
java 泛型 反射 动态代理 注解
https://www.cnblogs.com/20183544-wangzhengshuai/p/16033270.html
Java 高级特性有挺多,但是这几个一直没搞太通透,只会简单用用,为什么这么设计,有没有什么有意思的玩法都没探究过,今天就来整理一下。
泛型
说到泛型,肯定很熟悉了,我们天天用的 List:
List<String> list=new ArrayList<>();ArrayList就是个泛型类,我们通过设定不同的类型,可以往集合里面存储不同的数据类型(而且只能存储设定的数据类型,这是泛型的优势之一)。“泛型”简单的意思就是泛指的类型(参数化类型)。
有人灵机一动,就问这里为什么不用Object,到时候再转呐?
问得好,在泛型出现之前,的确是这么做的。但是这样的有一个问题:如果集合里面数据很多,某一个数据转型出现错误,在编译期是无法发现的,但是在运行期会发生java.lang.ClassCastException。
泛型一方面让我们只能往集合中添加一种类型的数据,同时可以让我们在编译期就发现这些错误,避免运行时异常的发生,提升代码的健壮性。
我们可以从以下几个方面理解泛型:
- 泛型通配符
- 泛型类
- 泛型接口
- 泛型方法
- 泛型擦除
- 泛型数组
泛型符号
可能有人注意到有不同的泛型符号,其实泛型可以使用任何大写字母定义,把 T 换成 A 也一样,这里 T 只是名字上的意义而已。以下是一般约定俗成的符号意义:
E - Element (在集合中使用,因为集合中存放的是元素) T - Type(Java 类) K - Key(键) V - Value(值) N - Number(数值类型) ?- 表示不确定的 Java 类型
对于?类型的泛型,我们称之为通配符,又有以下三种情况:
无限通配符<?>
无限通配符可以表示所有的类型。可能一般会有疑惑,泛型本来就具备泛化的功能,可以表示所有类型,那么<T>和<?>区别是什么?无限通配符的主要作用就是让泛型能够接受未知类型的数据。
?和 T 都表示不确定的类型,区别在于我们可以对 T 进行操作,但是对 ?不行,比如如下这种 :
// 可以
T t = operate();
// 不可以
? car = operate();T 是用于定义的时候,而 ? 用于使用的时候,我们可以这样:
class Test<T> {
T t;
}但是不可以:
class Test<?> {
? t;
}在调用的时候想法,我们可以用 ? 表示一个未知的泛型:
Test<?> test = new Test<>();这时候就不能用 T 了。但是注意,这里Test<?>类型的test独享是不能对其属性进行赋值的,也就是说下面的操作是不允许的:
Test<?> test = new Test<String>();
test.t="123";//Incompatible types. Found: 'java.lang.String', required: 'capture<?>'虽然我们创建了一个泛型类型为 String 的对象,但是不能对其赋值。可以看出Test<?>只是用于声明变量的时候用,你不能用它来实例化,尤其是用于当你不知道声明的泛型类型的时候。
上界通配符<? extends T>
使用固定上边界的通配符的泛型,就能够接受指定类及其子类类型的数据。要声明使用该类通配符,采用<? extends E>的形式,这里的 T 就是该泛型的上边界。注意:这里虽然用的是extends关键字,却不仅限于继承了父类 T 的子类,也可以代指显现了接口 T 的类。
举个栗子,我们定义两个类,水果和苹果,水果是苹果的父类。然后定义一个泛型类:
class Test<T> {
}
class Fruit{
}
class Apple extends Fruit{
}测试一下上界通配符可以发现:
Test<Fruit> fruit = new Test<>();
Test<Apple> apple = new Test<>();
Test<Object> object = new Test<>();
Test<? extends Fruit> newTest;
newTest=fruit;//可以
newTest=apple;//可以
newTest=object;//ide报错下界通配符<? super T>
跟上界通配符是相对应的,只接受指定类及其父类,很好理解。直接看栗子,还是用苹果和水果举例:
Test<Fruit> fruit = new Test<>();
Test<Apple> apple = new Test<>();
Test<Object> object = new Test<>();
Test<String> string = new Test<>();
Test<? super Fruit> newTest;
newTest=fruit;//可以
newTest=apple;//可以
newTest=object;//可以
newTest=string;//ide报错跟上面有一点点不同的是,由于Object是所有类的父类,所以也可以。
另外跟上界通配符不同的是,下界通配符<? super T>不影响往里面存储,但是读取出来的数据只能是 Object 类型。
原因是,下界通配符规定了元素最小的粒度,必须是 T 及其基类,那么我往里面存储 T 及其派生类都是可以的,因为它都可以隐式的转化为 T 类型。但是往外读就不好控制了,里面存储的都是 T 及其基类,无法转型为任何一种类型,只有 Object 基类才能装下。
最后简单介绍下 Effective Java 这本书里面介绍的 PECS 原则。
- 上界
<? extends T>不能往里存,只能往外取,适合频繁往外面读取内容的场景。 - 下界
<? super T>不影响往里存,但往外取只能放在Object对象里,适合经常往里面插入数据的场景。
泛型类
类结构是面向对象中最基本的元素,如果我们的类需要有很好的扩展性,那么我们可以将其设置成泛型的。
泛型类定义时只需要在类名后面加上类型参数即可,当然你也可以添加多个参数,类似于<K,V>,<T,E,K>等。这样我们就可以在类里面使用定义的类型参数。当然需要注意,泛型的类型参数只能是 Object 类(包括自定义类),不能是基本类型。
泛型接口
泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,如下:
//定义一个泛型接口
public interface Generator<T> {
public T next();
}当实现泛型接口的类,未传入泛型实参时,需将泛型的声明也一起加到类中:
/**
