又稳又快!基于ByteHouse ELT构建高性能离/在线一体化数仓
近期,ByteHouse与某数字娱乐公司达成合作,双方聚焦高性能离/在线一体化数仓展开合作。随着自身领域迅速发展的同时,该数字娱乐公司需要更稳定、易用的数据基础服务,但该方面遇到多种挑战,如数据融合与整合、实时数据分析、可扩展性和灵活性、多源数据入仓以及复杂的离线加工任务等。
作为一款云原生数据仓库,ByteHouse基于ClickHouse技术路线进行优化和升级,不仅拥有极致的分析性能、良好的扩展能力,而且有丰富的能力支撑ELT作业,支持fault tolerance、任务拆分等。
2023年该数字娱乐公司就引入 ByteHouse 构建实时数仓服务,2024年又将离线数仓迁移至 ByteHouse 上,至此完成了统一的离线/实时一体化数仓建设。通过数仓一体化升级,大幅提高数据分析的实时性(天级->分钟级),保证了大数据量级下数据处理的稳定性。
背景和挑战
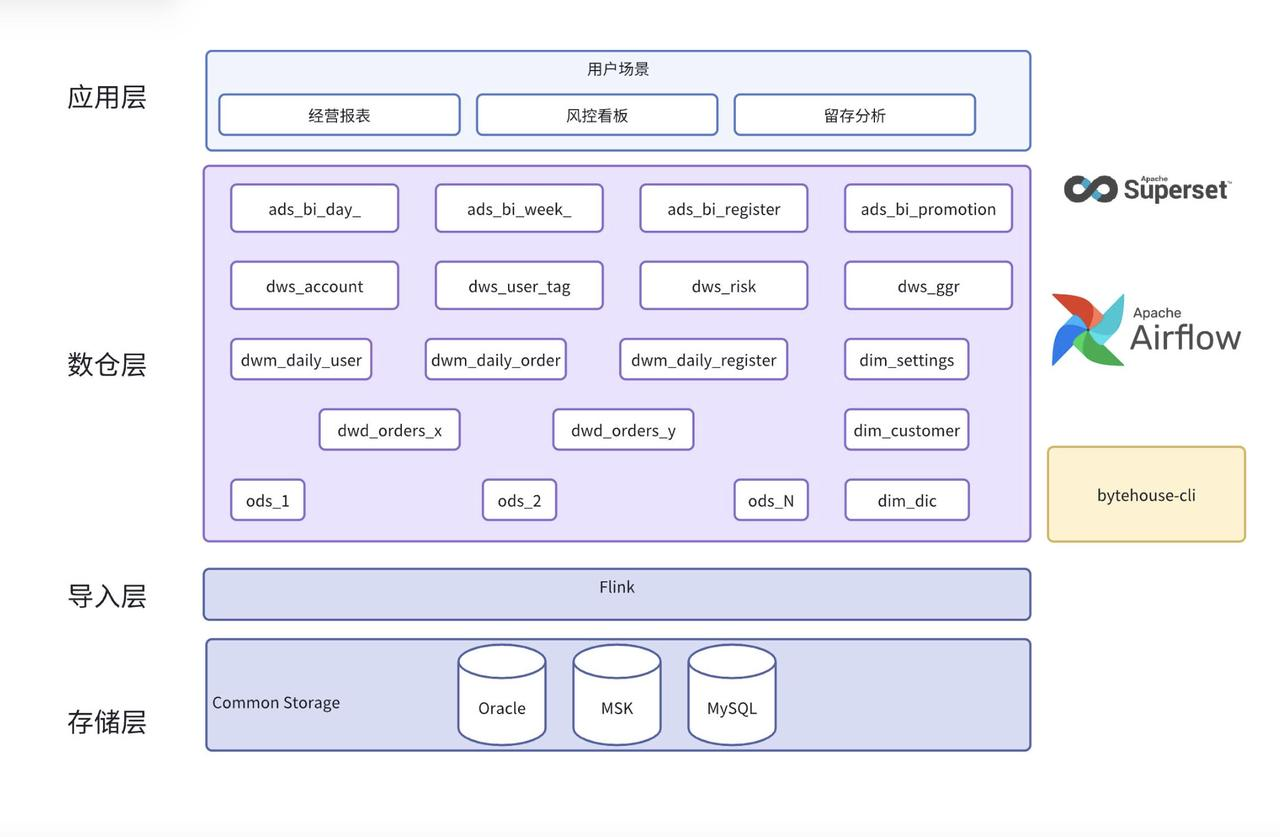
数据流向图
如上图所示,在一体化数仓改造前,该数字娱乐公司 的业务数据库在 Oracle 和 TiDB 上,使用 Flink 通过 CDC 方案将数据同步到数据仓库。导入后会经过一系列的离线加工任务,生成供业务读取的表,最终以报表、看板等形式展示到前端。
原架构中离线加工任务是由 Hive 和 Spark SQL 完成的,只有最终加工得到的数据才会存储在 ByteHouse 中,由 ByteHouse 提供实时查询能力。该方案有以下弊端:
- 架构复杂。用户需要维护多套引擎,无论是底层架构、运维方式、SQL语法还是参数调优,多套引擎都截然不同。这造成了额外的维护成本。
- 数据冗余。从 Hive/Spark SQL 到 ByteHouse 的数据同步链路需要额外开发,且数据是冗余存储了多份。无论从计算,还是存储方面,都造成了浪费。
- 效率瓶颈。当前资源下,该架构已经达到了每日多源数据融合的瓶颈,很难超过日增10亿这个量级。制约了公司业务的发展。
在这种情况下,客户选择使用 ByteHouse 构建一体化数仓,无论是 Adhoc 的报表查询、还是复杂的离线加工任务,都在一个系统中完成,减少运维、计算、存储方面的成本。
