
Cocos Creator 性能调优之《如何优化2D/3D Drawcall》
游戏渲染是性能开销的大头,在项目开发中掌握性能调优中渲染优化相关技巧是非常重要的。渲染优化又可以从很多方面来入手,其中降低Drawcall是非常重要的手段之一。接下来从4个点来详细的讲解基于Cocos Creator 3.x如何做Drawcall的性能优化:
为什么降低Drawcall能提升渲染性能;
常用合批技术的原理以及优点与缺点分析;
Cocos Creator 3.x 如何优化3D物体Drawcall;
Cocos Creator 3.x 如何优化2D UI物体Drawcall。
对啦!这里有个游戏开发交流小组里面聚集了一帮热爱学习游戏的零基础小白,也有一些正在从事游戏开发的技术大佬,欢迎你来交流学习。
为什么降低Drawcall能提升渲染性能
游戏引擎绘制一个游戏画面,遍历游戏场景中所有要绘制的物体,然后把这些物体提交给GPU来进行绘制。假设游戏场景中有100个需要位置的物体,假设游戏引擎把这100个物体一个一个的提交给GPU来进行绘制,绘制物体的时候游戏引擎底层会做下面的事情:
a:CPU 传递物体的渲染所需要的数据给GPU, 如网格模型,材质里面的一些参数,纹理对象, 物体的位置旋转缩放对应的矩阵, 摄像机的投影变换矩阵等数据。
b:CPU 把数据准备好以后,接下来向GPU来下达绘制命令(Draw cmd) 。
c: GPU 开机来渲染CPU提交过来的物体到我们的显示目标上。
CPU传递数据到GPU,CPU向GPU下达绘制命令,GPU绘制物体到屏幕都会产生性能开销。
在分析降低Drawcall为什么能提升渲染性能的原理之前先给大家介绍几个概念:
a: Drawcall: CPU提交数据给GPU,然后向GPU下渲染命令这个过程我们通常叫做DrawCall, 又叫同一个批次渲染。
b: Drawcall数目(批次数): 游戏引擎绘制完一个游戏场景中的所有物体需要向GPU提交几次渲染命令(Drawcall)。100个物体,一个个提交给GPU一个一个绘制,那么就要向GPU提交100次渲染命令(Drawcall)所以Drawcall数幕是100。又一种说话就是绘制一个游戏场景的物体分成了多少个批次来进行渲染的。
c: 合批(降低Drawcall数目): 把几个物体合在一起提交给GPU渲染绘制叫做合批。通过合批,可以降低绘制游戏场景的Drawcall数目。比如100个物体,我把前50个物体合在一起提交给GPU渲染,后50个物体合一起提交给GPU渲染,那么渲染100个物体用通过2批渲染绘制完成,也就是2次Drawcall。合批其实就降低了Drawcall的数目,我们通常说的降低Drawcall指的就是合批。
摆好这几个概念以后,接下来我们来分析合批对渲染性能有哪些方面的提升,提升点如下:
a:CPU把能合批的物体一起提交给GPU,避免重复的数据提交,如同一个模型的多个物体。CPU给GPU提交数据开销比较大。(大于CPU对内存的数据拷贝)
b:100个物体一个一个物体的绘制就要下达100次Draw Cmd, 而把100个物体合成一批提交给GPU,只要下达一次Draw Cmd,也就是GPU只要“开机”一次就能把所有的渲染完成,GPU不用“开机”100次。
c: 每个GPU每次“开机”绘制,都有一个吞吐量,如果我们尽可能的每次提交多提交一些三角形的面数,GPU一次渲染能吃更多的面,这样提升GPU的效率。就像工厂的流水线,只要开机,产100个商品和产1个商品的代价一样,那么在安排订单的时候,尽量每次开机凑够100个。所以合批提交渲染,能提升GPU的吞吐量,提升效率。
所以从上分析可以得出结论:尽可能的把物体合批到一起渲染(降低Drawcall数目)对于渲染优化是非常有效果的。Cocos Creator可以通过调试参数来看到当前渲染整个游戏场景分几次提交给GPU(Drawcall数目)如下图:

常用合批技术的原理以及优点与缺点分析
