

dataNode秒退的故障排查过程
情景
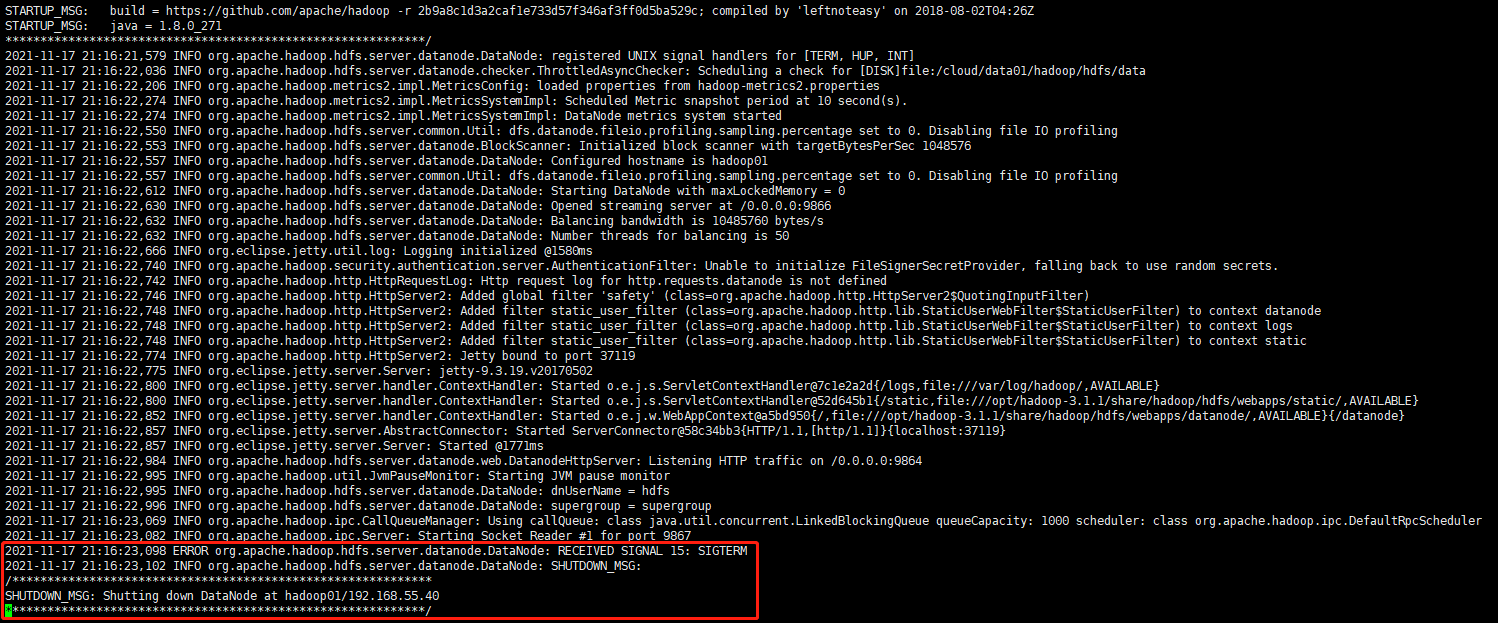
日志就只报了一个下面这样的报错给我,没给个异常栈,我连猜都不好猜,并且这个退出信息,每次启动dataNode的时候,都会在不同的位置突然跳出来,所以我猜测,这还是个异步的线程触发的这个关闭dataNode操作
1 1 2021-11-17 21:16:23,098 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: RECEIVED SIGNAL 15: SIGTERM 2 2 2021-11-17 21:16:23,102 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG: 3 3 /************************************************************ 4 4 SHUTDOWN_MSG: Shutting down DataNode at hadoop01/192.168.55.40 5 5 ************************************************************/
接着就去翻源码,希望从源码中发现点什么,找到了这条消息打印的地方,果然是个异步调用,是一个钩子,当被关闭的时候,触发调用这个run方法中的打印消息
1 static void startupShutdownMessage(Class<?> clazz, String[] args, 2 final LogAdapter LOG) { 3 final String hostname = NetUtils.getHostname(); 4 final String classname = clazz.getSimpleName(); 5 LOG.info(createStartupShutdownMessage(classname, hostname, args)); 6 7 if (SystemUtils.IS_OS_UNIX) { 8 try { 9 SignalLogger.INSTANCE.register(LOG); 10 } catch (Throwable t) { 11 LOG.warn("failed to register any UNIX signal loggers: ", t); 12 } 13 } 14 ShutdownHookManager.get().addShutdownHook( 15 new Runnable() { 16 @Override 17 public void run() { 18 //【重点】打印退出消息 19 LOG.info(toStartupShutdownString("SHUTDOWN_MSG: ", new String[]{ 20 "Shutting down " + classname + " at " + hostname})); 21 } 22 }, SHUTDOWN_HOOK_PRIORITY); 23 24 }
具体打印方法的就是org.apache.hadoop.util.StringUtils#toStartupShutdownString
1 public static String toStartupShutdownString(String prefix, String[] msg) { 2 StringBuilder b = new StringBuilder(prefix); 3 b.append("\n/************************************************************"); 4 for(String s : msg) 5 b.append("\n").append(prefix).append(s); 6 b.append("\n************************************************************/"); 7 return b.toString(); 8 }
这时候就麻烦了,我们也不知道谁异步会来触发这玩意,这时候有显示个异常栈就好了
重头戏:Javassist
1、首先将要修改的jar包下载下来
