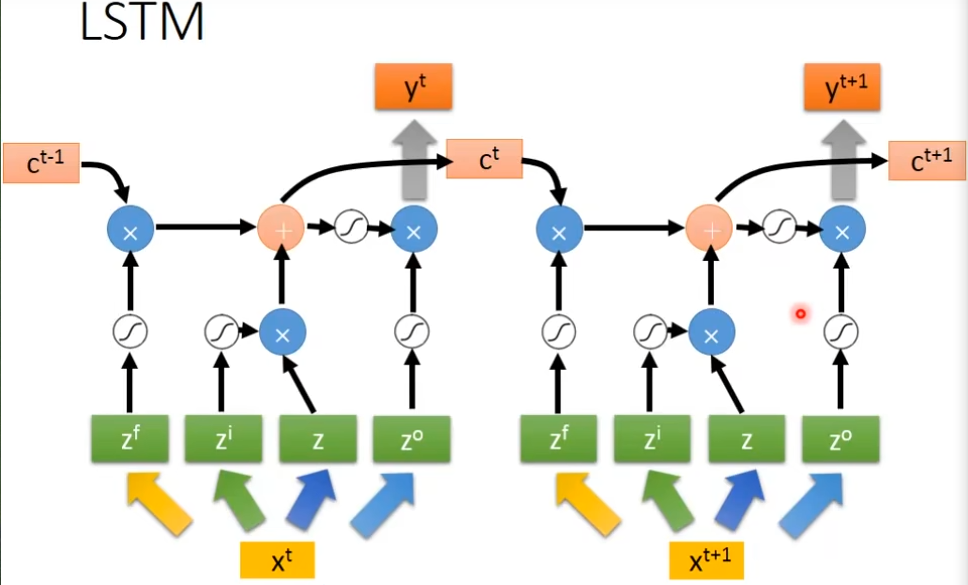
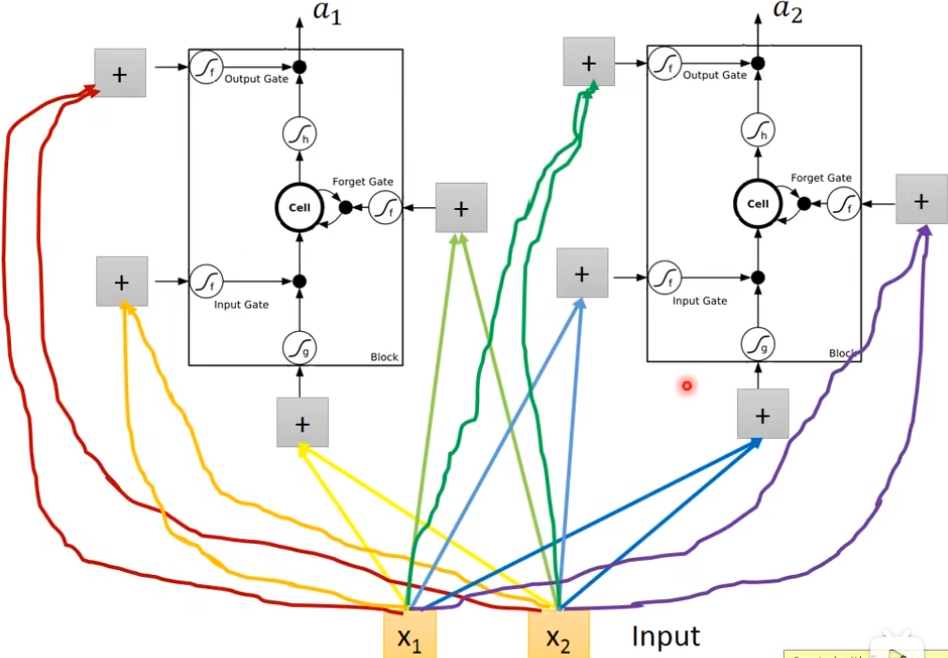
真正的LSTM会把上一个输出接进来,当做下一个时间点的input,下一个时间点操纵这些gate值,不是只看那个时间点的input,也是要看前一个时间点的output h,还会加一个东西叫做peephole,peephole的作用就是把存在memory里面的值拉过来,所以在操纵LSTM的4个gate的时候,同时考虑了x,h,c,把这个3个vector并在一起,乘上4个不同的transform,得到这4个不同的vector,再去操纵LSTM
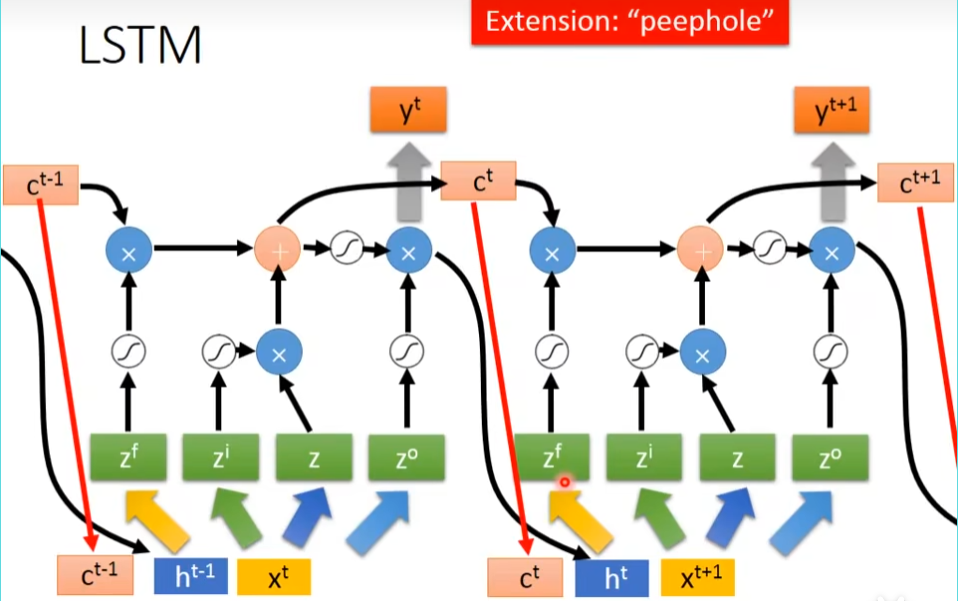
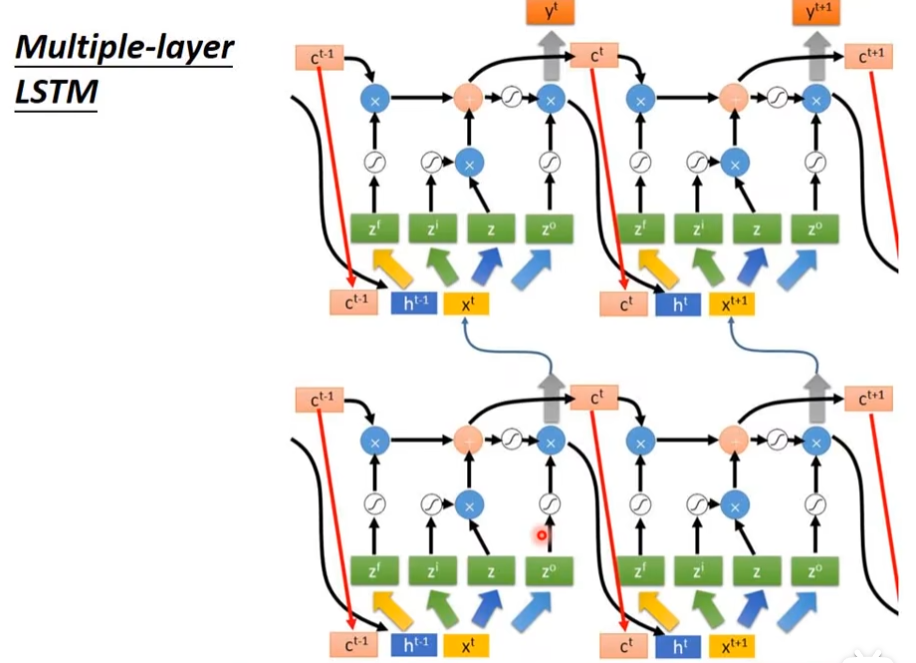
多层LSTM
Unsupervised Learning:word Embedding
如何把word转换为vector,第一种方法是1-of-N encoding,世界上有多少个word,这个vector的纬度就是多少,还有一种方式就是word class,把同样性质的wordcluster成一群一群的,然后用哪一个word所属的class来表示这个word。
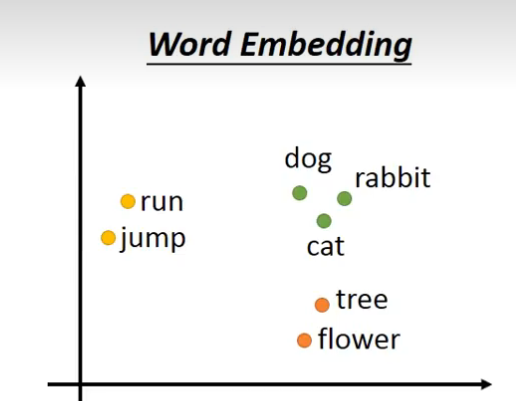
但是word class有个缺点是不同的class之间的关联是无法表示的,这时候需要用到word embedding,把每一个word都project到一个high dimensional的space上面,从1-of-N encoding到word embedding这是dimension reduction的过程
怎样做word embedding呢?怎样让machine知道每一个单词的含义是什么呢?
答:让machine读大量的文章,它就知道每个词的含义,它的embedding的feature vector应该是长什么样子,这是一个unsupervised problem,我们要做的就是找到一个function,让input一个word,output一个单词所对应的word embedding的vector,但是我们不知道这个word embedding应该长什么样子,也就是我们只知道输入,不知道输出,这里是不能用auto-encoder的
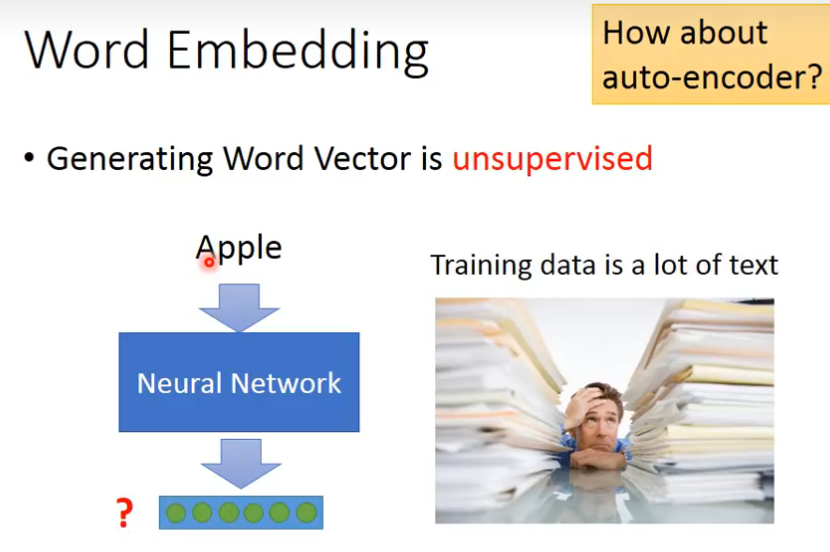
那怎么找word embedding呢?
如果想要了解一个词的含义了,你要看这个单词的contest(上下文)

如何利用这个上下文了?
- count based
- 如果两个单词经常在文中出现,那么它们的vector,就比较接近,计算这两个vector的inner product,假设说Ni,j是这两个单词在相同的文章中重复的次数,这时候希望给两个单词各找一个vector,希望这两件事情,越接近越好

