迭代器模式(Iterator Pattern)——遍历聚合对象中的元素
说明:设计模式系列文章是读刘伟所著《设计模式的艺术之道(软件开发人员内功修炼之道)》一书的阅读笔记。个人感觉这本书讲的不错,有兴趣推荐读一读。详细内容也可以看看此书作者的博客https://blog.csdn.net/LoveLion/article/details/17517213。
模式概述
模式定义
在软件开发中,经常需要使用聚合对象来存储一系列数据。聚合对象有两个职责:
- 存储数据
- 遍历数据
从依赖性来看,前者是聚合对象的基本职责,而后者既是可变化的,又是可分离的。因此,可以将遍历数据的行为从聚合对象中分离出来,封装在一个被称之为迭代器的对象中,由迭代器来提供遍历聚合对象内部数据的行为,这将简化聚合对象的设计,更符合单一职责的要求。
迭代器模式(
Iterator Pattern): 提供一种方法来访问聚合对象,而不用暴露这个对象的内部存储。迭代器模式是一种对象行为型模式。
模式结构图
在迭代器模式结构中包含聚合和迭代器两个层次结构,考虑到系统的灵活性和可扩展性,在迭代器模式中应用了工厂方法模式,其模式结构如图所示。
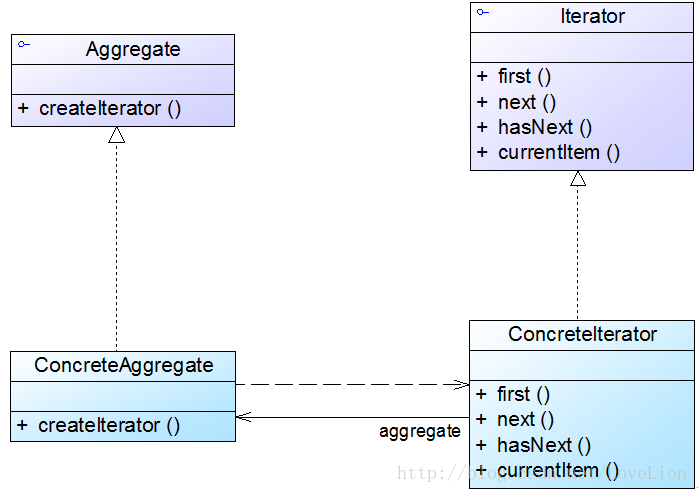
在迭代器模式结构图中包含如下几个角色:
Iterator(抽象迭代器):它定义了访问和遍历元素的接口,声明了用于遍历数据元素的方法,例如:用于获取第一个元素的first()方法,用于访问下一个元素的next()方法,用于判断是否还有下一个元素的hasNext()方法,用于获取当前元素的currentItem()方法等,在具体迭代器中将实现这些方法。ConcreteIterator(具体迭代器):它实现了抽象迭代器接口,完成对聚合对象的遍历,同时在具体迭代器中通过游标来记录在聚合对象中所处的当前位置,在具体实现时,游标通常是一个表示位置的非负整数。Aggregate(抽象聚合类):它用于存储和管理元素对象,声明一个createIterator()方法用于创建一个迭代器对象,充当抽象迭代器工厂角色。ConcreteAggregate(具体聚合类):它实现了在抽象聚合类中声明的createIterator()方法,该方法返回一个与该具体聚合类对应的具体迭代器ConcreteIterator实例。
模式伪代码
在抽象迭代器中声明了用于遍历聚合对象中所存储元素的方法
interface Iterator {
public void first(); //将游标指向第一个元素
public void next(); //将游标指向下一个元素
public boolean hasNext(); //判断是否存在下一个元素
public Object currentItem(); //获取游标指向的当前元素
}
在具体迭代器中将实现抽象迭代器声明的遍历数据的方法
class ConcreteIterator implements Iterator {
private ConcreteAggregate objects; //维持一个对具体聚合对象的引用,以便于访问存储在聚合对象中的数据
private int cursor; //定义一个游标,用于记录当前访问位置
public ConcreteIterator(ConcreteAggregate objects) {
this.objects=objects;
}
public void first() { ...... }
public void next() { ...... }
public boolean hasNext() { ...... }
public Object currentItem() { ...... }
}
聚合类用于存储数据并负责创建迭代器对象,最简单的抽象聚合类代码如下所示
interface Aggregate {
Iterator createIterator();
}
具体聚合类作为抽象聚合类的子类,一方面负责存储数据,另一方面实现了在抽象聚合类中声明的工厂方法createIterator(),用于返回一个与该具体聚合类对应的具体迭代器对象,代码如下所示
class ConcreteAggregate implements Aggregate {
//......
public Iterator createIterator() {
return new ConcreteIterator(this);
}
//......
}
模式改进
在迭代器模式结构图中,我们可以看到具体迭代器类和具体聚合类之间存在双重关系,其中一个关系为关联关系,在具体迭代器中需要维持一个对具体聚合对象的引用,该关联关系的目的是访问存储在聚合对象中的数据,以便迭代器能够对这些数据进行遍历操作。
除了使用关联关系外,为了能够让迭代器可以访问到聚合对象中的数据,我们还可以将迭代器类设计为聚合类的内部类,JDK中的迭代器类就是通过这种方法来实现的,如下AbstractList类代码片段所示
package java.util;
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
//...
public boolean add(E e) {...}
abstract public E get(int index);
public E set(int index, E element) {
throw new UnsupportedOperationException();
}
//...
public Iterator<E> iterator() {
return new Itr();
}
// 这里用内部类可直接访问到聚合对象中的数据
private class Itr implements Iterator<E> {
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
public E next() {
//...
}
public void remove() {
//...
