

关于从普通文本提取正则表达式的再思考
原文链接:http://iregex.org/blog/text-2-regular-expressions-again.html
rex按:
写完上一篇文章之后,一直在考虑如何真正实现从普通文本中归纳正则表达式的实现。走了许多弯路,也学了不少知识。例如,perl黑豹书上复杂的数据结构、匿名散列和数组、refenrence;紫龙书上的状态机的构造,数据结构上图论的知识,都是很有用的。另外还新学了graphviz的用法。以前觉得很神秘,不过一用才发现很直观。本文的插图是使用online版本的graphviz画的。
除了本文的这种实现方法(基于图),我还使用另一种方式实现了,很简单:基于关键词。具体作法是,逐一读取每一行文本,使用\s+等将其split开,形成array;然后再对所有的array进行求交集的操作(使用hash),得到每一行都有的关键词;然后按从左到右的顺序建立这覆的正则式^(.*?)keyword1(.*?)keyword2….keywordN(.*?)$,再分别匹配每一行文本,得到hash的hash表,或者array的array,转置,并列输出,得到^(option1|option2…)keyword1(option..)…$这样的正则式。最后作为验证,再将所最终生成的正则与每一行匹配测试一下。
这样以词为单位做完之后,再逐个字母地分隔开来,递归地处理(option1|option2…)的部分。先是单词级,再是字母级,有利于先在最大程度上找出重复的内容;而且粗化和细化的处理过程,思路是一致的,粒度不同罢了。
新手请自重,高手请赐教,我的思路未必是正确或最优的。
问题
有文本文件text.txt,内容如下:
this is a red fox
this is a blue firefox
this is a pig
a red fox
请写一则程序,根据文本内容,自动构造(比较合理的)正则表达式,使之能够匹配文件中每一行文本。
标准正则
有两种极端的解法是不可取的:
- ^.*$
- ^(this is a red fox|this is a blue firefox|this is a pig|a red fox)$
第一种失之于太宽泛,第二种失之于太狭隘。太宽泛则泥沙俱下,无论什么文本都能匹配;太狭隘则僵化死板,缺乏灵活性。好的正则表达式源于例文本(从例文本中提取规律),又高于例文本(能匹配同规律的其它文本)。匹配什么,排除什么,都有定则,所谓“君子有所为而有所不为”,指的就是这种情况(貌似跑题了:))。
那么,如何是比较靠谱的正则表达式呢?以上文的例子而言,可以是:
^(this is )?a (red fox|blue firefox|pig)$
现在我们向着标准答案出发。
思路
任何复杂的电路图,都可以拆分为三种简单的关系:串联,并联,短路。正则表达式也同理。
既然是一条正则匹配所有的文本,那么这条正则(记为$re)也应该匹配第一行文本。
第一行文本为this is a red fox。那么,从^this is a red fox$应该是$re的一个(真)子集。它的路径为:“^”->this->is->a->red->fox->”$”。全部节点之间,是串联关系,从左到右依次排列即可。
示意图如下(可以点击看全尺寸图,下同):

同理,第二行文本也应该是$re的子集。不过,由于已经存在了由^->this->is->a的路径,到a时出现支路,a->blue->firefox->$;
将此路径添加到示意图上,得到:

显而易见,这两条并列的支路,始于a,终于$,可以使用|来并列之。
好了,我们总结一下规律:
并列:如果存在A->B->C,且同时存在A->D->C,则B与D之间是并联关系。即出发点相同,结束点相同,且出发点与结束点之间各有一个以上的节点。并列使用括号来表示,之间以|分隔。例如,对于A->B->C,A->D->C,则可以使用A(B|D)C来表示其正则关系。
为什么要强调是一个以上节点呢?这里先卖个关子。请继续阅读。
再往下,this is a pig,同理,只需要在原图基础上添加a->pig->$的支路即可。此时图示如下:
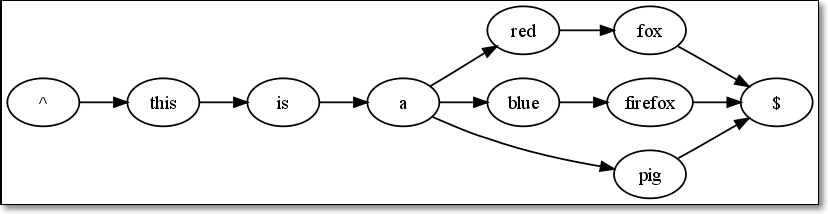
最后一条,a red fox。这条貌似复杂,但是只需在^->a之间新添加了一条路径而已;a->red->fox->$之间原有路径,可以继续使用。此时,得到完整的示意图如下:
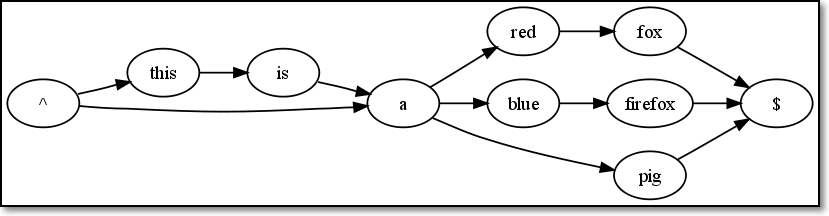
此时,观察可知,一种新的情况出现了。同时存在^->a,和“^”->this->is->a两条路径。想一下初中物理电路图,我们可以将这种情况称为“短路”,即,“^”->this->is->a这个线路的^、a两个节点之间,添加了一条无障碍通道,它能无视this、is的存在,因此,让this->is这条路径成为可选项。再总结一下规律:
如果有A->B->…C->D的路径,且有A->D的路径,则称A->D之间存在短路,此时,B->…->C可以用(B->…->C)?来表示(就是用括号来表示被短路的部分,问号表示短路之)。
顶点A,D之间,最多存在一个短路关系。但是可以有1或更多条并列的关系存在。
好了,分析结束,得到这样的正则式:
^(this is )?a (red fox|blue firefox|pig)$
这也就是为什么上文要强调是一个节点的缘故。
如果我们再精益求精的话,可以对red fox|blue firefox|pig这部分递归地进行上述分析过程,进而得到 (red |blue fire)fox|pig这样的结果。
实现
思路有了,编程就简单了。perl中,固然可以使用比较简洁的hash表来表示链表之间的关系:
例如:
my $hash;
$$hash{“^”}{“this”}{“is”}{“a”}{“red”}{“fox”}{“\$”}=”";
$$hash{“^”}{“this”}{“is”}{“a”}{“blue”}{“firefox”}{“\$”}=”";
…
但是,节点的增删修改都是麻烦事。(我在hash迷宫中lost了很久才爬出来)
抽空补了一下有向图的知识,觉得可以简化问题如下。
上图其实是一个有向图,只需记录所有的顶点集合,路径集合,再来求各路径之间的关系;最后打印输出,即是所求。
顶点集合为:
(^, this, is, a, red, fox, blue, firefox, pig, $);
通路关系集合为:
(^->this, this->is,…)
这两个集合在读取文本文件行的时候可以一次性建立。不复杂。关键是关系的确立。
再次总结,如下:
- 从一个顶点A出发的N条支路必定汇合(只是有时是同一个点,有时不在同一点而已。本文给出的例子是最简单的情况,这里可以假设为汇合到同一点)于M点。
- 这N条路中,每一条路径的长短以经过的节点个数来计算。例如上图中,^到a有一条路,上面的路径为2,下面的路径为0。
- 短的支路决定了这N条支路的关系。
- 长度为任意两点之间,最多只可能有一条长度为0的边。
- 如果存在长度为0的边,则其余的同级的支路被短路。
- 长度不为0的N-1条支路之间是并列关系。
- 整个图始于^,终于$。
这些条件、判断,均可以细化为函数。具体的程序从略。

