人脸检测与识别的趋势和分析
人脸遇到的一些问题:
Ø 图像质量:人脸识别系统的主要要求是期望高质量的人脸图像,而质量好的图像则在期望条件下被采集。图像质量对于提取图像特征很重要,因此,即使是最好的识别算法也会受图像质量下降的影响;
Ø 照明问题:同一张脸因照明变化而出现不同,照明可以彻底改变物体的外观;
Ø 姿势变化:从正面获取,姿势变化会产生许多照片,姿态变化难以准确识别人脸;
Ø 面部形状/纹理随着时间推移的变化:有可能随着时间的推移,脸的形状和纹理可能会发生变化;
Ø 相机与人脸的距离:如果图像是从远处拍摄的,有时从较长的距离捕获的人脸将会遭遇质量低劣和噪音的影响;
Ø 遮挡:用户脸部可能会遮挡,被其他人或物体(如眼镜等)遮挡,在这种情况下很难识别这些采集的脸。
没有深度学习出现之前的人脸检测:
1) 基于Adaboost人脸检测
Adaboost人脸检测算法,是基于积分图、级联检测器和Adaboost算法的方法,该方法能够检测出正面人脸且检测速度快。其核心思想是自动从多个弱分类器的空间中挑选出若干个分类器,构成一个分类能力很强的强分类器。
缺点:而在复杂背景中,AdaBoost人脸检测算法容易受到复杂环境的影响,导致检测结果并不稳定,极易将类似人脸区域误检为人脸,误检率较高。
2) 基于特征的方法(引用“Summary of face detection based on video”)
基于特征的方法实质就是利用人脸的等先验知识导出的规则进行人脸检测。
①边缘和形状特征:人脸及人脸器官具有典型的边缘和形状特征,如人脸轮廓、眼睑轮廓、虹膜轮廓、嘴唇轮廓等都可以近似为常见的几何单元;
②纹理特征:人脸具有特定的纹理特征,纹理是在图上表现为灰度或颜色分布的某种规律性,这种规律性在不同类别的纹理中有其不同特点;
③颜色特征:人脸的皮肤颜色是人脸表面最为显著的特征之一,目前主要有RGB,HSV,YCbCr,YIQ,HIS等彩色空间模型被用来表示人脸的肤色,从而进行基于颜色信息的人脸检测方法的研究。
3) 基于模板的方法
基于模板匹配的方法的思路就是通过计算人脸模板和待检测图像之间的相关性来实现人脸检测功能的,按照人脸模型的类型可以分为两种情况:
①基于通用模板的方法,这种方法主要是使用人工定义的方法来给出人脸通用模板。对于待检测的人脸图像,分别计算眼睛,鼻子,嘴等特征同人脸模板的相关性,由相关性的大小来判断是否存在人脸。通用模板匹配方法的优点是算法简单,容易实现,但是它也有自身缺点,如模板的尺寸、大小、形状不能进行自适应的变化,从而导致了这种方法适用范围较窄;
