

数据类型
- 特征属性类别:名词性(无序性,红、黄、蓝)、二元特征(正、负)、有序特征(大中小) 、数值性特征(量化数据,可计算:1.interval-scaled;2.ratio-scaled)、有/无序
数据的基本统计学描述
- 数据整体趋势描述
1.(加权)均值:
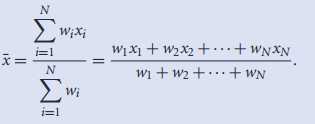
2.中值:快速近似计算,对数据按大小分组后实现
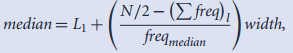
3.众数:可存在多个
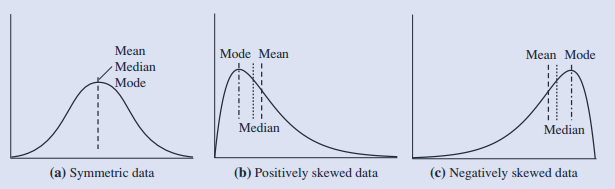
三种代表性数据分布的整体趋势:
- 数据发散程度描述:
1.范围:max()-min()
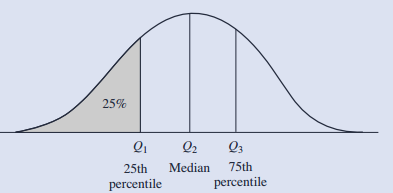
2.分位数:对有序分布的数据等间隔取点,将其划分为等间隔的子集,如下图四分位点
分位点间距离:IQR=Q3-Q1
分离异常数据:outliers<Q1-1.5*IQR或outliers>Q3+1.5*IQR
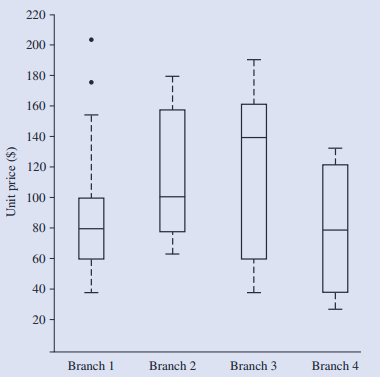
3.箱形图:利用五点数据[min,Q1,median,Q3,max]。图中箱形中的实线分别表示Q1、median、Q3,两端链接虚线的实线表示min与max
4.方差、标准差
- 数据图形化描述:
1.分位点图
2.柱状图
3.散点图
数据的可视化
1.基于像素点的可视化技术:利用像素点的颜色代表不同维度特征的数值,缺点在于无法帮助我们有效了解多维数据的分布情况

2.几何投影可视化技术:1)散点图配不同几何图案; 2)当数据维度高于四维时,可借助散点图矩阵实现可视化; 3)更高维数据,可视化利用并行坐标实现可视化,缺点是不能应用与大规模数据;
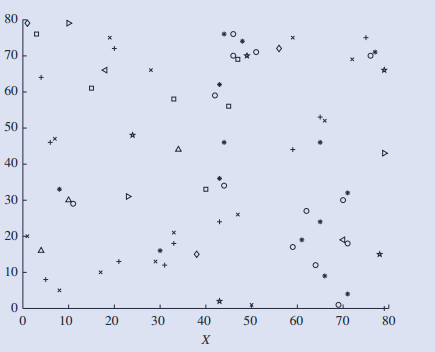
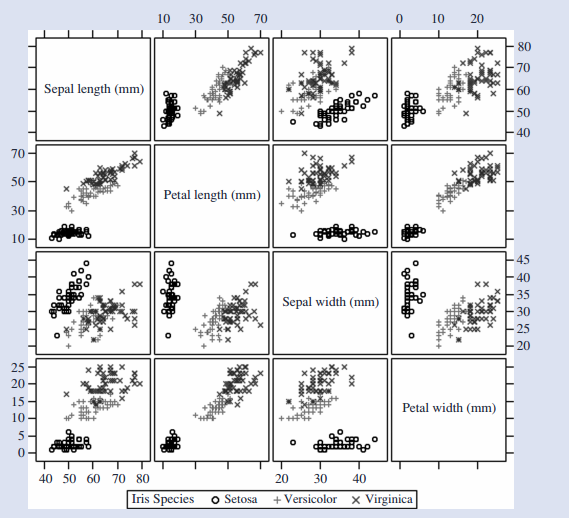
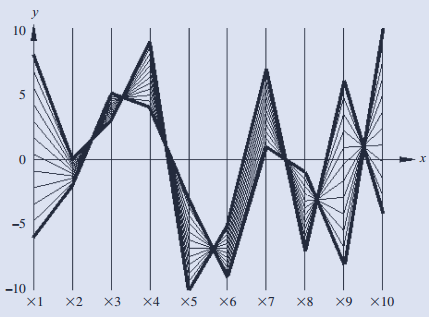
3.基于图标的可视化
4.分层可视化技术:将所有维度的数据划分为子空间后进行可视化,代表性的,1)n-vision; 2)tree-maps
5. 数据及其复杂关系的可视化:1.tag-cloud
数据的相似性与差异性度量:
1.名词属性特征的(不)相似度量:按不匹配比例
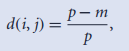
2.二元属性的(不)相似度量:1.对称的;2. 非对称的,即Jaccard系数;
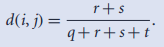 或
或 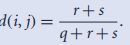
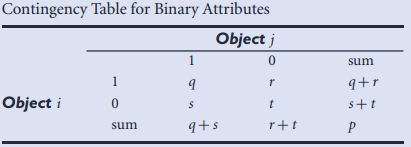
3.数值化属性的(不)相似度量:
- 欧式距离
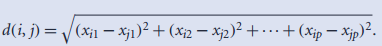
- 曼哈顿距离
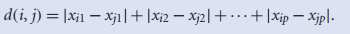
- Minkowsiki距离:L_p norm, h>=1
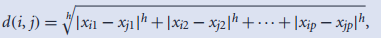
- 极限距离:
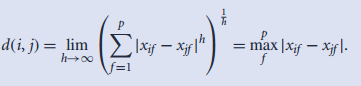
4.有序性属性的(不)相似度量:将其按其排名大小映射到如下z_if后,使用数值化相似度量方法实现度量
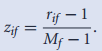
5.混合类型属性的(不)相似度量:1)同类型数据分组后进行挖掘; 2)变换不同类型属性的(不)相似数值到相似矩阵后,再去除缺失数据后综合计算
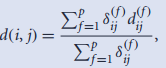
6.余弦相似度:
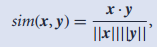
7.基于表示学习的相似度量: word2vec, node2vec等
引用:
[1] Han J, Pei J, Kamber M. Data mining: concepts and techniques[M]. Elsevier, 2011.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号