
selenium自动化环境搭建、元素的八大定位和等待机制
注意:py文件命名的时候,不能直接命名为selenium.py,会和第三方包selenium冲突
一、环境搭建:
1、下载第三方包selenium
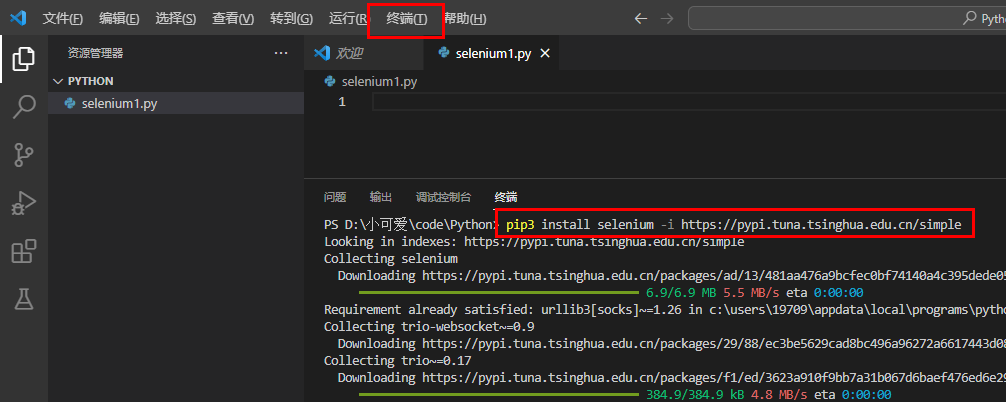
pip3 install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
注:可以直接在vscode里打开终端安装:
2、安装谷歌浏览器
常见支持的浏览器:ie、firfox、Chrome、edge浏览器,这里采用谷歌浏览器
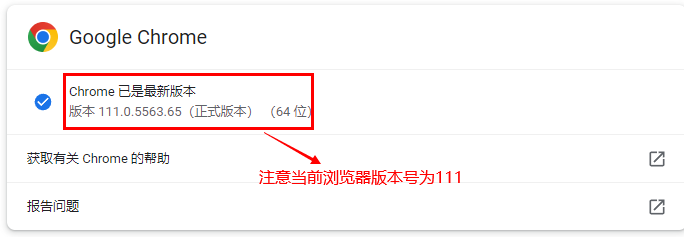
Chrome浏览器的版本号查看:谷歌浏览器右上角三个点---》帮助---》关于Google Chrome,当前版本为111
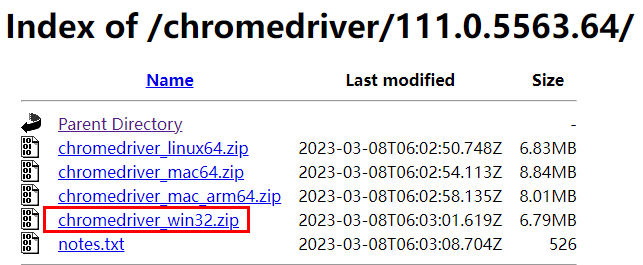
3、下载浏览器的驱动文件
到淘宝的驱动镜像网站上寻找自己浏览器版本号的驱动文件:http://npm.taobao.org/mirrors/chromedriver/
注意:找的是该版本号下最后一个文件,再根据当前操作系统下载驱动

4、下载好驱动文件后,解压后放在项目文件夹里
5、验证(测试一下能否自动打开百度,且打开之后不会自动关闭):
出现如下则验证成功:

二、编写脚本验证环境
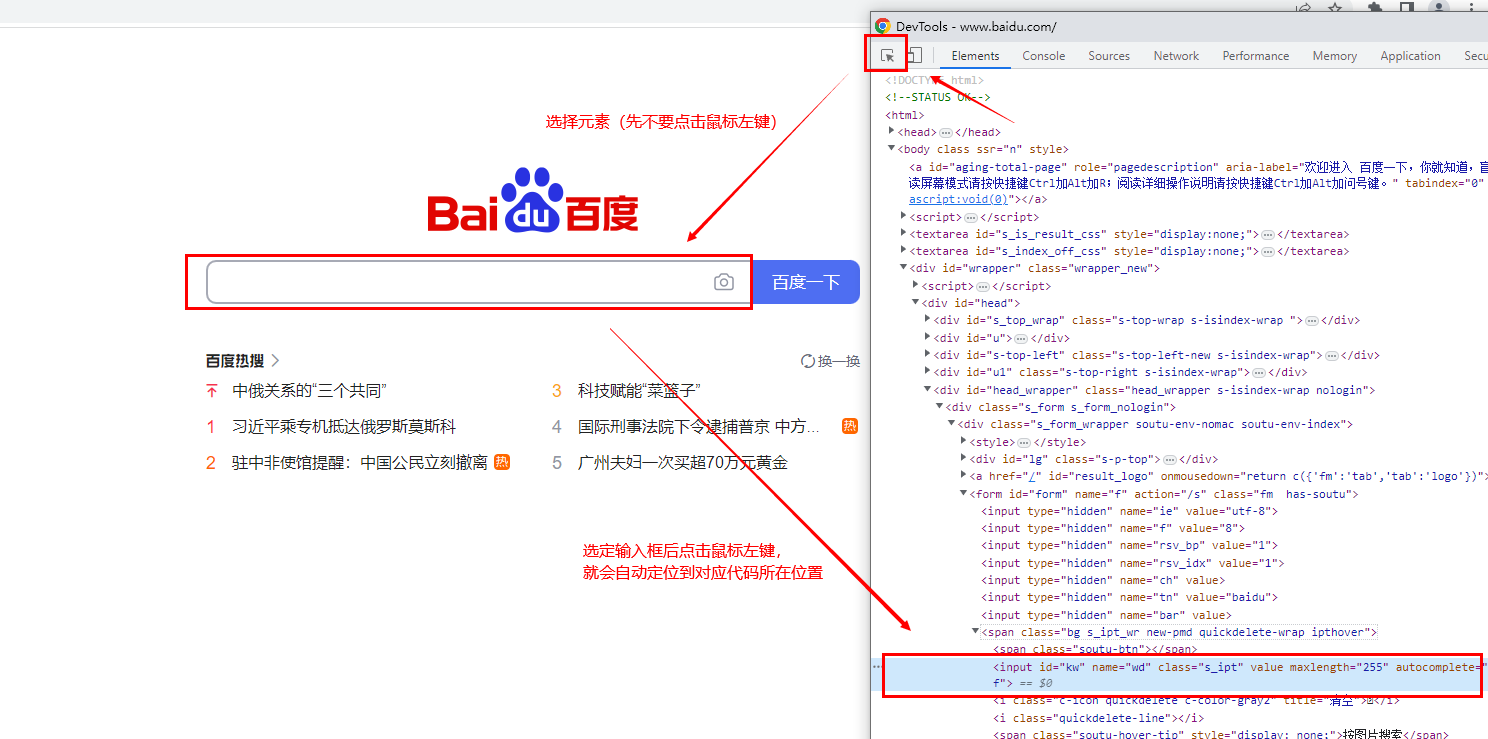
1、F12打开控制台,点击左上角,在网页上移动到要定位的元素后,单击左键,就会定位到代码所在的位置
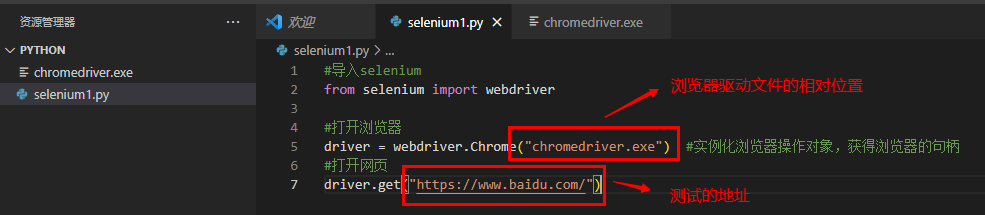
2、编写第一个脚本
