火山引擎 ByteHouse:只需 2 个方法,增强 ClickHouse 数据导入能力
 本篇文章来源于 ByteHouse 产品专家在火山引擎数智平台(VeDI)主办的“数智化转型背景下的火山引擎大数据技术揭秘”线下 Meeup 的演讲,将从 ByteHouse 数据库架构演进、增强 HaKafka 引擎实现方案、增强 Materialzed MySQL 实现方案、案例实践和未来展望四个部分展开分享。
本篇文章来源于 ByteHouse 产品专家在火山引擎数智平台(VeDI)主办的“数智化转型背景下的火山引擎大数据技术揭秘”线下 Meeup 的演讲,将从 ByteHouse 数据库架构演进、增强 HaKafka 引擎实现方案、增强 Materialzed MySQL 实现方案、案例实践和未来展望四个部分展开分享。
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
作为企业数字化建设的必备要素,易用的数据引擎能帮助企业提升数据使用效率,更好提升数据应用价值,夯实数字化建设基础。
数据导入是衡量 OLAP 引擎性能及易用性的重要标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。作为一款 OLAP 引擎,火山引擎云原生数据仓库 ByteHouse 源于开源 ClickHouse,在字节跳动多年打磨下,提供更丰富的能力和更强性能,能为用户带来极速分析体验,支撑实时数据分析和海量离线数据分析,具备便捷的弹性扩缩容能力,极致的分析性能和丰富的企业级特性。
随着 ByteHouse 内外部用户规模不断扩大, 越来越多用户对数据导入提出更高的要求,这也为 ByteHouse 的数据导入能力带来了更大的挑战。
本篇文章来源于 ByteHouse 产品专家在火山引擎数智平台(VeDI)主办的“数智化转型背景下的火山引擎大数据技术揭秘”线下 Meeup 的演讲,将从 ByteHouse 数据库架构演进、增强 HaKafka 引擎实现方案、增强 Materialzed MySQL 实现方案、案例实践和未来展望四个部分展开分享。
ByteHouse 数据库的架构演进
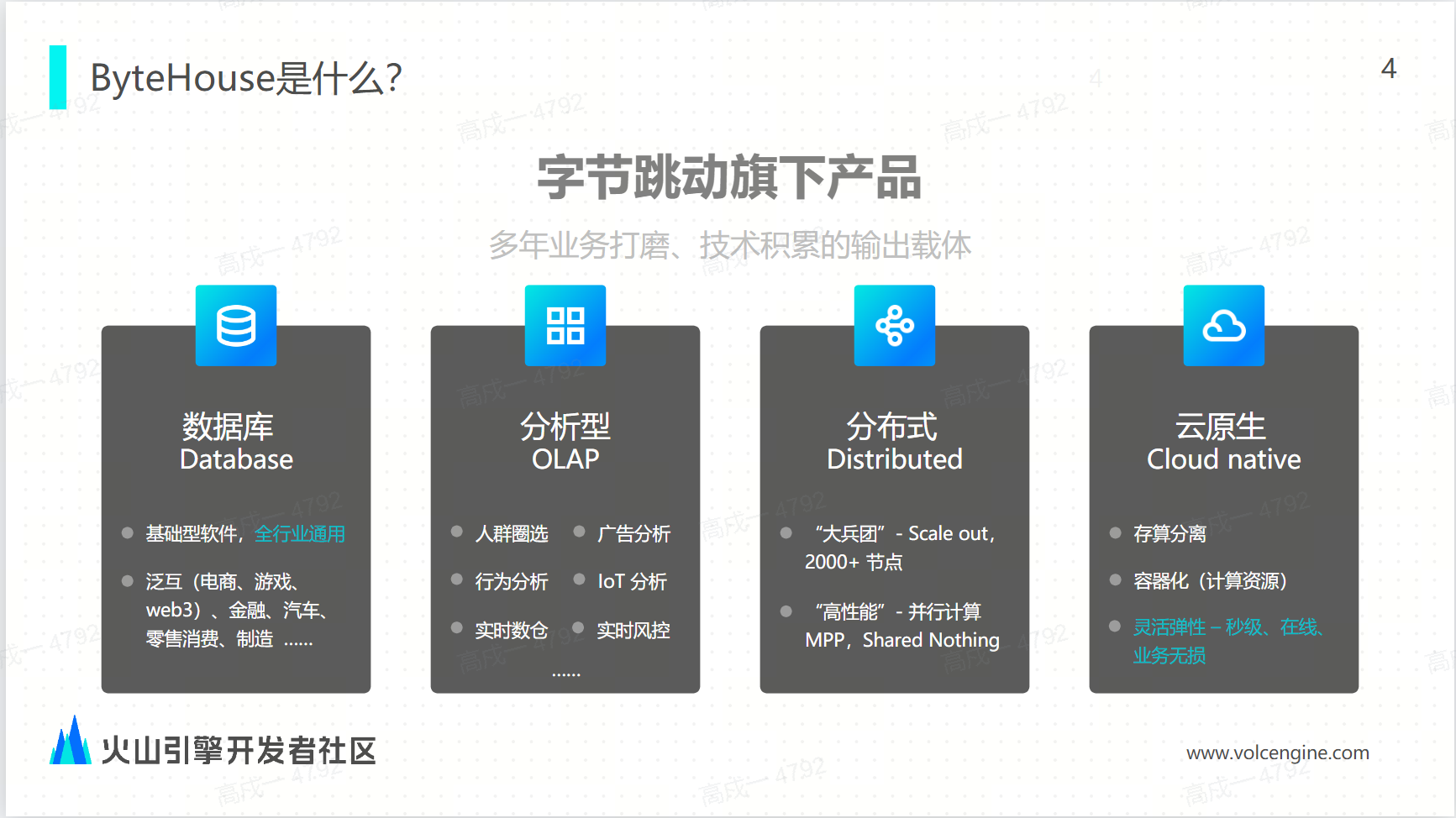
作为一款分析型数据库,ByteHouse 已经应用在互联网、金融、汽车领域,帮助企业实现人群洞察、行为分析、 IOT 风控等场景的实时分析。
ByteHouse 的演进
-
从 2017 年开始,字节内部的整体数据量不断上涨,为了支撑实时分析的业务,字节内部开始了对各种数据库的选型。经过多次实验,在实时分析版块,字节内部决定开始试水 ClickHouse。
-
2018 年到 2019 年,字节内部的 ClickHouse 业务从单一业务,逐步发展到了多个不同业务,适用到更多的场景,包括 BI 分析、A/B 测试、模型预估等。
-
在上述这些业务场景的不断实践之下,研发团队基于原生 ClickHouse 做了大量的优化,同时又开发了非常多的特性。
