
huggingface简明教程
https://www.bilibili.com/video/BV1a44y1H7Jc?p=2&vd_source=91219057315288b0881021e879825aa3
huggingface官网:Hugging Face – The AI community building the future.
数据集:https://huggingface.co/datasets
模型:https://huggingface.co/models
主要模型
-
自回归
GPT2、Transformer-XL、XLnet
-
自编码
BERT、ALBERT、RoBERTa、ELECTRA
-
StoS
BART、Pegasus、T5
安装环境
安装transformer
pip install transformers
安装datasets
pip install datasets
使用字典和分词工具
加载tokenizer(分词器)准备语料
from transformers import BertTokenizer
# 加载预训练字典和分词方法
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path = 'bert-base-chinese',
cache_dir=None,
force_download=False,
)
sents = [
'选择珠江花园的原因就是方便。',
'笔记本的键盘确实爽。',
'房间太小。其他的都一般',
'今天才知道这书还有第6卷,真有点郁闷.',
'机器背面似乎被撕了张什么标签,残胶还在。'
]
tokenizer,sents

简单的编码
# 编码两个句子
out = tokenizer.encode(
text=sents[0],
text_pair=sents[1],
#当句子长度大于max_length时,截断
truncation=True,
#一律补pad到max_length长度
padding='max_length',
add_speical_tokens=True,
max_length=30,
return_tensors=None
)
print(out)
tokenizer.decode(out)

增强的编码函数
# 增强的编码函数
out = tokenizer.encode_plus(
text = sents[0],
text_pair=sents[1],
# 当句子长度大于max_length长度
padding='max_length',
max_length=30,
add_special_tokens=True,
# 可取值tf,pt,np,默认返回list tensorflow,pytorch,numpy
return_tensors=None,
# 返回token_type_ids
return_token_type_ids=True,
# 返回attention_mask
return_attention_mask=True,
# 返回special_tokens_mask特殊符号标识
return_special_tokens_mask=True,
# 返回offset_mapping标识每个词的起始位置,这个参数只能BertTokenizerFast使用
# return_offsets_mapping=True,
# 返回长度
return_length = True
)
#input_ids 就是编码后的词
#token_type_ ids 第一- 个句子和特殊符号的位置是0,第二个句子的位置是1
#special_tokens_ mask 特殊符号的位置是1,其他位置是0
#attention_ mask pad的位置是0,其他位置是1
#length返回句子长度
for k,v in out.items():
print(k,':',v)
tokenizer.decode(out['input_ids'])

批量编码句子
# 增强的编码函数
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs = [sents[0],sents[1]],
add_special_tokens=True,
#当句子长度大于max_length时,截断
truncation=True,
# 一律补零到max_length长度
padding='max_length',
max_length=30,
# 可取值tf,pt,np,默认返回list tensorflow,pytorch,numpy
return_tensors=None,
# 返回token_type_ids
return_token_type_ids=True,
# 返回attention_mask
return_attention_mask=True,
# 返回special_tokens_mask特殊符号标识
return_special_tokens_mask=True,
# 返回offset_mapping标识每个词的起始位置,这个参数只能BertTokenizerFast使用
# return_offsets_mapping=True,
# 返回长度
return_length = True
)
for k,v in out.items():
print(k,':',v)
tokenizer.decode(out['input_ids'][0]),tokenizer.decode(out['input_ids'][1])
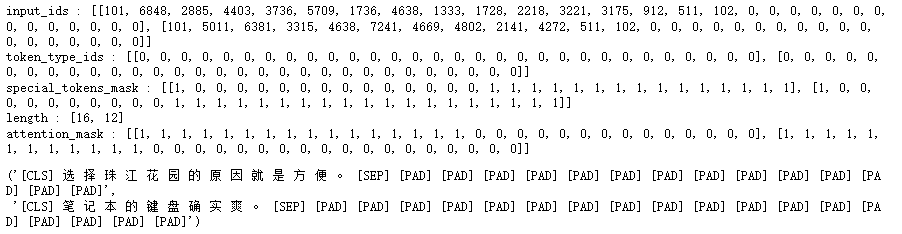
批量成对编码
# 批量成对
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs = [(sents[0],sents[1]),(sents[2],sents[3])],
add_special_tokens=True,
#当句子长度大于max_length时,截断
truncation=True,
# 一律补零到max_length长度
padding='max_length',
max_length=30,
# 可取值tf,pt,np,默认返回list tensorflow,pytorch,numpy
return_tensors=None,
# 返回token_type_ids
return_token_type_ids=True,
# 返回attention_mask
return_attention_mask=True,
# 返回special_tokens_mask特殊符号标识
return_special_tokens_mask=True,
# 返回offset_mapping标识每个词的起始位置,这个参数只能BertTokenizerFast使用
# return_offsets_mapping=True,
# 返回长度
return_length = True
)
for k,v in out.items():
print(k,':',v)
tokenizer.decode(out['input_ids'][0]),tokenizer.decode(out['input_ids'][1])

