
数据结构与算法之美学习笔记(二叉树基础)
目录:
- 树的基础知识
- 二叉树、满二叉树、完全二叉树
- 如何遍历一棵树
- 什么是二叉查找树
- 二叉查找树的增删改的实现
- 二叉查找树中的重复数据如何处理
- 散列表已经这么强了,为什么还要有二叉查找树(二叉查找树相对于散列表的优势)
笔记参考:
树的基础知识
1、什么是树

2、树的基本概念
节点、父子关系:
- 节点:图中的圆点就是树的元素,我们把它叫做节点。
- 父子关系:用来连接节点之间关系,叫做“父子关系”。
树的根节点、父节点、子节点、叶子节点、兄弟节点:

- 父节点:A节点是B、C、D的父节点。
- 子节点:同理B、C、D是A节点的子节点。
- 叶子节点:没有子节点的叫做叶子节点,也叫叶节点,如G、H、I、J、K、L。
- 兄弟节点:拥有同一个父节点的节点们叫做兄弟节点,如B、C、D是父节点,K、L是父节点等。
- 树的根节点:没有父节点的节点叫做,如图中E就是树的根节点。
节点高度、节点深度、节点的层数、树的高度:还是用上图来理解。
- 节点高度:该节点到叶子节点的最长路径(边数,从0开始计算),如F到叶子节点的最长路径也就是到G、H、I、J,所以F节点的高度为2。
- 节点深度:根节点到该节点的所经历的边数(从0开始计算),如C就是2。
- 节点的层数:节点深度加1。
- 树的高度:根节点的高度。
再来看个简单的例子:

二叉树、满二叉树、完全二叉树
满足树的条件,且一个节点最多只能有两个子节点的树就叫做二叉树,分别是左子树和右子树,如下图。
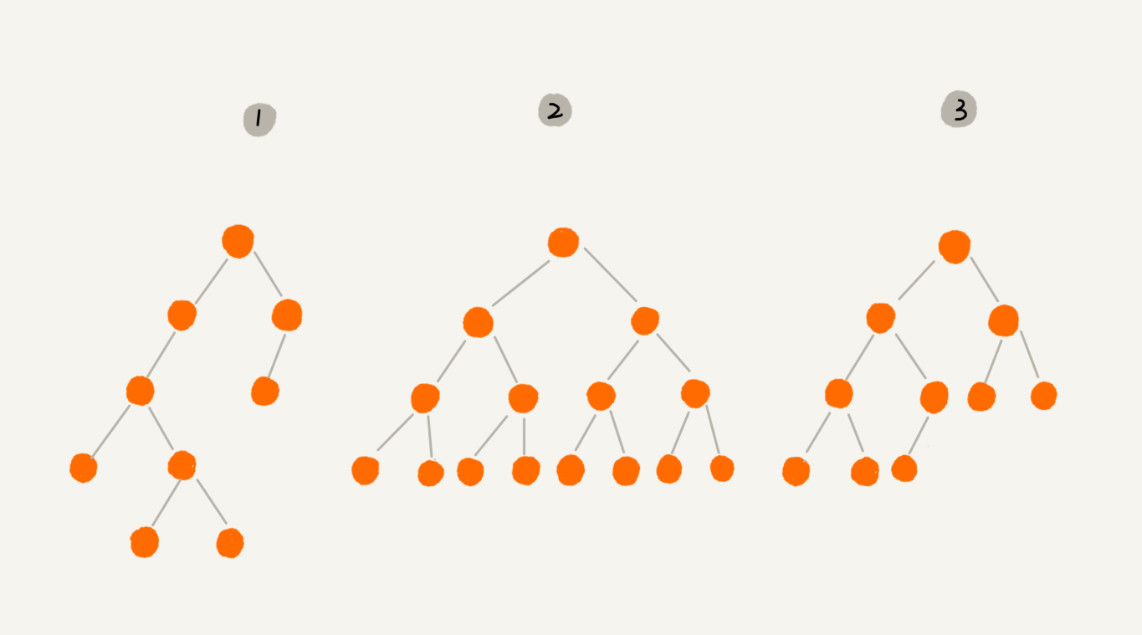
这个图里面,有两个比较特殊的二叉树,分别是编号2和编号3这两个。
编号2是满二叉树,编号3是完全二叉树。
1、满二叉树:
- 所有叶子节点都在最后一层,并且节点总数为2 ^ n - 1,其中n为树层数。
- 除叶子节点之外,每个节点都有左右两个子节点。
2、完全二叉树:
- 叶子节点都在最底下两层。
- 最后一层的叶子节点都靠左排列,并且除了最后一层,其它层的节点个数都要达到最大。

从长相上来看完全二叉树也不具有特殊性啊,为什么要单独把这种树拎出来呢?
