


volatile 关键字
一、cpu cache 模型

cpu 与 主存的速度差异因此产生了缓存。现在缓存的数量增加到3 级,最靠近cpu 的 称为 L1,然后依次是 L2 ,L3
由于程序指令与数据的行为和热点分布差异, L1 Cache 分为 L1i 和 L1d 。 缓存提高了吞吐力,单引入了缓存不一致问题。
比如:
i++
- 读取主内存的 i 到 cache
- 对 i 进行 +1
- 将结果写回到 cpu cache
- 将数据写回到主存
在单线程是没有问题的,但是在多线程就会出现问题。如何解决缓存不一致问题?
01.通过总线加锁 02.通过缓存一致性协议

二、理解 Volatile 关键字
并发三个特性
- 原子性
- 有序性
- 可见性
原子性:操作是不可再分割的一个整体,原子操作+原子操作 == 非原子操作
可见性:当一个线程对共享变量修改,别的线程立马可以看到修改后的新值
有序性: 指代码执行过程的先后顺序,在多线程的情况下,如果不能有序,则会产生很大问题
Java 如何保障可见性?
- volatile 修饰,对于资源的操作会直接在主内存中进行
- synchronized 保证可见性,同一时刻只能用一个线程可见
- juc 中的 Lock ,与 synchronized 相同
Java 中如何保证有序性?
- volatile
- synchronzied
- Lock
使用 Volatile 的意义:
- 线程之间变量的可见性
- 禁止指令重排序
- 不能保证原子性
volatile 如何保证禁止指令重排序?
被 volatile 修饰的变量会存储 Lock; 的前缀,Lock; 相当于 内存屏障。为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序
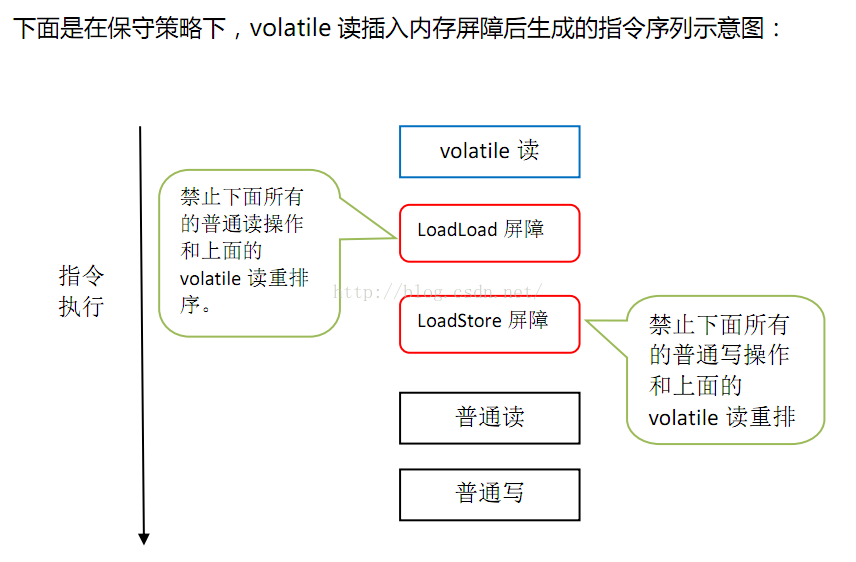
JMM基于保守策略的JMM内存屏障插入策略:
1.在每个volatile写操作的前面插入一个StoreStore屏障
2.在每个volatile写操作的后面插入一个SotreLoad屏障
3.在每个volatile读操作的后面插入一个LoadLoad屏障
4.在每个volatile读操作的后面插入一个LoadStore屏障
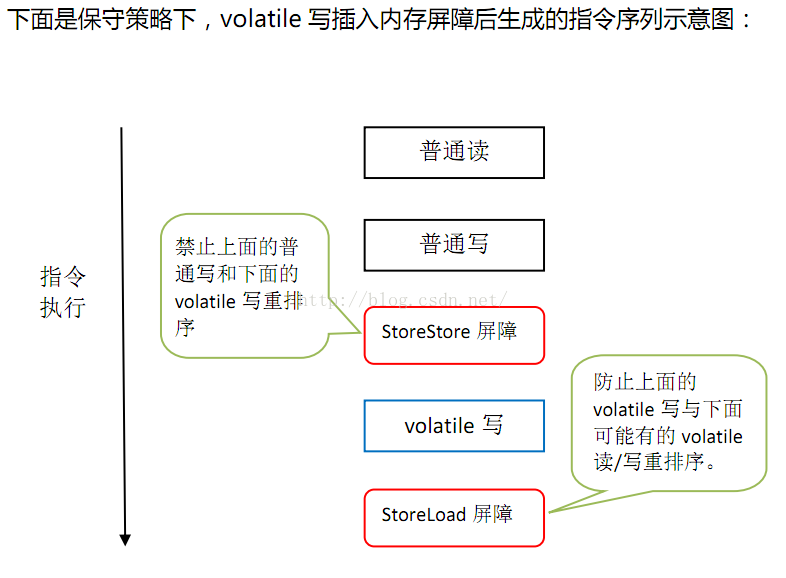
上图的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了
因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存

86处理器仅仅会对写-读操作做重排序
因此会省略掉读-读、读-写和写-写操作做重排序的内存屏障
在x86中,JMM仅需在volatile后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义
这意味着在x86处理器中,volatile写的开销比volatile读的大,因为StoreLoad屏障开销比较大