#导入selenium from selenium import webdriver #打开浏览器 driver = webdriver.Chrome("chromedriver.exe") #实例化浏览器操作对象,获得浏览器的句柄 driver.maximize_window() #最大化浏览器窗口 #打开网页 driver.get("https://www.baidu.com/") #定位输入框和搜索按钮 #通过元素的id定位 # <input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off"> #百度输入框的代码 driver.find_element_by_id("kw").send_keys("博客园") #<input type="submit" id="su" value="百度一下" class="bg s_btn"> #百度一下的按钮 driver.find_element_by_id("su").click() #退出测试(关闭浏览器) driver.quit()
三、元素的八大定位
我们可以通过元素的某些属性来定位这个元素,以此来操作元素(实际应用中,坚持一个原则:能id就id,不能就用x-path)
百度输入框源码:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
1、通过id值定位:
driver.find_element_by_id("kw").send_keys("博客园")
2、通过name值定位:
driver.find_element_by_name("wd").send_keys("博客园")
3、通过class定位:
driver.find_element_by_class_name('s_ipt').send_keys("博客园")
4、通过x-path定位:
x-path指的是元素在网页中的位置,有绝对位置和相对位置,推荐使用相对位置模糊查找
怎么找x-path:
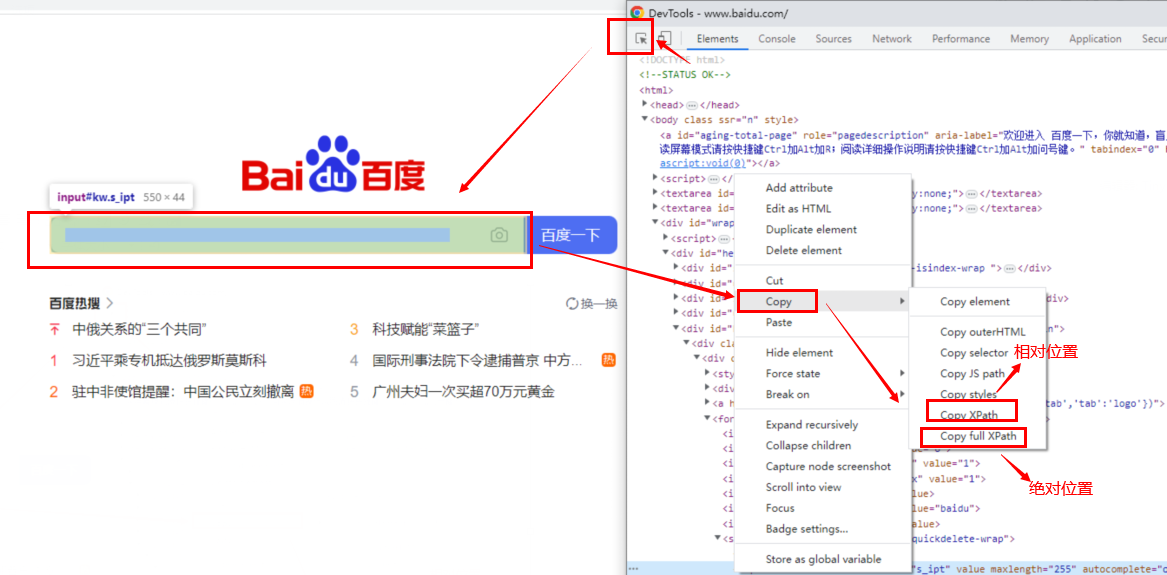
