
预训练语言模型-Transformer-BERT-的前世今生
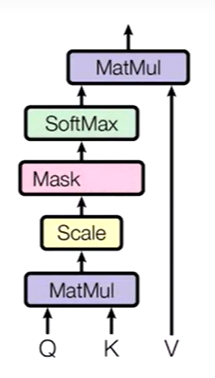
Attention
通过查询变量Q,去查询V里面有那些是重要的,得到Z,Z就是对V的表征,K往往等于V
这里的Q,K,V来源没有要求
Self-Attention
self-attention其实是attention的一个做法
这个self表示Q,K,V同源,即走来自于X。通过QKV计算最后会得到一个矩阵,这个矩阵表示的是两单词之间概率。Q,K,V就是X乘以不同的矩阵得到
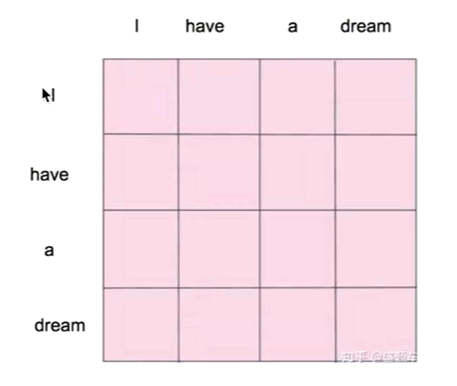
自注意力机制明确的知道这句话有多少个单词,并且一次性给足,而掩码是分批次给,最后一
次才给足
Masked Self-attention
掩码自注意模型,在self-attention上做了改进
为什么要做这个改进:生成模型,生成单词,一个一个生成的
当我们做生成任务的时候,我们也想对生成的这个单词做注意力计算,但是,生成的句子是一
个一个单词生成的

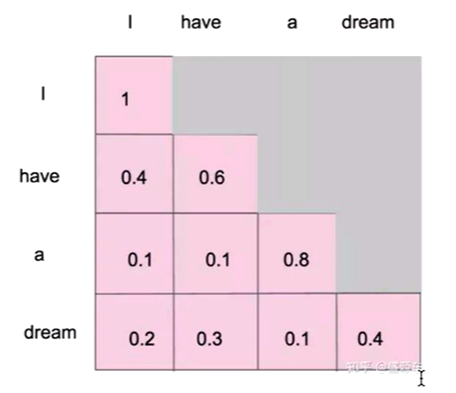
因为,每次只生成一个单词,因此掩码自注意机制应运而生,可以使用pytorch中torch.tril()下三角函数来生成下三角矩阵
我生成的时候并不知道单词后面是什么
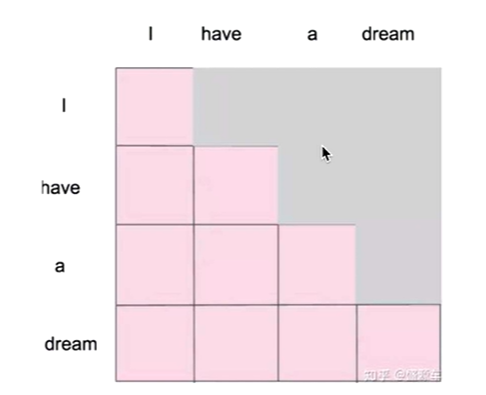
掩码后得到所有信息
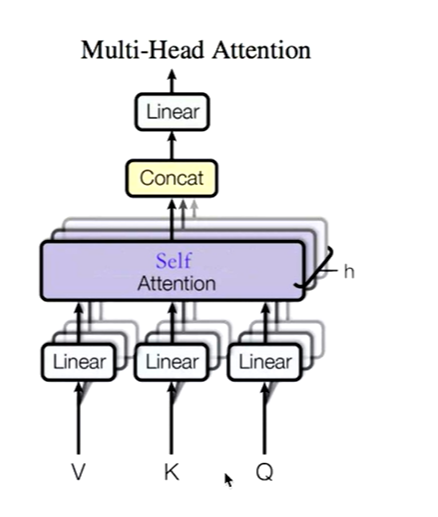
Multi-Head Self-Attention
