数据处理的两个基本问题
总结chapter5-8
这几章分散引入或总结了不少零碎的知识点,包括寻址方式、新增指令用法、伪指令,等等。知识本身难度不大,但是,由于比较零散,也容易给初学者造成困扰。因此,建议对内容进行分门别类梳理、归纳、总结,借助思维导图、表格等形式,让知识结构化、体系化、清晰化。不仅有助于自己学习理解,也有助于后期复习。
第五章[bx]和loop指令在上一篇博客有总结
第六章包含多个段的程序
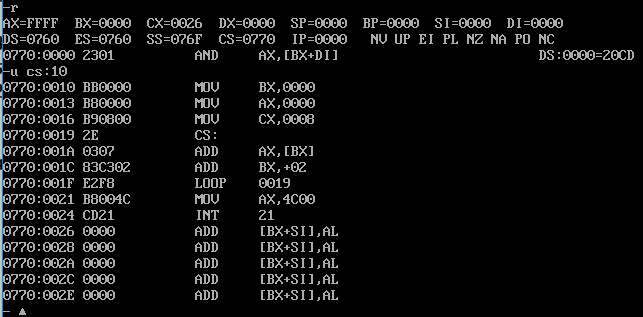
assume cs:code code segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h mov bx,0 mov ax,0 mov cx,8 s: add ax,cs:[bx] add bx,2 loop s mov ax,4c00h int 21h code ends end
"dw"的含义是定义字型数据。
通过ds=0760,可知道程序从0770开始存放,由于数据存放在代码段中,程序运行的时候cs中存放代码段的段地址,所以可以从cs中得到它们的段地址。
用debug加载后,可以将ip设置为10h,从而使cs:ip指向程序中的第一条指令。再用t命令,p命令,或者是g命令执行。

assume cs:code code segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h start : mov bx,0 mov ax,0 mov cx,8 s: add ax,cs:[bx] add bx,2 loop s mov ax,4c00h int 21h code ends end start
加入标号start,而这个标号在伪代码end的后面出现。end的作用除了通知编译器程序结束外,还可以通知编译器程序的入口在什么地方。我们用end指令指明了程序的入口在标号start处。
我们知道在单任务系统中,可执行文件中的程序执行过程如下:
1.由其他的程序(debug\command或其他程序)将可执行文件中的程序加载入内存。
2.设置cs:ip指向程序的第一条要执行的指令(即程序的入口),从而使程序得以运行。
3.程序运行结束后,返回到加载者。有了这种方法,就可以这样来安排程序的框架:
assume cs:code
code segment
:
:
数据
:
:
start:
:
:
代码
:
:
code ends
end start
下面的程序实现依次用内存0:0-0:f单元中的内容改写程序中的数据,数据的传送用栈来进行。栈空间设置在程序内。
assume cs:codesg codesg segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h dw 0,0,0,0,0,0,0,0,0,0 ;10个字单元用作栈空间 start: mov ax,cs mov ss,ax mov sp,30h mov ax,0 mov ds,ax mov bx,0 mov cx,8 s: push [bx] pop cs:[bx] add bx,2 loop s mov ax,4c00h int 21h codesg ends end
cs:10-cs:2f的内存空间当作栈来用,初始状态下栈为空,所以ss:sp要指向栈底,则设置ss:sp指向cs:30
预留16个字单元
dw 16 dup(0)
将数据、代码、栈放入不同的段
