超级简单的多元线性回归应用
首先表达一下自己对多元线性回归的理解:
方程:![]()
y为正确的结果。p0为常数项,e为误差,p1,p2,p3等是我们要通过sklearn训练数据集得出来的回归系数,x1,x2,x3等是我们训练集里的特征向量。
这次我用到的数据集是kaggle的入学几率预测数据集:
去kaggle搜索admission就是了
https://www.kaggle.com/datasets
长这个样子:
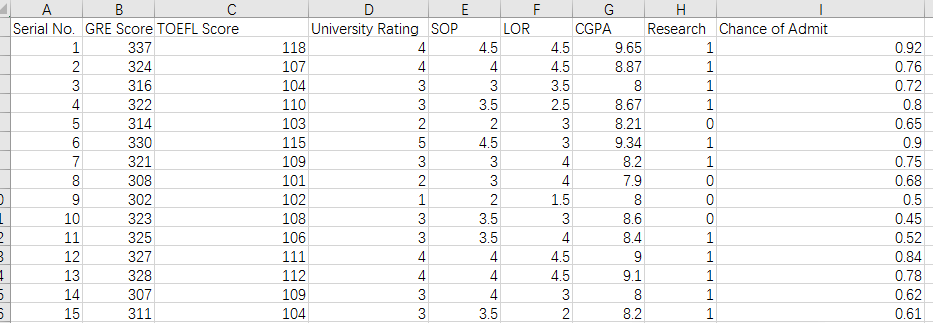
其中Chance of Admit 是最终要自己预测的label
思路非常之简单,上代码~
一:数据探索
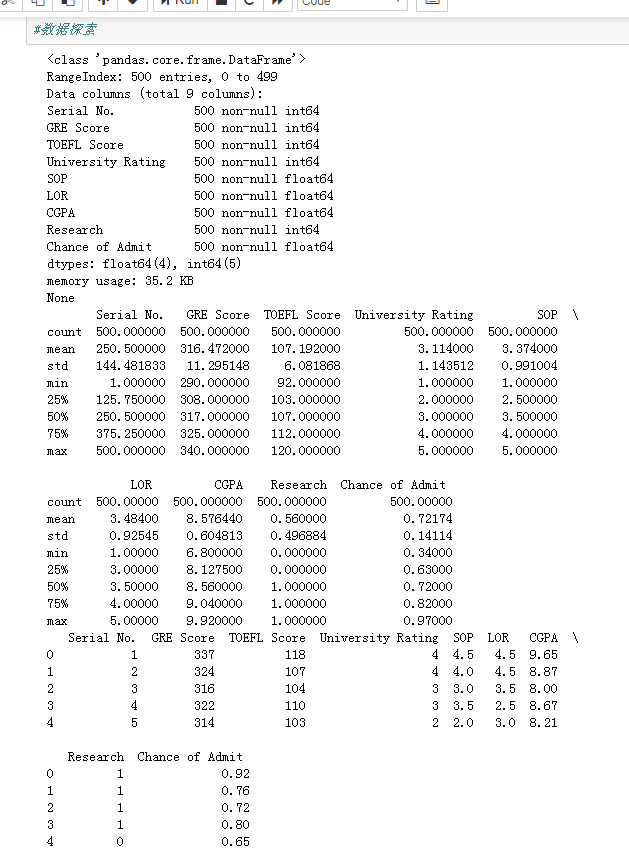
import pandas as pd import numpy as np import matplotlib.pyplot as plt csv_data = pd.read_csv('./data/Admission_Predict.csv') # 读取csv文件内容 print(csv_data.info()) # 了解数据表的基本情况:行数、列数、每列的数据类型、数据完整度。可以看到每列都有500行,可以说是没有缺失值的。 print(csv_data.describe()) # 了解总数、平均值、标准差等一些统计数据 print(csv_data.head()) # 了解数据的模样~ csv_data.drop('Serial No.',axis=1,inplace=True) # 去掉没什么用的ID一列 #数据归一化,简单地除以它们的最大值... csv_data['GRE Score'] = csv_data['GRE Score']/340 csv_data['TOEFL Score'] = csv_data['TOEFL Score']/120 csv_data['University Rating'] = csv_data['University Rating']/5 csv_data['SOP'] = csv_data['SOP']/5 csv_data['LOR '] = csv_data['LOR ']/5 csv_data['CGPA'] = csv_data['CGPA']/10 #数据探索