* 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
* 即:class FruitGenerator<T> implements Generator<T>
* 如果不声明泛型,如:class FruitGenerator implements Generator<T>,编译器会报错:"Unknown class"
*/
class FruitGenerator<T> implements Generator<T>{
@Override
public T next() {
return null;
}
}在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型:
/**
* 传入泛型实参时:
* 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型
* 即:Generator<T>,public T next();中的的T都要替换成传入的String类型。
*/
public class FruitGenerator implements Generator<String> {
@Override
public String next() {
return "Fruit";
}
}泛型方法
在java中,泛型类的定义非常简单,但是泛型方法就比较复杂了。
泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型。
需要注意的是:
public与返回值中间<T>非常重要,可以理解为声明此方法为泛型方法。- 只有声明了
<T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。 <T>表明该方法将使用泛型类型 T,此时才可以在方法中使用泛型类型 T。- 与泛型类的定义一样,此处 T 可以随便写为任意标识,常见的如 T、E、K、V 等形式的参数常用于表示泛型。
/**
* 泛型方法的基本介绍
* @param tClass 传入的泛型实参
* @return T 返回值为T类型
*/
public <T> T genericMethod(Class<T> tClass)throws InstantiationException ,
IllegalAccessException{
T instance = tClass.newInstance();
return instance;
}泛型类中的泛型方法
如果在泛型类中声明了一个泛型方法,使用泛型 E,这种泛型 E 可以为任意类型。可以类型与 T 相同,也可以不同,比如一个最***钻的情况:
class Test<T> {
<E> void func1(T t) {//这里传入的参数 t 跟类的泛型保持一致。所以这里的 E 是没有意义的,idea 会提示可以直接删掉。
}
<T> void func2(T t) {//这里的两个泛型 T 都是新的泛型,和类的泛型 T 没有关系。这么写的话很容易引起误会,所以 idea 也会提示建议重命名。
}
<E> void func3(E t) {//这个很清晰,E 和 T 是无关的泛型。
}
}静态方法与泛型
静态方法有一种情况需要注意一下,那就是在类中的静态方法使用泛型:静态方法无法访问类上定义的泛型,如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
public class Test<T> {
/**
* 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法)
* 即使静态方法要使用泛型类中已经声明过的泛型也不可以。
* 如:public static void show(T t){..},此时编译器会提示错误信息:
"StaticGenerator cannot be refrenced from static context"
*/
public static <T> void show(T t){
}
}泛型擦除
泛型擦除,或者叫泛型的类型擦除,出现的根本原因是为了保证兼容性。
泛型是 Java 1.5 版本才引进的概念,在这之前是没有泛型的概念的,但显然,泛型代码能够很好地和之前版本的代码很好地兼容。这是因为,泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。
在泛型类被类型擦除的时候,之前泛型类中的类型参数部分如果没有指定上限,如<T>则会被转译成普通的 Object 类型,如果指定了上限如<T extends String>则类型参数就被替换成类型上限。
如在代码中定义的List<object>和List<String>等类型,在编译后都会编程List。JVM 看到的只是List,而由泛型附加的类型信息对 JVM 来说是不可见的。Java 编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法避免在运行时刻出现类型转换异常的情况。类型擦除也是 Java 的泛型实现方法与 C++ 模版机制实现方式之间的重要区别。
泛型数组
关于泛型数组,还要提醒一下,在java中是“不能创建一个确切的泛型类型的数组”的。
也就是说下面的这个例子是不可以的:
List<String>[] ls = new ArrayList<String>[10];而使用通配符创建泛型数组是可以的,如下面这个例子:
List<?>[] ls = new ArrayList<?>[10];这样也是可以的:
List<String>[] ls = new ArrayList[10];反射
关于反射,基本的用法应该都熟悉了,可以通过全类名找到对应的类,然后实例化一个对象,还可以访问其变量,调用他的方法。甚至可以绕过private关键字的限制等等。
虽然有一点基础了解,但是一直不知道反射什么原理,为什么要设计这样一个功能。
首先我们先明确反射提供的功能:
- 在运行时判断任意一个对象所属的类;
- 在运行时构造任意一个类的对象;
- 在运行时判断任意一个类所具有的成员变量和方法(通过反射甚至可以调用private方法);
- 在运行时调用任意一个对象的方法。
首先为什么需要有反射?我们看下动态编译与静态编译的概念:
- 静态编译:在编译时确定类型,绑定对象。即通过
new关键字实例化一个对象。 - 动态编译:运行时确定类型,绑定对象。动态编译最大限度发挥了java的灵活性,体现了多态的应用,有以降低类之间的藕合性。
另外不妨用大家接触最早的一个反射用例作为例子。刚接触 JDBC 的时候可能就有疑问,为什么连接数据库一定要先注册驱动,也就是用Class.forName(驱动类)来加载驱动类?