-
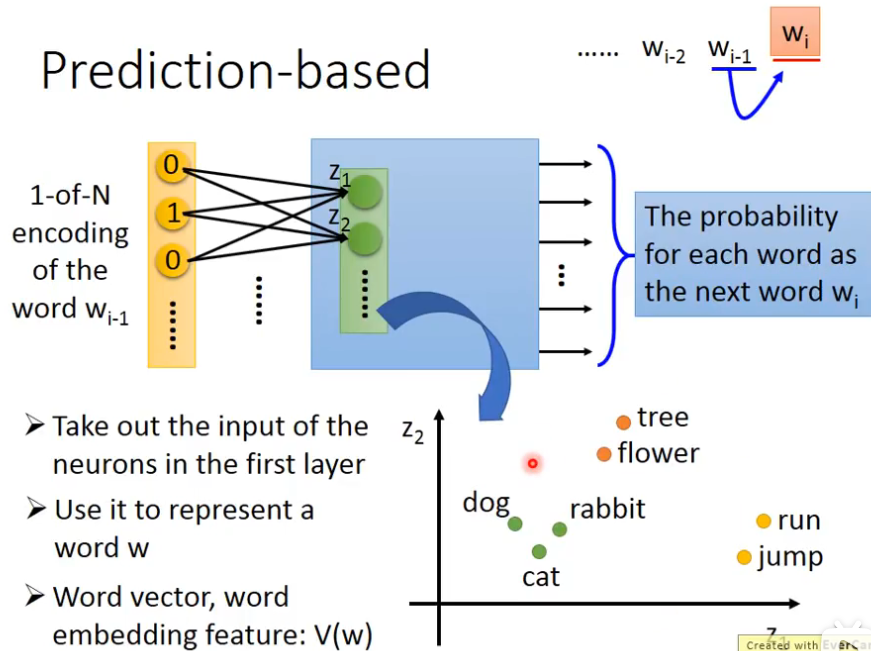
Predition based
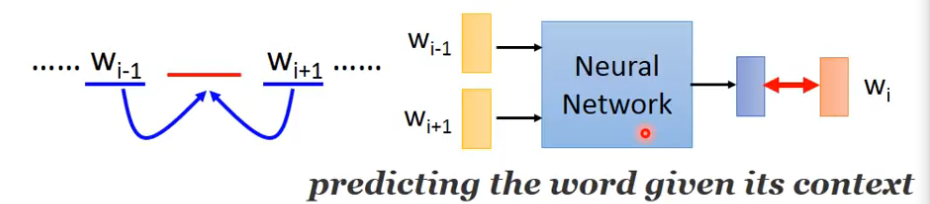
我们来learn一个neural network,它做的事情是prediction,这个neural network做的事是根据前一个word预测下一个可能出现的word是谁,每一个word我们都用1-of-N encoding,可以把它表示成一个feature vector,我们要learn一个neural network,它的input是前一个单词的1-of-N encoding的feature vector,那么它的output就是下一个word,w
i是某一个word的概率,也就是说,这一个model它的output的dimension就是vector的size,如果世界上有10万个word,那么这个output就是10万维,每一个维度代表某一个word的概率,当你把input feature vector丢进去的时候,通过一些hidden layer,就可以得到output,接下来把第一个hidden layer的input拿出来,假设第一个hidden layer的input,它的第一个dimension是z1,第二个是z2,我们用这些z就可以代表一个word,input不同的1-of-N encoding,这边的z就不同,我们把这边的z拿来代表一个词汇,input同一个词汇,它有同样的1-of-N encoding,在这边它的Z就会一样,input不同的词汇,这边的Z就会不一样,我们用input 1-of-N encoding得到Z的这个vector来代表这一个word,来当做那一个word的embedding
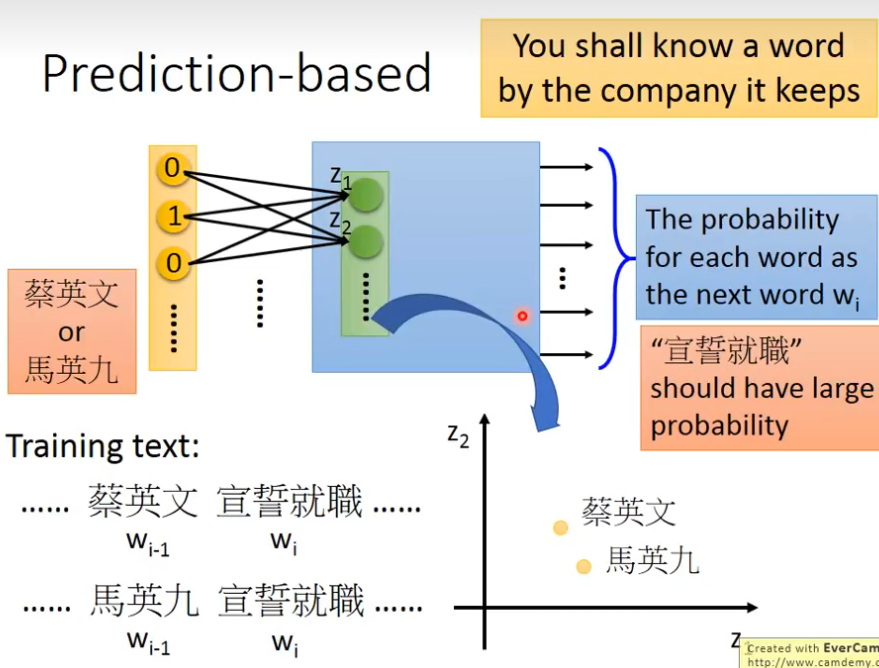
Prediction-based-Training
假设现在,你希望不管是input蔡英文,还是马英九的1-of-N encoding 你都会希望learn出来的结果是宣誓就职的概率比较大,虽然马英九和蔡英文虽然是不同的input,但是为了要让最后在output的地方,得到一样的output,你就必须在中间的hidden layer做一些事情,中间的hidden layer必须要学到这两个不同的单词必须把它们project到,通过weight的转换,把它们对应到同样的空间
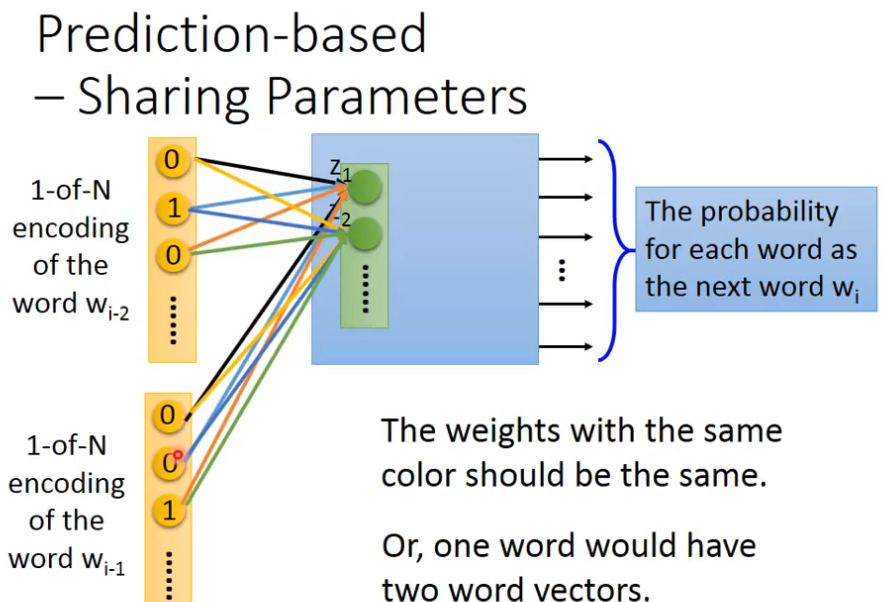
但是只根据前面的一个词,预测后一个词很难,那么我可以扩展一下,根据前面的2个词,来预测下一个单词,你可以轻易地把这个model扩展到N个词汇,比如说根据前面10个词,预测后面一个词,我们这边用input两个word当做例子,你可以轻易把这个model扩展成10个word,如果是一般的neural network,你就把input wi-2和wi-1的1-of-N encoding的vector,把它接在一起变成一个很长的vector,当做input丢到neural network就可以了,但是实际上你会希望wi-2的weight和wi-1的weight是tight在一起的,所谓的tight在一起就是说wi-2的第一个dimension跟第一个hidden layer的第一个neuron连接的weight和wi-1的第一个dimension跟第一个hidden layer的第一个neuron连接的weight必须是一样的,相同的颜色,表示weight值必须是一样的
为什么要这样做了?
答:如果我们不这么做的,你把同一个word放在 wi-2和wi-1位置通过transformer以后,它得到embedding就会不一样,这样做有个好处是,可以减少参数量,如果我们强迫让所有的1-of-N encoding它后面接的weight是一样的,那么就不会随着你的contest的增长,而需要更多的参数
 注意
注意
这些1-of-N encoding的长度是相同的,weight也必须是相同的,如果今天你要得到一个word的vector的时候,你就要把一个word的1-of-N encoding乘上这个W,就可以得到那一个word的word embedding
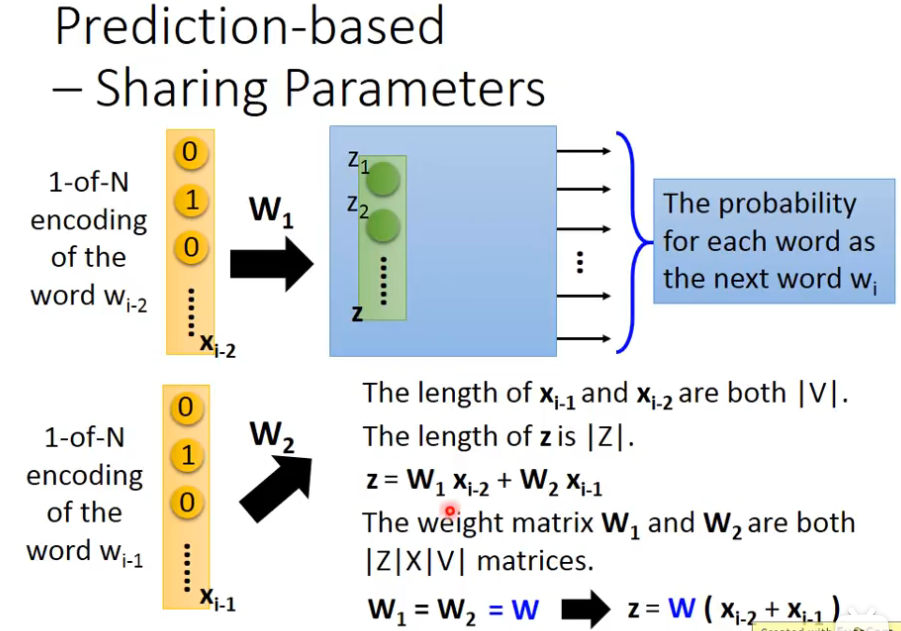
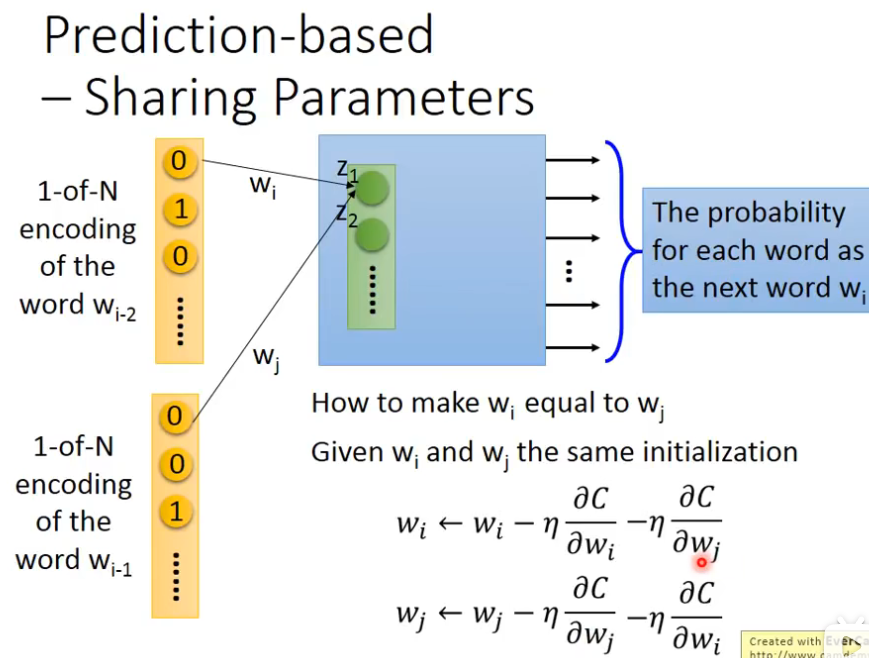
我们在train CNN的时候,我们也要让某一些参数,它们的weight必须是一样的,首先要给wi和wj一样的初始值,接下分别计算偏微分,然后减去对方的偏微分,然后更新参数
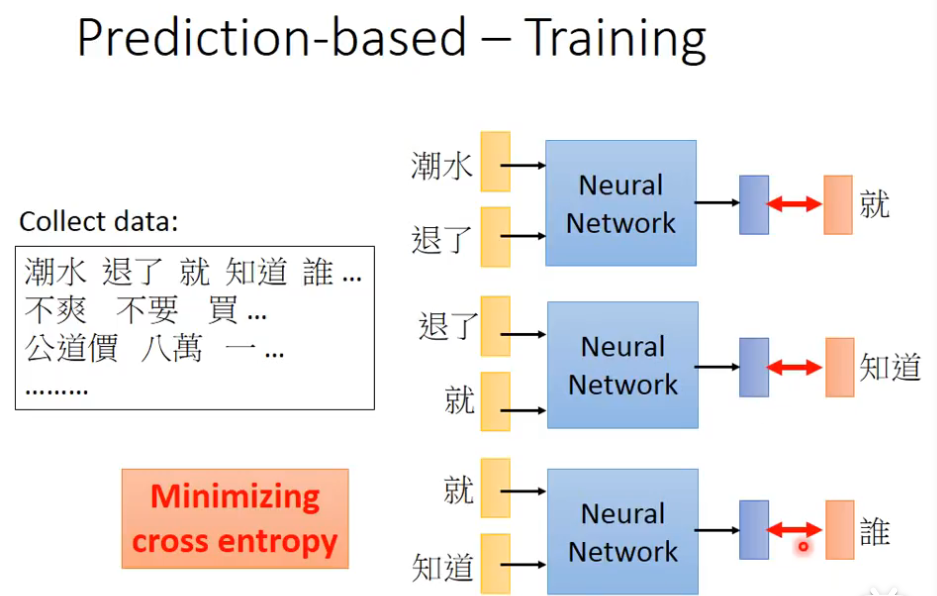
训练
这个network的训练完全是unsupervised的,这里比方说输入“潮水”和”退了",希望它的output是“就”这个样子,希望output和“就”的cross entropy很小,同理依次往下训练
Continuous bag of word(CBOW)model
拿某个词的context去predict中间的这个单词
Skip-gram
拿中间的词去预测接下来的context

