字节跳动数据湖技术选型的思考与落地实践
 本文是字节跳动数据平台开发套件团队在 Flink Forward Asia 2021: Flink Forward 峰会上的演讲,着重分享了字节跳动数据湖技术上的选型思考和探索实践。
本文是字节跳动数据平台开发套件团队在 Flink Forward Asia 2021: Flink Forward 峰会上的演讲,着重分享了字节跳动数据湖技术上的选型思考和探索实践。
本文是字节跳动数据平台开发套件团队在 Flink Forward Asia 2021: Flink Forward 峰会上的演讲,着重分享了字节跳动数据湖技术上的选型思考和探索实践。

文 | Gary Li 字节跳动数据平台开发套件团队高级研发工程师,数据湖开源项目 Apache Hudi PMC Member
随着 Flink 社区的不断发展,越来越多的公司将 Flink 作为首选的大数据计算引擎。字节跳动也在持续探索 Flink,作为众多 Flink 用户中的一员,对于 Flink 的投入也是逐年增加。
字节跳动数据集成的现状
在 2018 年,我们基于 Flink 构造了异构数据源之间批式同步通道,主要用于将在线数据库导入到离线数仓,和不同数据源之间的批式传输。
在 2020 年,我们基于 Flink 构造了 MQ-Hive 的实时数据集成通道,主要用于将消息队列中的数据实时写入到 Hive 和 HDFS,在计算引擎上做到了流批统一。
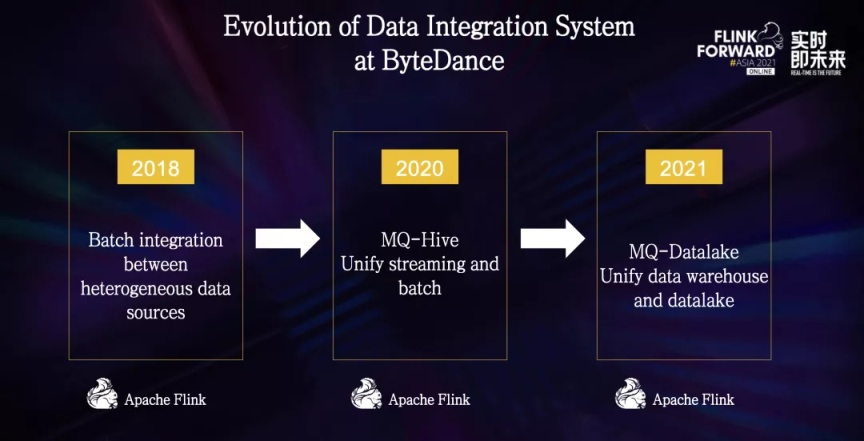
到了 2021 年,我们基于 Flink 构造了实时数据湖集成通道,从而完成了湖仓一体的数据集成系统的构建。
字节跳动数据集成系统目前支持了几十条不同的数据传输管道,涵盖了线上数据库,例如 Mysql Oracle 和 MangoDB;消息队列,例如 Kafka RocketMQ;大数据生态系统的各种组件,例如 HDFS、HIVE 和 ClickHouse。
在字节跳动内部,数据集成系统服务了几乎所有的业务线,包括抖音、今日头条等大家耳熟能详的应用。
整个系统主要分成 3 种模式——批式集成、流式集成和增量集成。
- 批式集成模式基于 Flink Batch 模式打造,将数据以批的形式在不同系统中传输,目前支持了 20 多种不同数据源类型。
- 流式集成模式主要是从 MQ 将数据导入到 Hive 和 HDFS,任务的稳定性和实时性都受到了用户广泛的认可。
- 增量模式即 CDC 模式,用于支持通过数据库变更日志 Binlog,将数据变更同步到外部组件的数据库。