②基于可变形模板的方法,可变形模板法是对基于几何特征和通用模板匹配方法的一种改进。通过设计一个可变模型,利用监测图像的边缘、波峰和波谷值构造能量函数,当能量函数取得最小值时,此时所对应的模型的参数即为人脸面部的几何特征。这种方法存在的不足之处在于能量函数在优化时十分复杂,消耗时间较长,并且能量函数中的各个加权系数都是靠经验值确定的,在实际应用中有一定的局限性。
4) 基于统计理论的方法
基于统计理论的方法是指利用统计分析与机器学习的方法分别寻找人脸与非人脸样本特征,利用这些特征构建分类,使用分类进行人脸检测。它主要包括神经网络方法,支持向量机方法和隐马尔可夫模型方法。基于统计理论的方法是通过样本学习而不是根据人们的直观印象得到的表象规律,因此可以减小由于人眼观测不完整和不精确带来的错误而不得不扩大检测的范围,但是这种方法需要大量的统计特性,样本训练费时费力。
以上也都是通过快速阅读得到的一些结论,大部分都是直接引用文章作者的语句。其中在这些方法中,都有很多改进,比如PCA+Adaboost,HMM等。。。。。。
现在用传统的技术已经不能再有新的突破,所以现在流行了DL架构,打破了人类的极限,又将检测,识别,跟踪等技术上升到另一个高度。
1)Retinal Connected Neural Network (RCNN)
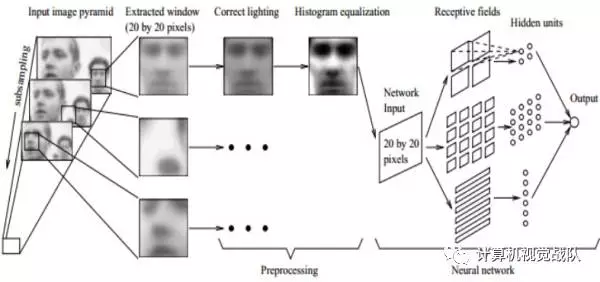
2)Rotation Invariant Neural Network (RINN)
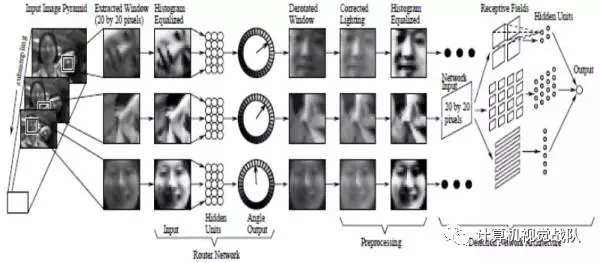
3)Principal Component Analysis with ANN (PCA & ANN)
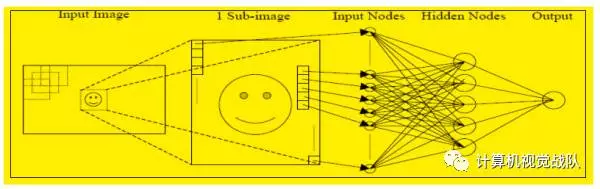
4)Evolutionary Optimization of Neural Networks
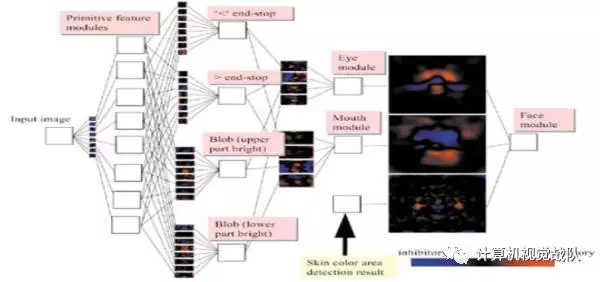
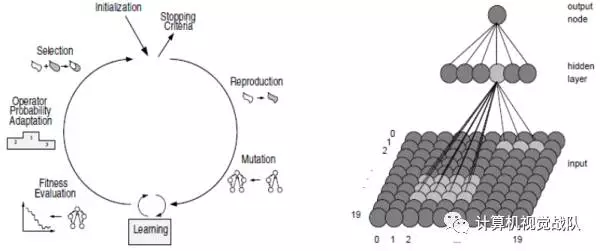
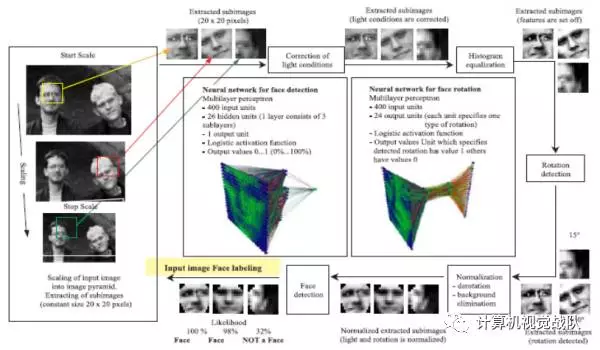
5)Multilayer Perceptron (MLP)
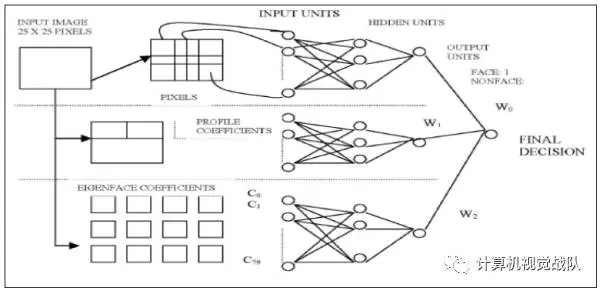
6) Gabor Wavelet Faces with ANN
还有好多就不一一介绍看了(先进的没有介绍,因为想必大家都有阅读,所以。。。嘿嘿,相信大家通过大量阅读一定已经有了自己的想法,赶快去实现吧!)。在此推荐读者你阅读《Recent Advances in Face Detection》,分析的特别详细,希望对大家有帮助,谢谢!