上面分析了合批对渲染性能提升的意义,接下来分析合批常用的技术原理以及优缺点。合批常用的技术手段如下:静态合批, 动态合批, GPU Instancing合批。在分析合批技术之前先来介绍一个概念以下称“能够合批”,我们把使用同一个材质且使用能合批的渲染组件(如MeshRenderer)的一些物体叫做”能够合批”。 合批的物体首先要满足能够合批的条件,否者任何技术手段都无法合批。
静态合批: 将“能够合批”物体的所有的网格按照它的位置预先重新合并生成一个大的新网格对象存到内存, 由于这些物体满足合批条件,都是同一个材质球,这样渲染这些物体只要把合并后的这个新网格对象一次提交给GPU,那么就能够实现把这些物体合批处理,降低Drawcall。
静态合批的优点分析:
a:能将一组渲染物体合批,获得合批所带来的渲染性能的提升
静态合批的缺点分析:
a:静态合批需要预先计算合并网格,延迟了运行初始化时的时间;
b:静态合批一但预先计算好合并后的网格,这些物体就不能再“移动”了除非每次重新计算合并网格(CPU也是开销),所以叫做静态合批。因为它不适合有经常移动的物体的合批。
c: 静态物体网格合并后可能会增大内存开销。这个点很多人不理解,觉得100个物体的Mesh数据合并后还是100个物体的Mesh数据不应该增加内存开销的,怎么会合并后会“可能”增大内存开销呢?这里首先有“可能”两个字,也就是说某些情况下会增加,某些情况下不会增加。试想一下如果100个物体完全不一样,合并后的Mesh顶点的内存开销和合并前都是一样的。但是如果100个物体的Mesh完全一样,合并前只有一个Mesh的顶点数据,合并后就有100个同一个Mesh不同位置的顶点数据了,这种合并就会增大内存开销。所以我们在做森林等场景的时候面对大量的树的时候我们不使用静态合批。
动态合批: 每次渲染之前,CPU将能够合批的物体的每个顶点的世界坐标计算出来(模型顶点坐标*世界变化矩阵),然后再把合批物体的顶点的世界坐标提交给GPU,然后世界矩阵用单位矩阵,来达到合批的效果。
动态合批的优点分析:
a:能获得合批所带来的渲染性能的提升;
b:适合移动的物体,因为每次渲染之前都会重新计算坐标;
c:没有额外的内存开销;
动态合批的缺点分析:
a:每次渲染物体,CPU都要计算一次模型坐标到世界坐标,所有增加了CPU的负担。使用动态合批的时候,要把CPU的额外的开销和合批带来的提升做一个权衡,所以动态合批不是万能的,不适合太多顶点数目的物体的渲染绘制。
GPU Instancing合批: 对于游戏场景中同一个物体的N个实例可以采用GPU Instancing的合批技术,它的原理是提交一次物体的模型,然后将实例的位置,旋转,缩放等信息提交给GPU,然后GPU绘制出N个实例出来。从技术原理来看GPU Instancing会非常好的合批手段,几乎不会带来额外的开销。
GPU Instancing合批优点分析:
a:能获得合批所带来的渲染性能的提升,不增加额外的开销;
GPU Instancing 合批的缺点分析:
a: 只能是同一个物体的N个不同实例才能合批;
b: 有些早期的显卡不支持GPU Instancing的特性;
c: GPU Instancing需要Shader的支持;
Cocos Creator 3.x 如何优化3D物体Drawcall
理解了合批的技术原理和优缺点以后,接下来我们来讲解如何具体的基于Cocos Creator来做Drawcall优化实操。摆在我们面前的首要问题有:
a:分析Drawcall消耗在哪些地方;
b:为尽可能多的物体创造“能够合批”的条件;
如何摸清楚哪些物体绘制消耗了多少Drawcall,一般我们会通过场景的组织来判断分析估算,同时通过显示/隐藏物体查看Drawcall数目变化来确认我的分析。如图隐藏前后Drawcall变化由3变化到1,说明了绘制隐藏的物体花了2个Drawcall。
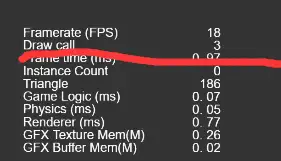
