bert详解
BERT代码(源码)从零解读【Pytorch-手把手教你从零实现一个BERT源码模型】_哔哩哔哩_bilibili
00 预训练语言模型的前世今生(全文 24854 个词) - 二十三岁的有德 - 博客园 (cnblogs.com)
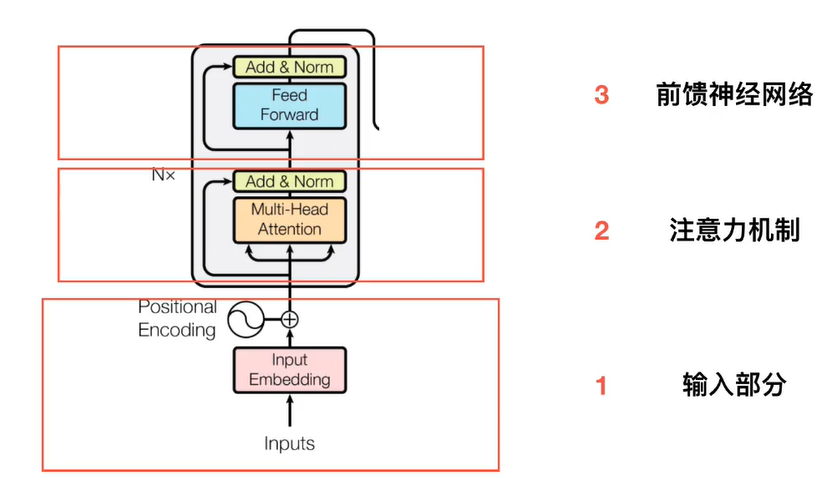
Bert基础架构
词语之间意义是有关联的,距离可以表示词与词之间的关系,比如苹果和梨都是水果,它们之间的距离就会比苹果和猫咪更近,这些向量是如何得到的,机器学习的出现,让我们不必为单词设计向量,而是将收集好的句子,文章等数据交给模型,由它为单词们找到最合适的位置,bert就是帮助我们找到词语位置的模型之一,它的诞生源于transformer,既然encoder能将语言的意义很好的抽离出来,那么将这部分独立,也许能很好的对语言做出表示,人们还为bert设计了独特的训练方式,其中之一是有遮挡的训练(masking input)在收集到的词汇中,随机覆盖15%的词汇,让bert去猜这些字是什么,此外还会输入成组的句子(next sentence prediction)由bert判断两个句子是否相连,前者让bert更好的依据语境做出预测,后者让bert对上下文关系有更好的理解,在完成不同的自然语言处理任务时,需要将已经训练好的bert依据任务目标增加不同功能的输出层联合训练,比如文本分类就增加了分类器,输入句子,输出类别。阅读理解增加了一个全连接层,输入问题和文章,输出答案的位置
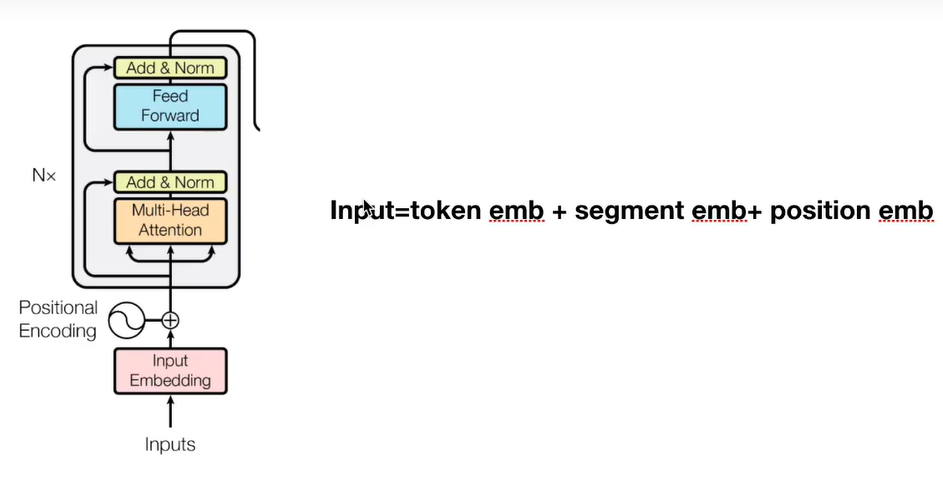
bert的输入
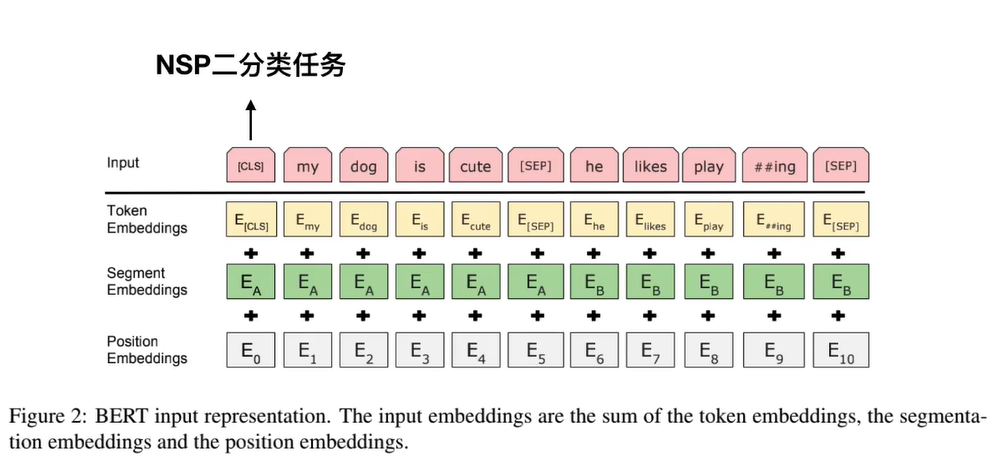
NSP二分类任务
https://blog.csdn.net/weixin_43797818/article/details/107352565
- [CLS] 标志放在第一个句子的首位,经过 BERT 得到的的表征向量 C 可以用于后续的分类任务。
- [SEP] 标志用于分开两个输入句子,例如输入句子 A 和 B,要在句子 A,B 后面增加 [SEP] 标志。
- [UNK]标志指的是未知字符