1 <project xmlns="http://maven.apache.org/POM/4.0.0" 2 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 3 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 4 https://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 <parent> 7 <groupId>org.apache.hadoop</groupId> 8 <artifactId>hadoop-project-dist</artifactId> 9 <version>3.1.3</version> 10 <relativePath>../../hadoop-project-dist</relativePath> 11 </parent> 12 <!-- 重点 --> 13 <artifactId>hadoop-common</artifactId> 14 <version>3.1.3</version> 15 <description>Apache Hadoop Common</description> 16 <name>Apache Hadoop Common</name> 17 <packaging>jar</packaging>
然后通过find命令找到jar包
1 [hdfs@hadoop01 hsperfdata_hdfs]$ find /opt/hadoop-3.1.1/ -name *hadoop-common* 2 /opt/hadoop-3.1.1/share/hadoop/common/hadoop-common-3.1.1-tests.jar 3 /opt/hadoop-3.1.1/share/hadoop/common/hadoop-common-3.1.1.jar 4 /opt/hadoop-3.1.1/share/hadoop/common/sources/hadoop-common-3.1.1-sources.jar 5 /opt/hadoop-3.1.1/share/hadoop/common/sources/hadoop-common-3.1.1-test-sources.jar 6 /opt/hadoop-3.1.1/share/doc/hadoop/hadoop-project-dist/hadoop-common 7 /opt/hadoop-3.1.1/share/doc/hadoop/hadoop-project-dist/hadoop-common/build/source/hadoop-common-project 8 /opt/hadoop-3.1.1/share/doc/hadoop/hadoop-project-dist/hadoop-common/build/source/hadoop-common-project/hadoop-common 9 /opt/hadoop-3.1.1/share/doc/hadoop/hadoop-common-project
所以就找到了/opt/hadoop-3.1.1/share/hadoop/common/hadoop-common-3.1.1.jar
2、写代码,对jar包进行读取和写出修改的文件
1 <dependency> 2 <groupId>org.javassist</groupId> 3 <artifactId>javassist</artifactId> 4 <version>3.20.0-GA</version> 5 </dependency>
Demo.java
1 package aaa.bbb.ccc.day2021_11_17; 2 3 import javassist.*; 4 import javassist.bytecode.*; 5 6 import java.io.IOException; 7 import java.util.Arrays; 8 import java.util.List; 9 import java.util.TreeMap; 10 import java.util.stream.Collectors; 11 12 public class Demo { 13 public static void main(String[] args) throws Exception { 14 //这个是得到反编译的池 15 ClassPool pool = ClassPool.getDefault(); 16 try { 17 //取得需要反编译的jar文件,设定路径 18 pool.insertClassPath("C:\\Users\\Administrator\\Desktop\\test\\hadoop-common-3.1.1.jar"); 19 //取得需要反编译修改的文件,注意是完整路径 20 CtClass cc1 = pool.get("org.apache.hadoop.util.StringUtils"); 21 22 //取得需要修改的方法(正常要用这样的方法,但是无奈hadoop这个方法同名重载了3个,我不知道如何写这个方法名,该方法适合方法名没有重载适可以使用) 