


浅谈HashMap的底层实现原理概述
HashMap的底层实现原理
先谈谈底层实现原理的过程,在深入了解源码
一、jdk 7底层实现原理(数组+链表)
-
HashMap map = new HashMap();在实例化以后,底层创建了长度是16的一维数组Entry[ ] table。
-
...可能已经执行过多次put... map.put(key1,value1)首先,调用key1所在类的hashCode( )计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。
(1)如果此位置上的数据为空,则此时的key1-value1添加成功。 情况1
(2)如果此位置上的数据不为空(意味着此位置上存在一个或多个数据【以链表形式存在】),比较key1和已经存在的一个或多个数据的哈希值:
1>如果key1的哈希值和已经存在的数据的哈希值都不相同,此时key1-value1添加成功。 情况2
2>如果key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2):
1>如果equals()返回false:此时key1-value1添加成功。 情况3
2>如果equals()返回true:使用value1替换value2。
- 补充:关于情况2和情况3,此时key1-value1和原来的数据以链表的方式存储。
在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
二、jdk 8相较于jdk 7在底层实现方面的不同
-
new HashMap( ):底层没有创建一个长度为16的数组。
-
jdk 8底层的数组是:Node[ ],而非Entry[ ]。
-
首次调用put( )方法时,底层创建长度为16的数组。
-
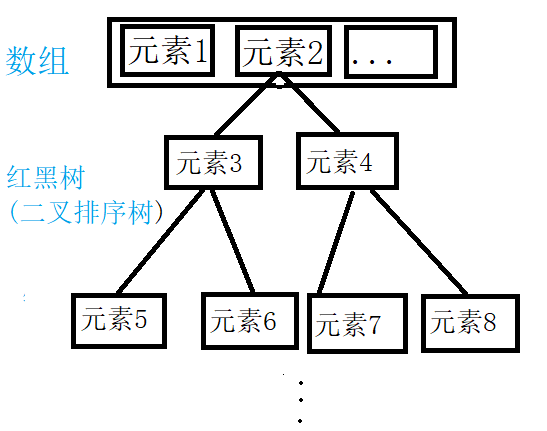
jdk 7底层结构只有:数组+链表。jdk 8中底层数据结构:数组 + 链表 + 红黑树。
-
使用红黑树的情况:当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8,且当前数组的长度 > 64时,此时此索引位置上的所有数据改为使用红黑树存储。
-
使用红黑树的原因:在jdk 7中,在添加元素时,可能要和已存在的数据比较哈希值,如果已存在的数据是链表形式的话,需要依次进行比较,这样太繁琐【示意图1】。而在jdk 8中,使用红黑树(有序二叉树)后,添加元素时,如果哈希值比已存在数据的哈希值小,则从左边开始找,否则从右边找。这就相当于是优化了,提高了查找效率【示意图2】。
示意图1 示意图2

-
