第一次个人编程作业
论文查重
计算模块接口的设计与实现
整体流程

类图
- TxtIO:txt文本的输入输出,转字符串
- SimHash:计算字符串的simhash值
- Hamming:通过两个01字符串计算海明距离、相似度
所有method都是static,三个类之间没有直接调用,使用方法写在注释中,由使用者调用

核心算法
算法的关键method是SimHash类的getSimHash

- 分词
- 给定一段语句,进行分词,得到有效的特征向量,然后为每一个特征向量设置1-5等5个级别的权重(如果是给定一个文本,那么特征向量可以是文本中的词,其权重可以是这个词出现的次数)。例如给定一段语句:“温柔正确的人总是难以生存”,分词后为:“温柔 正确 的 人 总是 难以 生存”,然后为每个特征向量赋予权值:温柔(4) 正确(5) 的(1) 人(2) 总是(2) 难以(3) 生存(5) ,其中括号里的数字代表这个单词在整条语句中的重要程度,数字越大代表越重要。
- hash
- 通过hash函数计算各个特征向量的hash值,hash值为二进制数01组成的n-bit签名。比如“温柔”的hash值Hash(温柔)为100101,“正确”的hash值Hash(正确)为“101011”。就这样,字符串就变成了一系列数字。
- 加权
- 在hash值的基础上,给所有特征向量进行加权,即W = Hash * weight,且遇到1则hash值和权值正相乘,遇到0则hash值和权值负相乘。例如给“温柔”的hash值“100101”加权得到:W(温柔) = 100101_4 = 4 -4 -4 4 -4 4,给“正确”的hash值“101011”加权得到:W(博正确)=101011_5 = 5 -5 5 -5 5 5,其余特征向量类似此般操作。