这里的原因就是包括:
- 解耦:所有不同数据库的驱动类都是 JDK 提供的通用接口
NonRegisteringDriver的实现,使用反射可以方便解耦,后需更换数据库驱动不需要修改代码,改个配置文件就行了。另外这里也是桥接模式的一个体现。 - 节省资源:我们加载驱动其实只是需要执行其静态代码块里的初始化代码,其他的都不会马上用到,所以更节省资源。
另外,其实用new com.mysql.jdbc.Driver();的方式加载驱动,也不是不可以,只不过不是最优选择。
另外,使用代理的优缺点也很明显:
- 优点 可以实现动态创建对象和编译,体现出很大的灵活性。采用静态的话,需要把整个程序重新编译一次才可以实现功能的更新,而采用反射机制的话,它就可以不用卸载,只需要在运行时才动态的创建和编译,就可以实现该功能。
- 缺点 对性能有影响。使用反射基本上是一种解释操作,我们可以告诉 JVM,我们希望做什么并且它满足我们的要求。这类操作总是慢于只直接执行相同的操作。
用途
关于反射主要的用途,有一个知乎回答说得很好:
比如你在开发一个 xxfreamwork,后续要初始化并管理其他开发者创建的类 Y y 的对象。你肯定不会在 freamwork 开发阶段就知道将来大家定义的类名,这时候可以把类名做参数初始化对象。
像 Spring Framework 就是大量用到了反射,之前用 xml 配置 bean,Spring 框架就是通过反射来创建一个 bean 的实例,然后放到池子里进行管理。这时候就不能用 new 关键字来创建了,以为你根本不知道对方会有哪些类。
除此之外,下面我们要说的动态代理也是另外一大重要用途,这个在下面详细说。
原理
对于最简单的一次反射使用样例:
Class actionClass=Class.forName("MyClass");
Object action=actionClass.newInstance();
Method method = actionClass.getMethod("myMethod",null);
method.invoke(action,null);前两行实现了类的加载、链接和初始化(newInstance方法实际上也是使用反射调用了<init>方法),后两行实现了从 class 对象中获取到 method 对象然后执行反射调用。
从上面的代码可以看出,如果我们自己想要实现invoke方法,其实只要实现这样一个 Method 类即可:
Class Method{
public Object invoke(Object obj,Object[] param){
MyClass myClass=(MyClass)obj;
return myClass.myMethod();
}
}看起来很简单吧,那么实际上 JVM 是怎么做的呐?
首先来看一下Method对象是如何生成的:
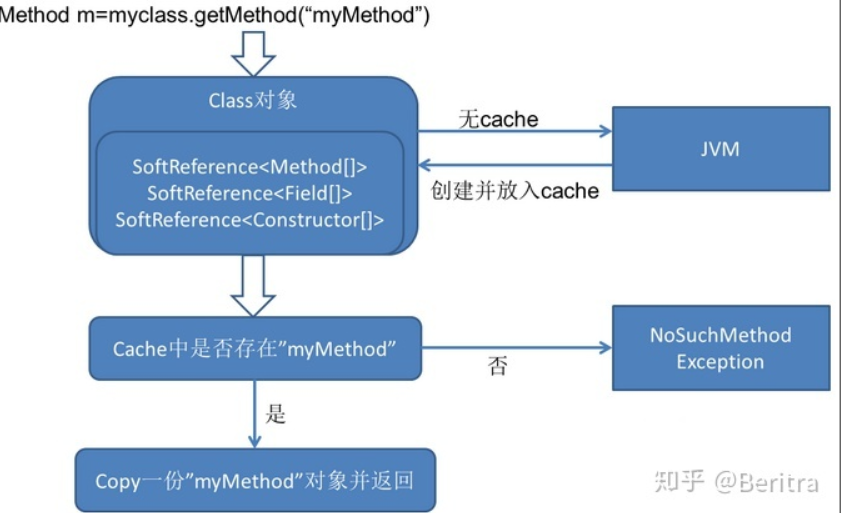
上面的 Class 对象是在加载类时由 JVM 构造的,JVM 为每个类管理一个独一无二的 Class 对象,这份 Class 对象里维护着该类的所有 Method,Field,Constructor 的 cache,这份 cache 也可以被称作根对象。每次getMethod获取到的 Method 对象都持有对根对象的引用,因为一些重量级的 Method 的成员变量(主要是 MethodAccessor ),我们不希望每次创建 Method 对象都要重新初始化,于是所有代表同一个方法的 Method 对象都共享着根对象的 MethodAccessor,每一次创建都会调用根对象的 copy 方法复制一份。
获取到Method对象之后,调用invoke方法的流程如下:
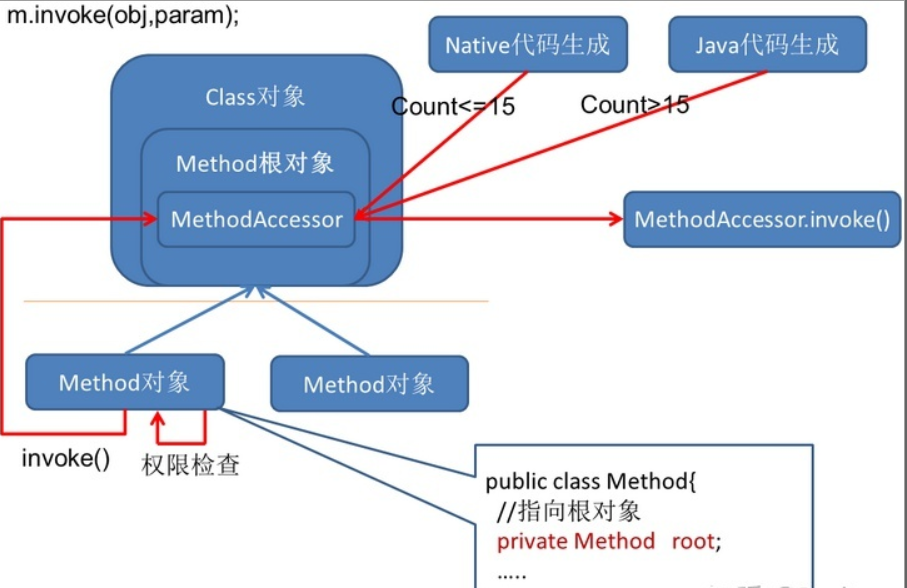
可以看到,调用Method.invoke之后,会直接去调MethodAccessor.invoke。MethodAccessor 就是上面提到的所有同名 method 共享的一个实例,由ReflectionFactory创建。创建机制采用了一种名为 inflation 的方式(JDK 1.4 之后):如果该方法的累计调用次数<=15,会创建出NativeMethodAccessorImpl,它的实现就是直接调用 native 方法实现反射;如果该方法的累计调用次数>15,会由 Java 代码创建出字节码组装而成的MethodAccessorImpl。(是否采用 inflation 和 15 这个数字都可以在 JVM 参数中调整)。
更加细致的过程R大有一篇博文:关于反射调用方法的一个log
动态代理
说道动态代理,就必须得回顾下代理模式这种设计模式了:
代理模式:给某一个对象提供一个代理,并由代理对象来控制对真实对象的访问。代理模式是一种结构型设计模式。
