JVM学习笔记(二、Class文件结构)
目录:
- Java虚拟机简介
- Class类文件结构
- Class类文件结构详解
Java虚拟机简介
在介绍JVM前首先我们来看看java的口号:一次编译到处运行。那这句话我们要怎么理解呢,换句话来说,java是如何实现一次编译到处运行的呢?
周所周知,机器识别的是二进制的数据,JVM是java程序的抽象计算器,它包含在JRE中,而每个操作系统安装的JRE版本都是不同的,有windows、linux、mac等等。源文件可通过编译编程class字节码文件,JVM能将字节码文件转换成计算器可执行的二进制文件。
综上,java实现一次编译到处运行这一功能功能就是通过在不同的平台相对应的JVM来实现的。
Java虚拟机(JVM)是运行Java程序的抽象计算机,它是一种计算机设备的规范,可以采用不同的方式进行实现。Java程序通过运行在JVM中从而实现跨平台特性。
Java虚拟机不和包括Java在内的任何语言绑定,它只和Class文件这种特定的二进制文件格式关联,Class文件中包含了虚拟机指令集和符号表以及若干其他辅助信息。
基于安全方面的考虑,Java虚拟机规范要求在Class文件中使用许多强制性的语法和结构化约束,但任一门功能性语言都可以表示为一个能被Java虚拟机所接受的有效Class文件。
这里就会涉及到一个问题,是不是只有Java编译器才能完成Java到class字节码文件的编译过程?
答案是当然不是,像Java/JRuby/Groovy等程序都可以通过自己的编译器转成字节码(class)文件,然后交给JVM。

Class类文件结构
Class文件是一组以8位字节为基础单位的二进制流,各项数据项目严格按照顺序紧凑地排列在Class文件之中,中间没有添加任何分隔符,如果是超过8位字节以上空间的数据项,则会按照高位在前的方式(Big-Endian)分割成若干个8位字节进行存储。
上面的概念说到了一个高位在前的方式,那这个高位在前是什么意思呢?
举个例子,数字123的读法就是高位在前的方式,因为它的含义是一百二十三;如果123代表的含义是三百二十一,那么这就是低位在前的方式。
换算成字节来说,8字节的高位在前;第1个字节表示56bit - 63bit,第2字节表示48bit - 55bit,以此类推第8个字节就表示0bit - 7bit。
基本概念说完了,接下来我们来看下一个Class类文件的基本构成。

其中u1、u2、u4、u8分别表示一个字节、两个字节、四个字节、八个字节;*_info表示符号表。
也就是说Class文件中只有两种数据类型:
- 无符号数,u1、u2、u4、u8这种。