-
2020 年, ByteHouse 正式在字节跳动内部立项,2021 年通过火山引擎对外服务。
-
截止 2022 年 3 月,ByteHouse 在字节内部总节点数达到 18000 个,而单一集群的最大规模是 2400 个节点。
ByteHouse 的架构
ByteHouse 架构分为分布式架构和云原生架构两种。分布式架构的主要特点就是单集群可以支持 2000 多个节点的“大兵团”;通过分布式的并行计算体现的高性能,能够充分利用每个节点的计算和存储资源;云原生实现了存算分离,计算资源通过容器化进行弹性和秒级的扩容,这对业务是无感知的。
从分布式架构来看,ByteHouse 具备 MPP 1.0 特点:
-
存算一体:通过本地存储能够保证它极致的这种查询性能。
-
自研的表引擎:包含 HaMergeTree 和 HaUniqueMergeTree。
-
在社区 RBO 优化器的基础上增强 RBO 加 CBO 的结合的查询优化,并基于 CBO 的分布式计划能够在集群模式下计算全局最优的查询计划。
-
支持数据的冷热分存,同时兼顾性能和成本。
-
增强关键的数据类型,从而优化查询性能。
-
通过统一的管控面提供可视化的管理查询和运维,从内到外给用户提供优质的使用体验。
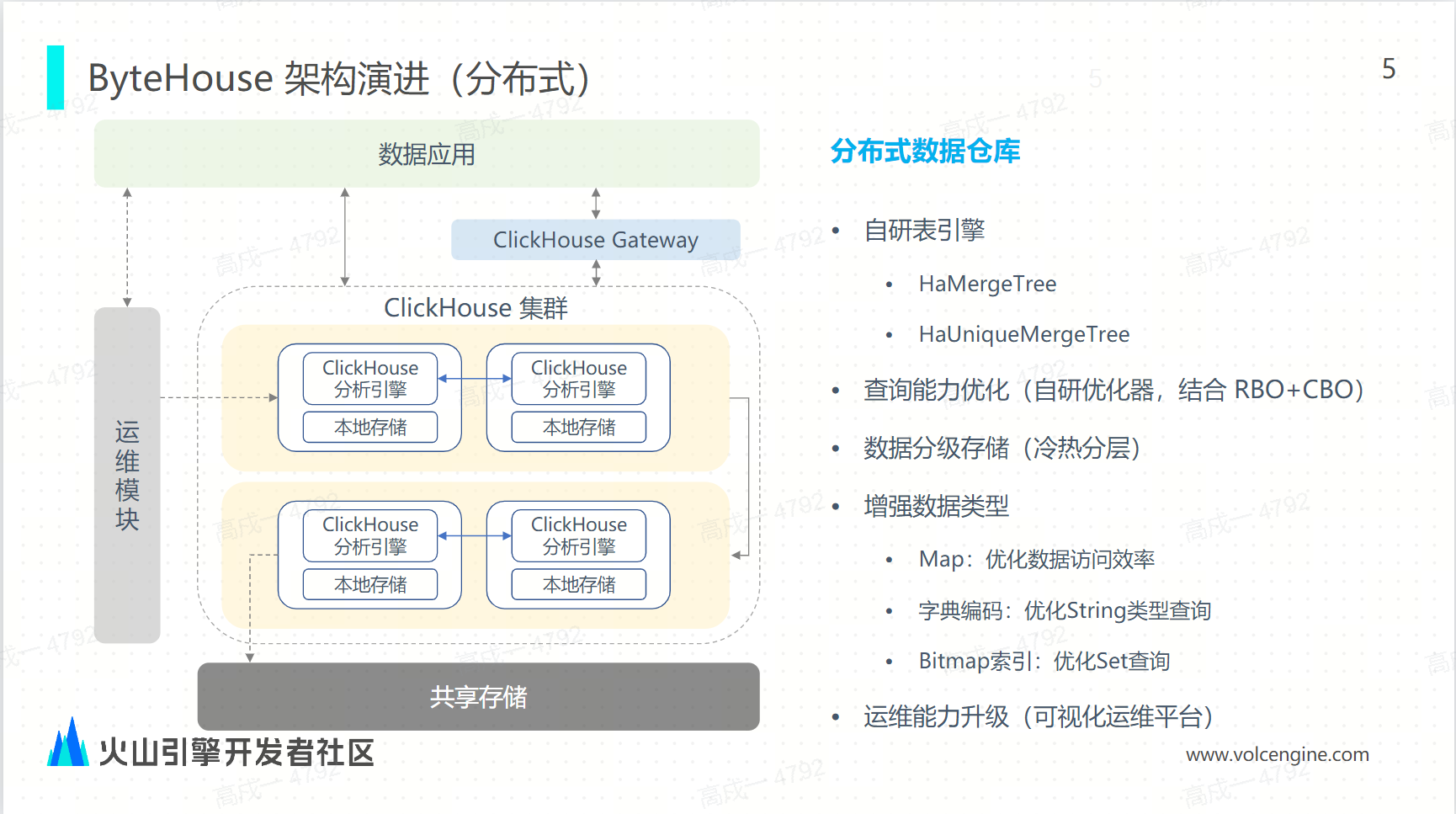
但 MPP 1.0 存在资源隔离、扩容等痛点,由此演进到云原生架构,即 MPP 2.0:其中存算分离通过结合 shared-everything 存储和 shared-nothing 计算层,避免了传统 MPP 架构中数据重新分配 (re-sharding) 的问题。
好处在于:
-
更好地实现资源隔离。每个用户不同的计算都提交到不同的计算组,并进行计算资源和存储资源的扩容,再结合按量计费的计费策略可以降低用户使用成本。
-
底层存储既支持 HDFS,也支持 S3 对象存储,能够让 ByteHouse 实现真正的云原生。

ByteHouse 技术优势
在增强型数据导入场景中,ByteHouse 核心优势体现在自研表引擎:
-
在社区版的基础上,ByteHouse 对表引擎做了进一步增强,使其能够实现开源的 ClickHouse 所做不到的场景。
-
高可用引擎,相比社区高可用引擎,可以支持表的数量更多,集群的规模更大,稳定性会更高。
-
实时数据引擎,相比社区实时数据引擎,消费能力更强,支持 at least once 的语义,排除单点写入的性能故障。
-
Unique 引擎,相比社区 Unique 引擎,ByteHouse 没有更新延迟问题,能够实现真正实时的 upsert。
-
Bitmap 引擎,在特定的场景比如用户圈选圈群的场景中支持大量的交并补操作,能够使整体的性能提升 10 - 50 倍以上。

这里具体再介绍一下 ByteHouse 自研引擎的优势——与导入密切相关的表引擎。
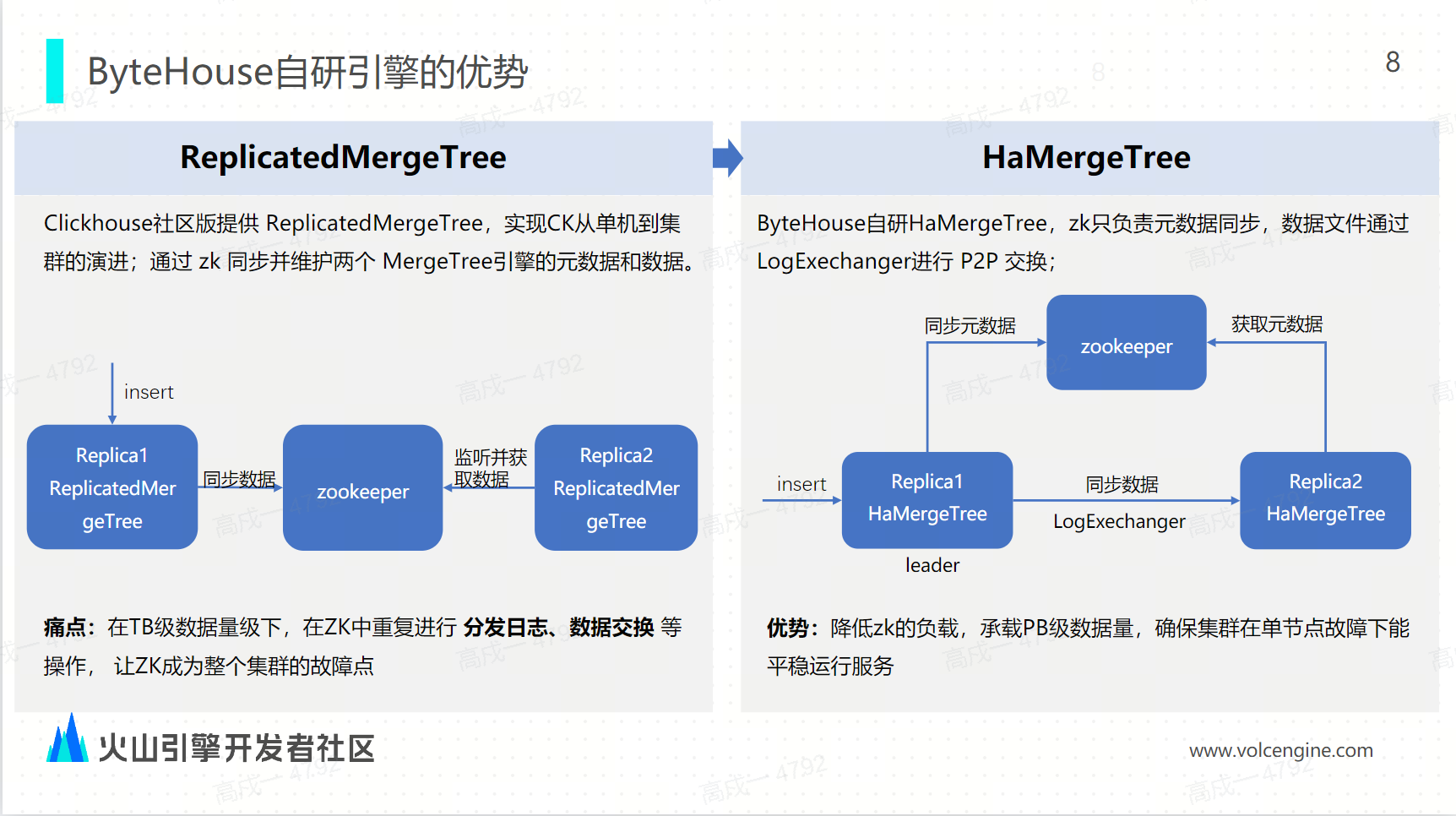
