从MySQL到ByteHouse,抖音精准推荐存储架构重构解读
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
抖音依靠自身推荐系统为用户推送可能感兴趣的视频内容,其中兴趣圈层是推荐的重要能力,通过理解核心用户的偏好特征,判断两者偏好的相似性,从而构建同类用户的兴趣圈层,实现精准推荐。
以往的兴趣圈层往往依赖单一的维度或标签,比如内容类型、时长、地理特征等,难以揭示用户兴趣的底层逻辑。例如,重庆美女小姐姐吃播视频、二次元古风舞蹈视频,表面上标签类型可能完全不一样,但深度分析后发现喜欢两个视频的是同一个类型的人,并把他们划分在同一个兴趣圈层中。
要搭建这样一套兴趣圈层平台,不仅需要算法策略,对底层数据存储架构也是一大挑战。抖音每日新增的数据量庞大、业务标签五花八门,更需要满足业务人员对复杂查询的实时性诉求。之前技术团队采用MySQL作为存储架构,作为一种行式存储的数据库,MySQL对于大量数据的处理效率较低。如果要在MySQL上查询上亿级别的数据,可能需要更高配置的硬件,甚至可能需要采用分片、读写分离等策略来提升性能,这将导致硬件成本显著提高。
因此,技术团队逐渐将兴趣平台基于ByteHouse进行重构。ByteHouse是一款OLAP引擎,具备查询效率高的特点,在硬件需求上相对较低,且具有良好的水平扩展性,如果数据量进一步增长,可以通过增加服务器数量来提升处理能力。本文将从兴趣圈层建设难点及构建方案等角度拆解如何基于OLAP引擎来搭建兴趣圈层平台。
兴趣圈层平台介绍
兴趣圈层指兴趣爱好相同的人组成的群体,兴趣圈层可以从用户视角更深入的理解短视频作者和内容,挖掘出该圈层作者核心用户群体的共同兴趣点和典型偏好特征,作为划分作者的重要标签,应用在内容分发、垂类运营、数据分析、战略规划等场景中输出价值。兴趣圈层以簇(cluster)的形式存在,通过机器模型聚类而成,每个簇包含一位种子作者及多位与之关联作者。
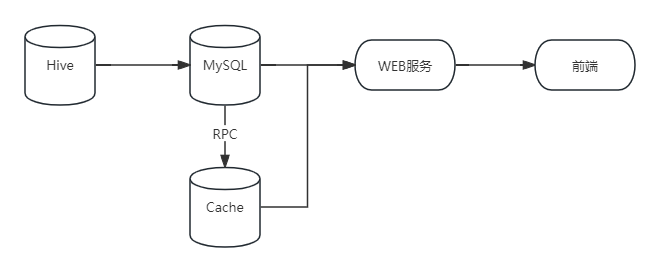
