
浅谈字符串
浅谈字符串
由于笔者字符串水平不高,可能会出现事实性的错误。
你说这篇博客会讲什么?我想大概会讲字符串技术巡礼中的前置知识(
- 字符集记作
- 一般使用
- 字符串
- 空串为长度为
- 字符串
- 字符串
- 对字符串
- 若
- 对字符串
- 我们称字符串
- 对于两个字符串
其实就是抄的 ix35 的博客
Hash 的思想是将不方便存储/比较的东西(比如字符串)通过 Hash 函数
一般来说,我们使用多项式 Hash:
显然有
定理 1.1:对于两个随机字符串
,它们哈希碰撞(即 但 )的概率为 。 证明不会,可以去看 oi-wiki。
定理 1.2:对于
个随机字符串,它们发生哈希碰撞的概率为 。 证明还是不会/oh/oh/oh。
一般我们会选择
我们可以将多项式 Hash 看成 将字符串
给定两个字符串
朴素做法是枚举
我们在后面会学到许多能在很优的复杂度内做字符串匹配的算法,但哈希也可以很简单地实现它。
我们先预处理出
还有很多本来应使用一些专属算法但能用 Hash 乱搞弄过去的题,下文讲这些题时将提到 Hash 做法。
自动机分确定有限状态自动机(DFA)和非确定有限状态自动机(NFA)。OI 中 DFA 要更为常见,所以本节只介绍 DFA。
你可以将 DFA 简单地看成一张带权有向图,其中顶点被称作状态,而有向边被称作转移,边权表示该转移接受的字符。状态中有一个起始状态
形式化的,DFA 由以下部分构成:
- 字符集
- 状态集
- 起始状态
- 接受状态集
- 转移函数
对于字符串
Trie 是一个树状自动机,它能够接受一系列字符串的所有前缀。
首先考虑只有一个字符串
对于多个字符串,我们可以依次按上面的流程建出一条从根挂下来的链,如果有两个字符串
偷一张 oi-wiki 的图:

这个 Trie 接受字符串
可以发现,如果按每一位从小到大的顺序深度优先遍历这棵 Trie,得到的字符串也是字典序从小到大依次递增的。
如果令
Trie 是许多 多串构造出来的自动机 的基础,而它本身也有许多应用。
Hash 做字符串匹配自然是一个很优的算法,但它毕竟是有错误率,且有时会点名被卡的算法,我们想要一个较优时间复杂度的确定性算法。
先来看下暴力匹配时怎么被卡到
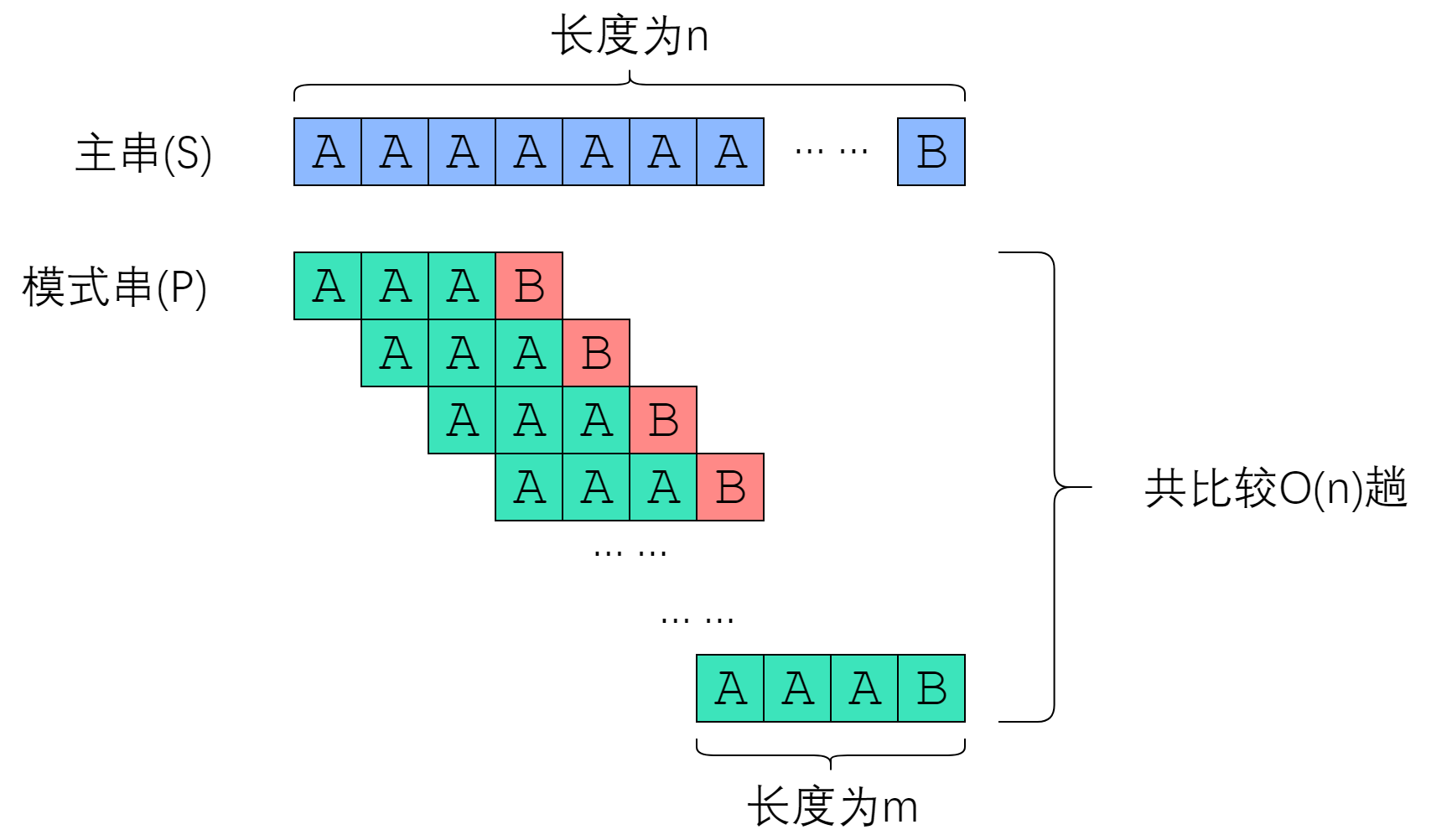
(图源 KMP 算法教程)
观察这个过程,我们实际上可以利用
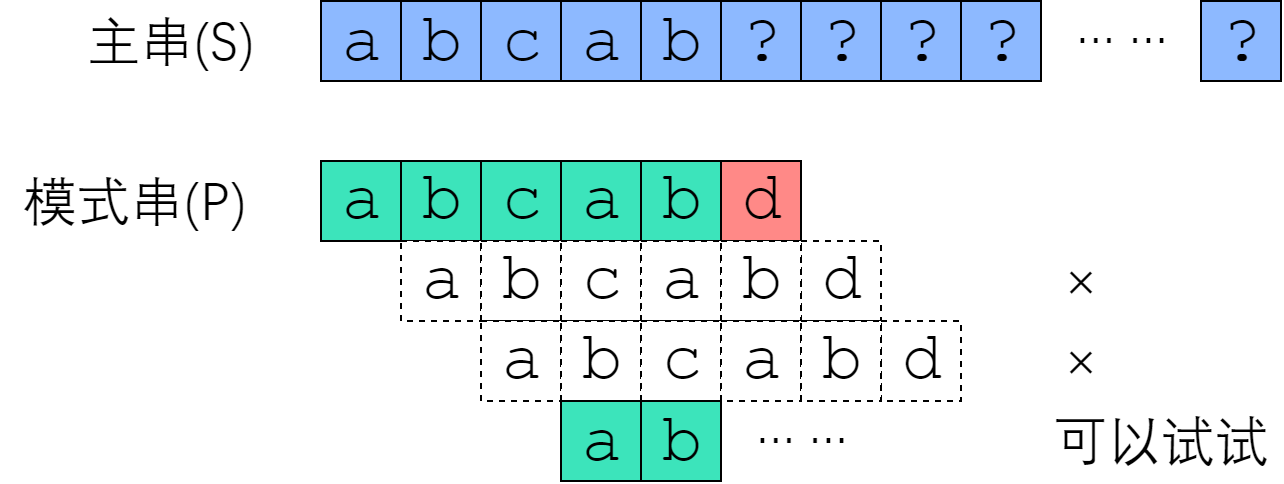
(图源 KMP 算法教程)
假设我们正在尝试从
上图中,我们从
而
描述一下上面的过程:由于
我们引入 Border 的概念:对于一个字符串
举个例子:
假设我们现在匹配到了
注意一个特例:如果
当我们找到一个
这个过程是
有
- 若
- 若
复杂度是
于是我们就做到了
考虑以自动机的形式理解 KMP:
我们需要实现一个自动机,使得其接受所有以给定串
首先我们挂出一条
于是对于当前状态,如果
形式化的,假设当前需要处理的字符是
- 若
- 若
于是我们只需要求出
假设我们已经求出了
在匹配
构建自动机时,我们只需要记录到下一个状态的转移和失配链接即可。
(虽然理解方式是自动机,但写出来其实和原来的几乎一样)
AC 自动机和 KMP 类似,不同的是,现在有多个模式串
显然可以直接对每个
参考上文 KMP 在自动机意义下的理解,我们考虑将其中的一条前缀链扩展成一棵 Trie。
失配链接也不局限于单个串


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?