首先,ByteHouse 提供的 HaMergeTree 方案能够降低 ZK 负载,提升可承载的数据量级。
-
ClickHouse 社区版本:社区提供的 ReplicatedMergeTree 表引擎让 ClickHouse 实现了从单机到集群的演进,通过 ZK 节点来同步并维护两个 MergeTree 之间的元数据和数据。痛点在于,在 TB 级的数据量级之下, ZK 重复地进行分发日志和数据交换等操作,极大地增加了 ZK 的压力,使 ZK 成为整个集群的故障点。
-
ByteHouse 自研 HaMergeTree: 将元数据的同步和数据的同步解耦,ZK 只负责元数据的同步,而数据的同步是通过 LogExchange 来实现,在两个 MergeTree 之间进行对等拷贝。优势在于,降低了 ZK 的负载,即使是承载 PB 级的数据量,集群也能够平稳地运行。
其次,ByteHouse 提供的 HaMergeTree 方案能平衡读写性能。
-
ClickHouse 社区版本:提供 ReplacingMerge Tree 实现了对唯一键的支持;使用 Merge-on-read 的实现逻辑,在不同批次的数据中包含着相同的 key ,需要在读时做合并,让相同的 key 返回最新的版本。痛点在于,数据存在延迟、滞后,降低读的性能。
-
ByteHouse 自研的 HaUniqueMergeTree:引入了 delete bitmap 的组件在数据插入时即标记删除,然后在数据查询时过滤掉标记删除的数据。优势在于,整体上平衡了读和写的性能,保障了读取时性能一致性。

增强 HaKafka 引擎实现方案
HaKafka 引擎架构介绍
社区版 Kafka 优势:由于社区版 ClickHouse 是一个分布式结构,其数据分布在多个 Shard 上,Kafka 引擎可以在多个 Shard 上去做并发的写入,而在同一个 Shard 内可以启动多线程做并发写入,并具备本地盘的极致的性能读写。
社区版 Kafka 不足:
-
在内外部业务的场景中,会经常遇到唯一键场景,由于社区版本的 Kafka 的 high level 的消费模式(这种模式就决定无法预知数据被写入到哪一个 Shard 上),所以很难满足这一类场景。
-
社区版的 Kafka 引擎没有高可用,即使 ClickHouse 是多副本的,在当一个节点发生宕机时,无法保证另一个节点继续消费。

HaKafka 引擎架构(分布式架构)
保持社区版本两级并发两大的优化点:
-
引入高可用,让备节点处于 stand-by 的状态,一旦主节点发生宕机,备节点立刻继续进行消费。
-
升级为 low-level 的消费模式,当数据写入的时候,相同的 key 会写到相同的 partition 里面,保证在同一个 Shard 下支持的唯一键场景。

ByteHouse 增强 HaKafka 引擎核心功能实现
-
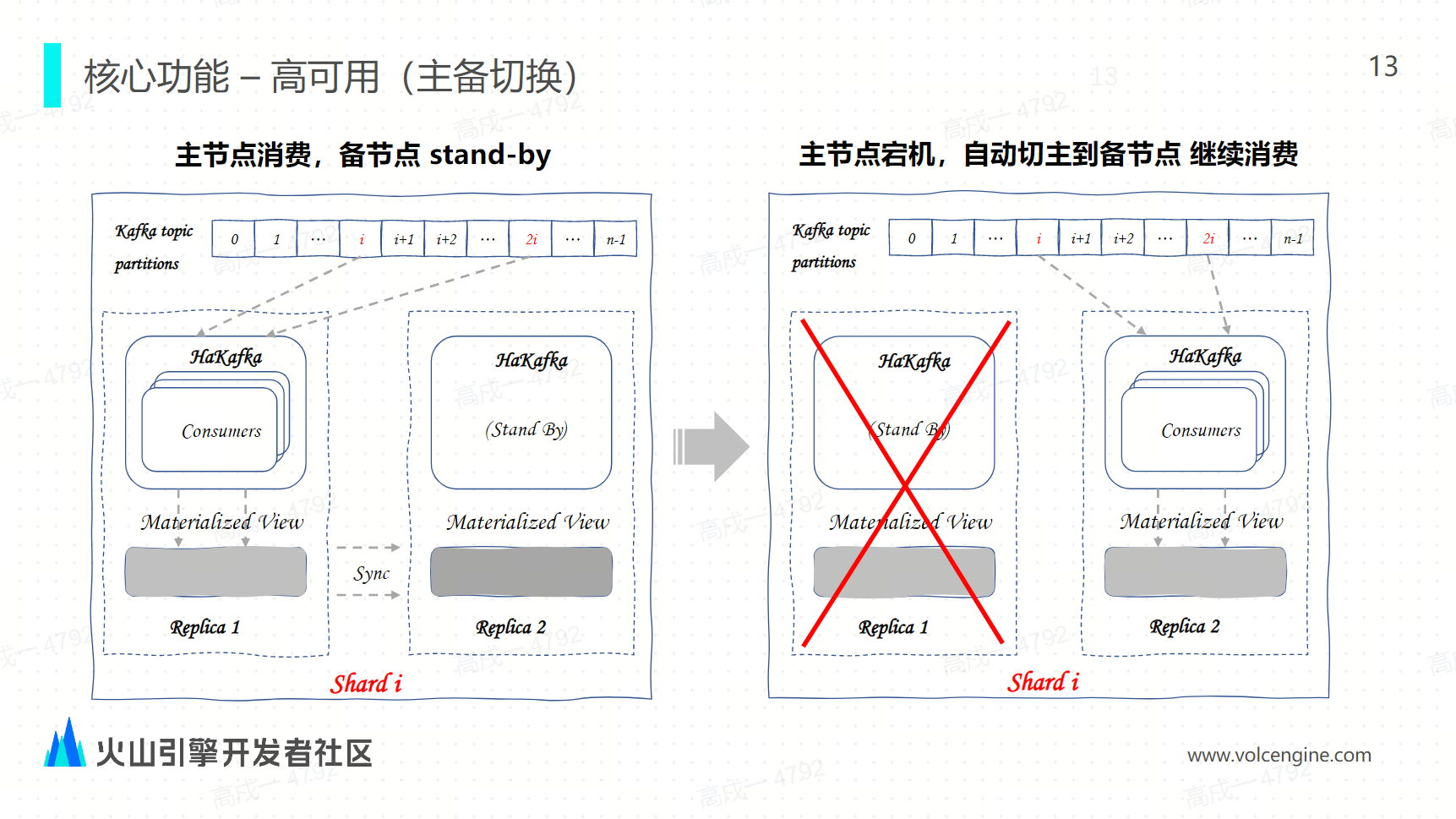
高可用(主备切换)