23 CtMethod method = cc1.getDeclaredMethod("toStartupShutdownString"); 24 25 //可以用insertBefore、insertAfter、setBody多种方法一起,来设置 26 method.setBody("{System.out.println(\"==============\" + Thread.currentThread().getName() + \"======================\");\n" + 27 " new java.lang.Exception(\"========test myError==========\").printStackTrace();\n" + 28 "\n" + 29 " StringBuilder b = new StringBuilder($1);\n" + 30 " b.append(\"\\n/************************************************************\");\n" + 31 " for (int i = 0; i < $2.length; i++) {\n" + 32 " String s = $2[i];\n" + 33 " b.append(\"\\n\").append($1).append(s);\n" + 34 " }\n" + 35 " b.append(\"\\n************************************************************/\");\n" + 36 " return b.toString();}"); 37 38 //遇到复杂的,有重载的情况,用下面这种方法。。。虽然土一点,但是管用 39 // CtMethod method = Arrays.stream(cc1.getMethods()) 40 // .filter(row -> "startupShutdownMessage".equals(row.getName())) //过滤出方法名为startupShutdownMessage的所有方法 41 // .collect(Collectors.toList()) 42 // .get(1);//取出需要的 43 44 //将修改出来的类的class,输出到指定路径 45 cc1.writeFile("C:\\Users\\Administrator\\Desktop\\test"); 46 } catch (NotFoundException e) { 47 e.printStackTrace(); 48 } catch (CannotCompileException e) { 49 e.printStackTrace(); 50 } catch (IOException e) { 51 e.printStackTrace(); 52 } 53 } 54 }
3、检查生成出来的代码,果然有编译进去

4、将编译出来的新class覆盖旧的jar里面的旧class
5、将注入的新jar,上传到服务器上代替旧jar
效果
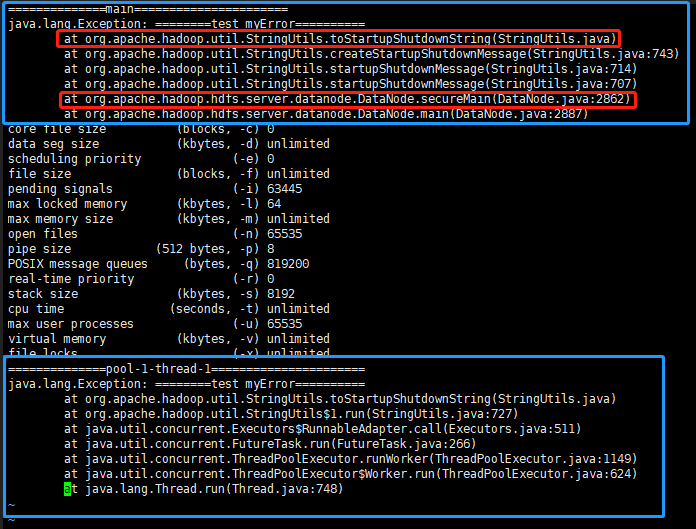
对源码进行分析
1 import javassist.*; 2 3 import java.io.IOException; 4 5 public class Demo1 { 6 public static void main(String[] args) throws Exception { 7 //这个是得到反编译的池 8 ClassPool pool = ClassPool.getDefault(); 9 try { 10 11 //取得需要反编译的jar文件,设定路径 12 pool.insertClassPath("C:\\Users\\Administrator\\Desktop\\test\\hadoop-hdfs-3.1.1.jar"); 13 14 //如果我们的要注入的方法中,参数使用其他jar包的类,这时候要把依赖类添加到classPath中 15 pool.appendClassPath("C:\\Users\\Administrator\\Desktop\\test\\hadoop-common-3.1.1.jar"); 16 //取得需要反编译修改的文件,注意是完整路径 17 CtClass cc1 = pool.get("org.apache.hadoop.hdfs.server.datanode.DataNode"); 18 19 // //取得需要修改的方法(正常要用这样的方法,但是无奈hadoop这个方法同名重载了3个,我不知道如何写这个方法名,该方法适合方法名没有重载适可以使用) 20 CtMethod method = cc1.getDeclaredMethod("secureMain"); 21 22 //遇到复杂的,有重载的情况,用下面这种方法。。。