ByteHouse案例实践:某销售数据平台如何基于OLAP大幅提升复杂查询效率?
 ByteHouse是火山引擎推出的一款定位为OLAP的分析型数据库,基于ClickHouse进行架构升级和优化,在复杂查询层面拥有显著优势。
ByteHouse是火山引擎推出的一款定位为OLAP的分析型数据库,基于ClickHouse进行架构升级和优化,在复杂查询层面拥有显著优势。
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
在现如今激烈的市场竞争中,销售数据是企业下一步市场决策的重要依据。销售数据提供了关于市场需求、客户行为、产品表现等方面的详细信息。通过深入分析这些数据,企业销售人员、决策者等可以获取有关市场趋势和消费者偏好的宝贵洞察,从而做出更加明智和精准的决策。
某公司的市场份额一直处于快速增长的态势,为了更好的统一数据口径、保障数据质量、控制数据权限,企业内部已将分散的销售数据统一到一套可视化分析平台中。该平台之前由开源ClickHouse作为数据分析引擎,但在引入鉴权ACL用于管理数据权限、保障数据安全之后,该平台出现性能不足、影响用户体验的情况。
ByteHouse是火山引擎推出的一款定位为OLAP的分析型数据库,基于ClickHouse进行架构升级和优化,在复杂查询层面拥有显著优势。该公司引入ByteHouse之后,结合相关销售场景,对ByteHouse优化器能力点对点优化,实现查询效率显著提升,在某些场景下效率提升达到16倍。
本文将从业务痛点、解决方案、优化结果三个方面,详细拆解该公司销售数据平台如何基于ByteHouse复杂查询能力实现效率提升。
业务背景:销售数据平台采用鉴权ACL模式管理数据权限
在该公司内部,销售人员(数据使用者)、数据分析师、数据工程师(数据维护和提供方)以及公司管理,一直以来都存在以下痛点问题:
- 对于销售来说,数据范围难以全平台对齐,即便是同一个数据集也会存在可见范围不同的问题;组织变动、负责的客户频繁,调整过后则会存在看数问题。
- 对于数据产品经理、数据工程师、数据分析师等数据维护和提供方来说,数据集行权限维护成本高,了解销售场景中复杂的鉴权逻辑,导致学习成本高。
- 对于公司合规管理来说,数据权限应该得到合理控制,各个销售能看到的客户信息应控制在最小范围内。
为了解决以上问题,该公司的研发团队单独把销售数据的鉴权内聚成新服务,并且引入新的一种查询鉴权模式 ACL来解决以上问题。