- 符号表,*_info:表是由多个无符号数或者其它表作为数据项构成的复合数据类型,所有表都习惯性地以_info结尾。表用于描述由层次关系的复合结构的数据,整个Class文件本质上就是一张表 。
综上Class类文件的结构可以类比成一个json串,无符号数表示一个个的属性,符号表表示一个json对象。
1 { 2 "name": "xxx", 3 "age": 18, 4 "userInfo": { 5 "address": "上海" 6 } 7 }
name、age就是无符号数,userInfo就是符号表,而这个json传其实也就是一个json对象,故整个Class文件本质就是一张表。
上面的图包含了Class文件的基本构成,而它的具体含义如下:
|
构成元素 |
字节数 |
变量名说明 |
数量 |
|
魔数 |
u4 |
magic |
1 |
|
次版本号 |
u2 |
minor_version |
1 |
|
主版本号 |
u2 |
major_version |
1 |
|
常量池计数器 |
u2 |
constant_pool_count |
1 |
|
常量池 |
cp_info |
constant_pool |
constant_pool_count-1 |
|
访问标志 |
u2 |
access_flags |
1 |
|
类索引 |
u2 |
this_class |
1 |
|
父类索引 |
u2 |
super_class |
1 |
|
接口计数器 |
u2 |
interfaces_class |
1 |
|
接口索引集合 |
u2 |
interfaces |
interfaces_count |
|
字段计数器 |
u2 |
fields_count |
1 |
|
字段表集合 |
field_info |
fields |
fields_count |
|
方法计数器 |
u2 |
methods_count |
1 |
|
方法表集合 |
method_info |
methods |
methods_count |
|
属性计数器 |
u2 |
attributes_count |
1 |
|
属性表集合 |
attribute_info |
attributes |
attributes_count |
Class类文件结构详解
在分析class类文件结构前,我们需要准备一个java文件,我把我分析的源文件贴在下面,因不同机器不同版本的JDK编译的字节码文件不太一样我就不展示我的字节码文件了,但分析的方法都是一致的。
