
基于 OLAP 湖仓一体架构,火山引擎 ByteHouse 助力企业降本增效
在数字化转型的浪潮中,企业对数据处理能力的要求日益提高。
过去,数据湖和数据仓库分别拥有两套独立的管理体系,这导致维护成本高昂,研发周期漫长。为了加强数据端到端的链路整合,构建一套低成本、高性能的数据湖仓一体分析能力成为越来越多企业的需求。
作为火山引擎推出的一款云原生数据仓库,ByteHouse 基于 ClickHouse 技术路线优化和演进,已具备实时数据分析、海量数据离线分析能力,便捷的弹性扩缩容、极致分析性能以及丰富的企业级特性,在金融、游戏、泛互等领域加速企业数字化转型。为了进一步提升使用体验、降低运维成本,ByteHouse 构建了高性能、功能全面的湖仓一体能力,支持对多种数据湖开放格式进行读写,并通过优化器和 Schema 动态感知增强性能,确保湖仓间数据高效流动。
据火山引擎 ByteHouse 产品负责人李群介绍:“ByteHouse 湖仓一体能力具备快、通、全三大特点,在保障湖仓数据联邦的分析高性能的同时,实现湖仓双向读写,精简了整体架构,还基于 Multi-Catalog 进行多源数据管理,提供更丰富、更全面的一体化能力。”
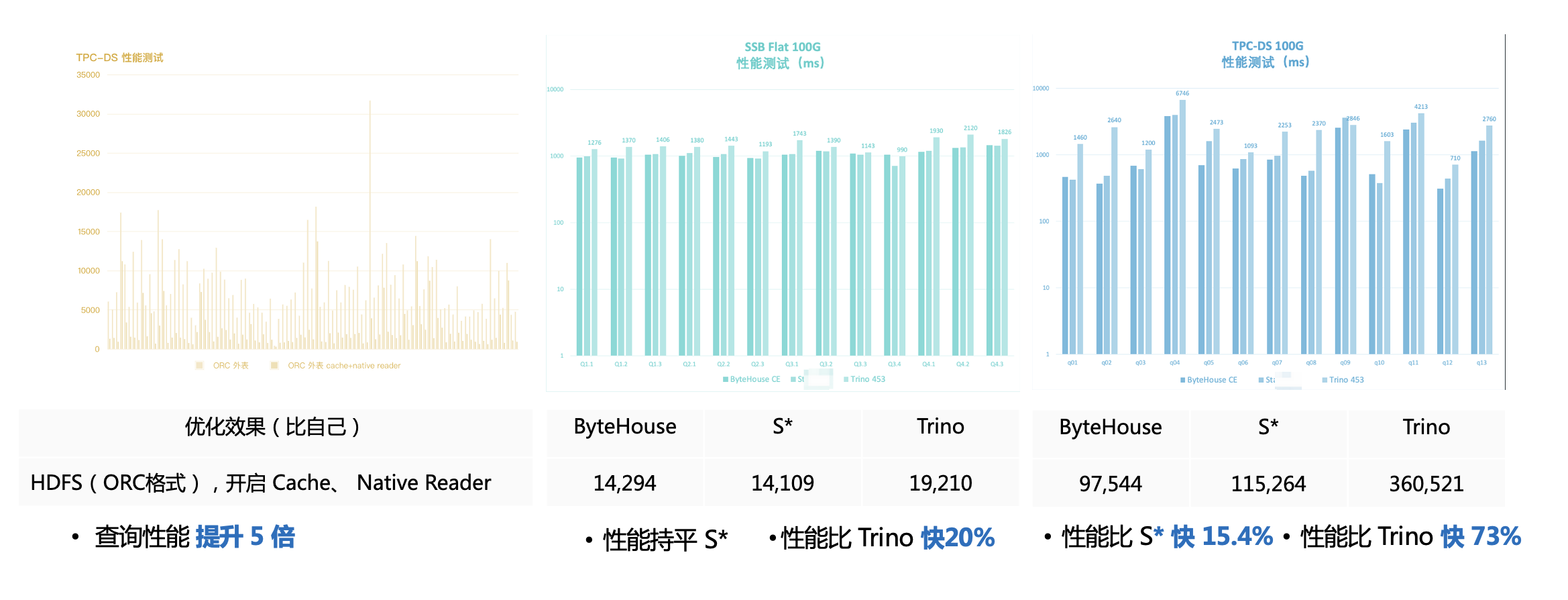
首先,ByteHouse 湖仓一体关键能力之一在于“快”。在当今复杂的商业环境下,企业每天需要面临大量决策,而高效的数据反馈可以提升企业决策效率和准确度。从 Native Reader、IO 优化、多级 Cache、物化视图、优化器五个方面,ByteHouse 针对性能进行了大量优化。例如,在并发支持和复杂模型处理上,ByteHouse 则通过自研优化器等手段优化了 ClickHouse 的不足,在经典的星星、雪花负载模型下已得到验证。从数据效果上看,ByteHouse 在 SSB Flat 100G 、TPC-DS 100G 测试中的表现,基本高于行业同类型产品。
其次是“通”。ByteHouse 采用 ZeroETL 理念,实现了湖与仓之间的双向互通,支持读取和写入数据,简化数据架构。具体而言,ByteHouse 湖-表格式在 EMR 上运行,支持对 Hive、Hudi、Paimon、Iceberg 等多种数据源的外表读操作。而湖-文件格式则支持在对象存储上进行 CSV、JSON/JSONB、Parquet、ORC 等多种格式的读写操作。此外,ByteHouse 还提供了 Spark、Flink 等 Connector,方便企业将 ByteHouse 与其他大数据处理框架进行集成,实现更加高效的数据处理和分析。
最后是“全”。基于 Multi Catalog 多源数据管理能力,ByteHouse 具备全域数据一张图的能力。例如,从治理角度,展示全域血缘、全域治理数据;从管控角度,展示全域多租户管理、全域权限管控数据;从合规角度,展示全域合规性建设数据等,助力企业从全局视角更好洞察和分析高价值数据,提升数据资产化能力。
除了湖仓一体化,ByteHouse 还从 TP、AP 一体化,仓、市一体化,AP、AI 一体化方面,逐步实现 ZeroETL 轻量化数据架构。通过“四个一体化”策略,不仅让数仓更轻快,数据免搬迁,还能保障数据质量,实现智能运维。
目前,ByteHouse“四个一体化”策略已经在抖音集团内部 BI 平台落地和验证,在报表查询、管理驾驶舱、指标平台等业务场景中,将性能至少提升 2 倍,成本降低 33%。