Z相比较X有了提升,通过Multi-Head Self-Attention,得到的相比较Z又有了进一步提升
多头自注意力,问题来了,多头是什么,多头的个数用h表示,- -般h= 8,我们通常使用的是8头自注意力
什么是多头
如何多头
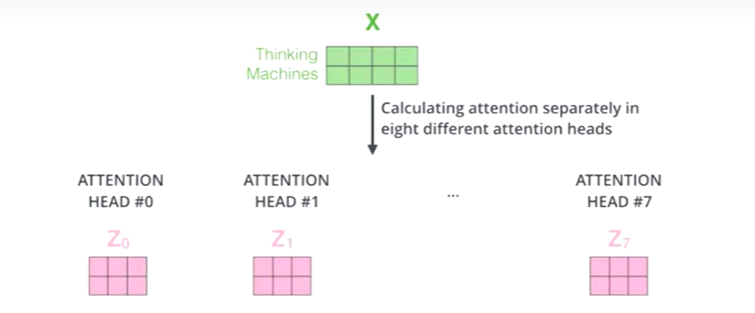
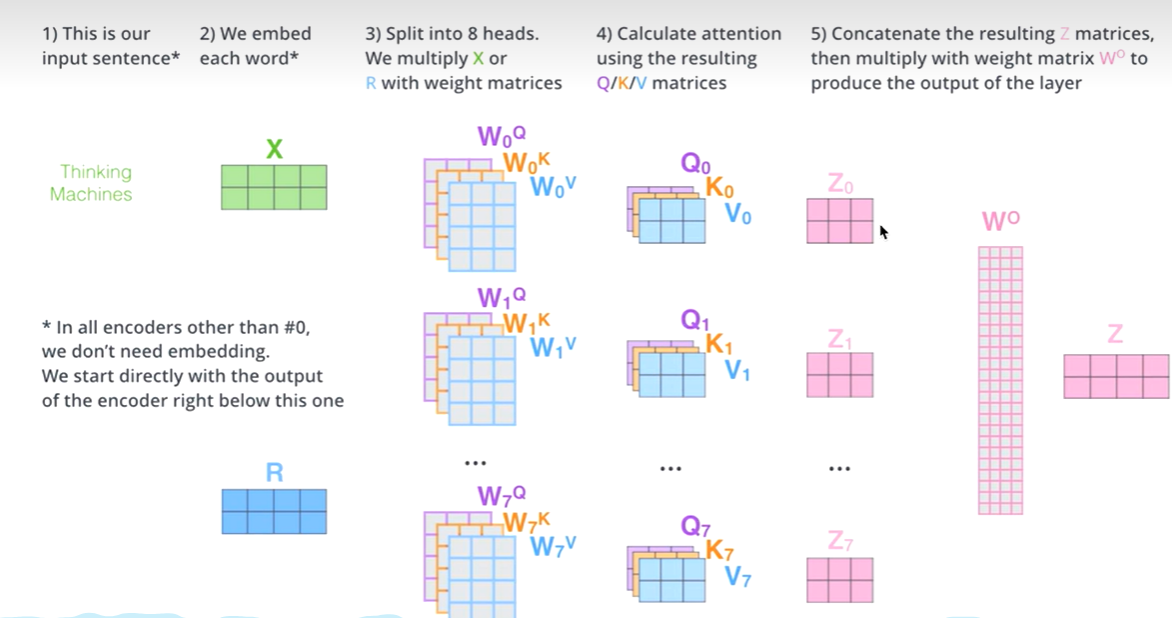
对于X,我们不是说,直接拿X去得到Z,而是把X分成了8块(8头),得到Z0-Z7
然后把Z0-Z7拼接起来,再做一次线性变换(改变维度)得到Z
机器学习的本质是什么: y=σ(wx+b), 在做- -件什么事情,非线性变换(把一 个看起来不合理的东西,通过某个手段(训练模型),让这个东西变得合理)
非线性变换的本质又是什么?改变空间上的位置坐标,任何一个点都可以在维度空间上找到,
通过某个手段,让一个不合理的点(位置不合理),变得合理
这就是词向量的本质
one-hot编码(0101010)
通过word2vec找到位置 (11, 222, 33)
通过emlo找到位置 (15, 3,2)
通过attention找到位置(124,2,32)
通过multi-head attention找到位置 (1231, 23, 3),把X切分成8块,这样一一个原先在一一个位置上的X,去了空间上8个位置,通过对8个点进行寻找,找到更合适的位置,为什么不切分成100块,如果100块有80个错的咋办?越多,错的越多
多头流程图
Positional Embedding
attention的优缺点
优点:
1.解决了长序列依赖问题
2.可以并行
缺点:
1.开销变大了