1 public class TestClass { 2 3 private int count; 4 5 public void inc() { 6 count++; 7 } 8 9 public int getCount() { 10 return count; 11 } 12 13
1、魔数 u4
每个Class文件的头四个字节数为魔数,唯一作用是确定这个文件是否是能被虚拟机接受的Class文件。
目前版本的值都是固定的,0xCAFEBABE(咖啡宝贝)。

次版本号、主版本号 u2、u2
紧接着魔数的是次版本号与主版本号,也就是5bit - 8bit。对应的16进制码分别为00 00 00 34,换算成10进制就是0和52,而52就是java8。
常量池计数器 u2
常量池计数器字节数为2,得到00 17,十进制为23。我们通过【javap -v class文件路径】来验证一下常量池的数量是否正确。
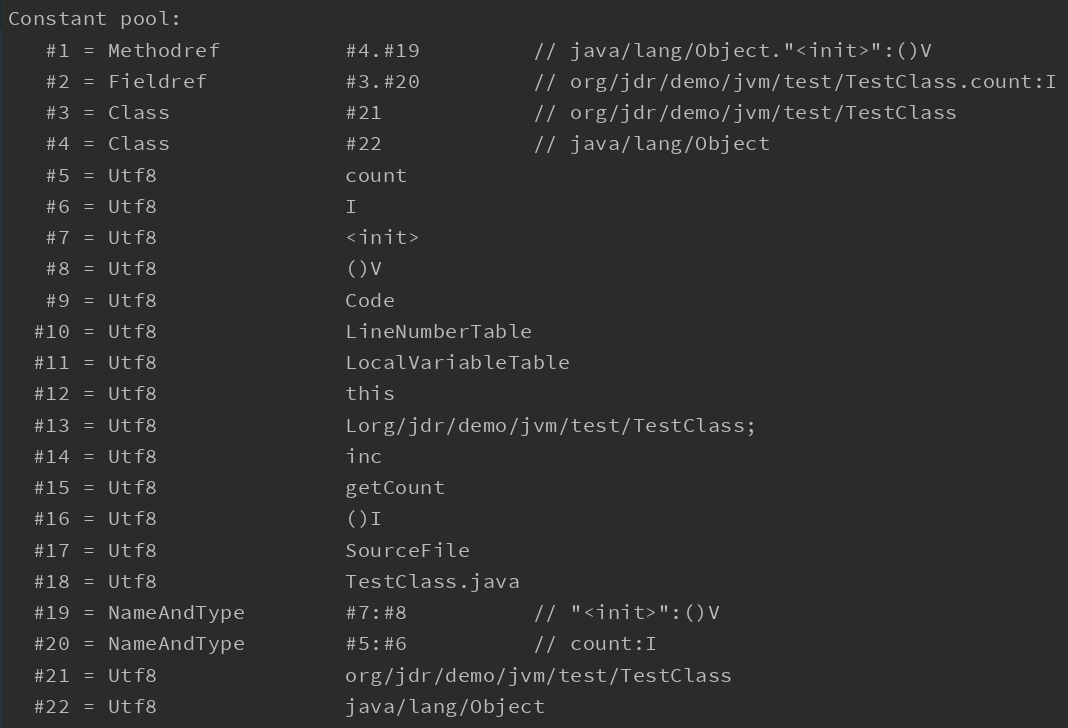
果然常量池中的常量数 = 常量池计数器 - 1
常量池
因为字段、方法引用只能通过运行期得到真正的内存地址入口,所以Java代码在编译后拿不到引用类实际的内存。因此Class文件并不会保存各个方法、字段的最终内存布局,只能使用“符号引用”来代替。
正因上面这些限制,JVM运行时就只能另辟蹊径的来创建或运行时解析具体的内存地址,辟蹊径的方式就是用符号引用,既然我拿不到那我就先标记一下,在运行时我再拿嘛。
那常量池是什么呢,我们想想啊,当符号引用较多时肯定是难以管理的,所以就要有一个工具来帮住我们管理这些符号引用,而常量池正是存储符号引用的容器。
比如:在类加载器加载Test类时,可以通过虚拟机先获取Test类的实际内存地址,然后将它标记为一个符号引用,key=xxx.xxx.Test,value=实际的内存地址。相当于预初始化类的内存地址,具体的字段及方法引用等运行期动态创建,这样就可以解决上面尴尬的问题啦。
上面说了常量池存的是符号引用,那么符号引用包含哪些常量呢:
- 类和接口的全限定名,如org.springframework.web.servlet.DispatherServlet。
- 字段的名称和描述符。
- 方法的名称和描述符。
而这三类常量又可大分为两类常量,字面量和符号引用。符号引用我们说了,字面量就是=号右边的那个值,如int i = 1,1就是字面量。
然后我们来看下常量池的结构:
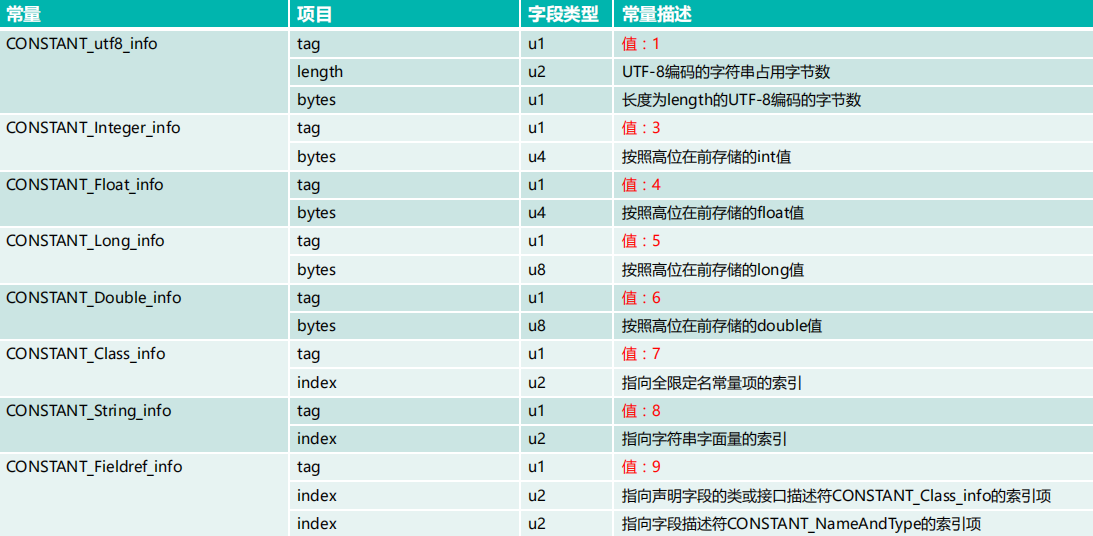
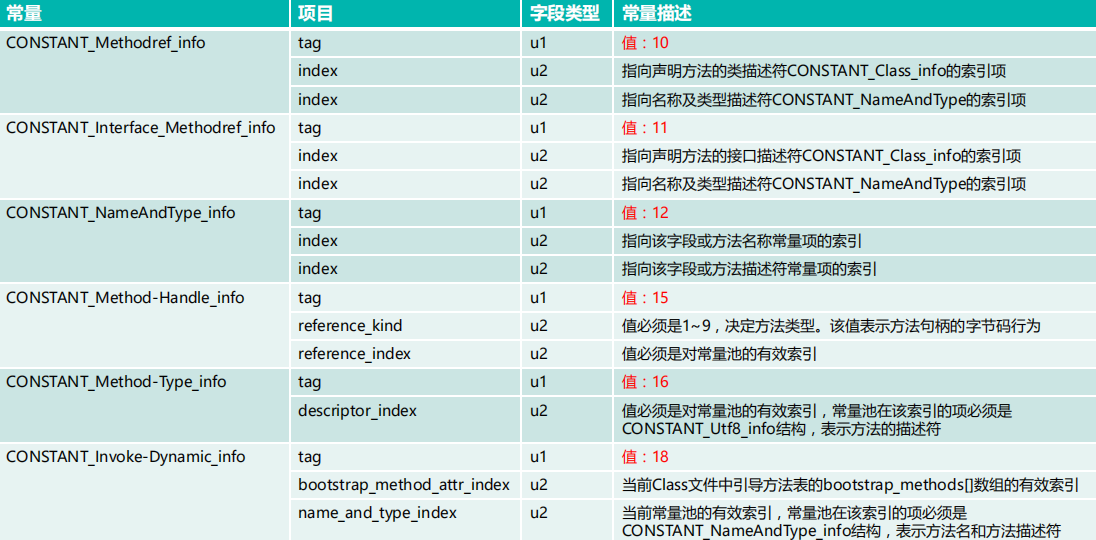