这种模式目前支持 5 种数据源,虽然数据源不多,但是任务数量非常庞大,其中包含了很多核心链路,例如各个业务线的计费、结算等,对数据准确性要求非常高。
在 CDC 链路的整体链路比较长。首先,首次导入为批式导入,我们通过 Flink Batch 模式直连 Mysql 库拉取全量数据写入到 Hive,增量 Binlog 数据通过流式任务导入到 HDFS。
由于 Hive 不支持更新操作,我们依旧使用了一条基于 Spark 的批处理链路,通过 T-1 增量合并的方式,将前一天的 Hive 表和新增的 Binlog 进行合并从而产出当天的 Hive 表。
随着业务的快速发展,这条链路暴露出来的问题也越来越多。
首先,这条基于 Spark 的离线链路资源消耗严重,每次产出新数据都会涉及到一次全量数据 Shuffle 以及一份全量数据落盘,中间所消耗的储存以及计算资源都比较严重。
同时,随着字节跳动业务的快速发展,近实时分析的需求也越来越多。
最后,整条链路流程太长,涉及到 Spark 和 Flink 两个计算引擎,以及 3 个不同的任务类型,用户使用成本和学习成本都比较高,并且带来了不小的运维成本。
为了解决这些问题,我们希望对增量模式做一次彻底的架构升级,将增量模式合并到流式集成中,从而可以摆脱对 Spark 的依赖,在计算引擎层面做到统一。
改造完成后,基于 Flink 的数据集成引擎就能同时支持批式、流式和增量模式,几乎可以覆盖所有的数据集成场景。
同时,在增量模式上,提供和流式通道相当的数据延迟,赋予用户近实时分析能力。在达到这些目标的同时,还可以进一步降低计算成本、提高效率。
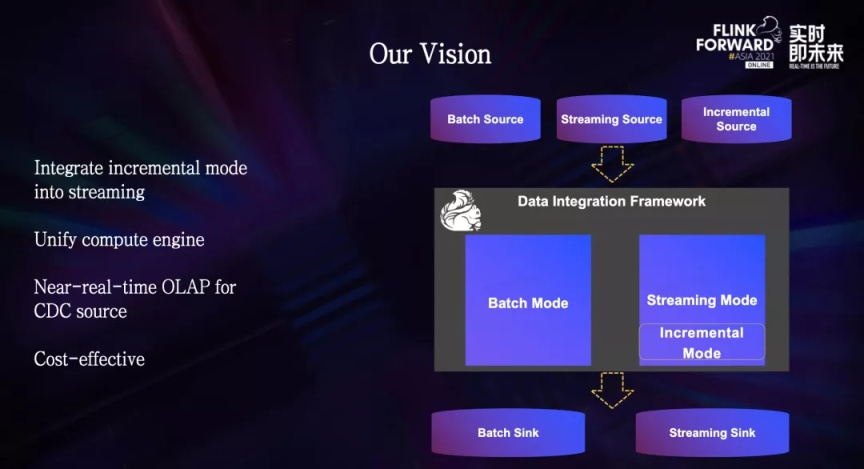
经过一番探索,我们关注到了正在兴起的数据湖技术。
关于数据湖技术选型的思考
我们的目光集中在了 Apache 软件基金会旗下的两款开源数据湖框架 Iceberg 和 Hudi 中。
Iceberg 和 Hudi 两款数据湖框架都非常优秀。但两个项目被创建的目的是为了解决不同的问题,所以在功能上的侧重点也有所不同:
- Iceberg:核心抽象对接新的计算引擎的成本比较低,并且提供先进的查询优化功能和完全的 schema 变更。
- Hudi:更注重于高效率的 Upsert 和近实时更新,提供了 Merge On Read 文件格式,以及便于搭建增量 ETL 管道的增量查询功能。
一番对比下来,两个框架各有千秋,并且离我们想象中的数据湖最终形态都有一定距离,于是我们的核心问题便集中在了以下两个问题:
哪个框架可以更好的支持我们 CDC 数据处理的核心诉求?
哪个框架可以更快速补齐另一个框架的功能,从而成长为一个通用并且成熟的数据湖框架?