最新深度网络用语人脸的部分介绍与分析:
DeepID网络结构:
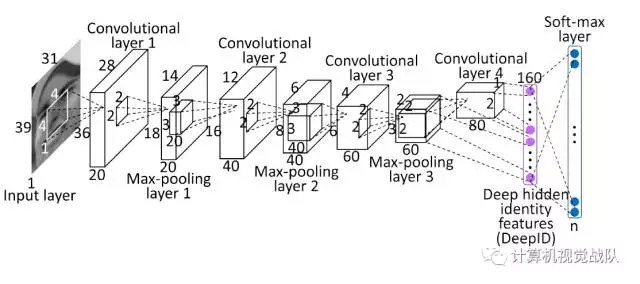
DeepID是第一代,其结构与普通的卷积神经网络差点儿相同。结构图例如上图。
该结构与普通的卷积神经网络的结构相似。可是在隐含层,也就是倒数第二层,与Convolutional layer 4和Max-pooling layer3相连,鉴于卷积神经网络层数越高视野域越大的特性,这种连接方式能够既考虑局部的特征,又考虑全局的特征。
实验结论
-
使用multi-scale patches的convnet比仅仅使用一个仅仅有整张人脸的patch的效果要好。
-
DeepID自身的分类错误率在40%到60%之间震荡,尽管较高。但DeepID是用来学特征的。并不须要要关注自身分类错误率。
-
使用DeepID神经网络的最后一层softmax层作为特征表示,效果非常差。
-
随着DeepID的训练集人数的增长,DeepID本身的分类正确率和LFW的验证正确率都在添加。
DeepID2:
相对于DeepID有了较大的提高。
其主要原因在于在DeepID的基础上加入了验证信号。详细来说。原本的卷积神经网络最后一层softmax使用的是Logistic Regression作为终于的目标函数,也就是识别信号;但在DeepID2中,目标函数上加入了验证信号。两个信号使用加权的方式进行了组合。
两种信号及训练过程
识别信号公式例如以下:
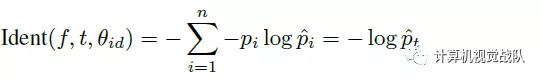
验证信号公式例如以下:
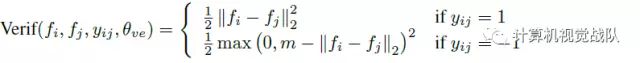
因为验证信号的计算须要两个样本,所以整个卷积神经网络的训练过程也就发生了变化,之前是将所有数据切分为小的batch来进行训练。 如今则是每次迭代时随机抽取两个样本,然后进行训练。
实验结论:
对lambda进行调整。也即对识别信号和验证信号进行平衡,发现lambda在0.05的时候最好。使用LDA中计算类间方差和类内方差的方法进行计算。
得到的结果例如以下:
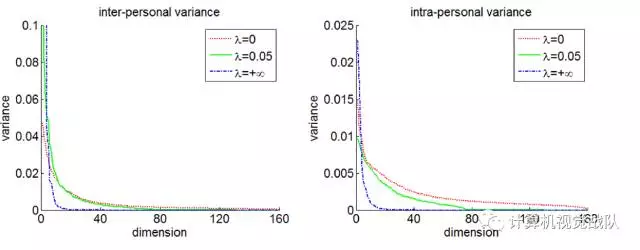
能够发现,在lambda=0.05的时候,类间方差差点儿不变,类内方差下降了非常多。 这样就保证了类间区分性,而降低了类内区分性。
DeepID2+:
DeepID2+有例如以下贡献,第一点是继续更改了网络结构;第二点是对卷积神经网络进行了大量的分析,发现了几大特征。包含:+ 神经单元的适度稀疏性,该性质甚至能够保证即便经过二值化后,仍然能够达到较好的识别效果;+ 高层的神经单元对人比較敏感,即对同一个人的头像来说。总有一些单元处于一直激活或者一直抑制的状态。+ DeepID2+的输出对遮挡很鲁棒。
网络结构变化
相比于DeepID2。DeepID2+做了例如以下三点改动:
-
DeepID层从160维提高到512维。
-
训练集将CelebFaces+和WDRef数据集进行了融合。共同拥有12000人,290000张图片。
-
将DeepID层不仅和第四层和第三层的max-pooling层连接,还连接了第一层和第二层的max-pooling层。
DeepID3:
DeepID3有两种不同的结构,分别为DeepID3 net1,DeepID3 net2。相对DeepID2+,它的层数更多,网络更深。同时还借鉴了VGG和GoogLeNet,引入了inception layer,这个主要是用在了DeepID3 net2里面。网络中还出现了连续两个conv layer直接相连的情况,这样使得网络具有更大的receptive fields和更复杂的nonlinearity,同时还能限制参数的数量。
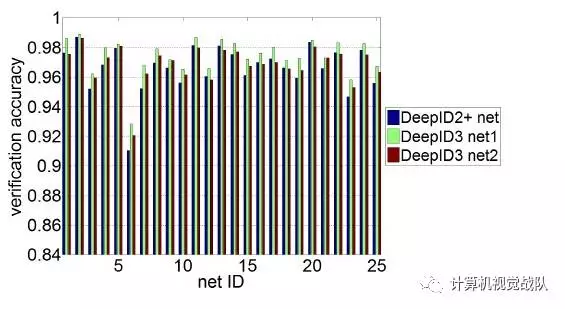
性能
在训练样本上,DeepID3仍采用原来DeepID2+中使用的样本,在25个image patches产生的网络上作对比时,DeepID3 net1优势最为明显,而DeepID3 net2提升不大显著。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号