字典操作
# 字典
zidian=tokenizer.get_vocab() # bert-base-chinese是一个一个字存储的,所以这列月光不在字典里面
type(zidian),len(zidian),'月光' in zidian,

# 添加新词
tokenizer.add_tokens(new_tokens=['月光','希望'])
# 添加新符号
tokenizer.add_special_tokens({'eos_token':'[EOS]'})
zidian = tokenizer.get_vocab()
type(zidian),len(zidian),zidian['月光'],zidian['[EOS]']
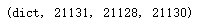
编码新词
# 编码新词
out = tokenizer.encode(
text='月光的新希望[EOS]',
text_pair=None,
#当句子长度大于max_length时,截断
truncation=True,
# 一律补零到max_length长度
padding='max_length',
add_special_tokens=True,
max_length=8,
return_tensors=None,
)
print(out)
tokenizer.decode(out)

加载Huggingface数据集
因为google访问不了,这里用git的方法把数据下下来,然后再本地加载。
下载
进入官网Hugging Face – The AI community building the future.
点击dataset
输入你要的数据集名称
然后点击这个
选中git,然后copy,到你想要保存的路径,把复制的git代码在命令行中运行,文件下好后不要去打开,也不要去解压里面的东西。
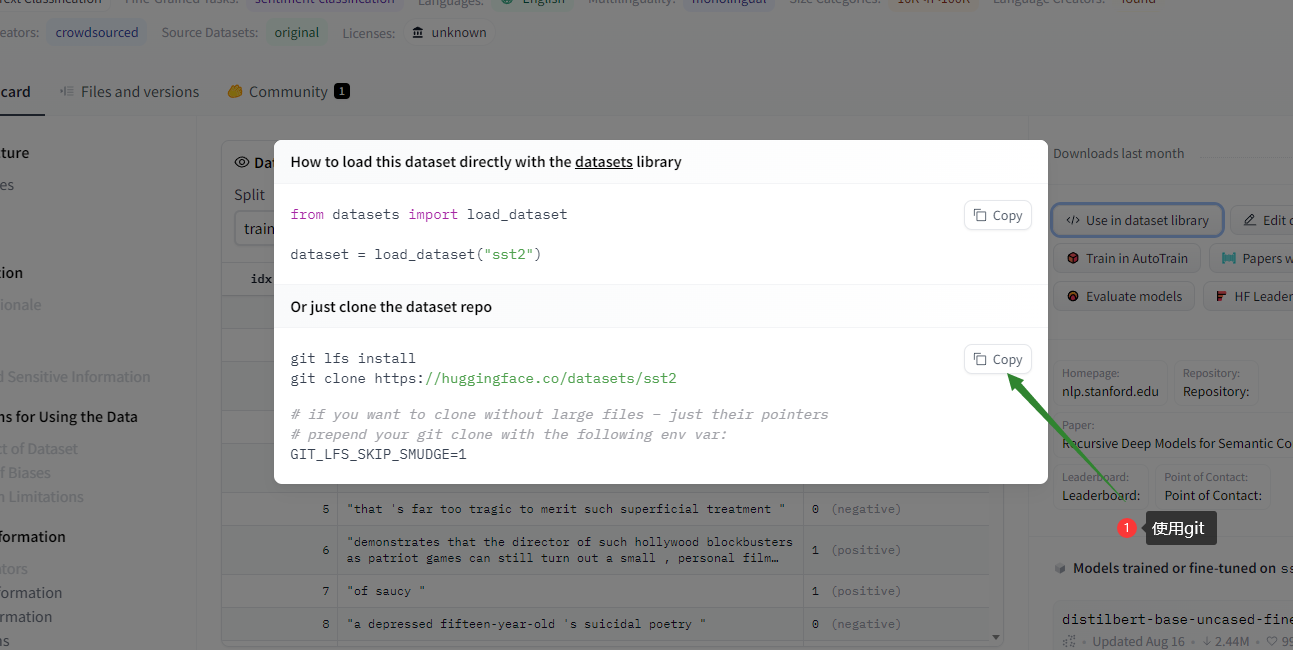
加载
找到刚才保存的目录加载数据
from datasets import load_dataset
# 加载
dataset = load_dataset("./data/clone/sst2")
# 保存
dataset.save_to_disk(dataset_dict_path='./data/sst2')
加载数据集
# 加载本地数据集
from datasets import load_from_disk
# from datasets import load_dataset 加载网上的数据集
# 加载数据
dataset = load_from_disk('./data/ChnSentiCorp')
# dataset = load_dataset(path='seamew/ChnSentiCorp',split='train')
dataset
# 保存数据集到磁盘
dataset.save_to_disk(dataset_dict_path='./data/ChnSentiCorp1')
# 查看一个数据
dataset['train'][0]