从结构上看所有的常量池结构都是由一个字节的tag和其它信息(看具体的*_info)组成,而常量池有22个,也就是说我们要接着上面的常量池计数器往后分析22个常量。
首先来看第一个常量:0a(十进制为10),由上图tag得知第一个常量为CONSTANT_Methodref_info,也就是它还包含2个字节的声明方法的类描述符的索引项和2个字节的名称及类型描述符的索引项。
我们按照这种方法以此类推:
1 constant1: 2 0a: CONSTANT_Methodref_info 3 00 03 4 00 04 5 6 constant2: 7 09: CONSTANT_Fieldref_info 8 00 03 9 00 14 10 11 constant3: 12 07: CONSTANT_Class_info 13 00 15 14 15 constant4: 16 07: CONSTANT_Class_info 17 00 16 18 19 constant5: 20 01: CONSTANT_utf8_info 21 00 05 22 63 6f 75 6e 74 (这里需要往后数length.value*u1个字节,constant5的话就是5个字节) 23 24 constant6: 25 01: CONSTANT_utf8_info 26 00 01 27 49 28 29 constant7: 30 01: CONSTANT_utf8_info 31 00 06 32 3c 69 6e 69 74 3e 33 34 constant8: 35 01: CONSTANT_utf8_info 36 00 03 37 28 29 56 38 39 constant9: 40 01: CONSTANT_utf8_info 41 00 04 42 43 6f 64 65 43 44 constant10: 45 01: CONSTANT_utf8_info 46 00 0f 47 4c 69 6e 65 4e 75 6d 62 65 72 54 61 62 6c 65
前四个没有什么特殊的,在第五个时需要注意下utf8这种类型,它由u1 tag,u2 length,u1 bytes组成,不同的是u1 bytes不是往后数一个字节,而是要往后数length.value * u1个字节,按照上面分析的也就是5个字节。其中这五个字节分别是63 6f 75 6e 74,转换成10进制为99 111 117 110 116,然后把它转成ASCII码后得到count这个字符,这不正是我们java源文件定义的count属性嘛!!!