“鉴权 ACL(Access Control List)”通常指用于进行身份鉴别和权限控制的访问控制列表。鉴权是指验证用户或实体的身份和权限,以确定其是否有权访问特定的资源或执行特定的操作。引入鉴权 ACL之后,能严格控制数据访问权限,确保只有授权人员可查看和操作敏感的销售数据,还可以根据员工职责精细划分权限,比如销售团队只能访问自身业务数据,管理层能获取更全面数据,提升数据使用的合理性和安全性。
- 引入鉴权ACL之前的查询情况:

- 引入鉴权ACL后:
绿色部分为SQL改动,通过引入子查询的方式,使用户无权限数据过滤,保证用户鉴权最新状态。

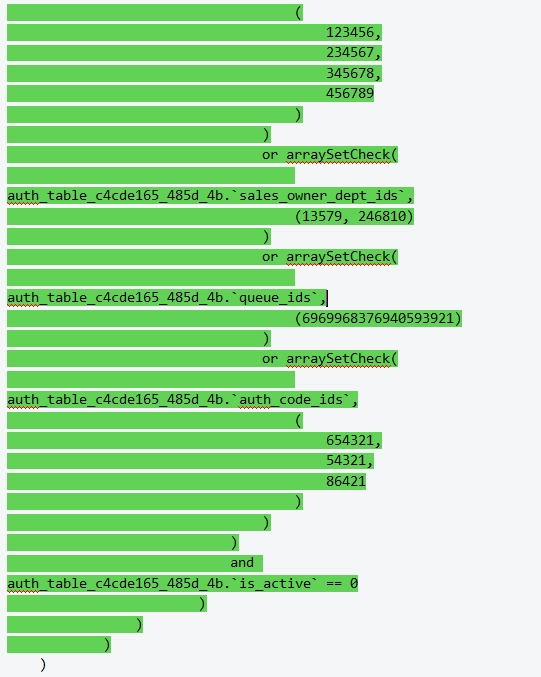
业务痛点:基于ClickHouse难以满足鉴权ACL下的数据查询需求
在引入ACL之前,日常销售分析查询就非常复杂、查询量级大。而在SQL加入ACL控制后,采用的是分布式表JOIN,且ACL表子查询返回结果大,进一步导致集群负载恶化,ClickHouse集群CPU使用率长期打满,影响用户体验。
性能恶化核心原因为ClickHouse社区的Scatter/Gather执行模型缺少shuffle的能力,对于多轮join难以很好支持。
下面用一个简单的例子说明Scatter/Gather执行模型下join的原理:
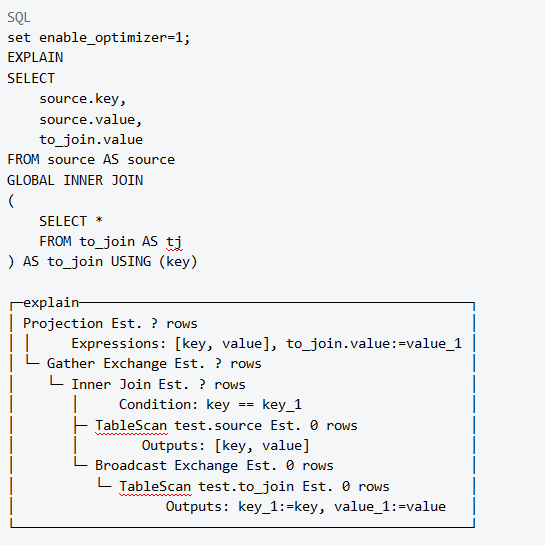
两张分布式表source和to_join(对应local表分别是source_local和to_join_local)数据分布在两个分片上,如下图:
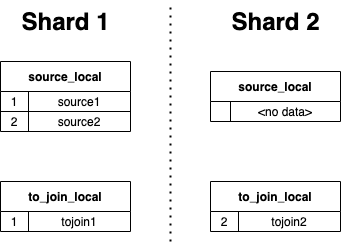
- 先设置
distributed_product_mode = 'allow',执行join查询:

- 每个分片节点独立执行子查询
SELECT *FROM to_join AS tj,然后在本地做join,最后在接收查询的节点(下文用host server指代)上汇总join结果,如下图所示

- 最终结果如下:

如果分片数目为N,右表表达式的分布式表
to_join在一次join中就会被重复查询N次,导致效率低下。为了解决该问题,我们采用Global Join,或者设置distributed_product_mode='global',引擎会自动将分布式表的join改写成Global Join。
Global Join的原理是host server先执行带分布式表的子查询,再类似临时表存在内存中,发送到其他的节点,让其他节点join的时不用重复查询该分布式表。这样的优化方式让Global Join效率基本可用了,但还存在如下局限性:
- 右表的大小影响join效率,如果右表比较大,join的时候cache missing会非常严重,性能很差;