圈层生产流程:数仓的天级 Hive 表以定时任务的方式将 Hive 表内数据按照分区导入 RDS(MySQL) 数据库,同时预计算脚本每天会定时将 RDS 内的数据按需写入缓存(如圈层信息等通用查询)或写回RDS(如圈层的父节点信息等核心数据),生产流程成功会标记在缓存代表今日数据有效,反之报警通知相关负责人。
圈层查询流程:用户操作查询,前端发送查询场景数据请求,服务端接收到请求后读取相应的缓存、数据库表及分区,对数据进行组装,最终返回给用户。
主要问题
数据膨胀
日更版本导致数据量级膨胀,圈层基础信息表日增万级数据,圈层作者信息表日增百万数据,圈层用户信息表日增千万条左右数据,已经达到 MySQL 秒级千万级查询的性能瓶颈。
查询效率已无法满足需求,即使有缓存加速减少联表查询,单表查询的效率在到10s以上,其中圈层理解(圈层用户信息表)进入页面的时间超过15s,一定程度影响业务使用体验。之前做了很多包括索引优化、查询优化、缓存优化、表结构优化,但是单次对表更新列/新增修改索引的时间已经超过2天,优化成本也逐渐升高。
历史架构过薄,难以承接较复杂圈选能力
从现状来看,当前圈层架构简单且为区分查询场景,与数据库直接交互且仅支持简单的同步查询,当业务需要较复杂的泛化圈选条件时,需要用户在平台等待超过15s。
从未来规划,目前以 RDS 为存储的同步查询架构已无法支持需要关联多个表和特征的复杂条件查询的业务场景。
业务特征膨胀
标签特征膨胀,当前圈层有越来越多的标签描述,由于不同业务方会通过不同视角理解圈层,如垂类标签/圈层关键词描述/圈层质量分类/圈层画风等,目前圈层信息实体特征达到几十种,预计圈层属性标签仍会膨胀。
一站式圈选泛化目标作者诉求增多,当前作者只包含基础信息,业务方希望基于圈层和其他基础作者特征,如粉丝数,作者质量,活跃度等以满足对作者的流量定向策略等需求,以满足复杂条件多维度的筛选排序功能。
基于 ByteHouse 重构兴趣圈层平台
RDS 作为行式数据库更适合单点事务分析工作显然不符合当前平台诉求,我们分别从查询场景、查询性能、存储成本、迁移成本对存储选型。