#x-path相对位置://*[@id="kw"] #x-path绝对位置:/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input driver.find_element_by_xpath('//*[@id="kw"] ').send_keys("博客园") #相对位置 driver.find_element_by_xpath('/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys("博客园")
5、通过css selector定位:
怎么找css selector:
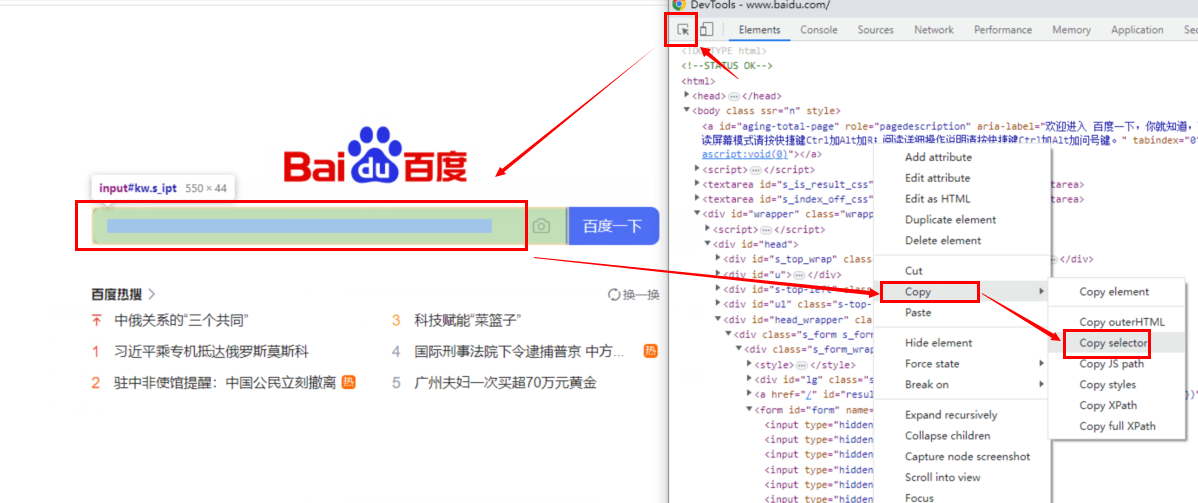
#css selector:#kw driver.find_element_by_css_selector('#kw').send_keys("博客园")
6-7、通过超链接的文本值定位(两种):
driver.find_element_by_link_text('hao123').click() #全部文本值 driver.find_element_by_partial_link_text('hao1').click() #部分文本值
8、通过tag定位:
driver.find_element_by_tag_name('input')
四、等待机制
Python代码的执行是相当快速的,当浏览器加载过慢时,就会导致浏览器还没加载出来,代码已经执行完了,这个时候就会报错,如下图,就是找不到元素的报错:
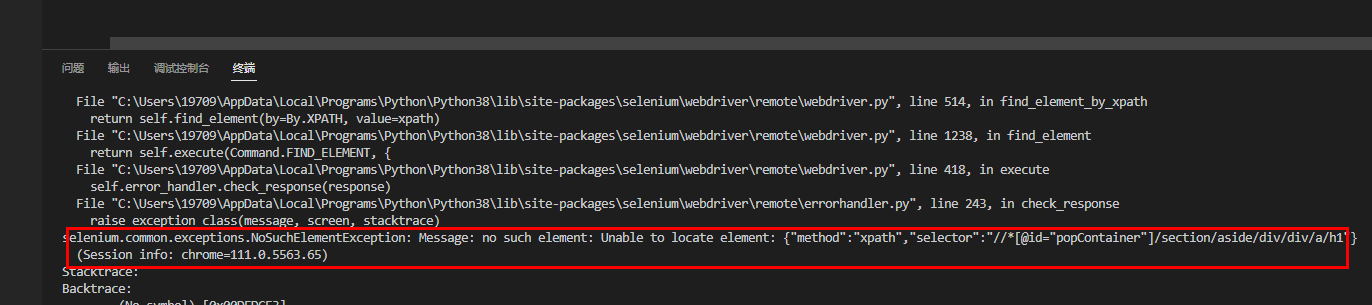
因此,为了避免找元素的时候浏览器加载过慢导致找不到元素,在网页跳转、元素动态加载是,代码就需要等待,有三种等待方式:强制等待、隐式等待、显示等待。
1、强制等待
需要引入第三方time包,time.sleeep(5)-----等待5s,显而易见,强制等待的弊端就是必须要等待指定的时间,即使网页已经加载成功了