代理模式角色分为 3 种:
Subject(抽象主题角色):定义代理类和真实主题的公共对外方法,也是代理类代理真实主题的方法;
RealSubject(真实主题角色):真正实现业务逻辑的类;
Proxy(代理主题角色):用来代理和封装真实主题;
代理模式的结构比较简单,其核心是代理类,为了让客户端能够一致性地对待真实对象和代理对象,在代理模式中引入了抽象层。
简单来说,代理模式就在真实的角色外面包装一层代理,可以在代理方法中执行真实的方法,还可以额外做一些逻辑判断和处理。
而动态代理,就是区别于静态代理的一种代理模式实现方式。二者根据字节码的创建时机来分类:
- 所谓静态也就是在程序运行前就已经存在代理类的字节码文件,代理类和真实主题角色的关系在运行前就确定了。
- 而动态代理的源码是在程序运行期间由JVM根据反射等机制动态的生成,所以在运行前并不存在代理类的字节码文件。
静态代理
我们先用更好理解的静态代理来了解一下代理的过程,然后理解静态代理的缺点,再来学习动态代理。
编写一个接口 UserService ,以及该接口的一个实现类 UserServiceImpl。
public interface UserService {
public void select();
public void update();
}
public class UserServiceImpl implements UserService {
public void select() {
System.out.println("查询 select 方法");
}
public void update() {
System.out.println("更新 update 方法");
}
}我们将通过静态代理对 UserServiceImpl 进行功能增强,在调用 select 和 update 之前记录一些日志。写一个代理类 UserServiceProxy,代理类需要实现 UserService:
public class UserServiceProxy implements UserService {
private UserService target; // 被代理的对象
public UserServiceProxy(UserService target) {
this.target = target;
}
public void select() {
before();
target.select(); // 这里才实际调用真实主题角色的方法
after();
}
public void update() {
before();
target.update(); // 这里才实际调用真实主题角色的方法
after();
}
private void before() { // 在执行方法之前执行
System.out.println(String.format("log start time [%s] ", new Date()));
}
private void after() { // 在执行方法之后执行
System.out.println(String.format("log end time [%s] ", new Date()));
}
}通过静态代理,我们达到了功能增强的目的,而且没有侵入原代码,这是静态代理的一个优点。
虽然静态代理实现简单,且不侵入原代码,但是,当场景稍微复杂一些的时候,静态代理的缺点也会暴露出来。
1、当需要代理多个类的时候,由于代理对象要实现与目标对象一致的接口,有两种方式:
- 只维护一个代理类,由这个代理类实现多个接口,但是这样就导致代理类过于庞大;
- 新建多个代理类,每个目标对象对应一个代理类,但是这样会产生过多的代理类。
2、 当接口需要增加、删除、修改方法的时候,目标对象与代理类都要同时修改,不易维护。
如何改进?就是使用动态代理。动态代理就是想办法,根据接口或目标对象,计算出代理类的字节码,然后再加载到 JVM 中使用。
动态代理
常见的字节码操作类库有如下几种:
这里有一些介绍:java-source.net/open-source…
- Apache BCEL (Byte Code Engineering Library):是 Java classworking 广泛使用的一种框架,它可以深入到 JVM 汇编语言进行类操作的细节。
- ObjectWeb ASM:是一个Java字节码操作框架。它可以用于直接以二进制形式动态生成 stub 根类或其他代理类,或者在加载时动态修改类。
- CGLib(Code Generation Library):是一个功能强大,高性能和高质量的代码生成库,用于扩展 JAVA 类并在运行时实现接口。