2.既然可以并行,也就是说,词与词之间不存在顺序关系(打乱- -句话,这句话里的每个词的词向量依然不会变),即无位置关系(既然没有,我就加一-个,通过位置编码的形式加)位置编码的问题
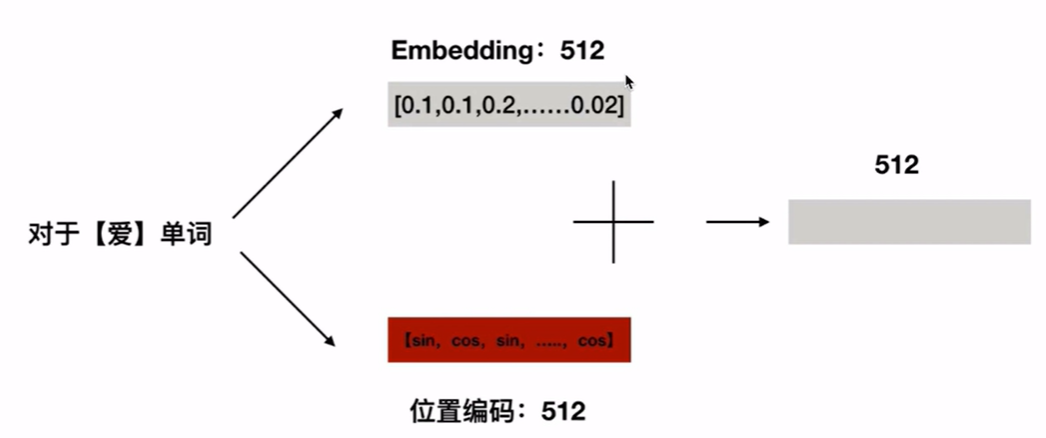
位置编码怎么做的
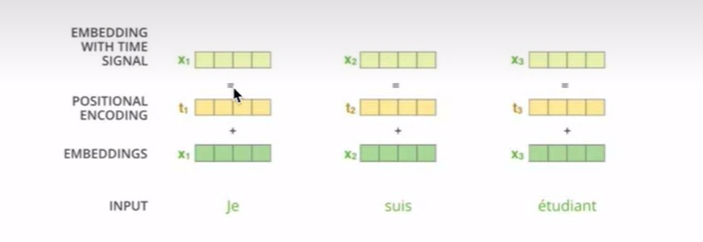
单词x1的embedding信息,加上单词x1在这句话中位置(positional encoding)。
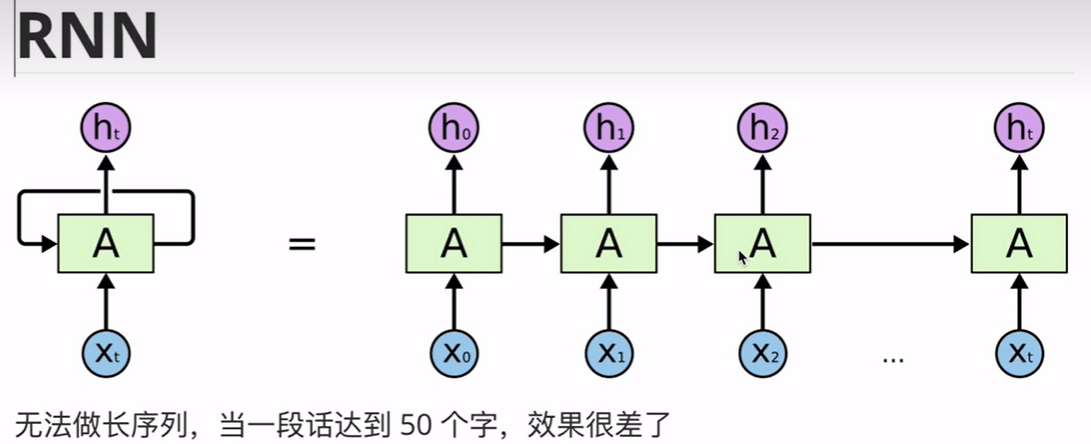
RNN中是默认有文字的顺序的,这个单词没弄往,不会弄下一个,保证了顺序
具体做法
pos:位置
i:维度
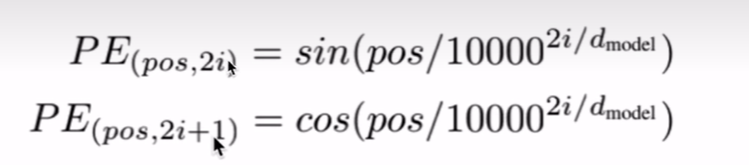
偶数用sin函数,奇数用cos函数
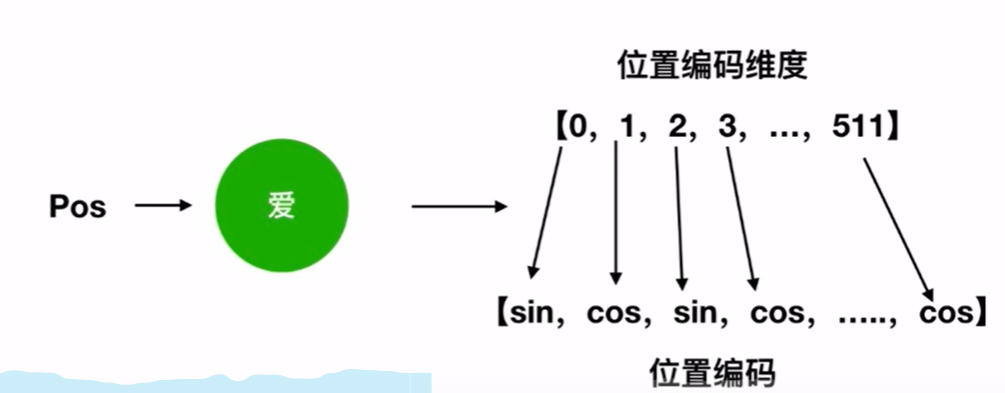
然后embedding + positional encoding
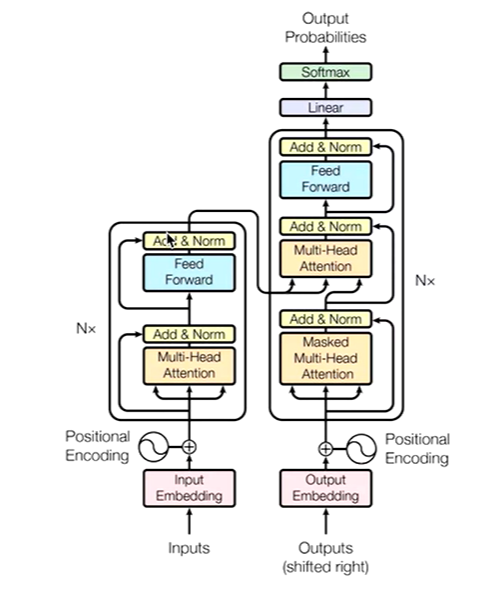
Transformer框架概述
整体框架
借用了seq2seq的思想
1.通过编码器对序列进行向量化(词向量)
2.把词向量输入到解码器,得到结果(生成单词)
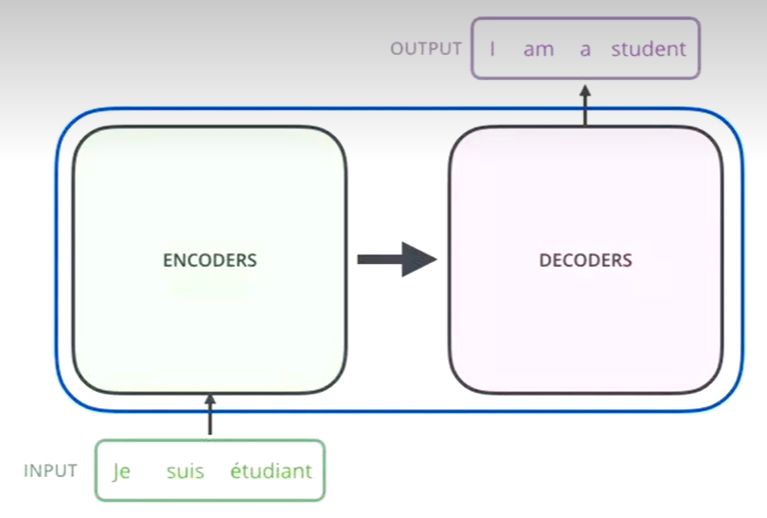
简化版
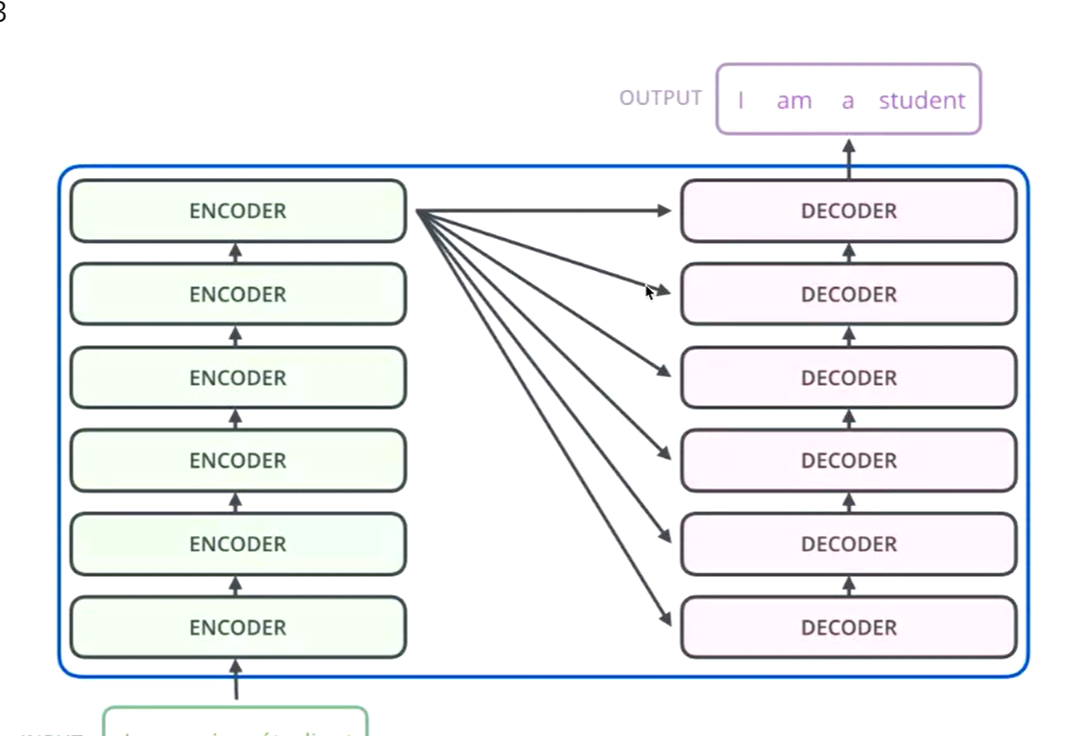
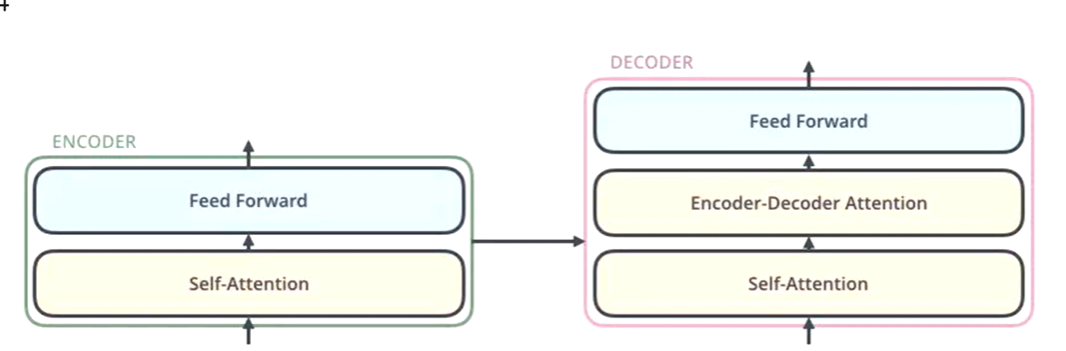
编码器和解码器