经过多次的内部讨论,我们认为:Hudi 在处理 CDC 数据上更为成熟,并且社区迭代速度非常快,特别是最近一年补齐了很多重要的功能,与 Flink 的集成也愈发成熟,最终我们选择了 Hudi 作为我们的数据湖底座。
01 - 索引系统
我们选择 Hudi,最为看重的就是 Hudi 的索引系统。
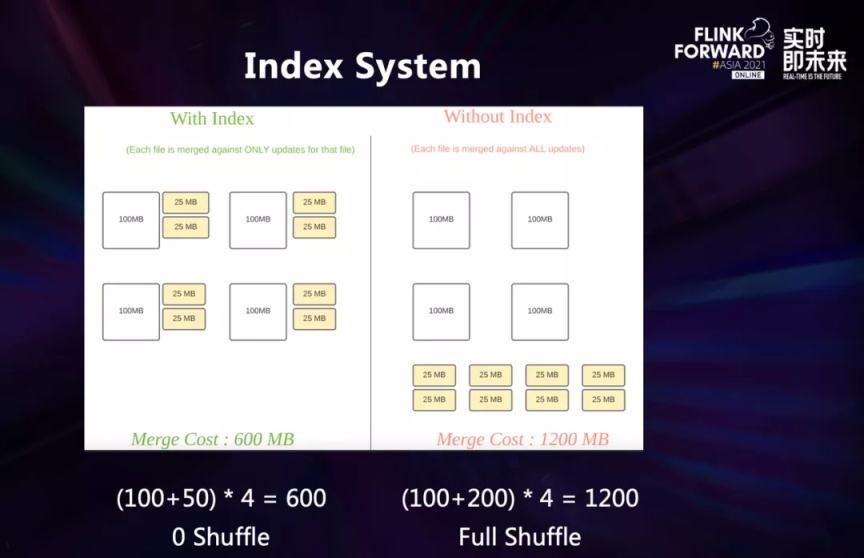
这张图是一个有索引和没有索引的对比。
在 CDC 数据写入的过程中,为了让新增的 Update 数据作用在底表上,我们需要明确知道这条数据是否出现过、出现在哪里,从而把数据写到正确的地方。在合并的时候,我们就可以只合并单个文件,而不需要去管全局数据。
如果没有索引,合并的操作只能通过合并全局数据,带来的就是全局的 shuffle。
在图中的例子中,没有索引的合并开销是有索引的两倍,并且如果随着底表数据量的增大,这个性能差距会呈指数型上升。
所以,在字节跳动的业务数据量级下,索引带来的性能收益是非常巨大的。
Hudi 提供了多种索引来适配不同的场景,每种索引都有不同的优缺点,索引的选择需要根据具体的数据分布来进行取舍,从而达到写入和查询的最优解。
下面举两个不同场景的例子。
1、日志数据去重场景
在日志数据去重的场景中,数据通常会有一个 create_time 的时间戳,底表的分布也是按照这个时间戳进行分区,最近几小时或者几天的数据会有比较频繁的更新,但是更老的数据则不会有太多的变化。
冷热分区的场景就比较适合布隆索引、带 TTL 的 State 索引和哈希索引。
2、CDC 场景
第二个例子是一个数据库导出的例子,也就是 CDC 场景。这个场景更新数据会随机分布,没有什么规律可言,并且底表的数据量会比较大,新增的数据量通常相比底表会比较小。
在这种场景下,我们可以选用哈希索引、State 索引和 Hbase 索引来做到高效率的全局索引。
这两个例子说明了不同场景下,索引的选择也会决定了整个表读写性能。Hudi 提供多种开箱即用的索引,已经覆盖了绝大部分场景,用户使用成本非常低。
02 - Merge On Read 表格式
除了索引系统之外,Hudi 的 Merge On Read 表格式也是一个我们看重的核心功能之一。这种表格式让实时写入、近实时查询成为了可能。
在大数据体系的建设中,写入引擎和查询引擎存在着天然的冲突:
写入引擎更倾向于写小文件,以行存的数据格式写入,尽可能避免在写入过程中有过多的计算包袱,最好是来一条写一条。