读写csv格式本地文件
# 导出为csv文件
dataset = dataset['train']
dataset.to_csv(path_or_buf='./data/ChnSentiCrop.csv')
# 加载csv格式数据
csv_dataset = load_dataset(path='csv',
data_files='./data/ChnSentiCorp.csv',
split='train')
csv_dataset[20]
排序
# sort
# 未排序前
print(dataset['label'][:10])
# 排序后
sorted_dataset = dataset.sort('label')
print(sorted_dataset['label'][:10])
print(sorted_dataset['label'][-10:])

打乱
# shuffle
shuffled_dataset = sorted_dataset.shuffle(seed=42)
shuffled_dataset['label'][:10]
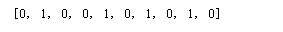
选择
# select
dataset.select([0,10,20,30])

过滤
# filter
def f(data):
return data['text'].startswith('选择')
start_with_ar = dataset.filter(f)
len(start_with_ar),start_with_ar['text']

切分
# 切分成训练集和测试集
dataset.train_test_split(test_size=0.1)

分桶
# 把数据切分到4个桶中,均匀分配
dataset.shard(num_shards=4,index=0)

列操作
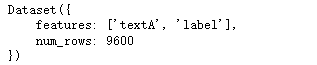
#rename
dataset.rename_column('text','textA')
#remove_columns
dataset.remove_columns(['text'])

# map
def f(data):
data['text'] = 'My sentence:' + data['text']
return data
dataset_map = dataset.map(f)
dataset_map['text'][:5]

保存和加载
dataset.save_to_disk('./')
dataset = load_from_disk("./")
其它格式
# 导出其他格式
dataset.to_csv('./')
dataset.to_json('./')
使用评价函数
查看可用的评价指标
from datasets import list_metrics
# 列出评价指标
metrics_list = list_metrics()
len(metrics_list),metrics_list

实战任务
中文分类
导包
import torch
from datasets import load_from_disk
定义数据集
# 定义数据集 定义dataloader
class Dataset(torch.utils.data.Dataset):
def __init__(self,name):
self.dataset = load_from_disk('./data/ChnSentiCorp')[name]
def __len__(self):
return len(self.dataset)
def __getitem__(self,i):
text = self.dataset[i]['text']
label = self.dataset[i]['label']
return text,label
dataset = Dataset('train')
len(dataset),dataset[0]

加载tokenizer
# 加载tokenizer
from transformers import BertTokenizer
# 加载字典和分词工具
token = BertTokenizer.from_pretrained('bert-base-chinese')
定义批处理函数
def collate_fn(data):
sents = [i[0] for i in data]
labels = [i[1] for i in data]
# 编码
data = token.batch_encode_plus(batch_text_or_text_pairs=sents,
truncation=True,
padding='max_length',
max_length=500,
return_tensors='pt',
return_length=True)
# input_ids:编码之后的数字
# attention_mask:补零的位置0,其他位置是1
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
labels = torch.LongTensor(labels)
return input_ids,attention_mask,token_type_ids,labels
定义数据加载器
# 数据加载器
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=16,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
break
print(len(loader)) # 600
input_ids.shape,attention_mask.shape,token_type_ids.shape,labels

