
Mysql 索引 BTree 与 Hash
一、B-Tree 简介
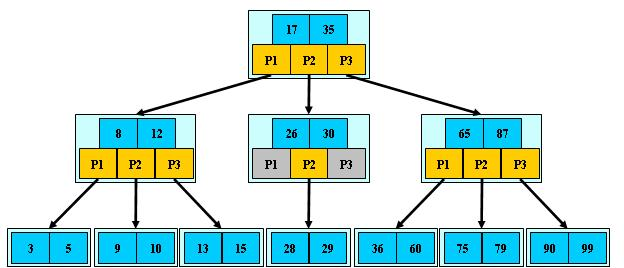
BTree 是一种多路搜索树
- 定义任意非叶子节点最多只有M个儿子 , M> 2
- 根节点的儿子数为 [2,M]
- 除根节点外的非叶子节点的儿子数为 [M/2,M]
- 每个节点存放至少 M/2-1 (向上取整) 和 至多M-1 个关键字 (至少2个关键字)
- 非叶子节点的关键字个数 = 指向儿子的指针个数 -1
- 非叶子节点的关键字: K[1]、K[2] ...K[M-1] , 且 K[i] < K[i+1]
- 非叶子节点的指针:P[1]、P[2] ...P[M] ,其中 P[1] 指向关键字小于 K[1] 的子树,P[M] 指向关键字大于 K[M-1] 的子树
- 所有叶子节点位于同一层
特点:
- 关键字集合分布在整棵树中
- 任何一个关键字出现且只出现在一个节点中
- 搜索有可能在非叶子节点结束
- 其搜索性能等价于关键字全集内做一次二分查找
- 自动层次控制
B-Tree 的搜索,从根节点开始,对节点内的关键字(有序)进行二分查找,如果命中则结束,否则进入查询关键字范围的儿子节点。重复直到对应的儿子指针为空,或者已经是叶子节点
二、B+Tree