后续的你可以自己去分析。。。。。。
最终用【javap -v class文件路径】来检验即可,向我上面分析的constant5=count就可以从常量池表中验证。
访问标志、类索引、父类索引、接口计数器、接口索引集合(u2、u2、u2、u2、u2)
逐步分析22个常量池中的常量后便来到了访问标识、类索引、父类索引、接口计数器、接口索引集合,共10个字节。
关于在class文件中访问标志的位置在哪的话你可以通过javap -v分析的常量池表来快速定位。
比如我有这样一个类(之后的分析会用到这个类):
1 package org.jdr.demo.jvm.test; 2 3 /** 4 * @author zhoude 5 * @date 2020/8/31 22:30 6 */ 7 public class TestClass2 { 8 9 static final long M = 1L; 10 int i = 2; 11 static int j = 3; 12 13 public TestClass2() { 14 } 15 16 public void desc() { 17 } 18 19 public static double test(double... money) { 20 return 1.8; 21 } 22 23 public int inc() { 24 int x; 25 try { 26 x = 1; 27 return x; 28 } 29 catch (Exception e) { 30 x = 2; 31 return x; 32 } 33 finally { 34 x = 3; 35 } 36 } 37 38 }
我们通过javac将其编译成class文件后再执行javap -v来查看它的常量池。
先从java汇编指令得到最后一个常量为java/lang.Throwable。

然后我们根据字节码分析的dump来快速定位,找到dump中的java/lang.Throwable,往后的便是访问标志了。


访问标志有2个字节00 21,咦根据上面的表格怎么找不到呢,哈哈因为它做的是“|”运算,也就是0x0020 | 0x0001,得到public class。
之后分别是类索引、父类索引、接口计数器、接口索引集合,索引的话就要去常量池找了,最后的结果如下:
1 00 07: org/jdr/demo/jvm/test/TestClass2 2 00 08: java/lang/Object(没有继承默认object) 3 00 00: 0(没有实现接口计数器为0) 4 00 03: 请不要计算进去,看下面的说明
这里有一点要注意下,访问标志之后顺序排列类索引(this)、父类索引(super)、接口索引集合(interfaces)。Class文件由这三项来确定这个类的集成关系。类索引和父类索引都是u2类型的数据。接口索引集合入口第一项是u2类型的接口计数器(interfaces_count)表示索引表的容量(即实现了几个接口)。如果该类没用实现任何接口,则计数器值为0,后面的接口索引表不再占用任何字节。
正式因为接口计数器为0,所以00 03不要算到接口索引集合里去,它不占字节,往后阅读的话00 03是归属到字段计数器里;刚好我们的类有三个字段,哈哈。
为了方便你理解,我再写一个实现接口的类。
1 package org.jdr.demo.jvm.test; 2 3 import java.io.Serializable; 4 5 /** 6 * @author zhoude 7 * @date 2020/8/31 22:30 8 */ 9 public class TestClass3 implements Serializable, Runnable, Comparable { 10 11 static final long M = 1L; 12 int i = 2; 13 static int j = 3; 14 15 public TestClass3() { 16 } 17 18 public void desc() { 19 } 20 21 public static double test(double... money) { 22 return 1.8; 23 } 24 25 public int inc() { 26 int x; 27 try { 28 x = 1; 29 return x; 30 } 31 catch (Exception e) { 32 x = 2; 33 return x; 34 } 35 finally { 36 x = 3; 37 } 38 } 39 40 @Override 41 public int compareTo(Object o) { 42 return 0; 43 } 44 45 @Override 46 public void run() { 47 } 48 49 }
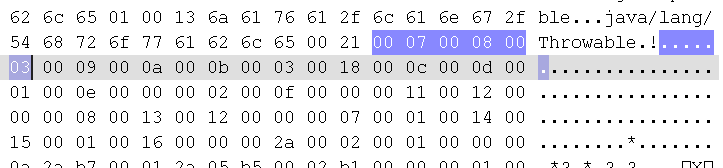
此时接口计数器便为00 03,也就是3个接口;所以接口索引集合就是3个,故我们往后数6个字节。
对照常量表后得到:
1 00 09: java/io/Serializable 2 00 0a: java/lang/Runnable 3 00 0b: java/lang/Comparable
是不是很简单呢!!!