加载bert中文模型
from transformers import BertModel
# 加载预训练模型
pretrained = BertModel.from_pretrained('bert-base-chinese')
# 不训练,不需要计算梯度,这里我们不使用fine-turning,直接把预训练模型的参数给冻住,只训练下游任务模型
# 对预训练模型本身它的参数,我们不调整
for param in pretrained.parameters():
param.requires_grad_(False)
# 模型试算
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
# 指定每一句话编码成500个词的长度,768是词编码的长度
out.last_hidden_state.shape
# torch.Size([16, 500, 768])
定义下游任务模型
# 下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768,2)
def forward(self,input_ids,attention_mask,token_type_ids):
with torch.no_grad():
# 先拿预训练模型做一个计算,抽取数据中的特征,
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
# 把抽取的特征放到全连接网络中去运算,并且只需要第0个词的特征
out = self.fc(out.last_hidden_state[:,0])
out = out.softmax(dim=1)
return out
model = Model()
model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids).shape
# torch.Size([16, 2])
训练下游任务模型
# 训练下游任务模型
from transformers import AdamW
# 训练
optimizer = AdamW(model.parameters(),lr=5e-4)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
loss = criterion(out,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 5 == 0:
out = out.argmax(dim=1)
accuracy = (out==labels).sum().item() / len(labels)
print(i,loss.item(),accuracy)
# 只训练了300次,并未把全部数据训练完
if i == 300:
break

在训练过程中,我们发现争取率可以达到百分之七八十的样子,这就是使用bert预训练模型抽取特征展现的威力,在以往的NLP上做一个文本分类的任务训练到七八十的正确率,训练量是非常大的,模型往往很难收敛,这里使用bert预训练模型来抽取特征,然后再做下游任务的一个迁移学习的话,可以在非常短的时间内,以一个非常快的速度就能达到一个很高的正确率。
测试
# 测试
def test():
model.eval()
correct = 0
total = 0
loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'),
batch_size=32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader_test):
if i == 5:
break
print(i)
with torch.no_grad():
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
out = out.argmax(dim=1)
correct += (out==labels).sum().item()
total += len(labels)
print(correct / total)
test()

中文分类在GPU上训练
代码
定义设备
def try_gpu(i=0):
if torch.cuda.device_count() >= i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
device = try_gpu()
将预训练模型放在GPU上
from transformers import BertModel
# 加载预训练模型
pretrained = BertModel.from_pretrained('bert-base-chinese')
# GPU
pretrained = pretrained.cuda()
# 不训练,不需要计算梯度,这里我们不使用fine-turning,直接把预训练模型的参数给冻住,只训练下游任务模型
# 对预训练模型本身它的参数,我们不调整
for param in pretrained.parameters():
param.requires_grad_(False)
将下游模型放在GPU上
# 下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768,2)
def forward(self,input_ids,attention_mask,token_type_ids):
with torch.no_grad():
# GPU
input_ids = input_ids.cuda()
attention_mask = attention_mask.cuda()
token_type_ids = token_type_ids.cuda()
# 先拿预训练模型做一个计算,抽取数据中的特征,
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
# 把抽取的特征放到全连接网络中去运算,并且只需要第0个词的特征
out = self.fc(out.last_hidden_state[:,0])
out = out.softmax(dim=1)
return out
model = Model().cuda()
model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids).shape
在GPU上训练
# 训练下游任务模型
from transformers import AdamW
# 训练
optimizer = AdamW(model.parameters(),lr=5e-4)
criterion = torch.nn.CrossEntropyLoss().cuda()
start_time = time.time()
model.train()
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
# GPU
input_ids = input_ids.cuda()
attention_mask = attention_mask.cuda()
token_type_ids = token_type_ids.cuda()
labels = labels.cuda()
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
loss = criterion(out,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 5 == 0:
out = out.argmax(dim=1)
accuracy = (out==labels).sum().item() / len(labels)
print(i,loss.item(),accuracy)
# 只训练了300次,并未把全部数据训练完
if i == 100:
break
end_time = time.time()
print(end_time - start_time)
在GPU上测试
# 测试
def test():
model.eval()
correct = 0
total = 0
loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'),
batch_size=16,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader_test):
# GPU
input_ids = input_ids.cuda()
attention_mask = attention_mask.cuda()
token_type_ids = token_type_ids.cuda()
labels = labels.cuda()
if i == 5:
break
print(i)
with torch.no_grad():
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
out = out.argmax(dim=1)
correct += (out==labels).sum().item()
total += len(labels)
print(correct / total)
start_time = time.time()
test()
end_time = time.time()
print(end_time - start_time)
训练
台式机(GTX1650 super):70°
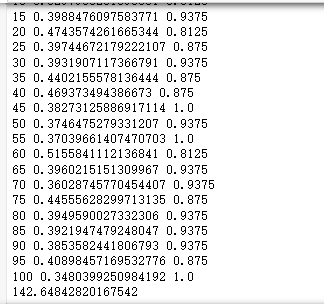
笔记本(RTX 3050 laptop):73°
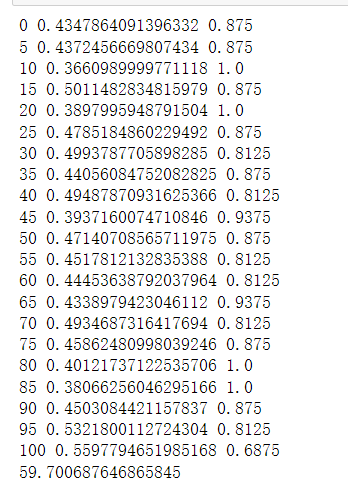
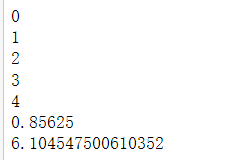
测试
台式机(GTX 1650 super):温度上升速度比笔记本慢些
batch_size设为32会报错cuda out of memory

