
RNN原理及其复现
RNN figures
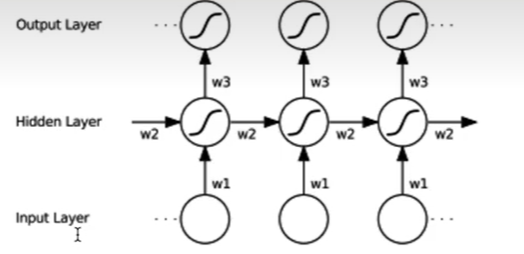
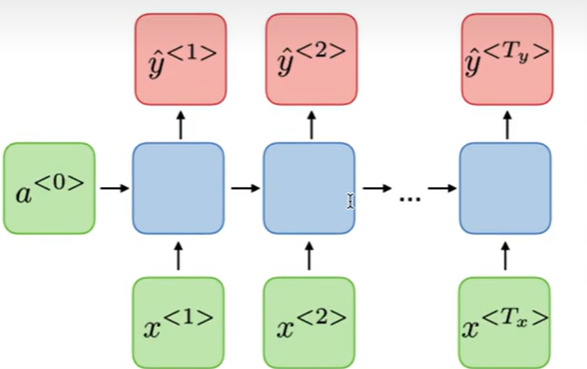
单层RNN
记忆单元和过去相关和未来无关
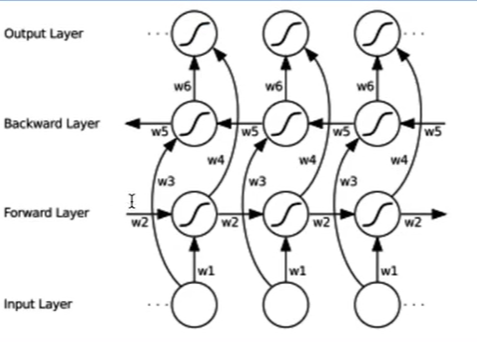
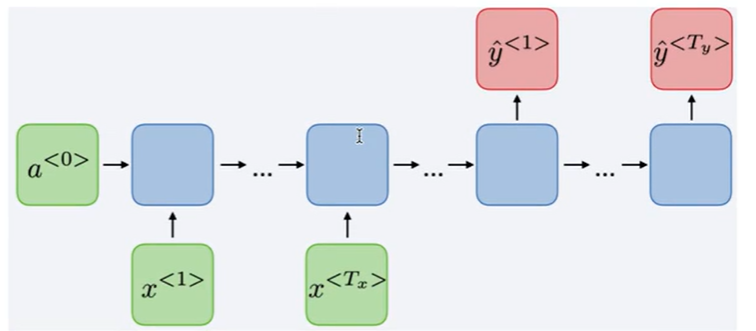
双向RNN
既能看到过去,也能看到未来
优点
- 可以处理变长序列
这个是DNN和CNN处理不了的,DNN的话输入特征是固定的,CNN的话,kernel不光和kernel_size有关还有输入通道数有关。之所以能够处理变长序列的原因是因为这些w1,w2,w3权重在每一个时刻是相等的,正因为这些权重无论在输入还是在记忆单元连接,还是历史信息和当前信息连接,权重都是固定的,正是因为权重在每一个时刻共享,所以RNN才能处理变长序列,一旦把共享的w去掉了,就不能处理变长序列了。
-
模型大小与序列长度无关
-
计算量与序列长度星线性增长
-
考虑历史信息
-
便于流式输出
每计算一步就可以输出
- 权重时不变
缺点
-
串行计算比较慢
-
无法获取太长的历史信息
应用场景
- Al诗歌生成
one to many任务