- [MASK] 标志用于遮盖句子中的一些单词,将单词用 [MASK] 遮盖之后,再利用 BERT 输出的 [MASK] 向量预测单词是什么。
Token Embedding
对input中所有词汇做embedding
Segment Embedding
对句子进行区分,不同区间的句子的值不同,比如从[CLS]到第一个[SEP]就是一个区间,它的值都是0,第二区间从he到结尾的[SEP]都是1
Position Embedding
位置编码
预训练之MLM详解
MLM掩码语言模型
AR
autoregressive,自回归模型;只能考虑单侧的信息,典型的就是GPT
AE
autoencoding,自编码模型;从损坏的输入数据中预测重建原始数据。可以使用上下文的信息,Bert就是使用的AE

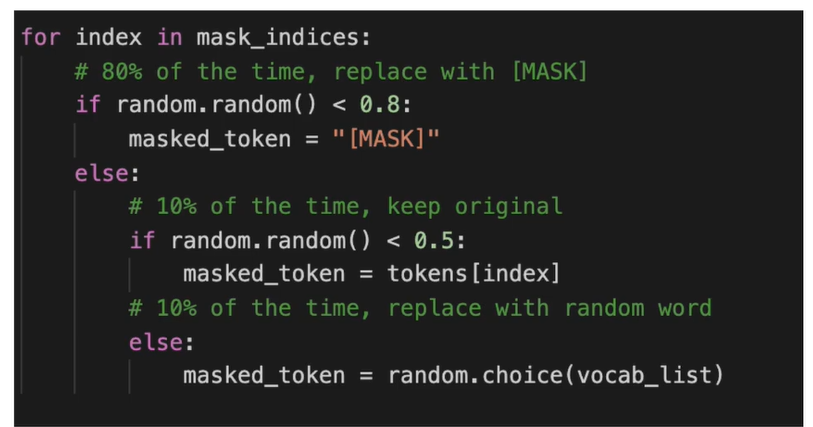
mask概率

NSP任务
下句预测任务

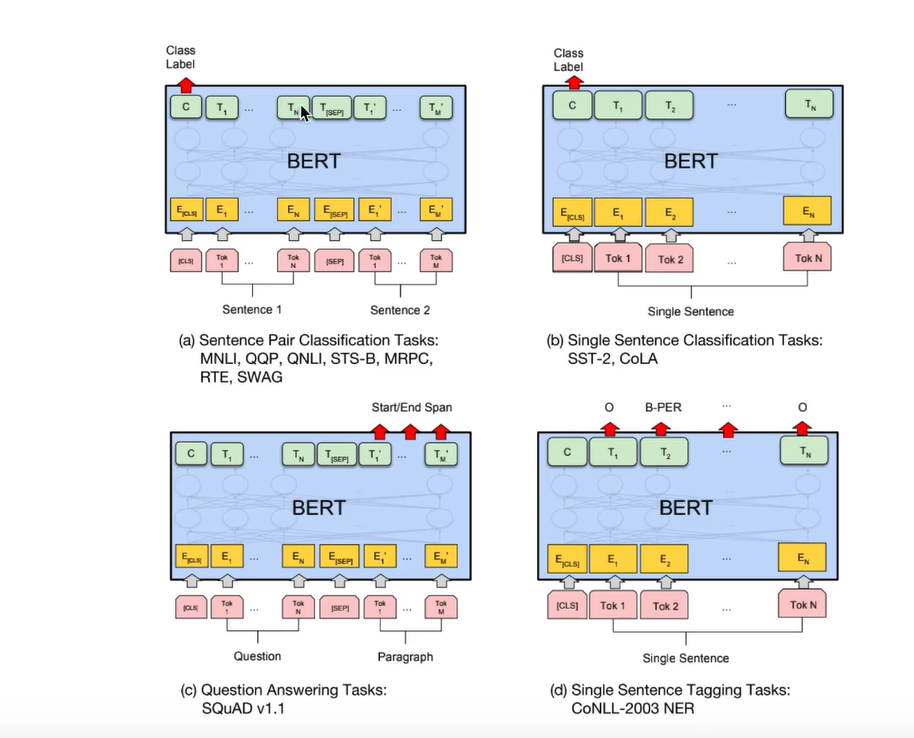
微调BERT
BERT代码
为什么填充0?
答:填充为0时,可以指定0不参与计算
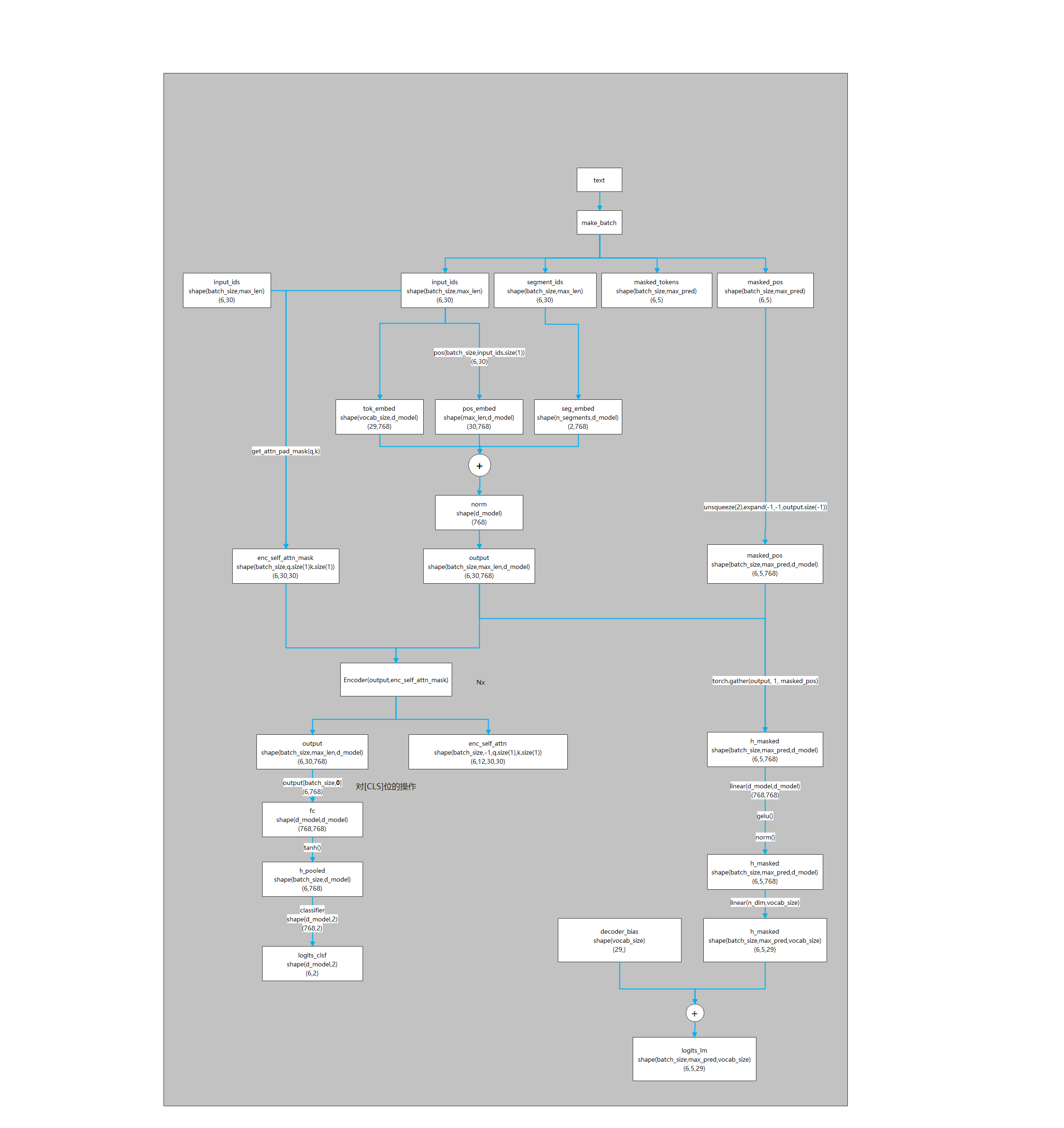
make_batch
1.首先随机生成两个数tokens_a_index,tokens_b_index(数值要sentences的范围内)
2.根据上面生成的这两个数去sentences中取两个句子
3.按照'[CLS] + 句子1 + [SEP] + 句子2 + [SEP]'的方式将句子拼接起来,生成input_ids,同时也生成segment_ids,segment_ids的前面为0,后面为1。
4.定义我要进行mask的次数,最多不超过max_pred
5.把第3步中拼接后的句子中每个单词的位置存起来,特殊字符除外
6.把第5步中的数值打乱
7.根据第4步中定义的次数,把第6步中生成的list前n_pred位进行mask操作,同时使用masked_tokens,maskd_pos记录每次进行masked操作的单词和在input_ids的位置
8.如果第3步中的input_ids和segment_ids的长度达不到max_len,就在句子后面填充0