笔记本(RTX 3050 laptop):57°,上升速度非常快
中文填词
导包
import torch
from datasets import load_from_disk
定义数据集
class Dataset(torch.utils.data.Dataset):
def __init__(self,name):
dataset = load_from_disk('./data/ChnSentiCorp')[name]
def f(data):
return len(data['text']) > 30
self.dataset = dataset.filter(f)
def __len__(self):
return len(self.dataset)
def __getitem__(self,i):
text = self.dataset[i]['text']
return text
dataset = Dataset('train')
len(dataset),dataset[0]

加载tokenizer
from transformers import BertTokenizer
token = BertTokenizer.from_pretrained('bert-base-chinese')
定义批处理函数
def collate_fn(data):
# 编码
data = token.batch_encode_plus(batch_text_or_text_pairs=data,
truncation=True,
padding='max_length',
max_length=30,
return_tensors='pt',
return_length=True)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
# 把第15个词替换为mask
print(input_ids[:,15])
labels = input_ids[:,15].reshape(-1).clone()
input_ids[:,15] = token.get_vocab()[token.mask_token]
return input_ids,attention_mask,token_type_ids,labels
定义数据加载器并查看数据样例
# 数据加载器
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=16,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
break
print(len(loader))
print(token.decode(input_ids[0]))
print(token.decode(labels))
input_ids.shape,attention_mask.shape,token_type_ids.shape,labels.shape