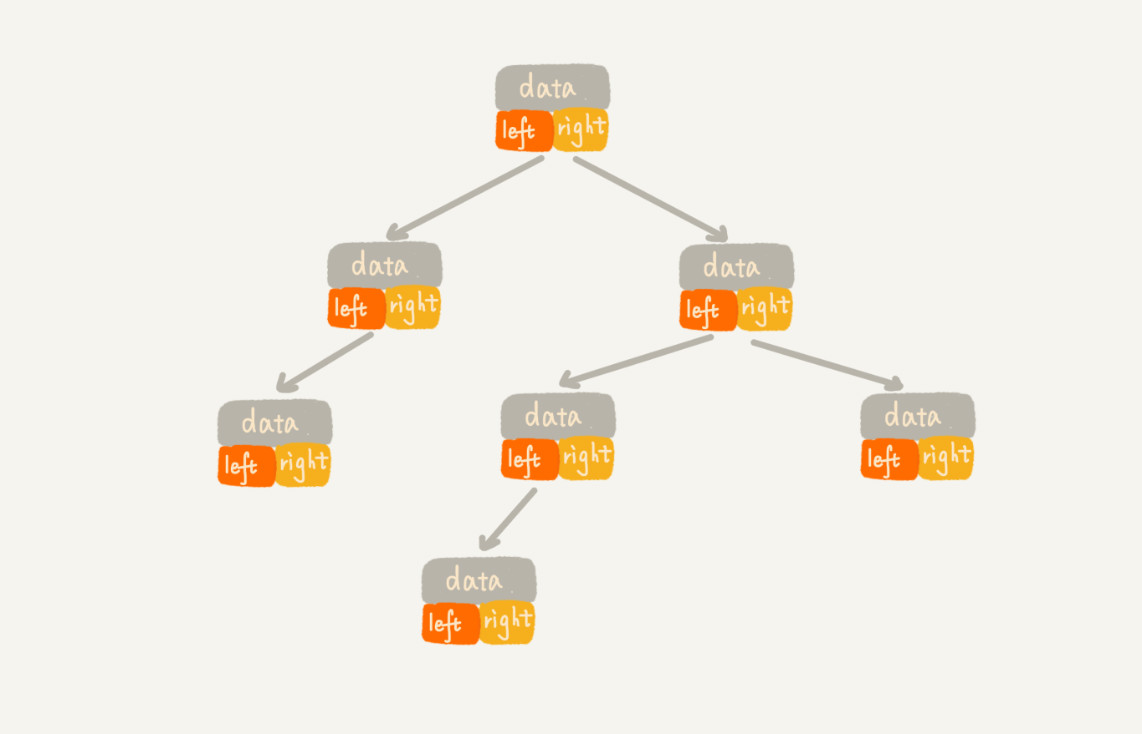
首先要了解到,表示一棵树可以用数组,也可以用链表(链表更直观些),就长下面那样。
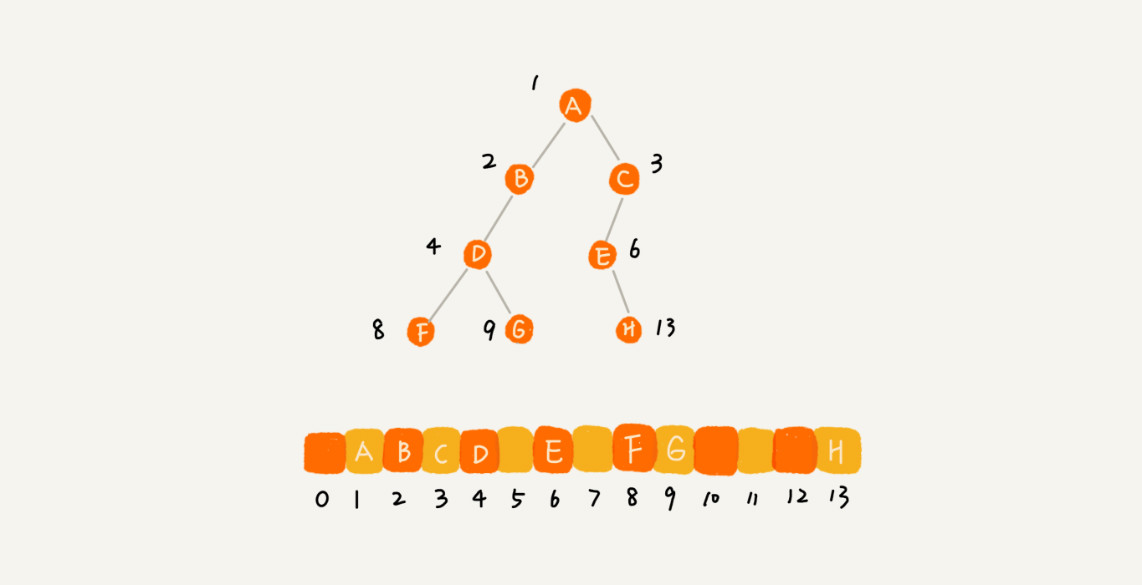
基于数组的顺序存储法,我们把根节点存储在下标 i = 1 的位置,那左子节点存储在下标 2 * i = 2 的位置,右子节点存储在 2 * i + 1 = 3 的位置。以此类推,B 节点的左子节点存储在 2 * i = 2 * 2 = 4 的位置,右子节点存储在 2 * i + 1 = 2 * 2 + 1 = 5 的位置。

也就是说,我们舍弃下标为0的空间,如果节点 X 存储在数组中下标为 i 的位置,下标为 2 * i 的位置存储的就是左子节点,下标为 2 * i + 1 的位置存储的就是右子节点。反过来,下标为 i/2 的位置存储就是它的父节点。通过这种方式,我们只要知道根节点存储的位置(一般情况下,为了方便计算子节点,根节点会存储在下标为 1 的位置),这样就可以通过下标计算,把整棵树都串起来。
综上,完全二叉树只需要浪费下标为0的空间就可以很好的把树串联起来了,如果不是完全二叉树的话则会浪费调很多空间。
所以,如果某棵二叉树是一棵完全二叉树,那用数组存储无疑是最节省内存的一种方式。因为数组的存储方式并不需要像链式存储法那样,要存储额外的左右子节点的指针。这也是为什么完全二叉树会单独拎出来的原因,也是为什么完全二叉树要求最后一层的子节点都靠左的原因。
如何遍历一棵树
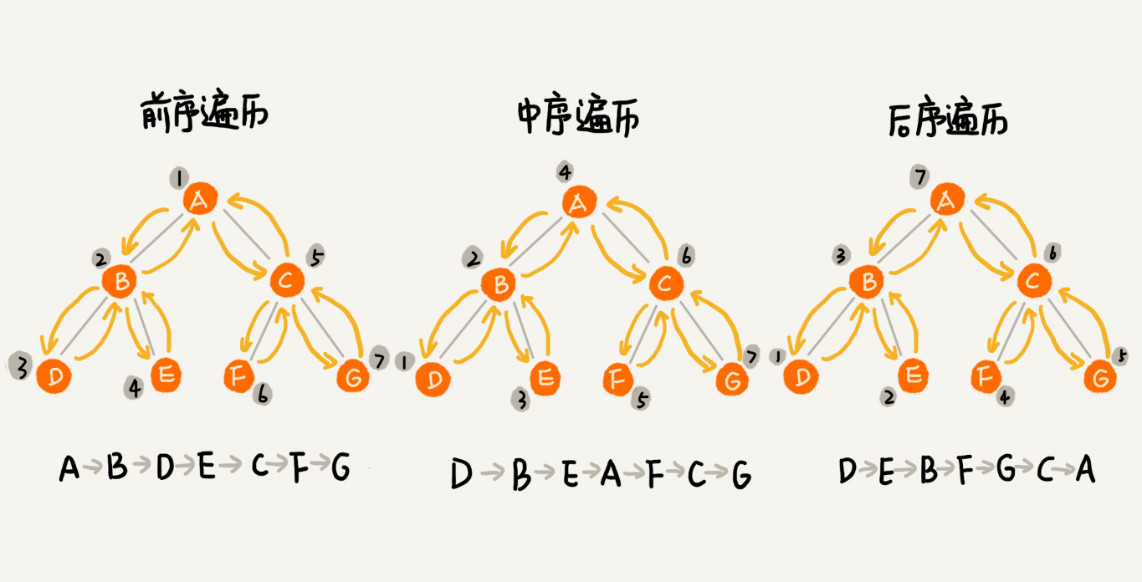
经典的方法有三种,前序遍历、中序遍历和后序遍历。
- 前序遍历是指,对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树。
- 中序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树。
- 后序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点本身。
1 public class BinaryTree { 2 3 /** 4 * 前序遍历 5 */ 6 public void preOrder(Node treeNode) { 7 if (treeNode == null) { 8 return; 9 } 10 System.out.print(treeNode.value + " "); 11 preOrder(treeNode.left); 12 preOrder(treeNode.right); 