查询引擎则更倾向于读大文件,以列存的文件格式储存数据,比如说 parquet 和 orc,数据以某种规则严格分布,比如根据某个常用字段进行排序,从而做到可以在查询的时候,跳过扫描无用的数据,来减少计算开销。
为了在这种天然的冲突下找到最佳的取舍,Hudi 支持了 Merge On Read 的文件格式。
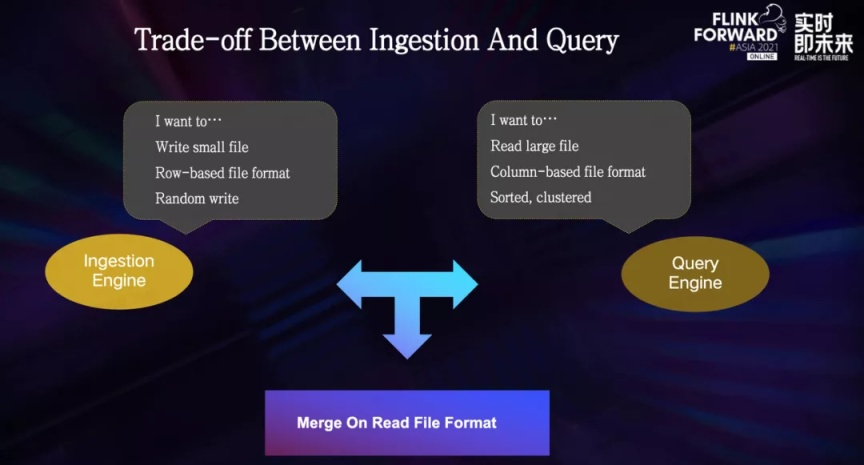
MOR 格式中包含两种文件:一种是基于行存 Avro 格式的 log 文件,一种是基于列存格式的 base 文件,包括 Parquet 或者 ORC。
log 文件通常体积较小,包含了新增的更新数据。base 文件体积较大,包含了所有的历史数据。
写入引擎可以低延迟的将更新的数据写入到 log 文件中。
查询引擎在读的时候将 log 文件与 base 文件进行合并,从而可以读到最新的视图;compaction 任务定时触发合并 base 文件和 log 文件,避免 log 文件持续膨胀。在这个机制下,Merge On Read 文件格式做到了实时写入和近实时查询。
03 - 增量计算
索引系统和 Merge On Read 格式给实时数据湖打下了非常坚实的基础,增量计算则是这个基础之上的 Hudi 的又一个亮眼功能:
增量计算赋予了 Hudi 类似于消息队列的能力。用户可以通过类似于 offset 的时间戳,在 Hudi 的时间线上拉取一段时间内的新增数据。
在一些数据延迟容忍度在分钟级别的场景中,基于 Hudi 可以统一 Lambda 架构,同时服务于实时场景和离线场景,在储存上做到流批一体。
字节跳动内部场景实践思考
在选择了基于 Hudi 的数据湖框架后,我们基于字节跳动内部的场景,打造定制化落地方案。我们的目标是通过 Hudi 来支持所有带 Update 的数据链路:
需要高效率且低成本的 Upsert
支持高吞吐
端到端的数据可见性控制在 5-10 分钟以内
目标明确后,我们开始了对 Hudi Flink Writer 进行了测试。这个图是 Hudi on Flink Writer 的架构:一条新的数据进来之后,首先会经过一个索引层,从而找到它需要去的地方。
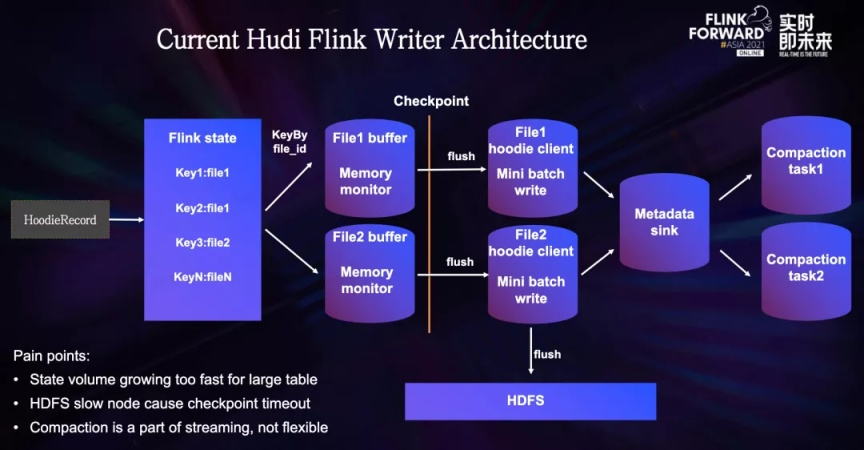
- State 索引中保存了所有主键和文件 ID 的一一映射关系,对于 Update 数据,会找到其所存在的文件 ID,对于 Insert 数据,索引层会给他指定一个新的文件 ID,或者是历史文件中的小文件,让其填充到小文件中,从而避免小文件问题。