B+Tree 是 B-Tree 的变体,也是一种多路搜索树
- 非叶子节点的子树指针与关键字个数相同
- 非叶子节点的子树指针 p[i] ,指向关键字值属于 (K[i] ,K[i+1]) 的子树
- 所有的叶子节点增加一个链指针
- 所有关键字都在叶子节点出现
特点:
- 所有关键字都出现在叶子节点的链表,且链表中的关键字恰好是有序的
- 不可能在非叶子节点命中
- 非叶子节点相当于叶子节点的索引,叶子节点相当于是存储关键字数据的数据层
- 更适合文件索引系统
B+Tree因为非叶子节点不存放数据,所以相对于B-Tree可以存放更多的键与指针,让树变得更矮,这样降低了I/O操作
不同的存储引擎对索引有不同的支持:Innodb 和 MyISAM 默认的索引是Btree , 而 memory 默认的索引是 Hash 索引
三、聚簇索引与非聚簇索引
聚簇索引
聚簇索引就是指主索引文件和数据文件为同一份文件,聚簇索引主要用在Innodb 存储引擎中。在该索引实现方式中 B+Tree 的叶子节点上的 data 就是数据本身,key 为主键。
如果是一般索引的话,data 便会指向对应的主索引在B+Tree 的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的 B+Tree ,这样做的目的是为了
提高区间访问的性能
非聚簇索引
非聚簇索引就是指B+Tree的叶子节点上的data ,并不是数据本身,而是数据存放的地址。主索引和辅助索引没有区别,只要主索引中的 key 一定得是唯一的,主要用在 MyISAM
存储引擎中。非聚簇索引比聚簇索引多了一次读取数据的IO 操作,所以查找的性能会差
四、哈希索引
哈西算法的时间复杂度为O(1) ,哈希表也称为散列表,在哈希的方式下,一个元素 k 处于 h(k) 中,即利用哈希数 h ,根据关键字 k 计算出槽的位置,函数 h 将关键字映射到哈希表 T[0 ...m-1] 的槽位上
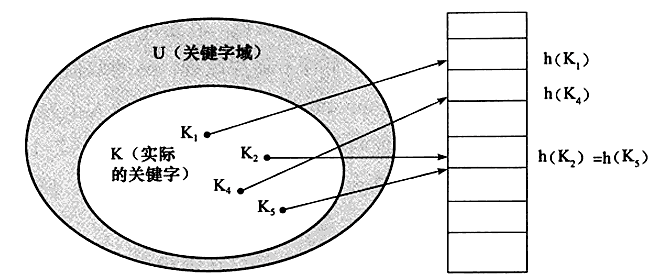
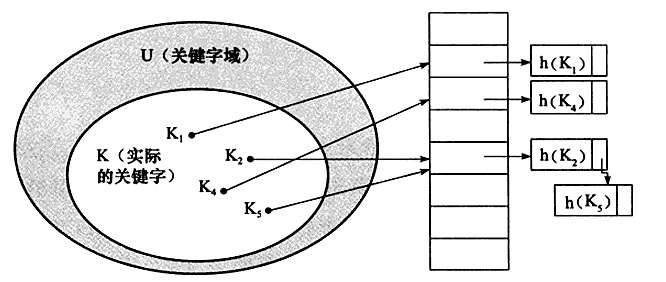
上图中哈希函数 h 可能将两个不同的关键字映射到相同的位置,这叫碰撞,在数据库中一般采用链接法解决,在链接法中,将散列到同一个槽位的元素放在一个链表中,如下图
BTree 索引与 Hash 索引的区别
Hash 索引结构特殊,检索效率非常高,索引可以一次定位,不像 BTree 索引需要从根节点到叶子节点,所以Hash 索引的查询效率要远高于B-Tree 索引。而数据库默认存储引擎 Innode 默认的索引却是
B+Tree ,因为 Hash 索引特殊也带来了很多限制与弊端
- Hash 索引仅仅能够满足 “=” ,“IN” , “<=>” 查询,不能使用范围查询,如 where age > 20,因为 Hash 索引是计算Hash运算后,处理后的值不能保证与原址的大小关系
- Hash 索引无法被用来避免数据的排序操作,因为同上,计算后的值无法利用索引的数据来避免任何排序运算
- Hash 索引在任何时候都不能避免表扫,可能存在不同的key 计算出相同的hash 值,所以即使满足hash 查询,也需要全表扫描
- Hash 索引遇到大量Hash 值相同的情况下性能会急剧下降
参考:https://www.cnblogs.com/igoodful/p/9361500.html
五、单一索引与复合索引
看了一篇文章,实际测试了索引是否生效,个人觉得最深的一句话是所有是否生效以及执行情况需要在具体的数据库版本与存储引擎下来将。本人将测试如下:
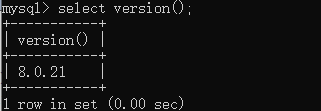
数据库版本:8.0.21
5.1 联合索引测试
创建表t_user,以及联合索引
CREATE TABLE `t_user` ( `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT, `user_id` varchar(20), `user_name` varchar(20), `password` varchar(20), `address` varchar(255), PRIMARY KEY (`id`) USING BTREE, INDEX `联合索引`(`user_id`,`user_name`,`password`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4;
1.条件 user_id , 使用了联合索引

2.条件user_name,没有进行索引查询

3.条件 password,也没有进行索引查询

4.组合查询:user_id and user_name ,依然走索引

5.将 and 换位 or , 也走索引

更换顺序,将 user_name 放前面。也是走索引的

6.条件 user_name,password,不走索引

7.条件 user_id,user_name,password ,走索引

8. 条件 user_id,password ,走索引

例如 (a,b,c)复合索引,等价于(a),(a,b),(a,b,c)这样的类型,如果查询(b),(c) ,(bc)是不走索引的,唯一与预期不复合的是 or 查询,也会走索引,与字段顺序无关。
5.1 单列索引测试
CREATE TABLE `t_user` ( `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT, `user_id` varchar(20), `user_name` varchar(20), `password` varchar(20), `address` varchar(255), PRIMARY KEY (`id`) USING BTREE, INDEX `用户id`(`user_id`) USING BTREE, INDEX `用户名称`(`user_name`) USING BTREE, INDEX `密码`(`password`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4;
1.条件 user_id ,走用户id 索引

