
HashMap 原理?jdk1.7 与 1.8区别
HashMap 结构 以及 1.7 与 1.8
一、区别
01. jdk 1.7 用的是头插法,而jdk1.8以后使用的是尾插法?为什么这样做呢?因为 JDK 1.7 是用单链表进行纵向延伸,采用头插法时会出现逆序循环链表死循环的问题,在 jdk 1.8 之后是
因为加入了红黑树,使用尾插法,能够避免出现逆序且链表死循环的问题。
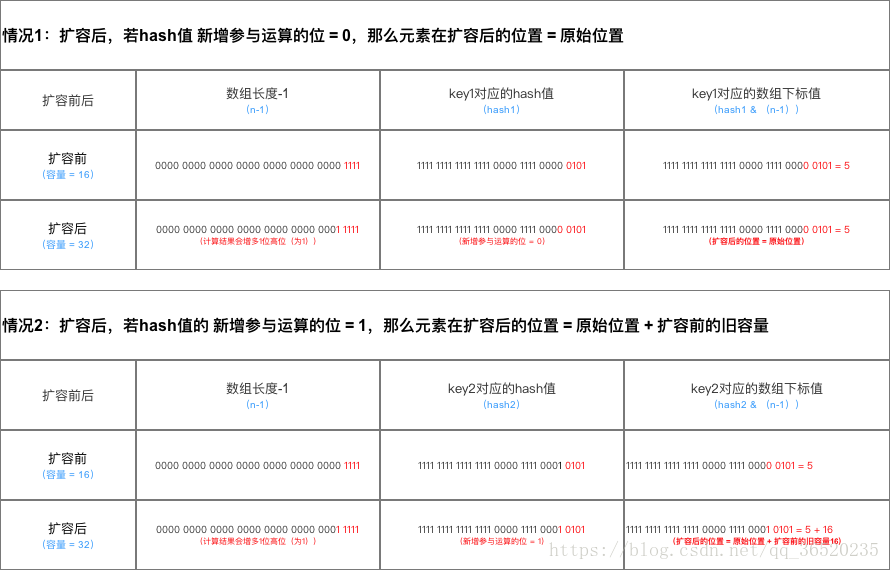
02.扩容后数据存储位置的计算方式也不一样,在 jdk1.7 的时候是直接用 hash 值和需要扩容的二进制数进行,()
03.jdk1.8 的时候直接使用了 jdk1.7 的时候计算的规律,也就是扩容前的原始位置+扩容的大小值 = jdk1.8 的计算方式,而不再是 jdk1.7 的那种异或方式。
但这种方式就相当于只需要判断 hash 值的新增参与运算的位置是0 还是1 就直接迅速计算出扩容后的存储方式
在计算 hash 值的时候, jdk1.7 用了9次扰动处理 = 4次位运算+5次异或,而jdk1.8 只用了2次扰动处理 = 1次位运算+1 次异或
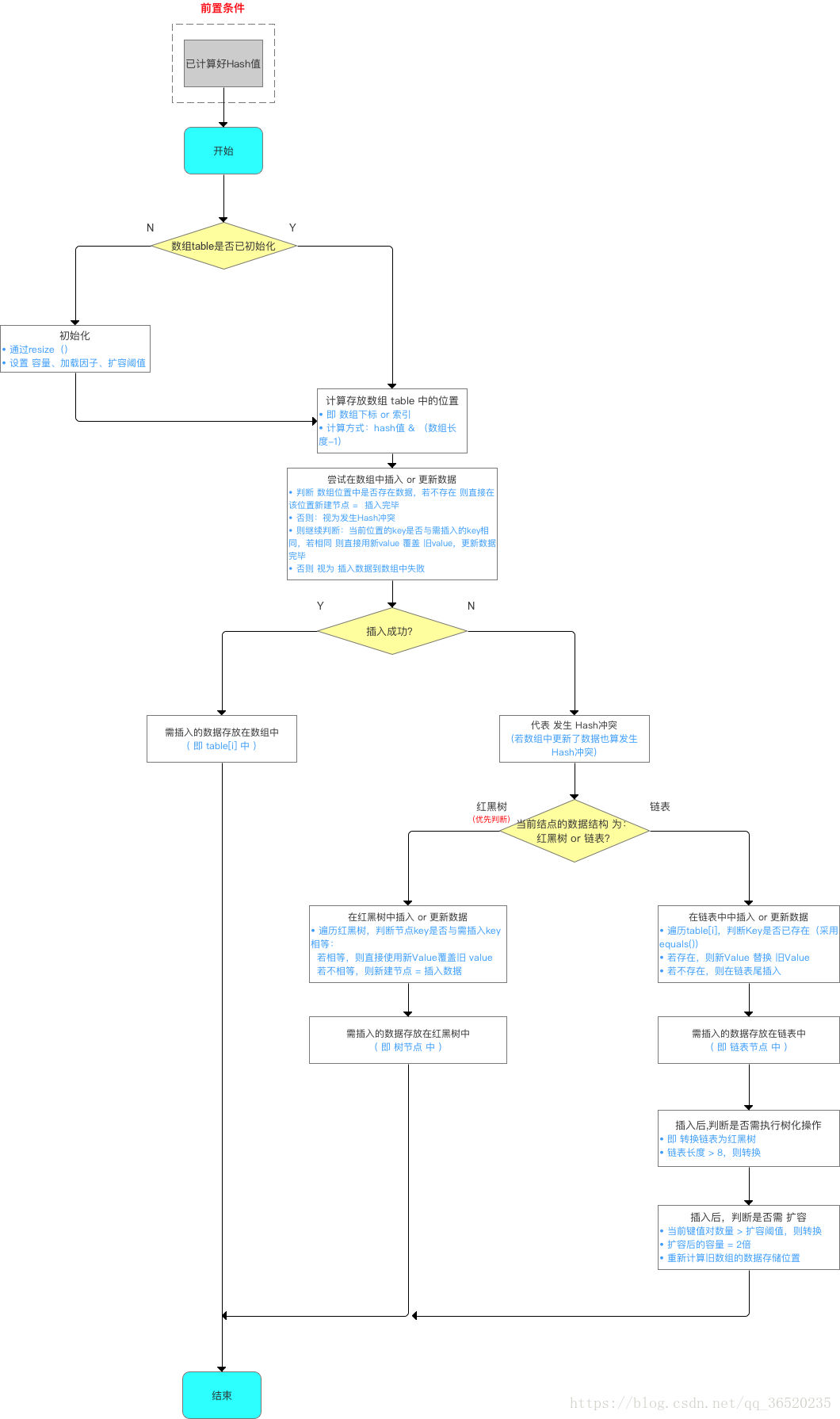
扩容流程对比:

JDK1.7 的时候使用的是数组+单链表的数据结构。但是在 jdK1.8 之后时,使用的是数组+链表+红黑树的数据结构,当链表深度达8的时候,也就是默认伐值,就会自动扩容把链表转换成红黑树的
数据结构把时间复杂度从O(n) 变成 O(logN),提高效率
补充:
01.为什么在 JDK1.7 的时候是先进行扩容后进行插入,而在 jdk1.8 的时候是先插入再进行扩容呢?
//其实就是当这个Map中实际插入的键值对的值的大小如果大于这个默认的阈值的时候(初始是16*0.75=12)的时候才会触发扩容, //这个是在JDK1.8中的先插入后扩容 if (++size > threshold) resize();
其实这个问题也是 jdk8 对 hashMap 中,主要是因为对链表转化为红黑树进行的优化,因为插入这个节点的时候有可能是普通链表节点,也有可能是红黑树节点,但是为社么1.8之后HashMap 变为先插入后扩容的原因?,,
但是在 jdK1.7中的话是先扩容后进行插入的,就是当你发现你插入的桶是不是为空,如果不为空说明存在的值发生了hash 冲突,那么必须得扩容,但是如果不发生 hash 冲突的话,说明当前桶是空的,那就等到下次hash
冲突的时候扩容。
为社么 jdk 1.8 在进行对 HashMap 优化的时候,把链表转换为红黑树的阈值是8,而不是7 或者20等等?
二、哈希表如何解决 Hash 冲突?

三、为什么 HashMap 具备如下特点: 键值都运行为空,线程不安全,不保证有序,存储位置随时间变化

四、为什么 Hashmap 中 String 、Integer 这样的包装类适合作为 key 键

参考:https://blog.csdn.net/qq_36520235/article/details/82417949
参考:https://www.jianshu.com/p/8324a34577a0?utm_source=oschina-app