字段计数器、字段表集合 u2、field_info
接口索引集合后边的是字段计数器:用于标识有多少个字段。
字段计数器之后接着就是字段表集合:字段表(field_info)用于描述接口或者类中声明的变量,字段包括类级变量以及实例级变量。
可以包括的信息有:
- 字段的作用域(public、private、protected修饰符)。
- 实例变量还是类变量(static修饰符)。
- 可变性(final)。
- 并发可见性(volatile)。
- 可否被序列化(transient)。
- 字段数据类型(基本类型,对象,数组)。
- 字段名称。
字段表结构:
1 u2 access_flags 1 2 u2 name_index 1 3 u2 descriptor_index 1 4 u2 attribute_count 1 5 attribute_info attributes attribute_count
access_flag:
1 ACC_PUBLIC 0X0001 字段是否public 2 ACC_PRIVATE 0X0002 字段是否private 3 ACC_PROTECTED 0X0004 字段是否protected 4 ACC_STATIC 0X0008 字段是否static 5 ACC_FINAL 0X0010 字段是否final 6 ACC_VOLATILE 0X0040 字段是否volatile 7 ACC_TRANSIENT 0X0080 字段是否transient 8 ACC_SYNTHETIC 0X0100 字段是否由编译器自动产生的 9 ACC_ENUM 0X0400 字段是否enum
attribute_info:
1 u2 attribute_name_index 1 2 u4 attribute_length 1 3 u1 info attribute_length
具体的属性表:
Class文件、字段表、方法表、属性表都可以携带自己的属性表集合,用于描述某些场景专有的信息。属性表集合的限制稍微宽松,不再要求各个属性表具有严格顺序,只要不与已有属性名重复,任何人实现的编译器都可以向属性表中写入自己定义的属性信息。
| Code | 方法表 | Java代码编译成的字节码指令 |
| ConstantValue | 字段表 | final关键字定义的常量值 |
| Deprecated | 类、方法表、字段表 | 被声明为deprecated的方法和字段 |
| Exceptions | 方法表 | 方法抛出的异常 |
| EnclosingMethod | 类文件 | 仅当一个类为局部类或者匿名类时才能拥有这个属性,这个属性用于标识这个类所在的外围方法 |
| InnerClasses | 类文件 | 内部类列表 |
| LineNumberTable | Code属性 | Java源码的行号与字节码指令的对应关系 |
| LocalVariableTable | Code属性 | 方法的局部变量描述 |
| StackMapTable | Code属性 | JDK1.6中新增的属性,供新的类型检查验证器(Type Checker)检查和处理目标方法的局部变量和操作数栈所需要的类型是否匹配 |
| SourceFile | 类文件 | 记录源文件名称 |
| Signature | 类、方法表、字段表 | JDK1.5中新增的属性,这个属性用于支持泛型情况下的方法签名,在Java语言中,任何类、接口、初始化方法或成员的泛型签名如果包含了类型变量(Type Variables)或参数化类型(Parameterized Types),则Signature属性会为它记录泛型签名信息。由于Java的泛型采用擦除法实现,在为了避免类型信息被擦除后导致签名混乱,需要这个属性记录泛型中的相关信息 |
| SourceDebugExtension | 类文件 | JDK1.6中新增的属性,SourceDebugExtension属性用于存储额外的调试信息。譬如在进行JSP文件调试时,无法通过Java堆栈来定位JSP文件的行号,JSR-45规范为这些非Java语言编写,却需要编译成字节码并运行在Java虚拟机中的程序提供了一个进行调试的标准机制,使用SourceDebugExtension属性就可以用于存储这个标准所新加入的调试信息 |
| Synthetic | 类、方法表、字段表 | 标识方法或字段为编译器自动生成的 |
| LocalVariableTypeTable | 类 | JDK1.5中新增的属性,它使用特征签名代替描述符,是为了引入泛型语法之后能描述泛型参数化类型而添加 |
| RuntimeVisibleAnnotations | 类、方法表、字段表 | JDK1.5新增的属性,为动态注解提供支持。RuntimeVisibleAnnotations属性用于注明哪些注解是运行时(实际上运行时就是进行反射调用)可见的 |
| RuntimeInvisibleAnnotations | 类、方法表、字段表 | JDK1.5新增的属性,与RuntimeVisibleAnnotations属性作用刚好相反,用于指明哪些注解是运行时不可见的 |