- 不考虑SPILL的情况下(Graceful hash join可以部分缓解这个问题),右表的必须全部在内存中,容易OOM。
- Broadcast右表实现的效率上也有提升空间,比方说右表数据先汇总到host server,再下发到各个节点多了一轮额外的传输和序列化反序列化开销。
- 多表JOIN,不同的join顺序对性能影响也很大,ClickHouse并没有join reorder的能力,依赖用户手动调优join的表的顺序。
解决方案:迁移到ByteHouse提升销售数据平台复杂查询效率
ByteHouse企业版支持优化器和MPP执行模型,可以较好的支持复杂join的场景,并且优化器能力可以进一步提升查询效率,成为该公司销售数据平台从ClickHouse迁移的首选。
优化器是DBMS中一个核心组件,它负责分析查询语句,并根据表的结构、索引等信息来生成最优的执行计划。通过优化查询执行计划,可以提高查询的执行效率,减少资源消耗,提升系统性能。为了提升在复杂场景的查询性能,ByteHouse 的自研优化器进行了大量的优化,主要包括四个大的优化方向:RBO(基于规则的优化能力),CBO(基于代价的优化能力),分布式计划优化以及一些高阶优化能力。
优化器和MPP执行模型原理
开启优化器后,执行模式由原来的Scatter/Gather模型切成了完全MPP模型。整个SQL的执行流程如下图所示(以3节点的集群为例)
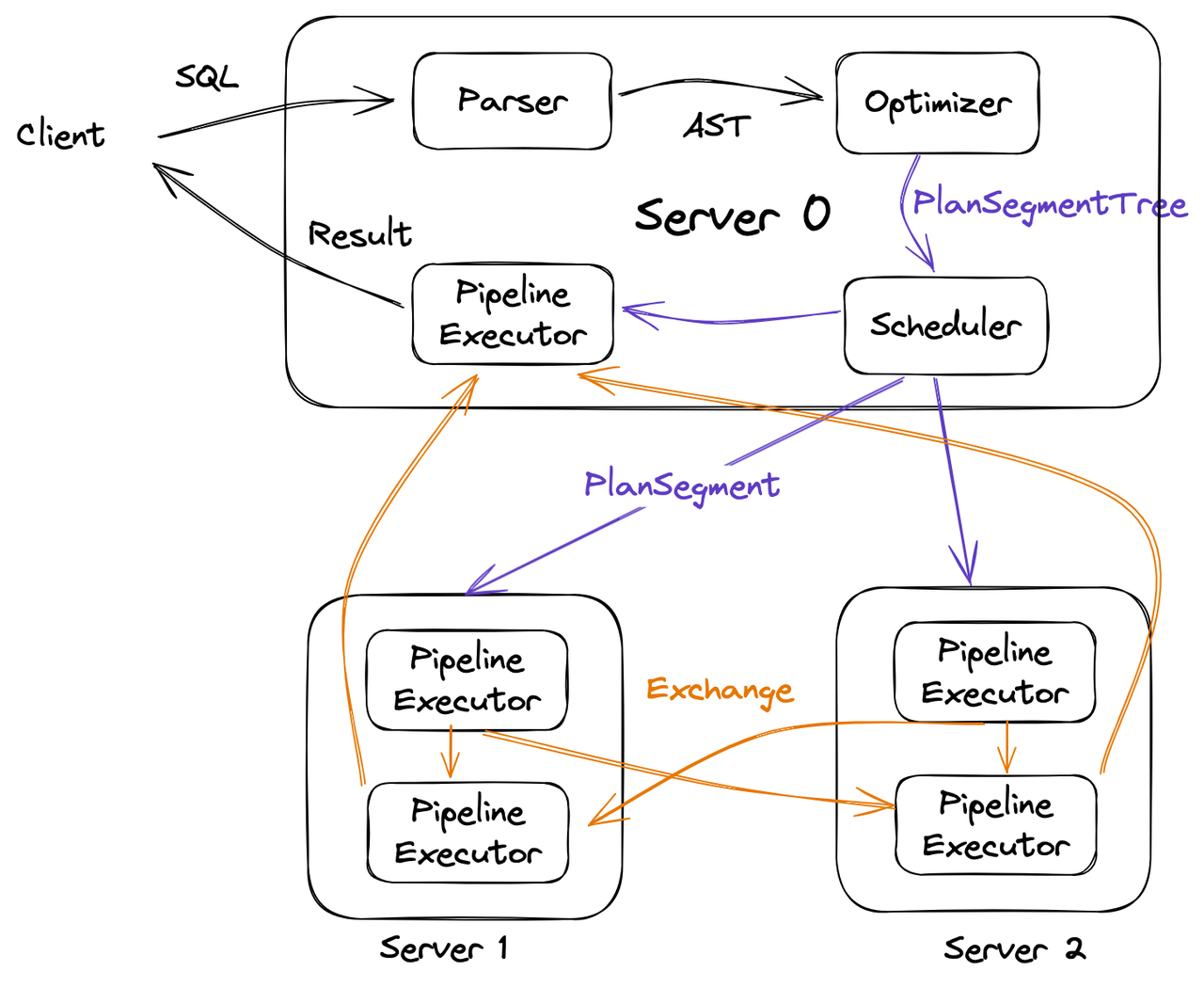
- PlanSegment:分布式执行计划逻辑单元(QueryPlan+Exchange输入输出)
- Optimizer: 根据Rule(RBO)和统计信息(CBO)进行查询计划的优化,生成最终的查询计划PlanSegmentTree. Query Optimizer User Guide
- Scheduler: 发送PlanSegment到各个Worker
- Exchange:在Pipeline之间传输数据
- PipelineExecutor: 驱动执行PlanSegment
ByteHouse优化器四大优化方向
下面用上一节的例子简单说明:采用之前的SQL
可以看到右表读取完之后通过exchange进行了广播到左表再join(不同于原来模式需要先在host server汇总右表再下发到各个节点)。
如果两个表很大,开启统计信息的情况下,计划如下:

左右表会先shuffle N份(N默认为分片总数/10,可以通过distributed_max_parallel_size参数控制)再进行join,这样单个节点join的时候右表的大小平均是总右表的1/N,内存占用和性能都有很大提升。