做游戏项目的时,隐藏地图节点,看Drawcal变化就知道地图花了多少Drawcall,隐藏角色节点,看Drawcall变化就知道角色占了多少Drawcall,这样你就摸清楚项目渲染的Drawcall分布。
让更多的物体有合并的可能,我采取的方式一般是将多个物体的材质球尽可能的合并,材质球主要包含shader+纹理,我们能做的其实就是合并shader和纹理对象,让更多的物体使用同一个shader,然后不同物体的纹理合并到一起,这样这些物体都使用同一个材质球,为合批创造“能够合批”的条件。改变渲染组件类型,让更多的物体满足合批所支持的渲染组件,
如将SkinnedMeshRenderer组件变成MeshRenderer组件。
摸清楚了Drawcall分布与尽可能的创造合批条件后,同时我们对合批技术的原理都了解清楚了, 我们就可以采用对应的技术来进行合批了。静态合批Cocos Creator 非常简单,你只要把需要静态合批的物体放到一个节点下,然后在初始化接口里面调用静态合批API接口预先计算好新合批后的物体,这样就可以做到合批了。如图:
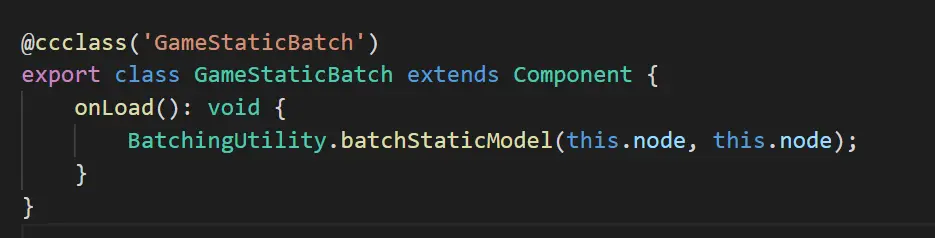
在初始化中预先计算好节点下面所有的物体的新的Mesh;
没有开启静态合批之前锥体+立方体需要2个drawcall,开启后锥体与立方体渲染只要1个drawcall,节约1个Drawcall


Cocos Creator的动态合批非常简单, 只要在材质球上勾选上 use Batch即可,如下图所示:
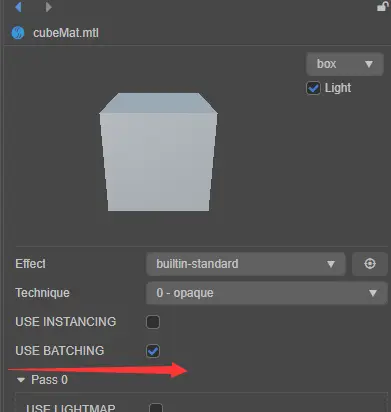
这样锥体+cube也可以合批到一起。
Cocos Creator GPU Instancing合批也是一样,只要在材质球上勾选上USE INSTANCING就可以了,如下图所示:

但是由于GPU Instancing的原理是只对一个Mesh的多个实例有用,所以圆锥+Cube仍然还是3个Drawcall, 但是两个Cube开启GPU Instancing后合并称一个Drawcall,如下图:

(不是同一个网格对象,不能合批)
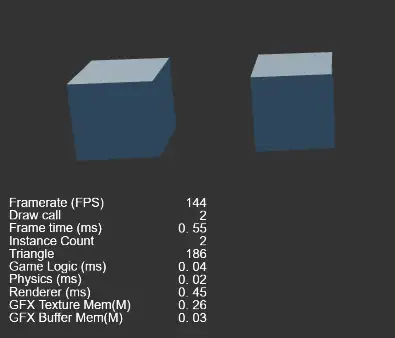
(同一个网格对象,可以合批)
Cocos Creator 3.x 如何优化2D UI物体Drawcall
2D是特殊的3D,所以上面在3D分析的一些技术手段在2D都可以适用。2D的Drawcall优化会更简单些,UI的合并条件只要UI元素使用同一个图集(同一个纹理),就可以合批。UI 元素使用的Shader都使用了Buildin-Sprite Shader这里面也包括了Label也使用这个Shader。所以“能够合批”就要看UI物体是否为同一个图集。精灵图集开发者知道在哪里,Label图集,引擎会自动生成图集,所以你可以理解为Label的图集和精灵的图集不是同一个图集。多个不同的Label如果开启了文本缓存模式就有可能文字被引擎生成到同一个图集。所以对于2D而言同一个图集的“能够合批”,Label会中断打乱“精灵的合批”。2D UI Drawcall优化的核心就3点:
a:打图集,尽量将同一个界面的UI元素打入同一图集;
b:优化2D的节点组织层级, UI是按照层级来渲染的,尽量防止不同图集的UI元素互相的打乱,以及Label的打断。如组织UI元素尽可能的是:
A1A2A3A4A5A6 B1B2B3B4B5B6 C1C2C3C4C5C6, A,B,C不同的图集在一起
不要这样来组织UI元素或图集内容
A1B1C1A2B2C2A3B3C3A4B4C4...
c: 注意Label打乱的UI物体的合批。
今天的分享就到这里了,如果大家觉得看文章还不过瘾,我这边配了一个2小时的视频讲解实操教程,现场实操一次,大家可以点击进入学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号