

OLAP进阶之“性能提升”
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
在数据处理和分析的领域,提升查询效率始终是一项关键挑战。对于 OLAP 来说,性能的关键需求在于能支持实时分析,应对复杂查询,提供快速响应,并具备良好的可扩展性。这些方面,对于满足高效、准确的数据分析需求至关重要。
火山引擎正式发布《云原生数据仓库ByteHouse性能白皮书》,白皮书通过使用 SSB 100G、TPC-H 100G、TPC-DS 100G 数据集进行性能测试,展示出 ByteHouse 在查询效率方面的显著成果,并详细介绍ByteHouse在实时数仓、复杂查询等八大应用场景的高性能应用表现。
作为一款OLAP引擎,伴随字节跳动各业务的发展,ByteHouse已经过数百个应用场景和数万用户锤炼,在2022年3月,部署规模已超过1万8000台,最大的集群规模在 2400 余个节点,管理总数据量超过700PB,并逐步在外部金融、泛互等场景应用和推广。为了更好支持字节内外部大规模数据和复杂场景应用,性能一直以来是ByteHouse重点打磨的产品基本功。
SSB、TPC-H 和 TPC-DS 是常用于测试分析型数据库/数据仓库的数据集。在白皮书中,通过使用以上三种数据集进行性能测试,并以性能著称的某开源OLAP为基准测试产品,ByteHouse在不同查询项上都有显著的性能提升。以TPC-H 数据集举例,在相同硬件和软件环境下, ByteHouse 查询效率高于本次基准测试产品几十倍。
背景
ByteHouse是字节跳动数据平台自主研发的云原生数据仓库产品,在开源ClickHouse引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能,已通过火山引擎对外提供服务。在可扩展性、稳定性、可运维性、性能以及资源利用率方面,ByteHouse都有巨大的提升。
ByteHouse以提供高性能、高资源利用率、高稳定性、低运维成本为目标,进行了优化设计和工程实现,产品特性和优势如下:
- 存储计算分离:解决了全局元数据管理,过多小文件存储性能差等等技术难题。在最小化性能损耗的情况下,实现存储层与计算层的分离,独立扩缩容。
- 新一代 MPP 架构:结合 Shared-nothing 的计算层以及 Shared-everything 的存储层,有效避免了传统 MPP 架构中的 Re-sharding 问题,同时保留了MPP并行处理能力。
- 数据一致性与事务支持。
- 计算资源隔离,读写分离:通过计算组(VW)概念,对宿主机硬件资源进行灵活切割分配,按需扩缩容。资源有效隔离,读写分开资源管理,任务之间互不影响,杜绝了大查询打满所有资源拖垮集群的现象。