- 合并
- 将上述各个特征向量的加权结果累加,变成只有一个序列串。拿前两个特征向量举例,例如“温柔”的“4 -4 -4 4 -4 4”和“正确”的“5 -5 5 -5 5 5”进行累加,得到“4+5 -4+-5 -4+5 4+-5 -4+5 4+5”,得到“9 -9 1 -1 1”。
- 降维
- 对于n-bit签名的累加结果,如果大于0则置1,否则置0,从而得到该语句的simhash值,最后我们便可以根据不同语句simhash的海明距离来判断它们的相似度。例如把上面计算出来的“9 -9 1 -1 1 9”降维(某位大于0记为1,小于0记为0),得到的01串为:“1 0 1 0 1 1”,从而形成它们的simhash签名。
计算模块接口部分的性能改进
算法准确性的提升
提升取权重、加权步骤的有效程度是提升算法准确性最有效的措施
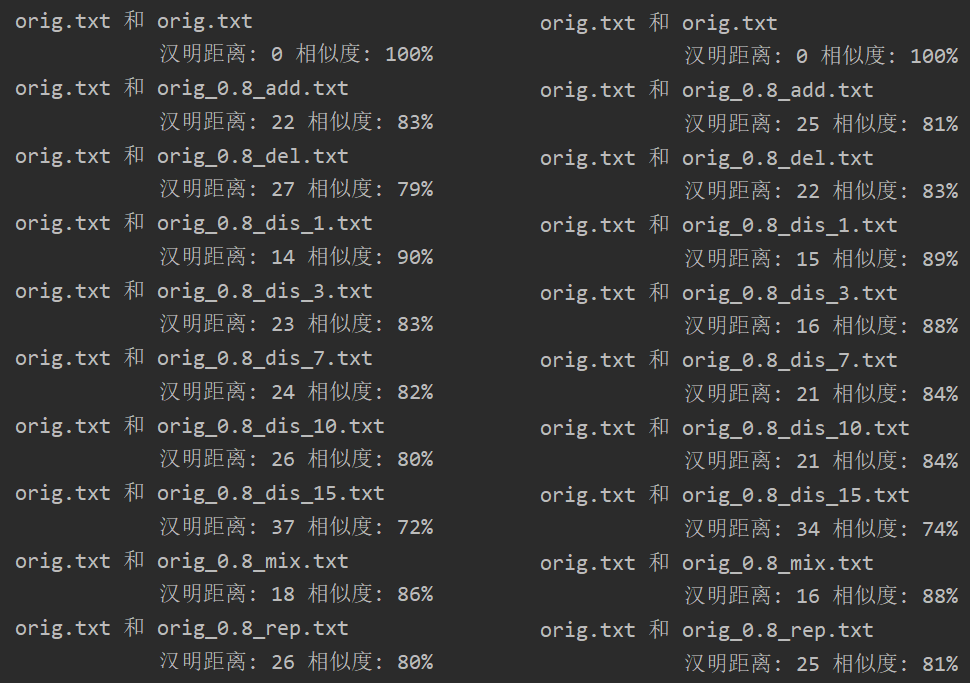
左边是对所有关键词取权重1,右边是对关键词词频从高到低分10级,分别取(10、9、8 -> 0)权重
从测试结果可以观察到,整体来说算法准确性有一定的提升
性能分析
- Overview
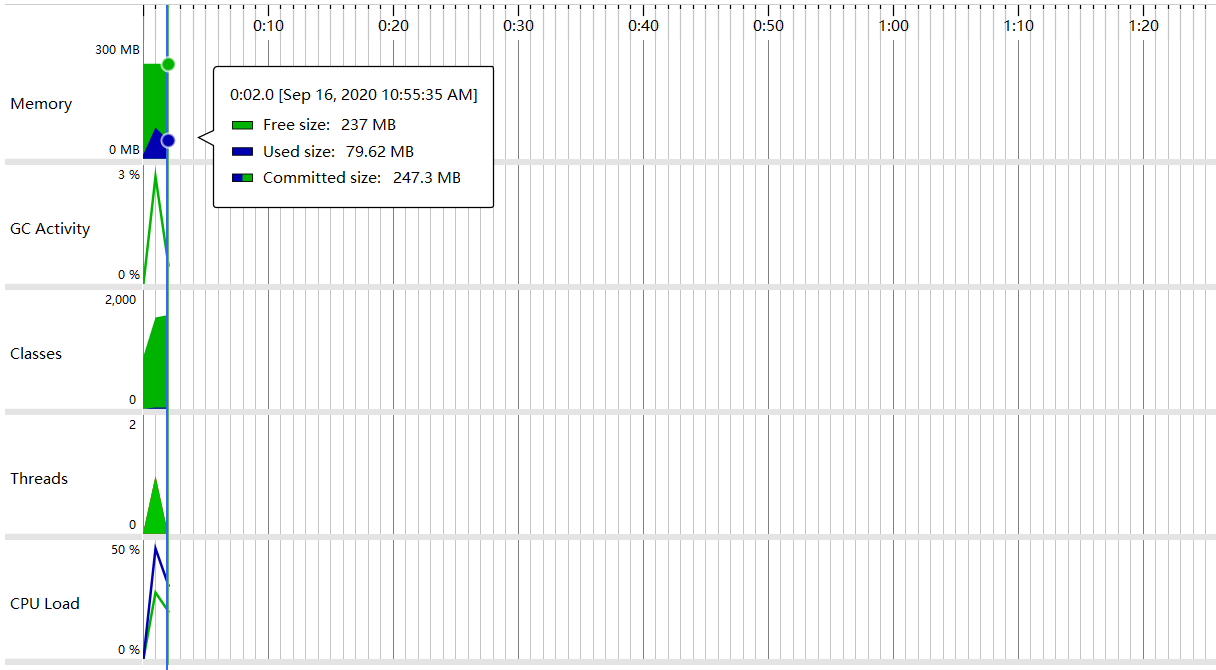
- 类的内存消耗
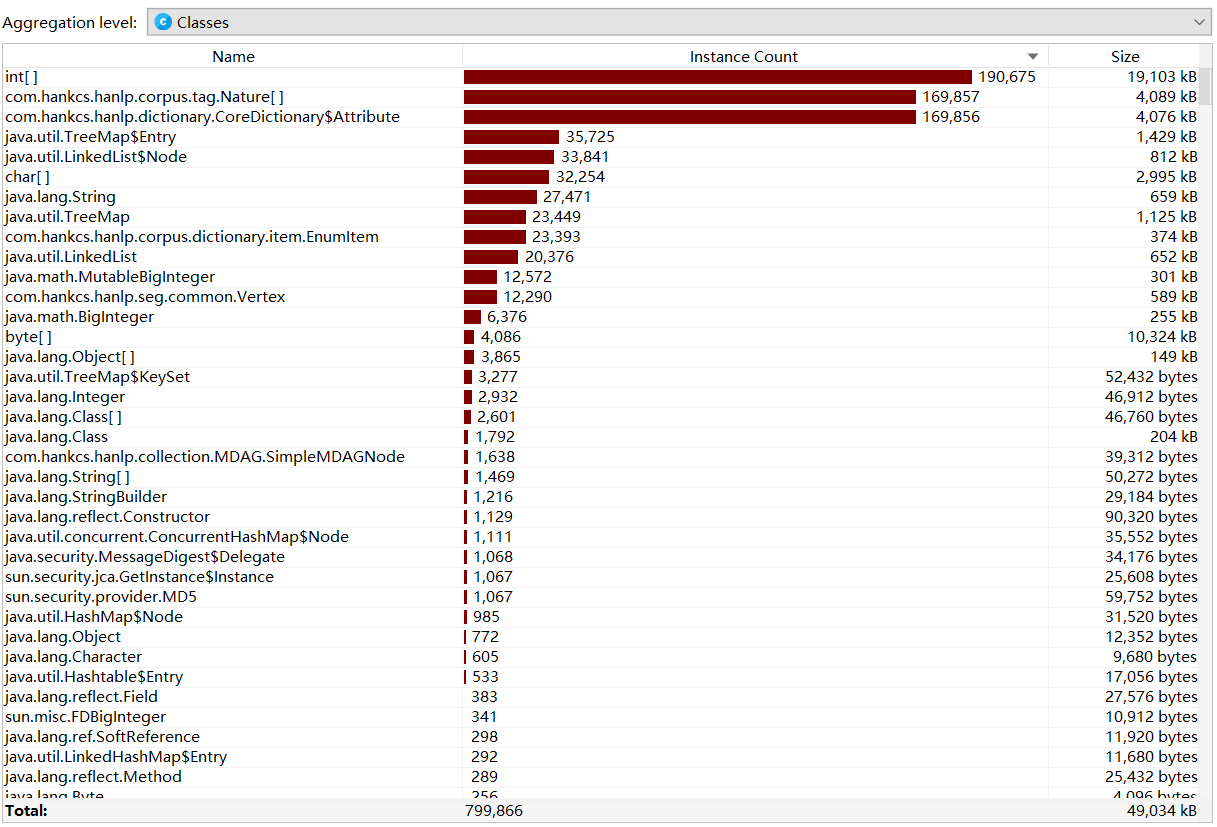
- method使用时间

