
C 理论复习
C 理论知识拾遗
为了应付学校的期末理论考试,总结了一下 ppt 上的知识点,并搜索了一些相关资料,编写时添加了自己的一点理解而成。
计算机基础
8 bit(位)= 1 bytes(字节)
补码、原码和反码
标识符 (Identifiers)
-
标识符是 数组、下划线、字母(小写或大写);和
\u及\U转义记号指定的 Unicode 字符(C99 起)的任意长度序列;合法的标识符必须以 非数字字符 开始。 -
C 关键词:
- 基本数据类型: char, short, int, long float, double void;建议不要使用 以下划线开头的首字母大写单词 和 以
_t结尾; - 对象的修饰、限定和属性名称:signed, unsigned, long, const, static, extern, volatile, auto, register;
- 复杂数据声明:struct, union, enum, typedef;
- 特殊操作:sizeof(
sizeof是一种 运算符); - 程序结构控制: if, else, switch, case, default, for, while, do, return, continue, break, goto;
- 基本数据类型: char, short, int, long float, double void;建议不要使用 以下划线开头的首字母大写单词 和 以
不同进制数字的表示法
| 进制 | 前缀 |
|---|---|
| 十进制 | 无,如 int decimalNum = 10; |
| 二进制 | '0b' 或 '0B',如 int binartNum = 0b1010; |
| 八进制 | 0,如 int octalNum = 012; |
| 十六进制 | '0x' 或 '0X',如 int hexNum = 0xA |
运算符 (Operators)
优先级与结合性
优先级:多个运算符出现在同一表达式中的运算顺序。
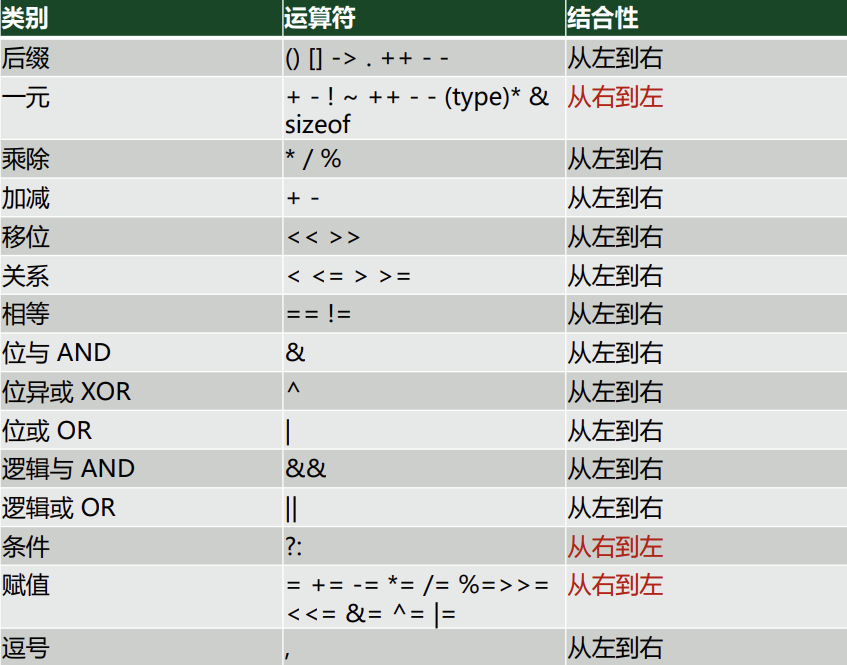
结合性:当表达式中出现多个优先级相同的运算符时的运算顺序。先执行左边的叫 左结合性,反之为 右结合性。
位运算
- 优先级:
~><<,>>>&>|>^; - 对象:只能为整型或字符型;
逻辑运算符
&&, ||, !