- ANSI-SQL:SQL兼容性全面提升,支持ANSI-SQL 2011标准,TPC-DS测试集100%通过率。
- UDF:支持Python UDF/UDAF创建与管理,补足函数的可扩展性。(Java UDF/UDAF已在开发中)
- 自研优化器:自研Cost-Based Optimizer,优化多表JOIN等复杂查询性能,性能提升若干倍。
产品能力上,在引擎外提供更加丰富的企业级功能和可视化管理界面:
- 库表资产管理:控制台建库建表,管理元信息。
- 多租户管理:支持多租户模型,租户间互相隔离,独立计费。
- RBAC权限管理:支持库、表、列级,读、写、资源管理等权限。通过角色进行管理。
- VW自动启停,弹性扩展:计算资源按需分配,闲时关闭。降低总成本,提高资源使用率。
- 性能诊断:提供Query History和Query Profiler功能,帮助用户自助地排查慢查询的原因。
ByteHouse性能优化:复杂查询、宽表查询
ByteHouse来源于ClickHouse,但又基于字节跳动内部实践场景经验,进行了一系列升级。在性能层面,主要复杂查询以及宽表查询两方面进行优化。
复杂查询优化
其中相比单表查询或者宽表查询而言,复杂查询主要包含较多的Agg join和嵌套子查询等特征。在复杂查询优化项中,相比于社区版ClickHouse,ByteHouse升级的能力包含自研优化器以及在引擎层新引入的exchange runtime Filiter模块以及为提升并行化能力而做的一些重构工作。
优化一:RBO(基于规则的优化能力)
首先,自研优化器RBO,即基于规则的优化,包含列裁剪、分区裁剪、表达式简化、子查询解关联、谓词下推、冗余算子消除、Outer-Join 转 Inner-Join、算子下推存储、分布式算子拆分等常见的启发式优化能力。
- 相对社区版ClickHouse,ByteHouse实现了完整的解关联,从而确保tpcds所有查询能够运行。如下图所示,一个customer表和一个含orders表的子查询进行关联,最后的计划会展开成对应的join、agg和filter等算子。
- 另外,针对非等值join,相对于先outer join后再执行非等值过滤这种组合,非等值join可以直接在join算子中完成非等值判断,从而提升了1倍的性能。
- 最后,针对很多通用的业务场景,RBO还实现了对多个列计算count distinct的优化,主要原理是基于复制的方式从而提升并行度来实现。
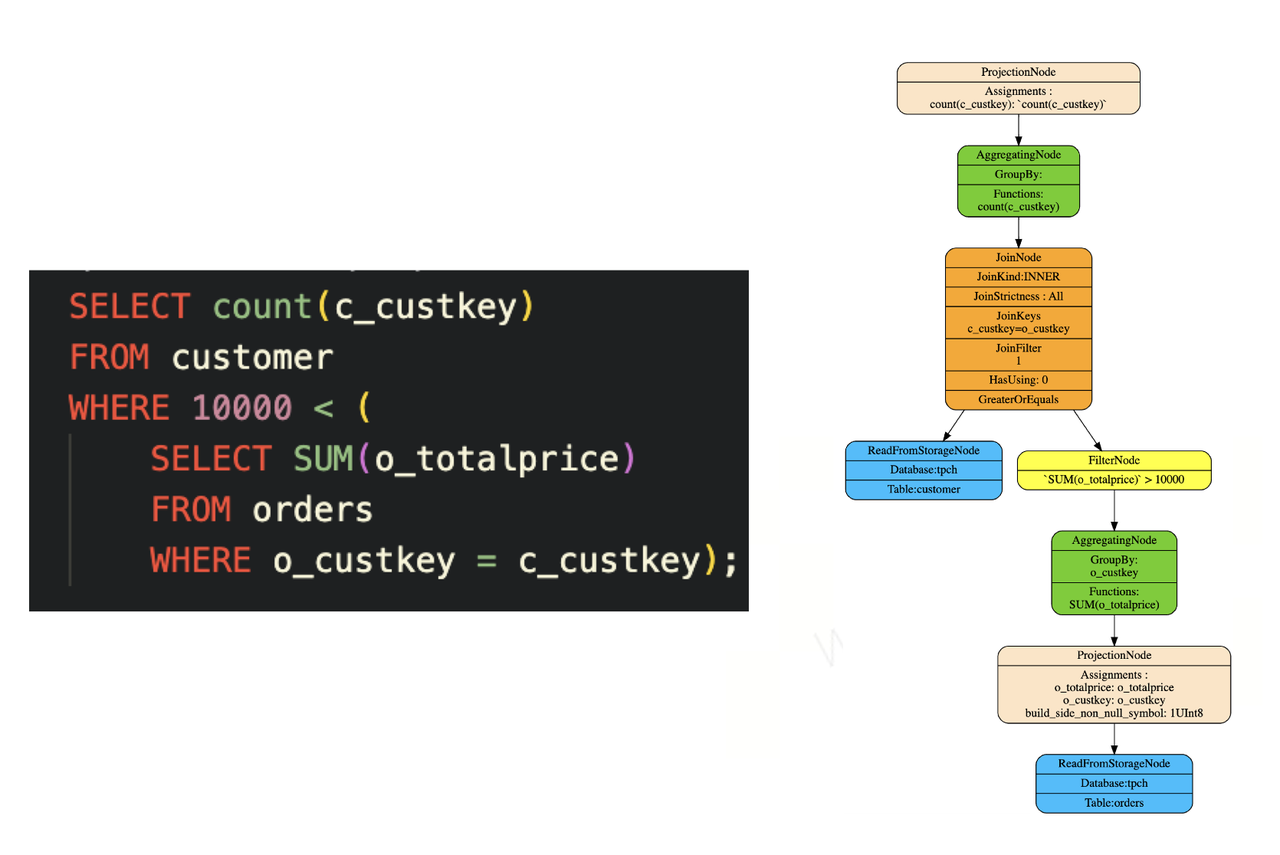