13 } 14 15 /** 16 * 中序遍历 17 */ 18 public void inOrder(Node treeNode) { 19 if (treeNode == null) { 20 return; 21 } 22 inOrder(treeNode.left); 23 System.out.print(treeNode.value + " "); 24 inOrder(treeNode.right); 25 } 26 27 /** 28 * 后序遍历 29 */ 30 public void postOrder(Node treeNode) { 31 if (treeNode == null) { 32 return; 33 } 34 postOrder(treeNode.left); 35 postOrder(treeNode.right); 36 System.out.print(treeNode.value + " "); 37 } 38 39 /** 40 * 树节点 41 */ 42 public static class Node { 43 int value; 44 Node left; 45 Node right; 46 47 public Node(int value) { 48 this.value = value; 49 } 50 51 public Node(int value, Node left, Node right) { 52 this.value = value; 53 this.left = left; 54 this.right = right; 55 } 56 } 57 58 }
什么是二叉查找树
二叉查找树是二叉树中最常用的一种类型,也叫二叉搜索树。顾名思义,二叉查找树是为了实现快速查找而生的。不过,它不仅仅支持快速查找一个数据,还支持快速插入、删除一个数据。它是怎么做到这些的呢?
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值(中序遍历二叉查找树可以输出有序的数据序列)。
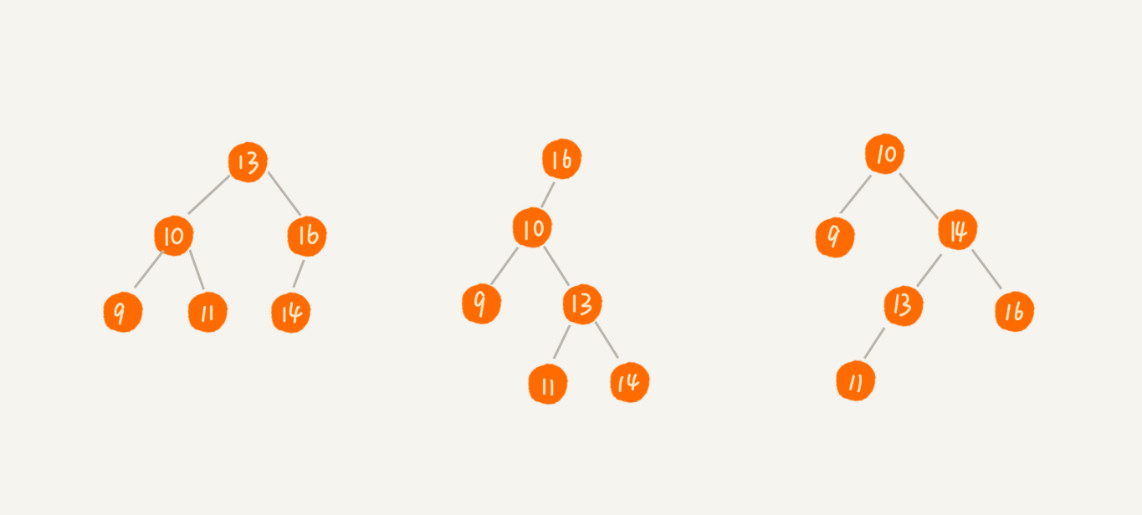
二叉查找树的增删查的实现
1、查询数据:
- 先取根节点,如果满足则返回根节点。
- 如果小于根节点则在左子树递归查找,大于则在右子树递归查找。

2、添加数据:
- 若根节点无数据则将数据放入根节点。
- 插入数据比节点大且右子树为空,则直接插入到右子节点;如果不为空,则递归遍历右子树。
- 同理,插入数据比节点小且左子树为空,则直接插入到左子节点;如果不为空,则递归遍历左子树。