-
and短路:
若
A为假,则A && B求值A后直接返回假,不求值B; -
or短路
若
A为真,则A || B求值A后直接返回真,不求值B。
其他运算符
sizeof:返回变量大小。注意sizeof为运算符;&:取地址符;*:解引用符;? ::三目运算符;对于A ? X : Y,如果A为真,则值为X,否则值为Y。
算数类型
布尔类型
_Bool。注意,到_Bool的转换,(bool)0或NULL求值为false,否则为true;<stdbool.h>中定义了bool代表_Bool,true代表1,false代表0。
字符类型
char:位宽为 8。
整数类型
下表总结所有可用的整数类型及其属性:
| 类型说明符 | 等价类型 | 大小 | 位宽 |
| char | char | 1 | 8 |
| signed char | signed char | 1 | 8 |
| unsigned char | unsigned char | ||
| short | short int | 2 | 16 |
| short int | |||
| signed short | |||
| signed short int | |||
| unsigned short | unsigned short int | ||
| unsigned short int | |||
| int | int | 4 | 32 |
| signed | |||
| signed int | |||
| unsigned | unsigned int | 4 | 32 |
| unsigned int | |||
| long | long int | 4 | 32 |
| long int | |||
| signed long | |||
| signed long int | |||
| unsigned long | unsigned long int | 4/8 | 32/64 |
| unsigned long int | |||
| long long | long long int (C99) |
8 | 64 |
| long long int | |||
| signed long long int | |||
| unsigned long long | unsigned long long
int (C99) |
8 | 64 |
| unsigned long long int |
1 == sizeof(char) \(\leq\) sizeof(short) \(\leq\) sizeof(int) \(\leq\) sizeof(long) \(\leq\) sizeof(long long)
实浮点类型
| 类型 | 大小 | 表示 |
|---|---|---|
float |
4 | 后缀 f 或 F,如 3.14F |
double |
8 | 默认为 double,如 3.14 |
long doub |
隐式转换
-
类型等级:
complex > imaginary > long double > double > float > 整型
-
低等级操作数转换到高等级,如:
1.f + 2L;long int 转 float,执行 float 加法;1.0 + 1.0f + 1;左结合,float 转 double 执行 double 加法;int 转 double 执行 double 加法;
-
数组到指针转换:
int a[3], b[3][4]; int *p = a; // 转换成 &a[0] int (*q)[4] = b; // 转换成 &b[0] -
整数提升:任何 等级 小于或等于
int等级 的整型,或是_Bool,运算时自动转为对应的int或是unsigned int。- 如果有高于
int等级,则低等级类型操作数转为高等级类型; - 提升后运算,
unsigned优先。
- 如果有高于
switch 语句
基本语法:
switch(expression) {
case constant-expression:
/* ... */
break; // 可选
case constant-expression: {
// 可以使用大括号分段
/* ... */
break; // 可选
}
default: //可选
/* ... */
}
switch 语句遵循以下规则:
-
可以有任意数量的
case语句;每个case后跟比较值constant-expression和 冒号:,其它都可以省略; -
比较值
constant-expression必须是常量或字面量;其类型应为整型或字符型; -
当测试值
expression等于比较值constant-expression时,执行对应case后的语句,直到遇到break语句;如果
case语句不包含break,控制流将会继续执行后续的case后的语句(包括default后的语句);当