- Javassist:是 Java 的加载时反射系统,它是一个用于在 Java 中编辑字节码的类库;它使 Java 程序能够在运行时定义新类,并在 JVM 加载之前修改类文件。
- ...
为了让生成的代理类与目标对象(真实主题角色)保持一致性,实际使用中我们最常见的两种实现方式是:
- 通过实现接口的方式 -> JDK动态代理
- 通过继承类的方式 -> CGLib动态代理
JDK 动态代理
JDK 动态代理主要涉及两个类:java.lang.reflect.Proxy 和 java.lang.reflect.InvocationHandler。还是以上面的例子,我们用动态代理的方式实现对 UserService 的日志记录。
public class LogProxy implements InvocationHandler {
Object target;//被代理的对象,实际的方法执行者。
public LogProxy(Object target) {
this.target = target;
}
// 调用invoke方法之前执行
private void before() {
System.out.println(String.format("log start time [%s] ", new Date()));
}
// 调用invoke方法之后执行
private void after() {
System.out.println(String.format("log end time [%s] ", new Date()));
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
before();
Object result = method.invoke(target, args); // 调用 target 的 method 方法
after();
return result; // 返回方法的执行结果
}
}这个就是日志记录代理类了,他的内部变量 target 是实际执行方法的对象,我们在执行对象的前后添加了日志记录方法。不同于静态代理中直接调用对象的方法,基于 JDK 的动态代理是利用反射来执行相应的方法。
执行代理的步骤如下:
// 1. 创建被代理的对象,UserService接口的实现类
UserServiceImpl userServiceImpl = new UserServiceImpl();
// 2. 获取对应的 ClassLoader
ClassLoader classLoader = userServiceImpl.getClass().getClassLoader();
// 3. 获取所有接口的Class,这里的UserServiceImpl只实现了一个接口UserService,
Class<?>[] interfaces = userServiceImpl.getClass().getInterfaces();
// 4. 创建一个将传给代理类的调用请求处理器,处理所有的代理对象上的方法调用。这里创建的是一个自定义的日志处理器,须传入实际的执行对象 userServiceImpl
InvocationHandler logHandler = new LogProxy(userServiceImpl);
/*
5.根据上面提供的信息,创建代理对象。在这个过程中:
a.JDK会通过根据传入的参数信息动态地在内存中创建和.class 文件等同的字节码
b.然后根据相应的字节码转换成对应的class,
c.然后调用newInstance()创建代理实例
*/
UserService proxy = (UserService) Proxy.newProxyInstance(classLoader, interfaces, logHandler);
// 调用代理的方法
proxy.select();
proxy.update();JDK 动态代理最主要的几个方法如下:
java.lang.reflect.InvocationHandlerObject invoke(Object proxy, Method method, Object[] args)定义了代理对象调用方法时希望执行的动作,用于集中处理在动态代理类对象上的方法调用
java.lang.reflect.Proxystatic InvocationHandler getInvocationHandler(Object proxy)用于获取指定代理对象所关联的调用处理器static Class getProxyClass(ClassLoader loader, Class... interfaces)返回指定接口的代理类static Object newProxyInstance(ClassLoader loader, Class[] interfaces, InvocationHandler h)构造实现指定接口的代理类的一个新实例,所有方法会调用给定处理器对象的 invoke 方法static boolean isProxyClass(Class cl)返回 cl 是否为一个代理类