开启ByteHouse优化器后,查询计划会有这四类优化:
优化一:RBO:
基于规则的优化能力。支持列裁剪,分区裁剪,表达式简化,子查询解关联,谓词下推,冗余算子消除,外部连接转内部连接,算子下推存储,分布式算子拆分等常见的启发式优化能力。
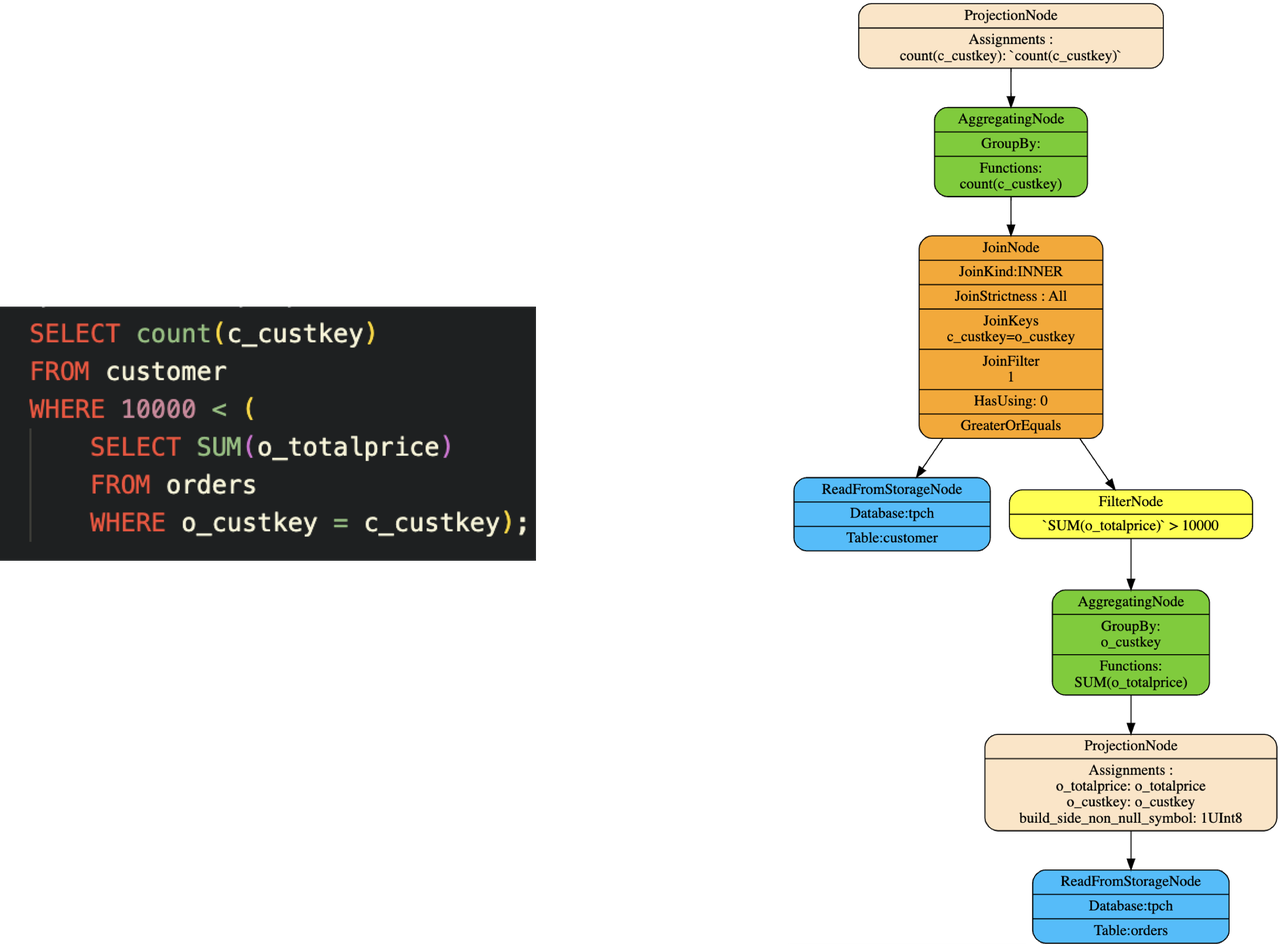
- 解关联
很多OLAP引擎不支持相关子查询,在语法分析阶段就会报错。优化器实现了完整的解关联能力,对于关联查询可以转换为常见的 join agg filter 等算子执行,下图就是一个简单的解关联例子。对于一些特殊类型的关联查询也可以利用 window 算子执行,更加快速简洁。
- 非等值Join优化
在很多引擎中,带有非等值条件的 join 需要通过多个算子来组合执行(
inner join + filter + group-by),而在 ByteHouse 中,支持非等值 join 之后可以直接在 join 算子中完成非等值条件的执行。优化器会对一些关联子查询转成非等值 join 来执行,相较于转成其他常见的算子(inner join, filter, agg)性能有一倍以上的提升。
优化二:CBO
基于代价的优化能力。基于级联搜索框架,利用Graph分区技术实现了高效的Join枚举算法,以及基于直方图的代价估算,对10表级别规模的Join Reorder问题,能够全量枚举并寻求最优解,同时针对于10表规模的Join Reorder支持启发式枚举并寻求最优解。CBO支持基于规程扩展搜索空间,除了常见的Join Reorder问题以外,还支持外部Join/Join Reorder、Aggregate/Join Reorder、Magic Set Placement等相关优化能力。
优化三:分布式计划优化
业界主流实现分为两个阶段,首先寻求最优的单机版计划,然后将其分布式化。但是这样的设计流程,不能提前考虑分布式系统的特点,可能会导致网络延迟、数据分布不均衡,并导致可扩展性限制等问题。我们的方案则是将这两个阶段融合在一起,在整个 CBO 寻求最优解的过程中,会结合分布式计划的诉求,从代价的角度选择最优的分布式计划,同时在 Join/Aggregate 过程中,也支持 Partition 属性展开。
另外,我们也在 CBO 中实现了对于 Aggregate/Join Reorder,Magic Set Placement 等相关能力。对于 CTE 的实现方式也基于 Cost 进行选择,在 inline,shared 和 partial inline 之间做权衡,选出最优的计划。在 tpcds 等 benchmark 中都有一定的应用。