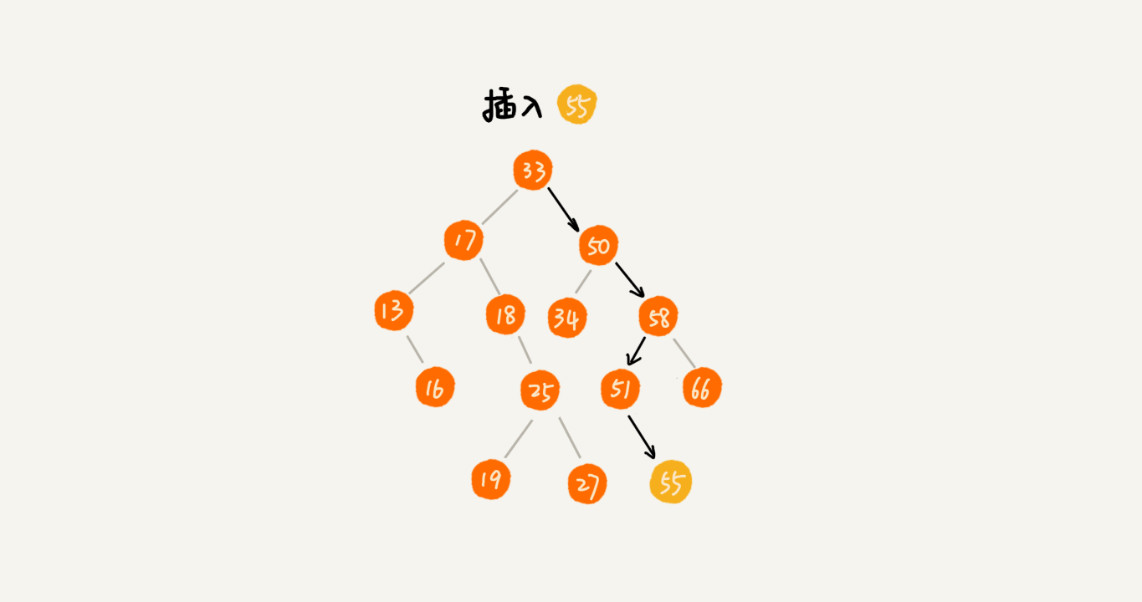
3、删除数据:
- 删除的是叶子节点,只需要将父节点中指向要删除节点的指针置为null。
- 删除的节点只有一个子节点(左子节点或右子节点),我们只需要将其父节点的指向改为其子节点即可(需要根据大小判断放在左还是右)。
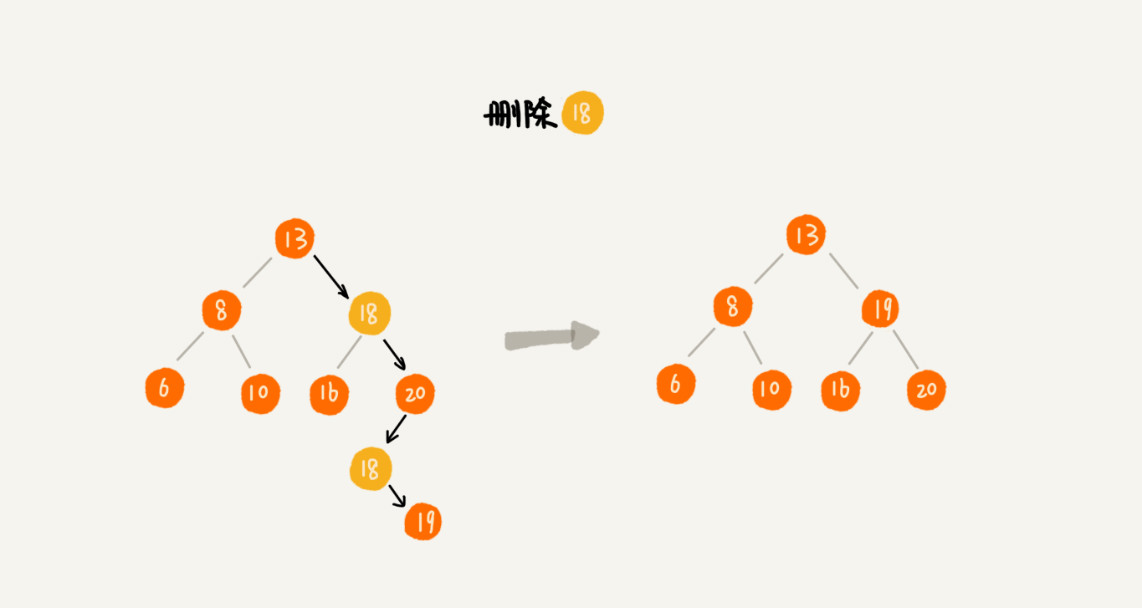
- 删除的节点有两个子节点,找到该节点右子树中最小的节点,把它替换到删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了)。
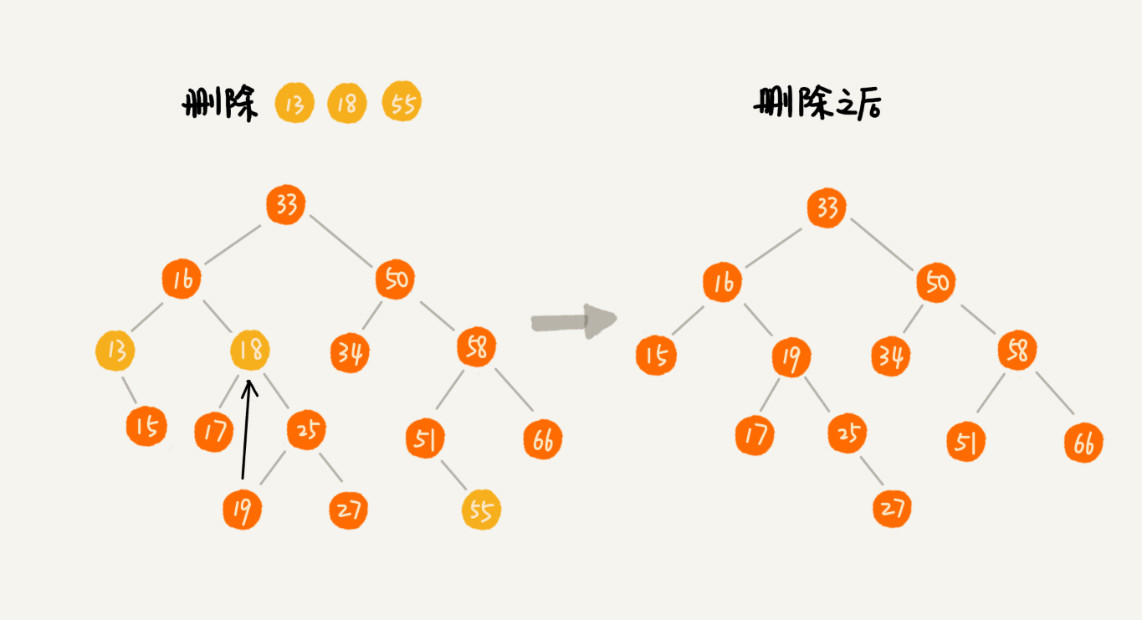
二叉查找树的查找、插入操作都比较简单易懂,但是它的删除操作就比较复杂了 。针对要删除节点的子节点个数的不同,我们需要分三种情况来处理。
- 第一种情况是,如果要删除的节点没有子节点,我们只需要直接将父节点中,指向要删除节点的指针置为 null。比如图中的删除节点 55。
- 第二种情况是,如果要删除的节点只有一个子节点(只有左子节点或者右子节点),我们只需要更新父节点中,指向要删除节点的指针,让它指向要删除节点的子节点就可以了。比如图中的删除节点 13。
- 第三种情况是,如果要删除的节点有两个子节点,这就比较复杂了。我们需要找到这个节点的右子树中的最小节点,把它替换到要删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了),所以,我们可以应用上面两条规则来删除这个最小节点。比如图中的删除节点 18。
实际上,关于二叉查找树的删除操作,还有个非常简单、取巧的方法,就是单纯将要删除的节点标记为“已删除”,但是并不真正从树中将这个节点去掉。
这样原本删除的节点还需要存储在内存中,比较浪费内存空间,但是删除操作就变得简单了很多。而且,这种处理方法也并没有增加插入、查找操作代码实现的难度。
1 public class BinaryTree { 2 3 /** 4 * 根节点 5 */ 6 private Node root; 7 8 /** 9 * 1、先取根节点,如果满足则返回根节点。 10 * 2、如果小于根节点则在左子树递归查找,大于则在右子树递归查找。 