
LSTM实现
LSTM实现
30、PyTorch LSTM和LSTMP的原理及其手写复现_哔哩哔哩_bilibili
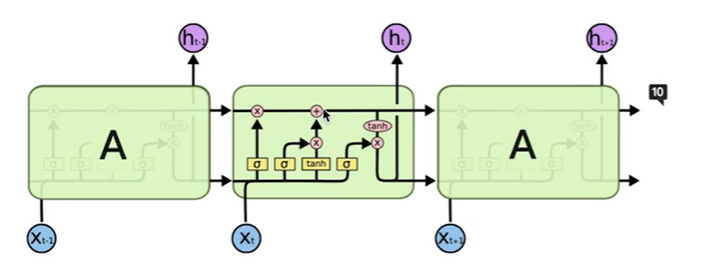
pytorch文档
LSTM — PyTorch 1.12 documentation
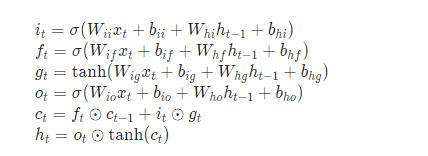
it:输入门
ft:遗忘门
gt:细胞
ot:输出门
ct:细胞状态,lstm就是靠ct来不断对历史信息进行筛选和更新
ht:当前时刻的输出
实例化对象的参数
- input_size :输入x的大小
- hidden_size :h的大小
- num_layers:层数
- bias :决定bi和bh是否可以丢弃
- batch_first :是否把batch放在第一维
- dropout :丢弃法
- bidirectional :是否双向
- proj_size :LSTM网络的变体(LSTMP),减少LSTM的参数和计算量
输入参数
Inputs: input, (h_0, c_0)
第一个参数:input
第二个参数:(h_0, c_0)
h_0和c_0是要以元祖的形式出现

- input:输入的特征
batch_first=False
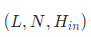
batch_first=True
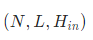
- h_0:初始状态

- c_0:细胞初始状态

输出参数
Outputs: output, (h_n, c_n)
第一个参数:output
第二个参数:(h_n, c_n)
h_n和c_n是要以元祖的形式输出
- output:整个序列的状态输出
batch_first=False
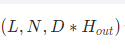
batch_first=True
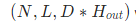
- h_n
如果带有proj_size,那么就会对h_n进行压缩

- c_n
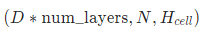
变量

API实现
# 实现LSTM和LSTMP的源码
# 定义常量
batch_size,T,i_size,h_size = 2,3,4,5
# proj_size
input = torch.randn(batch_size,T,i_size) # 输入序列
c0 = torch.randn(batch_size,h_size) # 初始值,不需要训练
h0 = torch.randn(batch_size,h_size)
# 调用官方API
lstm_layer = nn.LSTM(i_size,h_size,batch_first=True)
output,(h_final,c_final) = lstm_layer(input,(h0.unsqueeze(0),c0.unsqueeze(0))) # 定义的h0和c0不满足要求,需要对第0维扩维
print(output)
print(h_final)
print(c_final)

查看LSTM的参数
for k,v in lstm_layer.named_parameters():
print(k,v)

查看参数的shape
for k,v in lstm_layer.named_parameters():
print(k,v.shape)