优化二:CBO(基于代价的优化能力)
在自研优化器CBO,即基于代价优化部分,ByteHouse主要基于Cascade搜索框架,从而可以边生成物理计划边寻求最优解。并针对join order枚举问题采用了Join graph partition的方式减少了重复计划的生成从而提升搜索性能;另外代价则为基于统计信息生成。
在Join Recorder方面,针对10表级别规模的join recorder问题,ByteHouse能够在秒级别全量枚举并生成最优解,另外,针对大于10表的则使用了启发式,ByteHouse还支持混合Outer Semi Anti Join的reorder功能。
在CTE层面,ByteHouse支持了Inline, shared及partial inline等不同粒度的代价计算,从而计算最优解。
除此之外,ByteHouse具备基于magic set placement能力,通过计算join过滤度代价来选择下推到agg,从而减少agg计算热点的能力。
优化三:分布式计划生成方面推出了自研优化器
在生成计划过程中,区别于业界主流的二阶段方式,即先生成最优单机计划再生成分布式计划的方式。ByteHouse优化器融合了两个阶段,先展开所有分布式计划,然后基于全局代价生成最优解,并减少shuffle。其中,ByteHouse也会通过表的元数据信息和属性推论,利用数据分布来减少agg和join的shuffle开销。
优化器生成的物理计划往往按照数据重分布会拆解成多个计划片段即plan segment,相比于社区版ClickHouse,除了优化器生成的物理计划不同之外,plan segment之间数据的传输也是依赖我们新引入的exchange模块能力。模块分为两层,数据传输层和算子层。
- 数据传输层支持同进程传输,基于队列跨进程,基于 BRPC stream,并支持保序状态码传输、压缩和连接池复用等功能。为了确保稳定性,连接池可以让上下游 plan segment 在集群做数据 shuffle 的时候始终维持在固定数量的连接,从而提升稳定性。
- 在传输层之上,算子层提供了一对多的broadcast,多对多的repetition、多对一的gather、其进程内的round、 Robin 等算子。
此外,ByteHouse还实现了更多exchange性能相关优化,如尽量减少重复的序列化及载批等逻辑。