11 * 12 * @param value 查询的值 13 */ 14 public Node find(int value) { 15 Node node = root; 16 while (node != null) { 17 if (value > node.value) { 18 node = node.right; 19 } 20 else if (value < node.value) { 21 node = node.left; 22 } 23 else { 24 // value == node.value 25 return node; 26 } 27 } 28 return null; 29 } 30 31 /** 32 * 1、若根节点无数据则将数据放入根节点。 33 * 2、插入数据比节点大且右子树为空,则直接插入到右子节点;如果不为空,则递归遍历右子树。 34 * 3、同理,插入数据比节点小且左子树为空,则直接插入到左子节点;如果不为空,则递归遍历左子树。 35 * 36 * @param value 插入的值 37 */ 38 public void insert(int value) { 39 if (root == null) { 40 root = new Node(value); 41 return; 42 } 43 Node node = root; 44 while (node != null) { 45 if (value > node.value) { 46 if (node.right == null) { 47 node.right = new Node(value); 48 return; 49 } 50 node = node.right; 51 } 52 else { 53 // value <= node.value 54 if (node.left == null) { 55 node.left = new Node(value); 56 return; 57 } 58 node = node.left; 59 } 60 } 61 } 62 63 /** 64 * 1、删除的是叶子节点,只需要将父节点中指向要删除节点的指针置为null。 65 * 2、删除的节点只有一个子节点(左子节点或右子节点),我们只需要将其父节点的指向改为其子节点即可(需要根据大小判断放在左还是右)。 66 * 3、删除的节点有两个子节点,找到该节点右子树中最小的节点,把它替换到删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了)。 67 * 68 * @param value 删除的值 69 */ 70 public void delete(int value) { 71 // p指向要删除的节点,初始化指向根节点 72 Node p = root; 73 // pp记录的是p的父节点 74 Node pp = null; 75 // 找到要删除的节点 76 while (p != null && p.value != value) { 77 pp = p; 78 if (value > p.value) { 79 p = p.right; 80 } 81 else { 82 p = p.left; 83 } 84 } 85 if (p == null) { 86 // 没有找到要删除的节点 87 return; 88 } 89 90 // 要删除的节点有两个子节点,找到右子树的最小节点 91 if (p.left != null && p.right != null) { 92 Node minp = p.right; 93 Node minpp = p; 94 while (minp.left != null) { 95 minpp = minp; 96 minp = minp.left; 97 } 98 // 将minp的数据替换到p中 99 p.value = minp.value; 100 p = minp; 101 pp = minpp; 102 } 103 104 // 删除节点是叶子节点或仅有一个子节点 105 Node child; 106 if (p.left != null) { 107 child = p.left; 108 } 109 else if (p.right != null) { 110 child = p.right; 111 } 112 else { 113 child = null; 114 } 115 116 if (pp == null) { 117 // 删除的是根节点 118 root = child; 119 } 120 else if (pp.left == p) { 121 pp.left = child; 122 } 123 else { 124 pp.right = child; 125 } 126 } 127 128 /** 129 * 前序遍历 130 */ 131 public void preOrder(Node treeNode) { 132 if (treeNode == null) { 133 return; 134 } 135 System.out.print(treeNode.value + " "); 136 preOrder(treeNode.left); 137 preOrder(treeNode.right); 138 } 139 140 /** 141 * 中序遍历 142 */ 143 public void inOrder(Node treeNode) { 144 if (treeNode == null) { 145 return; 146 } 147 