word vector的neural network,它不是deep的,也就是没有很多层hidden layer
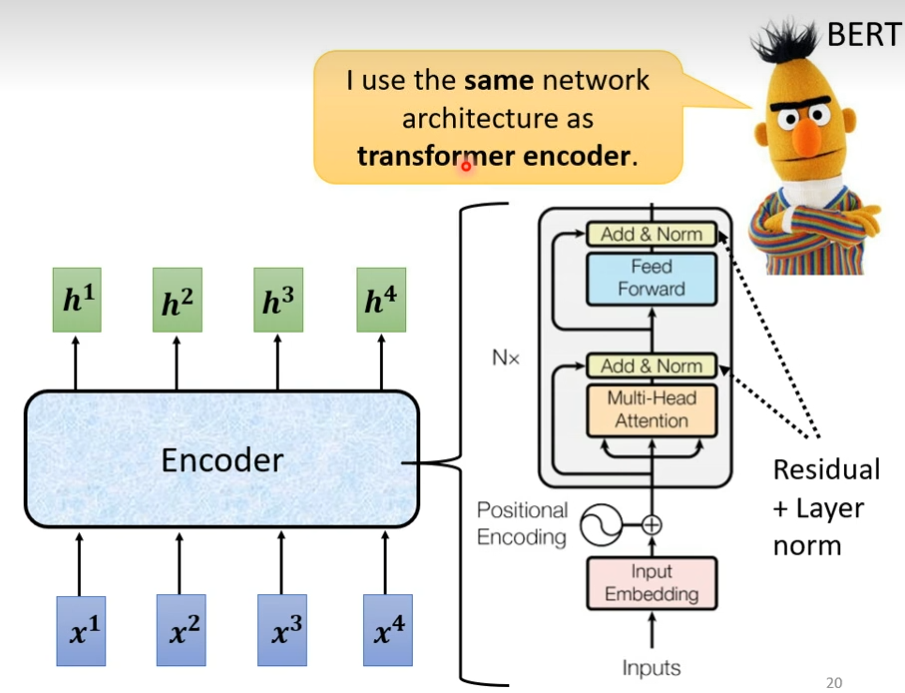
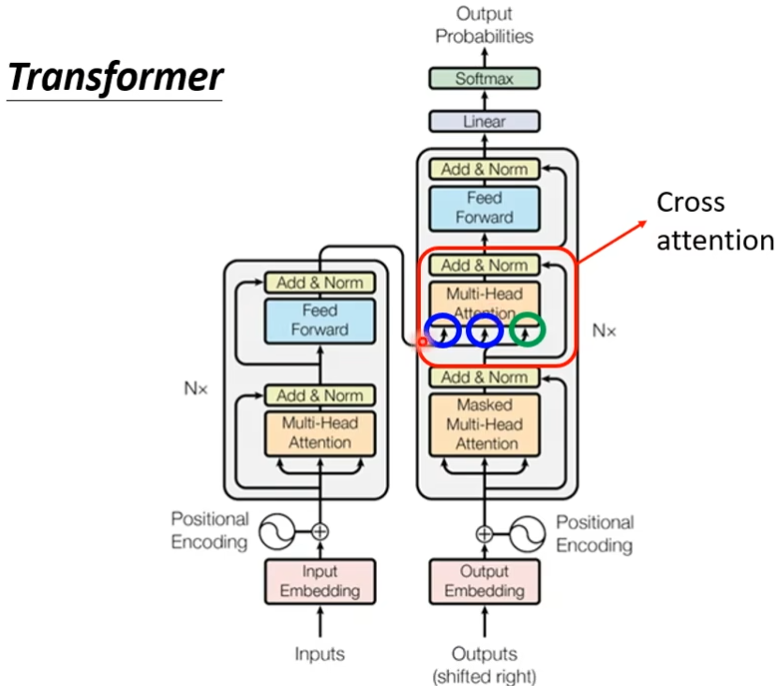
Transformer
参考链接:十分钟理解Transformer - 知乎 (zhihu.com)
完全基于self-attention,拥有encoder和decoder结构
Sequence-to-sequence(Seq2seq)
输入是一个sequence,输出也是一个sequence,输出的长度由模型决定,Seq2seq一般分为两块,一块是encoder,一块是decoder,先由encoder提取原始句子的意义,再用decoder将意义转换成对应的语言,依靠“意义”这个中介,seq2seq成功解决了两端单词数不对等的状况
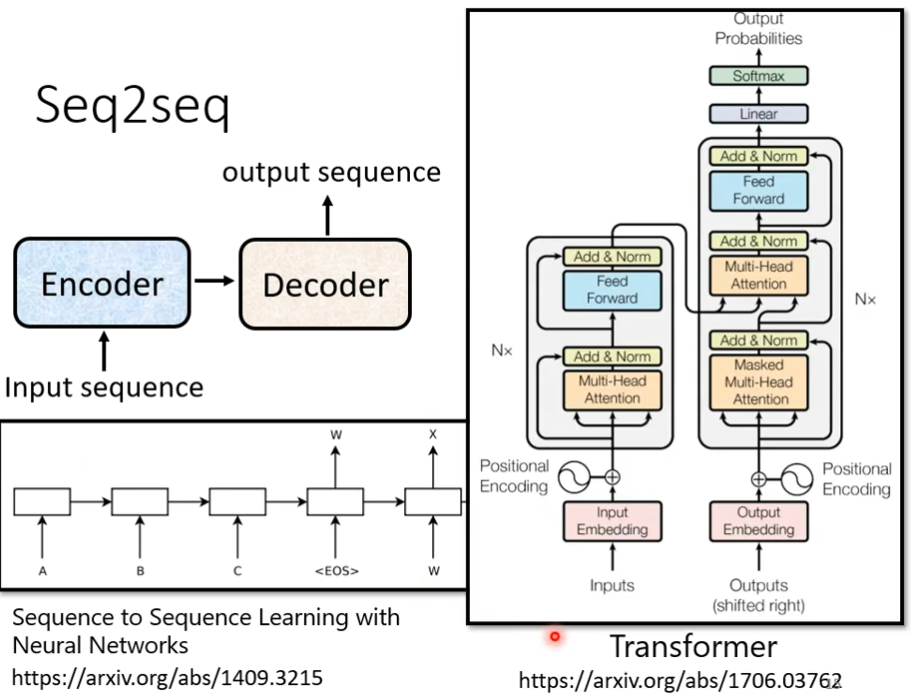
encoder
输入一排向量,输出一排向量
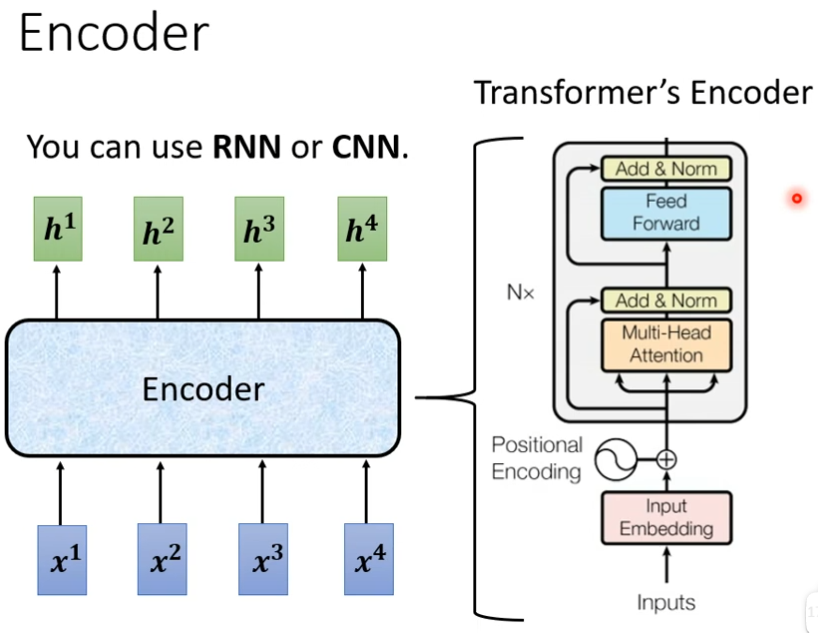
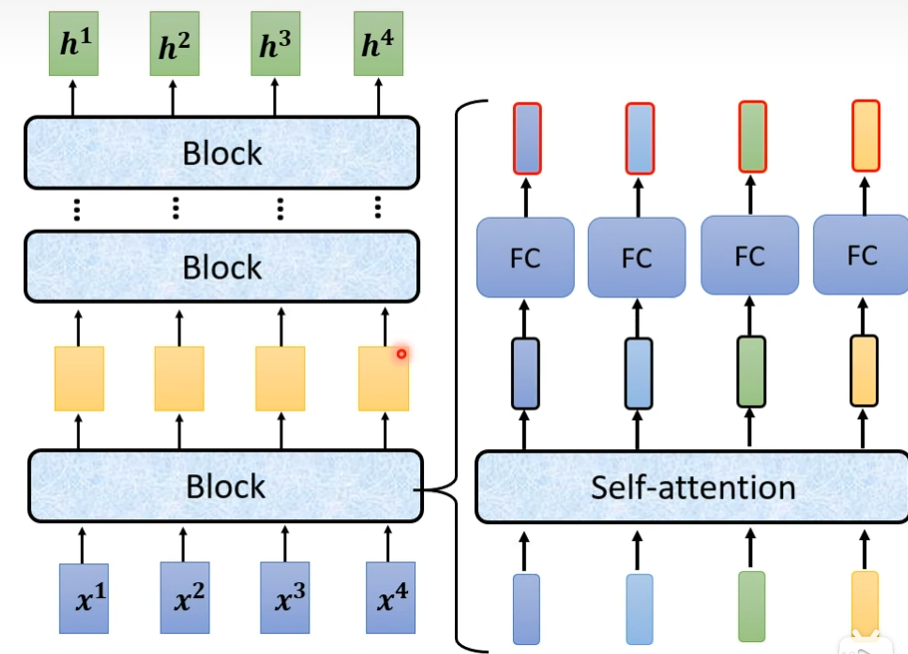
现在encoder里面会分成很多的block,每一个block都是输入一排向量,输出一排向量,每个block其实并不是network的一层,是因为block里面有很多层,每个block里面做的事大概是这样的,先做一个self-attention,考虑整个sequence的资讯,然后这一排输出,会被丢到fully connected的feed forward network里面,然后输出,这一排vector就是block的输出
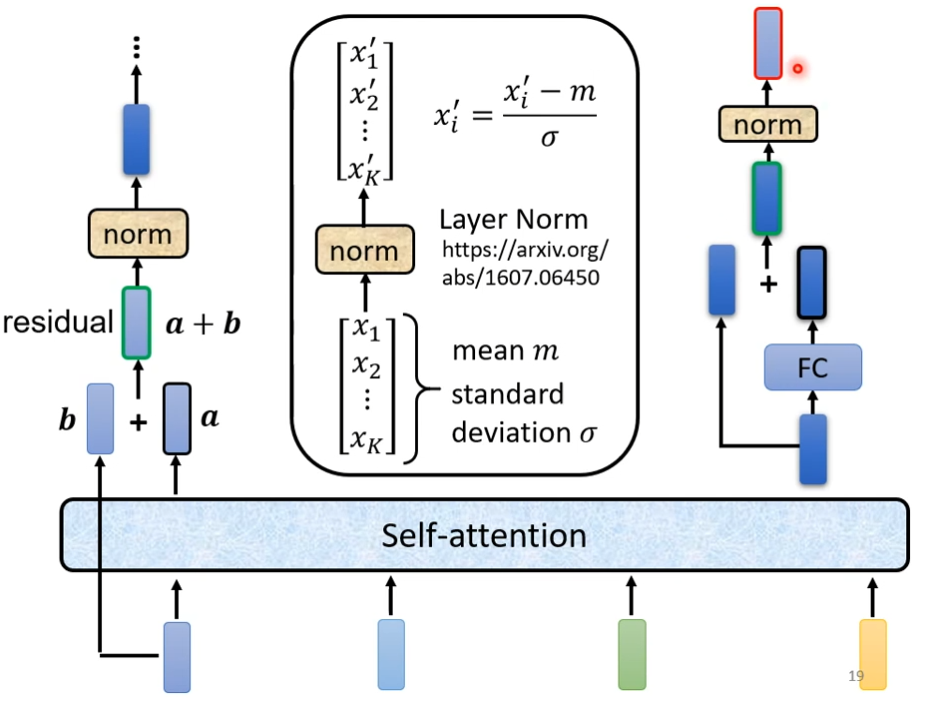
在原来的transformer里面实际上做的事更复杂的,不只是输出这个vector,还要把这个vector加上input,得到新的output,这种架构叫做residual connection,得到residual的结果后,把它normalization,这里不是batch normalization是layer normalization,layer norm不需要考虑batch,它计算mean和standard deviation,然后对FC也做residual,然后在layer norm一次
decoder
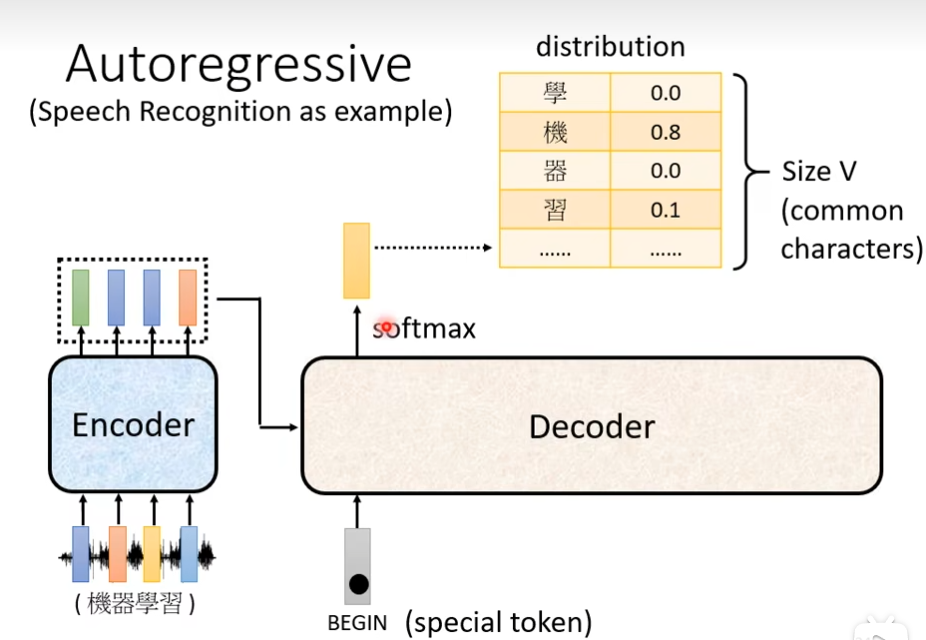
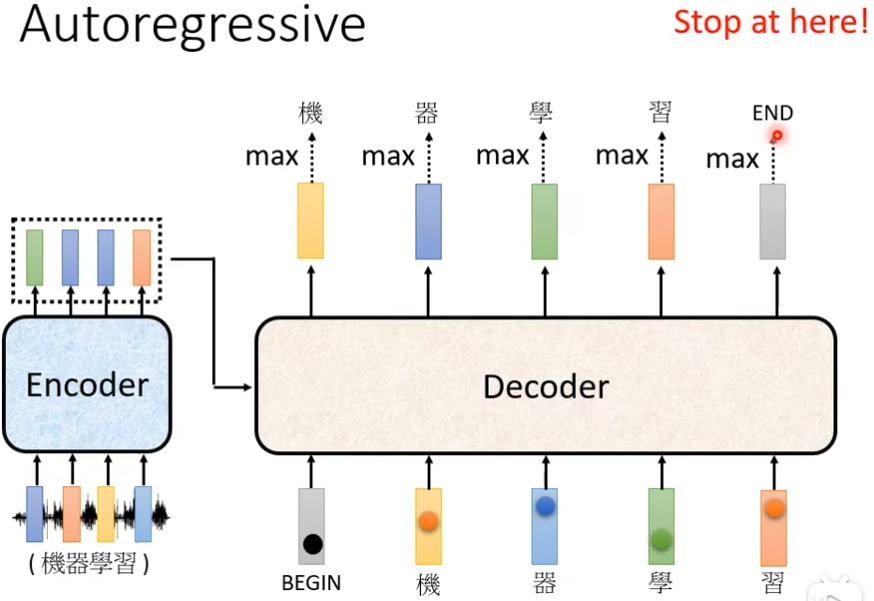
Autoregressive
首先你需要给一个信号begin表明”开始“,是一个vector,之后decoder会输出一个向量,这个向量的长度很长,跟你的vocabulary的size是一样的,这个vocabulary是你自己决定了,你可以让vocabulary里面存放常用的字,每一个中文的字会对应一个数值,这个数值就是概率,通常在输出这个向量之前,你会先经过softmax一次
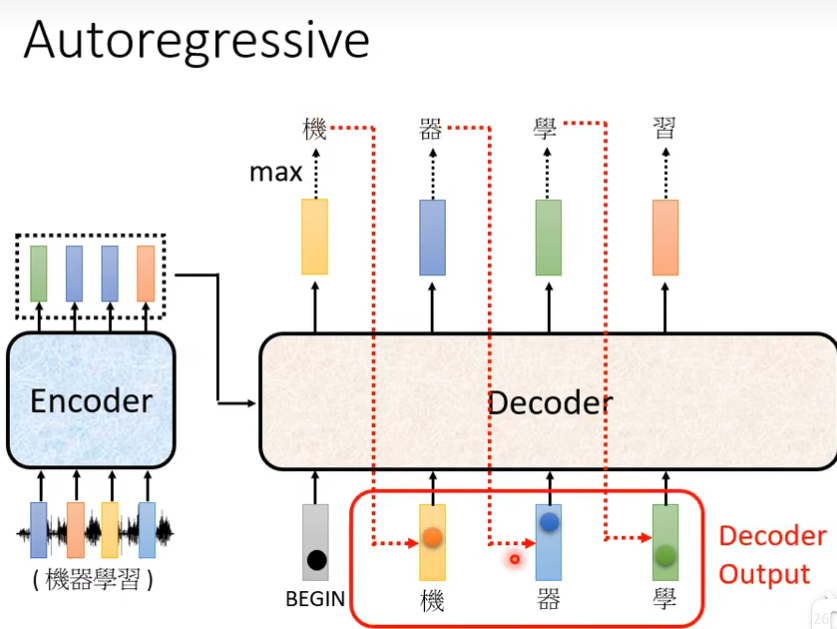
然后输出概率最高数值的汉字“机”,接下来把“机”当做decoder新的input,然后根据begin和“机”得到一个输出蓝色向量,输出这个蓝色向量里面分数最高的一个字,反复下去
如果把decoder中间遮住,发现encoder和decoder的差别不大
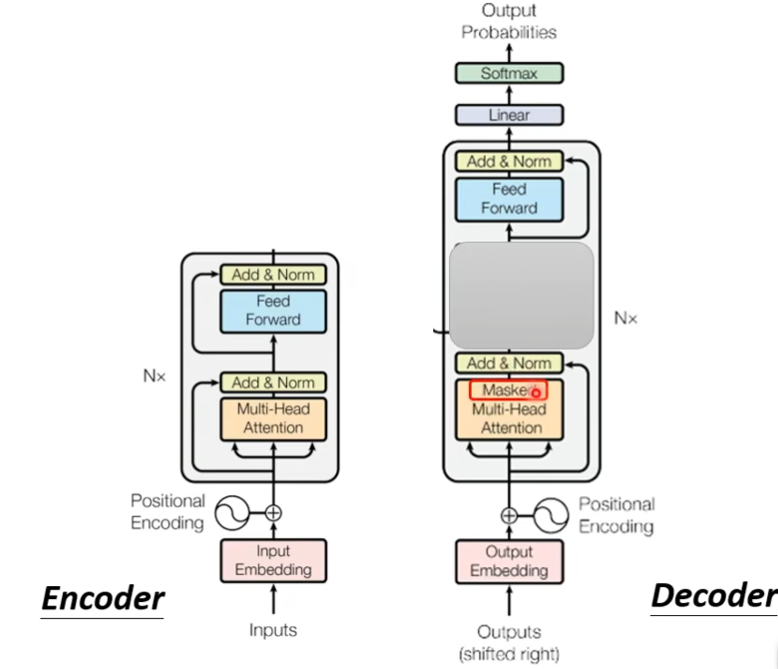
这个masked的意思是这样子的,之前self-attention是b1需要把a1的右边全部看完,才会输出b1,现在这个masked就表示只看a1,不考虑a2,a3,a4,产生b2的时候只看a1,a2,不看a3,a4,产生b3的时候,只看a1,a2,a3,不看a4,依次类推。
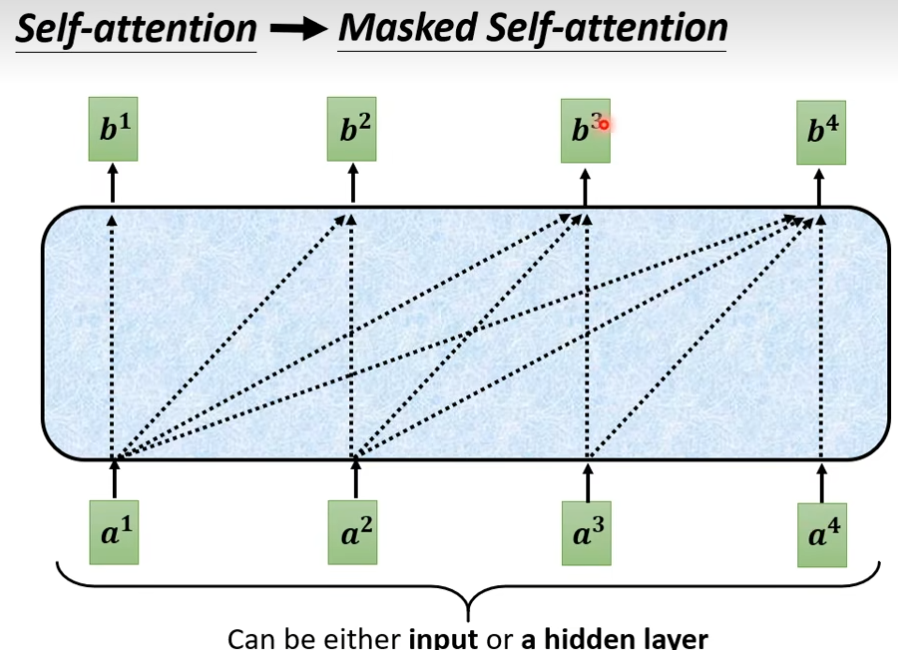
说详细点就是,q2只跟k1和k2计算
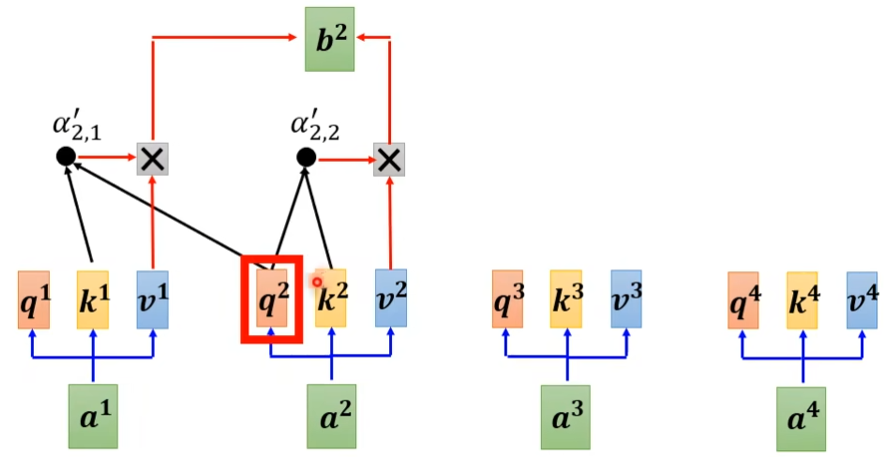
为什么masked的?
答:decoder是一个一个的输出,所以后面的就不考虑,先有a1,再有a2,a3,a4
还有一个关键问题是decoder必须自己决定输出的sequence的长度,可以这个长度到底是多少了?
答:如果输入是4个向量,那么输出一定是4个向量,但是现实中,输出和输入的长度关系是非常复杂的,我们希望是机器自己学到的,我们除了begin以外还需要指定一个符号END用来终止。我们希望decoder能够判断一句话输出后,输出这个“END”来终止,不需要再产生更多的词汇了,这个END的概率必须要是最大的,
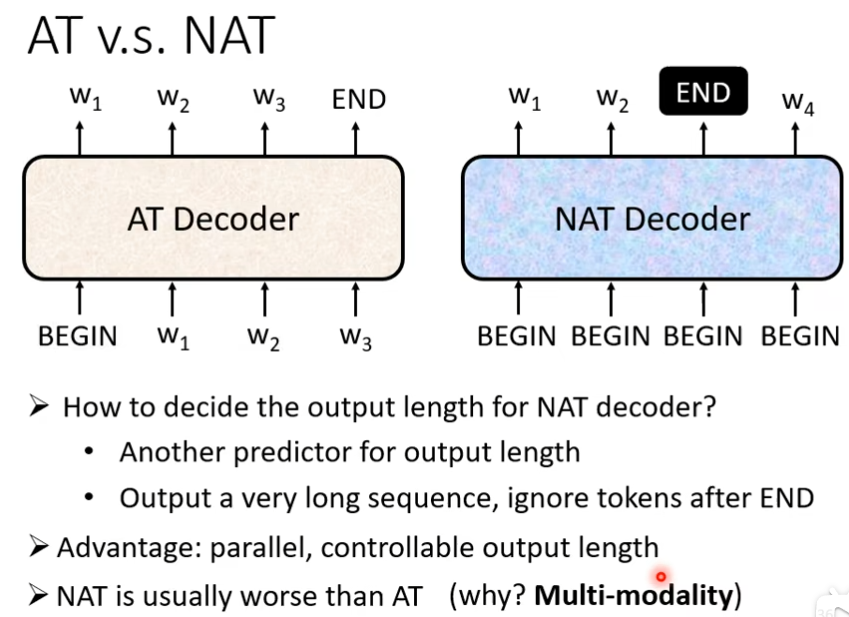
Non-autoregressive(NAT)
NAT不像AT一次产生一个字,它是一次把句子直接产生出来,你丢几个begin,他就产生几个中文的字,那我们怎么知道begin要放多少个呢?
答:1)另外扔一个classifier ,它吃encoder的input,输出是一个数字,这个数字代表decoder应该输出的长度。
2)你自己假设一个句子的上限,然后就给300个begin,如果有输出end的,忽略END后面输出的内容。
好处
- 并行,比AT快
- 能够控制输出的长度,用classifier决定,如果想要速度快点,classifier的outpu除以二,慢点,把classifier输出的那个长度,乘2
encoder和decoder传递资讯
蓝色圈圈来自encoder,绿色圈圈来自decoder
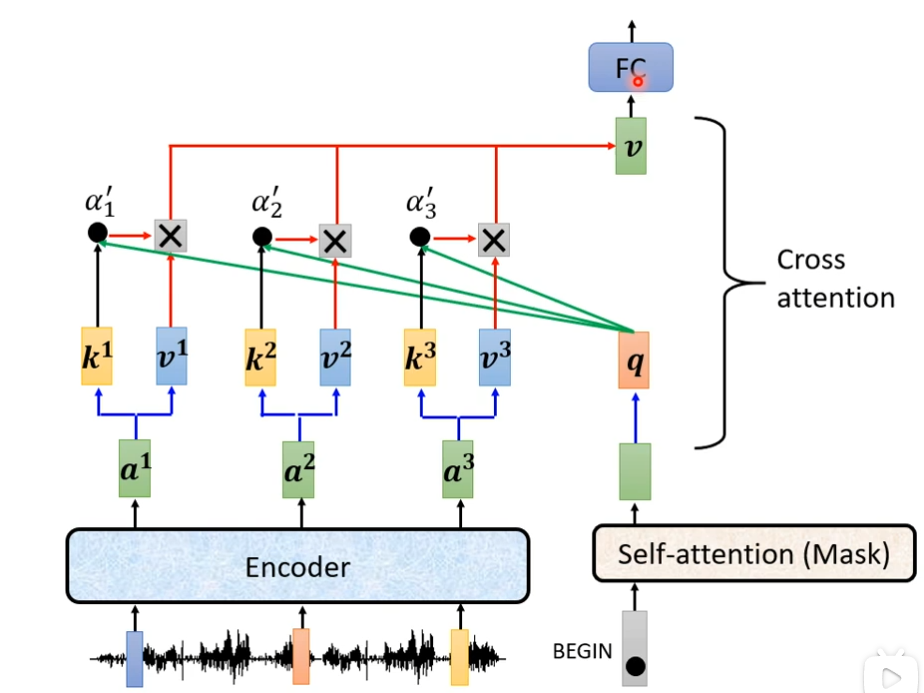
你的decoder,会把begin这个special token读进来,经过带有mask的self-attention后,得到一个向量,把这个向量乘上一个矩阵做一个transform得到一个query叫做q,然后用q与k1,k2,k3计算attention的分数,得到α1,α2,α3,接下来再乘上v1,v2,v3,再加起来得到v,再丢到FC中,这就是cross attention的过程
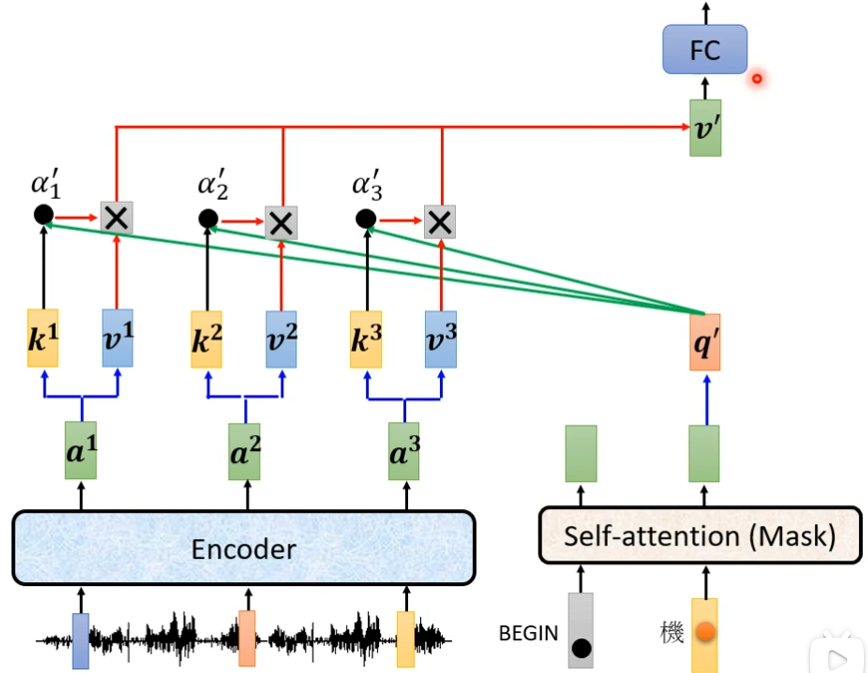
产生“机”后按照同样的步骤处理
training
你需要提供声音对应的词,这个transformer应该要学到听到这段声音讯号,然后输出相应的文字,假设现在第一个汉字是“机”,那么第一个应该输出就是“机”,当我们把begin丢给encoder的时候,它第一个输出要跟“机”越接近越好,什么叫做越接近越好了? “机”这个字会被表示成一个one-hot的vector,在这个vector里面,只有机对应的维度是1,其他都是0,decoder的输出是一个概率的分布,这个概率的分布和one-hot的vector越接近越好,我们需要计算ground truth和distribution它们之间的cross entropy,然后这个交叉熵的值越小越好。如果中文字有4000个,那么这个就是4000个分类问题,
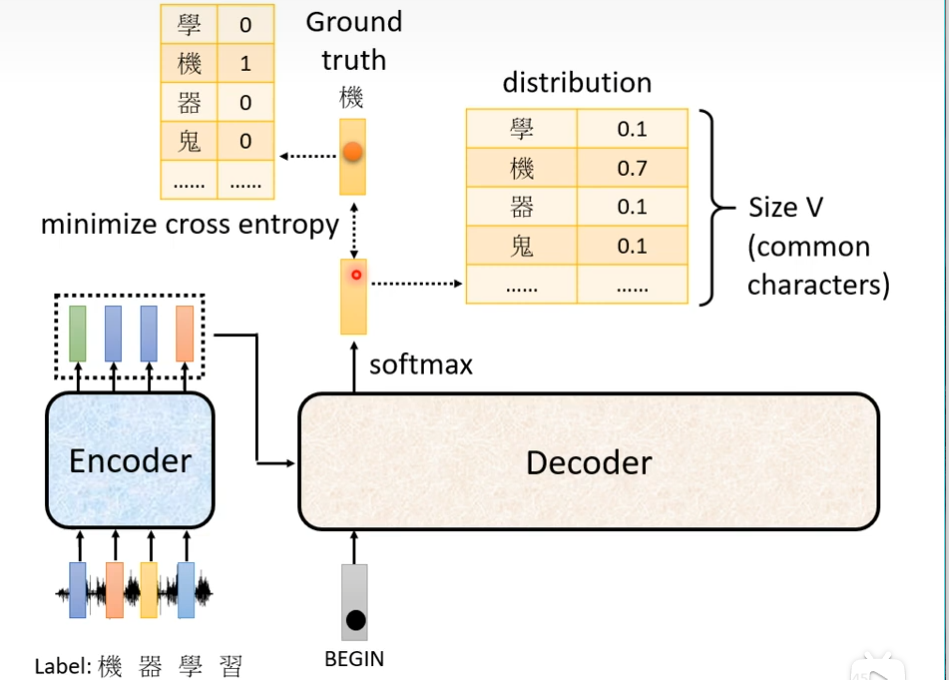
还有在训练的时候的我们在decoder这里输入正确答案,高速机器我们希望它根据这个正确答案,知道下一个输出什么,这种方式叫teacher forcing。
这时候有个问题是训练的时候,给正确答案,但是测试的时候不会给正确答案,怎样解决了?
tips
copy mechanism
对很多任务而言,我们要decoder自己产生输出,但是也许decoder没有必要创造输出,它要做的也许是从输入的东西里面复制一些东西出来,这种任务比如说:聊天机器人。
对机器来说,它其实没有必要创造库洛洛这个词汇,机器可能从来都没见到这个词汇,机器在学的时候并不是要学库洛洛这个三个字,它学到的是看到输入的时候说我是某某某,就应该把某某某直接复制过来,然后说某某某你好,机器有时候不需要创造一段文字,需要的是从使用者的话语中,复制一些当做输出