相对于社区对于join能力,ByteHouse提供了runtime filter能力,这是在执行引擎中动态构建filter的能力,例如在 Hash Join 的 Probe 阶段前,提前过滤掉大部分不会参与 Join 的左表数据,从而减少数据传输和计算的开销,提升性能。这里的Runtime Filter是在 Hash Join 的 Build 阶段后,结合 Join Key 和 Hash表生成。此外,ByteHouse支持根据不同的场景生成最优的 RuntimeFilter,优化了 Runtime Filter 的生成和执行的流程。同时,也支持 Distributed 和 Local 的 RuntimeFilter,及自适应的 Shuffle-Aware 能力。
优化四:并行化重构
除了以上介绍的优化器、exchange和runtime filter能力外,ByteHouse也是一直朝着提升并行计算能力的方向持续在演进。
针对agg和join,社区版ClickHouse的解法通常不会考虑数据的分布特性,以及一些算子的聚合度特性,从而产生大量的无意义的blocking的中间结果的merge开销以及join跨节点的shuffle开销。
针对agg,ByteHouse实现了自适应的agg streaming能力,可以根据聚合度减少无意义的中间merge开销。
另外,结合优化器,和bucket表能力,ByteHouse用了数据分布特性,大量减少了agg和join的shuffle开销,从而提升了并行度。
宽表查询优化项
针对社区ClickHouse典型宽表场景,ByteHouse做了全局字典、Zero copy以及Uncompress Cache优化。
首先,全局字典主要功能是通过全局字典编码的方式将变长的字符串转化为电长的数值。针对 AGG function 和 exchange 算子,不仅在单节点上单节点以,也可以在跨节点间直接进行这个编码值的计算,以此提升计算效率。
其次,Zero copy是应对内存墙的一种优化方式,通过减少数据传输中引发的深拷贝开销,尽量提升内存带宽在真正计算上的使用。
最后,针对单节点上多线程同时并发访问Uncompress cache引发常见的锁竞争的现象,ByteHouse做了针对性优化,保证了Cache带来的性能收益。
性能表现
以下是ByteHouse在标准数据集的性能表现。本次发布会主要聚焦100G 的规模。针对每项测试,ByteHouse和某款开源的 OLAP 引擎进行了性能对比。
- TPCDS 100G
从 TPC-DS 100G 的结果可以观察到,经过测试发现在完成 TPC-DS 标准测试数据集的 99 个查询中,ByteHouse比开源产品OLAP 引擎总体时间超出 6 倍多,并且开源产品部分语句无法正常执行。在两者均完成查询的结果中,开源产品与 ByteHouse 查询时间相差 15.7 倍,其中Q53、Q63、Q82 等语句的查询效率相差 200 倍左右。