在newProxyInstance中顺着代码可以看到整个动态代理的流程,简单来说就是对参数进行校验,然后生成一个代理类的字节码文件,如果你修改 jvm 参数jdk.proxy.ProxyGenerator.saveGeneratedFiles为 true 的话,还可以保存生成的字节码文件。
打印字节码文件我们可以看到生成的文件结构:
public final class $Proxy0 extends Proxy implements UserService {
static {
try {
m1 = Class.forName("java.lang.Object").getMethod("equals", Class.forName("java.lang.Object"));
m2 = Class.forName("java.lang.Object").getMethod("toString");
m4 = Class.forName("com.beritra.jdk.proxy.UserService").getMethod("select");
m0 = Class.forName("java.lang.Object").getMethod("hashCode");
m3 = Class.forName("com.beritra.jdk.proxy.UserService").getMethod("update");
} catch (NoSuchMethodException var2) {
throw new NoSuchMethodError(var2.getMessage());
} catch (ClassNotFoundException var3) {
throw new NoClassDefFoundError(var3.getMessage());
}
}
public final void update() throws {
try {
super.h.invoke(this, m3, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
public final void select() throws {
try {
super.h.invoke(this, m4, (Object[])null);
} catch (RuntimeException | Error var2) {
throw var2;
} catch (Throwable var3) {
throw new UndeclaredThrowableException(var3);
}
}
//其他部分没贴
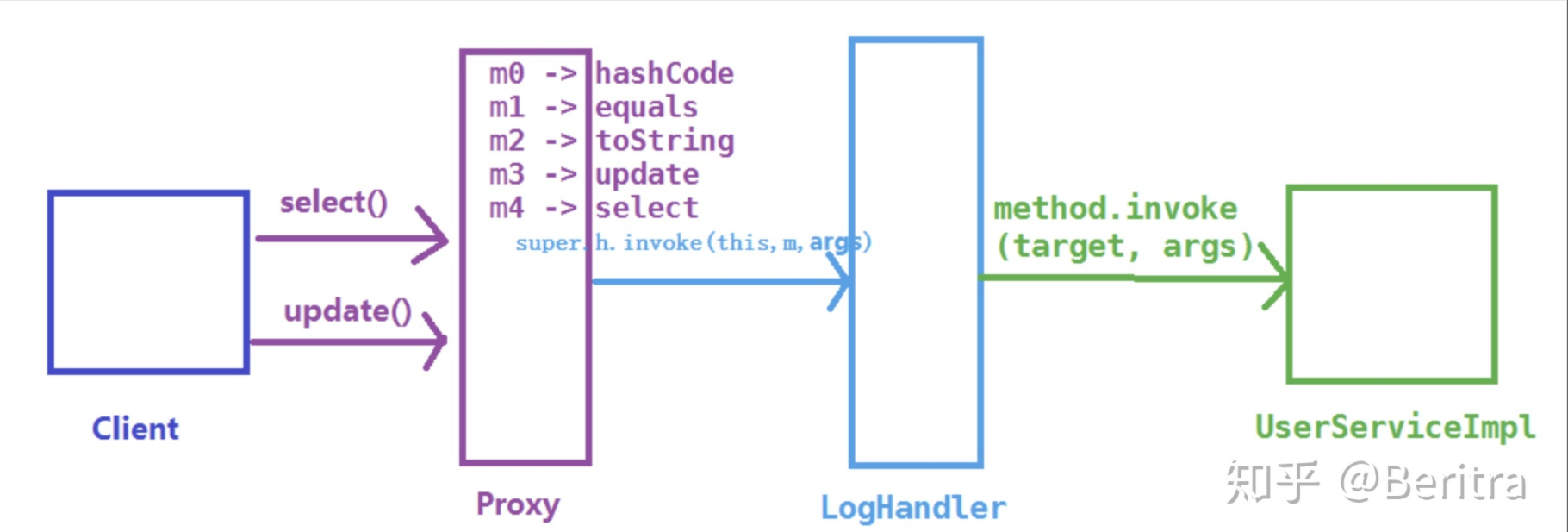
}从这个生成的代理的代码中我们可以发现:
- 继承了 Proxy 类,并且实现了被代理的所有接口,以及 equals、hashCode、toString 等方法
- 由于继承了 Proxy 类,所以每个代理类都会关联一个 InvocationHandler 方法调用处理器
- 类和所有方法都被
public final修饰,所以代理类只可被使用,不可以再被继承 - 每个方法都有一个 Method 对象来描述,Method 对象在static静态代码块中创建,以
m + 数字的格式命名 - 调用方法的时候通过
super.h.invoke(this, m4, (Object[])null);调用,其中的super.h.invoke实际上是在创建代理的时候传递给Proxy.newProxyInstance的 LogHandler 对象,它继承 InvocationHandler 类,负责实际的调用处理逻辑。 - 而 LogHandler 的 invoke 方法接收到 method、args 等参数后,进行一些处理,然后通过反射让被代理的对象 target 执行方法
流程如下:
CGLib 动态代理
在 maven 依赖中加入 CGLib 的库:
<!-- https://mvnrepository.com/artifact/CGLib/CGLib -->
<dependency>
<groupId>CGLib</groupId>
<artifactId>CGLib</artifactId>
<version>3.3.0</version>
