

漫谈.NET开发中的字符串编码
说明:
在《 .NET 4.0面向对象编程漫谈 》基础篇《 13.2.1 序列化与流》中,向大家介绍了如何向流中序列化一个对象。
本篇扩充阅读将向读者介绍将字符串对象的序列化,这里面的关键是字符串应该如何编码和解码为二进制数值,从而可以把它们保存到文件流( FileStream)中,或者通过网络流( NetworkStream)将它们远程发送到另一台计算机上。
抱怨一下:
使用CSDN的在线编辑器写文章是一个让人望而生畏的工作,当提交文档时,CSDN Web服务器经常报告“内部错误”,所以文章排版不好,诸位见谅。博客园的系统稳定些,读者可以访问http://www.cnblogs.com/bitfan/archive/2010/11/25/1887590.html 看到排版好一点的同样文章。
==============================================================
1 引子
在实际开发中,经常需要将一些字符串写入到文本文件中,或者从文本文件中读入字符串,在 .NET应用程序中,通常使用 StreamReader或 StreamWriter两个类完成这一工作,比如以下代码将 fileContent字串写入到 FileName文件中:
static void WriteFileUseStreamWriter(String fileContent, String FileName)
{
using (StreamWriter writer = new StreamWriter(FileName))
{
writer.Write(fileContent);
}
}
如果你使用 .NET基类库中相关类(比如 StreamReader或下面用到的 File类)去读取这个文件,你会发现一切如你所愿地正常运转:
Console.WriteLine(File.ReadAllText( " test.txt " )); // 输出:“中国ab”
由于多数情况下我们都工作在中文 Windows下,而且往往都是某个 .NET程序写,另一个 .NET程序读,所以,不少 .NET程序员可能都没注意到这其中其实存在着一个字符编码的问题,在特定的场合下,这一问题会给我们带来麻烦。
请看图 1:
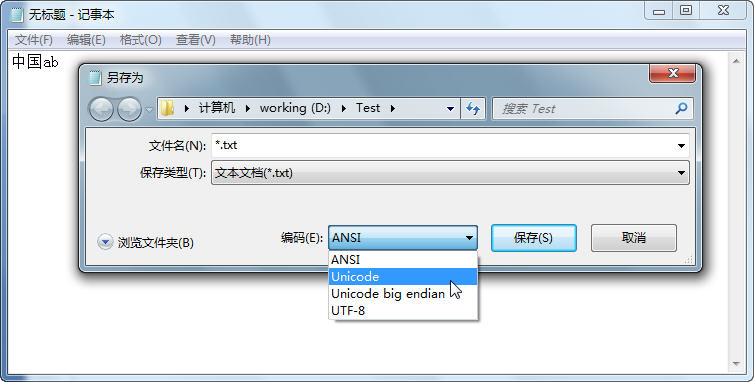
图1 记事本支持的编码方式
默认情况下, Windows记事本以 ANSI编码方式保存文件。如图 1所示,如果文本内容为“中国 ab ” ,记事本将其以 ASNI方式保存为“ test.txt”,则以下代码将“罢工”了(参看图 2):

图2 汉字将显示为乱码
如 图 2 所示, File.ReadAllText方法打开“ test.txt”文件时,会发现英文字符可以正常显示,但中文将显示为乱码。
2 了解字符的编码
我们可以做个试验,使用记事本将“中国 ab”这个中英混杂的字符串以不同编码方式保存为多个“ .txt”文件,然后直接查看其二进制内容:

图3 比对字符编码
图 3 展示了“中国 ab”按四种编码方式( ANSI、 UTF8、 Unicode、 Unicode Big Endian )得到的不同二进制数据。
以英文字符“ a”为例, ANSI和 UTF8得到的数值都是“ 61”,但 Unicode将它扩充为 2个字节 16位的二进制(“ 61 00”和“ 00 61”),所以我们又将这种编码方式称为 UTF-16。
UTF-16 又可以细分为 2种编码方式: Big Endian方式与 Little_Edian方式,这两者的唯一区别在于字节排列顺序刚好相反, Little_Edian方式将“ a”编码为“ 61 00”,而 Big Endian方式则编码为“ 00 61”。
现在看看中文字符,“中国”两个汉字, ANSI编码为“ D6 D0 B9 FA”, 4个字节,一个汉字占两个字节,而 UTF8则编码为“ E4 B8 AD E5 9B BD”, 6个字节,一个汉字占 3个字节!这说明 UTF8是一种“变长”的编码,可能使用 1~4个字节来表示某个字符。
另外,我们看到 UTF8和 Unicode编码(不管是 Big Endian还是 Little Endian )前面都有几个标记字符,这些字符放在文本文件的开头,称为“ BOM( Byte Order Mark,字节顺序标记)”指明了文本的编码方式,以下是 .NET程序中常见的字符编码方式的 BOM值:
| 编码 | BOM 值 |
| UTF-8 | EF BB BF |
| UTF-16 big endian | FE FF |
| UTF-16 little endian | FF FE |
| UTF-32 big endian | 00 00 FE FF |
| UTF-32 little endian | FF FE 00 00 |
了解了上述基础知识,我们就可以依据 BOM值自动检测字符串的编码方式,从而正确从二进制数据流中解码,以下代码检测文本二进制数据是否采用 UTF8编码:

byte [] FileContents = File.ReadAllBytes(FilePath);
int filelength = FileContents.Length;
// 检测BOM
if (FileContents[ 0 ] == 0xef && FileContents[ 1 ] == 0xbb && FileContents[ 2 ] == 0xbf )
{
// 按UTF8解码字符串,注意要排除掉BOM占用的3个字节。
String content = Encoding.UTF8.GetString( FileContents, 3 , filelength - 3 );
Console.WriteLine(content);
}
其他的编码方式都可以“依样画葫芦”。
3 详解 .NET 基类库中与字符编码相关的类
前述代码中的 Encoding类是 .NET实现字符编码解码的核心类型。图 4展示了它的属性:
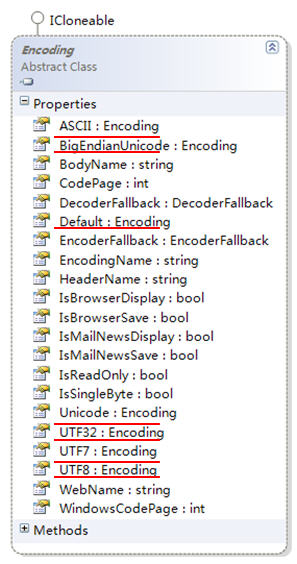
图 4 Encoding类型
如图 4所示, Encoding类型提供了 UTF8、 Unicode等编码和解码器,调用它的 Get系列方法完成编码和解码工作,以下为示例代码:
byte [] bytes = Encoding.UTF8.GetBytes( " 中国ab " );
foreach ( byte value in bytes)
Console.Write( " {0} " , value.ToString( " x " )); // 转化为16进制
Console.WriteLine();
// 解码
char [] chars = Encoding.UTF8.GetChars(bytes);
foreach ( char ch in chars)
Console.Write( " {0} " , ch);
运行结果如下:
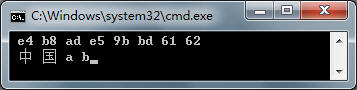
图5 编码和解码
需要注意的是上述二进制值不包括 BOM。
事实上, .NET中的 StreamWriter默认采用 UTF8编码格式编码字符串,但并不将 UTF8所对应的 BOM值(“ EF BB BF”)写入到二进制流中。以下是 StreamWriter的一个构造函数声明:
{ }
类似地, File.ReadAllText()方法在内部使用 UTF8来读取指定文件中的字符串 :
{
// ……
return InternalReadAllText(path, Encoding.UTF8);
}
由于默认编码方式一致,所以配套使用 StreamWriter和 File.ReadAllText()方法可以正确地从流中存取字符串。
出于提升代码可维护性考虑,正确的用法应该是明确地指明编码方式:
{
using (StreamWriter writer = new StreamWriter(FileName, false , Encoding.UTF8 ))
{
writer.Write(fileContent);
}
}
这时, StreamWriter会在文件开头写入 UTF8的 BOM标记,从而让其他的应用程序可以很明确地知道本文件中字符串的编码方式。
4 谈谈有趣的 Encoding.Default 属性
Encoding 类中有一个有趣的 Default属性,它的类型很奇怪,叫作“ DBCSCodePageEncoding”,这个类型在 MSDN中是查不到的。
“ DBCS”代表“ double-byte character set (双字节字符集)”,它是与“ SBCS( single-byte character set,单字节字符集)”相对应的, SBCS中,所有字符都只占一个字节,所以能表示的字符数有限,但在 DBCS中,英文字母占一个字节,汉字等特殊字符占有两个字节,从而扩充了 Windows能显示的字符数量。
DBCSCodePageEncoding 中的“ Code Page”被称为“ 代码页 ”,每个代码页定义了特定的编码将如何对应于特定的字符(比如简体和繁体中文就分别定义在不同的代码页中),因此,同样的二进制数值,在不同的代码页中,会代表不同的字符。中文 Windows通过使用基于代码页的 DBCS编码方式,可以方便地以多种编码方式显示和处理字符串。
我们在 MSDN中可以查到所有代码页的编号,下面列出了可能比较常用的代码页标识:
936 gb2312
950 big5
1200 utf-16
52936 hz-gb-2312
54936 GB18030
65000 utf-7
65001 utf-8
.NET 应用程序可以通过以下方式获取指定代码页的编码对象:
以下代码将按照指定代码页编码字符串,并将其写入到文件中:
{
using (StreamWriter writer = new StreamWriter(FileName, false , Encoding.GetEncoding(CodePage)))
{
writer.Write(fileContent);
}
}
现在,使用以下代码将按照 UTF8编码字符串:
5 结束语
除了本文所介绍的将字符串保存到文本文件的这种场景,字符串的编码方式在基于套接字的 TCP/UDP网络编程也非常重要,比如 .NET提供了一个 NetworkStream封装 Socket实现网络通讯,如果希望将一个命令字符串从客户端送到服务端,服务端通过读取这个字符串完成特定的工作,则编码方式就很重要了,客户端与服务端必须采用一致的编码方式传送命令,否则,网络服务就有可能因为无法解析客户端发送过来的数据而 Down掉。
有关网络编程的内容很有趣,我的下一篇文章会介绍 .NET套接字编程。
好了,这篇介绍字符串编码的短文写完了,希望本文能对读者有所帮助,如有错误,敬请指正。
附《.NET4.0面向对象编程漫谈》豆瓣链接:http://book.douban.com/subject/5319799/