自己实现
# 自己写一个LSTM模型
def lstm_forward(input,initial_states,w_ih,w_hh,b_ih,b_hh):
h0,c0 = initial_states # 初始状态
batch_size,T,i_size = input.shape
# 因为有4个门,这里有四个隐藏层
h_size = w_ih.shape[0] // 4
prev_h = h0
prev_c = c0
output_size = h_size
output = torch.zeros(batch_size,T,output_size) # 输出序列
# w不带batch维度的话,无法与x进行带有batch的乘法
# w_ih shape为(4*hidden_size,input_size)
batch_w_ih = w_ih.unsqueeze(0).tile(batch_size,1,1) # (batch_size,4*hidden_size,input_size)
batch_w_hh = w_hh.unsqueeze(0).tile(batch_size,1,1) # (batch_size,4*hidden_size,input_size)
for t in range(T):
x = input[:,t,:] # 当前时刻的输入向量,batch,当前是2维,需要扩维
# x.shape (batch_size,input_size)
# x.unsqueeze(-1)后x.shape (batch_size,input_size,1)
w_times_x = torch.bmm(batch_w_ih,x.unsqueeze(-1)) # (batch_size,4*hidden_size,1)
# 后面的那个1维不需要
w_times_x = w_times_x.squeeze(-1) # (batch_size,4*hidden_size)
w_times_h_prev = torch.bmm(batch_w_hh,prev_h.unsqueeze(-1))
w_times_h_prev = w_times_h_prev.squeeze(-1)
# 分别计算,输入门(i),遗忘门(f),cell门(g),输出门(o),
# w_time_x是一个四个门的权重拼起来的矩阵,每个门用的话,只需要用四分之一就可以了
i_t = torch.sigmoid(w_times_x[:,:h_size] + w_times_h_prev[:,:h_size] + b_ih[:h_size] + b_hh[:h_size])
f_t = torch.sigmoid(w_times_x[:,h_size:2*h_size] + w_times_h_prev[:,h_size:2*h_size] + b_ih[h_size:2*h_size] + b_hh[h_size:2*h_size])
g_t = torch.tanh(w_times_x[:,2*h_size:3*h_size] + w_times_h_prev[:,2*h_size:3*h_size] + b_ih[2*h_size:3*h_size] + b_hh[2*h_size:3*h_size])
o_t = torch.sigmoid(w_times_x[:,3*h_size:4*h_size] + w_times_h_prev[:,3*h_size:4*h_size] + b_ih[3*h_size:4*h_size] + b_hh[3*h_size:4*h_size])
prev_c = f_t*prev_c + i_t*g_t
prev_h = o_t * torch.tanh(prev_c)
output[:,t,:] = prev_h
return output,(prev_h,prev_c)
- 为什么要对w使用unsqueeze
for循环中x的维度是batch_size*input_size,w要和x要做乘法的话,也就是带有batch的乘法,需要使用到torch.bmm()函数,而这里的w的shape是(4*hidden_size,input_size)没有带batch_size,做带有batch_size的乘法,必须两个张量第一维是batch,所以这里对w使用unsqueeze,只对对一维扩维,后面的不变,使用tile函数,tile(batch_size,1,1)
output,(h_final,c_final) = lstm_forward(input,(h0,c0),lstm_layer.weight_ih_l0,lstm_layer.weight_hh_l0,lstm_layer.bias_ih_l0,lstm_layer.bias_hh_l0)
print(output)
print(h_final)
print(c_final)

API实现LSTMP
batch_size,T,i_size,h_size = 2,3,4,5
proj_size = 3
input = torch.randn(batch_size,T,i_size) # 输入序列
c0 = torch.randn(batch_size,h_size) # 初始值,不需要训练
# 不是用proj_size
h0 = torch.randn(batch_size,h_size)
# 使用proj_size
h0_proj_size = torch.randn(batch_size,proj_size)
lstm_layer1 = nn.LSTM(i_size,h_size,batch_first=True)
output1,(h_final1,c_final1) = lstm_layer1(input,(h0.unsqueeze(0),c0.unsqueeze(0)))
lstm_layer2 = nn.LSTM(i_size,h_size,batch_first=True,proj_size=proj_size)
output2,(h_final2,c_final2) = lstm_layer2(input,(h0_proj_size.unsqueeze(0),c0.unsqueeze(0)))
print('-'*10,'没有使用proj_size','-'*10)
print(output1.shape,h_final1.shape,c_final1.shape)
print('-'*10,'使用proj_size','-'*10)
print(output2.shape,h_final2.shape,c_final2.shape)

LSTMP只会对输出进行压缩,不会对细胞状态进行压缩
查看LSTMP的参数
for k,v in lstm_layer2.named_parameters():
print(k,v.shape)