虽然土一点,但是管用 23 // CtMethod method = Arrays.stream(cc1.getMethods()) 24 // .filter(row -> "createDataNode".equals(row.getName())) //过滤出方法名为startupShutdownMessage的所有方法 25 // .collect(Collectors.toList()) 26 // .get(1);//取出需要的 27 28 29 //可以用insertBefore、insertAfter、setBody多种方法一起,来设置 30 method.insertBefore("{" + 31 "System.out.println(\"===============secureMain stage1=================\");\n" + 32 "Thread.sleep(5000L);" + 33 "System.out.println(\"===============secureMain stage2=================\");\n" + 34 "}"); 35 36 method.insertAfter("{" + 37 "System.out.println(\"===============secureMain stage3=================\");\n" + 38 "Thread.sleep(5000L);" + 39 "System.out.println(\"===============secureMain stage4=================\");\n" + 40 "}"); 41 42 //将修改出来的类的class,输出到指定路径 43 cc1.writeFile("C:\\Users\\Administrator\\Desktop\\test"); 44 } catch (NotFoundException e) { 45 e.printStackTrace(); 46 } catch (CannotCompileException e) { 47 e.printStackTrace(); 48 } catch (IOException e) { 49 e.printStackTrace(); 50 } 51 } 52 }
结果如下,发现在secureMain还没开始前就出问题了,难道是DataNode的main函数就出问题了?
1 ===============secureMain stage1================= 2 core file size (blocks, -c) 0 3 data seg size (kbytes, -d) unlimited 4 scheduling priority (-e) 0 5 file size (blocks, -f) unlimited 6 pending signals (-i) 63445 7 max locked memory (kbytes, -l) 64 8 max memory size (kbytes, -m) unlimited 9 open files (-n) 65535 10 pipe size (512 bytes, -p) 8 11 POSIX message queues (bytes, -q) 819200 12 real-time priority (-r) 0 13 stack size (kbytes, -s) 8192 14 cpu time (seconds, -t) unlimited 15 max user processes (-u) 65535 16 virtual memory (kbytes, -v) unlimited 17 file locks (-x) unlimited
然后马上查看了一下main方法的源码:org.apache.hadoop.hdfs.server.datanode.DataNode#main
1 public static void main(String args[]) { 2 if (DFSUtil.parseHelpArgument(args, DataNode.USAGE, System.out, true)) { 3 System.exit(0); 4 } 5 6 secureMain(args, null); 7 }
带着这种用javassist 在方法头尾做标记的排查的思路,我发现居然也不是在main方法中产生的!