guided attention
我要指导机器在做attention的时候,是有固定的方式的,比如说在合成声音的时候,显然是由左念到右,但是机器可能就不按这个顺序来,这时候,我们要求机器从左往右来生成
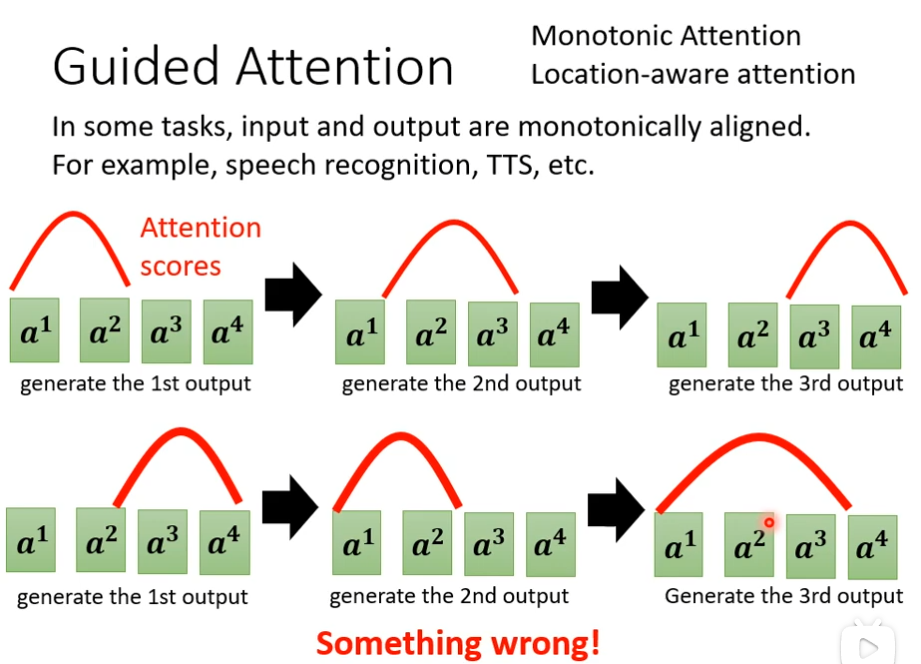
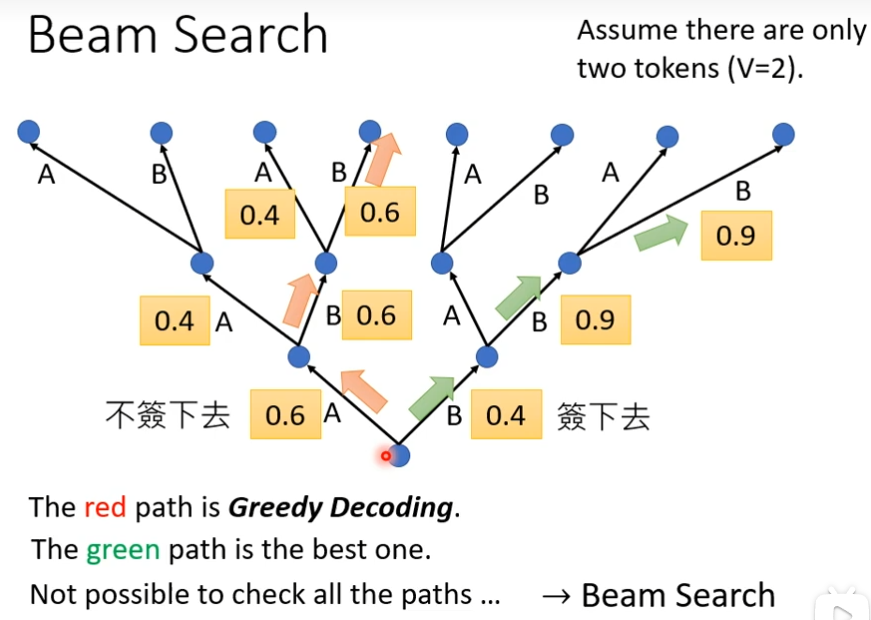
Beam search(束搜索)
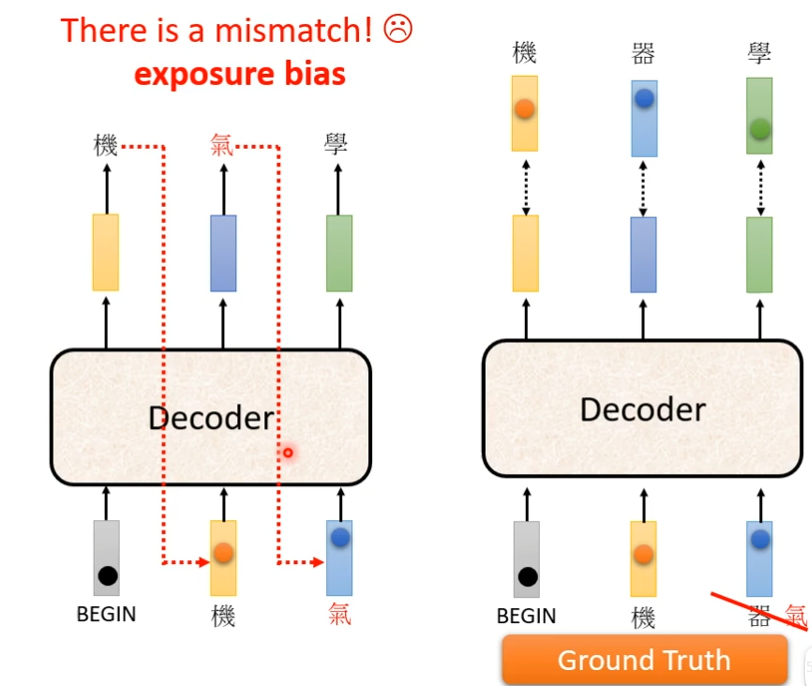
为了更高的准确性,在训练的时候,加入一点错误答案,反而训练的会更好
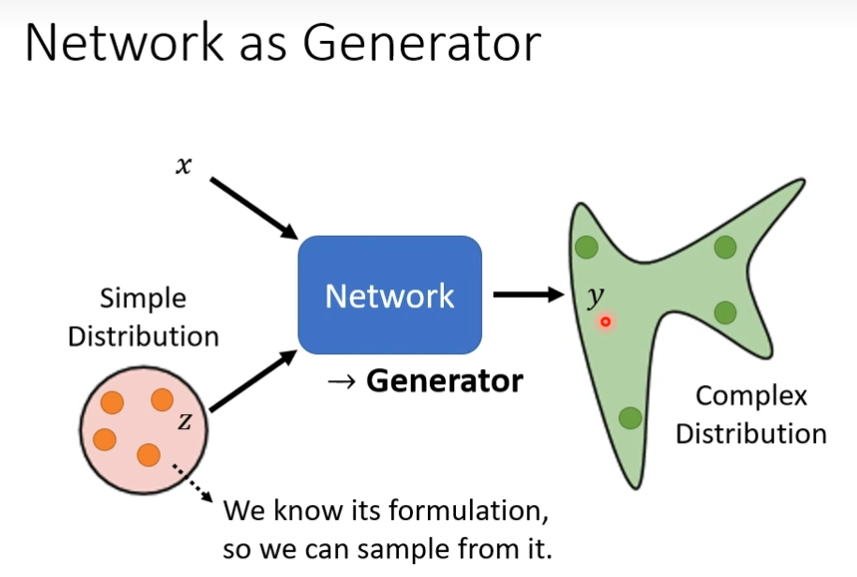
生成对抗式网络(GAN)
把network当做generator来使用,特别在于它现在的输入会加上一个随机变量z,这个z是某个分布sample出来的,现在的network不是看某个固定的x就得到输出,它是同时看x和z得到输出,这个z是不一样的,这个distributon有一个限制是必须够简单(我们得知道这个式子是长什么样子),z不同,y的输出也不同,这时候network输出就不再是单一固定的东西,而是变成了一个复杂的distribution,这种可以输出distribution的network,我们称之为generator
为什么我们需要generator,为什么要让输出是一个分布?
答:因为有时候我们要求输出的东西是概率性的,比如控制一个人向左走,向右走都是正确的信号,但是机器认为这两个都对,容易产生分裂现象,一个人即向左走,又向右走,我们要让机器不是单一的输出,而是让它的输出有一定的概率,举例来说,你选择的z是一个binary的随机变量,只有0和1各占50%,也许你的network就可以学到z是1的时候,向左转,z是0的时候,向右转,这样子可以解决很多不可预测的东西。
那我们什么时候需要这种generator的model呢?
答:当我们的任务需要一点的创造力的时候,也就是同样的输入有多重可能的输出,而这种不同的输出都是对的,比如画画,聊天机器人,不同的z输出就不同
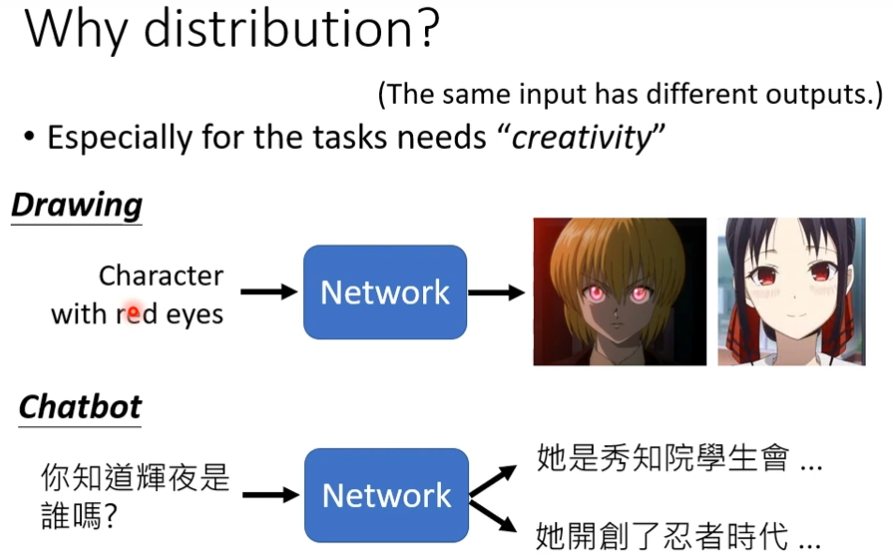
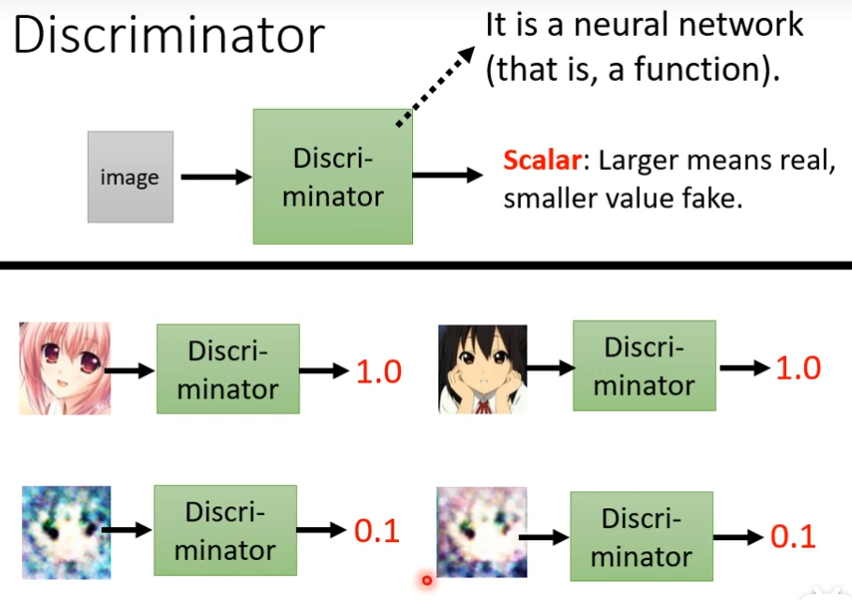
在GAN里面除了generator以外,还需要多训练一个东西,这个东西叫Discriminator,这个Discriminator它会拿一张图片当做输入,它的输出是一个数值(scalar,越大越真实,越小越假),它本身也是一个neural network
GAN的基本思想
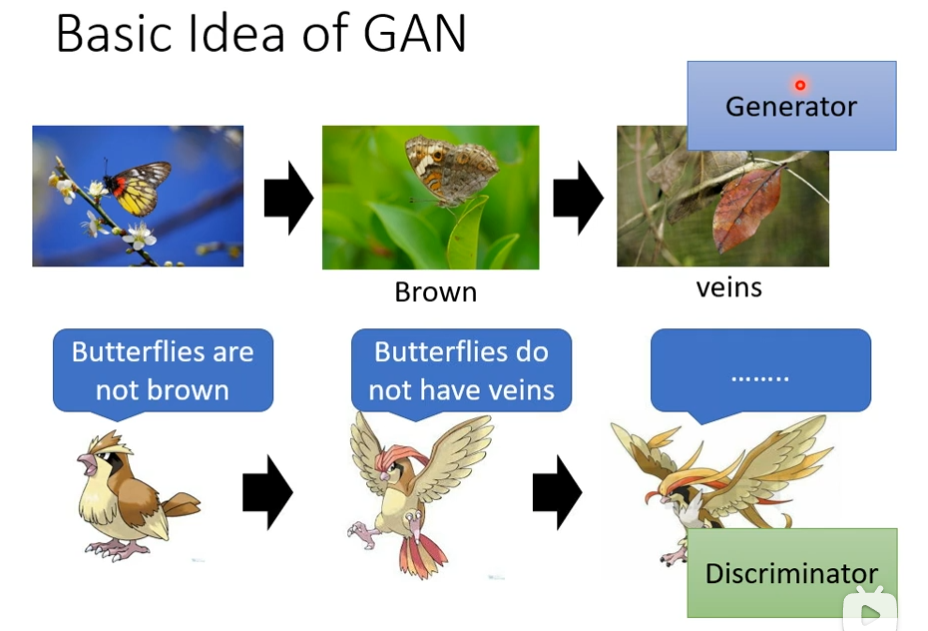
比如蝴蝶为了防止被吃,不断进化,就类似generator,而天敌想要识破蝴蝶的伪装也需要不停的进化,这里就类似于discriminator,天敌的第一次判别方式是,蝴蝶是彩色的,第二次是蝴蝶是没有叶脉的,所以蝴蝶最后进化的时候,就有了叶脉
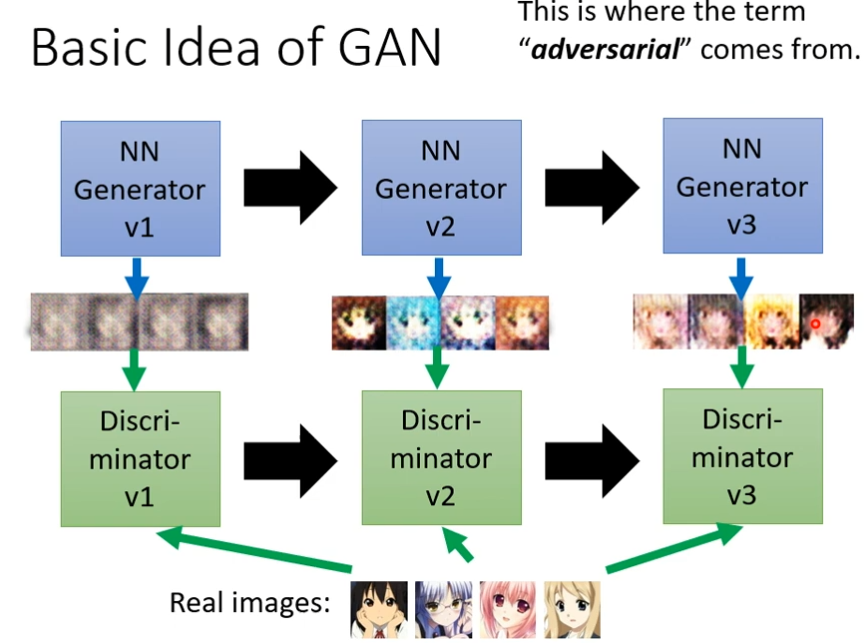
假设现在generator任务是画出二次元人物,第一代generator的参数完全是随机的,它根本不知道怎么画二次元的人物,所以画出来的也是一些杂讯,那么discriminator它学习的目标是要分辨generator的输出跟真正的图片的不同,第一次discriminator(第一代)判断的方法,图片中有没有眼睛,有眼睛就是二次元人物,没有眼睛就是generator,接下来generator(第二代)产生的东西,这时候generator就调整的它的参数,调整的目标是为了欺骗discriminator(第一代),如果discriminator(第一代)判断是不是二次元的依据是,有没有眼睛,那么generator(第二代)就会产生出眼睛出来,这时候就可以骗过第一代的discriminator,但是discriminator(第一代)也会进化的,第二代disc的判断方法是识别去分辨这一组图片跟真实图片之间的差距,它会视图去找出这两者之间的差异,比如说discriminator(第二代)发现这些图片比较简单的没有嘴巴,也没有头发,接下generator(第三代)就开始进化,开始变的有头发,有嘴巴,这时候discriminator也会进化,也会越来越严,然后generator产生的图片也会越来越像真实的二次元人物
generator和discriminator的算法
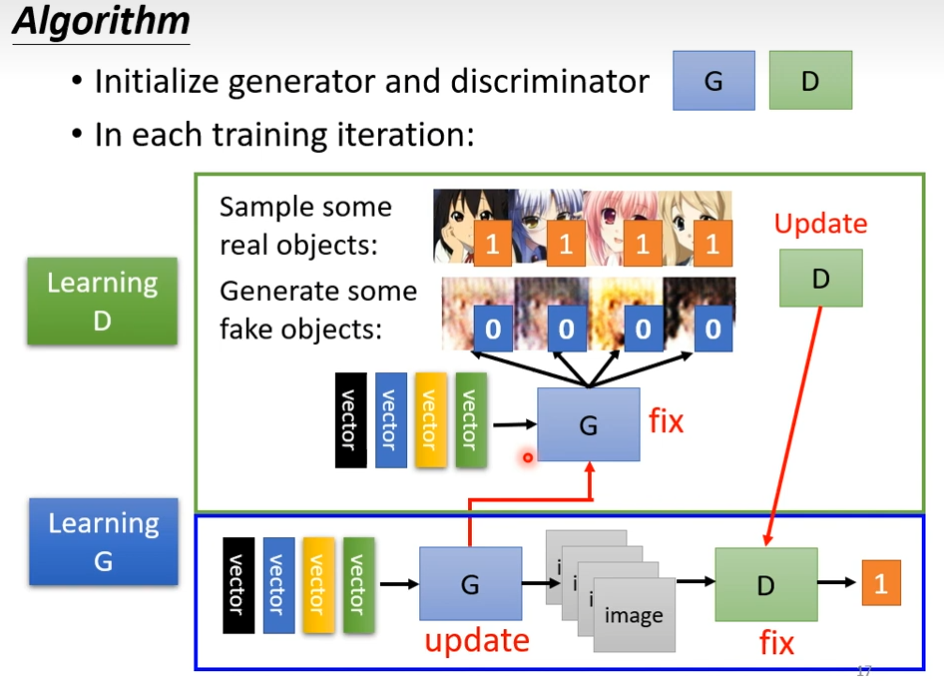
先初始化generator和discriminator
第一步
定住generator,它的参数都是随机的,丢一堆向量给它,输出的都是乱七八糟的图片,你从高斯分布中随便选一个向量给generator的话,它就产生一些图片,一开始这些图片会跟正常的二次元任务非常的不像,这时候你收集一些二次元人物头像跟generator产生的,去训练你的discriminator,discriminator训练的目标是要去分辨真正的二次元人物跟generator产生出来的二次元人物它们之间的差异,比如说真实的图片你都标1,generator出来的图片你都标0,接下来就是要么是分类的问题,要么是regression的问题,discriminator要去学会真实图片和generator产生的差别
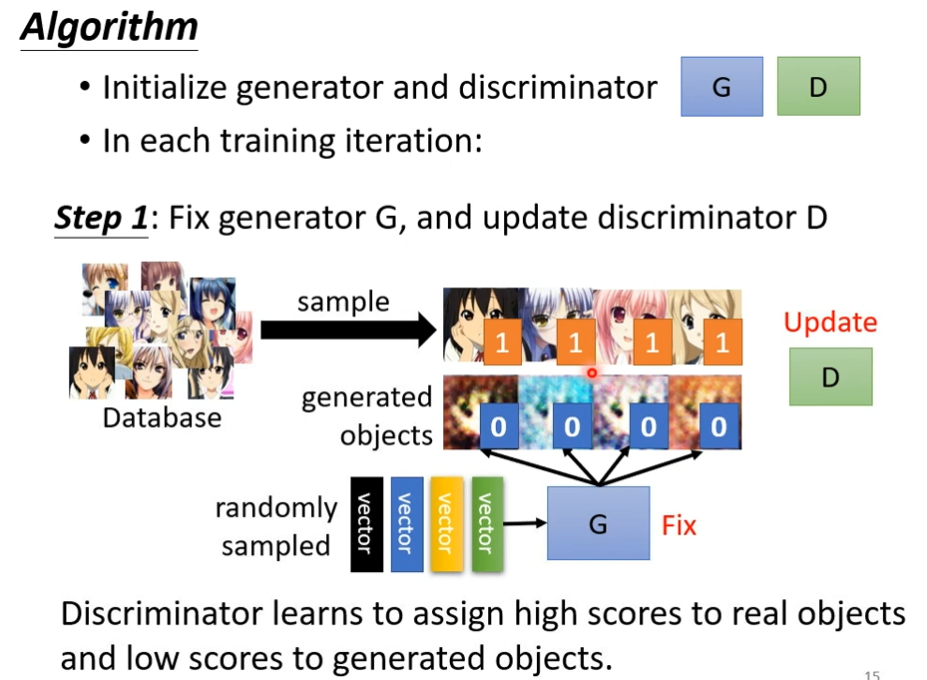
第二步
定住discriminator,改为训练generator(想办法欺骗discriminator),怎样欺骗了?generator用一个高斯分布的向量作为输入,产生一个图片,丢到第一代的discriminator里面,discriminator会给这个图片一个分数,因为discriminator是固定的,我们需要调整的generator的参数,如果调出的参数,discriminator会给高分,意味着generator产生的图片是比较真实的,接下来就是调整参数,让输出的分数越大越好
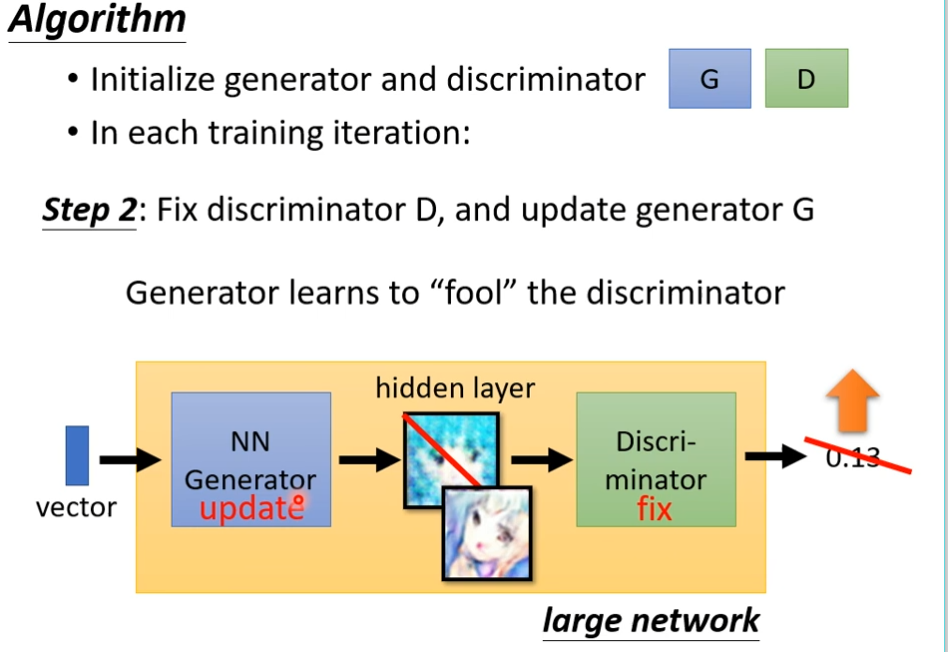
接下来就是反复的训练
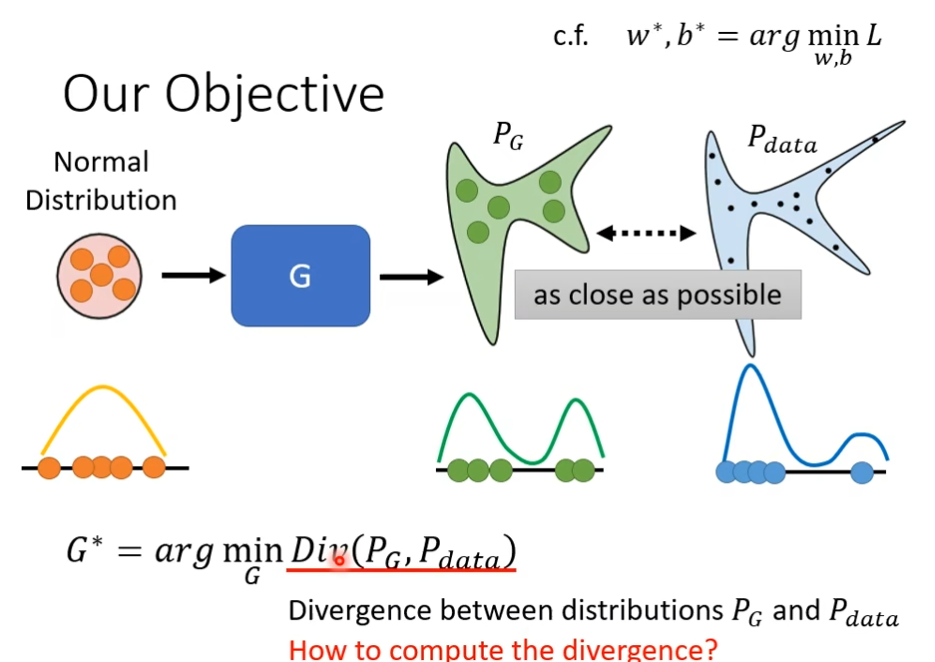
理论介绍与WGAN
为什么GAN的这一番操作,为什么generator和discriminator的互动,可以让我们的generator产生出来像是真正的人脸的图片,我们首先先要弄清楚我们训练的目标是什么,当我们训练network的时候,我们知道要定一个Loss function,定义完后用gradient descent去调你的参数,去minimize那个loss function,就结束了, 在generator里面,我们到底是想要minimize和maxmize什么样的东西呢
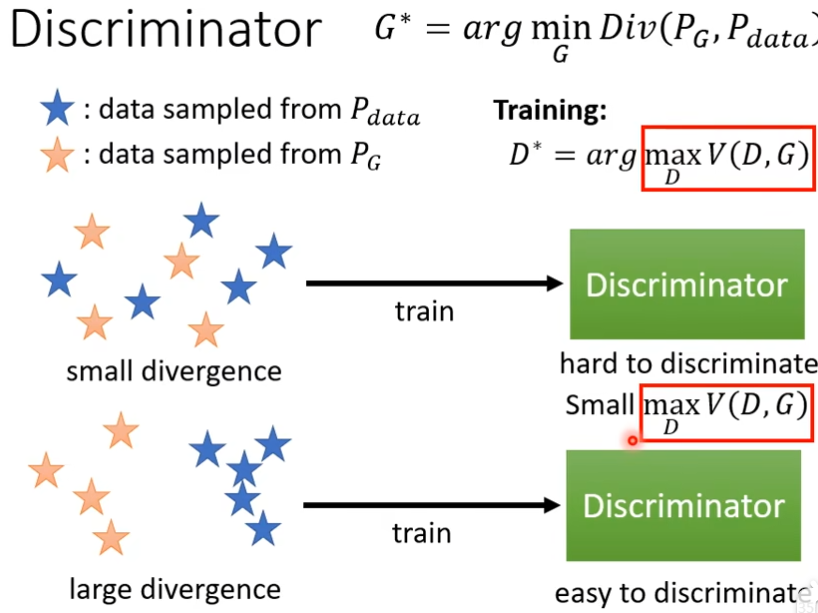
我们想要minimize的东西是这样的,我们有一个generator,给它一大堆的向量,会产生一个比较复杂的分布这里叫做PG,有个真正的data,这个data也形成一个分布叫Pdata,我们期待PG跟Pdata越接近越好,举个例子:我们假设generator的input是一个一维的向量,generator的output也是一个一维的向量,Normal distribution的5个点聚在一块,经过generator后,这个点就散开了,也就产生了一个新的分布,而Pdata真正的分布可能又是另一个样子,这时候我们期待generator的分别和真实数据的分布越接近越好。这里的divergence可以理解成两个distribution之间的某种距离,如果divergence越大,就代表这两个distribu越不像,反之,就代表这两个distribution越相近,divergen就是衡量两个distribution相似度的一个major,现在要找一个generator里面的参数,它可以让PG跟Pdata之间的divergence越小越好。
现在遇到一个问题,我们知道loss值很好算,但是这个divergence怎么算了?如果我们连divergence都不知道怎么算,又怎么能去升级generator呢
但是GAN告诉我们只要你知道怎样从PG跟Pdata这两个分布中,sample东西出来,就有办法计算divergence,而PG跟Pdata是可以sample的,怎样从真正的Data里面sample出图片呢?把图库拿出来,随机sample出来一些图片出来就得到了Pdata,怎么从generator里面产生一些东西出来了?从Normal distribution里挑选一些向量丢到generator里面,注意,这里挑选出来的要是简单的,也就是式子我们是知道,有办法从分布中弄出来的,这些就是PG,这个Nomral distribution可以是正态分布也可以是均匀分布,PG是正态分布经过生成器G变换之后的分布,我们不知道PG跟Pdata实际上完整的组成是什么样子的,在只能做sample的前提之下,居然就估测出了Divergence