最耗时的method是HanLp.extractKeyword,即分词、取关键词与词频花费了最多的时间
计算模块部分单元测试展示
TxtIOTest
import org.junit.Test;
public class TxtIOTest {
@Test
public void readTxtTest(){
String str = TxtIO.readTxt("D:/test/sim/orig.txt");
String[] strings = str.split(" ");
for (String string : strings)
System.out.println(string);
}
@Test
public void writeTxtTest(){
double[] elem = {0.11,0.22,0.33,0.44,0.55};
for(int i = 0; i < elem.length; i++){
TxtIO.writeTxt(elem[i],"D:/test/sim/ans.txt");
}
}
@Test
public void readTxtFailTest(){
String str = TxtIO.readTxt("D:/test/sim/none.txt");
}
@Test
public void writeTxtFailTest(){
double[] elem = {0.11,0.22,0.33,0.44,0.55};
for(int i = 0; i < elem.length; i++){
TxtIO.writeTxt(elem[i],"User:/test/sim/ans.txt");
}
}
}
测试覆盖率:

SimhashTest
import org.junit.Test;
public class SimHashTest {
@Test
public void hashTest(){
String[] strings = {"一位","真正","的","作家"};
for (String string : strings){
String hash = SimHash.hash(string);
System.out.println(hash);
System.out.println(hash.length());
}
}
@Test
public void getSimHashTest(){
String str0 = TxtIO.readTxt("D:/test/sim/orig.txt");
String str1 = TxtIO.readTxt("D:/test/sim/orig_0.8_add.txt");
System.out.println(SimHash.getSimHash(str0));
System.out.println(SimHash.getSimHash(str1));
}
@Test
public void shortStringSimHashTest(){//测试str.length()<200的情况
System.out.println(SimHash.getSimHash("一位正真的作家"));
}
}
测试覆盖率:

其中hash方法的catch内容无法被测试
HammingTest
import org.junit.Test;
public class HammingTest {
@Test
public void getDistanceTest(){
String str0 = TxtIO.readTxt("D:/test/sim/orig.txt");
String str1 = TxtIO.readTxt("D:/test/sim/orig_0.8_add.txt");
System.out.println(Hamming.getDistance(SimHash.getSimHash(str0),SimHash.getSimHash(str1)) + " 相识度: "
+ (100-Hamming.getDistance(SimHash.getSimHash(str0),SimHash.getSimHash(str1))*100/128)+"%");
//测试str0.length()!=str1.length()的情况
str0 = "10101010";
str1 = "1010101";
System.out.println(Hamming.getDistance(str0,str1));
}
@Test
public void getSimilarityTest(){
String str0 = TxtIO.readTxt("D:/test/sim/orig.txt");
String str1 = TxtIO.readTxt("D:/test/sim/orig_0.8_add.txt");
System.out.println("str0和str1的汉明距离: " + Hamming.getDistance(SimHash.getSimHash(str0),SimHash.getSimHash(str1))
+ " 相识度: " + Hamming.getSimilarity(SimHash.getSimHash(str0),SimHash.getSimHash(str1)));
}
}
测试覆盖率:

TestCase
import org.junit.Test;
public class TestCase {
@Test
public void origAndAllTest(){
String[] str = new String[10];
str[0] = TxtIO.readTxt("D:/test/sim/orig.txt");
str[1] = TxtIO.readTxt("D:/test/sim/orig_0.8_add.txt");
str[2] = TxtIO.readTxt("D:/test/sim/orig_0.8_del.txt");
str[3] = TxtIO.readTxt("D:/test/sim/orig_0.8_dis_1.txt");
str[4] = TxtIO.readTxt("D:/test/sim/orig_0.8_dis_3.txt");
str[5] = TxtIO.readTxt("D:/test/sim/orig_0.8_dis_7.txt");
str[6] = TxtIO.readTxt("D:/test/sim/orig_0.8_dis_10.txt");
str[7] = TxtIO.readTxt("D:/test/sim/orig_0.8_dis_15.txt");
str[8] = TxtIO.readTxt("D:/test/sim/orig_0.8_mix.txt");
str[9] = TxtIO.readTxt("D:/test/sim/orig_0.8_rep.txt");
String ansFileName = "D:/test/sim/ans.txt";
for(int i = 0; i <= 9; i++){
double ans = Hamming.getSimilarity(SimHash.getSimHash(str[0]),SimHash.getSimHash(str[i]));
TxtIO.writeTxt(ans,ansFileName);
}
}
@Test
public void origAndOrigTest(){
String str0 = TxtIO.readTxt("D:/test/sim/orig.txt");
String str1 = TxtIO.readTxt("D:/test/sim/orig.txt");
String ansFileName = "D:/test/sim/ans.txt";
double ans = Hamming.getSimilarity(SimHash.getSimHash(str0),SimHash.getSimHash(str1));
TxtIO.writeTxt(ans,ansFileName);
}
//其余单个文件的测试代码类似
}
测试结果:
计算模块部分异常处理说明
输入文本太短时,HanLp无法取得关键词,会丢出异常
public class ShortStringException extends Exception {
public ShortStringException() {
super();
}
public ShortStringException(String message) {
super(message);
}
public ShortStringException(String message, Throwable cause) {
super(message, cause);
}
public ShortStringException(Throwable cause) {
super(cause);
}
}
public static String getSimHash(String str){
int[] v = new int[128];//用数组表示特征向量,取128位,从0 1 2 位开始表示从高位到低位
try{
if(str.length() < 200) throw new ShortStringException("文本过短!");
}catch (ShortStringException e){
e.printStackTrace();
return null;
}
List<String> keywordList = HanLP.extractKeyword(str, str.length());//取出所有关键词
//以下代码省略
}
测试结果:

PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 计划阶段所花的 | 60 | 60 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 360 | 470 |
| Design Spec | 生成设计文档 | 90 | 30 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 90 | 60 |
| Coding | 具体编码 | 240 | 310 |
| Code Review | 代码复审 | 60 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 180 | 300 |
| Reporting | 报告 | ||
| Test Repor | 测试报告 | 60 | 90 |
| Size Measurement | 计算工作量 | 60 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 180 | 220 |
| Total | 合计 | 1440 | 1610 |
问题
IDEA中运行查重率与cmd中运行jar的到的结果不同:将输入文件编码设置为UTF-8后,重新编译打包即可
总结
-
关于资料方面:资料的质量参差不齐,找到高质量的资料能节省很多时间
-
性能改进方面:想找到完全符合自己要求,而没有做多余动作的库不容易啊,有HanLp能帮我分词、计算词频、排序,我也该满足了
-
平时偷懒,没写代码,好多东西东忘记了,软工作业也算是一个温故知新的好机会吧

