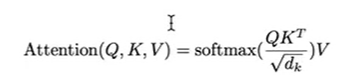Transformer实现
Seq2Seq模型
seq2seq一般由encoder,attention,decoder组成,encoder和decoder之间是依赖attention来建立关联性的
18、深入剖析PyTorch中的Transformer API源码_哔哩哔哩_bilibili
基础模块
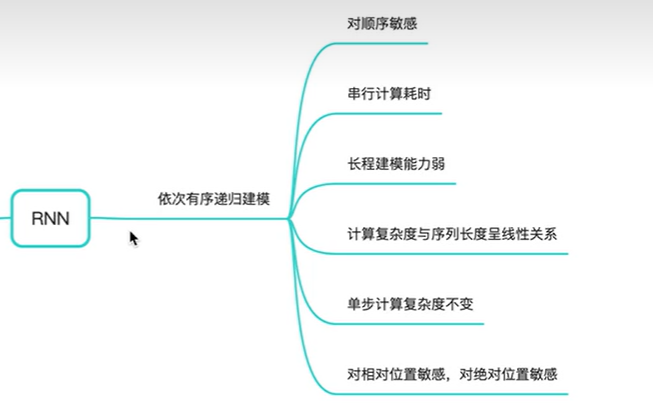
CNN
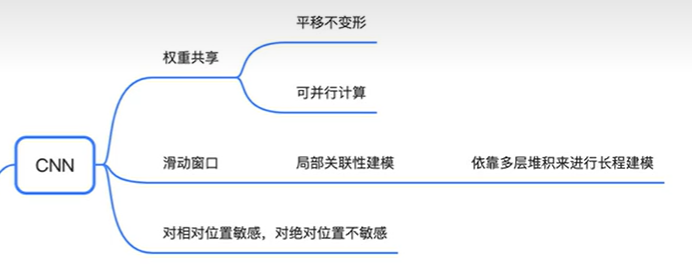
RNN
Transformer
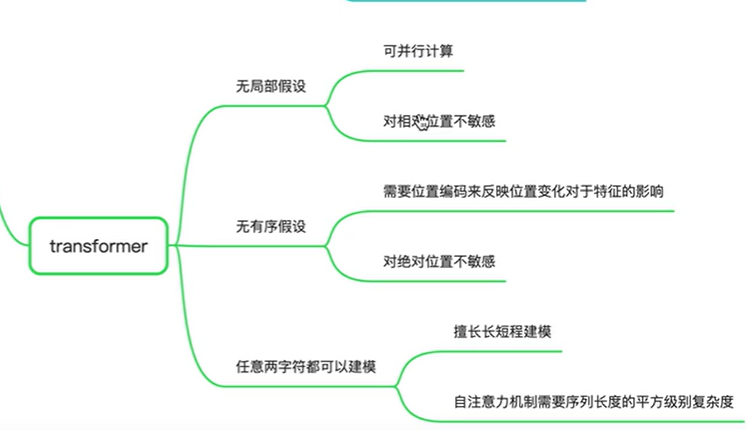
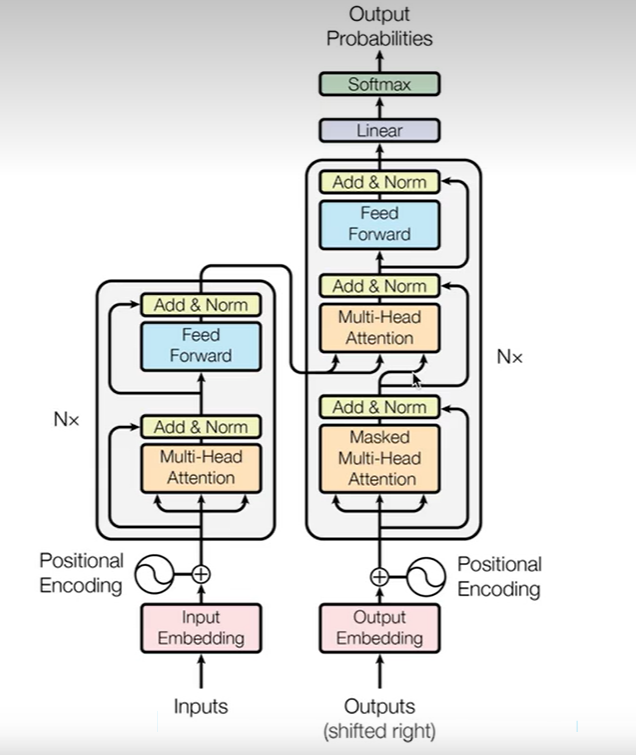
Transformer
Encoder部分
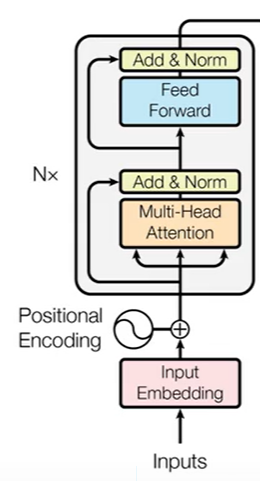
Encoder是以字符作为输入,以状态作为输出。
首先是由输入字符得到的Embedding以及位置编码作为输入,Encoder由N层构成,每个block里面包括两个部分,第一个部分是Mulit-Head,就是序列对序列自身的一个表征运算,第二个部分是一个前馈神经反馈网络,就是每个位置上都有一个独立的,但是相同的MLP去算出新的表征
Transformer对局部位置和全局位置不敏感,所以需要增加一个带有位置信息的向量,加到每一个input Embedding上面去,使得对位置敏感
Input word embedding