</dependency>如果我们用 CGLib 的方式实现动态代理,代码更简单一点。还是跟上面 JDK 动态代理类似的例子,我们复用上面的 UserService 和 UserServiceImpl 两个类,但是重新写代理:
public class LogInterceptor implements MethodInterceptor {
/**
* @param object 表示要进行增强的对象
* @param method 表示拦截的方法
* @param objects 数组表示参数列表,基本数据类型需要传入其包装类型,如int-->Integer、long-Long、double-->Double
* @param methodProxy 表示对方法的代理,invokeSuper方法表示对被代理对象方法的调用
* @return 执行结果
* @throws Throwable
*/
@Override
public Object intercept(Object object, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
before();
Object result = methodProxy.invokeSuper(object, objects); // 注意这里是调用 invokeSuper 而不是 invoke,否则死循环,methodProxy.invokesuper执行的是原始类的方法,method.invoke执行的是子类的方法
after();
return result;
}
private void before() {
System.out.println(String.format("log start time [%s] ", new Date()));
}
private void after() {
System.out.println(String.format("log end time [%s] ", new Date()));
}
}然后调用的时候:
LogInterceptor logInterceptor= new LogInterceptor();
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(UserServiceImpl.class); // 设置超类,CGLib是通过继承来实现的
enhancer.setCallback(logInterceptor);
UserService service = (UserService) enhancer.create(); // 创建代理类
service.update();
service.select();执行代码实现了类似的效果。CGLib 还提供了更多的功能,比如我们实现 CallbackFilter 接口的话,可以执行回调。
CGLib 创建动态代理类的模式是:
- 查找目标类上的所有非 final 的 public 类型的方法定义;
- 将这些方法的定义转换成字节码;
- 将组成的字节码转换成相应的代理的 class 对象;
- 实现 MethodInterceptor 接口,用来处理对代理类上所有方法的请求。
JDK 动态代理与 CGLib 动态代理对比
JDK 动态代理:基于 Java 反射机制实现,必须要实现了接口的业务类才能用这种办法生成代理对象。
CGLib 动态代理:基于 ASM 机制实现,通过生成业务类的子类作为代理类,所以代理的类不能是 final 修饰的。
JDK Proxy 的优势:
- 最小化依赖关系,减少依赖意味着简化开发和维护,JDK 本身的支持,可能比 CGLib 更加可靠。
- 平滑进行 JDK 版本升级,而字节码类库通常需要进行更新以保证在新版 Java 上能够使用。
- 代码实现简单。
基于类似 CGLib 框架的优势:
- 无需实现接口,达到代理类无侵入。
- 只操作我们关心的类,而不必为其他相关类增加工作量。
- 高性能。
Java 动态代理适合于那些有接口抽象的类代理,而 CGLib 则适合那些没有接口抽象的类代理。
关于二者的效率区别,有一条博客这么说:
1、CGLib 底层采用 ASM 字节码生成框架,使用字节码技术生成代理类,在 jdk6 之前比使用 Java 反射效率要高。唯一需要注意的是,CGLib 不能对声明为 final 的方法进行代理,因为 CGLib 原理是动态生成被代理类的子类。
2、在 jdk6、jdk7、jdk8 逐步对 JDK 动态代理优化之后,在调用次数较少的情况下,JDK 代理效率高于 CGLib 代理效率,只有当进行大量调用的时候,jdk6 和 jdk7 比 CGLib 代理效率低一点,但是到 jdk8 的时候,jdk 代理效率高于 CGLib 代理。
Spring 框架怎么对二者进行选择的?
