

spark由于shuffle中read过大造成netty申请DirectMemor失败异常分析
1.报错日志:
1 23/11/01 22:14:25 INFO [Executor task launch worker for task 79952] MapOutputTrackerWorker: Don't have map outputs for shuffle 7, fetching them 2 23/11/01 22:14:28 INFO [Executor task launch worker for task 79932] TorrentBroadcast: Started reading broadcast variable 174 3 23/11/01 22:14:28 INFO [Executor task launch worker for task 79932] MemoryStore: Block broadcast_174_piece0 stored as bytes in memory (estimated size 3.5 MB, free 8.0 GB) 4 23/11/01 22:14:28 INFO [Executor task launch worker for task 79932] TorrentBroadcast: Reading broadcast variable 174 took 29 ms 5 23/11/01 22:14:28 INFO [Executor task launch worker for task 79932] MemoryStore: Block broadcast_174 stored as values in memory (estimated size 3.5 MB, free 8.0 GB) 6 23/11/01 22:14:28 INFO [Executor task launch worker for task 79932] MapOutputTracker: Broadcast mapstatuses size = 435, actual size = 3636093 7 23/11/01 22:14:28 INFO [Executor task launch worker for task 79932] MapOutputTrackerWorker: Got the output locations 8 23/11/01 22:14:28 INFO [Executor task launch worker for task 79952] ShuffleBlockFetcherIterator: Getting 9369 non-empty blocks including 138 local blocks and 9231 remote blocks 9 23/11/01 22:14:28 INFO [Executor task launch worker for task 79972] ShuffleBlockFetcherIterator: Getting 9369 non-empty blocks including 138 local blocks and 9231 remote blocks 10 23/11/01 22:14:28 INFO [Executor task launch worker for task 79932] ShuffleBlockFetcherIterator: Getting 9369 non-empty blocks including 138 local blocks and 9231 remote blocks 11 23/11/01 22:14:28 INFO [Executor task launch worker for task 79952] ShuffleBlockFetcherIterator: Started 9 remote fetches in 9 ms 12 23/11/01 22:14:28 INFO [Executor task launch worker for task 79972] ShuffleBlockFetcherIterator: Started 11 remote fetches in 10 ms 13 23/11/01 22:14:28 INFO [Executor task launch worker for task 79932] ShuffleBlockFetcherIterator: Started 10 remote fetches in 12 ms //【故障分析点1】 14 23/11/01 22:14:30 WARN [shuffle-client-7-1] TransportChannelHandler: Exception in connection from emr-worker-2500.cluster-265451/10.64.156.19:7337 15 io.netty.util.internal.OutOfDirectMemoryError: failed to allocate 16777216 byte(s) of direct memory (used: 838860800, max: 838860800) //【故障分析点2】 16 at io.netty.util.internal.PlatformDependent.incrementMemoryCounter(PlatformDependent.java:725) //【故障分析点3】 17 at io.netty.util.internal.PlatformDependent.allocateDirectNoCleaner(PlatformDependent.java:680) 18 at io.netty.buffer.PoolArena$DirectArena.allocateDirect(PoolArena.java:758) 19 at io.netty.buffer.PoolArena$DirectArena.newChunk(PoolArena.java:734) 20 at io.netty.buffer.PoolArena.allocateNormal(PoolArena.java:245) 21 at io.netty.buffer.PoolArena.allocate(PoolArena.java:227) 22 at io.netty.buffer.PoolArena.allocate(PoolArena.java:147) 23 at io.netty.buffer.PooledByteBufAllocator.newDirectBuffer(PooledByteBufAllocator.java:342) 24 at io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:187) 25 at io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:178) 26 at io.netty.buffer.AbstractByteBufAllocator.ioBuffer(AbstractByteBufAllocator.java:139) 27 at io.netty.channel.DefaultMaxMessagesRecvByteBufAllocator$MaxMessageHandle.allocate(DefaultMaxMessagesRecvByteBufAllocator.java:114) 