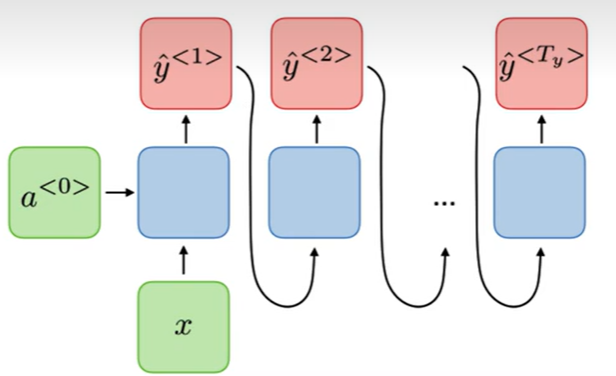
- 文本情感分类
many to one任务
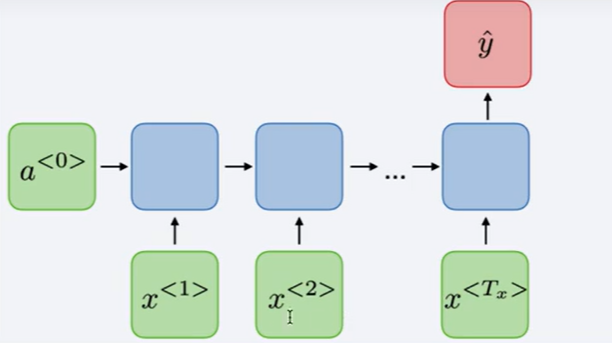
- 词法识别
many to many 任务,识别每个单词的词性
- 机器翻译
many to many 任务,seq2seq
-
语音识别/合成
-
语言模型
API
RNN — PyTorch 1.12 documentation
公式
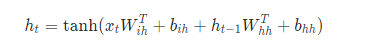
初始化RNN参数
- input_size
输入特征的维度
- hidden_size
每一个时刻ht的大小
- num_layers
RNN的层数,可以堆叠多层
- nonlinearity
激活函数,默认是tanh,可以用relu
- bias
偏置值
- batch_first
决定输入和输出的格式,为True的话,格式是这个样子的 (batch, seq, feature) ,为False的话,格式是这个样子的 (seq, batch, feature),很好的解释了沐神为什么在转换维度
-
dropout
-
bidirectional
为True的话,可以构造双向RNN结构,输出就是2×hidden_size,因为是双向,所以有2个隐藏状态
输入参数