2、隐式等待
使用selenium自带的方法,实现隐式等待
#强制等待 time.sleep(6) #会强制性的等待6s #隐式等待 driver.implicitly_wait(6) #每等待1s会自动检查浏览器的跳转情况,若跳转成功则不继续等待
3、显式等待
webdriverwait类可以实现在找元素时等待几秒再执行,从而实现显示等待
3.1、实现步骤:
①首先是引入这个类:
from selenium.webdriver.support.ui import WebDriverWait
②使用webdriverwait类的until()方法实现显示等待
在此之前,需要补充两点知识:
我们之前定义方法都是使用的def定义,其实还可以使用lambd匿名函数定义方法:方法名 = lambda 参数:返回值 ,两种方式定义的方法调用方式都是一样的,即方法名(参数)
a、定义方法的两种方式:
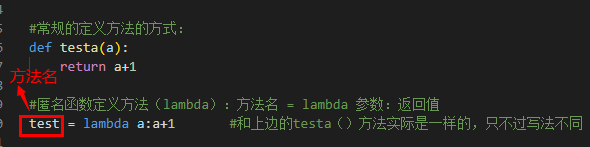
#常规的定义方法的方式: def testa(a): return a+1 #匿名函数定义方法(lambda):方法名 = lambda 参数:返回值 test = lambda a:a+1 #和上边的testa()方法实际是一样的,只不过写法不同
b、方法名字,也是可以作为参数进行传递的
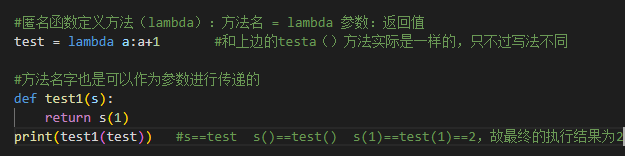
#匿名函数定义方法(lambda):方法名 = lambda 参数:返回值 test = lambda a:a+1 #和上边的testa()方法实际是一样的,只不过写法不同 #方法名字也是可以作为参数进行传递的 def test1(s): return s(1) print(test1(test)) #s==test s()==test() s(1)==test(1)==2,故最终的执行结果为2
显示等待实现:
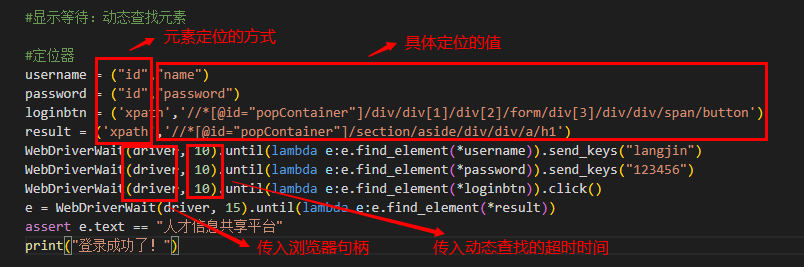
代码:
from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait driver = webdriver.Chrome("chromedriver.exe") driver.maximize_window() driver.get("http://47.113.200.30:2333") #显示等待:动态查找元素 #定位器 username = ("id","name") password = ("id","password") loginbtn = ('xpath','//*[@id="popContainer"]/div/div[1]/div[2]/form/div[3]/div/div/span/button') result = ('xpath','//*[@id="popContainer"]/section/aside/div/div/a/h1') WebDriverWait(driver, 10).until(lambda e:e.find_element(*username)).send_keys("langjin") WebDriverWait(driver, 10).until(lambda e:e.find_element(*password)).send_keys("123456") WebDriverWait(driver, 10).until(lambda e:e.find_element(*loginbtn)).click() e = WebDriverWait(driver, 15).until(lambda e:e.find_element(*result)) assert e.text == "人才信息共享平台" print("登录成功了!")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号