运行结果:
二:简单进行可视化
import seaborn as sns print(csv_data.columns) sns.regplot('GRE Score','Chance of Admit ',data=csv_data)

查看所有特征的联系:
sns.pairplot(csv_data,diag_kind='kde',plot_kws={'alpha':0.2})
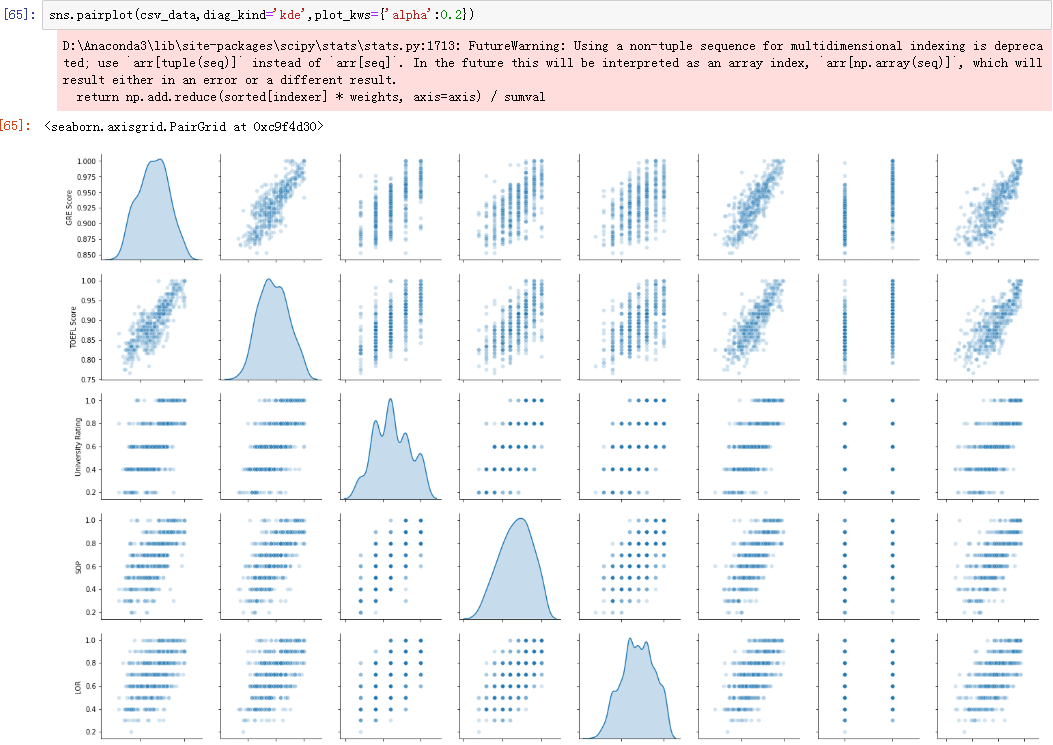
从图可以看到,的确有那么一点回归的样子~
三:模型构建
from sklearn import linear_model features = ['GRE Score', 'TOEFL Score', 'University Rating', 'SOP', 'LOR ', 'CGPA', 'Research',] # 特征选择 X = csv_data[features].iloc[:420,:-1] Y = csv_data.iloc[:420,-1] #选择训练集 X_test = csv_data[features].iloc[420:,:-1] Y_test = csv_data.iloc[420:,-1] #选择测试集 regr = linear_model.LinearRegression() #构造线性回归模型 regr.fit(X,Y) #模型训练 print(regr.predict(X_test)) # 预测 print(list(Y_test)) #答案 print(regr.score(X_test,Y_test)) #准确度
结果:

嘿,达到88%的准确度了呢,有用,开心/
The End~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号