针对TPC-DS 100G 数据集,涉及到前面的收益相关优化项,包括资源的优化器、 exchange 算子、 runtime filter 以及全局字典等。详细的结果可以在ByteHouse性能白皮中仔细阅览。
- TPCH 100G
针对 TPCH 100 数据集,在经过 TPCH 的标准测试数据集的 22 个查询中,开源产品部分与给予无法正常执行,整体查询周期很长,在两者均完成查询的结果中,开源产品与 ByteHouse 的查询时间相差无数倍,其中Q3、Q5、 Q7 等语句的查询效率相差 100 倍以上。相关 TPCH 相关的收益优化项包含优化器 exchange、 runtime filter以及前面提到的并行化重构和全局字典等。
- SSB Flat 100G 以及Standard SSB
公布的完整的SSB 测试结果,不仅是 13 条针对宽表的测试,还包另外 13 条在星状模型场景下的进行多表关联的测试。
首先从 13 条宽表查询的结果来看, SSD 宽表测试的 13 个查询中, ByteHouse 查询性能全面超越开源产品,整体查询性能达到该产品的 3.6 倍多。对其中涉及的收益相关的优化项包括优化器 exchange 全区字典 Zero copy 以及 Uncompressed Cache 。
除了以上的宽表查询之外,针对标准的 SSB 多表关联的查询,从结果可以看出,在 13 个查询中,开源产品最后 3 个查询因为内存问题查询失败,整体查询性能与ByteHouse相差较大,其中涉及的优化项包含优化器exchange、 runtime filter、全局字典等。
高性能场景之高并发点查
在大数据和实时分析的时代,在很多业务场景,比如广告等,都对OLAP点查能力有强需求。高并发点查对于商业决策、市场分析、用户行为研究场景中的使用体验和查询精准度都起到重要作用。
如果OLAP系统的高并发点查能力不足,就会存在响应时间慢等情况,在技术层面则体现为索引计算繁重、点查读放大严重、执行链路冗长、锁竞争激烈等问题,ByteHouse通过采用短链路的执行方式、建立unique table 点查索引、提升读链路效率等方式进行优化
高并发瓶颈
- 索引计算繁重:ByteHouse在做索引计算时会引入很多表达式计算,导致比较高的CPU消耗,因此优化索引计算开销是提升QPS水平的关键。
- 点查读放大严重:在下图中有很多decompress函数,对于通用的OLAP引擎,读一行数据通常也需要读取大量的block,再将block解压反序列化成内存格式,需要消耗大量的CPU资源。在高并发的场景下,点查读放大的问题更加突出。
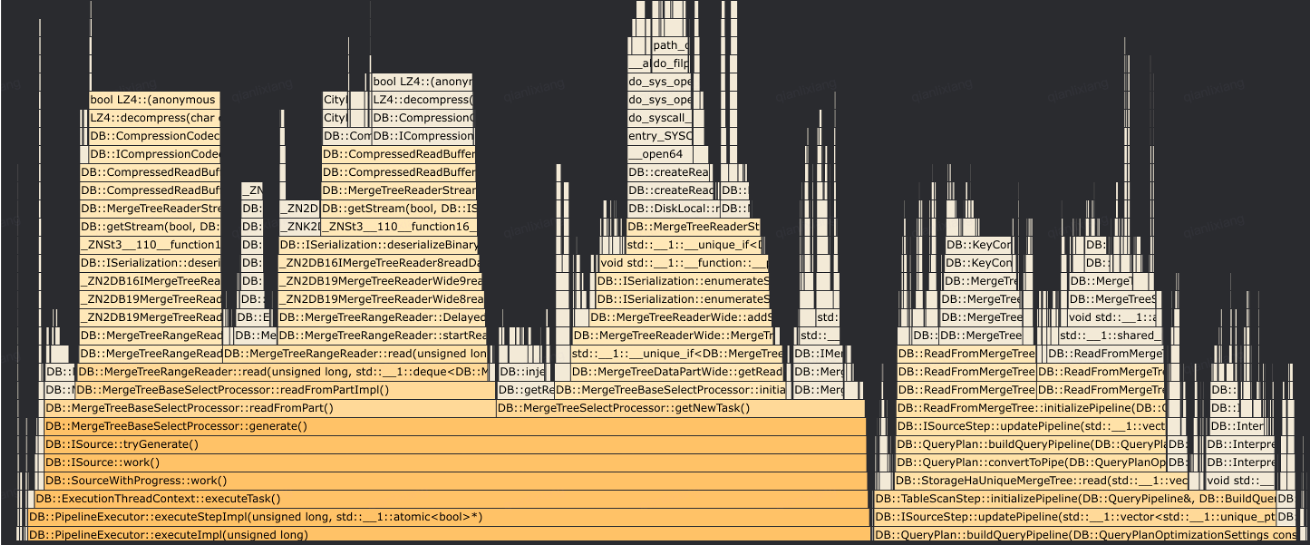