优化四:高阶优化能力
ByteHouse实现了动态Filter下推、物化视图改写、基于代价的CTE(公共表达式共享)、计划复用、结果复用等高阶优化能力。
最佳实践之“聚合计算加速”
在数据库中,优化器对于聚合计算加速起着关键作用。优化器能够分析查询语句的结构和涉及的数据,评估不同的执行计划。对于聚合计算,它会考虑数据的分布、索引的可用性以及表之间的关系等因素。除了JOIN场景,ByteHouse在聚合计算场景也产生了积极的影响。
- 多节点并行merge聚合结果
分散/聚集模式在聚集阶段会聚合各个节点局部聚合的中间结果,这时容易遇到单节点的性能和内存瓶颈,其典型的场景是大数据的
count distinct。开启ByteHouse优化器后,我们可以使用10%的分片(通过distributed_max_parallel_size参数调整,最大值为集群分片数目)来做最终的聚合操作,实现较好的并行聚合。- 优化器会对聚合进行改写优化,提升聚合性能
如果缺少group by key的聚合操作,在没开优化器的情况下,Gather阶段在单机内为单线程聚合(由于缺少group by key无法并行)。ByteHouse优化器能实现进行自动改写,除了多节点并行合并聚合结果,单节点内部也能并行。
下面为
tpch的数据(6亿数据的lineitem表)在一个两节点集群测试(最后merge的节点为同一个),SQL如下:
开启优化器耗时从5.913秒下降到了2.263秒。
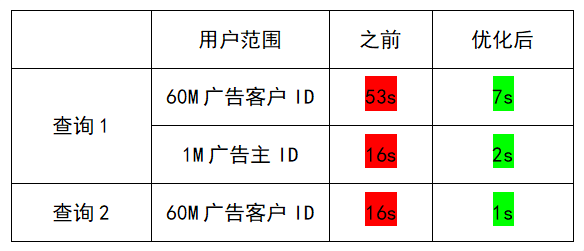
优化结果:最高16倍,相关场景查询效率提升
通过非ACL查询和ACL查询两个方向,我们可以看到查询时间在优化前后有显著提升。其中,在ACL查询中的60M广告客户DI场景中,引入ByteHouse之后将查询效率从16s缩短为秒级,提升了16倍。
- 非ACL查询
抽取该公司销售平台某数据集测试

- ACL查询
抽取该公司销售平台某数据集测试
总结来看,但随着用户使用场景愈加复杂,ByteHouse针对复杂的查询场景,在RBO、CBO、分布式计划等层面进行大量优化,进一步提升了OLAP在各个场景下的查询性能。未来,ByteHouse也将持续为更多企业的数据分析能力提供支持,助推数智化转型升级。
点击跳转 火山引擎云原生数仓ByteHouse 了解更多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号