
FastText
总览
- 用途:文本分类
- 优点:在精度上与深度学习的方法媲美,但更高效,速度快多个数量级。
模型结构
- fastText的结构:输入为一个句子的N个词(ngram)的向量和表示,训练之前单个词向量可利用随机数进行初始化,随后将这些词向量加权平均得到对应文本的向量表示;输出为文本对应的标签。此模型结构与CBOW很相似,只是将输出由单词替换成了文本对应的标签。
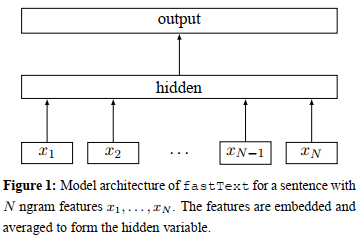
- 对包含N个文档的样本中,模型的优化对应于最小化下述目标函数,其中x_n为归一化的ngram的特征向量,y_n为对应标签,A与B为加权矩阵
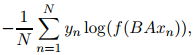
- 隐式层细节:分层softmax以及哈夫曼树,参考word2vec结构。树结构中位于深度l+1处且具有父节点n_1,...,n_l节点对应的概率为,
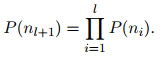
- 模型复杂度:文本表示的特征向量深度为h, 标签的类别为k
O(hlog2k)
- 技巧:
1. bag of n-grams
2. hashing tricks
引用:
[1] Joulin, Armand, et al. "Bag of tricks for efficient text classification." arXiv preprint arXiv:1607.01759 (2016).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号