在备节点上起一个 stand by 的 consumer ,通过 ZK 来进行选组,选到的主节点进行消费,当主节点发生宕机或者无法进行服务时,在秒级之内切换到备节点上,让备节点继续消费。
假设现在 replica 1 因为故障宕机了,无法继续进行消费,那么 Z K 能在秒级内把 replica 2 选为 leader。 replica 2 随即会立即启动相同数量的消费者,启动之后会继续从 replica 1 的消费位置开始继续进行消费。
-
替换节点
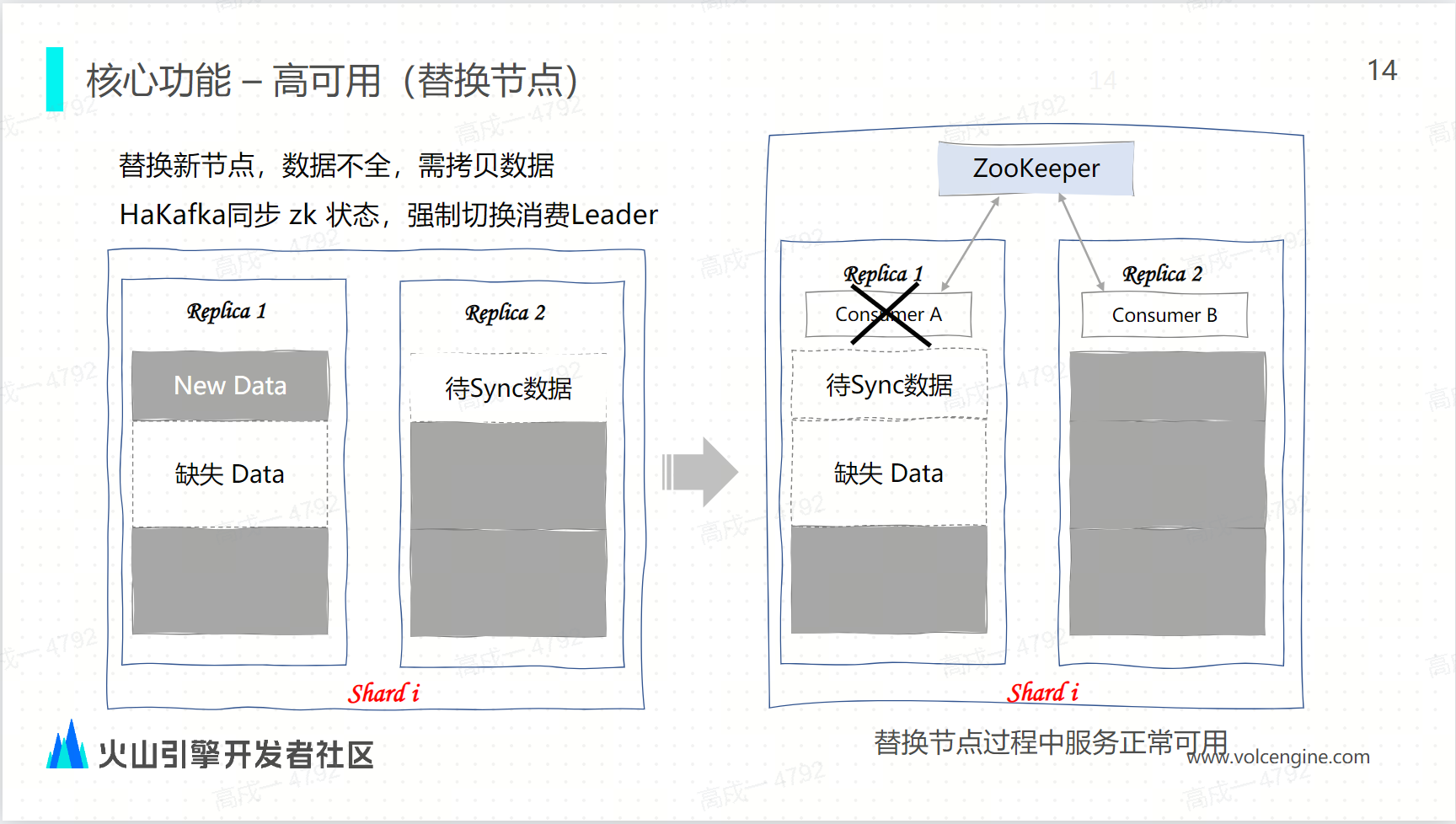
随着集群规模的增大,节点数越来越多的情况下,不可避免地遇到节点故障,这个时候就需要替换节点。
对于分布式架构,替换节点一个重要的操作就是拷贝数据,在拷贝数据的时候意味着新的节点的数据是不全的,如图示,示意图 replica 1 为新替换的节点,还处于数据拷贝的状态,即数据是不全,如果此时实施消费的 leader 起在了 replica 1,就意味着 最新的消费数据会写进 replica 1,但是它缺失一部分旧的数据。
而 replica 2 有旧的数据,它的最新数据还需要从 replica 1 进行拷贝,那这个时候下载之内没有一个副本上面的数据是完整的,所有的节点就不可能对外提供服务。
这时 HaKafka 会做强制限制,如果 replica 1 是一个新节点,且还在拷贝数据的状态,那么就会强制把 leader 切换成 replica 2,由 replica 2 继续去消费最新的数据,replica 1 保持继续拷贝数据,这样可以保证在节点替换的过程中至少有一个副本是能够正常提供服务。
-
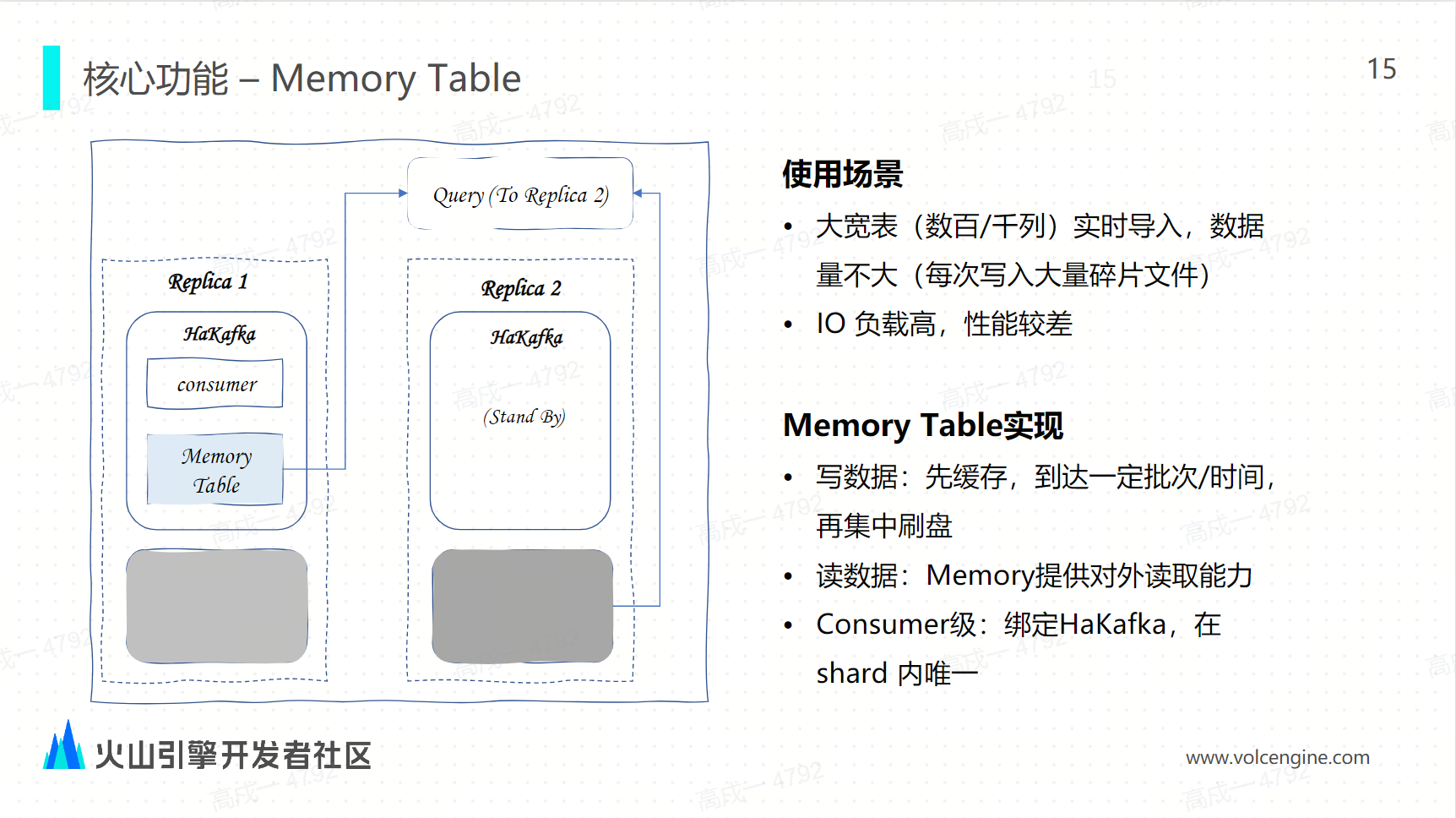
Memory table
不同于社区的 Memory Table 和底层存储绑定,ByteHouse 的 Memory Table 是和 Hakafka 绑定的,主要使用在有百列或者千列的大宽表的场景。
对于 ClickHouse 来说,每一次导入的写的文件的数量和列数是成正比的。如果列很多,但是每批次写入的数据量不大,这时每一次写入就会造成很多的碎片,这对于 IO 的消耗会比较高,写入的性能其实也会比较差。
针对这种情况,考虑使用 Memory Table,让写不直接落盘,每一次写先写到 Memory Table 中,攒到一定的批次或者到达一定的时间之后再一次性刷盘。
当数据写入 Memory Table 之后,就可以对外提供查询服务了,因为 memory table 是跟 Kafka 绑定的,在同一个下的内是唯一的。当查询来了之后,只需要路由到对应的消费节点下 the Memory Table,就能保证了数据查询的一致性。
-
云原生架构增强
分布式架构的痛点在于:
1.节点故障:字节的集群规模较大,每周/每天会遇到节点故障的问题,需要进行节点替换,是一个比较大的负担。
2.读写冲突问题:随着集群的接入的业务越来越多,数据量越来越大的情况下,每一个节点同时承担着查询和写入的操作,之间会有冲突。