9.判断tokens_a_index+1 等不等于tokens_b_index,如果相等就是正例那么positive加1,否则就是负例negative加1,最后正例和负例的个数要各占一半
batch生成测试样本
def make_batch():
batch = []
positive = negative = 0
while positive != batch_size/2 or negative != batch_size/2:
tokens_a_index, tokens_b_index= randrange(len(sentences)), randrange(len(sentences))
tokens_a, tokens_b= token_list[tokens_a_index], token_list[tokens_b_index]
input_ids = [word_dict['[CLS]']] + tokens_a + [word_dict['[SEP]']] + tokens_b + [word_dict['[SEP]']]
segment_ids = [0] * (1 + len(tokens_a) + 1) + [1] * (len(tokens_b) + 1)
n_pred = min(max_pred, max(1, int(round(len(input_ids) * 0.15))))
cand_maked_pos = [i for i, token in enumerate(input_ids)
if token != word_dict['[CLS]'] and token != word_dict['[SEP]']]
shuffle(cand_maked_pos)
masked_tokens, masked_pos = [], []
for pos in cand_maked_pos[:n_pred]:
masked_pos.append(pos)
masked_tokens.append(input_ids[pos])
if random() < 0.8: # 80%
input_ids[pos] = word_dict['[MASK]']
elif random() < 0.5: # 10%
index = randint(0, vocab_size - 1)
input_ids[pos] = word_dict[number_dict[index]]
n_pad = maxlen - len(input_ids)
input_ids.extend([0] * n_pad)
segment_ids.extend([0] * n_pad)
if max_pred > n_pred:
n_pad = max_pred - n_pred
masked_tokens.extend([0] * n_pad)
masked_pos.extend([0] * n_pad)
if tokens_a_index + 1 == tokens_b_index and positive < batch_size/2:
batch.append([input_ids, segment_ids, masked_tokens, masked_pos, True])
positive += 1
elif tokens_a_index + 1 != tokens_b_index and negative < batch_size/2:
batch.append([input_ids, segment_ids, masked_tokens, masked_pos, False])
negative += 1
return batch
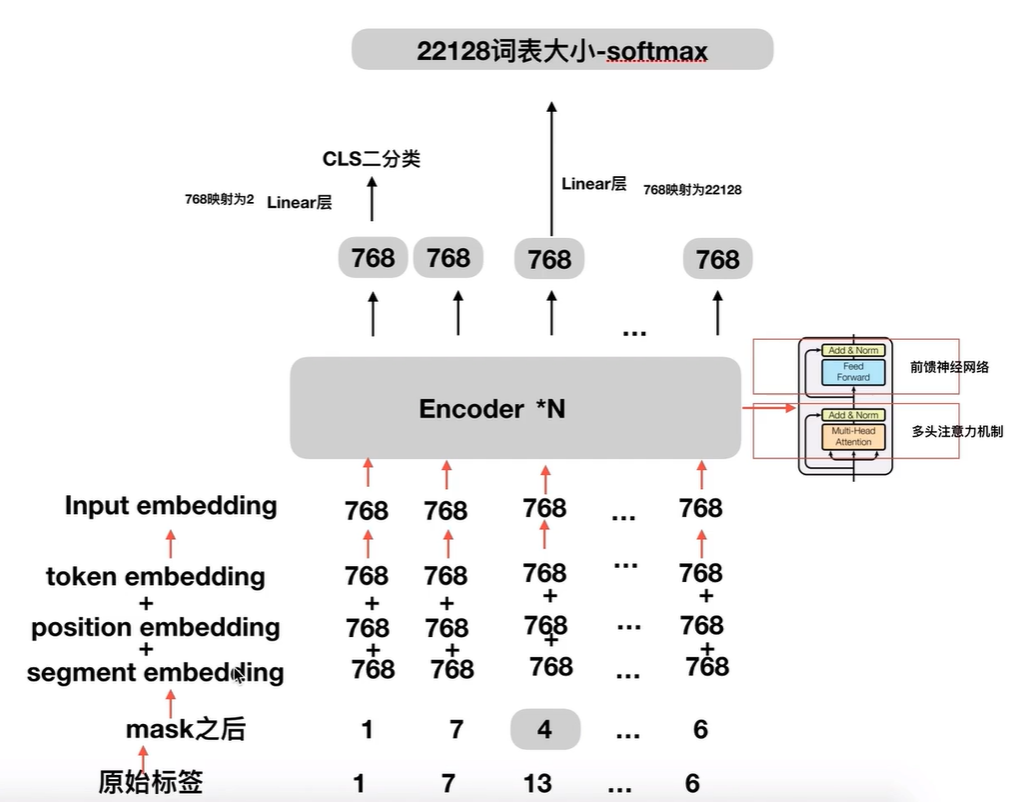
Embedding
output = self.embedding(input_ids, segment_ids) # input_ids:[batch_size,max_len],segment_ids:[batch_size,max_len]
class Embedding(nn.Module):
def __init__(self):
super(Embedding, self).__init__()
self.tok_embed = nn.Embedding(vocab_size, d_model)