break,switch终止,控制流将跳转到switch语句后的下一行。
函数
定义与声明
- 定义:给出 函数名、形参、返回类型;有 函数主体(函数的内部逻辑代码);
- 声明:给出 函数名、形参、返回类型;无 函数主体;也叫函数的接口信息。
实参与形参
- 定义时必须给出形参的名称;声明时可以只给出类型。
- 函数调用时实参表达式按 从右往左 顺序赋予形参。
常见数学函数(要求掌握)
<stdlib.h>
int abs(int n);
<math.h>
double fabs(double arg);double exp(double arg);计算 e 的幂;double log(double arg);计算以 e 为底的对数;double log10(double arg);double pow(double base, double exponent);幂函数;double sqrt(double arg);double sin(double arg);;还有 cos, tan, asin, atan, atan2;double ceil(double arg);向上取整;double floor(double arg);向下取整。
全局变量和局部变量
初始化
全局变量 和 静态变量 自动初始化为 0;局部变量 必须手动初始化。
外部(external)变量
-
extern关键字,用于 声明 一个 全局变量,表示该变量是在其它文件中定义的,当前文件只是引用而不进行定义。使用
extern声明的意义:-
全局变量定义由外部程序给出,或
-
全局变量定义后置给出,如
int main() { extern int a; // 定义后置给出,全局变量 a = 12 /* ... */ } int a = 12;
-
声明 与 定义 的区别:
声明 仅引入标识符的名称和类型,在编译过程中不会分配内存或提供具体实现。
定义 不仅引入名称和类型,还分配了存储空间并提供了具体实现(函数)或者初始值(变量)。
对于变量,C 允许重复声明,但类型必须相同,编译器会忽略额外的声明;定义涉及实际的内存分配和定义,符号重复定义会导致链接阶段出错,因此编译器会报错。
在 定义 变量时,extern 可以被省略;但在 声明 变量时,extern 必须添加在变量前,即
extern int a; // 声明一个全局变量 a
int a; // 定义一个全局变量 a
extern int a = 0; // 定义一个全局变量 a
int a = 0; // 定义一个全局变量 a
因此,对变量而言,当在本源文件 (A) 中使用另一个源文件 (B) 的变量,有两种方法:
- 在 A 中用
extern声明 B 中定义的变量(全局变量); - 在 A 中添加 B 文件对应的头文件,这个头文件包含 B 中的变量声明,也即在头文件中用
extern声明该变量。
extern int a;中类型int可省略,即extern a;;但其它类型不可省略。
静态(static)变量
-
static只能修饰变量; -
初始化:
static变量默认初始化为 0; -
持久性:
static变量和全局变量一样存储在静态数据区,生命周期为整个程序,可用于延长局部变量的生命周期;且只会初始化一次,如以下程序
#include <stdio.h> int fun(void){ static int count = 3; // 事实上此赋值语句从来没有执行过 return count--; } int count = 1; int main(void) { printf("global\t\tlocal static\n"); for(; count <= 3; ++count) printf("%d\t\t%d\n", count, fun()); return 0; } // 输出为: // global localstatic // 1 3 // 2 2 // 3 1 -
隐藏性:同时编译多文件时,所有未加
static前缀的 全局变量 和函数都具有全局可见性。即静态变量时局部变量,作用域 是一个块或一个文件; -
重名时会 屏蔽 作用域外部的定义。
数组
-
定义 时,除第一维外其他维的长度均不可忽略,如
int arr[][3] = {0, 1, 2, 3, 4, 5}; // 相当于 int arr[2][3] = {0, 1, 2, 3, 4, 5}; -
初始化 时,只对部分元素赋值,此时剩余的元素会被自动赋 0 值。
-
函数传参 时,
int arr[const]表示形参arr不可修改。 -
几种数组类型的变体:
- 已知常量大小的数组,如
int arr[2][3]; - 变长度数组(VLA)(C99),如
int arr[n]; - 未知大小数组,如
int a[];
VLA 和 未知大小数组 只能声明于 块作用域 或 函数原型 作用域中。
函数声明中,数组的第一个维度都被替换为未知大小。如形参