}
}
}
模式应用
模式在JDK中的应用
在JDK中,Collection接口和Iterator接口充当了迭代器模式的抽象层,分别对应于抽象聚合类和抽象迭代器,而Collection接口的子类充当了具体聚合类,如图列出了JDK中部分与List有关的类及它们之间的关系。
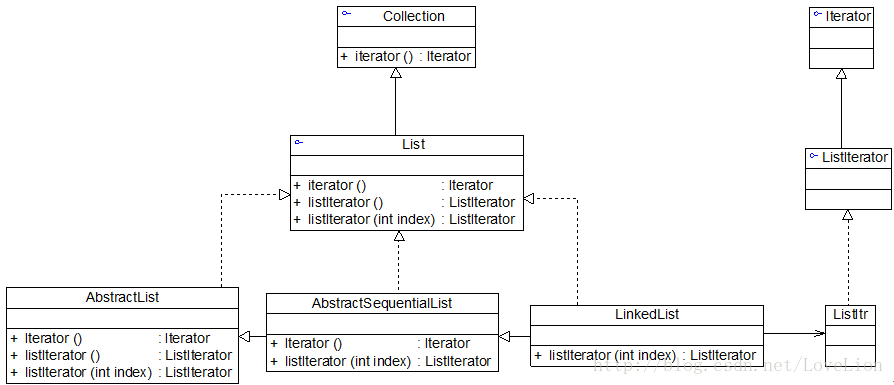
在JDK中,实际情况比上图要复杂很多,List接口除了继承Collection接口的iterator()方法外,还增加了新的工厂方法listIterator(),专门用于创建ListIterator类型的迭代器,在List的子类LinkedList中实现了该方法,可用于创建具体的ListIterator子类ListItr的对象。
既然有了iterator()方法,为什么还要提供一个listIterator()方法呢?这两个方法的功能不会存在重复吗?干嘛要多此一举?由于在Iterator接口中定义的方法太少,只有三个,通过这三个方法只能实现正向遍历,而有时候我们需要对一个聚合对象进行逆向遍历等操作,因此在JDK的ListIterator接口中声明了用于逆向遍历的hasPrevious()和previous()等方法,如果客户端需要调用这两个方法来实现逆向遍历,就不能再使用iterator()方法来创建迭代器了,因为此时创建的迭代器对象是不具有这两个方法的。具体可细读java.util.ListIterator
模式在开源项目中的应用
开源项目中用到遍历的地方,很多地方都会用到迭代器设计模式。这里只提一个org.apache.kafka.clients.consumer.ConsumerRecords。详情可以找kafka client源码阅读。
public class ConsumerRecords<K, V> implements Iterable<ConsumerRecord<K, V>> {
@Override
public Iterator<ConsumerRecord<K, V>> iterator() {
return new ConcatenatedIterable<>(records.values()).iterator();
}
private static class ConcatenatedIterable<K, V> implements Iterable<ConsumerRecord<K, V>> {
private final Iterable<? extends Iterable<ConsumerRecord<K, V>>> iterables;
public ConcatenatedIterable(Iterable<? extends Iterable<ConsumerRecord<K, V>>> iterables) {
this.iterables = iterables;
}
@Override
public Iterator<ConsumerRecord<K, V>> iterator() {
return new AbstractIterator<ConsumerRecord<K, V>>() {
Iterator<? extends Iterable<ConsumerRecord<K, V>>> iters = iterables.iterator();
Iterator<ConsumerRecord<K, V>> current;
public ConsumerRecord<K, V> makeNext() {
while (current == null || !current.hasNext()) {
if (iters.hasNext())
current = iters.next().iterator();
else
return allDone();
}
return current.next();
}
};
}
}
}
模式总结
迭代器模式是一种使用频率非常高的设计模式,通过引入迭代器可以将数据的遍历功能从聚合对象中分离出来,聚合对象只负责存储数据,而遍历数据由迭代器来完成。由于很多编程语言的类库都已经实现了迭代器模式,因此在实际开发中,我们只需要直接使用Java、C#等语言已定义好的迭代器即可,迭代器已经成为我们操作聚合对象的基本工具之一。
- 主要优点
迭代器模式的主要优点如下:
(1) 它支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,我们也可以自己定义迭代器的子类以支持新的遍历方式。
(2) 迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
(3) 在迭代器模式中,由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足开闭原则的要求。
(4) 不管实现如何变化,都可以使用Iterator,引入Iterator后可以将遍历与实现分离开来。对于遍历者来说我们可能只会用到hasNext()和next()方法,如果底层数据存储结构变了(举个例子原来用List存储,需求变动后改为用Map存储),对于上层调用者来说可能完全是透明的,遍历者并不关心你具体如何存储。
- 主要缺点
迭代器模式的主要缺点如下:
(1) 由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
(2) 抽象迭代器的设计难度较大,需要充分考虑到系统将来的扩展,例如JDK内置迭代器Iterator就无法实现逆向遍历,如果需要实现逆向遍历,只能通过其子类ListIterator等来实现,而ListIterator迭代器无法用于操作Set类型的聚合对象。在自定义迭代器时,创建一个考虑全面的抽象迭代器并不是件很容易的事情。
- 适用场景
在以下情况下可以考虑使用迭代器模式:
(1) 访问一个聚合对象的内容而无须暴露它的内部表示。将聚合对象的访问与内部数据的存储分离,使得访问聚合对象时无须了解其内部实现细节。
(2) 需要为一个聚合对象提供多种遍历方式。
(3) 为遍历不同的聚合结构提供一个统一的接口,在该接口的实现类中为不同的聚合结构提供不同的遍历方式,而客户端可以一致性地操作该接口。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号