Eureka原理
基本原理
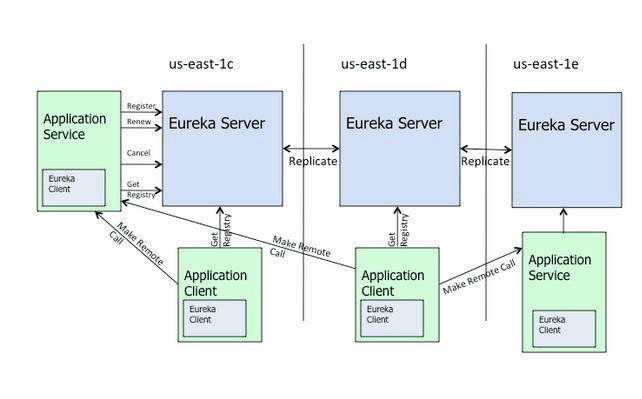
- 处于不同节点的eureka通过Replicate进行数据同步
- Application Service为服务提供者
- Application Client为服务消费者
- Make Remote Call完成一次服务调用
1. 服务启动后向Eureka注册,Eureka Server会将注册信息向其他Eureka Server进行同步,当服务消费者要调用服务提供者,则向服务注册中心获取服务提供者地址,然后会将服务提供者地址缓存在本地,下次再调用时,则直接从本地缓存中取,完成一次调用。
2. 当服务注册中心Eureka Server检测到服务提供者因为宕机、网络原因不可用时,则在服务注册中心将服务置为DOWN状态,并把当前服务提供者状态向订阅者发布,订阅过的服务消费者更新本地缓存。
3. 服务提供者在启动后,周期性(默认30秒)向Eureka Server发送心跳,以证明当前服务是可用状态。Eureka Server在一定的时间(默认90秒)未收到客户端的心跳,则认为服务宕机,注销该实例。
Eureka的自我保护机制
在默认配置中,Eureka Server在默认90s没有得到客户端的心跳,则注销该实例,但是往往因为微服务跨进程调用,网络通信往往会面临着各种问题,比如微服务状态正常,但是因为网络分区故障时,Eureka Server注销服务实例则会让大部分微服务不可用,这很危险,因为服务明明没有问题。
eureka.server.enable-self-preservation=true
它的原理是,当Eureka Server节点在短时间内丢失过多的客户端时(可能发送了网络故障),那么这个节点将进入自我保护模式,不再注销任何微服务,当网络故障回复后,该节点会自动退出自我保护模式。
Eureka与Zookeeper对比
Zookeeper保证CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
Eureka保证AP
Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)
Eureka源码剖析
1. Registry数据结构
public abstract class AbstractInstanceRegistry implements InstanceRegistry{ private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry = new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>(); }
- Registry的CocurrentHashMap,就是注册表的核心结构
- Eureka Server的注册表直接基于纯内存,即在内存里维护了一个数据结构registry
ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>()
- key是服务名称, value代表了一个服务的多个服务实例
Map<String, Lease<InstanceInfo>>
- key是服务实例的id, InstanceInfo代表了服务实例的具体信息, Lease会维护每个服务最近一次发送心跳的时间
2. Server端多级缓存机制
Eureka Server为了避免同时读写内存数据结构造成的并发冲突问题,采用了多级缓存机制来进一步提升服务请求的响应速度
拉取注册表
- 首先从ReadOnlyCacheMap里查缓存的注册表
- 若没有,就找ReadWriteCacheMap里缓存的注册表
- 如果还没有,就从内存中获取实际的注册表数据
注册表发生变更的步骤
- 会在内存中更新变更的注册表数据,同时过期掉ReadWriteCacheMap
- 此过程不会影响ReadOnlyCacheMap提供人家查询注册表
- 一段时间内(默认30秒),各服务拉取注册表会直接读ReadOnlyCacheMap
- 30秒过后,Eureka Server的后台线程发现ReadWriteCacheMap已经清空了,也会清空ReadOnlyCacheMap中的缓存
- 下次有服务拉取注册表,又会从内存中获取最新的数据了,同时填充各个缓存
Eureka Server如何实现高可用?
当Eureka以集群模式部署时,当集群中有分片出现故障时,Eureka会转入自我保护模式。它允许在分片故障期间继续提供服务的发现和注册,当分片故障恢复运行时,集群中的其他分片会把它们的状态再次同步回来。不同可用区域的服务注册中心通过异步模式互相复制各自的状态,这表明在任意给定的时间点每个实例关于所有服务的状态是有细微差别的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号