编码器:把输入变成一个词向量(Self-Attetion)
解码器:得到编码器输出的词向量后,生成翻译的结果
Nx的意思是,编码器里面又有N个小编码器(默认N=6)
通过6个编码器,对词向量一步又一步的强化(增强)
流程
FFN (Feed Forward) : w2( (w1x+b1) )+b2 其实就是线性变换
Transformer的编码器
编码器详细图
编码器包括两个子层,Self-Attention、 Feed Forward
每一个子层的传输过程中都会有一个(残差网络+归一化)
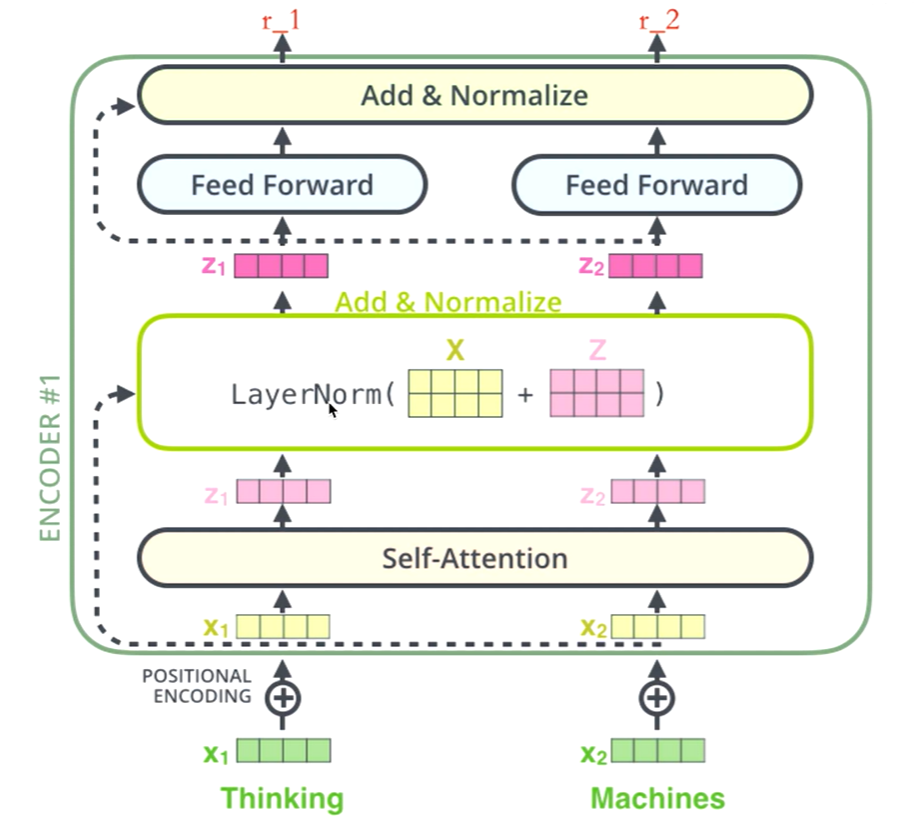
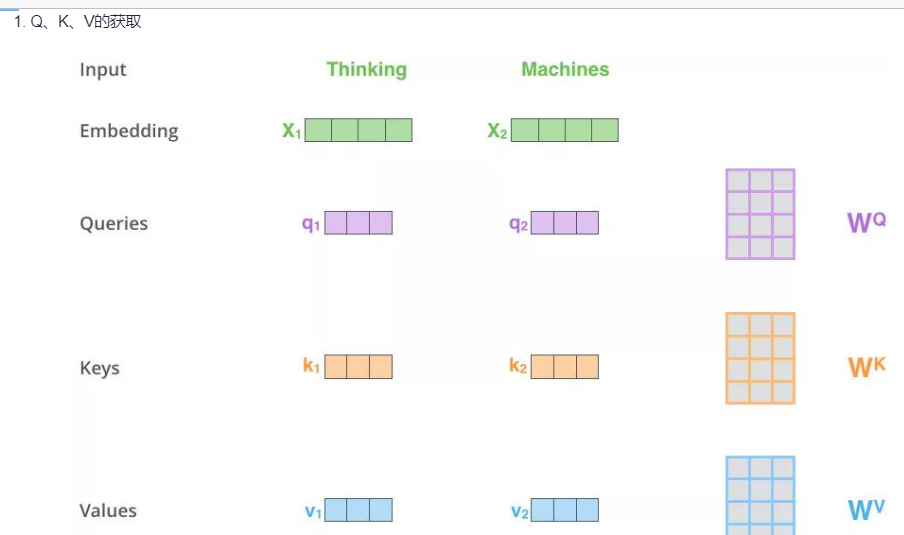
Thinking
-->》得到绿色的x1 (词向量, 可以通过one-hot、word2vec 得到) + 叠加位置编码(给x1赋予位置属性)得到黄色的x1
-->》 输入到Self-Attention子层中,做注意力机制(x1、x2拼接起来的- -句话做),得到z1 (x1 与x1, x2拼接起来的句子做了自注意力机制的词向量,表征的仍然是thinking),也就是说z1拥有了位置特征、句法特征、语义特征的词向量
-->》残差网络(避免梯度消失,w3(w2(w1x+b1)+b2)+b3, 如果w1, w2,w3 特别小,
0.00000000000......1,. X就没了,[w3(w2(w1x+b1)+b2)+b3+x] ),归一化(layerNorm),做标准化(避免梯度爆炸),限制区间,得到了深粉色的z1