就是将one-hot乘以Embedding得到一个稠密的连续向量,来表示单词,可以节约内存
Position encoding
multi-head self-attention

feed-forward network

代码实现
导包
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
关于word embedding
# 先构建source_length和target_length,然后根据长度随机生成索引
batch_size = 2
# 单词表大小
max_num_src_words = 8
max_num_tgt_words = 8
# 原句子的长度
src_len = torch.Tensor([2, 4]).to(torch.int32)
# 目标句子的长度
tgt_len = torch.Tensor([4, 3]).to(torch.int32)
# 单词索引构成的句子
src_seq = [torch.randint(1,max_num_src_words,(L,)) for L in src_len ]
tgt_seq = [torch.randint(1,max_num_tgt_words,(L,)) for L in tgt_len ]
print(src_seq,tgt_seq)

- 单词索引是什么
假设现在src_len = [2,3],说明里面有两个句子,第一个句子的长度是2,第二个句子的长度是3,长度是2说明句子里面有2个单词,那么怎么表示这个单词呢?通过单词索引,假设这里的单词索引是[1,8](为什么这里的长度是2 ?因为有两个单词,所以这里的长度才为2),那么这个1和8又是什么?这里的1和8分别对应不同的单词。举个栗子
a = "thank you"
上面的句子长度是2,这里的src_len = 2,通过单词表(可以理解存储单词的地方,通过索引来获取单词信息),知道thank的索引是1,you的索引是8,那么src_seq就可以表示为[1,8]
我们发现上面的src_seq和tgt_seq的长度不等,src_seq的第一个句子是[2,1]长度为2,而tgt_seq的第一个句子是[6,2,6,2]长度为4,这就很难办,需要让它们的长度一致
# 填充,使得句子长度一致
# 序列的最大长度
max_src_seq_len = 5
max_tgt_seq_len = 5
# 单词索引构成源句子和目标句子,构建batch,并且做了padding,默认值为0
src_seq = torch.cat([torch.unsqueeze(F.pad(torch.randint(1,max_num_src_words,(L,)),(0,max(src_len) - L)),0) for L in src_len ])
tgt_seq = torch.cat([torch.unsqueeze(F.pad(torch.randint(1,max_num_tgt_words,(L,)),(0,max(tgt_len) - L)),0) for L in tgt_len ])
print(src_seq)
print(tgt_seq)

# 现在把这个序列拼接起来
# 我们需要使用到torch.cat()函数
# 单词索引构成源句子和目标句子,构建batch,并且做了padding,默认值为0
src_seq = torch.cat([torch.unsqueeze(F.pad(torch.randint(1,max_num_src_words,(L,)),(0,max_src_seq_len - L)),0) for L in src_len ])
tgt_seq = torch.cat([torch.unsqueeze(F.pad(torch.randint(1,max_num_tgt_words,(L,)),(0,max_tgt_seq_len - L)),0) for L in tgt_len ])
print(src_seq)
print(tgt_seq)

- torch.cat()
# 假设我现在想把a和b连接在一起组成一维的向量,那么a和b的维度必须是一样的,且都是一维的
a = torch.tensor([1])
b = torch.tensor([2])
c = torch.cat((a,b))
c
# tensor([1, 2])
- 其他的类似cat的方法

# 构造embedding
model_dim = 8 # 模型的特征大小
src_embedding_table = nn.Embedding(max_num_src_words+1,model_dim) # 加1是加padding,,如果不加1,那么padding的embedding怎么表示了?
tgt_embedding_table = nn.Embedding(max_num_tgt_words+1,model_dim) # 加1是加padding
src_embedding = src_embedding_table(src_seq)
tgt_embedding = tgt_embedding_table(tgt_seq)
print(src_embedding_table.weight)

Embedding — PyTorch 1.12 documentation
# 查看单词索引的wordembedding
print(src_seq) # 单词的索引
print(src_embedding_table(src_seq)) # 单词的embedding