这个是要靠discriminator的力量,我们根据PG跟Pdata去训练一个Discriminator,它的目标是看到真实图片会给一个较高的分数,看到generator的data的给一个较低的分数,也可以写成一个式子当做optimization的问题,我们要训练一个Discriminator,这个Discriminator可以去maximize某一个function,我们这边叫做objective function,就是我们要maxmize的东西,叫做objective function,我们要minimize的东西,叫做loss function,这里的E是取期望,意思是用y~Pdata的分布对logD(y)做加权平均,我们希望这个Objective Function V越大越好,就意味着这边的D(Y)越大越好
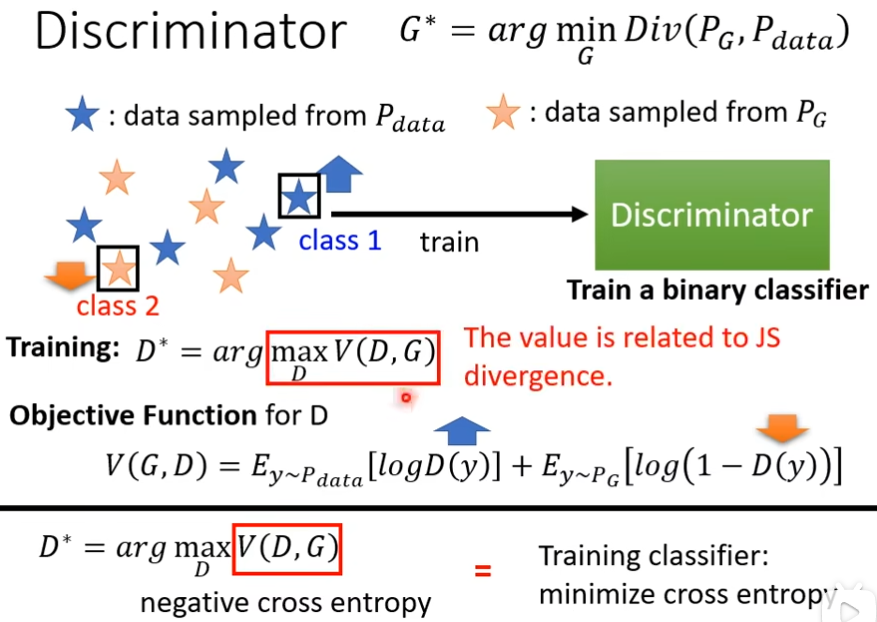