int arr[3][3]编译解释为int arr[][3]。 - 已知常量大小的数组,如
变长数组(VLA)初始化问题
在C语言中,可以在声明数组的同时对其进行初始化,但有一些限制。对于静态数组(即大小在编译时就已确定的数组),你可以在声明时对其进行初始化。但对于变长数组(VLA,即大小在运行时确定的数组),不支持使用初始化器来初始化。
静态数组的声明并初始化示例如下:
int array[] = {1, 2, 3}; // 静态数组声明并初始化这样会根据初始化列表中的元素数量确定数组的大小,并将数组初始化为相应的值。
然而,对于变长数组(VLA),不能在声明时进行初始化。以下代码是不允许的:
int size = 3; int array[size] = {1, 2, 3}; // 错误!VLA不能在声明时初始化对于VLA,你需要在运行时动态地为其赋值。这意味着你可以在之后的代码中使用循环或其他逻辑来为VLA分配内存并初始化其元素。
int size = 3; int array[size]; // 声明VLA // 在运行时使用循环为VLA初始化 for (int i = 0; i < size; i++) { array[i] = i + 1; }这段代码使用循环为VLA赋值,但请注意,无法在声明时使用初始化器对VLA进行初始化。
—— ChatGPT
字符串和字符数组
字符
char c0 = 'A';
char c1 = 65; // 字符是一个数字
char c2 = '\n'; // 特殊字符转义
char c3 = '\x41'; // 用16进制表示字符
char c4 = '\101'; // 用8进制表示字符
常见字符的 ASCLL 码:
- 0:
'\0'字符床结束标志; - 48~57:
'0' ... '9' - 65~90:
'A' ... 'Z' - 97~122:
'a' ... 'z'
字符串概述
-
结束符:C 中字符串以
'\0'作为结束符,处理字符串的标准库函数都需要依靠结束符来判定该字符串是否结束。因此请务必确保你的字符串(字符数组)含有结束符且位置正确。 -
字符串常量:字符字面量存储在静态存储区,具有持久性。如
"Hello World!",注意虽然表面上其结尾没有结束符,但实际上在内存中最后有结束符。 -
初始化:可以用 多个字符 或 字符串 初始化
char类型的数组元素,但在用多个字符初始化时需要手动赋于结束符char str[5] = {'H', 'e', 'l', 'l', 'o'}; // 不是字符串 char str[6] = {'H', 'e', 'l', 'l', 'o', '\0'}; char str[6] = "Hello"; char str[] = "Hello"; // 后三种声明式等价的字符串 -
输入:
scanf("%s", str);读入字符串时遇到空白字符停止,即仅得到空白字符之前的字符串。
常用字符串函数
-
gets()读入一行-
函数原型:
char *gets(char *str); -
gets()函数将用户输入的字符串读取到参数str所指向的字符数组中,知道遇到 换行符 或 文件结束符(EOF),然后将换行符替换为null终止符'\0'。 -
注意,如果输入的字符数超过了数组大小,就会导致缓冲区溢出,可能导致破坏程序的其它内存空间。
-
-
strlen(str):返回字符串长度,但不包括结尾空字符;时间复杂度线性。 -
strcat(toStr, fromStr):去掉toStr的结束符,并将fromStr连接到toStr后,返回toStr的首地址;注意toStr数组必须足够长。 -
strncat(toStr, fromStr, n):将fromStr的前n个字符连接到toStr后。 -
strcpy(toStr, fromStr):将fromStr(包括末尾终止符'\0')拷贝到toStr。 -
strncpy(toStr, from Str):拷贝前n个字符。 -
strcmp(str1, str2):按照字符集中的表示值逐个比较str1和str2的字符;str1大于str2时,返回大于 0 的整数;等于时,返回整数值 0;str1小于str2时,返回小于 0 的整数值。 -
strncmp(str1, str2):比较前n个字符的大小。 -
strlwr(str):将str的字母全部转化为小写;不改变除字母以外的字符。 -
strupr(str):将str的字母全部转化为大写。 -
strchr(str, c)字符检索-
函数原型:
char *strchr(const char *str, int c); -
strchr()函数在参数str指向的字符串中查找第一个出现的字符c,并返回指向该字符的指针;如果没有找到则返回NULL。
-
-
strstr(str1, str2)字符串检索-
函数原型:
char *strstr(const char *str1, const char *str2); -