技术挑战
该数字娱乐公司 的离线加工场景对 ByteHouse 的能力提出了更高的要求,具体表现在:
- 数据量大。数据增量每天10亿级别,最大的表10TiB+,数据量1000亿+。
- 加工链路长。一共200+表,多层加工,任务依赖比较复杂,重试成本高。日常加工任务4-5千个,高峰时每天超过1万。
- 查询复杂。查询通常涉及大数据量 aggregate、多表 join,容易挤压资源,造成 OOM、超时等报错。
解决方案和收益
提升任务并行度,保障业务平稳运行
传统架构中,之所以要分别建设离线数仓和实时数仓,是因为常见的 OLAP 产品不擅长处理大量的复杂查询,很容易把内容打满任务中断,甚至造成宕机。
ByteHouse 具备 BSP 模式,支持将查询切分为不同的 stage,每个 stage 独立运行。在此基础上,stage 内的数据也可以进行切分,并行化不再受节点数量限制,理论上可以无限扩展,从而大幅度降低峰值内存。
在实际应用中,通过对关键的大表增加并行度,该数字娱乐公司 的离线任务整体内存峰值降低了40%左右。有效减少了内存溢出的概率,保障任务平稳运行。
任务级重试,减少重试成本
离线加工任务的另外一个特点就是链路比较长,并且任务间有依赖关系。如下图所示:
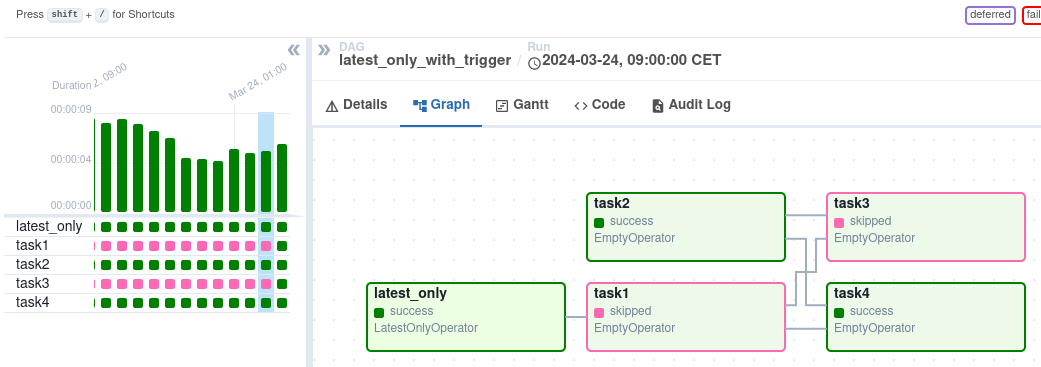
如上图所示,task4 依赖 task1、task2 的完成。如果 task1 失败发起重试,会显示为整个链路执行失败。
ByteHouse 增加了任务级重试能力,在 ByteHouse 中只有运行失败的 task 需要重试。以10月15日到10月17日为例:
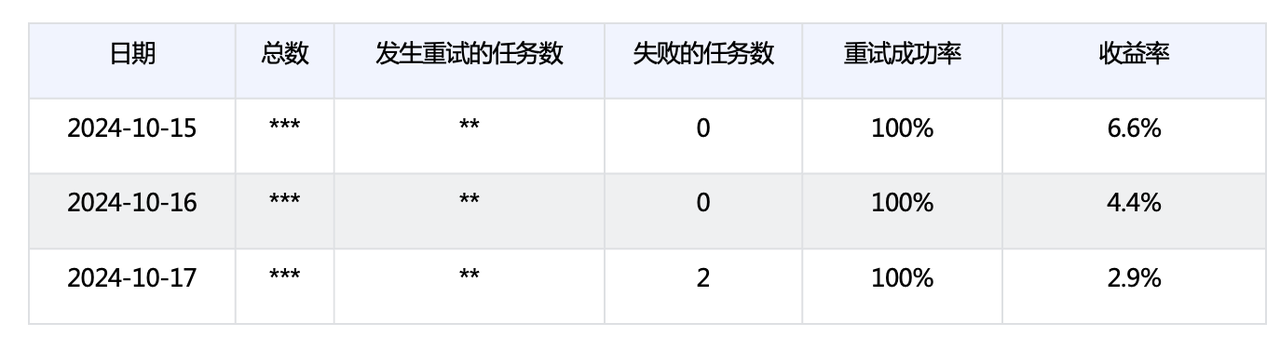
总数及发生重试的任务数以***脱敏展示
可以看到,任务的成功率在这三天内分别提高了6.6%、4.4%和2.9%,整体成功率为100%。除提高任务执行的成功率外,还能显著减少重试时间,体现为降低整体的离线任务执行时间。
大批量并行写入,稳且快
该数字娱乐公司 的业务数据存在频繁更新的特点,使用重叠窗口进行批量 ETL 操作时,会带来大量的数据更新。在这种场景下,ByteHouse 做了大量的优化。
