

Deep Learning 学习随记(三)Softmax regression
讲义中的第四章,讲的是Softmax 回归。softmax回归是logistic回归的泛化版,先来回顾下logistic回归。
logistic回归:
训练集为{(x(1),y(1)),...,(x(m),y(m))},其中m为样本数,x(i)为特征。
logistic回归是针对二分类问题的,因此类标y(i)∈{0,1},。其估值函数(hypothesis )如下:
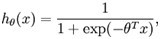
代价函数:
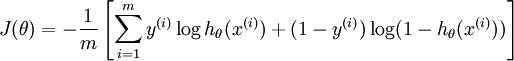
softmax 回归:
softmax回归解决的是多分类问题,即y(i)∈{1,2,...,k}。(这里softmax回归一般从类别1开始,而不是从0)。
其估值函数形式如下:

为了方便起见,我们同样使用符号θ来表示全部的模型参数。在实现softmax回归时,你通常会发现,将θ用一个k×(n+1)的矩阵来表示会十分便利,该矩阵是将θ1,θ2,...,θk按行罗列起来得到的,如下所示:
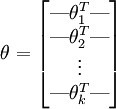
下面是softmax回归的代价函数:

可以看出softmax是logistic的一个泛化版。logistic是k=2情况下的softmax回归。
为了求解J(θ),通常借助于梯度下降法或L-BFGS算法等迭代优化算法。经过求导,我们可以得到梯度公式为:
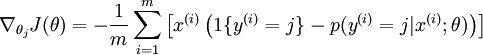
有了上面的偏导数公式以后,我们就可以将它带入到梯度下降法等算法中,来使J(θ)最小化。例如,在梯度下降法标准实现的每一次迭代中,我们需要进行如下更新:
 (对每个j=1,2,...k)
(对每个j=1,2,...k)
有一点需要注意的是,按上述方法用softmax求得的参数并不是唯一的,因为,对每一个参数来说,若都减去一个相同的值,依然是上述的代价函数的值。证明如下:
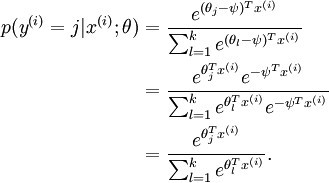
这表明了softmax回归中的参数是“冗余”的。更正式一点来说,我们的softmax模型被过度参数化了,这意味着对于任何我们用来与数据相拟合的估计值,都会存在多组参数集,它们能够生成完全相同的估值函数hθ将输入x映射到预测值。因此使J(θ)最小化的解不是唯一的。而Hessian矩阵是奇异的/不可逆的,这会直接导致Softmax的牛顿法实现版本出现数值计算的问题。
为了解决这个问题,加入一个权重衰减项到代价函数中:
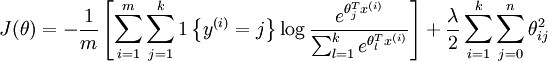
有了这个权重衰减项以后(对于任意的λ>0),代价函数就变成了严格的凸函数而且hession矩阵就不会不可逆了。
此时的偏导数:

softmax 练习:
这里讲义同样给出了练习题,打算自己写写看,暂时先写到这,接下来有时间把自己写好的代码贴上来。