inOrder(treeNode.left); 148 System.out.print(treeNode.value + " "); 149 inOrder(treeNode.right); 150 } 151 152 /** 153 * 后序遍历 154 */ 155 public void postOrder(Node treeNode) { 156 if (treeNode == null) { 157 return; 158 } 159 postOrder(treeNode.left); 160 postOrder(treeNode.right); 161 System.out.print(treeNode.value + " "); 162 } 163 164 /** 165 * 树节点 166 */ 167 public static class Node { 168 int value; 169 Node left; 170 Node right; 171 172 public Node(int value) { 173 this.value = value; 174 } 175 176 public Node(int value, Node left, Node right) { 177 this.value = value; 178 this.left = left; 179 this.right = right; 180 } 181 } 182 183 }
1 public class BinaryTreeTest { 2 3 public static void main(String[] args) { 4 // 4 5 // 2 6 6 // 1 3 5 7 7 BinaryTree binaryTree = new BinaryTree(); 8 binaryTree.insert(4); 9 binaryTree.insert(2); 10 binaryTree.insert(6); 11 binaryTree.insert(1); 12 binaryTree.insert(3); 13 binaryTree.insert(5); 14 binaryTree.insert(7); 15 16 BinaryTree.Node node = binaryTree.find(4); 17 System.out.println("----- 二叉树前序遍历 -----"); 18 binaryTree.preOrder(node); 19 System.out.println("\r\n----- 二叉树中序遍历 -----"); 20 binaryTree.inOrder(node); 21 System.out.println("\r\n----- 二叉树后序遍历 -----"); 22 binaryTree.postOrder(node); 23 24 binaryTree.delete(4); 25 } 26 27 }