3.扩容成本:唯一键的场景对数据分布要求非常严格,扩容在这种场景下很难支持,因为扩容之后 partition 的映射关系发生了变化。
云原生架构优点在于,存算分离、自动扩容、自动容错轻量级的扩缩容等,因为云原生支持事物,让我们可以将消费语义增强到 exactly once。

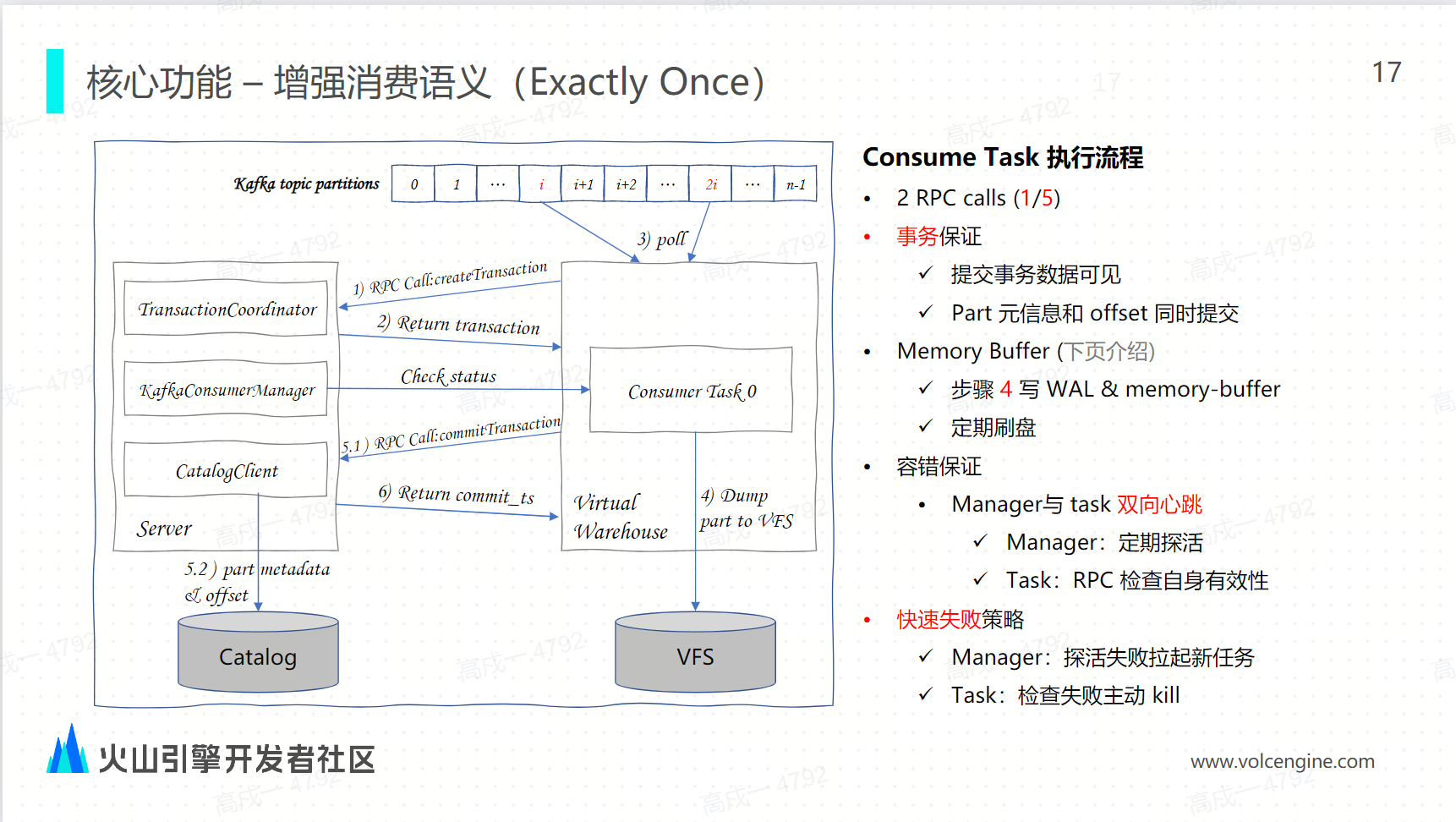
在云原生架构下的 Kafka 引擎是如何通过事务来实现 exactly once:
-
事务保证:因为云原生架构有事务的支持,所以每一轮的消费都需要有事物来保证。因为 Catalog 的元信息和 Catalog 元信息的交互是在 Server 端进行的,所以第一步会通过 RPC 的请求向 Server 端请求创建消费事务,然后客户端创建正常,创建消费事务之后会把 transaction ID 给 consumer, consumer 拿到这种全声音 ID 之后就可以开始正常地消费了。之后它就会从分配到的 partition 里面不停地消费数据,当消费到足够的数据量或者消费满足一定的时间时,它就会把消费的这数据转换为对应的 part 文件并 dump 到存储层。在 dump 之后,数据是不可见的,因为这个时候的 transaction 还没有提交,所以在第五步的时候,还是会通过一个 RPC 的 call 把刚才 dump 的元信息消费的 offseed 提交到 catalog 中。这一步是一个原子性的提交,也是我们的消费语义升级从 at least once 到 exactly once 的一个核心关键点
容错保证:因为 manager 和它具体之间的任务是在不同的节点上的,所以需要有一定的这种容错机制。当前是让 manager 和 task 之间保持一种一个双向的心跳机制来保证,比如说 manager 每隔 10 秒钟会去探活一次,看看当前任务是否正常运行,如果没有在正常运行,它就会重新拉起一个新的 task。而对于 task 来说,它每一次的消费都会有两次的 RPC call 和 Server 端做交互,这两次的 RPC 交互都会向 manager 去校验自身的有效性,如果校验到自己当前是一个失效的状态,它就会把自己 kill 掉,从而保证整个全局的唯一任务的运行。
-
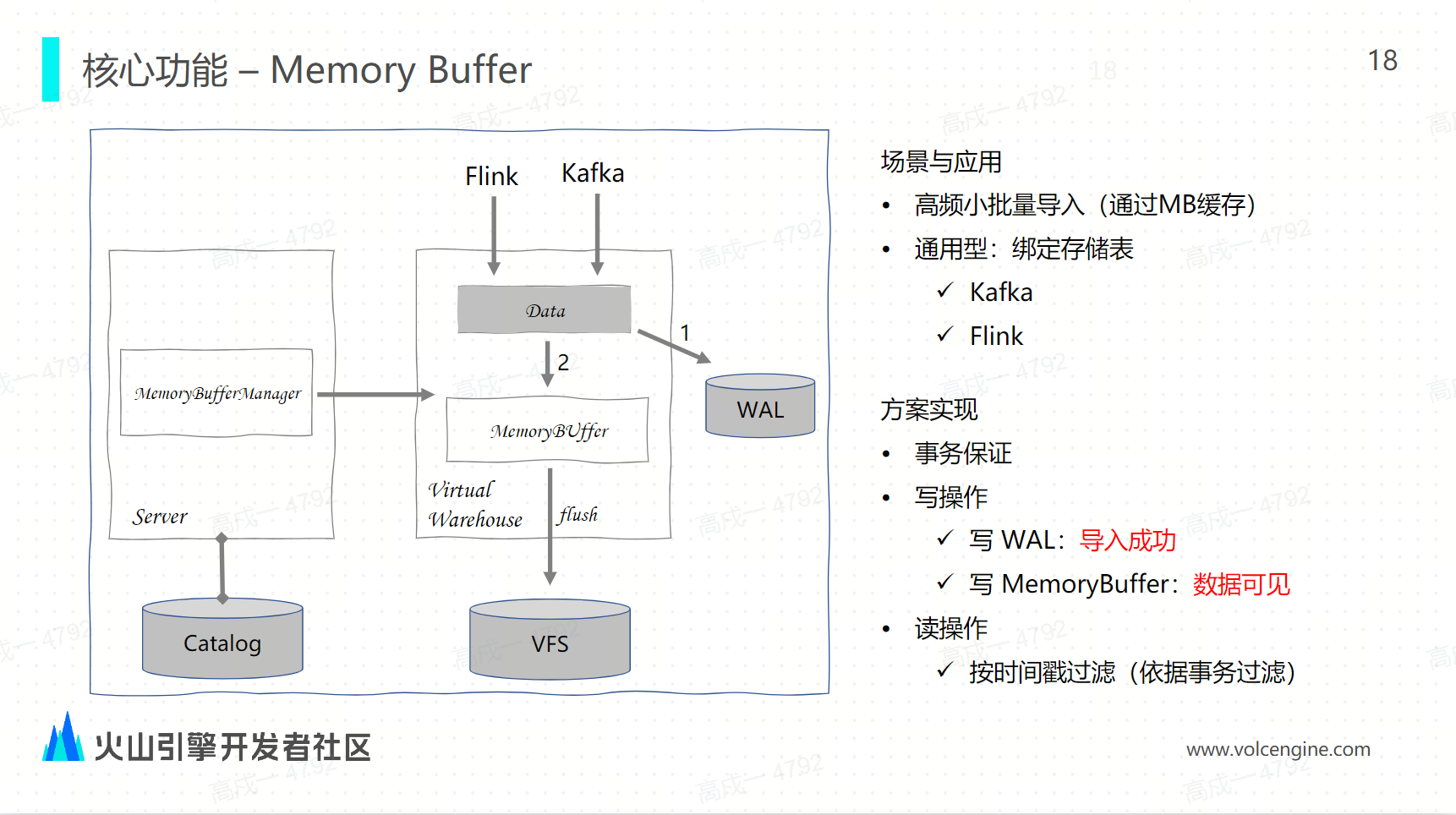
Memory Buffer:与社区相似,Memory Buffer 和底层的存储表绑定。因为都是写入底表的,不仅 Kafka 的导入可以用,Flink 的导入也可以用。memory buffer 的使用场景是高频的小批量的导入场景,因为每一次导入都会写一个 part,不停地写 part 会对集群产生压力。而 ClickHouse 的话,对 ClickHouse 来说 part 越多性能越差,所以使用 memory buffer 来缓存小批量的数据,到达一定批次之后再进行导入。首先需要有一个事务的保证,才能保证导入的完整性和一致性。另外它需要有 WAL,因为首先把数据要先写到 WAL 中,数据写入到 WAL 中之后,就认为导入成功了,因为 WAL 本身也是一个持久化的存储,数据写入 WAL 之后,再将数据写入到 memory buffer。当数据写入了 memory buffer 之后就可以对外提供查询服务。
