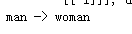seq2seq的Pytorch实现
seq2seq的pytorch实现
Seq2Seq的PyTorch实现 - mathor (wmathor.com)
导包
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Data
定义训练设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
处理文字,生成语料库,定义一些超参数
letter = [c for c in 'SE?abcdefghijklmnopqrstuvwxyz']
letter2idx = {n:i for i,n in enumerate(letter)}
# 一个简单的机器翻译任务
seq_data = [['man','woman'],['black','white'],['king','queen'],['girl','boy'],['up','down'],['high','low']]
# n_step保存单词最长长度
n_step = max([max(len(i),len(j)) for i,j in seq_data])
n_hidden = 128
n_class = len(letter2idx)
batch_size = 3
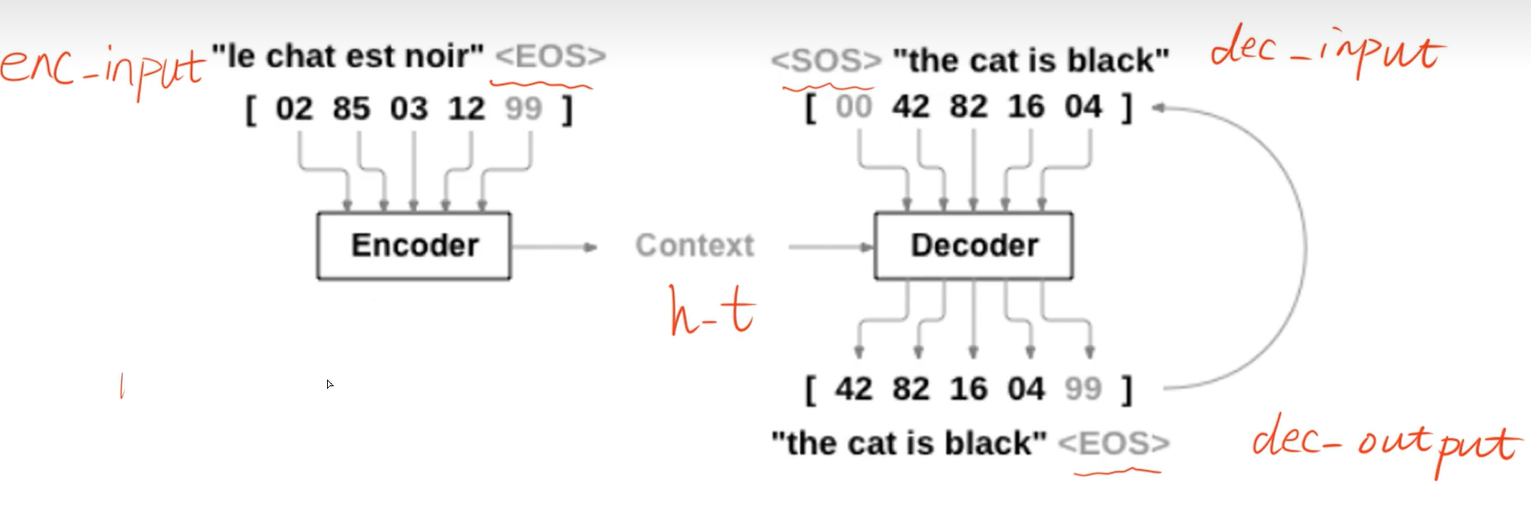
对单词长度不够的,用“?”填充,Decoder的输入数据末尾加终止标志"E",Decoder的输入数据的开头加开始标志"S"。然后把每个seq(里面只有2个单词)转换为one-hot编码
def make_data(seq_data):
enc_input_all,dec_input_all,dec_output_all = [],[],[]
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + '?' * (n_step - len(seq[i])) # 'man??', 'women'
enc_input = [letter2idx[n] for n in (seq[0] + 'E')] # ['m', 'a', 'n', '?', '?', 'E']
dec_input = [letter2idx[n] for n in ('s' + seq[1])] # ['S', 'w', 'o', 'm', 'e', 'n']
dec_output = [letter2idx[n] for n in (seq[1] + 'E')] # ['w', 'o', 'm', 'e', 'n']
enc_input_all.append(np.eye(n_class)[enc_input])
dec_input_all.append(np.eye(n_class)[enc_input])
dec_output_all.append(dec_output)
return torch.Tensor(enc_input_all),torch.Tensor(dec_input_all),torch.LongTensor(dec_output_all)
enc_input_all,dec_input_all,dec_output_all = make_data(seq_data)
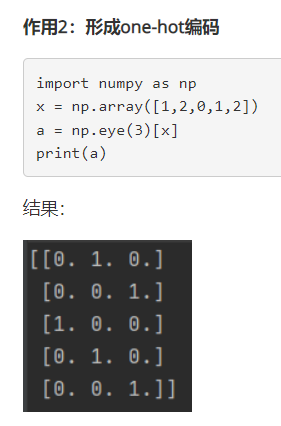
- 创建独热编码
python | np.eye()函数_淳延的博客-程序员信息网_np.eye - 程序员信息网 (4k8k.xyz)