tips
JS divergence
PG跟Pdata它们重复的部分往往非常少,第一个理由是来自Data本身的特性PG跟Pdata都要产生图片,图片是高维空间里面的低维的mainfol

生成器效能评估与条件式生成
如果你要做WGAN的话,效果最好的是Spectral Normalization GAN(SNGAN),虽然有WGAN,但是并不代表说GAN就一定好训练,GAN仍然是很难训练起来的,Discriminator的职责是要分辨真的图片跟产生出来的图片的差异,而Generator要做的是产生假的图片骗过Discriminator,这两个必须互相协作,才能共同成长的,其中一个停止训练,另外一个也会停止
GAN for Sequence Generation
如果使用GAN来生成文字的话,当Decoder发生变化时,Discriminator没有发生变化,也就无法进化
Conditional Generation
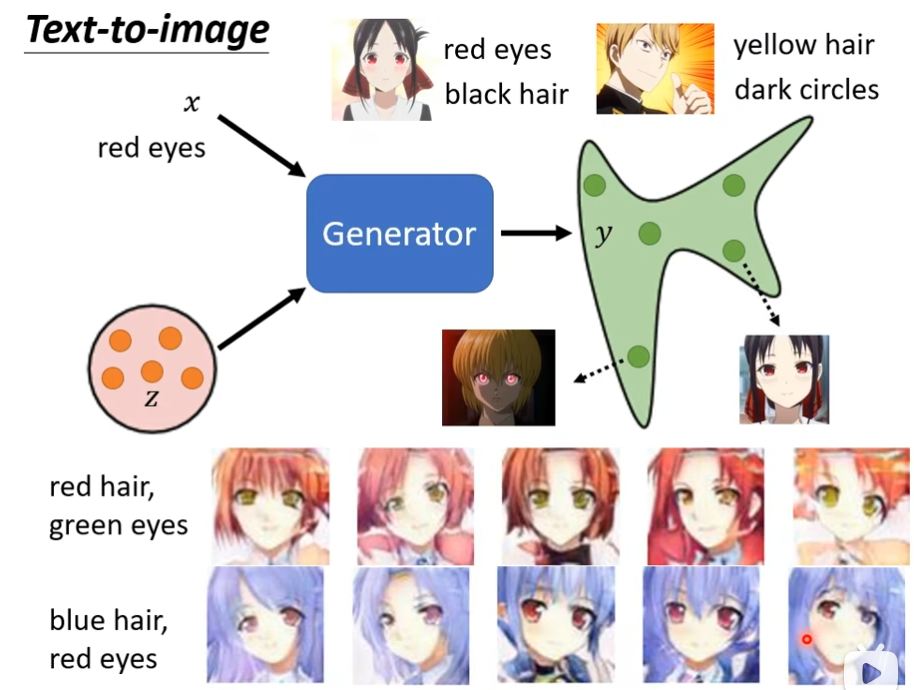
text-to-image
输入图片的要求,可以根据要求生成图片
Contional GAN
现在有两个输入,一个x(一段文字),一个Normal distribution,那么generator会产生一张图片y,那我们需要一个Discriminator,它需要一张图片y当做输入,输出一个数值,这个数值代表输入的图片图像是否是真的,我训练discriminator,让它看到真实的图片就输出1,看到生成的图片就输出0,但是这样的方法没有办法解决Conditional GAN的问题,因为如果我们只有train这个discriminator,这个discriminator只会看y当做输入的话,那么Generator会学到的是它会产生可以骗过Discriminator的非常清晰的图片,但是跟输入完全没有关系,因为它只要能够产生骗过discriminator的图片,那还要这个输入有什么用呢,这时候不管你输入什么文字都不管用了
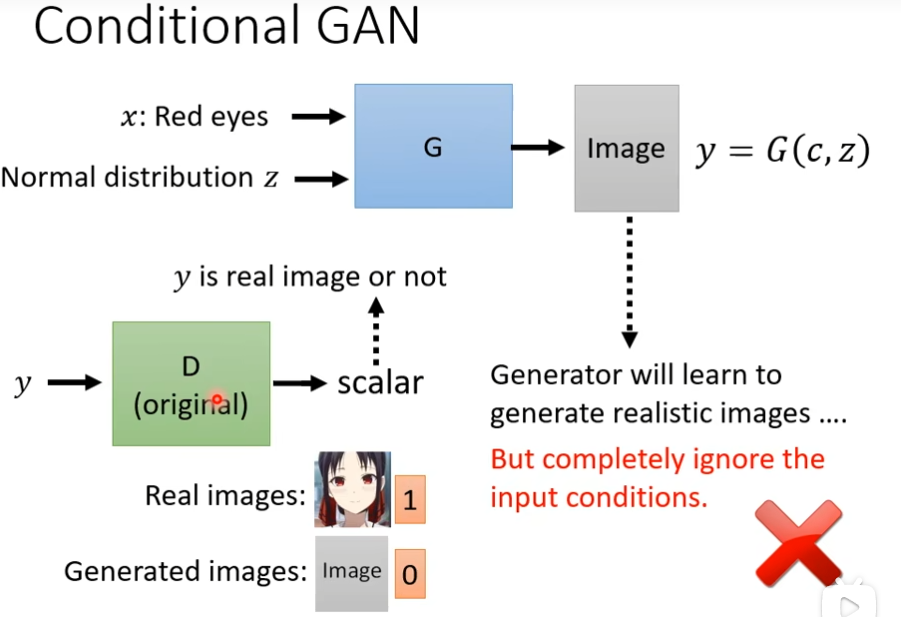
所以discriminator不仅要y当做输入,还要condition x,这时候discriminator不仅要评判这个图片是否真实,还需要看x和y是否相关,只有图片较为真实且和x相匹配才会给高分,所以训练的时候,你需要文字跟影响成对的资料,
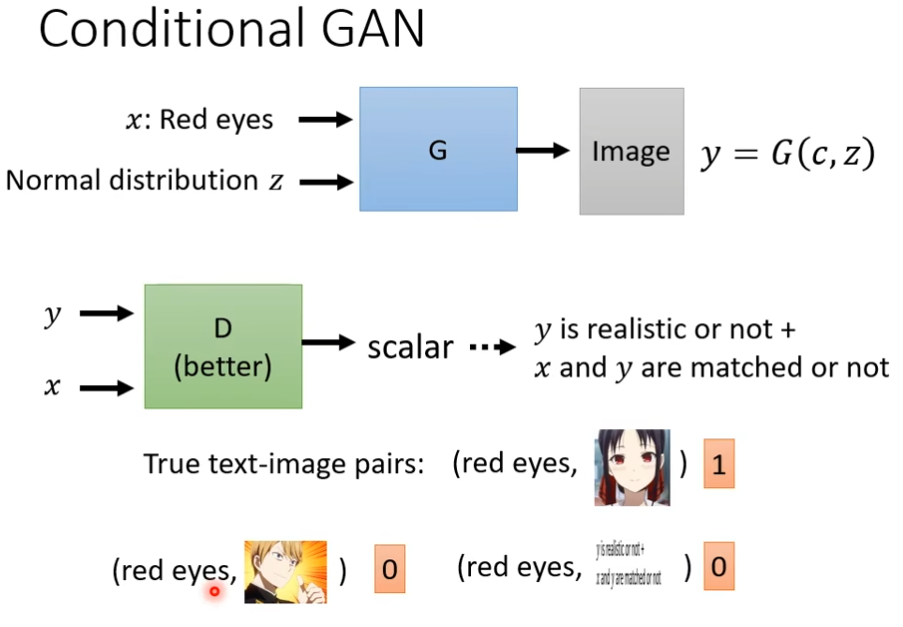
Cycle GAN
到现在为止,我们讲的基本上是supervised learning,network的输入叫做x,输出叫做y,我们需要成对的资料才能训练,但是我们有可能输入是一堆x,输出是一堆y,但是x跟y不成对,我们能不能用这种方式去训练network呢,这种没有成对的资料,我们叫做unlabeled的资料
learning from unparied data
现在x域和y域的图片不配对,没有关联,但是我想根据真人照片转换为二次元的头像怎么办,这里可以用GAN

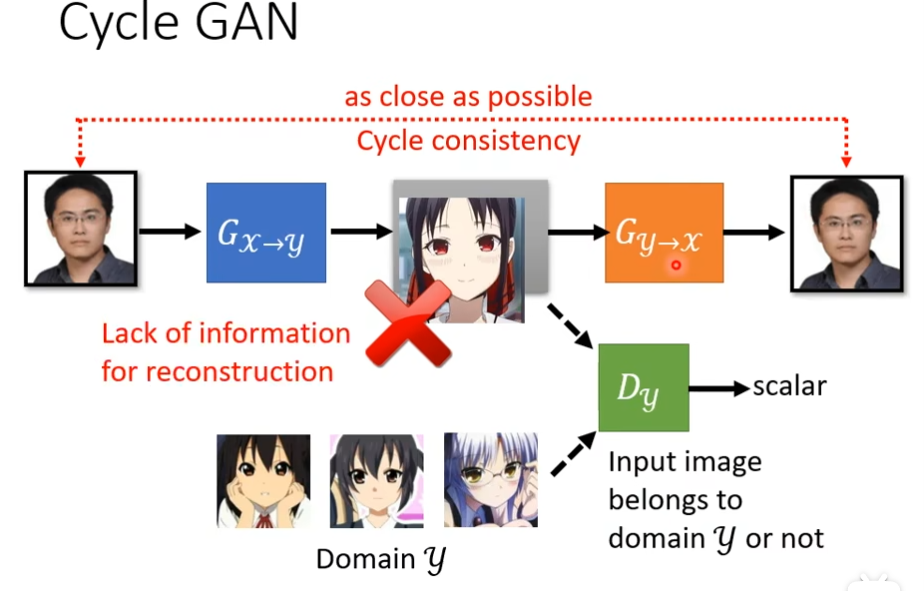
现在输入是x域的分布,输出是y域的分布,现在从x域中,挑选一个照片出来,丢到generator里面,让它产生另外一张图片(y域里的图片),那么怎么让它变为y域里面的分布了?这时候需要discriminator看过y域里面分布的图片,确保discriminator能够分别y域的图片和不是y域的图片,让y域的图片高分,不是y域的图片低分,现在问题是,generator可能真的学到输出y域的图片,但是它输出的图片一定要跟输入有关系吗,如果你没有任何的限制,你的generator也许就把这张图片当做一个gaussian的noise,不管你输入什么都无视它,然后随便输出一个像是二次元的图片,而且discriminator还觉得generator做得很好,如果我们用一般的GAN的做法,只训练一个generator,这个generator输入的分布从高斯分布变成x域的图片,然后训练一个discriminator是远远不够的,虽然generator能产生图片,但是和input的真实图片没有任何关系又有什么用了,和condition GAN的问题一样,但是不能直接套用它那种解决方法,因为现在x和y是不配对的,我们没有成对的资料告诉discriminator怎么样的x和y的组合才是对的