二叉查找树中的重复数据如何处理
1、节点扩展:比较容易。
二叉查找树中每一个节点不仅会存储一个数据,因此我们通过链表和支持动态扩容的数组等数据结构,把值相同的数据都存储在同一个节点上。
2、当成新节点处理:不好理解,不过更加优雅。
每个节点仍然只存储一个数据。在查找插入位置的过程中,如果碰到一个节点的值,与要插入数据的值相同,我们就将这个要插入的数据放到这个节点的右子树,也就是说,把这个新插入的数据当作大于这个节点的值来处理。
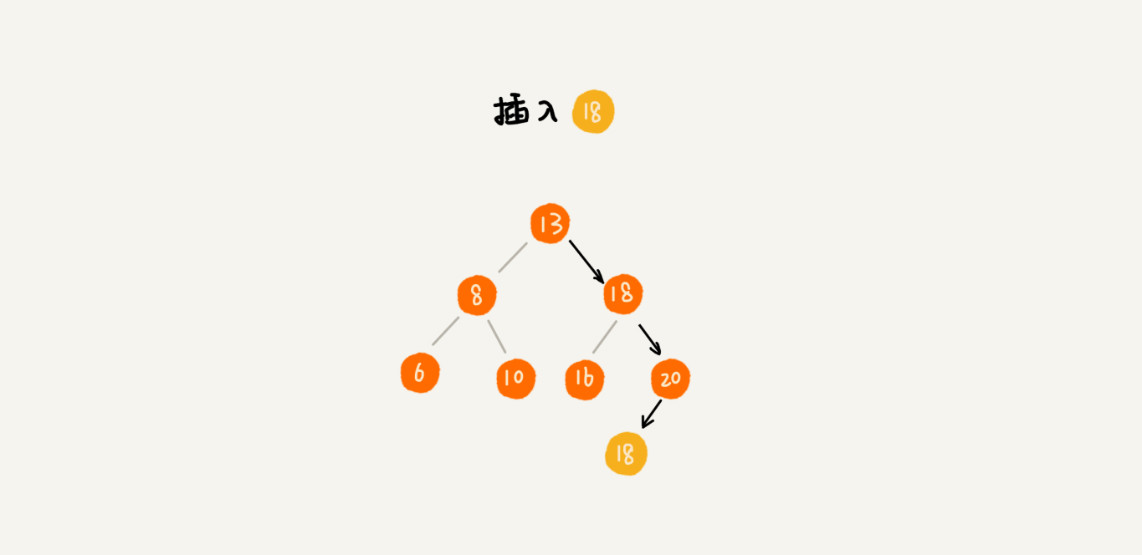
当要查找数据的时候,遇到值相同的节点,我们并不停止查找操作,而是继续在右子树中查找,直到遇到叶子节点,才停止。这样就可以把键值等于要查找值的所有节点都找出来。

对于删除操作,我们也需要先查找到每个要删除的节点,然后再按前面讲的删除操作的方法,依次删除。
散列表已经这么强了,为什么还要有二叉查找树(二叉查找树相对于散列表的优势)
1、第一,二叉树有先天的排序优势:散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找树来说,我们只需要中序遍历,就可以在 O(n) 的时间复杂度内,输出有序的数据序列。
2、第二,散列表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳定,但是在工程中,我们最常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在 O(logn)。
3、第三,笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数的耗时,也不一定就比平衡二叉查找树的效率高。
4、第四,散列表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定。
5、最后,为了避免过多的散列冲突,散列表装载因子不能太大,特别是基于开放寻址法解决冲突的散列表,不然会浪费一定的存储空间。综合这几点,平衡二叉查找树在某些方面还是优于散列表的,所以,这两者的存在并不冲突。我们在实际的开发过程中,需要结合具体的需求来选择使用哪一个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号