这里有3个数据需要返回,所以需要自定义DataSet,继承torch.utils.data.Dataset类,然后实现__len__方法和__getitem__方法
class TranslateDataSet(Data.Dataset):
def __init__(self,enc_input_all,dec_input_all,dec_output_all):
self.enc_input_all = enc_input_all
self.dec_input_all = dec_input_all
self.dec_output_all = dec_output_all
def __len__(self):
return len(self.enc_input_all)
def __getitem__(self,idx):
return self.enc_input_all[idx],self.dec_input_all[idx],self.dec_output_all[idx]
# 这里的getitem的方法必须有,不然的话,loader会报错
loader = Data.DataLoader(TranslateDataSet(enc_input_all,dec_input_all,dec_output_all),batch_size,True)
定义seq2seq模型
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq,self).__init__()
self.encoder = nn.RNN(input_size=n_class,hidden_size = n_hidden,dropout=0.5)
self.decoder = nn.RNN(input_size=n_class,hidden_size = n_hidden,dropout=0.5)
self.fc = nn.Linear(n_hidden,n_class)
def forward(self,enc_input,enc_hidden,dec_input):
enc_input = enc_input.transpose(0,1)
dec_input = dec_input.transpose(0,1)
_,h_t = self.encoder(enc_input,enc_hidden)
outputs,_ = self.decoder(dec_input,h_t)
model = self.fc(outputs)
return model
model = Seq2Seq().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
- transpose作用
transpose函数中的两个参数是要互换的轴,transpose只能对两个维度进行转换
https://icode.best/i/36133945644288
训练模型
for epoch in range(5000):
for enc_input_batch,dec_input_batch,dec_output_batch in loader:
h_0 = torch.zeros(1,batch_size,n_hidden).to(device)
(enc_input_batch,dec_input_batch,dec_output_batch) = (enc_input_batch.to(device),dec_input_batch.to(device),dec_output_batch.to(device))
pred = model(enc_input_batch,h_0,dec_input_batch)
pred = pred.transpose(0,1)
loss = 0
for i in range(len(dec_output_batch)):
loss += criterion(pred[i],dec_output_batch[i])
if (epoch + 1) % 1000 == 0:
print("Epoch:",'%04d' % (epoch+1),'cost=','{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()

测试
def translate(word):
enc_input,dec_input,_ = make_data([[word,'?'*n_step]])
enc_input,dec_input = enc_input.to(device),dec_input.to(device)
hidden = torch.zeros(1,1,n_hidden).to(device)
output = model(enc_input,hidden,dec_input)
# output : [n_step+1, batch_size, n_class] 这里的batch不是上面定义的,而是根据input的大小决定的
print(output.data)
print(output.data.max(2,keepdim=True))
predict = output.data.max(2,keepdim=True)[1]
decoded = [letter[i] for i in predict]
translated = ''.join(decoded[:decoded.index('E')])
return translated.replace('?','')
print('man ->', translate('man'))
- output.data

- output.data.max(2,keepdim=True)
输出包括2个元素,一个是最大的值,一个是该值在list中索引

- predict

- 输出结果