- input
如果batch_first为True的话,输入特征的shape要求为
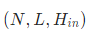
如果batch_first为False的话,输入特征的shape要求为
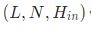
上述为有batch,没有batch的shape为
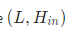
- h_0
初始状态要求有batch的shape为

没有batch的
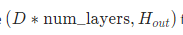
输出参数
- output
如果batch_first为True的话,输出shape为
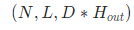
如果batch_first为False的话,输出shape为
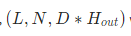
没有batch
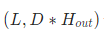
- h_n
最后时刻的状态,输出shape为

没有batch
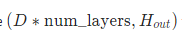
变量
- RNN.weight_ih_l[k]:第k层输入层的权重,shape为(hidden_size, input_size) ,
- RNN.weight_hh_l[k]:第k层隐藏层的权重,shape为 (hidden_size, hidden_size)
- RNN.bias_ih_l[k] :第k层输入层的偏置,shape为(hidden_size)
- RNN.bias_hh_l[k]:第k层隐藏层的偏置,shape为(hidden_size)
API实现单层,单向RNN
| 参数名 | 值 |
|---|---|
| input_size | 4 |
| hidden_size | 3 |
| num_layers | 1 |
| batch_size | 1 |
| seqLength | 2 |
| D | 1 |
| batch_first | True |
import torch
import torch.nn as nn
single_rnn = nn.RNN(4,3,1,batch_first=True) # input_size * hidden_size * num_layers
input_x = torch.randn(1,2,4) # batch_size * seqLength * input_size
output,h_n = single_rnn(input_x)
output # batch_size * seqLength * (D * hidden_size)
#tensor([[[ 0.6475, -0.3831, -0.0288],
# [ 0.4701, -0.7224, -0.1448]]], grad_fn=<TransposeBackward1>)
h_n # (D * num_layers) * batch_size * hidden_size
# tensor([[[ 0.4701, -0.7224, -0.1448]]], grad_fn=<StackBackward0>)
API实现单层,双向RNN
| 参数名 | 值 |
|---|---|
| input_size | 4 |
| hidden_size | 3 |
| num_layers | 1 |
| batch_size | 1 |
| seqLength | 2 |
| D | 2 |
| batch_first | True |
| bidirectional | True |
bidirectional_rnn = nn.RNN(4,3,1,batch_first=True,bidirectional=True) # input_size * hidden_size * num_layers
bi_output,bi_h_n = bidirectional_rnn(input_x)
bi_output # batch_size * seqLength * (D * hidden_size)
#tensor([[[ 0.2967, 0.0377, -0.3754, 0.1055, -0.8097, 0.5296],
# [ 0.6000, -0.3587, -0.2720, -0.2106, -0.3747, 0.4135]]],grad_fn=<TransposeBackward1>)
bi_h_n # (D * num_layers) * batch_size * hidden_size
#tensor([[[ 0.6000, -0.3587, -0.2720]],
# [[ 0.1055, -0.8097, 0.5296]]], grad_fn=<StackBackward0>)
RNN复现
单层,单向
def rnn_forward(input,weight_ih,weight_hh,bias_ih,bias_hh,h_prev):
batch_size,T,input_size = input.shape
h_dim = weight_ih.shape[0] # 隐藏层维度
h_out = torch.zeros(batch_size,T,h_dim) # 初始化一个输出(状态)矩阵
for t in range(T):
#x = input[:,t,:] # 获取当前时刻输入 batch_size * input_size
x = input[:,t,:].unsqueeze(2) # 做bmm运算时,需要对x扩维变成batch_size * input_size*1
# 这里给weight扩维度,主要是因为x里面有batch,
w_ih_batch = weight_ih.unsqueeze(0).tile(batch_size,1,1) # batch_size*h_dim*input_size
w_hh_batch = weight_hh.unsqueeze(0).tile(batch_size,1,1) # batch_size*h_dim*h_dim
w_time_x = torch.bmm(w_ih_batch,x).squeeze(-1)# 因为x是二维,需要x扩维 batch_size*h_dim
# 上一时刻的隐藏状态
w_time_h = torch.bmm(w_hh_batch,h_pre.unsqueeze(2)).squeeze(-1) #batch_size*h_dim
h_prev = torch.tanh(w_time_x+biash_ih+w_time_h+bias_hh)
h_out[:,t,:] = h_prev
return h_out,h_prev.unsqueeze(0)
batch_size,T = 2,3
input_size,hidden_size = 2,3
input = torch.randn(batch_size,T,input_size)
h_prev = torch.randn(batch_size,hidden_size)
weight_ih = torch.randn(hidden_size,input_size)
weight_hh = torch.randn(hidden_size,hidden_size)
bias_ih = torch.randn(hidden_size)
bias_hh = torch.randn(hidden_size)
r = rnn_forward(input,weight_ih,weight_hh,bias_ih,bias_hh,h_prev)
r