--》Feed Forward, Relu (w2(w1x+b1)+b2) ,(前面每 -步都在做线性变换,wx+b, 线性变化的叠加永远都是线性变化(线性变化就是空间中平移和扩大缩小),通过Feed Forward中的Relu做一次非线性变换,这样的空间变换可以无限拟合任何一种状态了),得到r1(是thinking的新的表征)
总结
做词向量,只不过这个词向量更加优秀,让这个词向量能够更加精准的表示这个单词这句话,
编码器在干吗:生成词向量、图片向量,总而言之,编码器就是让计算机能够合理地认识人类世界客观存在的一些东西
Transformer的解码器
解码器会接收编码器生成的词向量,然后通过这个词向量去生成翻译的结果。
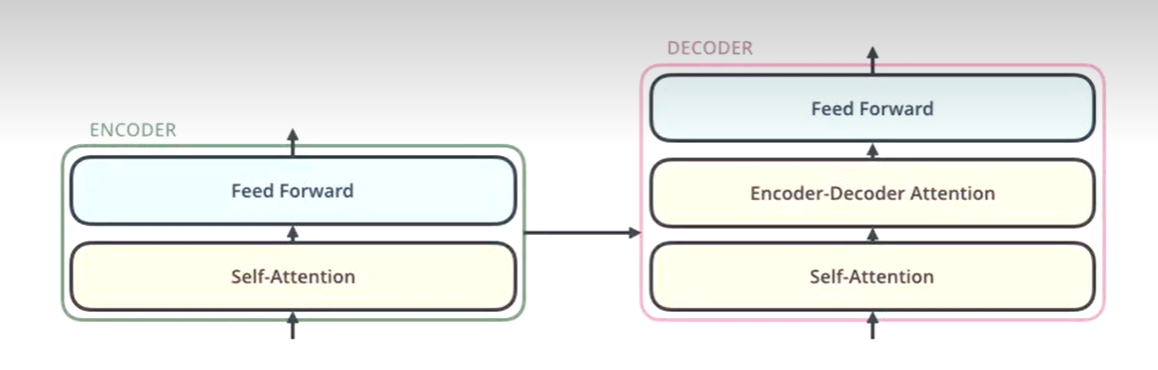
解码器的Self-Attention在编码已经生成的单词
假如目标词“我是一个学生"-- 》masked Self- Attention
训练阶段:目标词”我是一个学生”是已知的,然后Self-Attention是对“我是一个学生” 做计算
如果不做masked,每次训练阶段,都会获得所有的信息
如果做masked, Self-Attention 第一次对”我”做计算
Self-Attention第二次对“我是"做计算
测试阶段:
1.目标词未知,假设目标词是”我是一个老师”(未知),Self-Attention第一 次对“我"做计算
2.第二次对“我是”做计算
而测试阶段,没生成一点,获得一点
Decoder做Q,Encoder做K和V
生成词
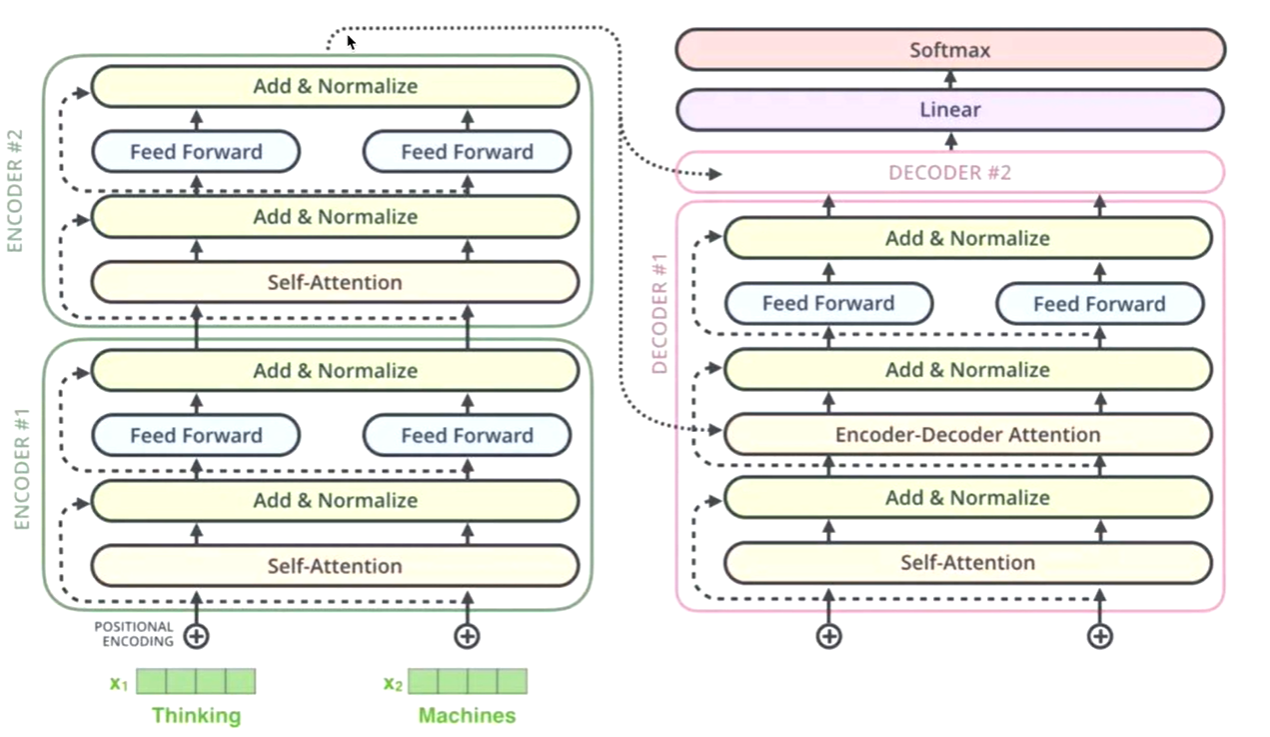
Linear层换成词表的维度
Softmax得到最大词的概率
log_probs,logits