- 执行链路冗长:ByteHouse自研优化器的规则,众多的 RBO 规则和CBO优化,导致执行链路非常长。
- 锁竞争激烈:由于较长的执行链路中间有很多共享变量,在多线程环境下需要加锁保护,导致锁竞争激烈。
优化手段
优化一:更简洁的短路执行计划
首先,我们为高并发的点查场景设计一套更简洁的短路执行计划。
当执行计划分析完后,如果query是一个点查场景,ByteHouse可以为其生成一个特定的优化的规则。
简化后只保留简单的几个规则,例如:
- 把limit下推,删除冗余的条件并精简plan,将谓词表达式下推到存储层。
普通的query会生成执行计划,分为两个阶段:阶段一,segment 1下发到各个节点去执行,阶段二 segment 0 汇聚各个节点的数据,这种计划会带来大量的 plan 序列化反序列化,网络传输、数据汇总等一系列的开销;而在点查场景中,可能存在点查只会命中一条数据,那么这一条数据势必就会存在于某一个节点上,那么没有必要把计划发送到各个节点。为此,我们做了如下优化:
- 将两阶段的计划合并成一个segment 计划
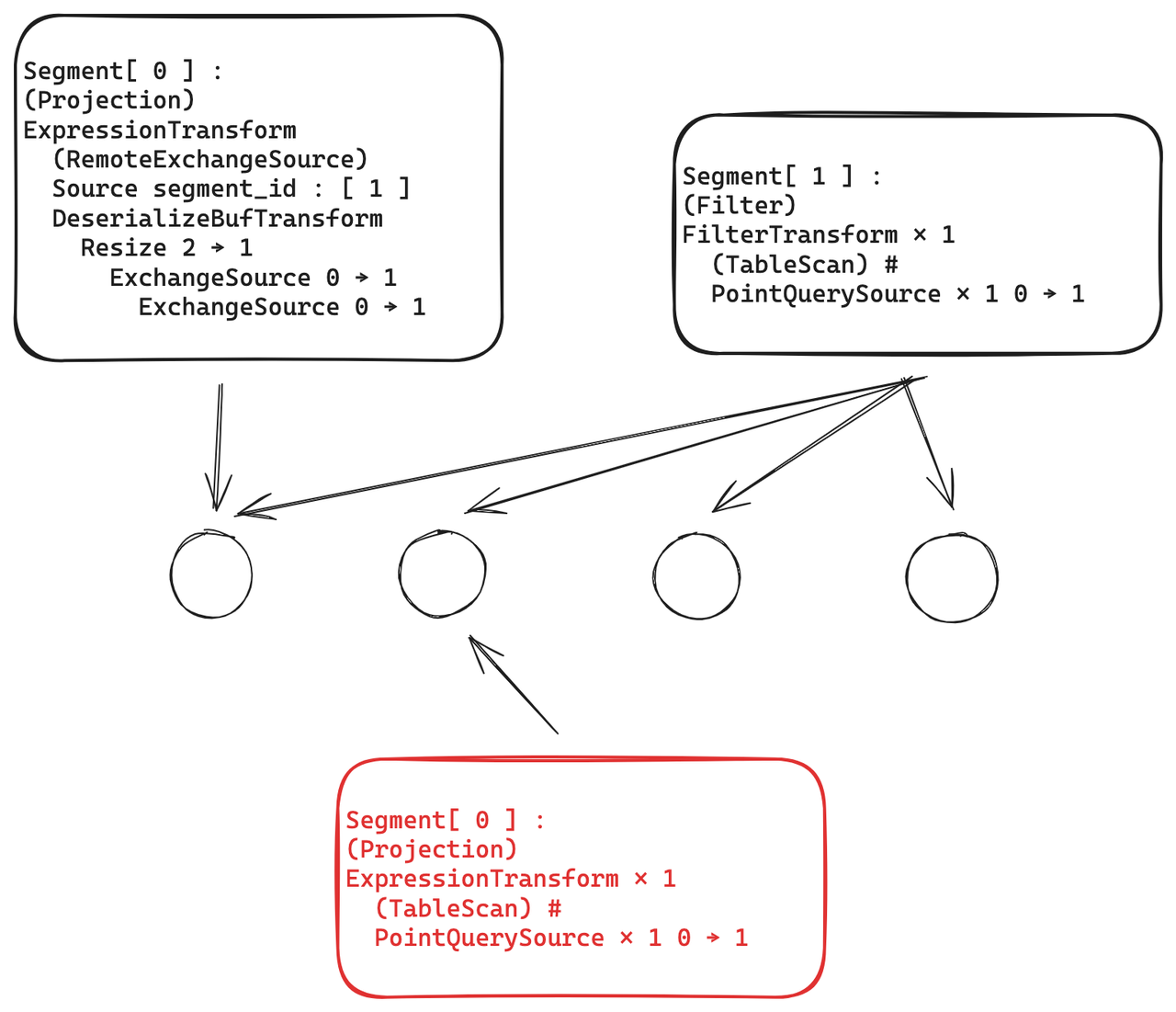
- ByteHouse在生成完计划之后,会计算出计划命中的节点,并将节点裁掉,将精简的执行计划发送到特定的节点。
优化二:基于 unique table 点查索引
完成执行计划上的优化之后,在真正做查询的时候,ByteHouse引入了一个基于unique table 的点查索引。
该索引为一个内存的结构(KV结构),k是检查中所用到的谓词值,value是行号,直接访问点查索引就能得到对应的行号或者对应的mark。点查索引可以和行存复用,通过索引得到行号的集合后可以直接访问对应行的数据。
优化三:高效的读链路优化
读链路中首先会进行分区的裁剪,和之前主键过滤一样,分区的裁剪里面有大量的表达式的计算,为此ByteHouse做了更轻量的分区的裁剪,并基于分区裁剪和 unique index 的过滤的结果得到 part 和 mark 的值。针对 limit 可以下推的场景,ByteHouse在 mark 的粒度上建了一个 Min-Max 的索引,然后按照 Min-Max 索引做排序就可以通过 limit 值来判断出真正需要读的 mark 是哪些。这样就可以只读少量的mark,不必要读所有筛选出来的 mark 再做过滤。
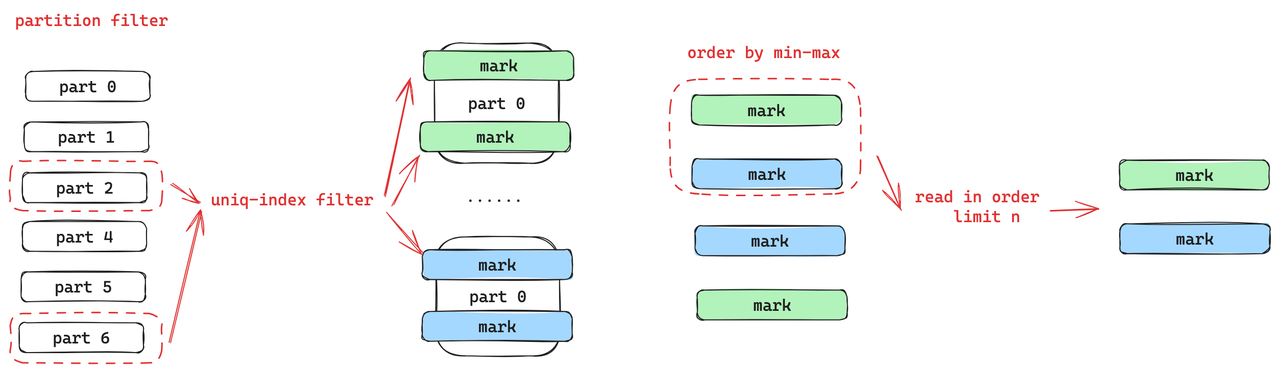
读链路里面存在两种格式,一种是列存的格式,一种是行存的格式。
- ByteHouse为列存的格式的底层做了一层 bucket cache,在多线程访问mark 数据时能有效减少锁竞争。