增强 Materialzed MySQL 实现方案
社区版 Materialzed MySQL 介绍
物化 MySQL 将 MySQL 的表映射到 ClickHouse 中, ClickHouse 服务会读取 binlog,并执行 DDL 和 DML 的请求,实现了这种基于实现了基于 MySQL binlog 的实时 CDC 同步。它的架构很简单,不依赖于数据同步工具,使用自身的资源就能将整个 MySQL 的数据库同步到 ClickHouse 中,并且时效性很好,因为实时同步的延时一般在秒级、毫秒级到秒级之间。
社区版本的这种物化 MySQL 在很大程度上去解决了 MySQL 数据库到 ClickHouse 之间的这种实时同步。在实际业务、实际场景中,遇到不少问题:
1.社区版本的物化 MySQL,它是不支持同步到分布式表,也不支持跳过 DDL,缺乏这些功能就很难将数据库的引擎应用到实际生产中。
2.社区版本的物化 MySQL 不支持在数据同步发生异常时进行辅助,发生异常的时候发起重新同步的命令,它没有同步的日志信息和没有同步的状态信息,缺少了这些信息会导致同步发生异常的时候,很难在短期内把这些任务重新启动。
基于这些问题和痛点, ByteHouse 在社区版本的物化 MySQL 的基础之上做了一些功能增强易用性,降低了运维成本,让数据的同步更加稳定。

ByteHouse 的物化 MySQL 结合了 HaUniqueMergeTree 表引擎:结合这样的表引擎之后,它就能够实现数据的实时去重能力,同时它能够支持分布式的能力,我们通过底层的中间的参数优化,比如 include tables、 exclude tables、 SKIP DDL 等等能够允许用户自定义同步的表的同步范围。
通过下 model 这样的一个参数,能够支持分布式表的同步,然后通过 Rethink 参数的设置支持将额外增加的表启动独立的数据同步任务去进行 CDC 同步,在出现异常的时候,我们也支持跳过这种不支持的 DDL 语句。另外,可以通过系统日志的抓取和展示进行可视化的运维。
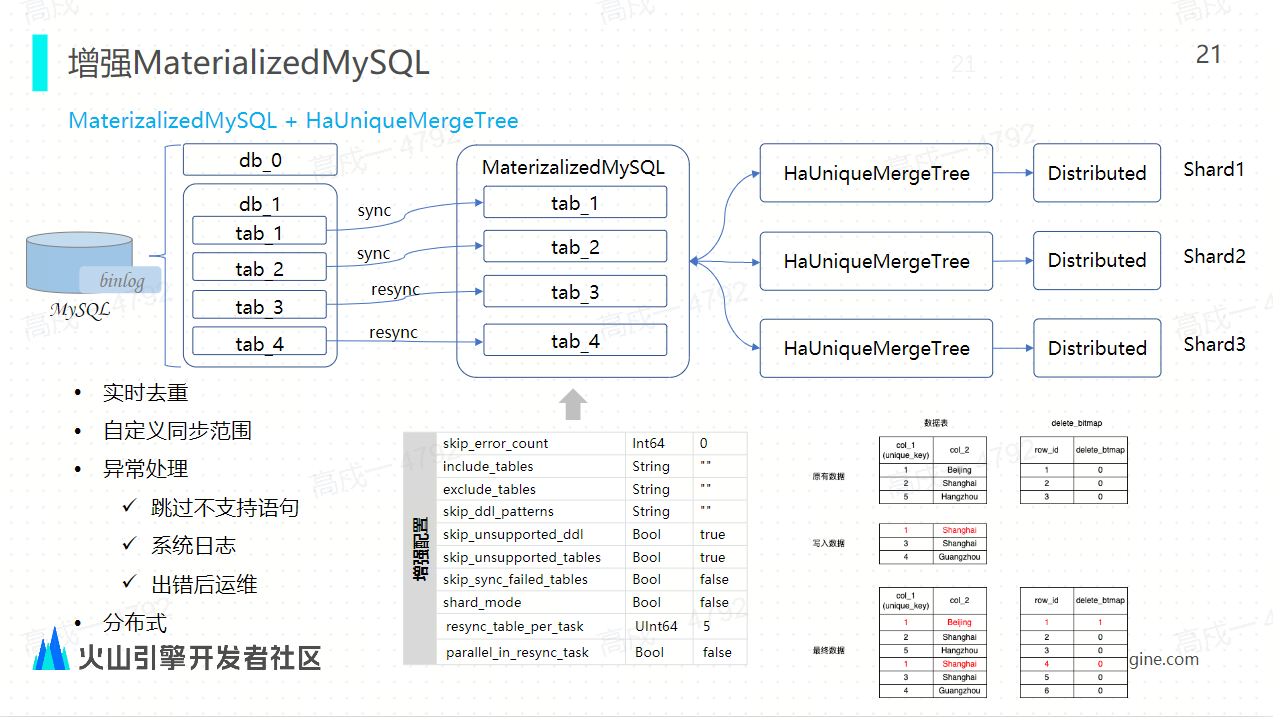
ByteHouse 增强 Materialzed MySQL 核心功能实现
-
实时去重/分布式
社区版的物化 MySQL 使用的是 ReplacingMergeTree,每一个同步任务都会将源端的 MySQL 数据库同步到 ClickHouse 的某一个节点上面,它不支持按照分片逻辑将数据分布到所有的节点,也无法利用 ClickHouse 整个集群的分布式计算和存储能力,所 ByteHouse 的物化 MySQL 支持分布式地同步利用。我们利用 HaUniqueMergeTree 表引擎,将每张表同步到对应的分布式节点上,充分利用集群的这种分布式计算能力,同时通过表引擎的实时 upsert 能力来实现快速地去重。