2.条件 user_name,走索引

3.条件 password,走索引

4. 复合查询 user_id and user_name

将 and 换为 or

5. 复合查询 user_id,user_name,password

将 and 换为 or

单列索引:如果使用 or 查询不使用 索引,and 查询直走第一个参数的索引
此处解释 explain 执行计划各个字段的含义:
id :选择标识符
select_type : 查询的类型
table : 结果集的表
partitions : 匹配的分区
type : 连接的类型
possible_keys : 查询时可能使用的索引
key:实际使用的索引
row : 扫描出的行数
filtered : 按表条件过滤的百分比
extra: 执行情况的描述和说明
参考:https://www.cnblogs.com/tufujie/p/9413852.html
参考:https://blog.csdn.net/Abysscarry/article/details/80792876
六、索引类型
唯一索引 Unique :不允许重复的索引
普通索引 Normal :提高性能,普通索引
全文索引Fulltext :使用长文本
空间索引 Spatial : 用户空间类型
唯一索引的查询性能要大于普通index
七、不走索引的情况
1.单列索引
索引列 a ,b 普通列 c
a and b : 走一个索引,由sql 执行优化器决定
a or b : 不走索引
a and c : 走索引
a or c : 不走索引
结果: 单列索引,条件包含 or 即不执行索引
大于 、小于 、不等于、in 区间判断
大于号:走索引

小于号:走索引

不等于:走索引

in :走索引

in 多个字段也走索引(有博客说多个参数不走索引,实测走)

like %开头不走索引,非 %开头的会走索引
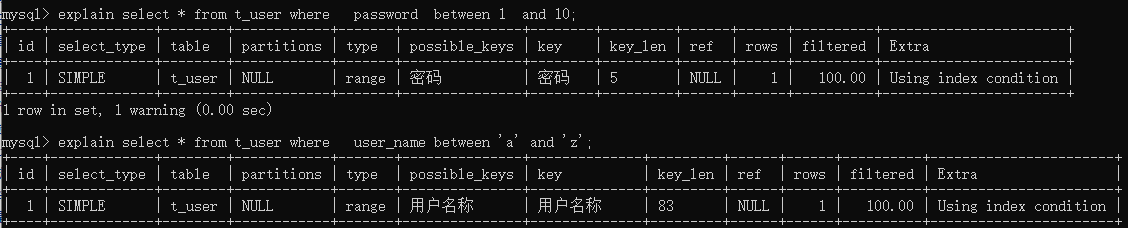
between and 走索引
左侧有表达式不走索引
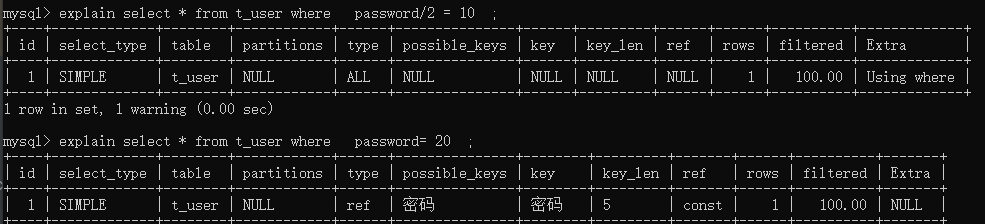
右侧计算走索引

null 值判断 is null 走索引。 = null 不走

字符类型与数值类型比较:不走索引

substring 计算字符不走索引

有博客说:最左匹配原则,第一个条件不走索引,后面的都不走,实际上(age 普通字段,user_name索引字段 )还是会走索引

单列索引总结
使用到索引的情况:
- 大于号
- 小于号
- 等于
- 不等
- like 非%开头
- in (参数不限多少都走)
- not in
- 条件表达式右侧计算 age = 10/2 或者 age = 10/2 + 1
- between and
- is null
未走索引的情况:
- like % 开头
- 条件左侧有计算 age /2 = 10 或者 age+1 = 10
- = null
- 字符类型与数值类型比较
- substring
- or 不走索引
2.复合索引
复合索引列:user_id ,user_name,password
第一列大于小于号走索引

第二列、第三列比较不走索引

第一列不等于走索引

第一列 in 走索引

第一列 between and 走索引

包含or 即不走索引