加载bert中文模型
from transformers import BertModel
# 加载预训练模型
pretrained = BertModel.from_pretrained('bert-base-chinese')
# 不训练,不需要计算梯度
for param in pretrained.parameters():
param.requires_grad_(False)
# 模型试算
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
out.last_hidden_state.shape
# torch.Size([16, 30, 768])
定义下游任务
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.decoder = torch.nn.Linear(768,token.vocab_size,bias=False)
self.bias = torch.nn.Parameter(torch.zeros(token.vocab_size))
self.decoder.bias = self.bias
def forward(self,input_ids,attention_mask,token_type_ids):
with torch.no_grad():
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
out = self.decoder(out.last_hidden_state[:,15])
return out
model = Model()
model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids).shape
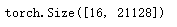
训练下游任务模型
from transformers import AdamW
# 训练
optimizer = AdamW(model.parameters(),lr=5e-4)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(5):
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
out = model(input_ids=input_ids,
attention_mask = attention_mask,
token_type_ids=token_type_ids)
loss = criterion(out,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 50 == 0:
out = out.argmax(dim=1)
accuracy = (out==labels).sum().item() / len(labels)
print(epoch,i,loss.item(),accuracy)
测试
# 测试
def test():
model.eval()
correct = 0
total = 0
loader_test = torch.utils.data.DataLoader(dataset=Dataset('test'),
batch_size=32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader_test):
if i == 15:
break
print(i)
with torch.no_grad():
out = model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
out = out.argmax(dim=1)
correct += (out==labels).sum().item()
total += len(labels)
print(token.decode(input_ids[0]))
print(token.decode(labels[0]))
test()
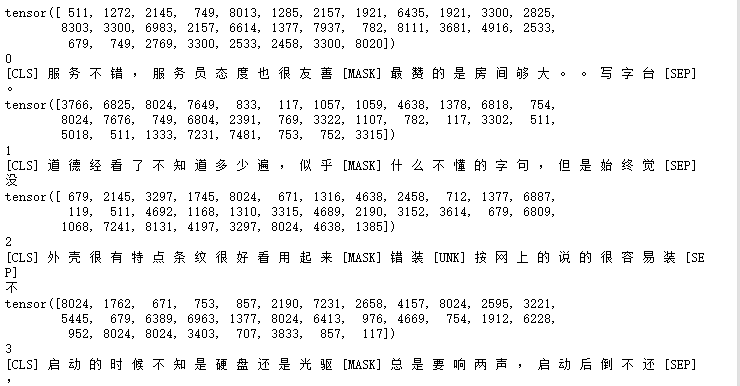
中文句子关系推断
定义数据集
import torch
from datasets import load_from_disk
import random
# 定义数据集
class Dataset(torch.utils.data.Dataset):
def __init__(self,name):
dataset = load_from_disk('./data/ChnSentiCorp')[name]
def f(data):
return len(data['text']) > 40
self.dataset = dataset.filter(f)
def __len__(self):
return len(self.dataset)
def __getitem__(self,i):
text = self.dataset[i]['text']
# 切分一句话为前半句和后半句
sentence1 = text[:20]
sentence2 = text[20:40]
label = 0
# 有一半的概率把后半句替换为一句无关的话,
if random.randint(0,1) == 0:
j = random.randint(0,len(self.dataset)-1)
sentence2 = self.dataset[j]['text'][20:40]
label = 1
return setence1,sentence2,label
查看数据样例
dataset = Dataset('train')
sentence1,sentence2,label = dataset[0]
len(dataset),sentence1,sentence2,label

加载tokenizer
from transformers import BertTokenizer
# 加载字典和分词工具
token = BertTokenizer.from_pretrained('bert-base-chinese')
token
定义批处理函数
def collate_fn(data):
sents =[i[:2] for i in data]
labels = [i[2] for i in data]
# 编码
data = token.batch_encode_plus(batch_text_or_text_pairs=sents,
truncation=True,
padding='max_length',
max_length=45,
return_tensor='pt',
return_length=True,
add_special_tokens=True)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
labels = torch.LongTensor(labels)
return input_ids,attention_mask,token_type_ids,labels
定义数据加载器并查看数据样例
# 数据加载器
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=8,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
break
print(len(loader))
print(token.decode(input_ids[0]))
input_ids.shape,attention_mask.shape,token_type_ids.shape,labels

加载bert中文模型
from transformers import BertModel
# 加载预训练模型
pretrained = BertModel.from_pretrained('bert-base-chinese')
# 不训练,不需要计算梯度
for param in pretrained.parameters():
param.requires_grad_(False)
# 模型试算
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
out.last_hidden_state.shape
# torch.Size([8, 45, 768])
定义下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768,2)
def forward(self,input_ids,attention_mask,token_type_ids):
with torch.no_grad():
# 先拿预训练模型做一个计算,抽取数据中的特征,
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
# 把抽取的特征放到全连接网络中去运算,并且只需要第0个词的特征
out = self.fc(out.last_hidden_state[:,0])
out = out.softmax(dim=1)
return out
model = Model()
model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids).shape
# torch.Size([8, 2])
训练下游任务
# 训练下游任务模型
from transformers import AdamW
# 训练
optimizer = AdamW(model.parameters(),lr=5e-4)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
loss = criterion(out,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 5 == 0:
out = out.argmax(dim=1)
accuracy = (out==labels).sum().item() / len(labels)
print(i,loss.item(),accuracy)
# 只训练了300次,并未把全部数据训练完
if i == 300:
break
测试
# 测试
def test():
model.eval()
correct = 0
total = 0
loader_test = torch.utils.data.DataLoader(dataset=Dataset('validation'),
batch_size=32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader_test):
if i == 5:
break
print(i)
with torch.no_grad():
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
out = out.argmax(dim=1)
correct += (out==labels).sum().item()
total += len(labels)
print(correct / total)
test()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号