- 经过索引层之后,每条数据都会带有一个文件 ID,Flink 会根据文件 ID 进行一次 shuffle,将相同文件 ID 的数据导入到同一个子任务中,同时可以避免多个任务写入同一个文件的问题。
- 写入子任务中有一个内存缓冲区,用于储存当前批次的所有数据,当 Checkpoint 触发时,子任务缓冲区的数据会被传入 Hudi Client 中,Client 会去执行一些微批模式的计算操作,比如 Insert/Upsert/Insert overwrite 等,每种操作的计算逻辑不同,比如说 Insert 操作,会生成一个新的文件,Upsert 操作可能会和历史文件做一次合并。
- 待计算完成后,将处理好的数据写入到 HDFS 中,并同时收集元数据。
- Compaction 任务为流任务的一部分,会定时的去轮训 Hudi 的时间线,查看是否有 Compaction 计划存在,如果有 Compaction 计划,会通过额外的 Compaction 算子来执行。
在测试过程中,我们遇到了以下几个问题:
- 在数据量比较大的场景下,所有的主键和文件 ID 的映射关系都会存在 State 中,State 的体积膨胀的非常快,带来了额外的储存开销,并且有时会造成 Checkpoint 超时的问题。
- 第二个问题是,由于 Checkpoint 期间,Hudi Client 操作比较重,比如说和底层的 base 文件进行合并,这种操作涉及到了历史文件的读取,去重,以及写入新的文件,如果遇到 HDFS 的抖动,很容易出现 Checkpoint 超时的问题
- 第三个问题是,Compaction 任务作为流式任务的一部分,任务启动后资源就不可调节,如果需要调节,只能重启整个任务,开销比较大,如果不能灵活调节 Compaction 任务,就可能会出现 Compaction 算子空跑导致资源浪费,或者资源不足导致任务失败的情况
为了解决这些问题,我们开始针对我们的场景进行了定制化的优化
字节跳动的定制化优化技术方案
01 - 索引层
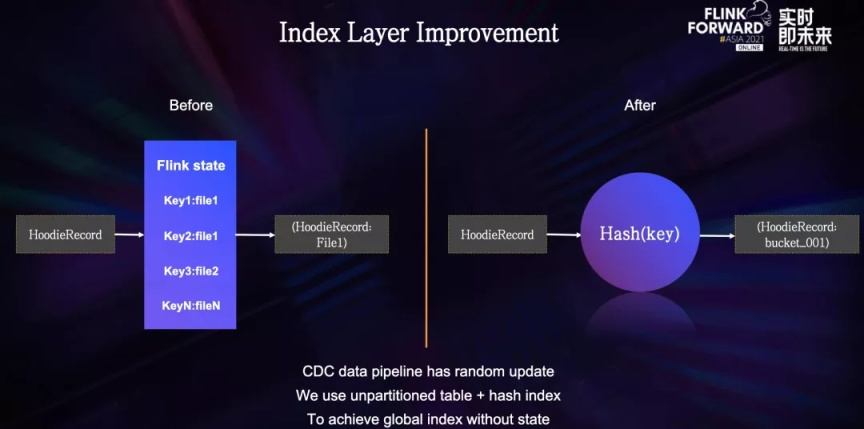
索引的目的就是找到当前这条数据所在的文件地点,存在 State 中的话每条数据都涉及到一次 State 的读和写,在数据量大的场景下,所带来的计算和储存开销都是比较大的。
字节跳动内部开发了一种基于哈希的索引,可以通过直接对主键的哈希操作来找到文件所在的位置,这种方式在非分区表下可以做到全局索引,绕过了对 State 的依赖,改造过后,索引层变成了一层简单的哈希操作。