不用API实现LSTMP
# w_hr判断是不是LSTMP
def lstm_forward(input,initial_states,w_ih,w_hh,b_ih,b_hh,w_hr=None):
h0,c0 = initial_states # 初始状态
batch_size,T,i_size = input.shape
# 因为有4个门,这里有四个隐藏层
h_size = w_ih.shape[0] // 4
prev_h = h0
prev_c = c0
# 引入proj_size所做的改变 *************更改的地方**********
if w_hr is not None:
proj_size = w_hr.shape[0]
output_size = proj_size
# 对w_hr引入batch_size
batch_w_hr = w_hr.unsqueeze(0).tile(batch_size,1,1) # [batch_size,proj_size,h_size]
else:
output_size = h_size
# *************更改的地方**********
output = torch.zeros(batch_size,T,output_size) # 输出序列
# w不带batch维度的话,无法与x进行带有batch的乘法
# w_ih shape为(4*hidden_size,input_size)
batch_w_ih = w_ih.unsqueeze(0).tile(batch_size,1,1) # (batch_size,4*hidden_size,input_size)
batch_w_hh = w_hh.unsqueeze(0).tile(batch_size,1,1) # (batch_size,4*hidden_size,input_size)
for t in range(T):
x = input[:,t,:] # 当前时刻的输入向量,batch,当前是2维,需要扩维
# x.shape (batch_size,input_size)
# x.unsqueeze(-1)后x.shape (batch_size,input_size,1)
w_times_x = torch.bmm(batch_w_ih,x.unsqueeze(-1)) # (batch_size,4*hidden_size,1)
# 后面的那个1维不需要
w_times_x = w_times_x.squeeze(-1) # (batch_size,4*hidden_size)
w_times_h_prev = torch.bmm(batch_w_hh,prev_h.unsqueeze(-1))
w_times_h_prev = w_times_h_prev.squeeze(-1)
# 分别计算,输入门(i),遗忘门(f),cell门(g),输出门(o),
# w_time_x是一个四个门的权重拼起来的矩阵,每个门用的话,只需要用四分之一就可以了
i_t = torch.sigmoid(w_times_x[:,:h_size] + w_times_h_prev[:,:h_size] + b_ih[:h_size] + b_hh[:h_size])
f_t = torch.sigmoid(w_times_x[:,h_size:2*h_size] + w_times_h_prev[:,h_size:2*h_size] + b_ih[h_size:2*h_size] + b_hh[h_size:2*h_size])
g_t = torch.tanh(w_times_x[:,2*h_size:3*h_size] + w_times_h_prev[:,2*h_size:3*h_size] + b_ih[2*h_size:3*h_size] + b_hh[2*h_size:3*h_size])
o_t = torch.sigmoid(w_times_x[:,3*h_size:4*h_size] + w_times_h_prev[:,3*h_size:4*h_size] + b_ih[3*h_size:4*h_size] + b_hh[3*h_size:4*h_size])
prev_c = f_t*prev_c + i_t*g_t
prev_h = o_t * torch.tanh(prev_c)
# 进行压缩 *************更改的地方**********
if w_hr is not None:
prev_h = torch.bmm(batch_w_hr,prev_h.unsqueeze(-1)) # (batch_size,proj_size,1)
prev_h = prev_h.squeeze(-1) # (batch_size,proj_size)
# *************更改的地方**********
output[:,t,:] = prev_h
return output,(prev_h,prev_c)
lstm_layer = nn.LSTM(i_size,h_size,batch_first=True,proj_size=proj_size)
output,(h_final,c_final) = lstm_layer(input,(h0_proj_size.unsqueeze(0),c0.unsqueeze(0)))
print('----api实现-----')
print(output)
print(h_final)
print(c_final)
print('----不用api实现-----')
output,(h_final,c_final) = lstm_forward(input,(h0_proj_size,c0),lstm_layer.weight_ih_l0,lstm_layer.weight_hh_l0,lstm_layer.bias_ih_l0,lstm_layer.bias_hh_l0,lstm_layer.weight_hr_l0)
print(output)
print(h_final)
print(c_final)