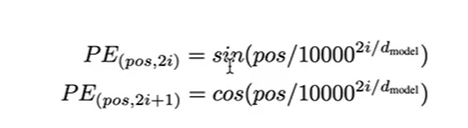
根据上图知道这应该是一个二维矩阵,然后根据公式实现下面代码
# 构造position embedding
max_position_len = 5
pos_mat = torch.arange(max_position_len).reshape((-1,1)) # 变为一列
i_mat = torch.arange(0,8,2).reshape((1,-1)) / model_dim # 变为一行
i_mat = torch.pow(10000,i_mat)
pe_embedding_table = torch.zeros(max_position_len,model_dim)
# 对偶数列赋值
pe_embedding_table[:,0::2] = torch.sin(pos_mat / i_mat)
# 对奇数列赋值
pe_embedding_table[:,1::2] = torch.cos(pos_mat / i_mat)
print(pe_embedding_table)

# 使用torch.api的embedding来构建
pe_embedding = nn.Embedding(max_position_len,model_dim)
pe_embedding.weight = nn.Parameter(pe_embedding_table,requires_grad=False)
print(torch.allclose(pe_embedding.weight,pe_embedding_table))
# true
position encoding
positional encoding位置编码详解:绝对位置与相对位置编码对比_夕小瑶的博客-CSDN博客_相对位置编码
位置编码(PE)是如何在Transformers中发挥作用的|序列|索引|余弦|seq_网易订阅 (163.com)
位置编码
位置编码(Positional encoding)可以告诉Transformers模型一个实体/单词在序列中的位置或位置,这样就为每个位置分配一个唯一的表示。
# 这里需要传入的是位置索引,因为单词索引值可能会超出这个postion_embedding的范围,但是为什么是位置索引了?
# 这里的位置索引对应的单词在整句话中的位置,位置编码将位置映射到一个向量
src_pos = torch.cat([torch.unsqueeze(torch.arange(max(src_len)),0) for _ in src_len]).to(torch.int32)
tgt_pos = torch.cat([torch.unsqueeze(torch.arange(max(tgt_len)),0) for _ in tgt_len]).to(torch.int32)
print(src_pos)
src_pe_embedding = pe_embedding(src_pos)
tgt_pe_embedding = pe_embedding(tgt_pos)
print(src_pe_embedding)

构造encoder的self-attention mask
# 有效位置,因为有的是填充0
valid_encoder_pos = [torch.ones(L) for L in src_len ]
print(valid_encoder_pos)
# 第一个句子中前2个有效位,第二个句子前4个是有效位
# [tensor([1., 1.]), tensor([1., 1., 1., 1.])]
# 因为训练是按照句子最长长度进行训练,所以还需要填充
valid_encoder_pos = [F.pad(torch.ones(L),(0,max(src_len)-L)) for L in src_len]
print(valid_encoder_pos)
# [tensor([1., 1., 0., 0.]), tensor([1., 1., 1., 1.])]
# 拼接
valid_encoder_pos = torch.cat([torch.unsqueeze(F.pad(torch.ones(L),(0,max(src_len)-L)),0) for L in src_len])
print(valid_encoder_pos)
# tensor([[1., 1., 0., 0.],
# [1., 1., 1., 1.]])
# 扩维
valid_encoder_pos = torch.unsqueeze(torch.cat([torch.unsqueeze(F.pad(torch.ones(L),(0,max(src_len)-L)),0) for L in src_len]),2)
print(valid_encoder_pos.shape) # torch.Size([2, 4, 1])
# 两个矩阵的两两相乘,就能得到之间的关联性
valid_encoder_pos_matrix = torch.bmm(valid_encoder_pos,valid_encoder_pos.transpose(1,2))
print(valid_encoder_pos_matrix.shape) # torch.Size([2, 4, 4])
# 单词之间的关联性
print(src_len) # tensor([2, 4], dtype=torch.int32)
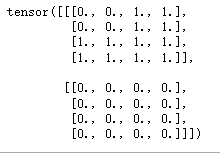
print(valid_encoder_pos_matrix)

这里有两个句子,第一个句子长度为2,从矩阵可以看出,首先[0][0]和[0][1]都是1,说明它们之间有关联,[0][2]和[0][3]都是0,说明第一个单词和后面没关联(因为后面的都是填充),第3行和第4行都是0,因为都是填充
接下来看下面一个,因为这句话里有4个单词,所以单词与单词之间都有关联性,所以这里全部都是1
# 构建无效矩阵
invalid_encoder_pos_matrix = 1 - valid_encoder_pos_matrix
invalid_encoder_pos_matrix
mask_encoder_self_attention = invalid_encoder_pos_matrix.to(torch.bool)
mask_encoder_self_attention