02 - 写入层
早期的 Hudi 写入和 Spark 强绑定,在 2020 年底,Hudi 社区对底层的 Hudi Client 进行了拆分,并且支持了 Flink 引擎,这种改造方式是将 Spark RDD 的操作变成了一个 List 的操作,所以底层还是一个批式操作,对于 Flink 来说,每一次 Checkpoint 期间所需要做的计算逻辑是类似于 Spark RDD 的,相当于是执行了一次批式的操作,计算包袱是比较大的。
写入层的具体流程是:一条数据经过索引层后,来到了写入层,数据首先会在 Flink 的内存缓冲区积攒,同时通过内存监控来避免内存超出限制导致任务失败,到了 Checkpoint 的时候,数据会被导入到 Hudi Client,然后 Hudi Client 会通过 Insert,Append,Merge 等操作计算最终的写入数据,计算完成后将新的文件写入到 HDFS 并同时回收元数据。
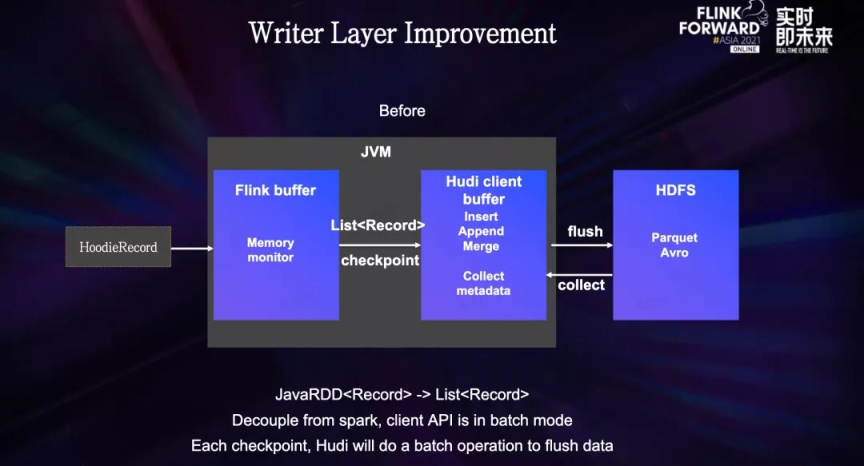
我们的核心目标在于如何让这种微批的写入模式更加的流式化,从而降低 Checkpoint 期间的计算负担。
在表结构上,我们选择了与流式写入更加匹配的 Merge on Read 格式,写入的算子只负责对于 log 文件的追加写入,不做任何别的额外的操作,例如和 base 文件进行合并。
在内存上,我们将第一层 Flink 的内存缓冲区去掉,直接把内存缓冲区建立在了 hudi client 中,在数据写入的同时进行内存监控避免内存超出限制的情况,我们将写入 hdfs 的操作和 Checkpoint 进行了解耦,任务运行过程中,每一小批数据就会写入 HDFS 一次,由于 HDFS 支持追加写操作,这种形式也不会带来小文件的问题,从而将 Checkpoint 尽可能的轻量化,避免 HDFS 抖动和计算量过大带来的 Checkpoint 超时的问题。
03- Compaction 层
Compaction 任务本质上是一个批任务,所以需要和流式写入进行拆分,目前 Hudi on Flink 支持了异步执行 Compaction 的操作,我们的线上任务全部使用了这种模式。
在这种模式下,流式任务可以专注于写入,提升吞吐能力和提高写入的稳定性,批式的 Compaction 任务可以流式任务解耦,弹性伸缩高效的利用计算资源,专注于资源利用率和节约成本。