self.pos_embed = nn.Embedding(maxlen, d_model)
self.seg_embed = nn.Embedding(n_segments, d_model)
self.norm = nn.LayerNorm(d_model)
def forward(self, x, seg):
seq_len = x.size(1)
pos = torch.arange(seq_len, dtype=torch.long)
pos = pos.unsqueeze(0).expand_as(x)
# x 类似于[[6,1..],...[0,5...]], pos类似于[[0,1...]..[0,1...]],seq类似于[[0,0....1,1],[0,1...1,1]]
embedding = self.tok_embed(x) + self.pos_embed(pos) + self.seg_embed(seg)
return self.norm(embedding)
BERT
- [:,:,None]
[pytorch | tensor维度中使用 None_jmucvm的博客-CSDN博客_tensornone]
- masked_pos[:, :, None].expand(-1, -1, output.size(-1))
print(masked_pos.shape)
print(masked_pos[0])
masked_pos = masked_pos[:, :, None].expand(-1, -1, output.size(-1))
print(masked_pos.shape)
print(masked_pos[0])

- gather
同一个维度的元素的长度必须相等

训练
model = BERT()
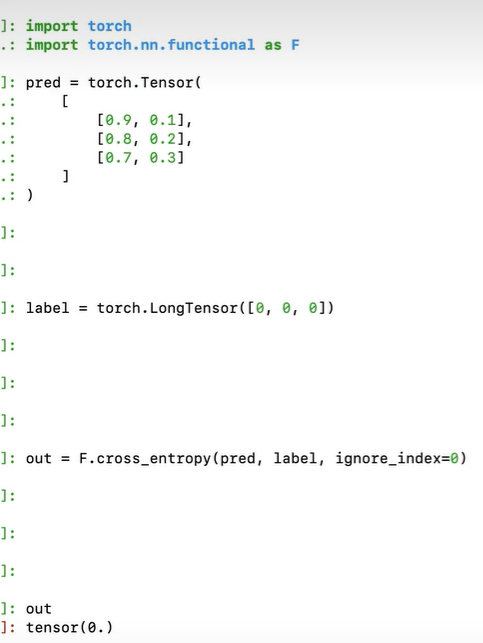
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(1):
optimizer.zero_grad()
logits_lm, logits_clsf = model(input_ids, segment_ids, masked_pos)