对系统日志进行分析
对可疑进程进行分析
1 #!/bin/bash 2 while [ true ] 3 do 4 ps aux | grep hdfs 5 echo "==============================" 6 sleep 0.05 7 done
接着,我再次启动dataNode,然后我看到了下面这些进程
1 ============================== 2 root 18771 0.0 0.0 191880 2348 pts/1 S 14:45 0:00 su hdfs 3 hdfs 18773 0.0 0.0 115548 2112 pts/1 S 14:45 0:00 bash 4 hdfs 21215 4.0 0.0 113832 2200 pts/1 S+ 14:50 0:00 bash /opt/hadoop-3.1.1/sbin/hadoop-daemons.sh start datanode 5 hdfs 21245 5.0 0.0 113924 2284 pts/1 S+ 14:50 0:00 bash /opt/hadoop-3.1.1/bin/hdfs --workers --daemon start datanode 6 hdfs 21277 0.0 0.0 113924 1180 pts/1 S+ 14:50 0:00 bash /opt/hadoop-3.1.1/bin/hdfs --workers --daemon start datanode 7 hdfs 21278 2.0 0.0 130816 2992 pts/1 S+ 14:50 0:00 ssh -o BatchMode=yes -o StrictHostKeyChecking=no -o ConnectTimeout=10s localhost -- /opt/hadoop-3.1.1/bin/hdfs --daemon start datanode 8 hdfs 21279 0.0 0.0 117044 956 pts/1 S+ 14:50 0:00 sed s/^/localhost: / 9 root 21280 1.0 0.0 33692 3068 ? Ss 14:50 0:00 sshd: hdfs [priv] 10 hdfs 21287 0.0 0.0 33692 1408 ? S 14:50 0:00 sshd: hdfs@notty 11 hdfs 21289 9.0 0.0 113880 2304 ? Ss 14:50 0:00 bash /opt/hadoop-3.1.1/bin/hdfs --daemon start datanode 12 hdfs 21353 19.0 0.1 5918412 31872 ? Sl 14:50 0:00 /opt/jdk1.8.0_271/bin/java -Dproc_datanode -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=ERROR,RFAS -Dyarn.log.dir=/var/log/hadoop -Dyarn.log.file=hadoop-hdfs-datanode-hadoop01.log -Dyarn.home.dir=/opt/hadoop-3.1.1 -Dyarn.root.logger=INFO,console -Djava.library.path=/opt/hadoop-3.1.1/lib/native -Dhadoop.log.dir=/var/log/hadoop -Dhadoop.log.file=hadoop-hdfs-datanode-hadoop01.log -Dhadoop.home.dir=/opt/hadoop-3.1.1 -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.datanode.DataNode 13 hdfs 21354 0.0 0.0 108056 616 ? S 14:50 0:00 sleep 1 14 root 21397 0.0 0.0 112816 956 pts/0 S+ 14:50 0:00 grep hdfs
其中下面这三个进程,引起我的关注
1 hdfs 21215 4.0 0.0 113832 2200 pts/1 S+ 14:50 0:00 bash /opt/hadoop-3.1.1/sbin/hadoop-daemons.sh start datanode 2 hdfs 21277 0.0 0.0 113924 1180 pts/1 S+ 14:50 0:00 bash /opt/hadoop-3.1.1/bin/hdfs --workers --daemon start datanode 3 hdfs 21353 19.0 0.1 5918412 31872 ? Sl 14:50 0:00 /opt/jdk1.8.0_271/bin/java -Dproc_datanode -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=ERROR,RFAS -Dyarn.log.dir=/var/log/hadoop -Dyarn.log.file=hadoop-hdfs-datanode-hadoop01.log -Dyarn.home.dir=/opt/hadoop-3.1.1 -Dyarn.root.logger=INFO,console -Djava.library.path=/opt/hadoop-3.1.1/lib/native -Dhadoop.log.dir=/var/log/hadoop -Dhadoop.log.file=hadoop-hdfs-datanode-hadoop01.log -Dhadoop.home.dir=/opt/hadoop-3.1.1 -Dhadoop.id.str=hdfs -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.datanode.DataNode
分析如下:
定位hdfs脚本具体怎么执行代码的
1 if [[ -f "${HADOOP_LIBEXEC_DIR}/hdfs-config.sh" ]]; then 2 #【重点】 3 . "${HADOOP_LIBEXEC_DIR}/hdfs-config.sh" 4 else 5 echo "ERROR: Cannot execute ${HADOOP_LIBEXEC_DIR}/hdfs-config.sh." 2>&1 6 exit 1 7 fi
