

为什么用Spring的一个原因(转)
当你发现代码经常重复,你会考虑将其写成函数,封装工具;
当你发现多人合作时,代码耦合严重,你会将其模块化。
每个轮子的出现都是因为希望优化生产,提高效率,仅此而已。
正如评论里的朋友所说,spring存在自己的问题,因为复杂度是不会凭空消失的,只是从一个地方转移去另一个地方。
一开始我的认识也不太够,举了个简单的通用例子,这个例子其实是spring依赖注入后带来的好处,而并非只是为了如此。
后面讲了个过程,可以发现,重点在于层层封装,形成模块化,良好代码环境,便于维护。
简单来说,给你一套ssm,ssh的代码,你能立刻知道先看什么,按什么规范写;给你一套无接口风格各异的代码,有可能看半天。
框架这种东西本来就是致力于统一生产形式,也有时效性。
面向接口编程现在也经常被怀疑是否有意义。
感觉有点偏题了,互勉。
// 添加内容
作为几个月前是新手的次新手的我,在之前没有分层解耦的需求下,完全不能接受“让容器(框架)去new对象”这种抽象,因为没有说出其意义。
假如我们要实现一个存款的应用,那么,我们的思维是这么走的:
1.写一个“存款类”,里面有“存款方法”,“存款方法”直接操作数据库实现存款逻辑。
2.你突然发现,操作数据库的方法都是增删查改,为什么不写成一个类,让“存款方法”去调用这个操作数据库的类,减少了不少重复代码。
(分层思想来了,业务逻辑和数据操作分离了)
3.你的朋友知道了你在写这个应用,就跟你提意见,不如我帮你写操作数据库的类,你写存款业务的类,这样不就快了吗?我们约定一个接口,你调用这个接口,我实现这个接口,这样开发就很快了。
(接口思想来了,调用方不必理会具体实现,专注于自己的逻辑)(工厂模式)
4.你在写你的业务逻辑的时候,发现虽然你不用管数据操作逻辑的实现,但是在你的代码了,创建一个对象的语法:
接口 变量名 = new 实现类();
在做了那么多分离工作,还是要写new 实现类();,还是依赖于实现类。你就想,能不能做一个容器,自动帮我将实现类赋给接口呢?(依赖注入思想)
于是,你写出了spring,一开始使用xml配置,在类里面只需要getBean(),接口和实现类和调用类基本分离了(松耦合形成了),后来xml你也懒得写,弄出一批注解,实现类注解一下是组件,调用类声明一个接口,写个@AutoWired,spring容器就帮你完成了将实现类赋给接口的工作,即所谓的spring帮你new了一个对象。
最后你的应用结构如下图:
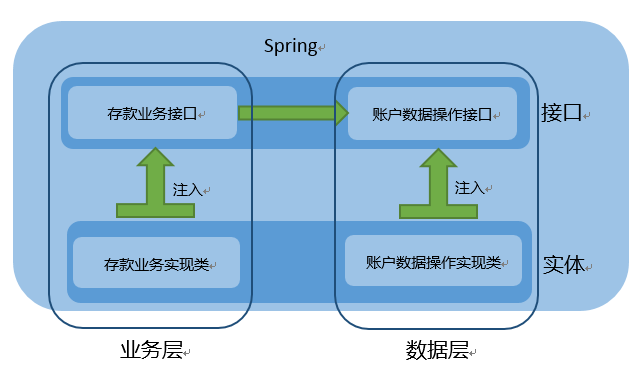
比起刚开始一个类里面参杂着各式各样的代码,现在看一个个部件似的,何等舒服!
注:spring不止是DI,还有AOP,MVC等等,依赖注入只是它的一个功能。
// 旧答案
举个例子,比如你写
Apple apple = new Apple();
People people = new People();
people.eat(apple);
然后有一天,客户说不想吃Apple了
给我改成吃Orange,然后你打开源文件
Orange orange = new Orange();
People people = new People();
people.eat(orange);
再重新编译
再一天,客户又觉得不好,要Peach了
Peach peach = new Peach();
People people = new People();
people.eat(peach);
再重新编译
………
然后你在客户的需求下崩溃了
倘若您用spring
Fruit fruit = (Fruit)beanFactory.getBean("fruit");
People people = (People)beanFactory.getBean("people");
people.eat(fruit);
这样使用了接口Fruit,你只需要在xml文件配置,更换fruit的bean,无需改变源代码。对于people也如此。
会发现,我们在这种设计下会少维护了很多代码,达到这样的效果的原因是因为,Fruit和People没有参杂在一起,没有谁调用了谁等等,实际上就是没有耦合,他们的关系由接口代替表示了。