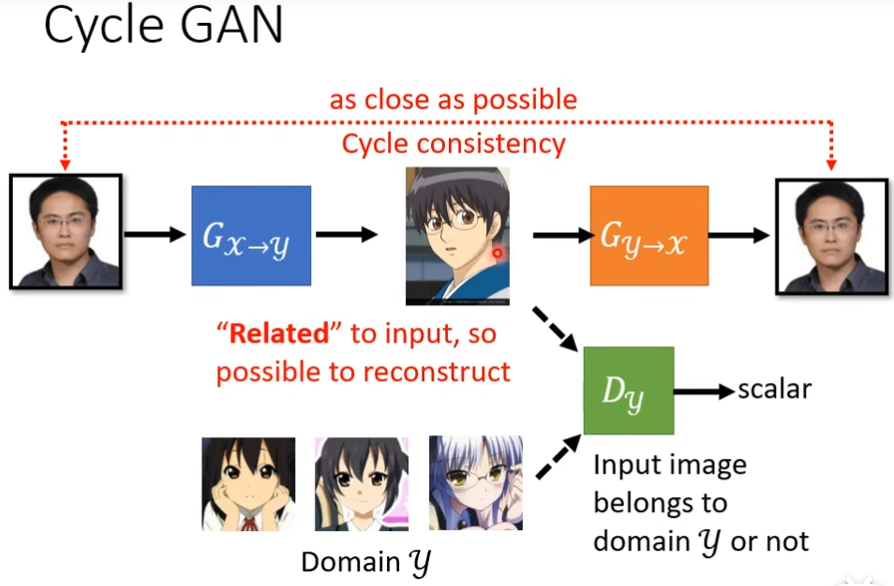
这边一个解决思路是cycle GAN,我们会训练两个generator,第一个是把x域的图片变成y域的图片,第二个是看到y域的图片,把它还原成x域的图片,我们增加一个额外的目标就是把x域的图片转成y域的图,又转成x域的图片,输入和输出要越接近越好,为了让第二个generator产生的图片和原始的图片不能相差太多,第一个generator产生的图片,就不能和输入差太多有点关系才好,比如下图,最起码也得是个男生戴眼镜
像下图才比较好
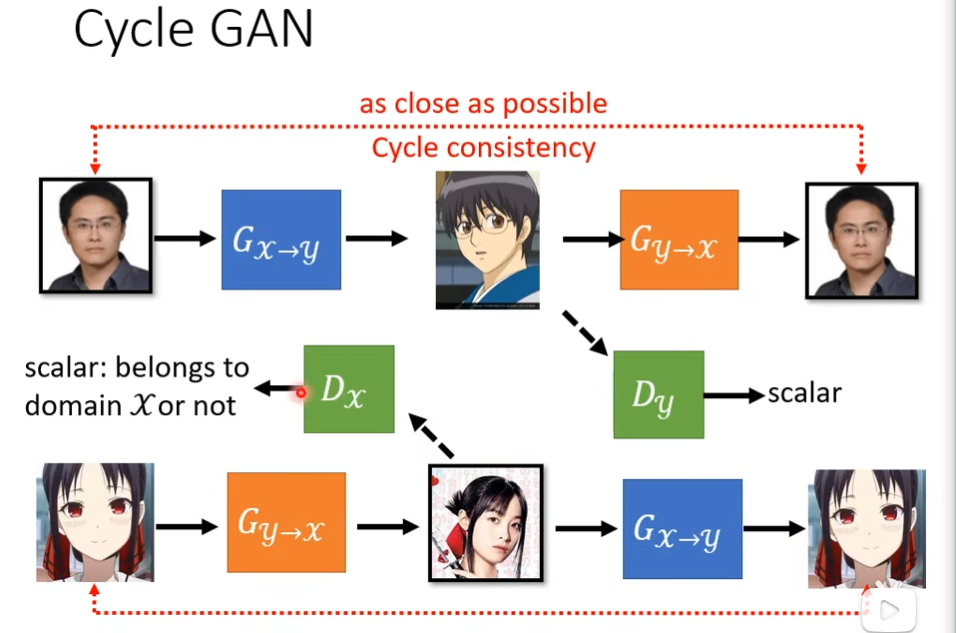
自监督式学习
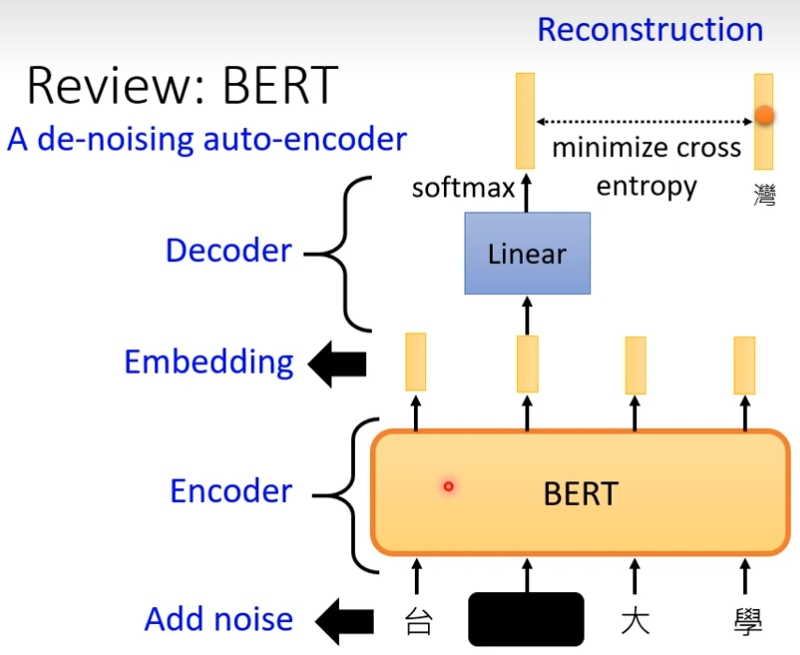
BERT
词语之间意义是有关联的,距离可以表示词与词之间的关系,比如苹果和梨都是水果,它们之间的距离就会比苹果和猫咪更近,这些向量是如何得到的,机器学习的出现,让我们不必为单词设计向量,而是将收集好的句子,文章等数据交给模型,由它为单词们找到最合适的位置,bert就是帮助我们找到词语位置的模型之一,它的诞生源于transformer,既然encoder能将语言的意义很好的抽离出来,那么将这部分独立,也许能很好的对语言做出表示,人们还为bert设计了独特的训练方式,其中之一是有遮挡的训练(masking input)在收集到的词汇中,随机覆盖15%的词汇,让bert去猜这些字是什么,此外还会输入成组的句子(next sentence prediction)由bert判断两个句子是否相连,前者让bert更好的依据语境做出预测,后者让bert对上下文关系有更好的理解,在完成不同的自然语言处理任务时,需要将已经训练好的bert依据任务目标增加不同功能的输出层联合训练,比如文本分类就增加了分类器,输入句子,输出类别。阅读理解增加了一个全连接层,输入问题和文章,输出答案的位置
self-supervised learning
supervised
需要自己指定label
self-supervised
在没有label的情况下,让机器想自己弄label
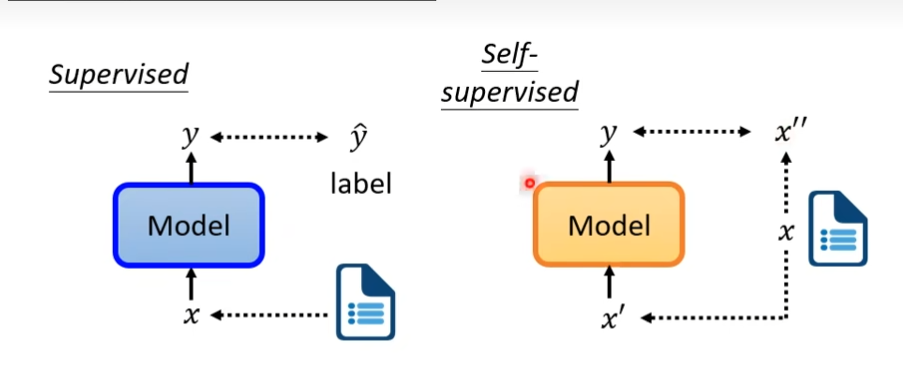
Masking Input
BERT可以做的是输入一排向量,输出一排向量,一般用在NLP,文字处理上,这里的BERT输入是一段文字,接下来要做的是随机把这段文字中的部分挡住,这个挡住指的是把句子里面某个字换成某个特殊的符号或者随便换成某个字,然后这个处理后的文字放到bert中,把挡住部分的输出,做一个线性化,然后做一个softmax,输出一个概率分布,这个分布是所有文字的分布然后“湾”这个one-hot向量做交叉熵,这就像做填空题一样
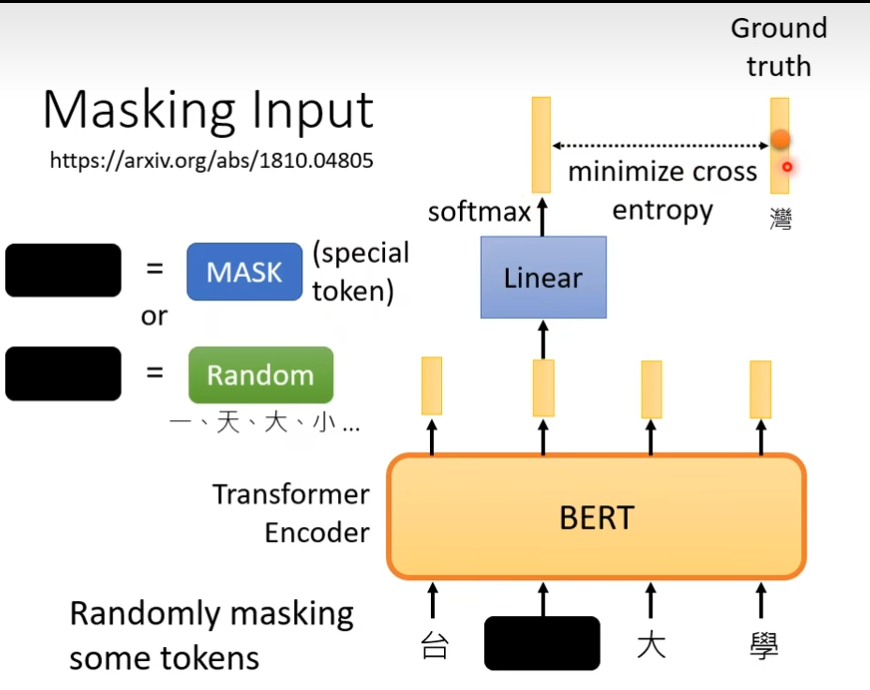
Next Sentence Prediction
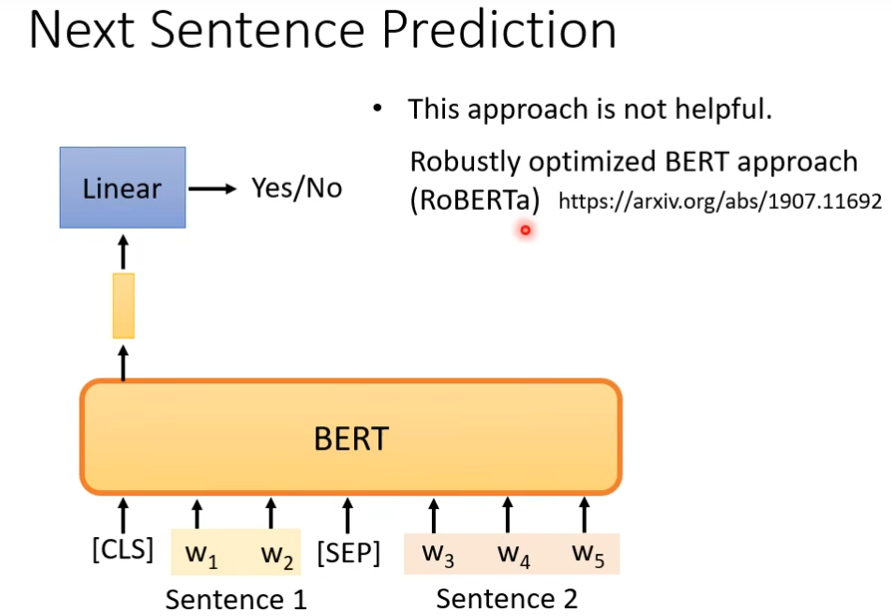
你拿出两个句子,在这两个句子中加个分隔符,然后整个sequence前面加个符号(cls),然后丢到bert里面,然后我们只看CLS的输出,对这个输出做线性化,然后做的是二元的分类问题,它要预测的就是yes或no,这个yes或no指的是这两个句子是不是相接的,相接输出yes
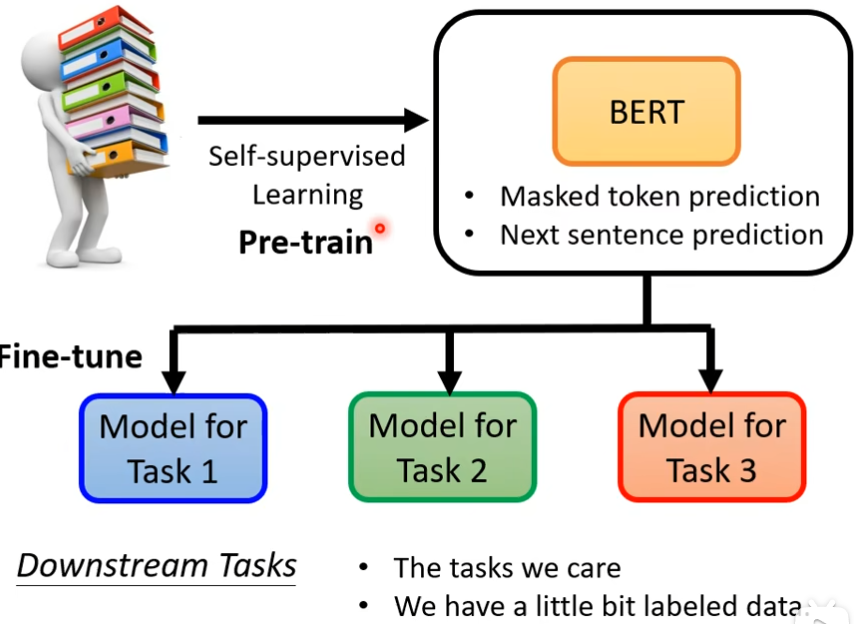
BERT被使用的任务,称为Downstream Tasks,Bert可以分化成各式各样的任务叫做fine-tune,在fine-tune之前产生bert的过程叫做pre-train,上游预训练,下游微调
评价self-supervised learning的好坏,可以通过下面的九个任务