28 at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:147) 29 at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:700) 30 at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:635) 31 at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:552) 32 at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:514) 33 at io.netty.util.concurrent.SingleThreadEventExecutor$6.run(SingleThreadEventExecutor.java:1044) 34 at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) 35 at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) 36 at java.lang.Thread.run(Thread.java:748)
2.错误分析:
(1)、通过【故障分析点1】我们能发现,应该是在做shuffle,并且去上游取回数据(因为fetches)
(2)、通过【故障分析点2】spark程序去申请了16777216字节的Direct内存,也就是16MB,结果说申请失败,因为最大只能使用838860800字节,也就是800MB
(3)、通过【故障分析点3】,我们去找源代码,发现如果申请的内存 + 使用的内存超过 DIRECT_MEMORY_LIMIT,则报错,也就是【故障分析点2】的报错:failed to allocate 16777216 byte(s) of direct memory (used: 838860800, max: 838860800)
private static void incrementMemoryCounter(int capacity) {
if (DIRECT_MEMORY_COUNTER != null) {
for (;;) {
long usedMemory = DIRECT_MEMORY_COUNTER.get();
long newUsedMemory = usedMemory + capacity;
if (newUsedMemory > DIRECT_MEMORY_LIMIT) {
throw new OutOfDirectMemoryError("failed to allocate " + capacity
+ " byte(s) of direct memory (used: " + usedMemory + ", max: " + DIRECT_MEMORY_LIMIT + ')');
}
if (DIRECT_MEMORY_COUNTER.compareAndSet(usedMemory, newUsedMemory)) {
break;
}
}
}
}
那么DIRECT_MEMORY_LIMIT是什么呢?追踪源码发现,是通过 maxDirectMemory 获取到的,通过上面的注解,可以知道,如果没有配置 io.netty.maxDirectMemory 参数,则使用当前使用内存的2倍,但是我们当前的使用内存配置的executor是20G,对不上
1 // Here is how the system property is used: 2 // 3 // * < 0 - Don't use cleaner, and inherit max direct memory from java. In this case the 4 // "practical max direct memory" would be 2 * max memory as defined by the JDK. 5 // * == 0 - Use cleaner, Netty will not enforce max memory, and instead will defer to JDK. 6 // * > 0 - Don't use cleaner. This will limit Netty's total direct memory 7 // (note: that JDK's direct memory limit is independent of this). 8 long maxDirectMemory = SystemPropertyUtil.getLong("io.netty.maxDirectMemory", -1); 9 DIRECT_MEMORY_LIMIT = maxDirectMemory;
最后我们在环境中找到这个配置,真相确认
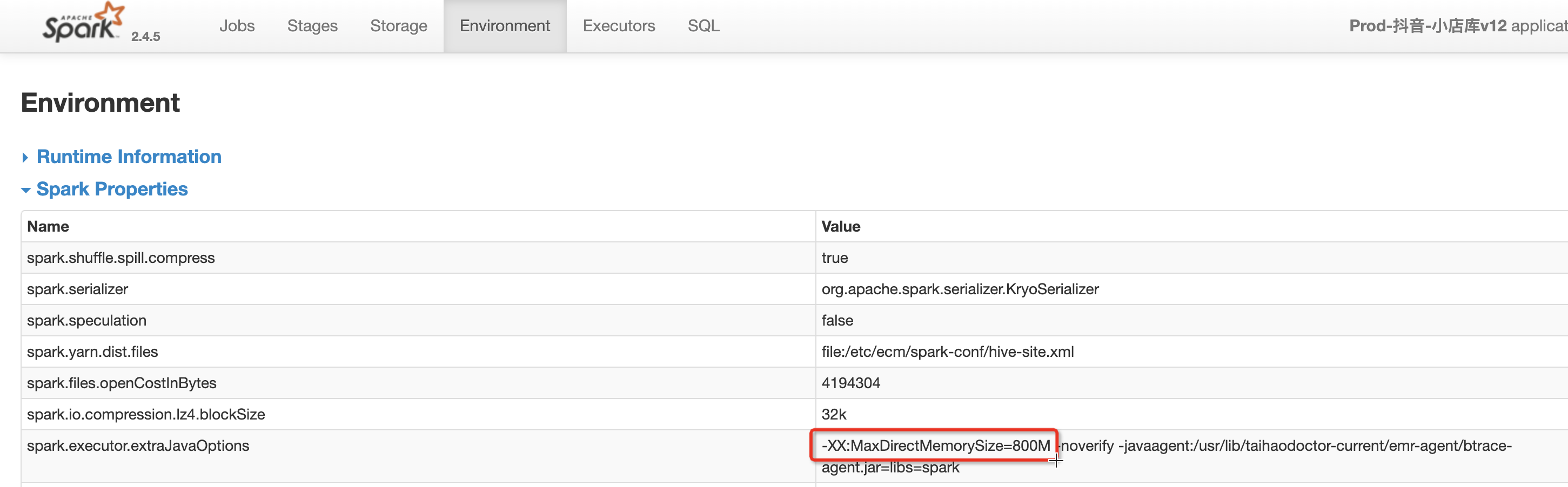
3.科普一下,为什么在shuffle read的时候,netty要申请内存?
这里就直接摘抄别人的描述
shuffle分为shuffle write和shuffle read两部分。
这两部是采用Netty框架,日志就是netty内存泄漏问题.
shuffle write的分区数由上一阶段的RDD分区数控制,shuffleread的分区数则是由Spark提供的一些参数控制。
shuffle write可以简单理解为类似于saveAsLocalDiskFile的操作,将计算的中间结果按某种规则临时放到各个executor所在的本地磁盘上。
shuffle read的时候数据的分区数则是由spark提供的一些参数控制。可以想到的是,如果这个参数值设置的很小,同时shuffle read的量很大,就会导致netty自身接收数据的缓存不够用,然后申请Direct 内存来补充,每次只申请16MB,达到最大上限就会报错失败
4 解决方案:
知道原因后问题就好解决了,这里也直接把网上现成的答案搬过来就行,主要从shuffle的数据量和处理shuffle数据的分区数两个角度入手。
(1). 减少shuffle数据
思考是否可以使用map side join或是broadcastjoin来规避shuffle的产生。
将不必要的数据在shuffle前进行过滤,比如原始数据有20个字段,只要选取需要的字段进行处理即可,将会减少一定的shuffle数据。
(2). SparkSQL和DataFrame的join,groupby等操作
通过spark.sql.shuffle.partitions控制分区数,默认为200,根据shuffle的量以及计算的复杂度提高这个值。
(3). Rdd的join,groupBy,reduceByKey等操作
通过spark.default.parallelism控制shuffleread与reduce处理的分区数,默认为运行任务的core的总数(mesos细粒度模式为8个,local模式为本地的core总数),官方建议为设置成运行任务的core的2-3倍。
(4). 提高executor的内存
通过spark.executor.memory适当提高executor的memory值。
(5). 是否存在数据倾斜的问题
空值是否已经过滤?异常数据(某个key数据特别大)是否可以单独处理?考虑改变数据分区规则。