在这一系列的优化过后,我们在一个 2 百万 rps 的 Kafka 数据源上进行了测试,使用了 200 个并发导入到 Hudi。和之前相比,Checkpoint 耗时从 3-5 分钟降低到了 1 分钟以内,HDFS 抖动带来的任务失败率也大幅度下降由于 Checkpoint 耗时降低,实际用于数据处理的时间变得更多了,数据吞吐量翻了一倍,同时 State 的存储开销也降到了最低。

这是最终的 CDC 数据导入流程图
首先,不同的数据库会将 Binlog 发送到消息队列中,Flink 任务会将所有数据转换成 HoodieRecord 格式,然后通过哈希索引找到对应的文件 ID,通过一层对文件 ID 的 shuffle 后,数据到达了写入层,写入算子以追加写的形式将数据频繁的写入到 HDFS 中,Checkpoint 触发后,Flink 会将所有的元数据收集到一起,并写入到 hudi 的元数据系统中,这里就标志了一个 Commit 提交完成,一个新的 Commit 会随之开始。
用户可以通过 Flink Spark Presto 等查询引擎,近实时的查询已经提交完成的数据。
数据湖平台侧托管的 Compaction 服务会定时提交 Flink Batch 模式的 Compaction 任务,对 Hudi 表进行压缩操作,这个过程对用户无感知并且不影响写入任务。

我们这一整套解决方案也会贡献给社区,感兴趣的同学可以关注 Hudi 社区最新的进展
流式数据湖集成框架的典型落地场景
流式数据湖集成框架改造完成后,我们找到了一些典型的落地场景:
应用最普遍的就是将线上数据库导入到离线数仓进行分析的场景,和之前的 Spark 离线链路相比:端到端的数据延迟从一个小时以上降低到了 5-10 分钟,用户可以进行近实时的数据分析操作。
在资源利用率方面,我们模拟了一个 Mysql 导入离线数仓进行分析的场景,将 Flink 流式导入 Hudi 和 Spark 离线合并的方案进行了对比,在用户小时级查询的场景下,端到端的计算资源大约节约了 70%左右。
在字节跳动 EB 级数据量的数仓场景下,这种资源利用率的提升所带来的收益是非常巨大的。

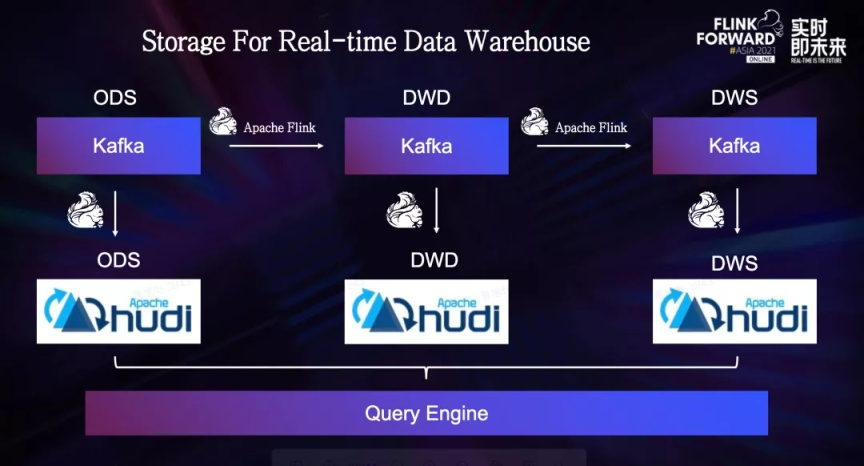
对于基于消息队列和 Flink 构建实时数仓的用户来说,他们可以把不同数仓层级的实时数据导入到 Hudi,这类数据 update 的情况很多,所以相较于 Hive,Hudi 可以提供高效率且低成本的 Upsert 操作,从而用户可以对于全量数据进行近实时查询,避免了一次去重的操作。