assume cs:b,ds:a,ss:c1 a segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h a ends c1 segment dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 c1 ends b segment d: mov ax,c1 mov ss,ax mov sp,20h ;希望用C1段当作栈空间,设置ss:sp指向c:20 mov ax,a mov ds,ax ;希望用ds:bx访问a段中的数据,ds指向a段 mov bx,0 ;ds:bx指向a段中的第一个单元 mov cx,8 s: push [bx] add bx,2 loop s ;以上将a段中的0-15个单元中的8个字型数据依次入栈 mov bx,0 mov cx,8 s0: pop [bx] add bx,2 loop s0 ;以上依次出栈8个字型数据到a段的0-15个单元中 mov ax,4c00h int 21h b ends end d ;d处是要执行的第一条指令,即程序的入口
第七章 更灵活的定位内存地址的方法
and 和 or 指令
and指令:逻辑与指令,按位进行与运算。
通过该指令可将操作对象的相应位设为0,其他位不变。
or指令: 逻辑或指令,按位进行或运算。
通过该指令可将操作对象的相应位设为1,其他位不变。
关于ascii码
世界上有很多编码方案,有一种方案叫做ascii码,是在计算机系统中通常被采用的。简单地说,所谓编码方案,就是一套规则,它约定了用什么样的信息来表示现实对象。我们可以看到,显卡在处理文本信息的时候,是按照ascii码的规则进行的。这也就是说,如果我们要想在显示器上看到"a",就要给显卡提供“a“的ascii码,61h,如何提供?当然是写入显存中。
我们可以在汇编程序中,用'.....'的方式指明数据是以字符的形式给出的,编译器将它们转化为相对应的ascii码。
大小写转换
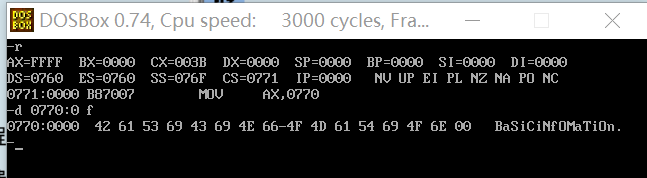
assume cs:codesg,ds:datasg datasg segment db 'BaSiC' db 'iNfOMaTiOn' datasg ends codesg segment start: mov ax,datasg mov ds,ax ;设置ds指向datasg段 mov bx,0 ;设置(bx)=0,ds:bx指向'BaSiC'的第一个字母 mov cx,5 ;设置循环次数5,因为'BaSiC'有5个字母 s:mov al,[bx] ;将ASCII码从ds:bx所指的单元中取出 and al,11011111B ;将al中的ASCII码的第5位置为0,变为大写字母 mov [bx],al ;将转变后的ASCII码写会原单元 inc bx ;(bx)加1,ds:bx指向下一个字母 loop s mov bx,5 ;设置(bx)=5,ds:bx指向'iNfOMaTiOn'的第一个字母 mov cx,11 ;设置循环次数11,因为'iNfOMaTiOn'有11个字母 s0:mov al,[bx] or al,00100000B ;将al中的ASCII码的第5个位置为1,变为小写字母 mov [bx],al inc bx loop s0 mov ax,4c00h int 21h codesg ends end start

c语言: a[i],b[i]
汇编语言: 0[bx],5[bx]
通过比较我们可以发现,[bx+idata]的方式为高级语言实现数组提供了便利机制。