sbin/hadoop-config.sh:104
1#【重点】 3 hadoop_parse_args "$@"
bin/hadoop-functions.sh:2519
1 function hadoop_parse_args 2 { 3 HADOOP_DAEMON_MODE="default" 4 HADOOP_PARSE_COUNTER=0 5 6 # not all of the options supported here are supported by all commands 7 # however these are: 8 hadoop_add_option "--config dir" "Hadoop config directory" 9 hadoop_add_option "--debug" "turn on shell script debug mode" 10 hadoop_add_option "--help" "usage information" 11 12 while true; do 13 hadoop_debug "hadoop_parse_args: processing $1" 14 case $1 in 15 .... 16 --workers) 17 shift 18 # shellcheck disable=SC2034 19 #【重点】 20 HADOOP_WORKER_MODE=true 21 ((HADOOP_PARSE_COUNTER=HADOOP_PARSE_COUNTER+1)) 22 ;; 23 *) 24 break 25 ;; 26 esac 27 done 28 29 hadoop_debug "hadoop_parse: asking caller to skip ${HADOOP_PARSE_COUNTER}" 30 }
bin/hdfs:269
1 if [[ ${HADOOP_WORKER_MODE} = true ]]; then 2 #【重点】 3 hadoop_common_worker_mode_execute "${HADOOP_HDFS_HOME}/bin/hdfs" "${HADOOP_USER_PARAMS[@]}" 4 exit $? 5 fi
sbin/hadoop-functions.sh:1068
1 function hadoop_common_worker_mode_execute 2 { 3 #【重点】 4 hadoop_connect_to_hosts -- "${argv[@]}" 5 }
sbin/hadoop-functions.sh:991
1 function hadoop_connect_to_hosts 2 { 3 .... 4 5 if [[ -e '/usr/bin/pdsh' ]]; then 6 ... 7 else 8 if [[ -z "${HADOOP_WORKER_NAMES}" ]]; then 9 HADOOP_WORKER_NAMES=$(sed 's/#.*$//;/^$/d' "${worker_file}") 10 fi 11 #【重点】 12 hadoop_connect_to_hosts_without_pdsh "${params}" 13 fi 14 }
sbin/hadoop-functions.sh:1047
1 function hadoop_connect_to_hosts_without_pdsh 2 { 3 # shellcheck disable=SC2124 4 local params="$@" 5 local workers=(${HADOOP_WORKER_NAMES}) 6 for (( i = 0; i < ${#workers[@]}; i++ )) 7 do 8 if (( i != 0 && i % HADOOP_SSH_PARALLEL == 0 )); then 9 wait 10 fi 11 #【重点】 12 hadoop_actual_ssh "${workers[$i]}" ${params} & 13 done 14 wait 15 }
sbin/hadoop-functions.sh:973
1 function hadoop_actual_ssh 2 { 3 # we are passing this function to xargs 4 # should get hostname followed by rest of command line 5 local worker=$1 6 shift 7 8 #【重点】 9 ssh ${HADOOP_SSH_OPTS} ${worker} $"${@// /\\ }" 2>&1 | sed "s/^/$worker: /" 10 }
使用 ssh ${HADOOP_SSH_OPTS} ${worker} $"${@// /\\ }" 2>&1 | sed "s/^/$worker: /" 命令执行的时候,发现依然出现dataNode被杀死的功能,
但是在salve节点上执行 ${worker} $"${@// /\\ }" 2>&1 | sed "s/^/$worker: /" 命令时,却能正常运行,但是退出当前session后,dataNode马上被杀死
这时候,我大概知道为什么了,这是因为我的系统是centos7,搭配新版的sshd服务,在新版的sshd中,退出ssh后,默认配置会杀死当前控制组里面的所有子进程,修改策略即可
解决方案
1 [Unit] 2 Description=OpenSSH per-connection server daemon 3 Documentation=man:sshd(8) man:sshd_config(5) 4 Wants=sshd-keygen.service 5 After=sshd-keygen.service 6 7 [Service] 8 EnvironmentFile=-/etc/sysconfig/sshd 9 ExecStart=-/usr/sbin/sshd -i $OPTIONS 10 KillMode=process #追加这个配置 11 StandardInput=socket