| RuntimeVisibleParameterAnnotations | 方法表 | JDK1.5新增的属性,作用与RuntimeVisibleAnnotations属性类似,只不过作用对象为方法参数 |
| RuntimeInvisibleParameterAnnotations | 方法表 | JDK1.5新增的属性,作用与RuntimeInvisibleAnnotations属性类似,只不过作用对象为方法参数 |
| AnnotationDefault | 方法表 | JDK1.5新增的属性,用于记录注解类元素的默认值 |
| BootstrapMethods | 类文件 | JDK1.7中新增的属性,用于保存invokedynamic指令引用的引导方法限定符 |
每个属性表所对应的字节码结构也都不一样,在分析的时候具体查阅即可,我这里吧后续可能会用到的先贴出来。
ConstantValue:
ConstantValue属性的作用是通知虚拟机自动为静态变量赋值。只有被static关键字修饰的常量(类变量)才可以使用这项属性。目前Sun Javac编译器的选择是:如果同时使用final和static来修饰一个变量,并且这个变量的数据类型是基本类型或者java.lang.String的话,就生成ConstantValue属性来进行初始化,如果这个变量没有被final修饰,或者并非基本类型及字符串,则将会选择在<clinit>方法中进行初始化。
1 attribute_name_index u2 1 2 attribute_length u4 1 3 constantvalue_index u2 1
LineNumberTable属性表:
LineNumberTable属性用于描述Java源码行号与字节码行号(字节码的偏移量)之间的对应关系。可以在编译的时候分别使用-g:none和-g:lines选项来取消或者要求生成这项信息。
1 attribute_name_index u2 1 2 attribute_length u4 1 3 line_number_table_length u2 1 4 line_number_table line_number_info line_number_table_length
Code属性表:
Java程序方法体中的代码经过Javac编译处理后,最终变为字节码指令存储在Code属性中,Code属性出现在方法表的属性集合之中。但并非所有方法表都有Code属性,例如抽象类或接口。
1 u2 attribute_name_index 1 2 u4 attribute_length 1 3 u2 max_stack 1 4 u2 max_locals 1 5 u4 code_length 1 6 u1 code code_length 7 u2 exception_table_length 1 8 exception_info exception_table exception_table_length 9 u2 attribute_count 10 attribute_info attributes attribute_count
- attribute_info attributes attribute_count。
- attribute_name_index:指向CONSTANT_Utf8_info类型常量的值固定为“Code”。
- attribute_length:属性值的总长度。
- max_stack:操作数栈(Operand Stacks)深度的最大值。
- max_locals:局部变量所需的存储空间(单位:Slot)。
- code_length:和code是用来存储Java源程序编译后产生的字节码指令。
了解上述信息后我们就可以继续分析字节码文件了:
(150, b) - (150, c) 字段计数器;fields_count u2;1个 00 03:3个字段
第一个字段表结构:
(150, d) - (150, e) 访问标记;access_flags u2;1个 00 18;final static
(150, f) - (160, 0) 字段名下标;name_index u2;1个 00 09;M
(160, 1) - (160, 2) 描述符下标;descriptor_index u2;1个 00 0a;J -> long
(160, 3) - (160, 4) 属性数量;attribute_count u2;1个 00 01;1个属性
无字节码坐标 访问标记;attributes u2;attribute_count个 找到属性表
第一个字段的属性:
(160, 5) - (160, 6) 属性名下标;attribute_name_index u2;1个 00 0b;ConstantValue
(160, 7) - (160, a) 属性占用字节长度;attribute_length u4;1个 00 00 00 02;属性信息占用字节数
(160, ) - (160, ) 具体的属性表;info u1;attribute_length个
第一个字段的属性祥表:
(160, b) - (160, c) 属性名下标;attribute_name_index u2;1个 00 0c;1L