怎样使用BERT
样例1
输入是一个sequence,输出是一个class,例如输入一段话,判断这段话好不好
在一个句子前面放一个CLS,CLS输出一个向量,把它做一个线性变换,通过一个softmax,知道这个输出的类别(正面还是负面),做的时候,你需要有下游任务的标注资料,也就是bert没有办法凭空去接情感分析这个问题,你仍然需要提供标注资料,提供给它大量的句子还有每一个句子是正面的还是负面的,才能去训练这个BERT的模型,在训练的时候,我们把这个bert加上这个线性变化合起来说是一个情感分析模型,在训练的时候的linear部分和bert部分都会用gradient descent去更新,只不过原linear部分的参数是随机初始化的,而bert的初始化的参数是从学习了做填空题的那个bert来的,我们在训练模型的时候,会随机初始化参数,然后通过gradient descent去调那个参数,然后去减少那个loss值,bert这边也要减少loss值就是做情感分类的时候 ,但是我们的参数 不是完全随机初始化的,有了bert唯一随机初始化的只有linear部分,而bert本体是一个巨大的transformer的encoder ,这个network的参数不是随机初始化的, 是把学会做填空题的bert参数拿到这里,当做初始化的参数,这种方法比随机初始化值好
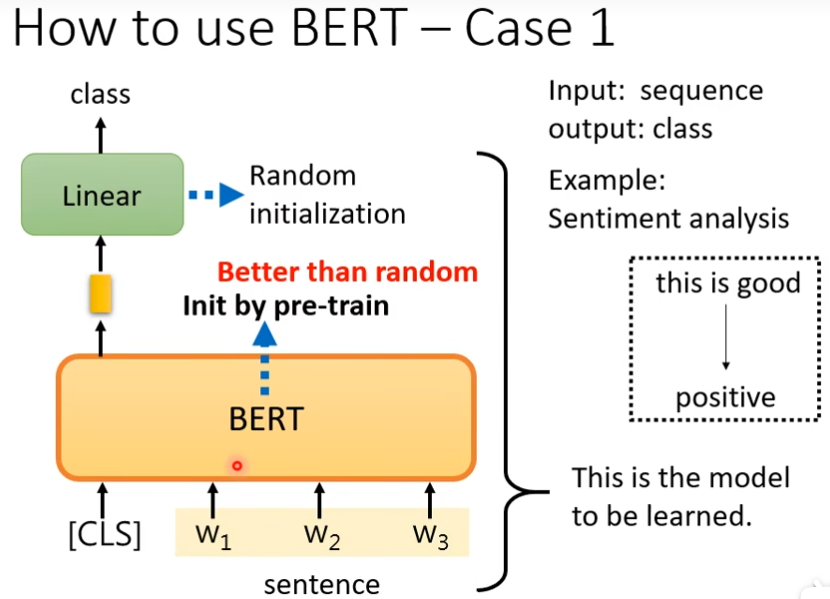
pre-train比随机初始化的参数,loss下降速度快
样例2
输入一个sequence,输出另外一个sequence,但是长度都是一样的,bert的初始化参数还是pre-train的,带cls的应该都是分类任务吧,作用应该就是告诉模型输出的是分类信息
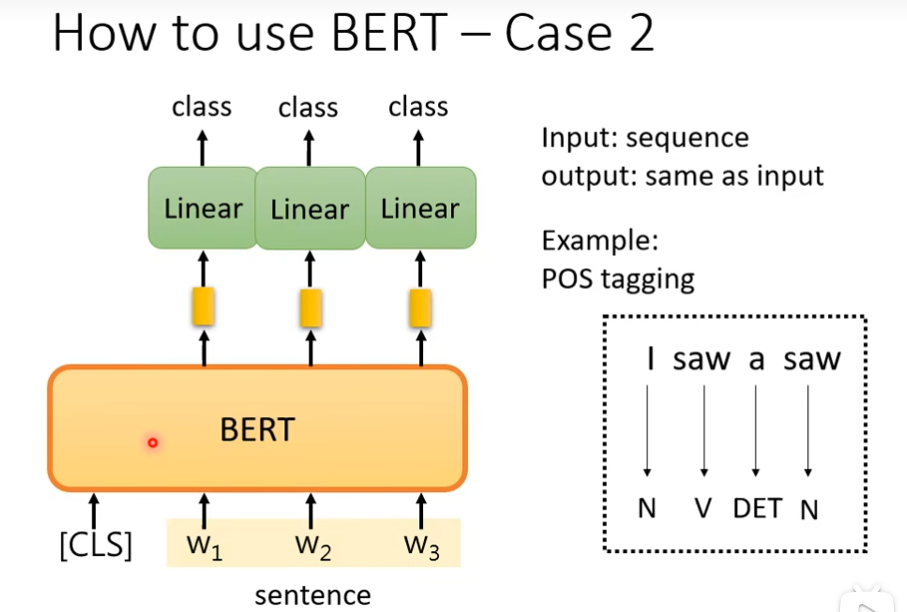
样例3
需要两个句子,一个是前提,一个是假设,机器要做的是能不能从前提推出假设,看这两个句子的关系
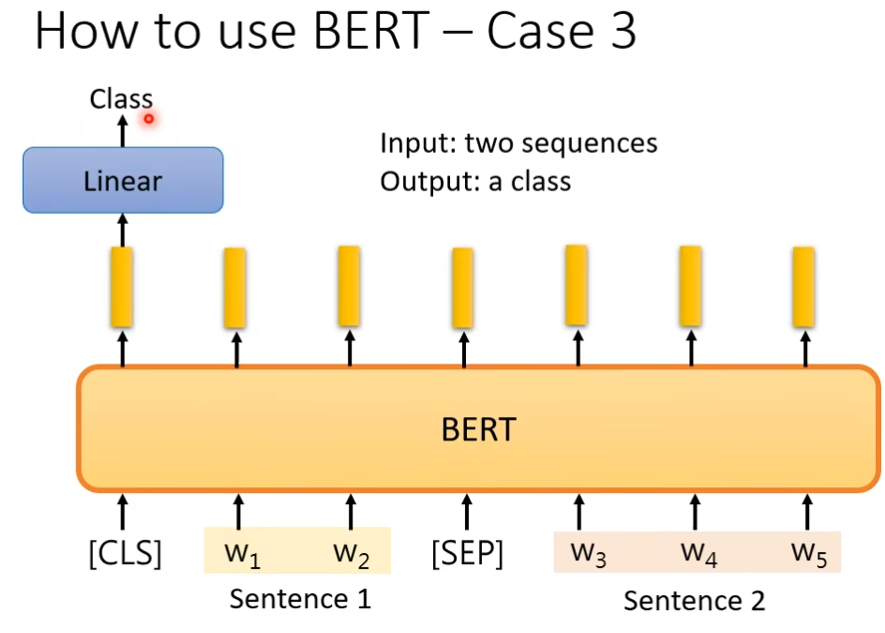
基础架构-TRM的Encoder
BERT和GPT
bert相当于transformer的encoder,gpt相当于transformer的decoder
Auto-encoder(自动编码器)
简介
自动编码器是用于无监督学习高效编码的人工神经网络。 自动编码器的目的是学习一组数据的表示(编码),通常用于降维。
首先你有大量的没有标注的资料,用这些没有标注的资料,你可以去训练一个模型,你必须发明一些不需要标注资料的任务,比如做填空题,比如说预测下一个token,你必须要自己想一些不需要标记资料的任务,给你的模型进行学习,这种不用标注资料的学习,叫做self-supervised learning或者是pre-train,但是经过这个学习后的模型没有什么用,bert只能做填空题,gpt只能把一句话读完,但是你可以用在下游任务中,在这种不用标注就可以学习的任务里面,叫做auto-encoder,可以看做self-supervised learning的一种pre-training的方法
运作流程
假设现在有大量的图片,在auto-encoder里面有两个network,一个叫encoder,一个叫decoder,encoder把一张图片读进来,把这张图片变为一个向量,接下来这个向量会变成decoder的输入。Decoder会产生一张图片,decoder的架构像GAN的generator。现在的目标是希望encoder的输入跟decoder输出越接近越好。假设把图片当做一个向量的话,希望输入的向量和输出的向量的距离越接近越好(reconstruction)。和cycle GAN概念其实是一模一样的,希望所有的图片经过两次转换以后,要跟原来的输出越接近越好。而这个训练的过程完全不需要任何标注资料,你只需要收集大量的图片就可以做这个实验。所以它是一个unsupervised learning的方法。Encoder的输出,有时候我们叫它embedding(深度学习入门篇:说人话,到底什么是Embedding,为什么要引入它 - 知乎 (zhihu.com))。
如何使用
我们如何将训练完后的auto-encoder用在下游任务里面呢?
答:常见的做法是原来的图片你也可以把它看做是一个很长的向量。但是这个向量太长了不好处理,把图片输入到encoder里面,然后输出另外一个向量。这个向量非常大,但是经过encoder后只有十维或者只有100维,然后你拿这个新的向量来做你接下来的任务,也就是图片不再是一个很高维度的向量,它通过encoder的压缩以后,变成一个低维度的向量。你在拿这个低维度的向量做你想做的事
好在哪里
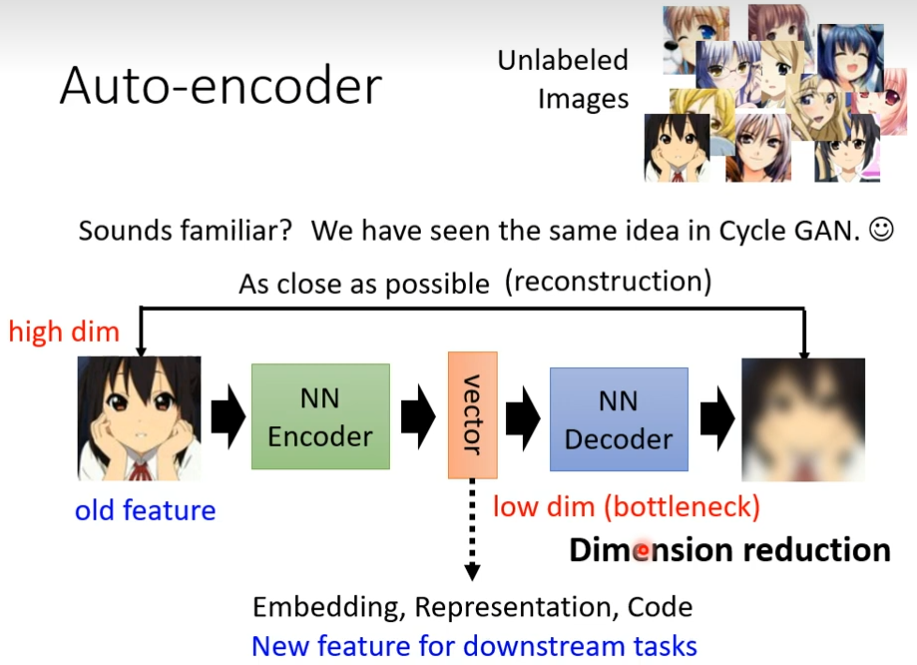
auto encoder这件事要做的事,把图片压缩之后又还原回来,但是还原这件事情为什么能成功呢?因为图片的变化是有限的,所以你在做这个encoder的时候,这里图片是3×3的,我们就可以用两个维度来描述一张图片。虽然图片是3×3,应该要用九个数值才能存储。但是实际上它的变化也许只有两种类型。有些复杂的东西,它只是表面比较复杂。事实上它这这的变化是有限,你只要找出他有限的变化就可以让原本复杂的东西用比较简单的方法来表示它,如果我们可以把复杂的图片用简单的方法表示它,那我们就只需要比较少的训练资料。
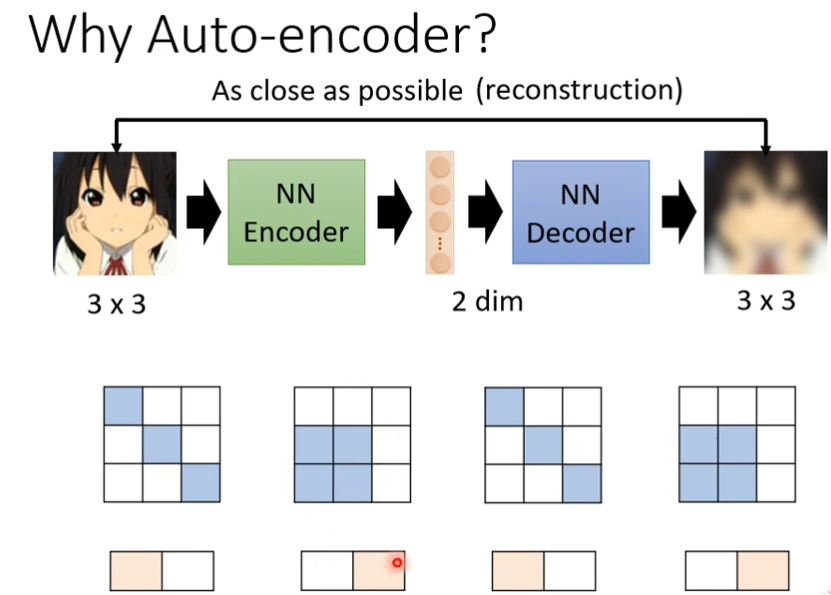
de-nosing auto-encoder
在图片加入杂讯,要机器学会去掉杂讯,bert就是de-nosing auto-encoder
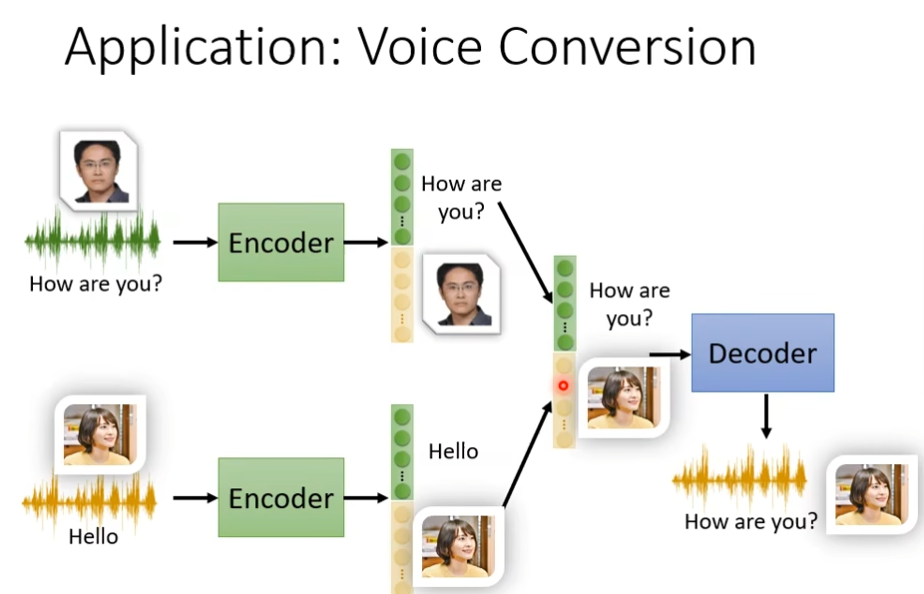
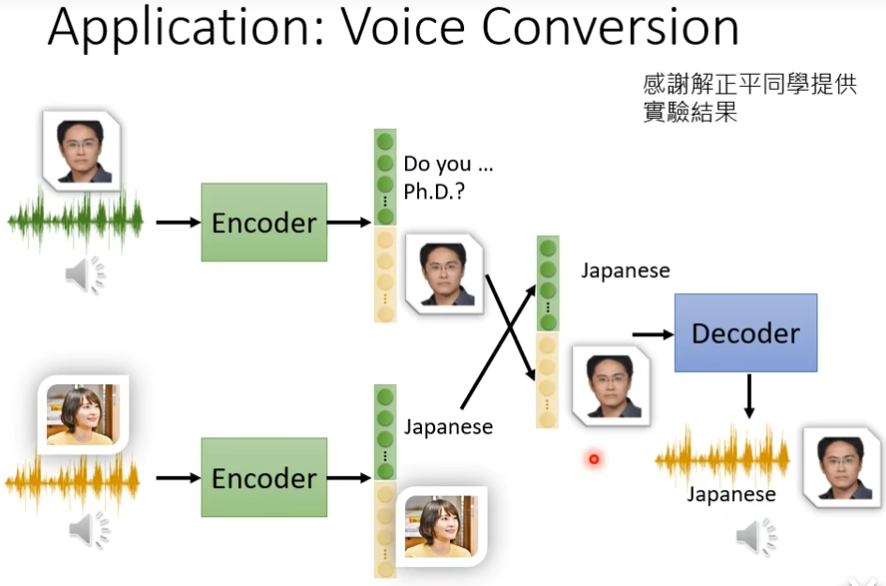
领结变声器与更多应用
Feature disentangle
auto-encoder做的事是。如果输入是一张图片。把图片变为code(encoder输出的向量)。然后再把code变回图片。既然这个Code可以变为图片。那么说明这个code里面有很多资讯。包含图片里面所有的资讯。比如说图片的色泽和纹理等,在其他方面,比如说语音,文字处理上,经过encoder输出的向量包含了这些输入东西里面的所有咨询,但是这也资讯全部纠缠在一个向量里面。我们并不知道一个向量的哪些纬度代表了哪些资讯,比如图片经过encoder输出后可能有纹理和色泽这些咨询,但是我们不知道纹理是属于那个纬度。比如说我们把一段声音信号丢进encoder,他会给我们一个向量,但是这个向量里面哪些维度代表的这句话的内容?哪些维度代表了这句就是谁说的,而Feature disentangle想要做的事情就是我们在训练一个auto-encode的时候,同时有办法知道这个representation(或叫embedding,code),那些维度代表着哪些资讯呢。假如我们让encounter输出100维的向量,我们就说前50维代表了这句话的内容,后五十维代表了这个说话人的特征。这样的技术就叫做feature disentangle。
变声器是如何工作的?
假设现在将我的声音输入到encoder后,使用Feature disentangle技术就可以让我们知道输出的code里面,那些是内容,那些是语者(谁说的),那些是特征,然后将这些特征和你想要变声的人物的特征相结合,然后在放到decoder里面就完成变声了
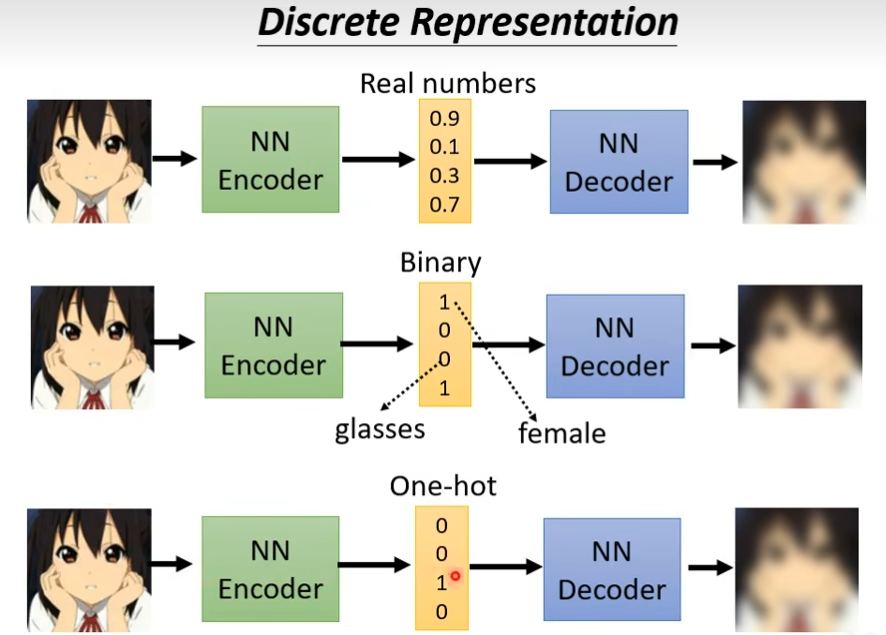
Discrete Representation
输出的这个向量可以是real number可以是binary,还可以是one-hot
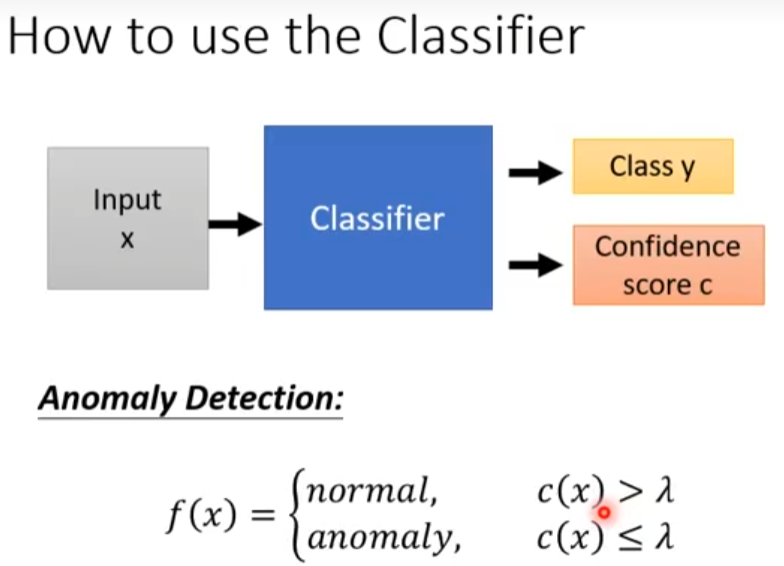
Anomaly Detection(异常检测)
假设你现在有一堆训练资料,Anomaly Detection要做的就是现在来了一笔新的资料,和我们之前在训练里面看到的资料相不相似?也就是你需要有一个异常检测的系统,是通过大量已经看过的资料训练出来的,给他一笔新的资料,如果看起来像是训练资料里面的数据的话,就说他是正常的,否则就是异常的。可以用来做诈骗预防,假设你的训练资料里面有一大笔信用卡的交易记录。大多数都是正常的。那你拿这些正常的信用卡训练的交易记录来训练一个异常检测的模型。当有一笔新的交易记录进来时,你可以让机器帮你判断这笔交易记录是否正常。

异常检测不能进行二元分类
二元分类的思路是定义一个正常数据,定义一个异常数据,训练一个二元分类器,但是这个二元分类不是特别容易,假设这里正常数据是宝可梦,异常数据是不含宝可梦的,关键是不含宝可梦的东西太多了,无法穷举完,所以异常检测不能做二元分类,另外一个原因是你不太容易收集到正常的数据

带有label的classifier
怎么做
我希望这个分类器,不仅仅告诉我属于哪个类,并且也告诉我一个分数,根据这个分数就可以做异常检测这件事情,信心分数越高,概率越大

机器学习的可解释性
机器给出结果的时候,还需要给出为什么给出这个结果,有些模型解释性很强,但是作用不大,像深度学习,虽然很强,但是其解释性不强,就像一个黑盒子一样

目标
现在大家觉得深度学习是一个黑盒,很难知道其运行流程,觉得不应该去相信,但是,现实中很多东西都是黑盒,比如我们的脑子,你相信某个人等。人们需要解释性可能是觉得一个理由很重要

Explainable ML
根据某张图片来回答问题叫做local explanation,当你给一堆参数的时候,对这些参数而言,什么样的东西叫做一只猫叫做global explanation