这是一个 Flink 双流 Join 的场景,很多 Flink 的用户会使用双流 Join 来进行实时的字段拼接,在使用这个功能的时候,用户通常会开一个时间窗口,然后将这个时间窗口中来自不同数据源的数据拼接起来,这个字段拼接功能也可以在 Hudi 的层面实现。
我们正在探索一个功能,在 Flink 中只将不同 Topic 的数据 Union 在一起,然后通过 Hudi 的索引机制,将相同主键的数据都写入到同一个文件当中,然后通过 Compaction 的操作,将数据进行拼接。
这种方式的优点在于,我们可以通过 Hudi 的索引机制来进行全局字段拼接,不会受到一个窗口的限制。
整个拼接逻辑通过 HoodiePayload 实现,用户可以简单的继承 HoodiePayload,然后来开发自己的自定义的拼接逻辑,拼接的时机可以是 Compaction 任务,也可以是 Merge on Read 近实时查询,用户可以根据需求场景,灵活的使用计算资源。但是相比 Flink 双流 Join,这种模式会有一个缺点,就是实时性和易用性上要差一些。
结语
在这一系列的工作过后,我们对数据湖的未来满怀期待,同时也设立的明确的目标。
首先,我们希望将 Hudi 作为所有 CDC 数据源的底层存储,完全替换掉基于 Spark 的离线合并方案,通过数据集成引擎流式导入,将近实时离线分析的能力带给所有的在线数据库。
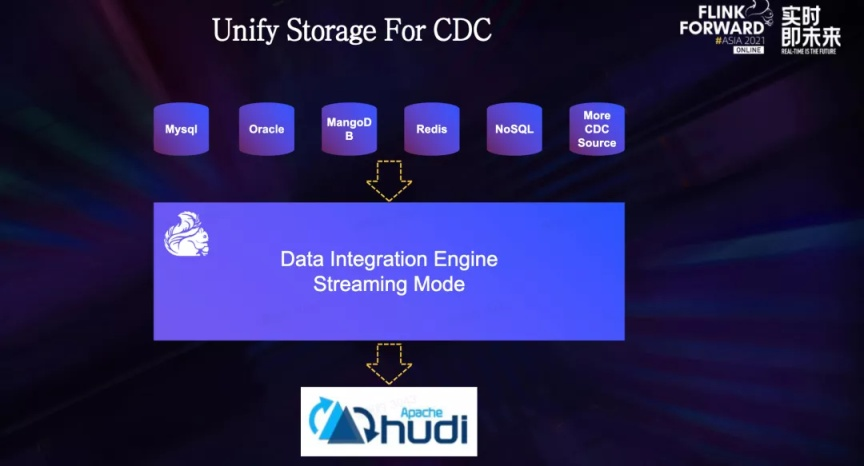
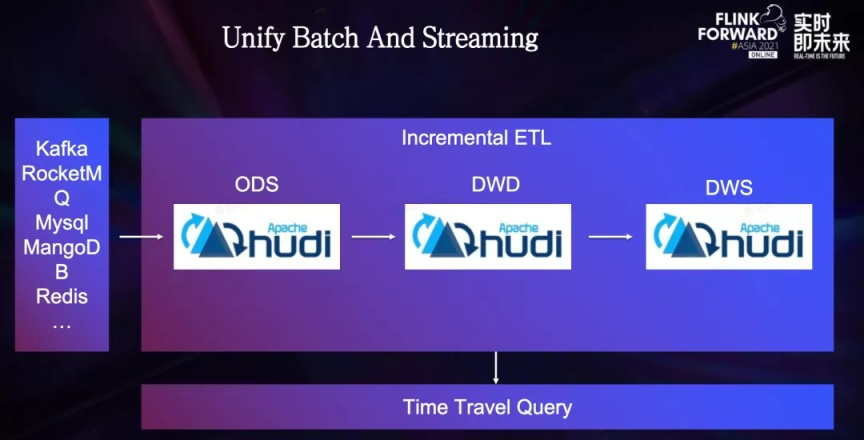
接着,增量 ETL 场景也是一个重要的落地场景,对于数据延迟容忍度在分钟级的场景,Hudi 可以作为统一存储同时服务于实时链路和离线链路,从而将传统的数仓 Lambda 架构升级到真正意义上的流批一体。
最后,我们希望建设一个智能数据湖平台,这个平台会托管所有数据湖的运维管理,达到自我治理的一个状态,用户则不需要再为运维而烦恼。
同时,我们希望提供自动化调优的功能,基于数据的分布找到最佳的配置参数,例如之前提到的不同索引之间的性能取舍问题,我们希望通过算法来找到最佳的配置,从而提高资源利用率,并降低用户的使用门槛。
极佳的用户体验也是我们的追求之一,我们希望在平台侧做到一键入湖入仓,大大降低用户的开发成本。

数据湖集成技术也已经通过火山引擎大数据研发治理套件DataLeap对外开放。
欢迎关注字节跳动数据平台同名公众号

 浙公网安备 33010602011771号
浙公网安备 33010602011771号