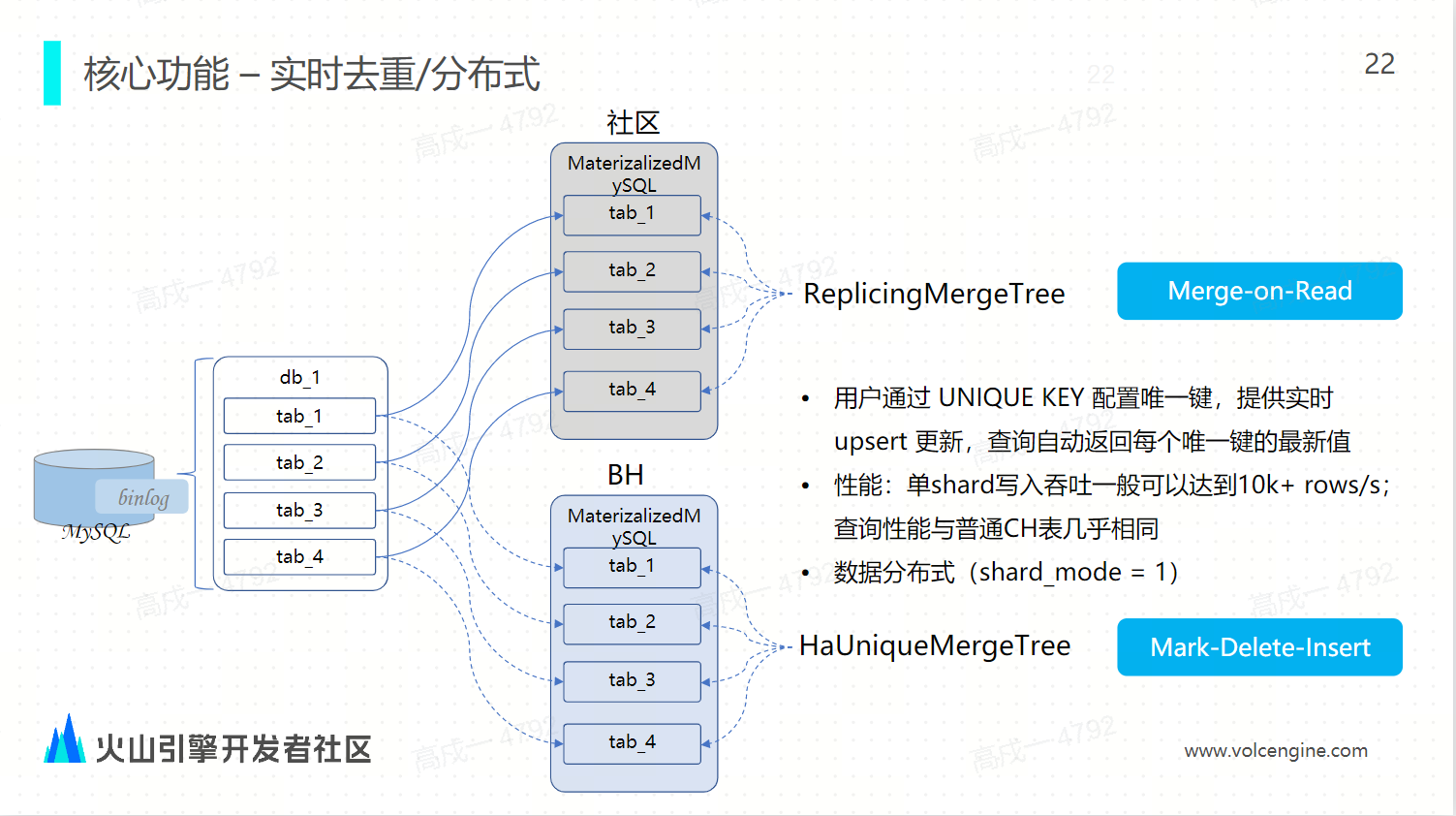
-
异步 Resync
这里有三个对象, SYNC manager 是用来管理主 SYNC 线程和 Resync 线程,然后 SYNC task 和 resync task 各自管理各自的任务。比如说一个 MySQL 的库有 100 张表,我们选了 50 张表进行同步,所以在同步进行过程中,当 think task 同步到 binlog 的 position 位置,比如到 1000 的时候,用户修改了配置之后,它增加了 30 张表。增加 30 张表的时候, SYNC manager 就会启动 Resync task 去同步另外 30 张表,那这个时候 SYNC task 是继续执行的;RESYNC task 会从 position 0 开始,它先做全量的同步,然后再做增量的同步。所以当到达某一个阶段,比如说 sync task 跑到了 position 1500 的时候, resync task 跑到了 position 1490 的时候,这时 SYNC manager 就会去判断两者的误差,这个 position 的误差在一定的阈值之内,在一定阈值之内之后,它会将 SYNC task 停止 1 秒钟,将 RESYNC task 合并到 SYNC task 中。合并成功之后,这 80 张表就都会通过 SYNC task 继续同步,而 RESYNC task 这个任务就会被停止掉。这就是现在 RESYNC task 做了一个能力实现。
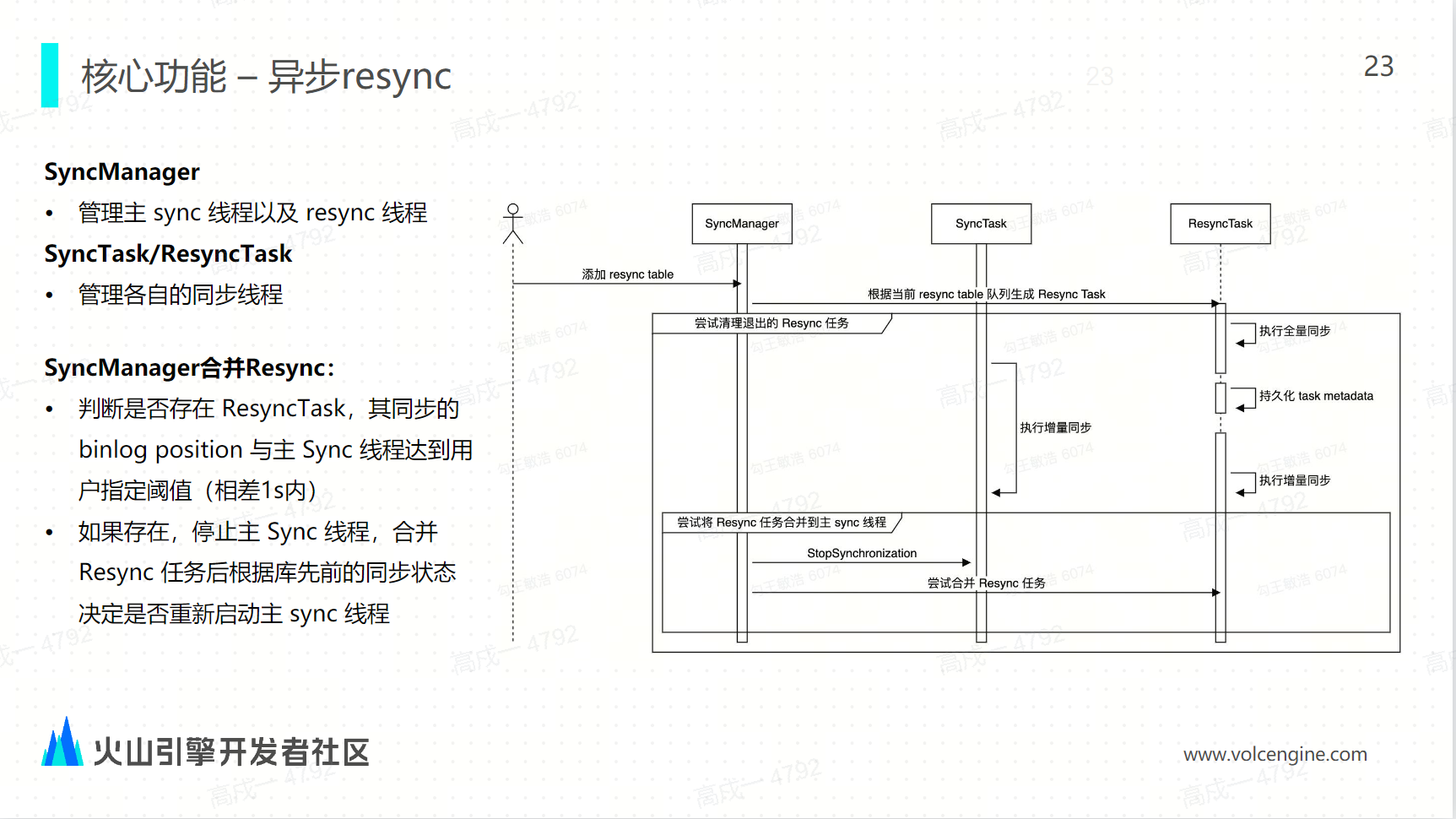
-
可视化运维
通过可视化的任务监控和任务启停异常的重启任务告警这些方式实现了物化 MySQL 的可视化易用性的极大提升。
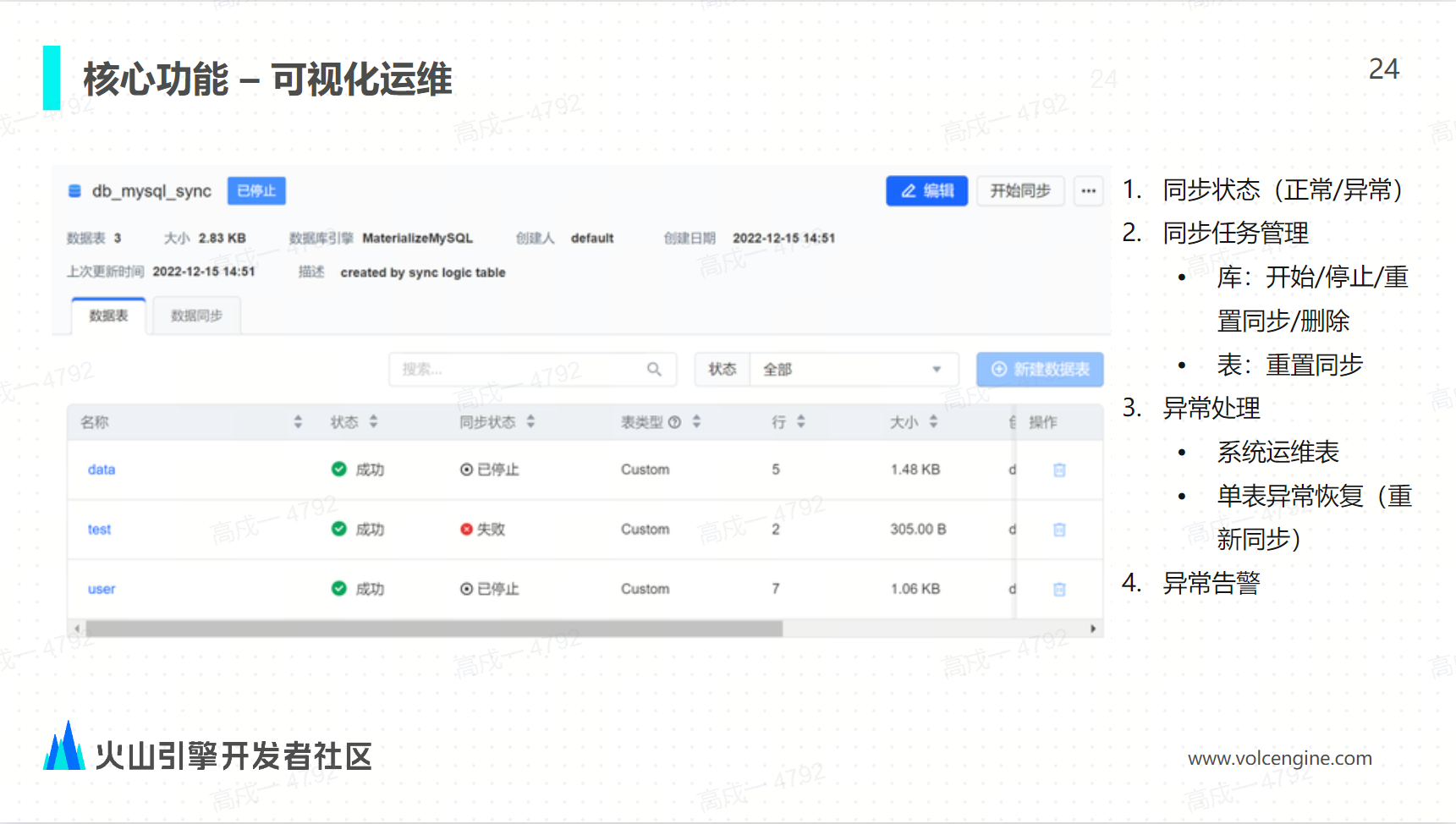
案例实践与未来展望
案例一:短视频直播
该场景下的数据是批流一体写入,为了维护和管理抖音创作者的数据,并且面向这种业务运营和达人经营提供数据查询服务,需要将短视频和直播的实时数据和离线数据做融合,来构建 B 端的数据分析。
-
问题:首先,创作者是唯一的,需要我们进行数据去重。第二,数据源是比较多样化的,所以它整个字段超过 4000 +,是典型的大宽表场景。第三,T+1 的数据,T+1 数据离线同步后,T+0 数据要对它进行更新。第四,是对任何指标的实时查询需要秒级出结果,这是业务面临的问题。
-
解决方案:第一,我们采用了自研的 Unique 表引擎来做实时的去重,并且能够让数据在写入时就可以实时去重、实时查询。第二,通过 Kafka 引擎的 memory table 来实现大宽表数据先缓存,到达了一定的批次之后再集中刷盘。通过对 Byte house 的优化方案有效地解决了碎片化、IO 负载高的问题,能够支持 10 亿+创作数据实时写入和实时查询。