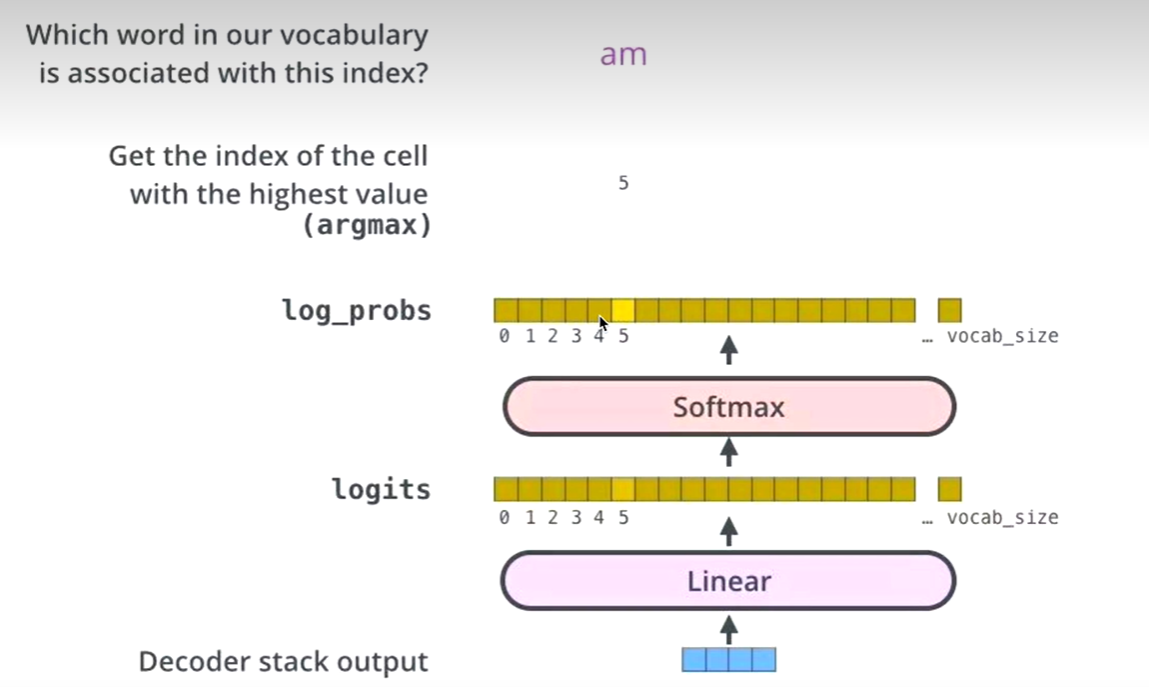
单词表
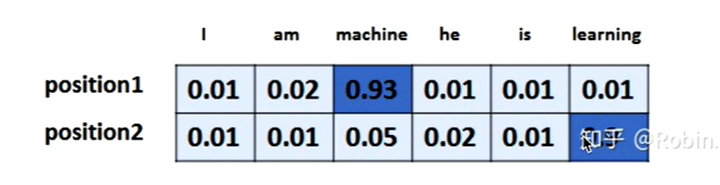
Transformer解码器的两个为什么(为什么做掩码、为什么用编码器-解码器注意力)
问题1:为什么Decoder需要做Mask
机器翻译:源语句(我爱中国) 目标语句(I love China)
为了解决训练阶段和测试阶段的gap (不匹配)
训练阶段:解码器会有输入,这个输入是目标语句,就是l love China,通过已经生成的词,去让解码器更好的生成(每一 次都会把所有信息告诉解码器)
测试阶段:解码器也会有输入,但是此时,测试的时候是不知道目标语句是什么的,这个时候,你每生成一个词,就会有多一个词放入目标语句中,每次生成的时候,都是已经生成的词(测试阶段只会把已经生成的词告诉解码器)
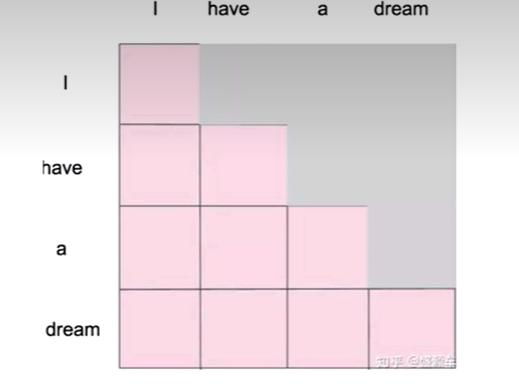
为了匹配,为了解决这个gap, masked Self-Attention就登场了,我在训练阶段,我就做一个masked,当你生成第一个词,我啥也不告诉你,当你生成第二个词,我告诉第一个词
问题二:为什么Encoder给予Decoders的是K、V矩阵
Q来源解码器,K=V来源于编码器
Q是查询变量,Q是已经生成的词
K=V是源语句
当我们生成这个词的时候,通过已经生成的词和源语句做自注意力,就是确定源语句中哪些词对接下来的词的生成更有作用。
通过部分(生 成的词)去全部(源语句)的里面挑重点
如果Q是源语句,K, V是已经生成的词,源语句去已经生成的词里找重点,找信息,已经生成的词里面压根就没有下一个词.