# 单词与单词之间的关联性,注定是个方阵,另外shape还得和mask_encoder_self_attention一样
score = torch.randn(batch_size,max(src_len),max(src_len))
print(score.shape,mask_encoder_self_attention.shape) # torch.Size([2, 4, 4]) torch.Size([2, 4, 4])
masked_score = score.masked_fill(mask_encoder_self_attention,-1e9)
prob = F.softmax(masked_score,-1)
print(src_len)
print(score)
print(masked_score)
print(prob)

Decoder部分
Decoder是以上一时刻的字符作为输入,把Encoder的状态作为输入的一部分,最后返回字符预测的概率
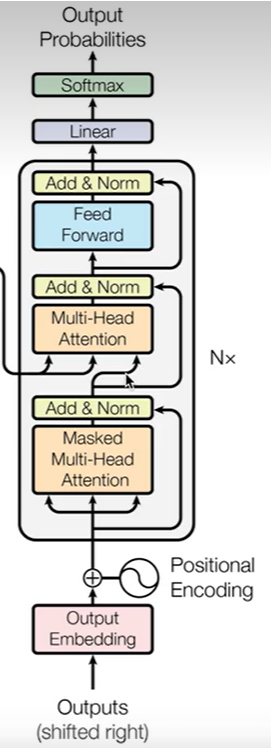
Decoder也是由多个BLOCK组成,这里有三个模块
最下面的模块是由Masked Multi-Head Attention构成,同样以输入字符的Embedding和位置编码来作为输入,然后通过Masked Multi-Head做一个自身表征
第二个模块是交叉注意力,它是以掩码多头注意力的输出作为query,然后以Encoder的输出作为key和value来算出Encoder序列和Decoder序列之间的关联性,然后算出一个表征,也就是算decoder输入序列和encoder输入序列之间的关系,将这个关系变为一个权重,再跟Encoder的状态做一个加权求和
第三部分是一个前向反馈网络
代码实现
构造intra-attention的mask
# Q @ K^T shape bs*tgt_seq_len*src_seq_len
valid_encoder_pos = torch.unsqueeze(torch.cat([torch.unsqueeze(F.pad(torch.ones(L),(0,max(src_len)-L)),0) for L in src_len]),2)
valid_decoder_pos = torch.unsqueeze(torch.cat([torch.unsqueeze(F.pad(torch.ones(L),(0,max(tgt_len)-L)),0) for L in tgt_len]),2)
print(valid_encoder_pos.shape)
print(valid_decoder_pos.shape)
# 两个有效矩阵的交互性
valid_cross_pos_matrix = torch.bmm(valid_decoder_pos,valid_encoder_pos.transpose(1,2))
print(valid_cross_pos_matrix)
invalid_cross_pos_matrix = 1 - valid_cross_pos_matrix
mask_cross_attention = invalid_cross_pos_matrix.to(torch.bool)
print(mask_cross_attention)

构造decoder self-attention的mask
掩码自注意机制

# 生成下三角矩阵,在decoder预测第一个位置的时候,decoder的输入只给一个字符,解码器的输入要往左shift一位刚好和输出有一个偏移,0就是掩码
tri_matrix = [torch.tril(torch.ones(L,L)) for L in tgt_len]
print(tri_matrix)

例如第一行中,第一个位置是1,表示是decoder的输入,后面的0是输出,第二行,前两个1都是输入,来预测第三个0的输出
valid_decoder_tri_matrix = torch.cat([torch.unsqueeze(F.pad(torch.tril(torch.ones((L,L))),(0,max(tgt_len) - L,0,max(tgt_len) - L)),0) for L in tgt_len])
print(valid_decoder_tri_matrix.shape)
invalid_decoder_tri_matrix = 1-valid_decoder_tri_matrix
invalid_decoder_tri_matrix = invalid_decoder_tri_matrix.to(torch.bool)
print(invalid_decoder_tri_matrix)
score = torch.randn(batch_size,max(tgt_len),max(tgt_len))
# 将invalid_decoder_tri_matrix中False填充为-1e9
masked_score = score.masked_fill(invalid_decoder_tri_matrix,-1e9)
prob = F.softmax(masked_score,-1)
print(tgt_len)
print(prob)

构建scaled self-attention
# 构建scaled self-attention
def scaled_dot_product_attention(Q,K,V,attn_mask):
# shape of Q,K,V bs * num_head,seq_len,model_dim / num_head
score = torch.bmm(Q,K.transpose(-2,-1)) / torch.sqrt(model_dim)
masked_score = score.masked_fill(score * attn_mask,-1e9)
prob = F.softmax(masked_score,-1)
context = torch.bmm(prob,V)
return context