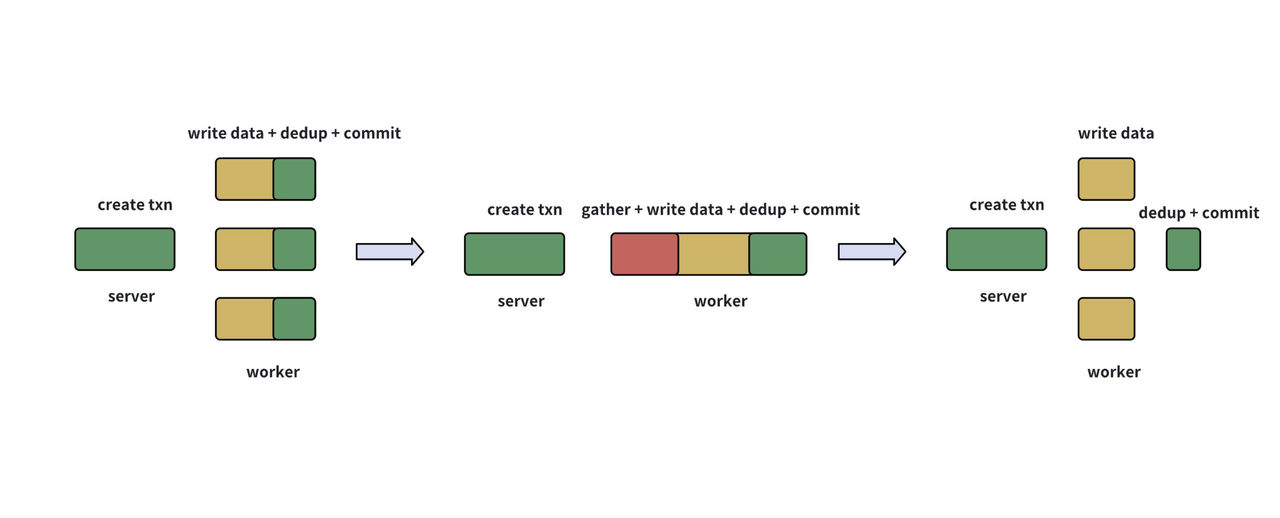
写入优化示意图
经过持续优化,将最耗时的数据写入部分单独并行化,并且在写入 part 文件时标记是否需要进行后续的 dedup 作业。在所有数据写入完毕后,由 server 指定一个 worker 进行 dedup 和最后的事务提交(如上图最右)。
经过优化,在保持稳定的前提下,用户十亿表的 insert 作业运行时间从48分钟降低到13分钟,提速73%。其他相对较小的表插入效率也提高了26%-44%左右。
简化数据链路,提高健壮性
ByteHouse 在传统的 MPP 链路基础上增加了对复杂查询的支持,这使得 join 等操作可以有效地得到执行。在数据交换方面,要求所有 stage 之间的依赖必须在查询执行之前以网络连接的形式体现。离线加工场景下,这种方式有着天然的劣势:
- stage 较多、并行度较大时,每一个 task 出现的抖动都会影响整体链路,叠加的抖动增加任务失败的概率;
- task 同时拉起会进一步对资源进行挤占。
BSP 模式使用 barrier 将各个 stage 进行隔离,每个 stage 独立运行,stage 之内的 task 也相互独立。即便机器环境发生变化,对查询的影响被限定在 task 级别。且每个 task 运行完毕后会及时释放计算资源,对资源的使用更加充分。
在这个基础上,BSP 的这种设计更利于重试的设计。任务失败后,只需要重新拉起时读取它所依赖的任务的 shuffle 数据即可,而无需考虑任务状态。
总结
所有以上提到的这些优化,均建立在ByteHouse提供极速分析性能的基础上。在实时数仓的能力上,通过叠加对离线数仓能力的支持,ByteHouse通过将查询切分为独立的阶段、阶段内进行并行度的拓展,对大查询的内存降低、任务的失败降低、写入效率和整体鲁棒性来说,都有明显的效果。这在最终促成了该数字娱乐公司可以使用ByteHouse一个引擎同时完成数据加工和数据分析,减少了组件冗余,节省了人力成本,大大提高了数据实时性、优化了运营效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号