

awk----基本用法
awk具体的请看这个
https://www.cnblogs.com/bwbfight/p/9402738.html
awk 竟然自诩一种语言,ok.... 牛
既然这样就学习一下吧
awk -F‘[指定多个分隔符]’
比如 awk -F'[ :]'表示指定:空格为分隔符
涉及多个重复分割符可以这样指定 awk -F'[ :]+' 表示多个空格或者多个:号表示一个整体
例子
获取ip:
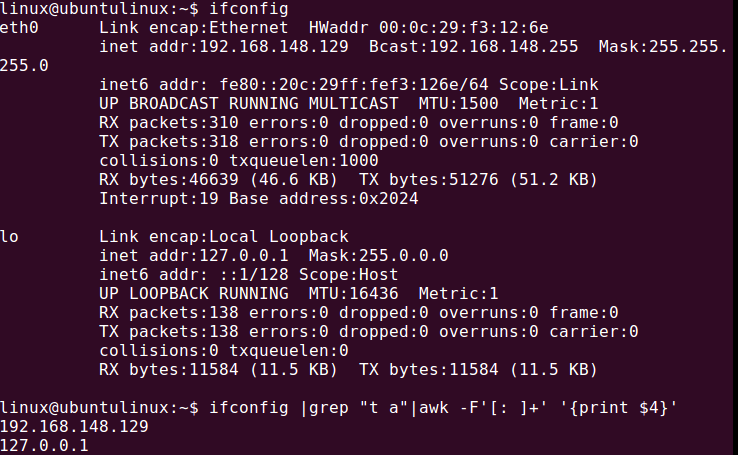
NF(number of field)字段数:
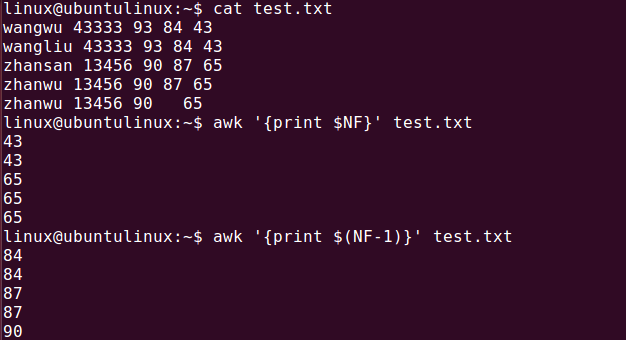
如果字段数不一样如何取最后一个字段呢?
如下例子
这里引入一个FNR

上面表示如果NR和FNR相等,显然打印test.txt(NR顺序计数,FNR分别计数),不等打印test1.txt
FNR在多文件时会分别统计行数,NR则是一起统计

打印指定行
打印第三行 awk 'NR==3{ print $0}' test.txt
awk 模式
awk 'true/false{行为}true/false{行为}'
awk '0{print $1}' test.txt =====结果一行也不打印
awk '1{print $1}' test.txt =====结果全部打印
awk 'NR==3{print $1}' test.txt====打印第三列
awk 'NR==2{print $1} NR==3' test.txt===打印第二三列
awk 'BEGIN{pint “-----start--------”}NR==1{print $0 }END{print '-----end----------------'}' test.txt
awk计算
awk '{a+=$1}END{print $1} ' a.txt ===把a.txt第一列加起来,并打印结果
awk '{a=$1+$2+$3;print a,int(a/3)}' a.txt====把a.txt的每一行第一列,第二列,第三列加起来求平均值
awk变量
在shell外边定义的变量,如何在awk中使用呢?
a=1
awk -va=$a '{print a}'
awk ‘{print '$a'}’
以上为获取bash上变量的值在awk中使用的方法
-v 定义变量
awk -va=1 '{print $a}'
awk '{a=1;print a}'

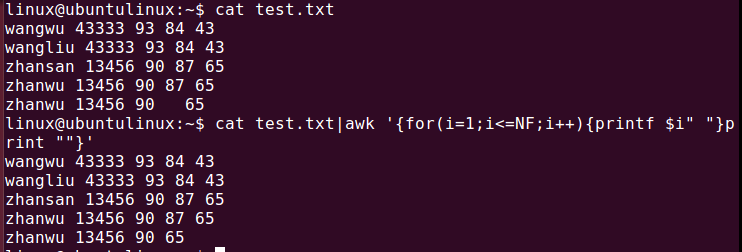
awk for循环
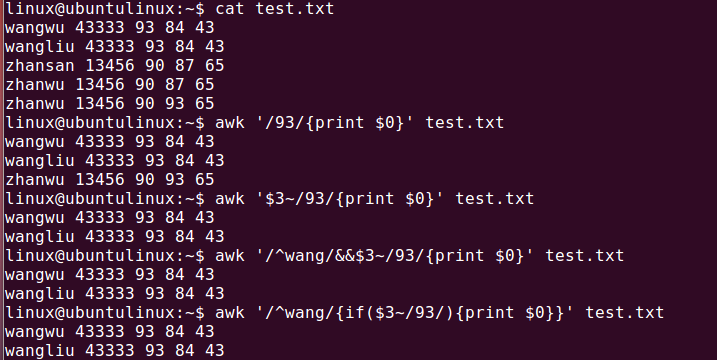
awk 正则表达式
取ip

这种awk不支持
获取test.txt第一列和test1.txt的第二列写入文件
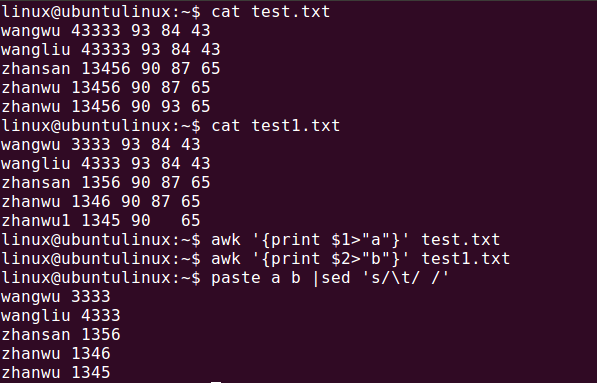
方法二:

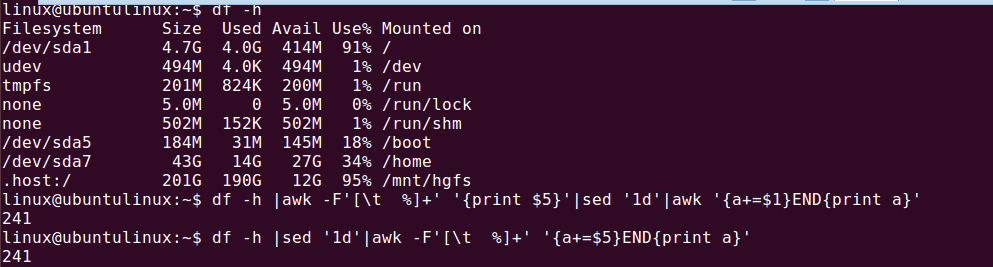
取 df -h中USe%列的和
实现只打印前六行