解决了以前的seq2seq框架的问题
Istm做编码器(得到词向量 C), 再用Istm做解码器做生成
用这种方法去生成词,每一次生成词,都是通过C的全部信息去生成
很多信息对于当前生成词而言都是没有意义的
Transformer实现
残差和标准化
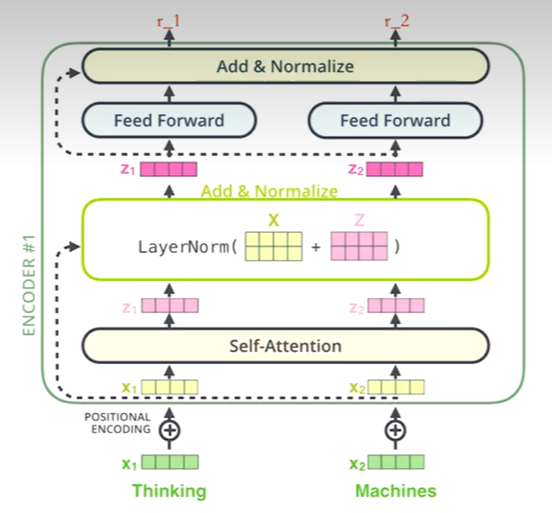
首先由一个norm函数
norm里面做残差,会输入(x和淡粉色z1,残差值),输出一个值紫粉色的 z1
class SublayerConnection(nn.Module):
# 这里不仅仅做残差,这是把残差和layernorm一起做了
def __init__(self,size,dropout=0.1):
super(SublayerConnection,self).__init__()
# 第一步做 layernorm
self.layer_norm = LayerNorm(size)
# 第二步做 dropout
self.dropout = nn.Dropout(p=dropout)
def forward(self,x,sublayer):
# x是self-attention的输入
# sublayer是self-attention
return self.dropout(self.layer_norm(x + sublayer(x)))
标准化

class LayerNorm(nn.Module):
def __init__(self,feature,eps=1e-6):
# feature:你的self-attention的x大小
super(LayerNorm,self).__init__()
# γ
self.a_2 = nn.Parameter(torch.ones(feature))
# β
self.b_2 = nn.Parameter(torch.zeros(feature))
# 防止分母为0
self.eps = eps
def forward(self,x):
# 这里的x是图中的X+Z
# 均值
mean = x.mean(-1,keepdim=True) # -1表示对最后一个维度取均值,keepdim表示保持维度不变
# 方差
std = x.std(-1,keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
多头注意力机制
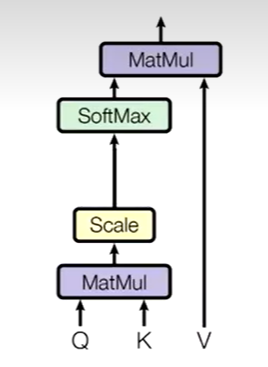
注意力机制就是QKV相乘,QK相乘得到相似度A,AV相乘得到注意力值Z
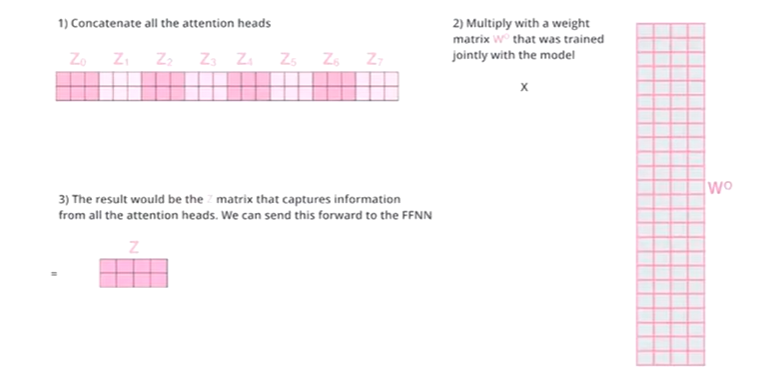
X乘以8个W矩阵,得到8个z,然后对这8个z做一个线性变化得到Z
第一步实现一个自注意力机制
def self_attention(query,key,value,dropout=None,mask=None):
d_k = query.size(-1)
# 除以math.sqrt(d_k)是做scale操作,让后面做softmax的时候,值会合理一点
scores = torch.matmul(query,key.transpose(-2,-1)) / math.sqrt(d_k)
# mask的操作在QK之后,softmax之前,这个mask在做解码器的时候会用到,也就是掩码自注意机制
if mask is not None:
mask.cuda()
# 将mask中值为0的,填充为-1e9
scores = scores.masked_fill(mask==0,-1e9)
self_attn = F.softmax(scores,dim=-1)
if dropout is not None:
self_attn = dropout(self_attn)
# 矩阵相乘就可以得到矩阵之间的关联性了
return torch.matmul(self_attn,value),self_attn
第二步实现多头注意力机制
class MultiHeadAttention(nn.Module):
def __init__(self,head,d_model,dropout=0.1):
super(MultiHeadAttention,self).__init__()
# head :头数
# d_model:输入的维度
#
assert(d_model % head == 0)
self.d_k = d_model // head
self.head = head
self.d_model = d_model
# 自注意力机制,QKV同源,线性变换
self.linear_query = nn.Linear(d_model,d_model)
self.linear_key = nn.Linear(d_model,d_model)
self.linear_value = nn.Linear(d_model,d_model)
self.linear_out = nn.Linear(d_model,d_model)
self.dropout = nn.Dropout(p=dropout)
self.attn = None
def forward(self,query,key,value,mask=None):
if mask is not None:
mask = mask.unsqueeze(1)
# 批量化处理,多头需要对这个X切分成多头,每个batch都需要对n_batch
n_batch = query.size(0)
query = self.linear_query(query).view(n_batch,-1,self.head,self.d_k).transpose(1,2) # [b,8,32,64]
key = self.linear_key(query).view(n_batch,-1,self.head,self.d_k).transpose(1,2) # [b,8,32,64]
value = self.linear_value(query).view(n_batch,-1,self.head,self.d_k).transpose(1,2) #[b,8,28,64]
x,self.attn = self_attention(query,key,value,dropout=self.dropout,mask=mask)
# [b,8,32,64]
# 变为三维
x = x.transpose(1,2).contiguous().view(n_batch,-1,self.head*self.d_k) # [b,32,512]
return self.linear_out(x)
- 关于Q,K,V的shape问题
交叉注意力机制
Q 和 V shape不同,但是 K 和 V 相同
cyd 注意力机制
Q 和 V shape不同,Q 和 K 相同
xxx 注意力机制
Q 必须为 1,K 和 V 不同源
Positional encoding
这个位置编码,确定每句话中单词的位置信息,不同的位置信息,所产生的句子具有不同的含义
比如
"我等你"
"你等我"
“我”和“你”在这句话中位置信息,句子的意思也不同

class PositionalEncoding(nn.Module):
def __init__(self,dim,dropout,max_len=5000):
super(PositionalEncoding,self).__init__()
# 词向量的维度必须是偶数维
if dim % 2 != 0:
raise ValueError("Cannot use sin/cos positional encoding with odd dim (got dim={:d})".format(dim))
pe = torch.zeros(max_len,dim) # max_len是解码器生成句子的最长的长度
