


-
概述:隐式语义模型将query与document映射到低维空间,把二者的相关性问题转化为低维空间向量的距离。DSSM使用深度结构实现此映射过程,同时提出word hashing技术使得模型适用于大规模数据
-
经典的隐式语义模型:
1)无监督,目标函数与评价指标耦合关系较弱,效果不佳
1.latent semantic analysis: 对document-term利用SVD进行分解,映射doc或term到低维空间
2.probabilistic latent semantic analysis
3.latent dirichlet allocation
2)拓展隐式语义模型:利用用户点击数据
1.Bi-Lingual Topic Models: 生成模型
2.Discriminative Projective Mdoels:使用S2Net算法进行学习
3)拓展隐式语义模型:利用自动编码器,生成模型
-
DSSN模型:
1)结构:
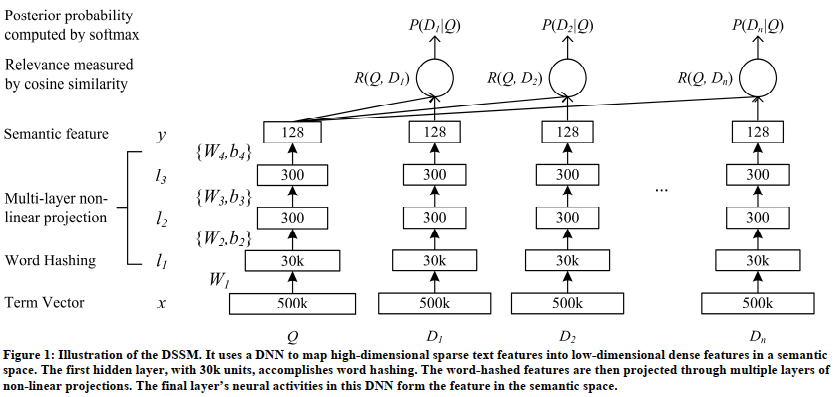
2)计算:

3)DSSM模型学习过程:
1.给定query时点击文档的后延概率:
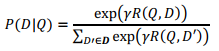
2.最小化目标函数:D+正样本、随机采样未点击D-负样本
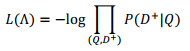
4)word hashing: 解决term vector太大问题,对bag-of-word向量降维
1.方法:以单词good为例,先为其添加起止符号为#good#,然后拆分为n-gram,典型的trigrams为(#go,goo,ood,od#),最后单词被表示为n-gram字符的向量
2.优点:将低term vector的维度
3.不足:碰撞问题