loss_lm = criterion(logits_lm.transpose(1, 2), masked_tokens)
loss_lm = (loss_lm.float()).mean()
loss_clsf = criterion(logits_clsf, isNext)
loss = loss_lm + loss_clsf
loss.backward()
optimizer.step()
- map(zip(*))的作用
Python map() 函数 | 菜鸟教程 (runoob.com)

- 为什么要交叉熵的损失函数中的input做transpose

根据官网文档可以知道针对带有batch的数据,第一个是batch_size,第二个是C,这个C就是你分类的个数,这里分数的个数是29个,而29是在2维,所以需要transpose(1,2)
- 为什么下面的criterion(logits_clsf, isNext) 这里不需要进行transpose
因为logits_clsf的第1的维度就是C,所以不需要
预测
# Predict mask tokens ans isNext
input_ids, segment_ids, masked_tokens, masked_pos, isNext = map(torch.LongTensor, zip(batch[0]))
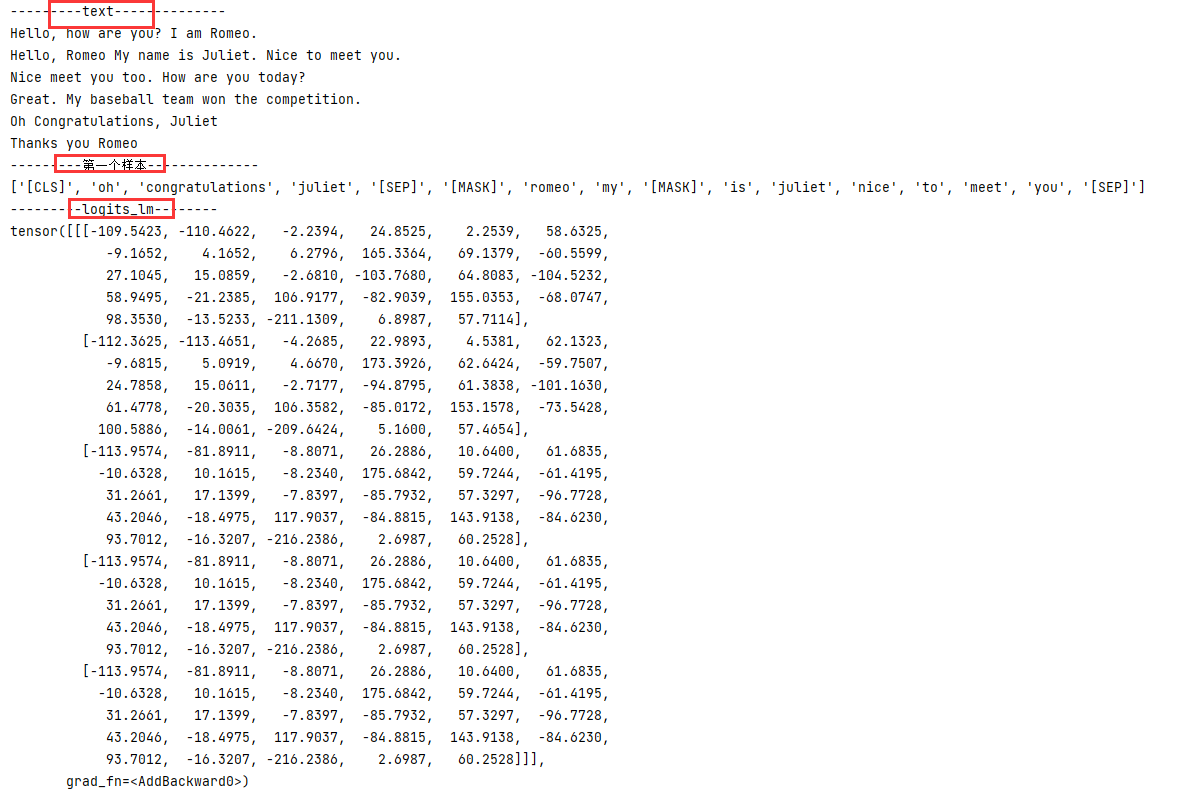
print('---------text--------------')
print(text)
print('---------第一个样本--------------')
print([number_dict[w.item()] for w in input_ids[0] if number_dict[w.item()] != '[PAD]'])
#
logits_lm, logits_clsf = model(input_ids, segment_ids, masked_pos)
print('---------logits_lm--------')
print(logits_lm)