- c[:,1,:]
变为2维的

- tile用法
只传入一个参数
x = torch.tensor([[1, 2], [3, 4]])
print(x.tile((2, )))
>>> tensor([[1, 2, 1, 2],
[3, 4, 3, 4]])
# 只有一个参数,可以理解最后一个维度里面的元素进行复制,所以就是把1,2复制两边就是1,2,1,2 把3,4复制两边就是3,4,3,4
# 这里最后一个维度是[1,2],[3,4],里面的元素分别是1,2,3,4
传入两个参数
x = torch.tensor([[1, 2], [3, 4]])
print(x.tile((2, 2)))
>>> tensor([[1, 2, 1, 2],
[3, 4, 3, 4],
[1, 2, 1, 2],
[3, 4, 3, 4]])
# 传入两个参数,首先对最后一个维度里面的元素复制2遍就是[1,2,1,2],[3,4,3,4],然后把最后一个维度的上一个维度的元素复制两遍就是
# [[1, 2, 1, 2],
# [3, 4, 3, 4],
# [1, 2, 1, 2],
# [3, 4, 3, 4]]
传入三个参数
x = torch.randn(2, 2)
print(x)
>>> tensor([[ 1.1165, -0.5559],
[-0.6341, 0.5215]])
print(x.tile((2, 2, 2)))
>>> tensor([[[ 1.1165, -0.5559, 1.1165, -0.5559],
[-0.6341, 0.5215, -0.6341, 0.5215],
[ 1.1165, -0.5559, 1.1165, -0.5559],
[-0.6341, 0.5215, -0.6341, 0.5215]],
[[ 1.1165, -0.5559, 1.1165, -0.5559],
[-0.6341, 0.5215, -0.6341, 0.5215],
[ 1.1165, -0.5559, 1.1165, -0.5559],
[-0.6341, 0.5215, -0.6341, 0.5215]]])
# 传入3个参数,首先对最后一个维度里面的元素复制2遍就是[1.1165, -0.5559, 1.1165, -0.5559],然后对最后一个维度的上一个维度里面的元素复制2遍,就是
[[ 1.1165, -0.5559, 1.1165, -0.5559],
[-0.6341, 0.5215, -0.6341, 0.5215],
[ 1.1165, -0.5559, 1.1165, -0.5559],
[-0.6341, 0.5215, -0.6341, 0.5215]]
# 接着,对到倒数第3个维度里的元素进行复制,这里没有倒数第三个维度,所以创建一个维度,然后再把倒数第三个维度的值复制两遍
双向RNN
# 手写一个bidirectional
def bidirectional_rnn_forward(input,weight_ih,weight_hh,bias_ih,bias_hh,h_prev,
weight_ih_reverse,weight_hh_reverse,bias_ih_reverse,bias_hh_reverse,
h_prev_reverse):
batch_size,T,input_size = input.shape
# 隐藏层的维度
h_dim = weight_ih.shape[0]
# output
h_out = torch.zeros(batch_size,T,h_dim*2) # 初始化一个输出,注意双向是两倍的特征大小
# 正向层,这里对结果取[0]只取output
forward_output = rnn_forward(input,weight_ih,weight_hh,bias_ih,bias_hh,h_prev)[0]
# 反向层
backward_output = rnn_forward(torch.flip(input,(1,)),weight_ih,weight_hh,bias_ih,bias_hh,h_prev)[0]
# 有两个dim,分别赋值
h_out[:,:,:h_dim] = forward_output
h_out[:,:,h_dim:] = backward_output
return h_out,h_out[:,-1,:].reshape((batch_size,2,h_dim)).transpose(0,1) # 交换维度
# API实现双向
# 验证以下bidirectional_rnn_forward正确性
bi_rnn = nn.RNN(input_size,hidden_size,batch_first=True,bidirectional=True)
h_prev = torch.zeros(2,batch_size,hidden_size) # 这个2表示双向RNN,h_prev[0]是正向,h_prev[1]是反向
bi_rnn_output,bi_state_final = bi_rnn(input,h_prev)
print(bi_rnn_output)
print(bi_state_final)

- torch.flip
你传入那个dim,我就对那个dim反转,这里
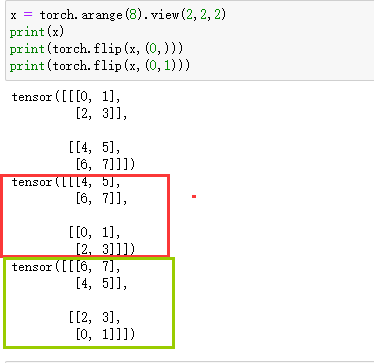
# 查看网络的参数
for k,v in bi_rnn.named_parameters():
print(k,v)

# 直接把api的bidirectional的weight拿过用到自己实现的
bidirectional_rnn_forward(input,bi_rnn.weight_ih_l0,bi_rnn.weight_hh_l0,
bi_rnn.bias_ih_l0,bi_rnn.bias_hh_l0,h_prev[0],
bi_rnn.weight_ih_l0_reverse,bi_rnn.weight_hh_l0_reverse,
bi_rnn.bias_ih_l0_reverse,bi_rnn.bias_hh_l0_reverse,
h_prev[1])