结果:final static long M = 1L;
第二个字段表结构:
(160, d) - (160, e) 访问标记;access_flags u2;1个 00 00;无访问标记
(160, f) - (170, 0) 字段名下标;name_index u2;1个 00 0e;i
(170, 1) - (170, 2) 描述符下标;descriptor_index u2;1个 00 0f;I -> int
(170, 3) - (170, 4) 属性数量;attribute_count u2;1个 00 00;无属性,无需往后走
无字节坐标 访问标记;attributes u2;attribute_count个 找到属性表
结果:int i;
第三个字段表结构:
(170, 5) - (170, 6) 访问标记;access_flags u2;1个 00 08;static
(170, 7) - (170, 8) 字段名下标;name_index u2;1个 00 10;J
(170, 9) - (170, a) 描述符下标;descriptor_index u2;1个 00 0f;I -> int
(170, b) - (170, c) 属性数量;attribute_count u2;1个 00 00;无属性,无需往后走
无 访问标记;attributes u2;attribute_count个 找到属性表
结果:static int J;
方法计数器、方法表:
方法计数器和方法表和属性非常类似,你可以对照着分析的结果来读(一定要自己读才能动,主要也是偷懒了)。
同样的方法有00 05,共五个,分别是:
- 构造方法:TestClass2()。
- desc()。
- test(double... money)。
- inc()。
- static{}。
方法表的结构和属性表一致,但访问修饰符我们需要注意下:
|
ACC_PUBLIC |
0X0001 |
方法是否public |
|
ACC_PRIVATE |
0X0002 |
方法是否private |
|
ACC_PROTECTED |
0X0004 |
方法是否protected |
|
ACC_STATIC |
0X0008 |
方法是否static |
|
ACC_FINAL |
0X0010 |
方法是否final |
|
ACC_SYNCHRONIZED |
0X0020 |
方法是否synchronized |
|
ACC_BRIDGE |
0X0040 |
方法是否由编译器产生的桥接方法 |
|
ACC_VARARGS |
0X0080 |
方法是否接受不定参数 |
|
ACC_NATIVE |
0X0100 |
方法是否为native |
|
ACC_ABSTRACT |
0X0400 |
方法是否为abstract |
|
ACC_STRICTFP |
0X0800 |
方法是否为strictfp |
|
ACC_SYNTHETIC |
0X1000 |
防范是否由编译器自动产生 |
因为分析方法大同小异,只需要按图索骥,所以我只分析第一个:
方法一:构造函数,TestClass2()
1 access_flags; 00 01: public 2 name_index; 00 1l: <init> 3 descriptor_index; 00 12: ()V 4 attribute_count; 00 01: 1个方法 5 attribute_info: 6 7 attribute_name_index;00 13: Code 8 attribute_length; 00 00 00 2a: 方法表长度42 9 max_stack; 00 02: 2个栈 10 max_locals; 00 01: 1个本地变量表 11 code_length; 00 00 00 0a: code_length=10 12 code; 2a b7 00 01 2a 05 b5 00 02 b1: 10个字节码指令 13 00 00: 异常表长度0 14 无异常表 15 attribute_count; 00 01: 属性表数量1 16 属性表: 17 18 attribute_name_index;00 14: LineNumberTable 19 attribute_length; 00 00 00 0e: 属性长度14 20 info; 00 03: LineNumberTable长度3 21 line_number_table: 4u * LineNumberTable长度 = 12u 22 00 00 00 0d 00 04 00 0a 00 09 00 0e: 23 0-13 24 4-10 25 9-14
属性计数器、属性表:
这个也很简单,我们按照上面的逐步分析后就能找到,不再赘述。
最后:
最后我把我分析的字节码放在下面,这样你可以清晰自己的思路。
https://files.cnblogs.com/files/bzfsdr/JVM%E5%AD%97%E8%8A%82%E7%A0%81%E5%88%86%E6%9E%90.rar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号