print('---------logits_lm.shape--------')
print(logits_lm.shape)
logits_lm = logits_lm.data.max(2)[1][0].data.numpy()
print('---------------logits_lm---------------')
print(logits_lm)
print('masked tokens list : ',[pos.item() for pos in masked_tokens[0] if pos.item() != 0])
print('predict masked tokens list : ',[pos for pos in logits_lm if pos != 0])
#
print('---------------logits_clsf---------------')
print(logits_clsf)
logits_clsf = logits_clsf.data.max(1)[1].data.numpy()[0]
print('---------------logits_clsf---------------')
print(logits_clsf)
print('isNext : ', True if isNext else False)
print('predict isNext : ',True if logits_clsf else False)
- input_ids

- print([number_dict[w.item()] for w in input_ids[0] if number_dict[w.item()] != '[PAD]'])
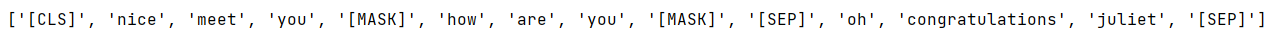
- data.max(2)
就相当于argmax
[.data.max和torch.max的笔记_agoodboy1997的博客-CSDN博客_.data.max(1)1]
输出结果

图片
预处理
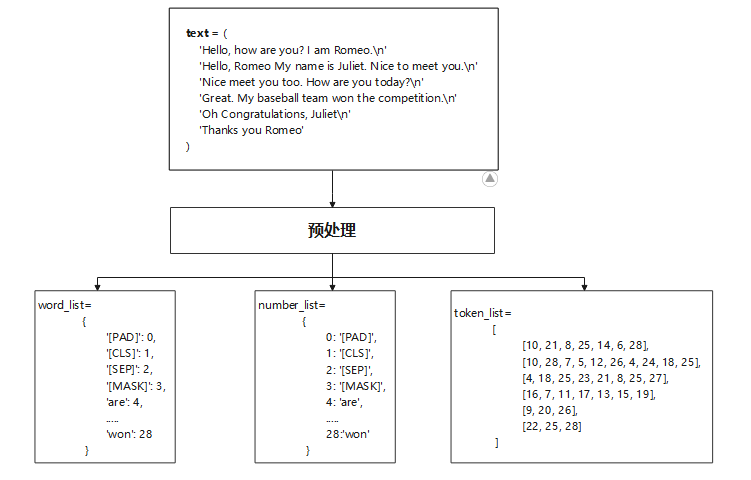
整体流程图