position = torch.arange(0,max_len).unsqueeze(1)
div_term = torch.exp((torch.arange(0,dim,2,dtype=torch.float) * -(math.log(10000.0) / dim)))
pe[:,0::2] = torch.sin(position.float() * div_term)
pe[:,1::2] = torch.cos(position.float() * div_term)
pe = pe.unsqueeze(1)
self.register_buffer('pe',pe)
self.drop_out = nn.Dropout(p=dropout)
self.dim = dim
def forward(self,emb,step=None):
emb = emb * math.sqrt(self.dim) # 没什么影响,不重要
# 这个emb就是字向量x
# emb [seq_len,batch_size,....]
if step is None: # 表示输入是某句话
emb = emb + self.pe[:emb.size(0)] # word_embedding + position_encoding
else: # 表示输入是某个词
emb = emb + self.pe[step] # 取某个词的词向量
return emb
前馈神经网络FFN
class PositionWiseFeedForward(nn.Module):
def __init__(self,d_model,d_ff,dropout=0.1):
super(PositionWiseFeedForward,self).__init__()
self.w_1 = nn.Linear(d_model,d_ff)
self.w_2 = nn.Linear(d_ff,d_model)
self.layer_norm = nn.LayerNorm(d_model,eps=1e-6)
self.dropout_1 = nn.Dropout(dropout)
self.relu = nn.ReLU()
self.dropout_2 = nn.Dropout(dropout)
def forward(self,x):
inter = self.dropout_1(self.relu(self.w_1(self.layer_norm(x))))
output = self.dropout_2(self.w_2(inter))
return output
Linear+Softmax实现
class Generator(nn.Module):
def __init__(self,d_model,vocab_size):
super(Generator,self).__init__()
self.linear = nn.Linear(d_model,vocab_size)
def forward(self,x):
return F.log_softmax(self.linear(x),dim=-1)
掩码的多头注意力机制
def subsequent_mask(size):
attn_shape = (1,size,size)
mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')
return (torch.from_numpy(mask) == 0).cuda()
Encoder实现
def clones(module,n):
return nn.ModuleList([copy.deepcopy(module) for _ in range(n)])
# 单层encoder
class Encoderlayer(nn.Module):
def __init__(self,size,attn,feed_forward,dropout=0.1):
super(EncoderLayer,self).__init__()
self.attn = attn
self.feed_forward = feed_forward
# encoder有两个 残差连接和标准化,所以这里克隆2次
self.sublayer_connection = clones(SublayerConnection(size,dropout),2)
def forward(self,x,mask):
# 这一个实现的是多头注意力,后面的attn()中x分别是q,k,v
x = self.sublayer_connection[0](x,lambda x:self.attn(x,x,x,mask))
return self.sublayer_connection[1](x,self.feed_forward)
# 多层encoder
class Encoder(nn.Module):
def __init__(self,n,encoder_layer):
super(Encoder,self).__init__()
self.encoder_layer = clones(encoder_layer,n)
def forward(self,x,src_mask):
for layer in self.encoder_layer:
x = layer(x,src_mask)
return x
Decoder实现
class DecoderLayer(nn.Module):
def __init__(self,size,attn,feed_forward,sublayer_num,dropout=0.1):
super(DecoderLayer,self).__init__()
# 多头注意力机制
self.attn = attn
# FFN
self.feed_forward = feed_forward
self.sublayer_connection = clones(SublayerConnection(size,dropout),sublayer_num)
def forward(self,x,memory,src_mask,trg_mask,r2l_memory=None,r2l_trg_mask=None):
x = self.sublayer_connection[0](x,lambda x:self.attn(x,x,x,trg_mask))
# memory是编码器的输出
x = self.sublayer_connection[1](x,lambda x:self.attn(x,memory,memory,src_mask))
# 双向解码器
if r2l_memory is not None:
x = self.sublayer_connection[-2](x,lambda x:self.attn(x,r))
return self.sublayer_connection[-1](x,self.feed_forward)
wordEmbedding
class TextEmbedding(nn.Module):
def __init__(self,vocab_size,d_model):
super(TextEmbedding,self).__init__()
self.d_model = d_model
self.embed = nn.Embedding(vocab_size,d_model)
def forward(self,x):
return self.embed(x) * math.sqrt(self.d_model)
本文作者:放学别跑啊
本文链接:https://www.cnblogs.com/bzwww/p/16805532.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步