
Wenet分布式训练对学习率调整的影响
Wenet分布式训练对学习率调整的影响
背景
Wenet多机多卡分布式训练时,发现多机多卡(16卡)开发集loss收敛速度远远慢于单机多卡(4卡)。
分布式训练收敛速度和学习率变化的关系
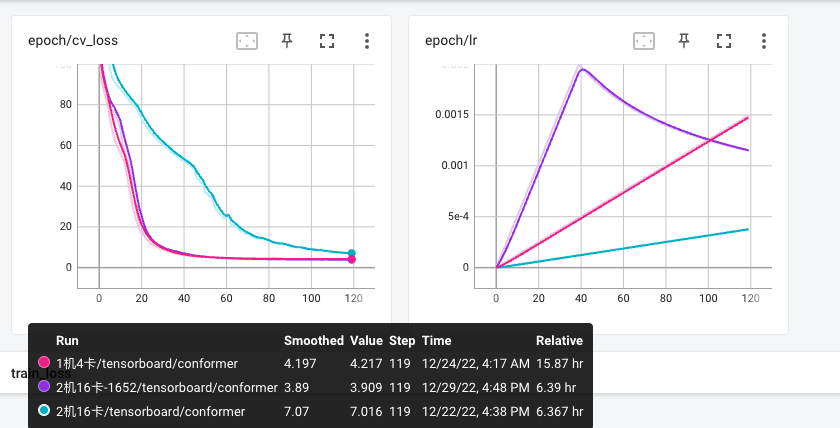
Tensorboard可视化分布训练开发集loss收敛和学习率的变化过程:
训练学习率相关参数:
conf/train_conformer.yaml
optim: adam
optim_conf:
lr: 0.002
scheduler: warmuplr # pytorch v1.1.0+ required
scheduler_conf:
warmup_steps: 25000
- 红色线条代表1机4卡,warmup_steps为25000
- 紫色线条代表2机16卡,warmup_steps为25000
- 蓝色线条代表2机16卡,warmup_steps为1652
结论:随着多机多卡分布式训练卡数量增加,每个Epoch的step数量减少,Warmup学习率的调整变慢,进而导致收敛速度变慢。根据训练卡的数量调整warmup_steps后,2机16卡与1机4卡的收敛速度接近。
Wenet学习率调整策略分析
Wenet Warmup学习率源代码分析
wenet/utils/scheduler.py
class WarmupLR(_LRScheduler):
...
def get_lr(self):
step_num = self.last_epoch + 1
if self.warmup_steps == 0:
# 不进行学习率的warmup,学习率根据step增加而衰减,衰减函数是平方根函数的倒数
return [
lr * step_num ** -0.5
for lr in self.base_lrs
]
else:
# 先进行学习率的warmup(线性增长),再进行学习率的衰减。
return [
lr
* self.warmup_steps ** 0.5
* min(step_num ** -0.5, step_num * self.warmup_steps ** -1.5)
for lr in self.base_lrs
]
def set_step(self, step: int):
self.last_epoch = step
Wenet学习率调整公式:
\[ f(step) = \left\{
\begin{array} \\
baseLR \cdot \frac{1}{\sqrt{warmupSteps}} \cdot \frac{step}{warmupSteps^{\frac{3}{2}}} & {step <= warmupSteps}\\
baseLR \cdot \frac{1}{\sqrt{warmupSteps}} \cdot \frac{1}{\sqrt{step}} & {step > warmupSteps}\\
\end{array}
\right.\]
- 当
step小于warmupSteps时,学习率随着step线性增长,直到baseLR; - 当
step大于warmupSteps时,学习率随着step增加而衰减,衰减函数是平方根函数的倒数。
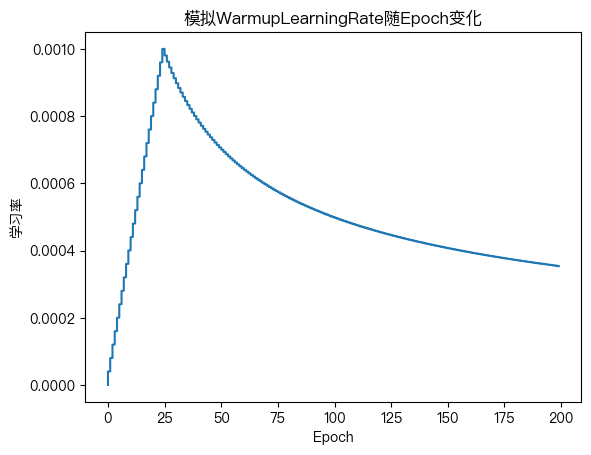
模拟Wenet 预热学习率调整策略
# 学习率调整函数
def f(step, lr=1e-3, warmup_steps=25000):
next_lr = lr * warmup_steps ** 0.5
if step < warmup_steps:
return next_lr * step * warmup_steps ** -1.5
else:
return next_lr * step ** -0.5
x = list(range(1, 200000))
y = list(map(f, x))
# 每个Epoch有1000个Steps
epochs = list(map(lambda x: int(x / 1000), x))
fig, ax = plt.subplots()
ax.plot(epochs, y)
ax.set_xlabel("Epoch")
ax.set_ylabel("学习率")
ax.set_title("模拟WarmupLearningRate随Epoch变化")
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号