strstr()函数在str1指向的字符串中查找第一个出现的str2字串,并返回指向该子串的指针;如果没有找到则返回NULL。
-
结构体
#pragma pack(N)
预编译指令 #pragma pack(N) 可以用来改变默认的对齐方式,将后继定义的结构体或共用体的对齐值设定为 N 字节。其中 \(N \in \{ 1, 2, 4, 8, 16, 32 \}\)。
结构体对齐规则
对齐的目的在于提高内存访问效率。按照合适的对齐规则,使得数据在内存中的存放方式更加整齐,这样处理器可以更快地读取和写入数据。
基本数据类型的对齐值通常等于其自身的大小(字节数)
- 对齐规则:结构体的对齐值 默认等于其最大成员的对齐值(即最大成员的大小);如果使用
#program pack(N)指令,则结构体的对齐值等于min(成员中对齐值最大值, N),即N规定了结构体中的 最大对齐值。- 结构体变量的首地址能被其对齐值整除;
- 每个成员相对于结构体首地址的偏移量都是
min(该成员大小, 结构体对齐值)的整数倍,如有需要编译器会在成员间加上填充字符; - 结构体总大小为其对齐值的整数倍,如有需要编译器会在末尾加上填充字符。
共用体(union)
共用体允许在相同的内存位置存储不同的数据类型,即其所有成员共享同一块内存。
union 语句格式:
union UnionName {
type1 member1;
type2 member2;
};
使用共用体时,可以通过不同的成员来访问共用体的内存空间。
内存大小(同 结构体 内存大小计算):共用体的大小必须足够容纳其中最大的成员;且总大小为共用体中 对齐字节数 的整数倍;
对齐字节数:若没有设定对齐字节数,则对齐字节数为最大成员的大小;否则为
min(最大成员大小, 设定的对齐字节数)。
枚举类型(enum)
枚举(Enumeration)是一种用户自定义的数据类型,用于定义命名的整数常量。
enum 语法结构:
enum EnumName{
Identifier1,
Identifier2,
/* ... */
};
-
默认情况下,枚举的第一个标识符的值为 0,后续的标识符依次加一。
-
可以显式地为枚举成员指定值,其后续地成员也是依次加一;标识符仅能定义一次,但多个成员可以拥有相同地常量值,如
enum Numbers {One = 1, Two, Three, First = 0, Second, Third}; -
枚举类型的大小与其底层的整数类型相同(通常为
int或unsigned int类型)。 -
C 语言中枚举元素的数据类型实质上是整数类型,即枚举类型在内部被实现为整数类型。
位域(Bit Fields)
位域允许在一个字节(或多个字节)中以位 (bit) 为单位对数据进行存储。
语法结构:
struct BitField {
type member_name : width;
type : width; // 无名位域(匿名位域)表示跳过若干位,不能被使用
type : 0; // 0宽度位域表示当前整数包已满,下个位域分配在新整数单元
/* ... */
};
-
位域的宽度不能超过其数据类型的大小;
-
位域的数据类型可以是
int,unsigned int,signed int等整型,也可以是枚举类型enum,_Bool; -
关于位域的内存存储:
-
相同类型的相邻位域的字段紧邻存储;
实测中,不区分有无符号(
signed int和unsigned int);int和long int算“同一种类型”。 -
内存每开辟一个新的单元,其大小位当前类型大小的字节数(
sizeof(type)),偏移量为其 对齐值 的整数倍;如当前单元所剩空间不够存放另一位域时,或下一位域的类型不同,则会开辟新的单元,并从下一单元起存放该位域;
-
0宽度位域将会强制下一位域分配在新单元;
-
除以上“单元式”内存分配规则外,位域对齐规则与结构体对齐规则相同。
-
-
位域不能求地址。
-
位域的操作和结构体的操作类似。
C 文件操作
printf() 格式化输出
格式化说明符基本形式:
"%[标志][最小字段宽度][.精度][长度修饰符] 转换说明符"
-
标志:可选,用于指定对齐,显示正负号等,如
符号 作用 -(负号) 左对齐 +(正号) 显式正负号 0 用零填充 -
最小字段宽度:可选,指定输出字段的最小宽度。
-
精度:可选,用于控制小数点后的位数或最大字符串函数。
-
长度修饰符:可选,用于指定输出类型的长度。
-
转换说明符:必须,指定要输出的数据类型。以下给出部分转换说明符:
| 类型 | 格式化字符串控制符 |
|---|---|
| 整数 | |
int |
%d |
short int |
%hd |
long int |
%ld |
long long int |
%lld |
unsigned int |
%u |
unsigned short |
%hu |