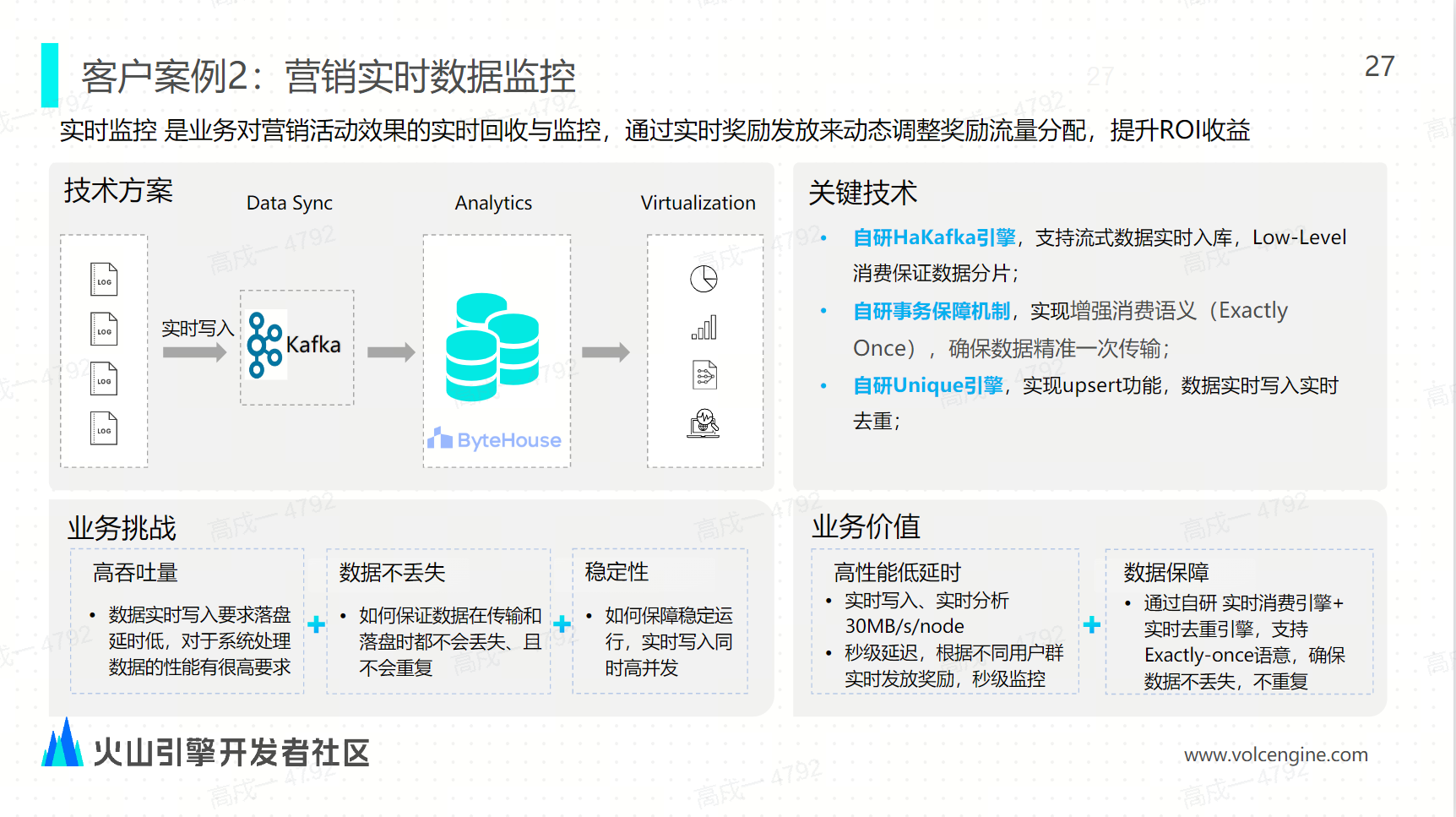
案例二:营销实时数据的监控
营销实时监控是对业务营销活动效果的实时查询和实时回收,希望通过这种实时回收来动态调整奖品的实时发放策略来做到最终的 IOR、ROI 的提升。这就要求数据实时写入、落盘延时要非常低,对数据处理的性能也有很高的要求。在数据传送上面需要保证数据传输的唯一性,以保证奖品不会重复发放,也不会丢失。
-
解决方案:我们在方案上首先采用自研的 Kafka 引擎来支持流式数据的实时写入,实时写入便实时入库。通过 low-level 的这种消费来保证数据的有序分片,再通过增强的消费语义 exactly once 保证数据的精准一次传输。最后我们通过自研的 Unique 引擎来实现实时的这种 upsert 的语义,让数据实时写入、实时去重。通过 ByteHouse 方案的优化,营销业务的每一个节点的实时性能达到了 30 MB/s/node,分析性能也是在秒级的延时,让运营人员能根据不同用户群,实时发放奖励,并秒级地监控奖品发放的进展,从而调整奖品的发放策略。
案例三:游戏广告的数据分析
游戏广告数据分析是在广告业务中会做一些人群圈选、广告投放、效果反馈等投放策略,用户行为预测这些全流程的统计和监控来实现广告营销过程的数字化,提升整个广告游戏投放的 ROI 。
-
问题:业务数据和日志数据要求实时写入、实时去重,由于体量比较大,所以写入压力和查询压力都比较大。
-
解决方案:首先使用 Kafka 引擎来支持流式数据写入,通过 low level 消费模式保障数据的有序分片,再通过 Unique 引擎来实现数据的唯一性,并且实时地去重。在业务数据方面,我们使用物化 MySQL 来保障业务数据从 MySQL 到 ByteHouse 之间能够实时同步。最后使用自研的查询优化器来优化查询性能,通过 ByteHouse 的优化之后,广告效果分析从原来的小时级提升到了现在的秒级延时数据查询的性能,单线程同步 20+MB/s ,并且整个查询性能提升了 3 倍,用户的收益和体验得到了明显的改善。

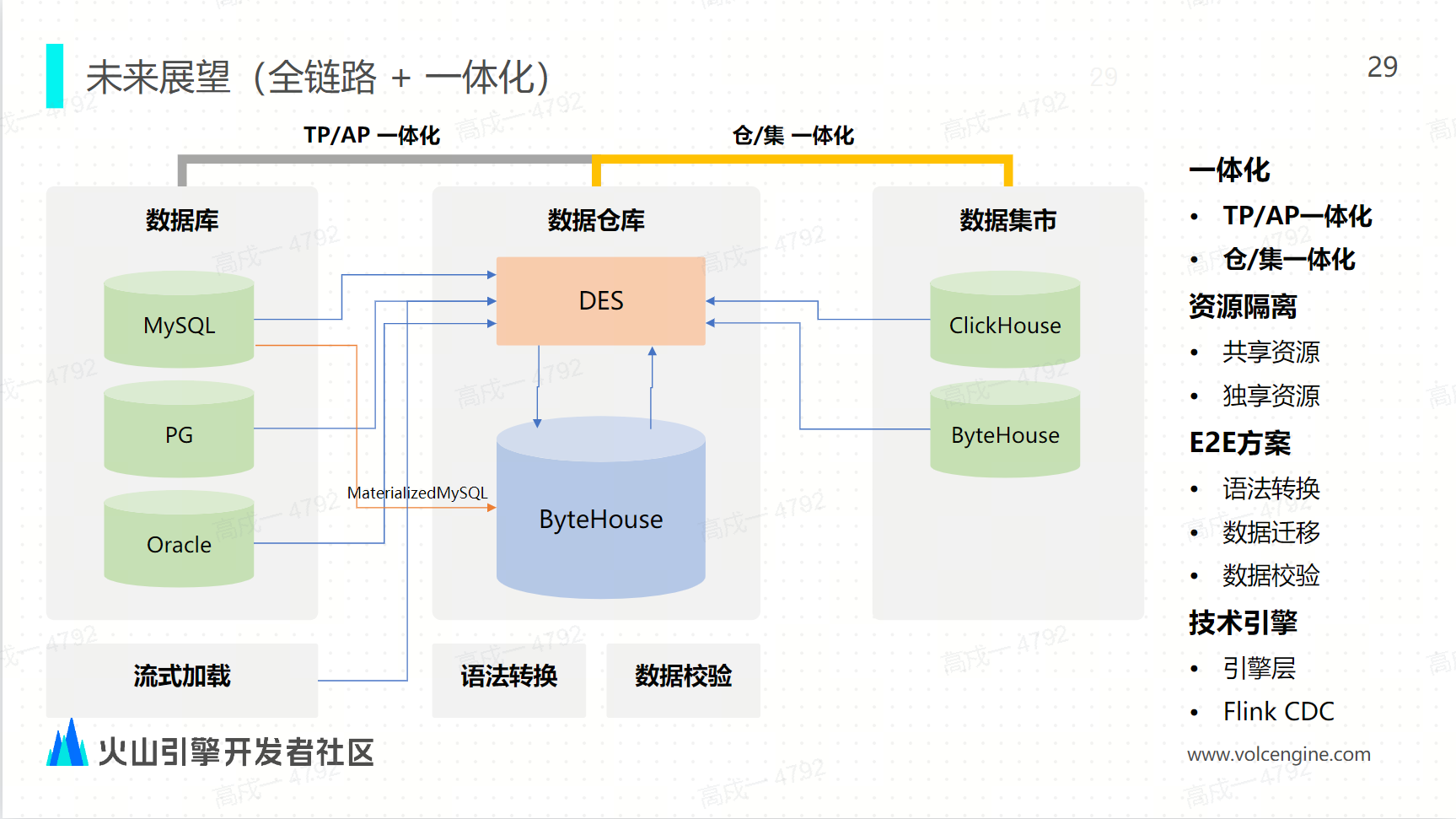
未来战略:全链路和一体化
-
端到端。从语法转换、数据迁移,到数据校验,形成完整的全链路方案。
-
一体化。通过 DES 的逻辑复制能力实现 TP / AP 的一体化,同时实现数据仓库和数据集市的一体化。
-
资源隔离。支持用户使用共享资源池或者数据库引擎来进行数据的同步,也支持用户通过独享的资源池来进行高效数据同步。
-
多引擎方案。除了基于 ClickHouse 引擎的基础能力,我们也会去探索更多的底层引擎能力来增强 ByteHouse 的数据同步。
点击跳转 云原生数据仓库ByteHouse 了解更多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号