查询场景
- 圈层信息由模型生产,按时间分区批量导入,不存在临时导入,为 append only 场景。
- 圈层特征多,业务方按照诉求对和自身业务相关的特征进行筛选,列式存储比行式存储更合适。
- 圈层主要以分析统计为主,不强需求事务处理,面向 OLAP 业务。
查询性能
- MySQL 对于多列复杂的条件查询时,查询性能很难优化,需要通过强依赖 redis 缓存加速,否则平台功能不可用。
- 圈层场景通常限制在局部数据中聚合分析,如计算圈层id位于集合内的关键词频率统计,若该集合范围过大索引失效会被劣化为全表扫描。
详细场景测试
重构前后存储对比
| MySQL | ByteHouse |
|---|---|
| 关系型数据库,支持事务 | 分布式列数据库,支持最终事务 |
| 行存储模式,适合尽量少的读取需要的行数据 | 列存储模式,且数据压缩比高,对大批量数据读取有着天然优势 |
| 单进程多线程服务,单条业务请求查询无法有效利用到多个 CPU 资源 | 多核并行 |
| 面向 OLTP 业务 | 面向 OLAP 业务 |
具体场景对比
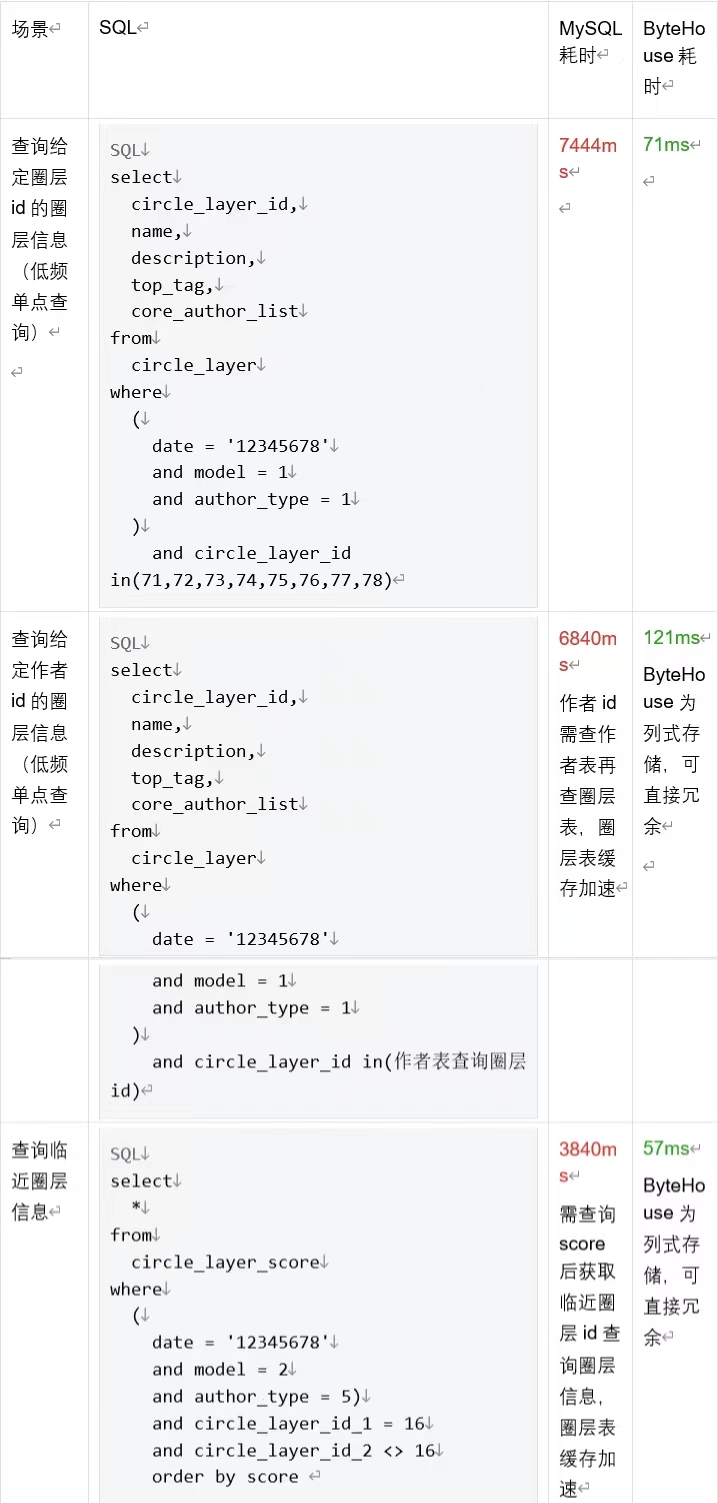
数据管理信息查询场景:
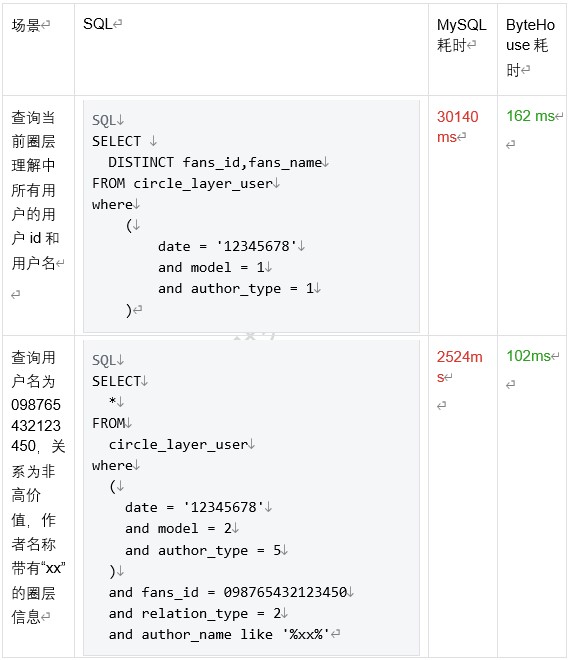
应用工具分析场景:
总结
综上可以看到,基于 ByteHouse 替换 MySQL 重构抖音兴趣圈层平台后,不同几个典型场景的查询效率平均提升了 100 倍左右,大大提升了用户体验。由于 ByteHouse 出色的查询性能和良好的数据压缩比,中等资源的服务器就能很好的满足需求,这也降低了综合硬件成本。此外,ByteHouse 具有良好的水平扩展能力,如果数据量进一步增长,也可以便捷的通过增加服务器数量来提升分析能力。
点击跳转火山引擎ByteHouse了解更多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号