- 当 Bean 实现接口时,Spring 就会用 JDK 的动态代理。
- 当 Bean 没有实现接口时,Spring 使用 CGlib 实现。
- 可以强制使用 CGlib(在 spring 配置中加入
<aop:aspectj-autoproxy proxy-target-class="true"/>)。
注解
注解(Annotation)在 JDK 1.5 之后增加的一个新特性,注解的引入意义很大,有很多非常有名的框架,比如 Hibernate、Spring 等框架中都大量使用注解。注解对于开发人员来讲既熟悉又陌生,熟悉是因为只要你是做开发,都会用到注解(常见的@Override)。陌生是因为即使不使用注解也照常能够进行开发,注解不是必须的。
本质
Java.lang.annotation.Annotation接口中有这么一句话,用来描述注解。
The common interface extended by all annotation types
所有的注解类型都继承自这个普通的接口(Annotation)
这句话有点抽象,但却说出了注解的本质。我们看一个 JDK 内置注解的定义:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}其实这个注解的本质就是:
public interface Override extends Annotation{
}只不过是继承了Annotation接口的接口。如果想验证,你可以去反编译任意一个注解类,就会得到相同的结论。
所以注解说白了就是一个标签,甚至是一种特殊的注释,他本身不起作用,没有功能,需要额外的工具进行解析,实现它的功能。
解析一个类或者方法的注解往往有两种形式,一种是编译期直接的扫描,一种是运行期反射。反射的方式后面详细叙述,而编译器的扫描指的是编译器在对 Java 代码编译字节码的过程中,会检测到某个类或者方法被一些注解修饰,这时它就会对于这些注解进行某些处理。
典型的就是注解 @Override,一旦编译器检测到某个方法被修饰了 @Override 注解,编译器就会检查当前方法的方法签名是否真正重写了父类的某个方法,也就是比较父类中是否具有一个同样的方法签名。
这一种情况只适用于那些编译器已经熟知的注解类,比如 JDK 内置的几个注解,而你自定义的注解,编译器是不知道你这个注解的作用的,当然也不知道该如何处理,往往只是会根据该注解的作用范围来选择是否编译进字节码文件,仅此而已。
元注解
什么东西只要一带上“元”就瞬间高大上了起来,类似“元数据”的意思是用来描述数据的数据。“元注解”就是用来修饰注解的注解,通常用在注解的定义上。
还是看 @Override 的定义:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}其中的 @Target,@Retention 两个注解就是元注解。
JAVA 中有以下几个元注解:
- @Target:注解的作用目标
- @Retention:注解的生命周期
- @Documented:注解是否应当被包含在 JavaDoc 文档中
- @Inherited:是否允许子类继承该注解
@Target 用于指明被修饰的注解最终可以作用的目标是谁,也就是指明,你的注解到底是用来修饰方法的?修饰类的?还是用来修饰字段属性的。一共有以下几个属性:
被这个 @Target 注解修饰的注解将只能作用在成员字段上,不能用于修饰方法或者类。他的值 ElementType 是一个枚举类型,有以下一些值:
- ElementType.TYPE:允许被修饰的注解作用在类、接口和枚举上
- ElementType.FIELD:允许作用在属性字段上
- ElementType.METHOD:允许作用在方法上
- ElementType.PARAMETER:允许作用在方法参数上
- ElementType.CONSTRUCTOR:允许作用在构造器上
- ElementType.LOCAL_VARIABLE:允许作用在本地局部变量上
- ElementType.ANNOTATION_TYPE:允许作用在注解上
- ElementType.PACKAGE:允许作用在包上
@Retention 用于指明当前注解的生命周期,他的值 RetentionPolicy 也是枚举类型,包括以下几种:
- RetentionPolicy.SOURCE:当前注解编译期可见,不会写入 class 文件
- RetentionPolicy.CLASS:类加载阶段丢弃,会写入 class 文件
- RetentionPolicy.RUNTIME:永久保存,可以反射获取
剩下两种类型的注解我们很少用,也比较简单。
@Documented 注解修饰的注解,当我们执行 JavaDoc 文档打包时会被保存进 doc 文档,反之将在打包时丢弃。
@Inherited 注解修饰的注解是具有可继承性的,也就说我们的注解修饰了一个类,而该类的子类将自动继承父类的该注解。
写一个注解
现在我们尝试自己写一个注解,以一个最简单的为例,假设我们写的注解叫PrintMethods,作用在类上,作用就是打印这个类所有的方法。然后仿照官方的注解定义该注解如下:
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface PrintMethods {
}然后找一个测试类加上注解:
@PrintMethods
public class AnnotationTest {
public static void main(String[] args) {
AnnotationTest main = new AnnotationTest();
main.print();
}
private void print() {
System.out.println("print");
}
}执行一下,看看发生了什么。
答案是什么都没发生。之前说过了,注解就像一个标签,本身没什么功能。我们需要手动扫描注解:
Class<?> clazz = AnnotationTest.class;
Annotation annotation = clazz.getAnnotation(PrintMethods.class);
if (annotation != null) {
for (Method method : clazz.getDeclaredMethods()) {
System.out.println(method.getName());
}
} else
System.out.println("No Annotation");执行这段代码,就会发现AnnotationTest这个类中的注解被顺利的打印了出来,包括main和print两个方法。
其实在框架中也是这样的,比如 SpringBoot 的@Componen注解,把一个类标注为 bean,让 Spring 去管理,原理就是我们先通过@ComponentScan注解指定了包,然后 Spring 去吧所有包下面的类都扫描一遍,然后找到带有@Componen注解的,然后进行后续处理。
参考:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端
2021-03-14 Windows CLion 远程Linux服务器 开发调试