Python-定义中的传参&递归
pass占位符
在python中在定义函数时候可以这样写
def boo(self,x,y): pass
使用pass来进行占位,这样代码能执行不会报错
可变参数传参*args关键字传参**kw
非关键字*args是默认写法,一般*name,args可以接受任意数量的参数,并将他们存储在tuple中。
关键字**kw将接收到的任意数量参数存到一个dict中。
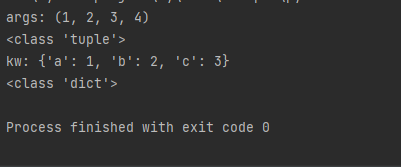
def try_this(*args, **kw): print('args:', args) print(type(args)) print('kw:', kw) print(type(kw)) try_this(1, 2, 3, 4, a=1, b=2, c=3)
可以看到这里输出的结果虽然kw是{},而且也有key和value,但是并不表示这是一个字典,
kw是一个dict,因为dict内的key-value是没有顺序的
注意定义函数时:python中的一般参数、默认参数、非关键字参数和关键字参数可以一起使用,或者只用其中某些,但是请注意,参数定义的顺序必须是:一般参数、默认参数、可变参数和关键字参数,先后顺序不能颠倒。即:
def func(a, b, c=0, *args, **kw): pass
顺带说一下python中的拷贝
a = [1, 2] b = a a.append(3) print(a, b)
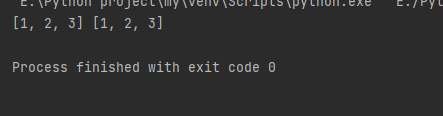
a和b所指的还是同一个对象
深层的拷贝需要用copy.deepcopy
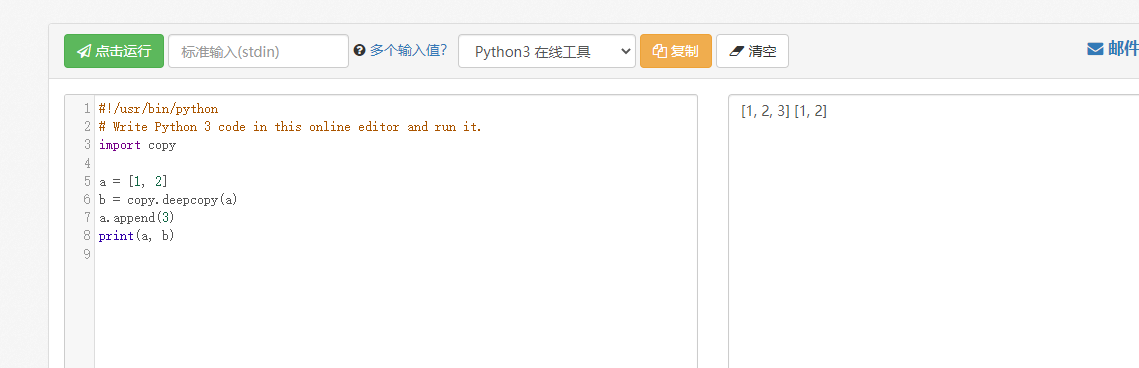
以下链接写的很清楚:
https://www.runoob.com/w3cnote/python-understanding-dict-copy-shallow-or-deep.html
递归
简单来说这就是(递龟)递归~~

嘿嘿,用一张力扣上的图,刷力扣的时候自己怎么想都想不到递归,想不出来递归解想去死,看到了别人给的递归解也想去死。
函数在运行的时候自己调用自己,而调用过程是一个进栈出栈的
比如函数 F(x)=f(x-1)+x
也就是
def f(x): return f(x - 1) + x
但是这样函数永远不会结束,因为他没有结束的条件
要使用递归一定要写好结束条件!!就跟使用循环一样 每个语法上都有结束条件i>n
其实所有的递归函数都能写成循环函数,只是递归更加逻辑清晰。
这里加上结束条件:
def f(x): if x > 0: return f(x - 1) + x else: return 0 print(f(3))
结果就是为6,来debug一下具体遍历过程
先是进栈的过程,到了最后,f(0)=0,
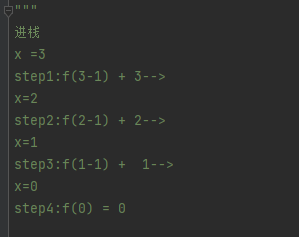
然后开始出栈,大家都知道是先进后出
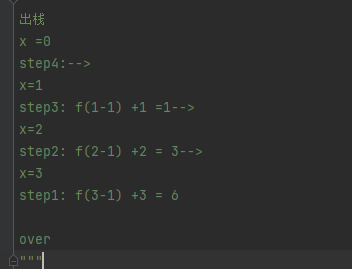
debug查看流程
x=3
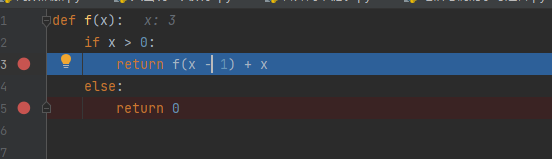
x=1

再到x=0,这时候全部进栈了
接下来就是一步步出栈
x=1
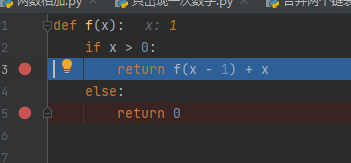
x=2
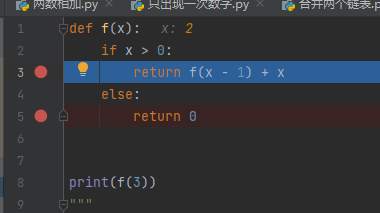
x=3
递归的确很简洁方便,他就像是学霸的解,但是他没有缺陷吗?
当然有,递归次数过多可能会导致栈溢出,也就是我们,
return语句中包含了表达式,如何优化呢?
更改代码
使得return中没有表达式,这种递归称之为尾递归
来看看这个阶乘函数
function fact(n) { if (n <= 0) { return 1; } else { return n * fact(n - 1); } }
这就是return 了表达式,未作尾递归优化的,会不断增加栈长
这是尾递归的
function fact(n, r) { if (n <= 0) { return 1 * r; } else { return fact(n - 1, r * n); } }
跟上面的普通递归函数比起来,貌似尾递归函数因为在展开的过程中计算并且缓存了结果,使得并不会像普通递归函数那样展开出非常庞大的中间结果,所以不会爆栈是吗?
当然不是!不会爆栈是因为语言的编译器或者解释器所做了“尾递归优化”,才让它不会爆栈的。
遗憾的是,大多数编程语言没有针对尾递归做优化,Python解释器也没有做优化。