unsigned long int |
%lu |
unsigned long long int |
%llu |
| 字符 | |
char |
%c |
| 浮点数 | |
float |
%f |
double |
%lf |
long double |
%Lf |
| 指针 | |
void* 或任何其他类型指针 |
%p |
| 其它格式化字符串控制符 | |
| 字符串 | %s |
| 十六进制数 | %x(小写)%X(大写) |
| 八进制数 | %o |
| 指数表示法的浮点数 | %e(小写)%E(大写) |
| 百分号 | %% |
文件基础
文件类型:
- 文本文件(text);
- 二进制文件:以字符数组格式存放的数据。
文本文件基础:
- 文本由行构成,因此文本流默认为行缓冲,即遇到换行符文本处理函数才会启动。如
getchar()逐一读入字符,但字符流保存在行缓冲中直到换行或流结束。 - 部分文本流可能不存在结束,即
feof()函数永远为假。如键盘输入流。 - 文本文件操作分为 有格式文本操作函数 和 无格式文本操作函数。
二进制文件基础:
- 二进制本文是 byte 流,默认按块从磁盘读入或输出,即块缓冲。
- 二进制磁盘文件通常数据量较多,不只需要顺序读写,更多时候需要读写其中部分内容,即需要更新模式的支持。
相关函数与数据结构:头文件 <stdio.h> 给出了 C 语言与操作系统交互的函数与数据结构:
-
结构体 FILE:描述了控制与管理 IO 流需要的信息。编程时应使用
FILE*指针通过相关函数操作文件。 -
预定义标准流:
标准文件 文件指针(FILE*) 默认设备 标准输入 stdin 控制台键盘输入 标准输出 stdout 控制台输出显示设备 标准错误 stderr 控制台输出显示设备 -
函数:
- 文件访问
- 直接输入/输出
- 无格式文本输入/输出。标准输入/输出
- 格式化文本输入/输出。标准输入/输出,字符串输入/输出
- 文件位置
- 错误处理
- 文件操作
-
宏常量:EOF。
文件访问基础函数
打开文件 fopen()
-
函数原型:
FILE *fopen(const char *filename, const char *mode); -
参数:
filename是一个字符串,表示要打开文件的文件名或文件路径;mode是一个字符串,用于指定文件的打开模式。 -
返回值:
若成功打开
filename所指示文件,返回指向关联到该文件的文件流的指针;若错误返回空指针
NULL;最好在使用文件指针之前检查其是否为NULL。 -
打开模式:
模式字符串 含义 解释 文件存在 文件不存在 "r"只读 打开已有文件读取 从头读 返回 NULL"w"只写 创建文件以写入 销毁内容 创建新文件 "a"追加 后附到文件 写到结尾 创建新文件 "r+"读写 打开文件以读/写 从头读 返回 NULL"w+"读写 创建文件以读/写 销毁内容 创建新文件 "a+"读写 打开文件以读/写 写到结尾 创建新文件 文件访问标签
"b"可选地指定以二进制模式打开文件,如:"rb", "wb", "ab", "r+b", "w+b", "a+b"。此标签仅在 Windows 系统上生效。在附加文件访问模式下,数据被写入到文件尾,而不考虑文件位置指示器的当前位置。
关闭文件 fclose()
-
原型:
int fclose(FILE *stream); -
作用:关闭给定的文件流。冲入任何未写入到缓冲数据到 OS。舍弃任何为读取的缓冲数据。
-
这是一个很重要的步骤,因为在程序中打开的每个文件都会消耗系统资源。
检查文件结束 feof
-
原型:
int feof(FILE *stream); -
作用:
feof()会检查stream指向的文件是否已经到达了文件末尾。当文件读取操作遇到文件末尾时,文件结束标志会被设置为真(非零值)。 -
返回值:
如果文件结束标志已设置,返回非零值;
如果文件尚未到达末尾末尾或发生了错误,返回零。
二进制文件读写函数
读取数据 fread()
-
原型:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); -
参数:
ptr是一个指向存储读取数据的内存块的指针;size是每个数据项的字节数;nmemb是要读取的数据项的数量;stream是一个指向文件的指针,用于指定从哪个文件读取数据。 -
返回值:返回成功读取的数据项数量。
-
作用:从文件当前位置开始,每次读取
size个字节的数据到ptr指向的内存块中,直到读取nmemb个数据项或到达文件末尾位置。 -
fread()不区别文件尾和错误,须用feof()和ferror判断。
写入数据 fwrite()
-
原型:
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream); -
参数:
ptr是一个指向要写入的数据的指针;size是每个数据项的字节数;nmemb是要写入的数据项的数量;stream是一个指向文件的指针,用于指定写入数据的目标文件。 -
返回值:返回成功写入的数据项数量。返回值与
nmemb不同,则写入时可能发生了错误。 -
作用:每次写入
size个字节的ptr指向的内存块中的数据到由stream指定的文件中,总共写入nmemb个数据项。
文本文件操作
格式化读 fscanf()
-
原型:
int fscanf(FILE *stream, const char *format, ...); -
参数:
steam是一个指向文件的指针,用于指定从哪个文件读取数据;format是一个格式化字符串,指定了要读取的数据类型和格式;···表示可变数量的参数,根据format字符串中指定的格式进行读取。 -
返回值:
返回成功匹配并赋值的变量数量;若输入首个参数赋值前发生失败则返回 EOF。
-
作用:
fscanf()根据format字符串的指定格式从文件中读取数据,并根据格式对数据进行转换和赋值,存储到相应的变量中。
格式化写 fprintf()
-
原型:
int fprintf(FILE *stream, const char *format, ...); -
返回值:
返回成功写入文件的 字符数;如果发生错误,则返回一个负数表示出错(输出错误或编码错误)。
字符串读 fgets()
-
原型:
char *fgets(char *str, int n, FILE *stream); -
参数:
str是一个指向字符数组的指针,用于存储读取到的数据;n是要读取的最大字符数(包括存储字符串结束符'\0',即从文件流读取最多n - 1个字符)。 -
作用:
fgets()用于从指定文件中读取一行数据;fgets()会读取指定长度的字符,直到遇到换行符'\n'或达到指定的字符数(n - 1),然后将读取的数据存储到提供的字符数组中,并在末尾添加'\0'作为字符串结束符; -
返回值:
fgets成功读取数据时返回第一个参数str;如果达到文件尾或发生错误,则返回空指针
NULL。 -
注意事项:
fgets()在读取时会保留换行符'\n'。
字符串写 fputs()
-
原型:
int fputs(const char *str, FILE *stream); -
作用:
fputs()将字符串str中的内容按顺序写入到文件流stream中,直到遇到字符串的结束符'\0'。 -
返回值:成功写入时返回非负数;若出现错误则返回 EOF(通常为
-1)。 -
puts()等价于fputs(str, stdout)。
字符读 fgetc()
-
原型:
int fgetc(FILE *stream); -
作用:从文件流
stream中以unsigned char类型读取下一个字符,并返回其对应的int类型整数值(ASCLL 码)。 -
返回值:返回读取字符对应的整数值;若到达文件结束符或者出现错误,则返回 EOF。
-
getchar()等价于fgetc(stdin)。
字符写 fputc()
-
原型:
int fputc(int character, FILE *stream); -
参数:
character是要写入文件的字符,以整数形式传递(ASCLL 码)。 -
返回值:成功写入时返回写入的字符
character;若出现错误则返回 EOF(通常为-1)。
随机读写
寻找文件位置 fseek
-
原型:
int fseek(FILE *stream, long offset, int origin); -
参数:
stream参数是一个指向 FILE 类型的指针,指向要移动文件指针的文件;offset参数是一个 long 类型的值,表示偏移量;可以为正数、负数或零,用于指定文件指针相对于origin的位置;origin参数是一个整数,用于指定起始位置。可以取三个值之一:SEEK_SET(文件起始处)、SEEK_CUR(当前位置)或SEEK_END(文件末尾)。 -
作用:
fseek可以移动文件指针到指定位置,然后进行读取或写入操作。 -
返回值:成功执行时返回 0;否则返回非零值。
-
若
stream以 二进制模式 打开,offset可用于上述三个位置的偏移量;若
steam以 文本模式 打开,则offset只能为零(任意origin)。 -
以
"a"或"ab"模式打开文件,则会阻止fseek等函数对文件位置指示器的修改;可用"a+"或"ab+"让fseek等函数生效。
移到文件首 rewind
-
原型:
void rewind(FILE *stream); -
作用:将文件指针设置为文件的起始位置;等价于
fseek(stream, 0, SEEK_SET)。 -
rewind()不会清除文件缓冲区,在重新定位后,需要小心处理缓冲区的内容,以免数据丢失。 -
rewind()对二进制方式和文本方式都有效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号