si和di是8086CPU中和bx功能相近的寄存器,si和di不能够分成两个8位寄存器来使用。
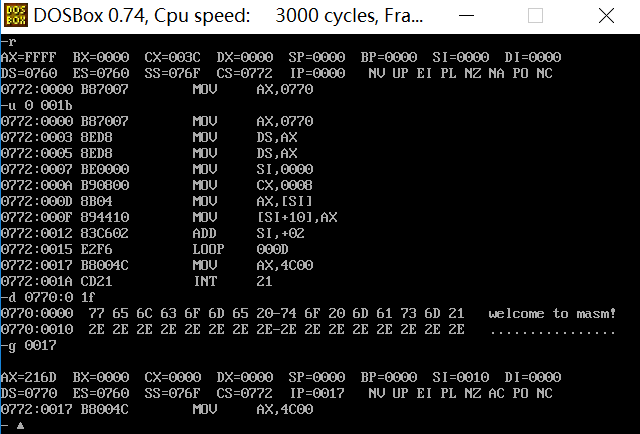
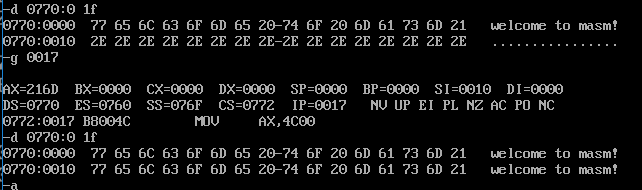
assume cs:codesg,ds:datasg datasg segment db 'welcome to masm!' db '................' datasg ends codesg segment start: mov ax,datasg mov ds,ax mov ds,ax mov si,0 mov cx,8 s: mov ax,0[si] mov 16[si],ax add si,2 loop s mov ax,4c00h int 21h codesg ends end start
[bx+si+idata]表示一个内存单元,它的偏移地址为(bx)+(si)+idata(即bx中的数值加上si中的数值再加上idata)
第八章 数据处理的两个基本问题
我们定义的描述性符号:reg和sreg
reg的集合包括:ax,bx,cx,dx,ah,al,bh,bl,ch,cl,dh,dl,sp,bp,si,di
sreg的集合包括: ds,ss,cs,es
在8086CPU中,只有这4个寄存器可以用在”[...]“中来进行内存单元的寻址。比如下面的指令是正确的:
mov ax,[bx]
mov ax,[bx+si]
mov ax,[bx+bi]
mov ax,[bp]
mov ax,[bp+si]
mov ax,[bp+bi]
mov ax,[si]
mov ax,[di]
mov ax,[bx+si+idata]
mov ax,[bx+di+idata]
mov ax,[bp+si+idata]
mov ax,[bp+di+idata]
div指令
div指令时除法指令,使用div做除法的时候应注意以下问题。
1.除数:有8位和16位两种,在一个reg或内存单元中。
2.被除数:默认放在AX或DX中,如果除数为8位,被除数则为16位,默认在AX中存放,如果除数为16位,被除数则为32位,在DX和AX中存放,DX存放高16位,AX存放低16位。
2.结果:如果除数为8位,则AL存储除法操作的商,AH存储除法操作的余数。如果除数为16位,则AX存储除法操作的商,DX存储除法操作的余数。
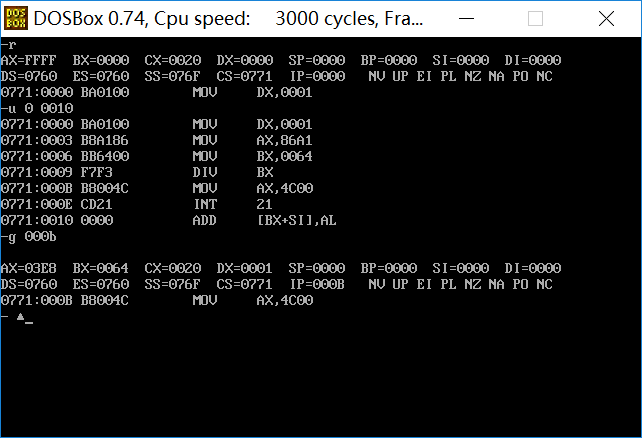
求10001/100
assume cs:code, ds:data data segment dd 100001 dw 100 data ends code segment start: mov dx,1 mov ax,86A1h mov bx,64h div bx mov ax,4c00h int 21h code ends end start
商ax=03e8h,余数dx=1
dup
dup是一个操作符,在汇编语言中db、dw、dd等一样,也是由编译器识别处理的符号。它是和db、dw、dd等数据定义伪指令配合使用的,用来进行数据的重复。
比如:db 2 dup (0)
定义了3个字节,它们的值都是0,相当于db 0,0,0
db 3 dup(0,1,2)
定义了9个字节,它们是0,1,2,0,1,2,0,1,2.相当于db 0,1,2,0,1,2,0,1,2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号