- 在访问行存的时候,ByteHouse在行存的下一层做了一个基于行存的 cache,这会大大提高行存查询的效率。
- 最后一个优化点是新语法prepared statement,它可以用来优化parser解析时间和queryplan 生成的时间。比如,ByteHouse会定义 prepared statement,然后在需要定义的query 里面去指定查询的参数模板。当真正运行的时候,就可以通过 prepare statement 填充上它的值并做查询。有了该查询模板之后,parser解析时间和queryplan 生成的时间基本上可以被消除。
性能表现
- 测试环境:32core/128G/1T SSD
- 数据:100000000行数据
测试场景为 unique 表,点查query为用 unique 表的 key 为谓词。下图中展示了每个优化阶段完成后对应的 QPS 变化,baseline 表示的是未进行任何优化时候的表现
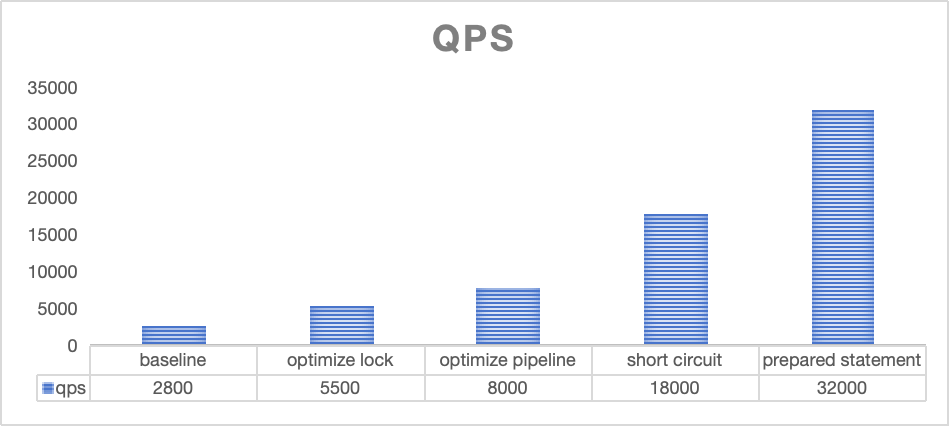
- 当做完锁优化、pipeline 优化之后,性能达到 5, 500- 8, 000 QPS。
- 当引入了比较精简的执行计划之后,性能达到 18, 000 的QPS。
- 再将AST 解析和plan build 时间去掉之后,ByteHouse能获得32000 QPS 的水平。
结语
不仅仅是技术层面的性能提升,ByteHouse在实时数仓、复杂查询、宽表查询、人群圈选、行为分析等八大场景中,也将高性能落地。其中,在人群圈选场景中,ByteHouse可以满足大规模数据的分析和查询需求,并具有一套用于解决集合的交并补计算的定制模型BitEngine,该模型能解决实时分析场景中的性能提升问题。相比于普通和Array或者用户表方式,BitEngine在查询速度上有10-50倍提升,解决了人群圈选中误差大、实时性不强以及存储成本高的痛点。
通过一系列技术优化手段,ByteHouse实现性能进一步提升,缩短查询执行时间、优化资源利用,能应对更复杂的查询场景,为用户提供更流程的数据分析体验。不仅仅是探索性能突破,ByteHouse也在持续拓展产品一体化、易用性、生态兼容性,为业务带来更多的价值,推动各行各业数字化转型。
#活动推荐#
限额50位 ByteHouse性能挑战赛正式开启!
● 活动时间:3月26日-4月26日截止
● 如果你对OLAP性能调优感兴趣,如果你正在进行数据库选型,如果你遇到数据库性能瓶颈......
⭐️参与性能复现和挑战,即有机会获取airpods、智能手表、机械键盘等大奖
添加小助手,回复“性能挑战赛”立即报名



